基于Ridgelet变换的多文种文档图像文种识别
2020-11-17热依汗古丽卡森木木特力铺马木提吾尔尼沙买买提阿力木江艾沙库尔班吾布力
热依汗古丽·卡森木,木特力铺·马木提,吾尔尼沙·买买提, 阿力木江·艾沙,库尔班·吾布力+
(1.新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046; 2.新疆大学 网络与信息中心,新疆 乌鲁木齐 830046)
0 引 言
作为OCR[1](光学字符识别)系统的重要组成部分,文种识别技术尤其是多文种识别技术近来受到越来越多的关注[2]。韩兴坤等[3,4]认为对于具有相似性的语言文种,单一的纹理特征是不能够详细体现图像的纹理,提出了基于NSCT子带纹理特征融合的多文种文档图像文种识别方法,平均准确率为99%。布阿加姑丽等[5]针对11种文档图像提取均值、标准差、熵等6种纹理特征进行加权融合,在自建的两个数据库中进行实验,识别率分别为99.38%和95.69%。李顺等[6]提出了基于离散曲波变换的文种识别,在包含10个文种共10 000幅图片中进行实验,最终识别率为99.25%。
近年来通过学者们的不懈努力,基于纹理特征的文种识别技术取得了很大的进步,但是已有的文献中都存在文档图像库中文种的类别不够丰富的问题。随着国家提出的一带一路战略的稳步推进,世界各国之间的经济、贸易、文化等也有了频繁的交流,这对印刷体文档图像的文种识别带来了更大的机遇和挑战,为了解决这方面的问题,本文提出了基于Ridgelet变换的多文种文档图像多文种识别方法,通过对图像进行脊波变换来提取多文种文档图像的纹理特征,并使用KNN、线性判别分析等多个分类器对来特征进行训练和分类,寻找最佳的分类器和阈值,实现文档图像的多文种识别。
1 脊波变换
目前大部分图像中有大量的纹理特征表现比较突出,小波变换不能达到最优的逼近,为了克服小波这种不足Candes等提出了多尺度变换——Ridgelet变换[7],又能够称为脊波变换,其对于直线奇异的多变量函数能够实现不错的逼近性能,即对于纹理特征丰富的图像,Ridgelet可以获得比小波更加稀疏的表示。Ridgelet变换的主要步骤是使用Radon变换将多个方向的线性奇异性映射为某个点的奇异性,接着刻画点的奇异性,主要用一维的小波变换来实现,最终具体体现图像中直线或曲线奇异性等重要特征。由此,小波变换较适用于表示孤立的点奇异性目标,脊波变换适用于体现直线奇异性。这就是多尺度Ridgelet,其Ridgelet变换原理如图1所示。
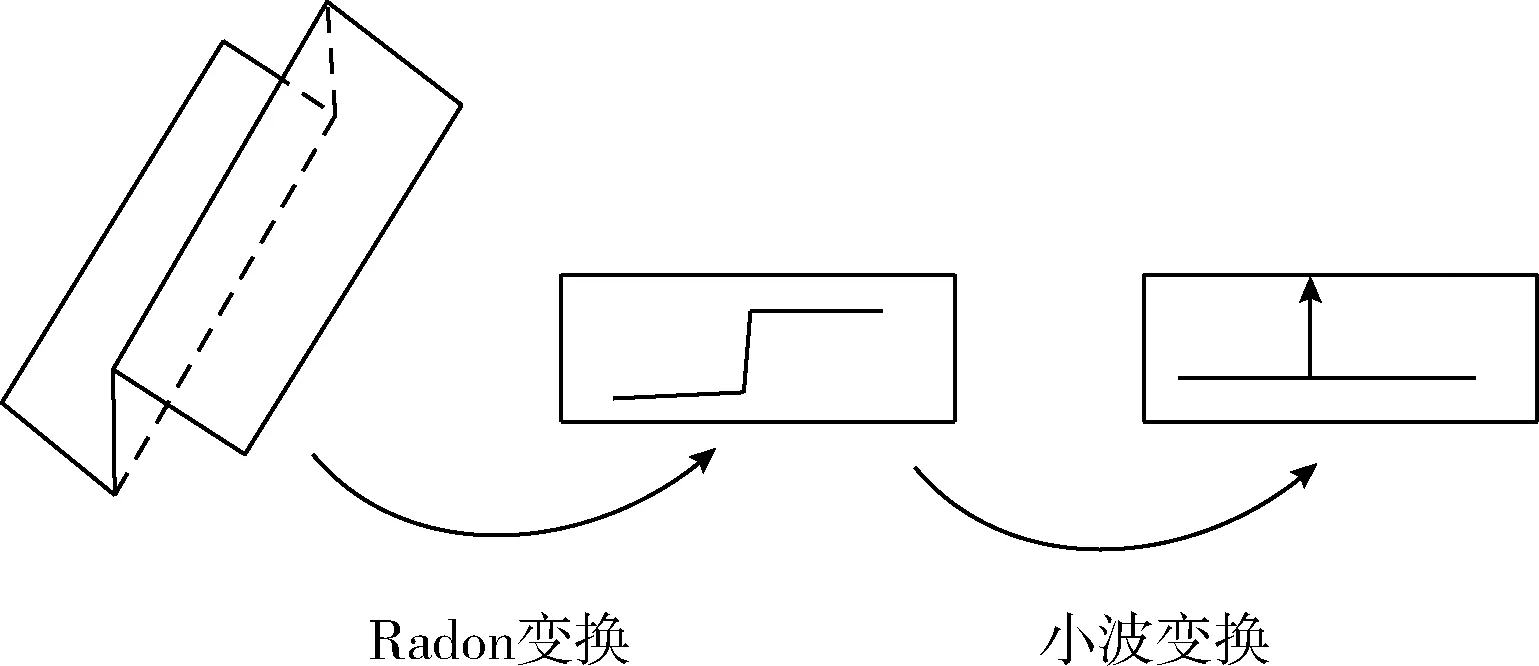
图1 Ridgelet变换原理
其中一维小波变换为
(1)
首先,用Radon变换将不同方向的线奇异性映射为点的奇异性,其Radon变换为
(2)
接着,然后用一维小波变换来刻画点的奇异性,最终得到Ridgelet变换
(3)
用Ridgelet变换后会得到N*M的脊波系数矩阵,组成特征向量,对此进行提取能量特征。
2 基于有限Ridgelet变换的文种识别方法
现有文种识别方法在标准文档图像库建立的基础之上,对文档图像进行预处理操作,主要包括:噪声去除、灰度化等;进行图像的特征提取;对所提取的特征进行训练,实现分类结果。其流程框架如图2所示。

图2 文种识别流程
首先是收集这9种文字的书本、报纸等纸质版资料。其中有一些在图书馆较难找到的文种如:像吉尔吉斯斯坦文等一部分文档图像是从官网上下载打印之后再通过扫描仪得到,样本图像大小为256×256,分辨率为200 dpi,通过裁剪工具裁剪得到同样大小标准的文档图像样本,建立实验所需的标准数据库,对准备好的标准文档图像进行去燥、灰度化、二值化等预处理,进行特征提取并保存。保存好的特征向量用本文所选的分类器进行训练和分类。
2.1 图像预处理
对文档图像的预处理是个尤为重要的阶段,预处理对图像文种识别效果有着直接的影响,用扫描仪把不同文字扫描成图片形式将其以bmp形式保存,各文档图像样本如图3所示。

图3 部分实验样本
由于扫描过程中扫描的纸质图像文档的样本颜色上有些不同,为了解决这类问题,要对文档图像进行预处理。
本文的预处理主要分为灰度化和二值化,灰度化采用加权平均法,二值化采用OSTU(最大类间方法)法,二值化后的图像减小了背景像素的干扰,能够更好提取图像的特征,提高文种识别率。
2.1.1 灰度化
在图像处理上,通常需要灰度化使其变为灰度图,以减少后续计算量。彩色图像有R、G、B这3个颜色通道,图像灰度化就是将三通道的彩色图像变为单通道的灰度图像。灰度化采用加权平均法,在计算时,求出3个通道的求出平均值,将此平均值作为对应灰度图像的像素值,计算公式如式(4)所示
f(i,j)=0.30×R(i,j)+0.59×G(i,j)+0.11×B(i,j)
(4)
2.1.2 二值化
对原始的文档图像进行灰度化处理后,还会留有灰色的背景信息,会对后期图像特征提取产生一定的影响,为了避免影响特征提取部分需要进行对文档图像进行二值化[8],图像二值化对后期的识别有直接的影响,文档图像二值化指的是把文档图像上的像素点的灰度值设置为0或255,将整个文档图像呈现出明显的黑白效果的过程,也就是说让文档图像变得简单从而得到数据的处理和压缩量上的减少,有利于凸显出文档图像的轮廓。其灰度值为255表示其表示的是我们的文档图像的背景是白色,灰度值为0其表示文档图像上的文字的黑色。
二值化后的图像如图4所示。

图4 图像二值化效果
2.2 特征提取
对大小为256*256,bmp格式的原始文档图像进行Ridgelet变换,通过变换以后得到256*256大小的脊波系数矩阵,对系数进一步进行分析并利用脊波系数提取脊波能量特征,实验过程中对每1*256的系数矩阵提取一维能量特征得到的实验结果最优,所以从文档图像脊波系数矩阵共得到256维脊波特征向量,其能量特征公式如下
(5)
n,k为矩阵的大小。
基于小波变换[9,10]的识别方法,其本质就是通过3级小波分解得到9个不同的细节子图,根据对每个细节子图能量特征、同一尺度的比例特征的计算,最终获取十八维度的能量特征。一张大小N*N的文档图像的平均能量定义为
(6)
细节子图的小波平均能量定义为
(7)

局部二值模式(local binary pattern,LBP)算法的原理图如图5所示。

图5 LBP原理
LBP[11,12]首先定义一个3*3的滑动窗口,阈值为中心点,通过比较对应像素点的大小来确定该像素点的二进制值,若中心点像素值大于周围某个点的像素值,则该点的值赋为0,反之为1。通过一一对比,大小为3*3的窗口,除去中心点,就产生出8个二进制数,二进制数通常转换为十进制数即LBP码,共28可能,也就是256种码序。这样得到的码序即是该点的LBP值,它反映该区域的纹理信息。为了使提取的LBP特征数据在文档图像产生一定的倾斜角度时有较好的鲁棒性、减少LBP特征数据的类别,从而降低特征数据计算复杂度,本文采用LBP等价模式来进行对比实验,这样特征向量的维数更少,并且可以减少高频噪声带来的影响。
2.3 训练和分类器的选择
2.3.1 KNN分类器
KNN算法[13]是一个得到大家青睐并成熟的分类算法之一。KNN的主要思想根据最相近的一个或者若干个样本的类别来判断待分类样本属于某一个类别。比如在若干个样本在特征空间里的k个最相近的样本大多数归为一类,那么这样本也会被判为属于该类别。
该算法主要参数的设置为K值,如果我们选择的K值较小,把我们得到的近邻数随着变少,这情况会导致噪声过大,影响分类效果。反过来要是选择的K值过大,本来不相似的数据也会混在其中造成噪声影响识别率。KNN分类器本文K值选为3使用余弦距离来计算相似度
(8)
2.3.2 贝叶斯分类器
贝叶斯分类器算法[14]是来自于贝叶斯定理,贝叶斯分类器(Bayes classifier,Bayes)的原理是对于一个不确定的分类项,首先假定在此类别出现的条件下其它类别出现的概率,其中哪个类别出现概率较大,它就属于这一个类别。
其计算公式如下
(9)
式中:P(D1),P(D2),…,P(Dm) 的值相同,变量x1,x2,……,xn相互独立,P(W) 为常数,则有
(10)
2.3.3 线性判别分析分类器
线性判别分析分类器[15](linear discriminant analysis classifier,LDA)是经典的分类器,基本思想比较简单:给定带有标签的训练样本集,设法将样本投影到一条直线上,使得同类样本的投影点尽可能近,异类样本的投影点尽可能远。在使用LDA进行分类[16]时,对样本进行投影,使其映射到相同的直线,根据映射点的位置确定类别。
其公式如下
(11)
3 实验结果与分析
3.1 实验设备与环境
本文实验平台是AMD A8-5600K APU with Radeon(tm)HD Graphics 3.60 GHz处理器、操作系统为Windows7 64位,4 GB内存,编译环境为MATLAB2016b,所有基于Ridgelet变换多文种文档图像文种识别实验在此基础上完成。
3.2 实验结果与分析
本次实验样本是通过对各类书刊、杂志等扫描后的图像以BMP形式保存,建立的数据库包括:英文、中文、阿拉伯文、土耳其文、吉尔吉斯坦文、俄文、国内少数民族文种(蒙文、藏文、维吾尔文)9个文种,切割成大小为256*256,bmp格式,分辨率为200 dpi的文档图像,每个语种各1000张共9000张文档图像的实验用数据库,本文文种样本包括世界主要使用的文种和少数民族文种。识别率计算如下公式
(12)
其中,Nr为该样本正确分类样本数,Nt为该文种测试本数,进行实验时文档图像特征训练集是按不同数量随机选取的,改变训练集数量,其余的作为测试集进行实验,实验分两个部分:首先用两个经典算法分别使用小波和LBP提取预处理之后的文档图像的纹理特征单独进行实验;再进行本文Ridgelet变换的实验对比最后的识别结果。实验一律进行10次,以10次实验的平均值作为识别结果。本文选取比较常用的KNN分类器,贝叶斯分类器和线性判别分析分类器进行分类作对比。
基于小波变换的文种识别方法使用不同的数量训练集得到的文种识别结果如图6所示。

图6 使用小波特征在不同数量训练集识别率
由图7可知,采用小波变换方法,训练集为500时,在LDA分类器下识别准确率能达到92.45%。随着训练集变化,整体曲线有波动,在LDA分类器力训练集数量从500开始就稳步上升最终最高识别率达到了92.85%,其次高的是贝叶斯分类器,贝叶斯分类器上最高识别率达到了91%以上。

图7 LBP特征使用不同数量训练集识别率
基于LBP特征的文种识别方法使用不同的数量训练集得到的文种识别结果如图7所示。
由图7可知,使用LBP特征在LDA分类器上可以达到95.20%的最好识别效果,平均识别率也达到了94.47%,而KNN分类器的识别效果则相对较差。比较图7 和图8可以看出使用LBP特征比使用小波特征的识别效果高。

图8 Ridgelet变换特征使用不同数量训练集
在LDA分类器上平均高出了2.6%。识别率排第二的是在贝叶斯分类器上平均识别率达到了93.20%,随着训练集数量的增加,识别率都能稳步提升。
基于Ridgelet变换的文种识别方法使用不同的数量训练集得到的文种识别结果如图8所示。
由图8可知在KNN分类器里面识别率平均达到了99.23%,最高识别率达到了99.67%,贝叶斯和LDA跟KNN相比识别率较低,在LDA分类器平均识别率达到了96.92%,比小波变换分别提高了8.13%和4.52%,跟LBP相比识别率分别提高了7.85%和2.45%。在每个文种的训练样本数量在500以下时,识别率随着训练集的增加而提高。但只要文种训练集数量超过500,每个分类器的识别效果都出现了小幅度下降,这是因为随着训练样本数量的增加,分类器因为学习到了样本集中的噪声或者不具有代表性的特征而产生了过拟合,导致错误分类。
在Ridgelet变换方法下还是存在错误分类,以更好验证本文提出的算法对每个文种的具体识别效果,对9个文种选取一部分作为训练集,其余部分作为测试集,训练集和测试集的比例是按500个训练、500个测试来进行实验。通过实验结果可以得出错误分类情况。本文对基于Ridgelet变换的多文种识别方法使用KNN分类器进行识别实验,错误分类样本分布见表1。

表1 在KNN分类器下Ridgelet变换错误分类统计
从表1可知,对书写方式和特征结构差异比较大的英文、吉尔斯斯坦文、俄文、蒙文等4种文种来说实现了无错误分类,出现错误分类比如错误分类较多的是蒙文属阿尔泰语系蒙文跟俄文书写形式较相似因此导致错误分类,阿拉伯文在分类时分到了维吾尔文,维吾尔文有个别字母是跟阿拉伯文的相似,就像中文词汇里的好多外来词汇一样,但这两个文种在字母组合方式有差异。
下面列出了Ridgelet变换和其它两个经典算法的各自所提取的特征维数N、特征提取时间T、3种方法的识别效率来进一步验证本文方法的有效性,其结果见表2。
从表2可知3种不同的识别方法其维度与时间性能不同基于小波变换的方法特征维数较低,计算用时较短,在消耗时间方面跟其它两个算法相比较快。LBP变换后,得到的系数矩阵较大,所以在计算难度上较大,时间较长。本文提出的Ridgelet变换方法,特征维数跟LBP方法同样是256,但Ridgelet变换系数矩阵结构简单,计算速度快,识别率跟其它两个经典算法对比识别率较高。小波变换特征提取时间最短,由于其算法的局限性,只能提取3个方向的特征。LBP方法在使用LDA分类器时,其效果相对较好,其准确率达到了95%左右。基于Ridgelet变换的文种识别方法在使用KNN分类器时,得到的分类效果好于其它两个分类器,平均文种识别率达到了99.23%。Ridgelet变换提取的图像的纹理特征比小波变换和基于LBP的方法提取的特征更加丰富,对图像细节的描述更加具体,因此对多文种文档图像的文种识别效果更好。
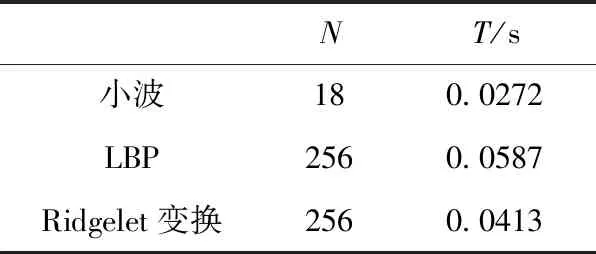
表2 识别效率比较
4 结束语
本文提出了一种基于Ridgelet变换的多文种文档图像文种识别方法,在Ridgelet变换后得到其系数矩阵,并从中提取能量特征,得到特征向量。选用KNN、贝叶斯,LDA等3个分类器用于特征训练和分类,在前期工作中建立的含有9个文种的文档图像数据库分别为英文、中文、阿拉伯文、土耳其文、吉尔吉斯坦文、俄文、国内少数民族文种(蒙文、藏文、维吾尔文),每个文种有1000张总9000张,实验数据对每个文种不同数量样本进行实验,选小波变换和LBP作为对比实验,从实验结果可知Ridgelet变换在KNN分类器里面效果最佳,在此分类器里平均识别率达到了99.23%,数据库采集时存在扫描仪和采集的数据样本本身的一些格式,噪声等问题,实验结果均显示该方法提取文档图像纹理特征的有效性,由于提取的特征位数较高所以特征提取时间跟对比方法相比中等,对于相似性文种的分类效果还有待提高,在今后的研究中继续深入研究这几个方面问题。
