基于优先级层次熵的高新技术企业创新能力评价方法
2020-11-15郭秀强孙延明
郭秀强,孙延明
(1.华南理工大学 工商管理学院,广东 广州 510641;2.广州大学 工商管理学院,广东 广州 510006)
自熊彼特1939年首次全面阐述技术创新理论以来,国内外学者对技术创新理论及实践应用开展了大量研究,其中,企业技术创新能力影响因素分析及评价体系构建一直是国内外学者重点关注的焦点[1]。整体而言,国内外学者主要基于创新投入、创新产出、创新环境等创新活动过程,同时也关注了社会资源投入、企业管理水平以及创新绩效等企业发展战略因素来构建评价指标体系[2-10],并运用主观赋权法[11-12]、客观赋权法[13]和组合赋权法[14]等科技评价方法进行企业创新能力实证研究,但已有文献对高新技术企业尤其是医药类企业研究较少。基于此,本文构建合理的创新能力评价指标体系,并建立定性定量相结合的优先级层次熵组合赋权方法,对广东省具有代表性的10家高新技术医药企业的科技创新能力进行案例研究,以深入掌握医药行业技术创新能力的发展态势,并期望能为政府决策、企业发展提供信息参考。
1 指标体系的建立
1.1 指标体系构建思路
高新技术企业创新能力评价是一项系统工程,涉及到的因素范围广、数量多,只有建立科学的指标体系,才能更加合理地反映企业的真实情况。本文以已有文献关于创新能力的影响因素为理论依据,选取《高新技术企业认定管理办法》、《高新技术企业认定管理工作指引》、《广东省2019年高新技术企业认定工作的通知》作为本次研究指标筛选的重要参考,从创新投入、创新产出、创新绩效三个维度,根据指标选择的科学性、系统性、重要性、可比性等原则建立企业科技创新能力评价的指标体系。
1.2 评价指标的筛选
1) 指标的海选。
为了指标选取的科学性,本文通过市场调研,并参考权威机构发布的评价指标体系以及现有文献中影响高新技术企业创新能力的高频率指标,结合高新技术企业高技术、高投入、高风险的特点,同时考虑数据的客观性、可获得性与可操作性,初步海选了包括职工人数、资产总额、拥有市级重点实验室等在内数10项指标。
2) 指标的筛选。
在评价指标体系海选的基础上,本文利用德尔菲分析法和相关系数分析法等定性与定量相结合的方法进一步筛选指标。具体步骤如下:首先,选择技术创新领域10位专家对海选指标的合理性进行判断,分析剔除非关键指标;之后,借鉴肖淑芳等[15]和张玉磊等[16]等相关研究,对指标体系进行相关性分析,若指标之间相关系数大于或等于0.8,则进行分析和选择性剔除。
3) 指标体系的构成。
根据指标体系选取的思路以及筛选原则,参照国内专家学者们对企业创新能力评级体系的总体设计[1,8,10],本文构建了包含创新投入能力、创新产出能力、创新效益等3个准则层,共计13个指标的科技评价指标体系,如表1所示。
2 基于优先级层次熵的指标权重确定方法
对于专家组来说,直接确定一个指标比另一个指标重要多少倍的数值比率很容易产生不同意见,而在两个指标中确定哪一个指标重要相对容易,而在专家组给出指标优先级排序时由于知识、背景所限会出现有些指标拿不定主意的情况,从而出现具有不完全信息的指标优先级情况[23]。本文在此思路的指引下,首先提出了一种指标优先级确定方法,之后在此基础上给出基于层次分析法和熵值相结合的主客观组合赋权方法。

表1 医药类高新技术企业科技创新能力指标评价体系Table 1 Evaluation system of scientific and technological innovation capability index of pharmaceutical high-tech enterprises
2.1 不完全信息指标优先级确定方法
假设从安全性、经济性两个方面评估一款高新技术产品,安全性指标比经济性指标拥有更高的优先级。选择m位专家(7≤m≤15)对n个指标同时进行优先级排序,假设有t个专家给出了完整排序,而另外(m−t)个专家排序中都存在不同程度的漏排指标现象。具体修正步骤如下。
1) 专家分类以及修正满足条件。
将排序指标数相同的专家归为一类,若该类专家排序中所有指标都被选择在内,即在该类别每个指标至少有一位选择,则可进行信息修正以及一致性检验,否则舍弃。
2) 用排序打分法将每位专家给出的不完全信息排序转换成分数。

其中,Rij为第i个指标在第j位专家所排的位次得分,n为评价指标数量,rij为第i个指标在第j位专家所排的位次。若存在并列排序,则将并列排名的后续评估客体作“跳位”处理,之后将相同序号调整为相应顺序号的平均值。
3) 计算不同方法下指标得分的均值。

4) 对于修正过的完整指标序关系,其结果或许会有差异,但是对于相同指标来说差异不应过大,所以要对排序进行基于斯皮尔曼等级相关系数的一致性检验,未通过一致性检验的专家排序将会被舍弃。设第j种方法得到的排序为Aj=(a1j,a2j,···,anj),则第j和第k个排序的Spearman等级相关系数公式为
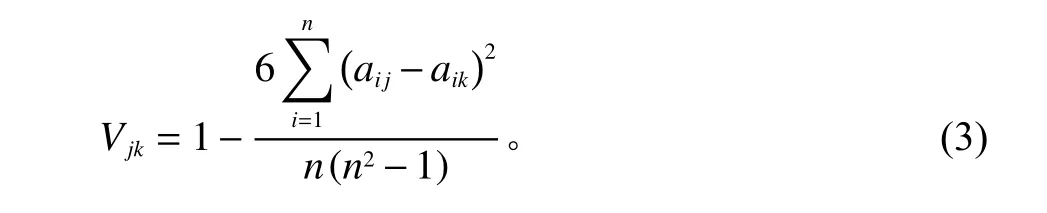
其中,Vjk为 Spearman等级相关系数,aij是指第i个指标在第j位专家所排的位次,aik是指第i个指标在第k位专家所排的位次。舍弃标准:计算斯皮尔曼等级相关系数,当均值大于等于0.7时满足信度的分值条件,通过一致性检验,否则,舍弃该专家排序。
5) 理想排序的确定。
对通过一致性检验的专家排序再次利用式(1)打分,若βij为第j位专家序关系下的第i项指标的得分,为第i个指标的综合得分均值,则

按大小进行重新排序,即为融合序关系。
2.2 基于优先级层次熵的指标权重确定方法
为了获取包含主、客观信息的指标权重,本文在指标优先级基础上采用层次分析法和熵技术相结合的方法确定组合权重。所谓优先级层次熵,是在保证指标优先级的基础上用层次分析法决定指标的主观权重,并用指标数据的熵值进行客观修正。
1) 利用层次分析法确定主观权重。
层次分析法(AHP)主要步骤如下[34-35]。
①建立层级结构。
②在保证指标优先级的基础上建立两两判断矩阵A。
③计算各指标权重。
采用和积法求权重向量θj(j=1,2,···,n),对矩阵A进 行归一化处理,得到标准矩阵B=(bij)n×n,然后按行求和并归一化,所得列向量即为A的特征向量,θi为特征向量

④利用方根法计算最大特征值,假设判断矩阵为A
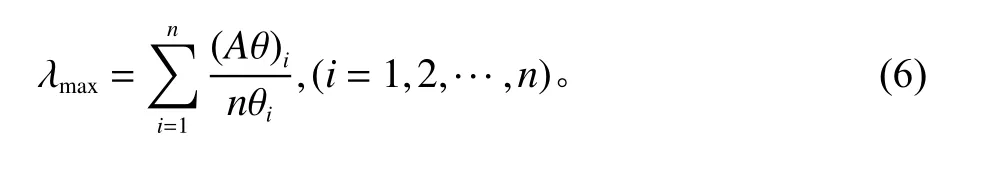
⑤进行一致性检验。
计算一致性指标
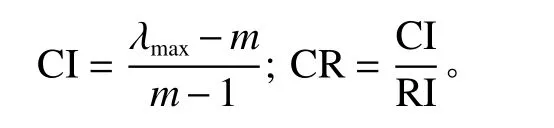
确定平均随机一致性指标RI,计算检验数CR,当0≤CR<0.1时,证明判断矩阵具有良好的一致性;当 0.1≤CR时,此时应该调整判断矩阵,直到符合一致性要求为止。
2) 利用具有指标优先级的熵值对指标权重进行修正。
①具有指标优先级的熵值算法。
设具有指标优先级的参评指标群体集为E={e1,e2,···,em}(m>2),其中,ek表示第k个优先级指标,(ai1,ai2,···,am)为参评指标ei给出的评价向量,则指标ei的评价熵[30,36-37]

②通过计算指标熵值Ek来确定相邻优先级指标xk−1与xk重要性程度之比rk。反应指标的数据信息,体现该方法的客观性。

③根据给出的rk值,计算准则层下第m个指标的权重tm为

④由权重tm可得第m−1,m−2, ···, 2个指标的权重

其中,tm表示准则层下第m个指标对该准则层的权重,rm为相邻优先级指标指标xm-1与xm重要性程度之比。
⑤基于优先级层次熵的混合赋权。
层次分析法权重 θj由于判断矩阵完全是依靠专家经验来决定,对于精度较高问题的解决方案有可能与实际情况并不相符。熵值赋权法权重tj依据方案的真实数据计算,避免了评价主体主观因素对于指标权重的影响,但当客观数据较为特殊时,权重会与实际情况相差较大。本文将采用具有指标优先级的熵权−层次分析法,定性与定量相结合,主观与客观相结合,使指标权重wj(j=1,2,···,m)更加科学、合理。
综合指标权重为

3 案例分析
3.1 研究对象和数据来源
当前,全球各地正面临着新型冠状病毒肺炎袭击的严峻挑战。习近平总书记指出“人类同疾病较量最有力的武器就是科学技术,战胜这场全球性的大瘟疫必须紧紧依靠医药技术的创新突破”。医药类高新技术企业作为科技创新和科技成果应用的主体,在本场疫情科研攻坚战中,始终冲在最前线,释放着科技创新的“硬核”力量。相比其他行业(如互联网、机械制造等)的高新技术企业,医药类高新技术企业的创新新能力表现出一些突出的特点:1) 属于高风险,高回报,投入大的行业,各地区发展不均衡,创新主体规模相对较小,整体的创新能力比较有限。2) 医药类高新技术企业整体制药水平和国际发达地区相比仍有较大差距,呈现研究周期长、成果转化率低的特点。3) 自主知识产权相对匮乏。除中药外,我国尚少有自主知识产权的药品,我国医药产业发展几乎始终以生产非专利药为增长点[1]。而广东作为全国生物医药产业大省,医药类高新技术企业众多,在我国历次重大突发公共卫生事件中都发挥了非常关键的作用。因此,分析和评价广东省医药类高新技术企业技术创新能力水平,探寻医药企业发展过程中存在的难题和症结,对于加快推进广东省高新技术企业高质量发展和战胜新冠肺炎疫情具有重要的理论价值和现实意义。
在数据获取上,本文根据广东省高新技术企业数据库,选取了医药行业的10家具有代表性的高新技术企业作为评价对象,并用2017-2019年运行情况的面板数据进行运算和评价。样本基本代表了广东省医药行业在全国的水平,对10家典型企业的创新能力评价,能较好地反映广东省医药行业的高新技术企业发展态势,原始数据来源于广东省科技统计报告以及广东省科技管理系统阳光政务平台广东省高新技术企业发展监测数据。限于篇幅,本文以创新产出能力评价为例演示评价得分的详细计算过程。考虑到有些企业的数据不宜公开,本文将企业名称进行了模糊化处理。
3.2 评价流程
本文采用基于优先级层次熵的组合赋权方法对广东省10家典型医药类高新技术企业产出能力进行评价,其评价步骤如下。1) 评价指标的标准化;2) 确定不完全序关系的指标优先级;3) 在保证指标优先级的情况下确定指标体系的主、客观指标权重;4) 确定混合权重以及进行综合评价。
3.3 模型计算与分析
1) 指标标准化。
由于算例指标中都是正向指标,取指标最大值为 (xij)max,然后使得每个指标值除以最大值,即标准化之后的值为若指标数据中含有零,为了有效利用熵值计算指标离散程度以及减少差异性的影响,该项指标数据全部添加最小值1。
2) 指标优先级的确定。
邀请9位评审专家给出指标的重要性优先级排序,其中有3位专家给出了完整指标序关系,3位专家为缺1项指标序关系,另外3位专家序关系缺2项,分别用A、B、C表示,Gj(j=1,2,3,4)表示第j项指标。A类专家排序分别为A1={G1≻G4≻G3≻G2},A2={G3≻G1≻G4≻G2},A3={G3≻G1≻G2≻G4};B类专家排序分别为B1={G1≻G3≻G2},B2={G3≻G1≻G4},B3={G1≻G4≻G2}; C类专家排序分别为C1={G1≻G3},C2={G3≻G4},C3={G1≻G4}。
步骤1由3.1小结知,A类专家排序为完整指标排序,视为有效排序;B类专家排序中有漏排指标现象但排序中包含了所有指标满足修正条件,应该被保留;C类专家排序不满足修正条件,应当被舍弃。
将B类专家排序代入到公式(1)、(2)得每个指标得分均值为

把均值分别与B类专家不完全信息排序得分进行对比,按大小把缺失指标插入到专家给出的残缺排名中,大小相同者对比加权变异率,得出每位专家的所有指标序关系如下

计算一位专家与其他两位专家的斯皮尔曼等级相关系数得

由于0.8大于一致性检验临界值0.7,则B1与B3修正后的排序通过一致性检验,B2修正后的排序被舍弃。这两个通过一致性检验的修正排序与A类3位专家的完整排序一起进行斯皮尔曼等级相关系数检验,求均值

对通过一致性检验的B1、B3以及A2再次求指标均值,按照大小进行排序,则指标总的排序结果为
3) 主、客观权重的确定。
步骤2在保证指标优先级不变的情况下,邀请专家给出判断矩阵,见表2。

表2 判断矩阵Table 2 Judgment matrix
通过计算得:对应的指标主观权重为θ={0 .5423,0.0847, 0. 2333, 0.1397},并满足一致性检验条件。
步骤3在保证指标优先级不变的情况下,对10家医药公司各个客观指标求熵值,并根据3.2小节求出客观权重t== {0.3048, 0.3048, 0.3048, 0.0855}。
4) 混合权重的确定及其评价结果。
步骤4根据公式(11)计算混合权重w={0.4236,0.0851,0.2691,0.2223}。
步骤5利用标准化数据以及混合权重计算医药公司创新产出能力评价值,分别为{23.91, 66.39,61.17, 36.80, 80.63, 52.33, 30.81, 36.10, 27.02, 55.32}。
3.4 企业综合创新能力评价
参照3.3小节,计算出2017~2019年整个指标体系中准则层和指标层的权重(见表3)。

表3 医药类高新技术企业创新能力评价指标权重Table 3 Weights of evaluation indexes for innovation capabilities of pharmaceutical high-tech enterprises
由于2017~2019年中每个指标的原始数据发生了变化,因而基于优先级层次熵的混合赋权得到的各指标权重3年内各有不同。但根据表3可以看到,指标权重在3年间的差异并不大,总体控制在0.2以内,尤其是高级技术职称占研发人员比例和研发人员占全体员工比例这2个指标,2017年和2018年两者之间的差异大小只有0.17%。这在一定程度上说明了混合权重具有很高的稳定度和可信性,进而证明了具有科学性和合理性。
根据混合权重和标准化数据以及综合指数的计算方法,计算10家企业准则层和目标层的总得分,评价结果如表4所示。

表4 医药类高新技术企业评价结果Table 4 Evaluation results of pharmaceutical high-tech enterprises
结果显示,广东省10家医药类高新技术企业的创新能力整体不强,只有个别企业的综合创新能力得分超过了60分;另外,企业呈现发展不均衡态势,彼此之间的综合得分差距较大。纵向对比来看,2017年广东医药高新技术企业创新态势相对较好,综合得分相对较高;2018~2019年,企业的创新能力得分则出现了普遍下降(公司3除外)。横向对比来看,广东省医药类高新技术企业创新能力发展不均衡,得分差距悬殊。如2019年,公司3和公司7综合创新能力得分相差超过61分。分析3个二级指标发现,创新绩效得分相差将近85分。因此,企业综合得分之间的差距主要源于创新绩效的差异。以公司3为例,2017~2019年间,公司创新投入和创新产出稳定,但创新绩效差异较大。2017年11月,该企业联合国内及全球知名保健品、营养品科研院成立“精准营养科研转化产业联盟”且成效显著,2018~2019年科技成果转化数是同行业企业的10~30倍,创新绩效大幅提升,综合创新能力排名也从2017年第八跃居第一。
综上,2017~2019年间,受国内宏观经济增长放缓和中美经贸斗争的双重影响,广东省医药类高新技术企业创新绩效水平不断下降,导致综合创新能力不高且呈整体下滑趋势。但也有个别企业在严峻挑战下能够逆流而上、化危为机,通过积极调整创新策略,大力提升成果转化率,稳定甚至提高了自身的创新绩效,在激烈的竞争中重新赢得优势。因此,广东省医药高新技术企业之间创新能力呈现出不均衡特点。
4 结束语
本文结合目前技术创新绩效评价研究的现状,基于高新技术企业的特点构建了技术创新能力绩效评价指标体系并提出了相应的基于优先级层次熵的主、客观组合赋权方法。该组合赋权方法包含主、客观权重以及指标优先级信息。具体研究结论如下。
1) 为了对高新技术企业创新能力进行绩效评价,本文考虑到指标之间存在的优先级关系,以及专家组给出指标优先级排序时由于知识、背景所限出现的具有不完全信息的指标优先级情况,提出了一种不完全信息指标优先级修正方法。
2) 在保证指标优先级的前提下将层次分析法和熵值法相结合,提出了一种包含主、客观权重的基于优先级层次熵的组合赋权方法,此方法能够保证指标优先级不变并包含主、客观权重,提高了指标权重的科学性和合理性。
3) 对10家广东省医药类高新技术企业的技术创新能力进行了案例研究,实例分析表明,基于优先级层次熵的主、客观组合赋权方法具有一定的实用性和可操作性,该方法可有效地利用已知的评价数据,得出的属性权重更加客观、合理,是创新能力绩效评价的一种有效方法,而且还可应用于供应商选择、项目投资决策、人事管理等诸多领域。
然而,由于指标数据来源具有一定的局限性,评价体系还存在不足之处,未来将在实际工作中根据医药类企业的发展逐步完善、优化指标体系,以期更准确地反映高新企业的实际技术创新能力。
