基于辅助模态监督训练的情绪识别神经网络
2020-11-17邹纪云许云峰
邹纪云 许云峰


摘 要:为了解决多模态数据中数据样本不平衡的问题,利用资源丰富的文本模态知识对资源贫乏的声学模态建模,构建一种利用辅助模态间相似度监督训练的情绪识别神经网络。首先,使用以双向门控单元为核心的神经网络结构,分别学习文本与音频模态的初始特征向量;其次,使用SoftMax函数进行情绪识别预测,同时使用一个全连接层生成2个模态对应的目标特征向量;最后,利用该目标特征向量计算彼此之间的相似度辅助监督训练,提升情绪识别的性能。结果表明,该神经网络可以在IEMOCAP数据集上进行情绪4分类,实现了826%的加权准确率和813%的不加权准确率。研究结果为人工智能多模态领域的情绪识别以及辅助建模提供了参考依据。
关键词:计算机神经网络;情绪识别;有监督训练;深度学习;多模态
中图分类号:TP31113 文献标识码:A doi:10.7535/hbkd.2020yx05006
Abstract:In order to solve the problem of imbalance of data samples in multi-modal data, the resource-rich text modal know-ledge was used to model the resource-poor acoustic mode, and an emotion recognition neural network was constructed by using the similarity between auxiliary modes to supervise training. Firstly, the neural network with bi-GRU as the core was used to learn the initial feature vectors of the text and acoustic modalities. Secondly, the SoftMax function was used for emotion recognition prediction, and simultaneously a fully connected layer was used to generate the target feature vectors corresponding to the two modalities. Finally, the target feature vector assisted the supervised training by calculating the similarity between each other to improve the performance of emotion recognition. The results show that this neural network can perform four emotion classifications on the IEMOCAP data set to achieve a weighted accuracy of 82.6% and an unweighted accuracy of 81.3%. The research result provides a reference and method basis for emotion recognition and auxiliary modeling in the multi-modal field of artificial intelligence.
Keywords:computer neural network; emotion recognition; supervised training; deep learning; multimodal
情绪通常由组合的多模态信息表示[1-2]。在表达不同情绪时,每个模态信息具有不同的比例。例如,惊奇和愤怒往往包含较少的文本模态信息,而声学模态信息在识别这2种情绪方面更为重要和有效。针对多模态情绪识别问题,本文着重从文本和声学2种模态进行情绪识别研究。
提取不同模态特征并寻找互补信息进行融合是解决模态信息缺失、提高多模态情绪识别性能的关键。目前已有的表示方法通常分为联合表示和协调表示。联合表示最简单的例子是不同模态特征的直接组合。DMELLO等[3]和PORIA等[4]利用双向长期短期记忆网络分别提取不同模态特征,控制它们在相同尺寸后进行拼接融合。在此基础上,PORIA等[5]又引入了注意力机制,进一步改进了融合方法。在协调表示方法上,GHOSAL等[6]提出了一种基于递归神经网络的多模态注意力框架,该框架利用上下文信息进行话语水平的情感预测。LEE等[7]利用可训练的注意力机制学习这些形态特征向量之间的非线性相关性,有助于在时域中保留数据的情绪信息,限制不同模态之间的信息协调表示[1]。PAN等[8]提出了一种联合嵌入模型,探索了视频模态与文本模态语义之间的关系。XU等[9]将联合空间中的深层视频模型和合成语言模型的输出距离最小化,共同更新这2个模型,提高了情绪识别任务性能。除表示方法外,多任务联合学习已广泛用于情感识别领域。AKHTAR等[10]提出了一个深度多任务学习框架,该框架共同执行情感和情绪分析。LI等[11]利用传统的机器学习方法对情绪进行分类,使用文本模态提取情绪诱因。XIA等[12-13]提取文档中潜在的情绪和诱因,进一步提出了一种基于循环递归神经网络分层网络的联合情绪-诱因提取框架。
这些代表性的融合方法在很大程度上依赖于有效的输入功能,如果缺失了某些模態信息,则无法有效完成情绪识别任务。同时,多任务联合学习的子任务大多通过损失函数直接进行交互,缺乏进一步捕获子任务之间相关信息的方法。
本文并没有使用统一的框架学习不同模态信息的特征表示,而是针对不同模态构建了不同的神经网络模型来学习表示,为了更有效地利用丰富的模态资源,提出了一种使用辅助模态监督训练的多任务情绪识别模型,通过最大化与辅助模态的相似性,提高情感识别任务的性能。
1 模态表示及多任务学习
11 模态表示
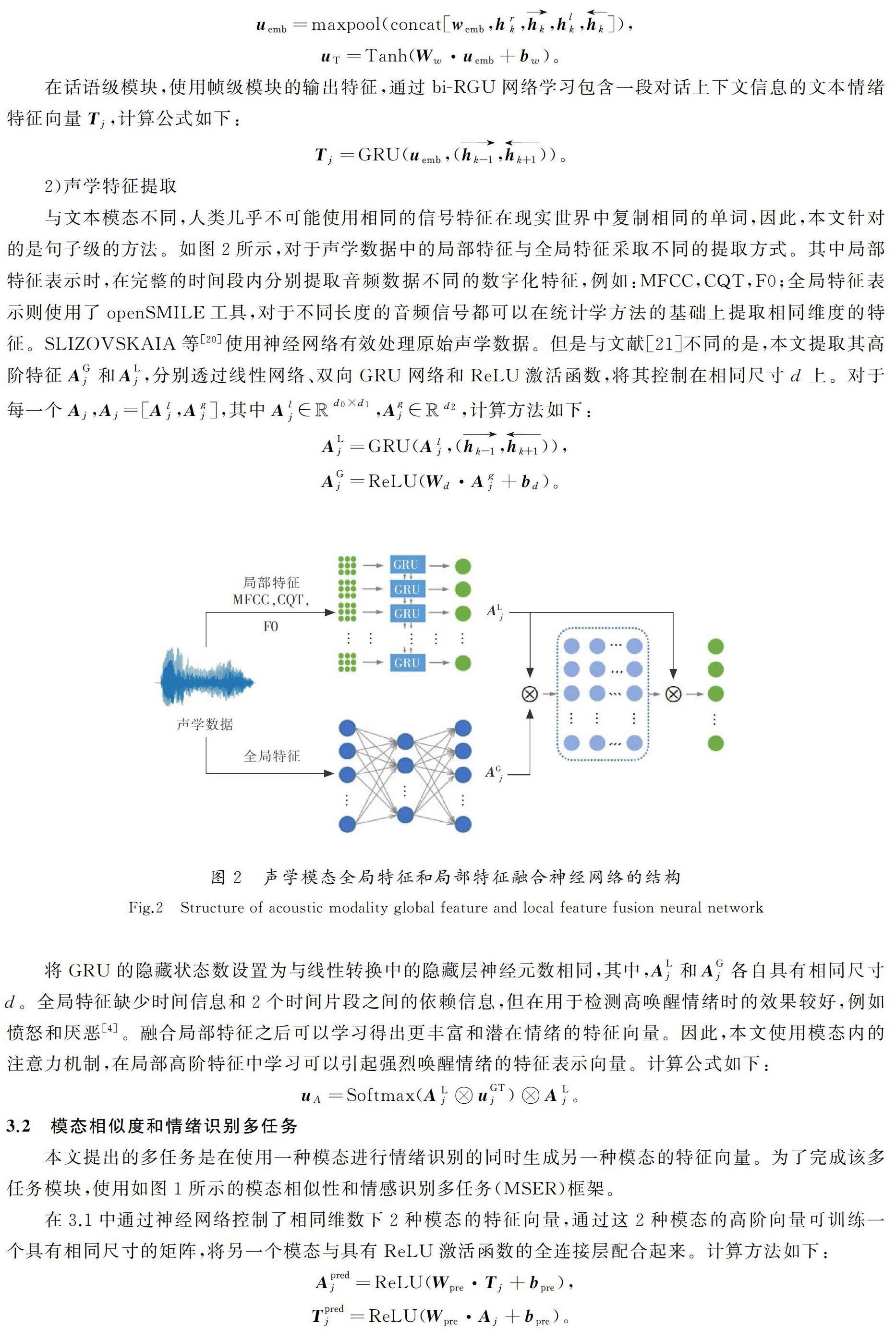
在文本模态中,使用word2vec预训练词典进行嵌入,并透过双向递归神经网络获取包含上下文信息的高阶特征仍然是一种主流且有效的方法。JIAO等[14]使用分层门控递归单元网络在话语级别探索文本模态的特征表示。在声学模态中,本文将现有基于特征工程的特征表示分为2种:局部特征和全局特征,认为语音片段内的局部特征信号是稳定的,全局特征是通过测量多个统计数据(例如平均、局部特征的偏差)进行计算。ZHOU等[15]利用openSMILE工具包[16]提取声学的全局特征,每个声音片段都会获得1 582个统计声学特征。LI等[17]使用LibROSA语音工具包[18],从原始语音中以25 ms帧窗口大小和10 ms帧间隔提取声音的局部特征,最终提取了41维帧级声学局部特征。同时考虑这2种特征的原因是全局特征缺少时间信息,且在2个片段之间缺乏依存关系。根据不同特征的特点,本文使用深度学习方法将它们融合在一起,以获得更有效的声学模态表示信息。
12 多任务学习
AKHTAR等[10]提出了基于上下文级别的模态注意框架,用于同时预测多模态样本的情感和表达的情绪。在分类任务设置上,情感分类分支包含用于分类的SoftMax层,而对于情绪分类,每种情绪分别使用Sigmoid层。XU等[9]提出了一个解决情绪诱因提取(ECPE)任务的2步框架,该框架执行独立的情绪提取或者诱因提取,进行情绪-诱因配对和过滤。为了进一步获得任务之间可以相互促进的信息,本文提出将计算声学和文本模态之间的相似度作为辅助任务的方法,以便将一个任务的预测值直接参与到另一个任务中。
2 问题定义
4.4 训练细节和参数设置
采用PyTorch框架实现整体模态相似性和情绪识别多任务模型。在每个训练时期开始时随机打乱训练集,在提取文本和声音模态特征的过程中,将最后1个维度参数d设置为100,当在句子级别上进行上下文信息学习时,双向GRU隐藏状态的维度设置为300,最后1个完全连接层包含100个神经元。声学模态的不同特征是在模态内进行拼接的,每个声学特征模型的隐藏状态尺寸设置为50,所有GRU模块的层数设置为1。采用Adam函数[27]作为优化器,将学习率设置为1×10-4。终止训练的条件是验证集的loss值连续10轮不再下降。
4.5 对比基线
将本文模型的各个模块与当前最新的4个基线模型进行比较,4个模型如下。
1)bcLSTM:可以包含句子级双向上下文信息LSTM,使用CNN提取的多模态特征。
2)MDNN:半监督的多路径生成神经网络,通过openSMILE提取的声学特征。
3)HiGRU:一个分层的门控循环单元(HiGRU)框架,文本模态特征由较低级别的GRU提取。
4)HFFN:使用双向LSTM,直接连接不同的局部交互作用,并将2个级别的注意力机制与CNN提取的多模态特征整合在一起。
4.6 实验结果与讨论
1)将使用辅助模态监督训练情绪识别神经网络的性能分析结果在IEOMCAP和MOSI数据集上与4个基线进行比较,如表3所示。
由表3可以看出,本文模型在4个评估指标上均优于其他方法。其中声学模态未加权准确率在IEMOCAP数据集上有显著改善,文本模态的WA和UWA也均有所改善,分别实现了0.5%和0.7%的提升。在CMU-MOSI数据集上,文本和声学模态的F1值分别比最高基准提高0.7%和0.3%。基于以上实验结果,分析如下:①本文模型对提高精度有一定的作用,声学模态的改进效果比文本模态更胜一筹。 CMU-MOSI数据集是一种情感分类任务,在CMU-MOSI数据集上2种模态的F1值已得到改善,表明获得了更加平衡的识别结果,在避免大多数预测都只具有一种情感的情况下提高了准确性。此外,文本模态似乎对声学模态更有帮助。②本文模型在IEMOCAP数据集所有模态上的性能都有所提高,但在CMU-MOSI数据集上却没有显著提高。由于从YouTube抓取的CMU-MOSI数据集是从实际情况中获得的,IEMOCAP数据集是基于演员的表演,因此,本文模型还需要改进对更多隐藏句子情感的识别。
2)对情绪识别任务和模态相似性任务的目标函数设置权重,分析权重对最终任务性能的影响,并通过权重参数λ进行调节。
首先,使用非端到端技术实现原始输入模态和预测生成模态的融合,作为最终性能检测方法。MSER模型训练后分别获得预测模态(Apred,Tpred),预测生成模态用于替换模型测试阶段中的原始输入模态T或A之一。融合实验(Apred+T,Tpred+A)的结果如图3所示,通过混淆矩阵可以更加直观地发现,声学模态在得到预测生成的文本模态向量后,其性能得到了明显改善。
其次,将文本模态和声学模态情绪识别任务的目标函数权重μ设置为0.5,利用不同的情绪识别和模态相似性任务权重,分析对整体框架的影响,如图4所示。本文使用的权重设置为01~05,其中水平轴代表权重,垂直轴代表情感识别任务的未加权准确性(UWA)。由图4可知,当权重为0.3时,文本模态和声学模态的情绪识别性能最佳。综上所述,设置计算出的模态相似度影响目标函数的任务,可以促進情绪识别任务性能的提高;情绪识别任务仍应设置为权重较大的主要任务,情绪识别任务上的参数更新对整个框架具有较大的影响。
5 结 语
1)本文提出了一個模态相似度和情绪识别多任务框架,利用辅助模态监督训练方法,解决了跨模态情绪识别过程中的一些缺陷。
2)使用非端到端方法完成了最终任务,大量实验证明了该方法对情绪识别的有效性。
3)所提方法通过使用来自一种模态的知识对另一种模态进行建模,这种通过计算模态之间相似度拟合其他模态情绪分类的特征向量方法,可以以一种真正有效的方式利用不同模态之间的补充信息,实现了多模态数据相关性的更有效利用。
4)本文方法尚未构建端到端模型,未来将继续探索使用辅助模态的端到端方法,以实现在缺失某些模态情况下提高单个模态性能的目标。
参考文献/References:
[1] BALTRUSAITIS T,AHUJA C,MORENCY L P.Multimodal machine learning:A survey and taxonomy[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2019,41(2):423-443.
[2] CHEN J. Natural Language Processing and Attentional-Based Fusion Strategies for Multimodal Sentiment Analysis[D]. London: Imperial College London, 2018.
[3] DMELLO S K, KORY J. A review and meta-analysis of multimodal affect detection systems[J]. ACM Computing Surveys, 2015, 47(3): 1-36.
[4] PORIA S,CAMBRIA E,HAZARIKA D,et al.Context-dependent sentiment analysis in user-generated videos[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics(Volume 1:Long Papers).[S.l.]: Association for Computational Linguistics,2017:873-883.
[5] PORIA S, CAMBRIA E, HAZARIKA D, et al. Multi-level multiple attentions for contextual multimodal sentiment analysis[C]//2017 IEEE International Conference on Data Mining(ICDM). [S.l.]: IEEE, 2017: 1033-1038.
[6] GHOSAL D, AKHTAR M S, CHAUHAN D, et al. Contextual inter-modal attention for multi-modal sentiment analysis[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. [S.l.]: Association for Computational Linguistics,2018: 3454-3466.
[7] LEE C W,SONG K Y,JEONG J,et al.Convolutional Attention Networks for Multimodal Emotion Recognition From Speech and Text Data[EB/OL]. [2020-07-10]. https://arxiv.org/abs/1805.06606.
[8] PAN Y W, MEI T, YAO T, et al. Jointly modeling embedding and translation to bridge video and language[C]//Proceedings of the IEEE conference on computer vision and pattern recognition.[S.l.]:[s.n.], 2016: 4594-4602.
[9] XU R, XIONG C, CHEN W, et al. Jointly modeling deep video and compositional text to bridge vision and language in a unified framework[C]// Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence. [S.l.]:[s.n.], 2015: 2346-2352.
[10] AKHTAR M S,CHAUHAN D S,GHOSAL D,et al.Multi-task Learning for Multi-modal Dmotion Recognition and Sentiment Analysis[EB/OL]. [2020-07-15]. https://arxiv.org/abs/1905.05812.
[11] LI W Y, XU H. Text-based emotion classification using emotion cause extraction[J]. Expert Systems with Applications, 2014, 41(4): 1742-1749.
[12] XIA R,DING Z X.Emotion-cause Pair Extraction:A New Task to Emotion Analysis in Texts[EB/OL]. [2020-07-15]. https://arxiv.org/abs/1906.01267.
[13] XIA R,ZHANG M R,DING Z X.RTHN:A RNN-transformer Hierarchical Network for Emotion Cause Extraction[EB/OL].[2020-07-15]. https.//arxiv.org/abs/1906.01236.
[14] JIAO W X,YANG H Q,KING I,et al.HiGRU:Hierarchical Gated Recurrent Units for Utterance-level Emotion Recognition[EB/OL].[2020-07-15]. https://arxiv.org/abs/1904.04446.
[15] ZHOU Suping, JIA Jia, WANG Qi,et al. Inferring emotion from conversational voice data: A semi-supervised multi-path generative neural network approach[C]// Thirty-Second AAAI Conference on Artificial Intelligence.[S.l.]:[s.n.],2018:579-587.
[16] EYBEN F, WLLMER M, SCHULLER B. Opensmile: The munich versatile and fast open-source audio feature extractor[C]//Proceedings of the 18th ACM international conference on Multimedia. New York:ACM Press,2010: 1459-1462.
[17] LI R N,WU Z Y,JIA J,et al.Inferring user emotive state changes in realistic human-computer conversational dialogs[C]//2018 ACM Multimedia Conference on Multimedia Conference.New York:ACM Press,2018:136-144.
[18] MCFEE B,RAFFEL C,LIANG D W,et al.Librosa:Audio and music signal analysis in python[C]//Proceedings of the 14th Python in Science Conference.Austin: SciPy,2015:18-25.
[19] CHO K,VAN MERRIENBOER B,GULCEHRE C,et al.Learning Phrase Representations using RNN Encoder-decoder for Statistical Machine Translation[EB/OL].[2020-07-16]. https.//arxiv.org/abs/1406.1078.
[20] SLIZOVSKAIA O,GMEZ E,HARO G.A Case Study of Deep-learned Activations via Hand-crafted Audio Features[EB/OL].[2020-07-16]. https://arxiv.org/abs/1907.01813.
[21] BADSHAH A M, AHMAD J, RAHIM N, et al. Speech emotion recognition from spectrograms with deep convolutional neural network[C]//2017 International Conference on Platform Technology and Service(PlatCon). [S.l.]:IEEE, 2017: 1-5.
[22] BUSSO C,BULUT M,LEE C C,et al.IEMOCAP:Interactive emotional dyadic motion capture database[J].Language Resources and Evaluation,2008,42(4):335-359.
[23] ZADEH A, ZELLERS R, PINCUS E, et al. Multimodal sentiment intensity analysis in videos: Facial gestures and verbal messages[J]. IEEE Intelligent Systems, 2016, 31(6): 82-88.
[24] MIKOLOV T,CHEN K,CORRADO G,et al.Efficient Estimation of Word Representations in Vector Space[EB/OL]. [2020-07-07]. https://arxiv.org/abs/1301.3781.
[25] ROZGIC V, ANANTHAKRISHNAN S, SALEEM S, et al. Ensemble of SVM trees for multimodal emotion recognition[C]//Proceedings of The 2012 Asia Pacific Signal and Information Processing Association Annual Summit and Conference. [S.l.]: IEEE, 2012: 1-4.
[26] POWERS D M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation[J]. J Mach Learn Technol, 2011, 2(1):37-63.
[27] KINGMA D P,BA J.Adam:A Method for Stochastic Optimization[EB/OL]. [2020-07-10]. https://arxiv.org/abs/1412.6980.
