基于GPU并行计算的雷达杂波模拟研究
2020-11-14徐国伟
徐国伟,陈 建,成 怡
(天津工业大学 a.电气工程与自动化学院; b.天津市电工电能新技术重点实验室,天津 300387)
0 概述
雷达设计与开发需要大量杂波实测数据,然而持续采集该数据会消耗较多人力和物力[1-2],此外由于杂波受多种因素影响且特征变化较大[3],因此有必要建立能充分反映雷达杂波特性的统计模型,将其统计结果作为评估与测试雷达系统参数的重要依据。
海杂波下目标检测是军用和民用雷达设计与开发面临的重要问题[4],建立精确描述海杂波统计特性的模型是研究人员关注的重点。K分布模型能很好地拟合真实数据[4],是解决上述问题较理想的模型。球不变随机过程(Spherically Invariant Random Process,SIRP)方法与零记忆非线性变换(Zero Memory Non-linear,ZMNL)方法是K分布杂波仿真的两种主要方法。基于ZMNL方法的随机序列产生方法直观、简洁,易于用算法快速实现,模拟非相参雷达杂波较方便,但应用该方法的前提是已知非线性变换前后杂波相关系数的非线性关系,对于相关相干K分布杂波,无法找到明确的非线性关系。由于SIRP方法允许对杂波的边缘概率密度函数和自相关函数进行独立控制,且高阶概率密度函数能以显式表达,克服了ZMNL方法中非线性变换对自相关函数的影响,因此通常将SIRP方法用于相关相干K分布杂波的模拟[5]。
目前随着雷达探测分辨率的提高,杂波建模与仿真方法不能很好地满足参数精度和计算效率要求,杂波计算耗时较长成为K分布杂波仿真系统面临的难题[6]。为更好地模拟实时环境,雷达每个相干处理周期都有相应杂波数据,需对杂波进行快速、准确地仿真才能满足雷达测试所要求的准确性与实时性。然而大数据量的杂波仿真仅通过单一中央处理器(Central Processing Unit,CPU)平台进行模拟难以实现,图形处理器(Graphic Processing Unit,GPU)的发展与计算统一设备架构(Compute Unified Device Architecture,CUDA)并行计算技术的出现使大数据量下计算速度得到大幅提升,通过单指令多数据(Single Instruction Multiple Data,SIMD)并行体系执行线程级并行任务[7-8]可使实时性不足的算法得到改进。文献[9]利用CUDA进行雷达杂波的网格映像法仿真,通过优化线程分配和并行归约获得最高约50倍的加速比。文献[10]在优化线程分配基础上,对杂波仿真中矩阵运算进行分块优化,并使用共享内存和CUDA流方法节省通信开销以提升杂波仿真速度。然而上述文献对SIRP方法没有深入分析,且通过降低通信开销进行优化效果有限,缺乏有效方法对杂波计算的CPU-GPU任务进行划分,导致执行GPU任务时CPU处于空闲状态,不能合理利用计算资源。
针对上述问题,文献[11]采用MPI+CUDA异构并行方法解决CPU-GPU异构平台的任务划分与协同计算问题。文献[12]在杂波仿真的矩阵计算中,利用cuBLAS库进行矩阵运算获得远超于CUDA核函数的计算性能。本文提出一种基于SIRP方法进行相关相干K分布杂波模拟的GPU改进算法,采用cuBLAS库和OpenMP+CUDA多任务调度机制改进卷积计算,划分GPU与CPU任务模块进行最优化调度,以实现相关相干K分布杂波模拟加速。
1 杂波模拟原理
1.1 球不变随机过程方法
SIRP方法采用非线性变换生成实非负变量来调制复Gaussian变量以获得相关相干K分布杂波,该方法流程如图1所示。独立实Gaussian变量序列w1,i,w2,i通过低通滤波器H1产生具有杂波功率谱的复Gaussian变量yi,使其实部y1,i和虚部y2,i具有高斯功率谱的形状,且满足y1,i~N(0,2va2)和y2,i~N(0,2va2)。由于低通滤波器H2用于使非线性变换后的随机序列功率谱足够窄,因此滤波器H2可采用多阶巴特沃斯滤波器[5]。|h0(·)|为一种非线性变换,使得序列si的平方服从Gamma分布,即si2~G(si2;1/v;v),最终获得相关相干K分布杂波序列zi。
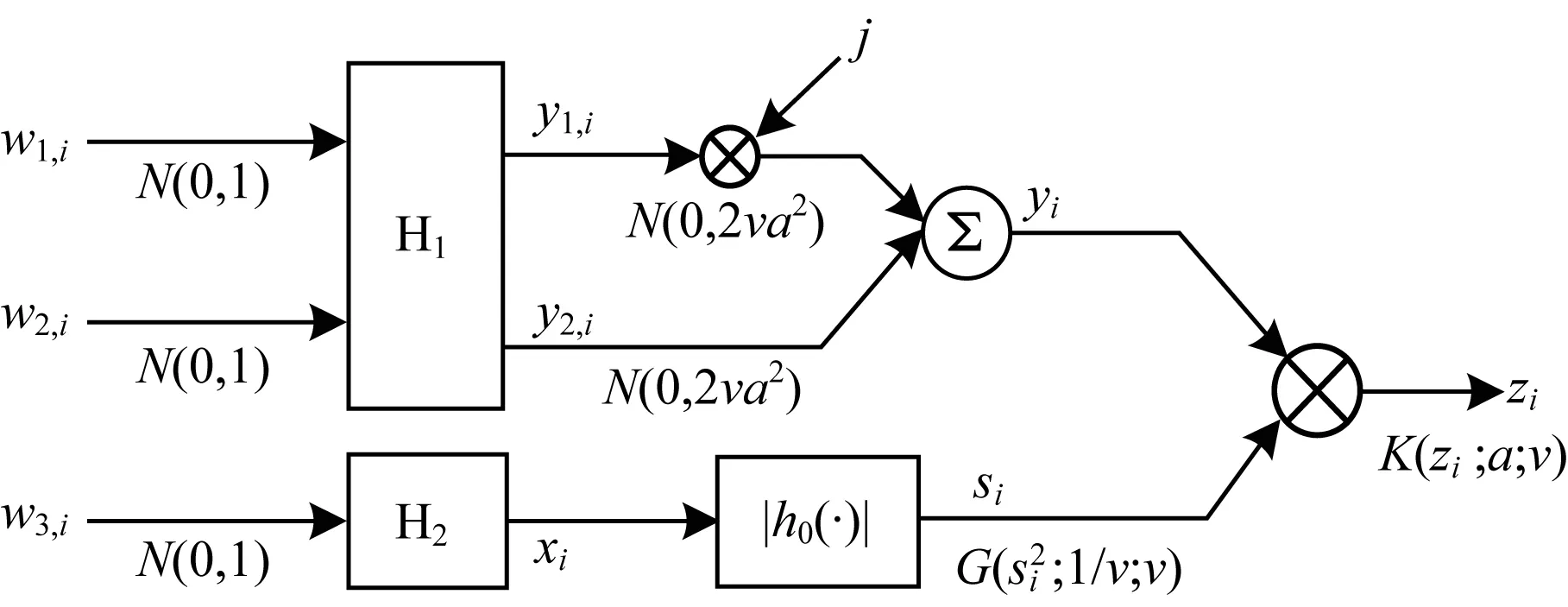
图1 SIRP方法流程
SIRP方法主要步骤如下:
1)生成2个独立Gaussian变量序列w1,i和w2,i。
2)2个Gaussian变量通过低通滤波器H1产生具有高斯功率谱的复Gaussian序列y1,i和y2,i。
3)将所得复Gaussian序列y1,i和y2,i相加得到yi。
4)产生第3个独立Gaussian变量序列w3,i,通过低通滤波器H2并经过h0的非线性变换得到si。
5)将yi与si两序列进行向量相乘运算,得到服从相关相干K分布的杂波数据。
由SIRP方法上述步骤可看出,整个过程运算量大且步骤支路较多,可并行程度高,因此可使用CUDA实现并行优化。
1.2 基于CUDA的SIRP并行算法
利用SIRP生成相关相干K分布序列时,需先采用CUDA生成Gaussian变量序列。Gaussian变量序列通过高斯分布随机数生成,高斯分布随机数产生的方法有反函数法[13]、中心极限定理法[14]、拒绝-接受法和递归法[15]等。本文使用Box-Muller变换法,该方法是反函数法的另一种形式,其主要通过中间变量进行变换间接获取高斯概率分布的逆变换,生成具有高斯概率密度的随机数序列,计算效率较高。
由于w1,i、w2,i、w3,i3个高斯序列生成时在时序与逻辑上均无相关性,因此可将三者合为一条并行支路来实现任务并行。根据并行计算中Sun与Ni定理,在存储空间允许的情况下,为满足规定的时间要求,应尽量增大计算量,实现三通道并行提高执行效率,并通过优化指令集提高生成效率。CUDA基于随机数生成机制提供应用于主机端与设备端的2种方法,其中主机端均匀分布随机数生成方法更有利于大数据量计算。在相关相干K分布杂波计算过程中,各单独环节数据计算串行度较低,滤波器H1通过CPU生成滤波器系数,并通过一维离散卷积使相关高斯数据序列获得相关高斯功率谱。滤波器H1与H2的系数计算量小,均可由CPU端计算。其中:H1滤波器进行滤波和非线性变换过程对序列的计算量较大,可使用GPU端对其进行并行计算;H2滤波过程采用多阶差分方程计算并通过非线性变换使杂波序列具有相应概率密度,且H2滤波中需计算差分方程,难以改成并行计算,因此,使用CPU端对其进行计算。
在使用滤波器H1对高斯序列进行卷积操作时,若高斯序列长度为L,滤波器系数个数为n,则卷积需进行L×n次乘法运算与n×(L-1)次加法运算,而由于在计算大量杂波数据时高斯序列长度L达到1.0×105~1.0×106,因此计算时间较长。滤波器H2在进行滤波时需求解多阶差分方程,而差分方程属于严格递归运算,在杂波数据量较大时计算时间较长。
2 基于CUDA的加速热点计算优化
本文针对H1滤波在大数据量下计算时间较长的问题,提出利用CUDA中cuBLAS库进行细粒度优化,并针对H2滤波计算效率较低的问题提出基于OpenMP+CUDA的多任务调度机制进行粗粒度优化,从而进一步提高并行效率。
2.1 基于CUDA的卷积计算优化
2.1.1 基于cuBLAS库的卷积计算
cuBLAS库是CUDA上基本线性代数子程序(Basic Linear Algebra Subroutine,BLAS)的实现。GPU采用cuBLAS库以串行与批量方式执行高效的并行矩阵运算,并利用单精度浮点运算,使计算速度显著增加[16-17]。
在多种深度学习框架下,采用caffe等矩阵乘法能加速GPU中的卷积计算。快速傅里叶变换(Fast Fourier Transform,FFT)方法是一种卷积加速方法,但由于H1滤波系数较少,导致卷积核与输入序列长度差距过大,因此在数据量较大的杂波计算中,其加速效果与直接卷积法等传统方法相比并不理想[18]。
在SIRP方法中,对高斯数据可用gemm函数进行卷积的矩阵乘法运算,以卷积数组A={a1,a2,a3}、卷积核B={b1,b2,b3}为例,卷积结果C={c1,c2,c3,c4,c5},其表达式如下:
(1)
调用cuBLAS库中gemm函数进行矩阵计算时,在对较大矩阵进行相乘操作且计算量相同的情况下,不同矩阵的计算速度差异较大。例如,矩阵A维度为m×n,矩阵B维度为n×k,若将m扩大p倍,同时将k缩小p倍,则在不改变m×k值(即不改变矩阵计算量)情况下改变矩阵维度,上述矩阵的计算效率差异较大。文献[19]利用gemv函数进行同样计算,发现不同维度下gemv函数对不同矩阵的计算效率具有较大差异。
设矩阵维度m=Q×p、n=Q、k=Q/p,其中Q分别为500、1 000、2 000,矩阵A=m×n、B=n×k,使用cuBLAS库对矩阵A和B进行相乘运算,不同矩阵维度下计算效率如图2所示。其中,以每秒10亿次的浮点运算数(Giga Floating-point Operations Per Second,GFLOPS)作为计算效率的评价指标。可以看出不同矩阵维度下计算所得GFLOPS均随着加权值p的增加而下降,且各个矩阵维度的GFLOPS在相同计算量下变化趋势明显。
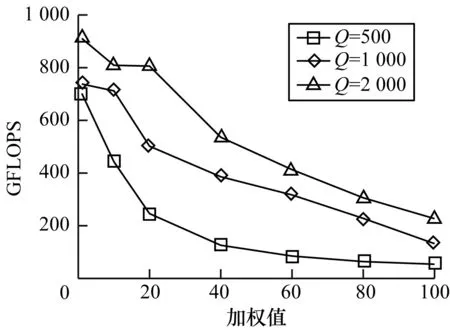
图2 不同矩阵维度下的计算效率
设m=Q、n=Q/p、k=Q,矩阵A=m×n,B=n×k,当Q取值为500、1 000、2 000时,不同矩阵维度下计算量随加权值p的增大而减小,计算量减小倍数为p,计算时间随加权值p的变化情况如图3所示。可以看出不同维度矩阵相乘的计算时间随加权值p的增大均出现下降,且当p取值范围为[1,10]时降幅明显,而在p=10后计算时间趋于恒定。
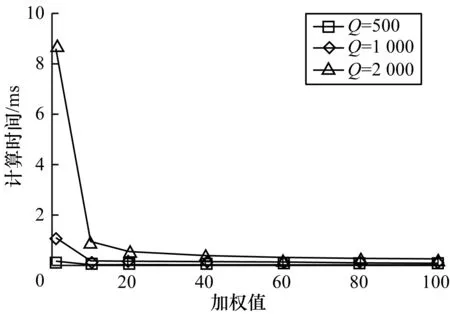
图3 不同矩阵维度下的计算时间
本文通过分析不同矩阵维度的计算特性,推导出适合cuBLAS库进行卷积计算的卷积加速方法ConvC。设L为高斯随机数序列长度,n为滤波器系数个数,若L可分解为M×N行矩阵,设i=N-(n-1),拓展到第k行,设K=(k-1)×N-(n-1),则矩阵A可变换为(M+1)×(N+n-1)维矩阵,矩阵B可变换为(N+n-1)×N维矩阵,具体变换如下:

(2)
(3)
在矩阵A中第一个高斯序列前补n-1个零元素,前M个行向量与矩阵B每个列向量相乘所得结果即为卷积计算结果中的每一个元素。但每一行元素有限,在计算每一行第N个元素的前n-1个元素时,由于无法提供其卷积运算的后n-1个元素,因此对每一行进行延拓,补出前一行高斯序列后的n-1个元素,将列个数设为N+n-1,以保证后续n-1个元素的卷积计算,并在矩阵A最后一行第n-1个元素后补N个零元素。由于矩阵相乘所得结果后N-(n-1)个元素为零元素,因此将其舍去后即完成卷积数组的计算。矩阵B第一列以倒序将卷积核中元素依次分布在前n行,并补出后N-1个零元素,后面每一列将前一列n个卷积核元素下移,同时在空缺位置补出零元素,共创建N列。由于N为变量,因此矩阵形式根据N的大小有所不同。
序列L可能有多个因数,对L=M×N中M与N的数值进行加权,设加权值为p,则L=(M×p)×(N/p),矩阵A维度为(M×p+1)×(N/p+n-1),矩阵B维度为(N/p+n-1)×(N/p),该矩阵维度具有可变性。假设序列L长度为1.0×106,卷积核长度为20,M=N=1 000,则L=(1 000×p)×(1 000/p)。当p为1时,矩阵A维度为(1 000+1)×(1 000+20-1),矩阵B维度为(1 000+20-1)×1 000;当p为2时,矩阵A维度为(2 000+1)×(500+20-1),矩阵B维度为(500+20-1)×500。根据cuBLAS库中gemm函数计算特性,改变矩阵行与列的维度可使卷积计算时间更短且浮点数计算性能更高,从而加速卷积计算。在当前数据量下,采用gemm方法创建矩阵所需元素量为L×n+n×1,而本文ConvC方法所需元素量为矩阵A和矩阵B元素总个数 (M+1+N)×(N+n-1)。设n=20,表1为gemm方法与ConvC方法进行卷积计算中创建矩阵所需元素量的对比,可以看出gemm方法所需元素量比ConvC方法多近10倍,因此采用gemm方法进行预处理耗时更长。
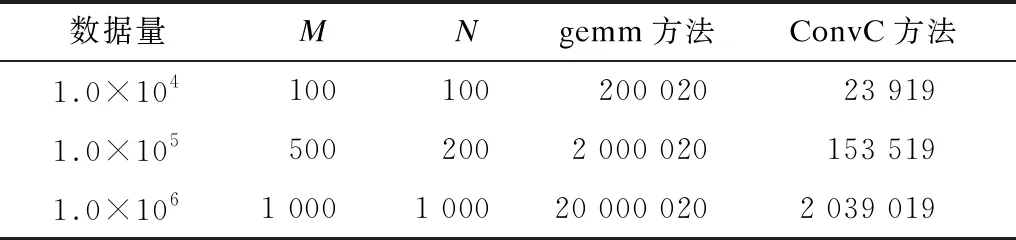
表1 gemm方法与ConvC方法所需元素量对比
2.1.2 基于CUDA的共享内存卷积计算
使用共享内存对卷积计算进行优化也是一种提高矩阵乘法运算效率的有效方法。共享内存是位于每个流处理器中的高速内存空间,用来存放线程块中所有线程都会频繁访问的数据。共享存储器是片上存储器,其访问延迟仅几个时钟周期,远低于数百个全局存储器时钟周期的访问延迟[20]。CUDA除全局内存和共享内存外,还支持常量内存。常量内存用于保存在核函数执行期间不发生变化的数据,其具有两个特性:1)高速缓存;2)支持将单个值广播到线程束的每个线程,可减少大量访问次数[21]。文献[22]利用CUDA共享内存方法降低线程块中数据访问延迟,可有效提高一般稀疏矩阵-矩阵乘法运算效率。
在高斯序列卷积计算中,高斯序列在第n个与第(L-n)个元素之间,对序列中元素和每个滤波器系数产生n次复用,由于n次全局存储访问开销较大,而共享内存的访问速度远高于全局内存,因此可使用共享存储单元替代全局存储单元,将高斯序列中元素放入共享存储单元。由于滤波器系数在核函数运行过程中未发生变化,因此可使用cudaCopyToSymbol函数将其放入常量内存中进行存储优化,并通过常量内存的线程广播机制提高线程内数据访问速度,进而减少通信开销。将高斯序列拆分为X段,分配X个线程块,并在每个线程块中配置共享内存空间,将每段数据存入相应线程块的共享存储空间内,同时在线程块中分配Y个线程,每个线程完成一次卷积计算,共完成X×Y=L+n-1次计算,卷积核函数计算中最多可减少n×L次全局内存访问开销。
通过将高斯序列分配到共享内存、滤波器系数分配到常量内存,可大幅减少访问全局内存的次数,从而缩短卷积核函数计算时间。此外,cuBLAS库有约200 ms初始化时间,若只需少量单次生成杂波数据,则可采用共享内存方法,下文将对该方法的优化效果进行介绍。
2.2 基于CUDA的串-并行任务调度优化
在采用H2滤波器进行滤波时,由于多阶巴特沃斯滤波器需计算多阶差分方程,因此H2滤波过程加速热点为H2递归的串行部分与H2滤波后si序列的生成。差分方程具有多参数递归性,若强行将其改为并行,则可通过系数矩阵与初始向量的线性关系构造矩阵和向量的乘法运算,但由于差分方程系数多、数据运算量过大导致其系数矩阵很复杂,且系数运算量随数据量的提升而增加,因此耗时严重,难以作为并行程序在GPU中执行,本文通过优化CPU-GPU任务调度模型进行粗粒度任务并行化处理。
差分方程计算中需生成高斯随机数作为其中的x,而si序列的生成则需滤波后的结果数据,各任务之间存在较强的数据依赖性。本文采用NVIDA公司提供的可视化性能分析器Visual Profiler对数据流进行分析,由于在各项任务执行过程中CPU与GPU均有较长数据等待时间,难以达到负载平衡,因此在大量数据下采用多任务分割模型将该串行程序进行任务并行化,以节省算法所需时间。在任务的并行模型选择上,OpenMP应用程序采用fork-and-join执行模型,并利用工作共享指令在所生成线程之间分配工作负载[23]。文献[24]利用OpenMP多核调度技术并行化CPU线程,可有效解决GPU-CPU负载不平衡问题,因此本文考虑采用OpenMP并行模型。
在大量数据下,GPU任务被分解为多块执行时仍能保持良好的加速比,在数据量为1.0×104的相乘开方运算中,较CPU单独执行快3倍以上。而在对高斯序列进行H2滤波计算时,由于需提前在GPU中生成高斯序列,因此将其作为GPU任务记为G1,在差分方程计算中,进行串行计算时将其作为CPU任务记为C1,在生成si序列时将其作为GPU任务记为G2,采用OpenMP+CUDA混合编程,如图4所示,其中:Task表示任务块;Device to Host表示从设备端拷贝数据到主机端,这也是CUDA中显存和主机内存的数据交换方式;Host to Device表示从主机端拷贝数据到设备端。
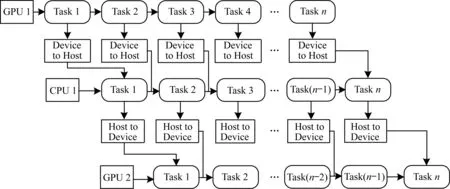
图4 串-并行执行任务调度模型结构Fig.4 Structure of task scheduling model of serial-parallel execution
图4中串-并行执行任务调度模型采用横向串行纵向并行调度模式,将3个任务G1、C1、G2作为父任务分解为n个子任务集合,即G1={G11,G12,…,G1n},C1={C11,C12,…,C1n},G2={G21,G22,…,G2n}。由于CPU端进行H2滤波前需已知高斯数据序列,且在进行非线性变换时需采用H2滤波结果数据,因此C1与G1、G2与C1之间具有数据依赖关系,在此情况下采用OpenMP多核技术并行调取CPU-GPU任务。执行G1中第1个子任务G11,将其结果作为C1中第1个子任务C11的数据来源,模型中横向为执行时间线,在执行G1第2个子任务时,CPU端执行G1前项任务数据,并将计算结果作为G2子任务的数据来源,此时其在纵向无数据依赖关系,以G1第1个子任务G11开始执行为时间起始节点,以G2最后1个子任务G2n执行完毕为时间结束节点。由于OpenMP主要是对for循环的多核并行调用[25],因此将纵向任务列为1个任务集合,通过判断for循环次数来选取相应核中子任务执行以进行任务调度,进而利用GPU实现细粒度数据并行计算。设G11与G2n的总执行时间为T1,G1与G2(不含G11与G2n)任务集合执行时间为T2,CPU程序C1的执行时间为T3,G1、G2与C13个任务总执行时间为Tmax,则其计算效率评价函数S的表达式为:
(4)
本文以相关相干K分布杂波为例,通过改进H1滤波中卷积计算方法和H2滤波中多任务串-并行任务调度机制,在SIRP方法基础上提出SIRP-CU算法。SIRP-CU算法将GPU并行计算特性与SIRP方法中杂波生成方式相结合,并使用CPU-GPU异构通信进行数据共享,其具体计算流程如图5所示。
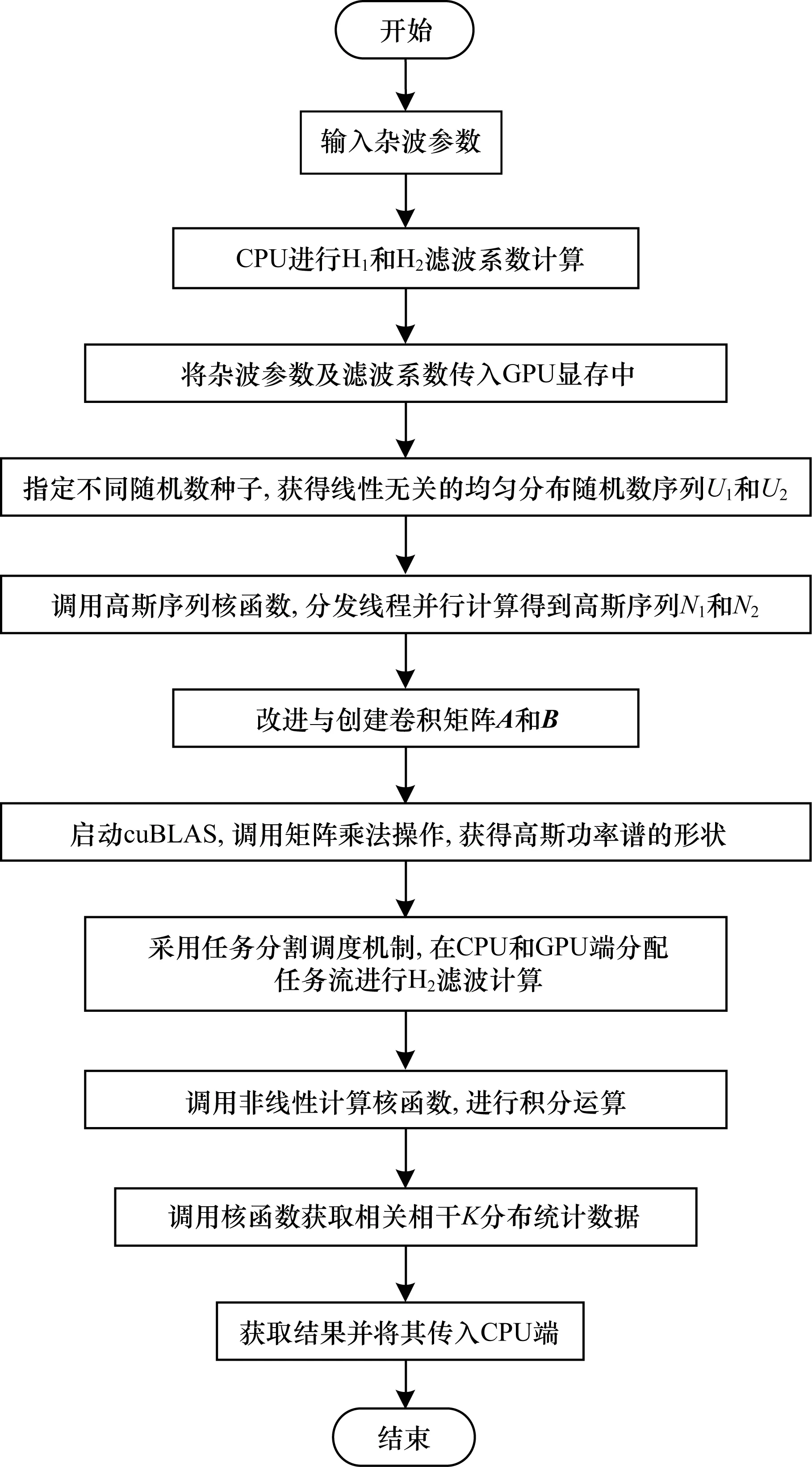
图5 SIRP-CU算法流程
3 实验与结果分析
本文使用SIRP-CU算法对相关相干K分布杂波进行仿真加速实验,所用CPU为 Intel i5-8300,GPU为Nvidia 1050Ti,软件平台为Visual Studio 2013、CUDA 8.0。选取形状参数λ为5和10,设定采样频率为Fs=1 000 Hz,2个半功率点之间的带宽f3 dB=50 Hz,功率谱形状为高斯功率谱,采样点数量设置为1.0×105个。图6为实验所得相关相干K分布杂波仿真曲线与理论曲线对比。可见仿真所得相关相干K分布杂波的概率密度和功率谱密度在多个形状参数下均可与理论曲线较好拟合,因此,利用SIRP-CU算法可对相关相干K分布杂波进行准确模拟。

图6 相关相干K分布杂波仿真曲线与理论曲线对比
目前卷积方法较多,在使用FFT方法对大量数据进行卷积测试中,由于卷积核较小,与卷积序列相差过大,采用FFT方法进行H1滤波效果不如gemm卷积方法,使用cuFFT库相较CPU的FFT效率提高数倍,但仍无法超过cuBLAS库中gemm方法计算性能,因此采用基于GPU的gemm方法、共享内存卷积方法(shared)与本文ConvC方法进行对比。在对杂波进行仿真时,H1滤波器系数个数设置为20,采用不同计算量对20个数字的卷积核进行卷积测试,得到GPU与CPU卷积计算加速比,如图7所示。可以看出当数据量为1.0×106时,ConvC方法加速比为340,其加速效果优于另外2种方法,gemm方法加速比为39.5,加速效果远低于ConvC方法。
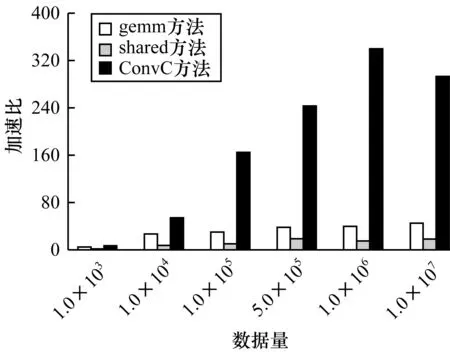
图7 3种方法所得GPU与CPU卷积计算的加速比
图8为ConvC与MKL库卷积计算的加速比,MKL库卷积方法包括FFT方法和直接卷积方法,本文选用MKL库卷积方法中的VSL_CONV_MODE_AUTO方法,其可自动选取使用FFT方法和直接卷积方法中更快的一种方法进行卷积。可以看出ConvC方法和MKL库方法的加速比最高达到6,当数据量较小时加速比约为2,随着数据量的增大加速比增加,ConvC方法加速效果明显提升。因此,在数据量较大且卷积核较小的情况下,采用ConvC方法进行卷积计算具有明显优势。
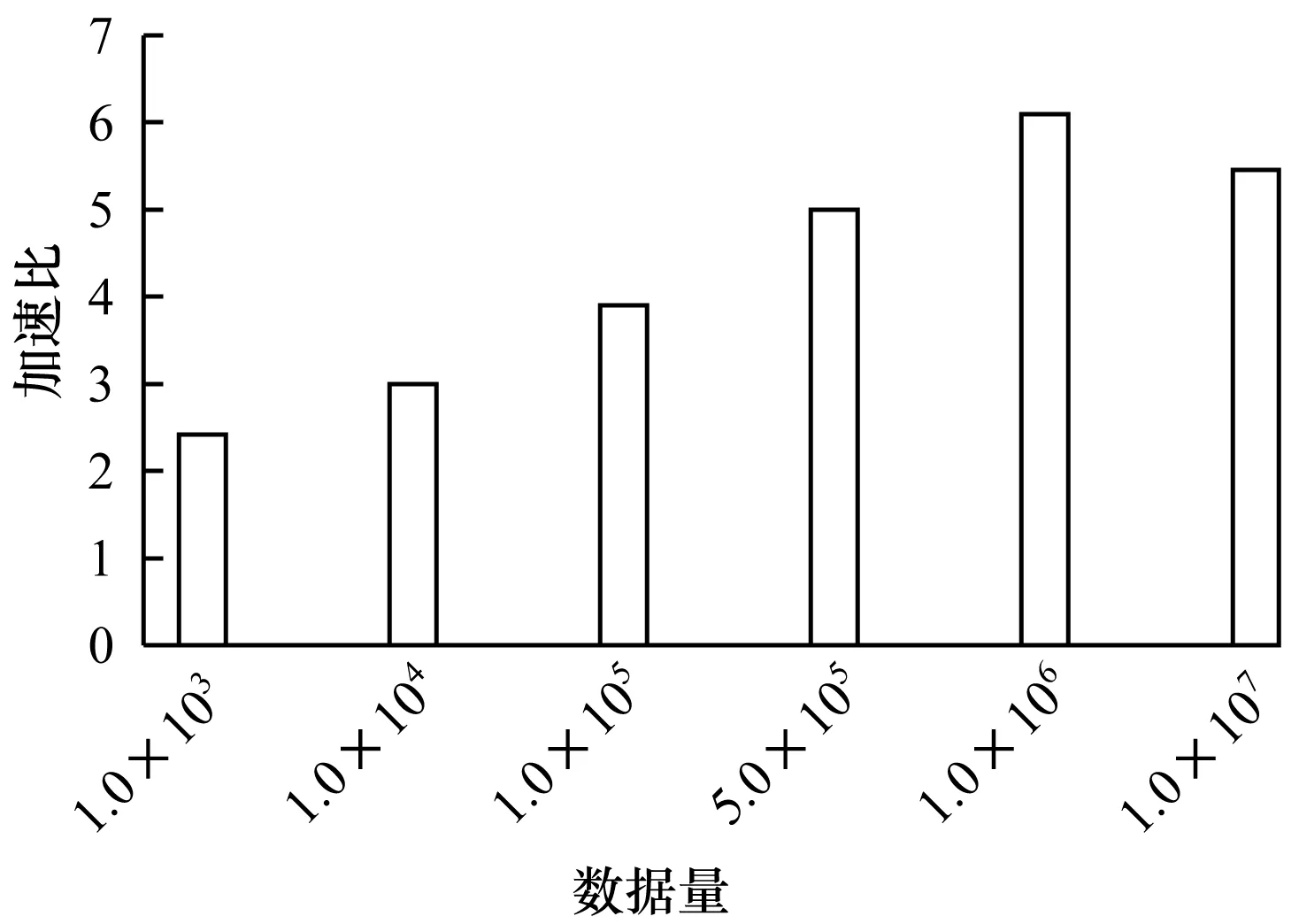
图8 ConvC与MKL库卷积计算的加速比
使用OpenMP+CUDA的任务分配与调度机制,可提升H2滤波模块的计算效率。根据式(4)中计算效率评价函数S的计算方法,针对H2滤波模块中不同数据量使用MPI+CUDA方法与OpenMP+CUDA方法进行评价函数值对比,结果如图9所示。可以看出当数据量由1.0×103增加到1.0×104时,OpenMP+CUDA方法计算效率提升约13%,与MPI+CUDA方法相差不大。但由于MPI所开辟进程具有单独内存空间,不同进程之间数据通信开销较大,随着数据量增多,该弊端逐渐明显。而OpenMP基于共享内存方式进行多线程协同运算,通信开销较小,相较MPI+CUDA方法在非分布式单一计算机上具有优势。当数据量为1.0×106时,OpenMP+CUDA方法所得评价函数值高达42%,而MPI+CUDA方法所得评价函数值为33%,OpenMP+CUDA方法提升计算效率更明显,这是因为OpenMP+CUDA基于多任务调度机制,对多个串-并行执行任务进行粗粒度任务分割与调度,提高任务之间并行率,从而使H2滤波模块的计算效率得到较大提升。
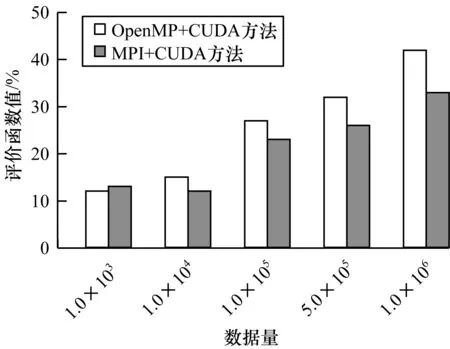
图9 2种方法所得评价函数值对比
杂波仿真中常用线程优化分配+共享内存方法,将其作为未优化方法与本文对细粒度与粗粒度优化的SIRP-CU方法以及CPU方法所用计算时间进行对比,结果如表2所示。可见当数据量为1.0×103时,未优化方法与SIRP-CU方法计算时间接近,但随着数据量的增大,3种方法所用计算时间差距逐渐增加,SIRP-CU方法在不同数据量下所用计算时间均少于其他2种方法。
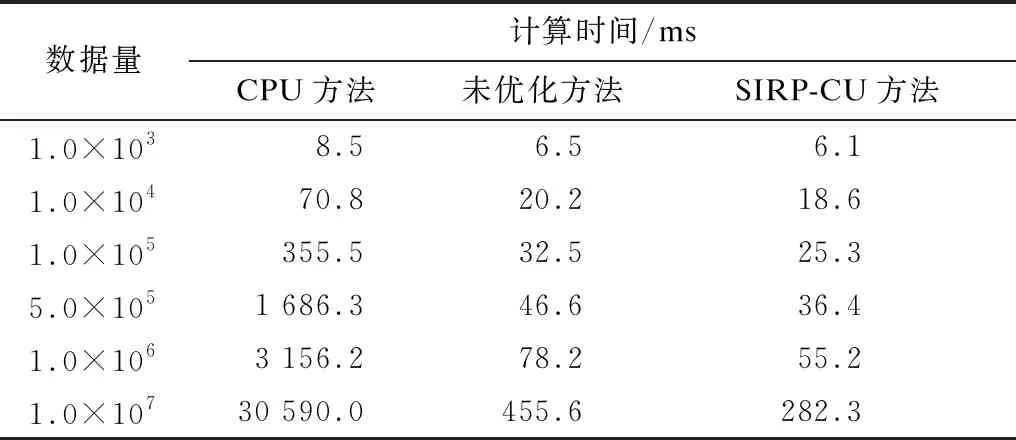
表2 3种方法所用计算时间的对比
图10为未优化方法与SIRP-CU方法所得GPU与CPU卷积计算的加速比。可以看出:当数据量为1.0×103时,2种方法加速比均较小;当数据量增大到5.0×105时,2种方法加速比均增大,计算效率均有所提升;当数据量达到1.0×107时,未优化方法加速比为67.1,SIRP-CU方法加速比高达108.3,相较未优化方法加速比大幅增加,计算效率更高。由上述可知:采用CPU生成杂波数据时,在大量数据下计算耗时较大;使用GPU进行较小数据量计算时,其计算效率提升不明显,但在大量数据计算时,GPU并行计算较CPU计算效率更高。
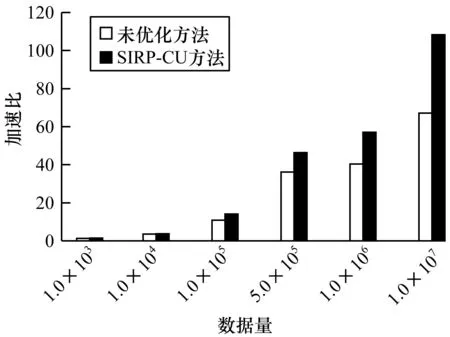
图10 2种方法所得GPU与CPU卷积计算的加速比
4 结束语
本文在SIRP方法基础上提出一种提升杂波生成实时性的方法。使用CUDA中数据库对相关相干K分布杂波的GPU计算方法进行优化,利用cuBLAS库和OpenMP+CUDA多任务调度机制改进卷积并行计算,以满足GPU环境下卷积数组与卷积核相差较大时的计算需求。实验结果表明,该方法能有效提升杂波生成实时性,当数据量逐渐增大时,计算加速效果显著,加速比高达108.3。下一步将在多GPU和多CPU场景下改进GPU优化策略,以获取更高的加速比和杂波模拟效率。
