基于强化学习的旅行商问题解构造方法
2020-11-14王若愚陈勇全
王若愚,陈勇全
(1.深圳供电局有限公司 输电规划科,广东 深圳 518001; 2.香港中文大学(深圳) 机器人与智能制造研究院,广东 深圳 518172; 3.深圳市人工智能与机器人研究院 无人系统研究中心,广东 深圳 518129)
0 概述
旅行商问题(Traveling Salesman Problem,TSP)是一个经典的NP-hard组合优化问题[1],其基本形式定义为:给定n个城市以及任意2个城市i和j之间的距离dij,要求从某个城市出发,不重复访问每个城市,最终回到出发城市形成一个环路,并使得路径的总长度尽可能短。若对于任意2个城市i和j都有dij=dji,则称为对称TSP,否则称其为非对称TSP。
TSP在机器人路径规划、交通物流、生物信息和芯片设计等领域有广泛的应用背景,如电力系统巡检机器人的路径规划问题即可建模成TSP,滴滴、顺丰、美团等公司经常面临的车辆调度问题[2]也可看作是在TSP的基础上,叠加多车辆、取送货等多种业务要求以及容量约束、时间约束、续航里程约束等约束条件。
由于TSP在理论和应用层面的重要性,已有研究人员对其进行持续而深入的研究,并设计出很多高性能的求解算法,主要可分为精确型算法、近似算法与启发式算法三大类。其中,精确型算法主要包括分支定界[3]、分支切割[4-5]等方法。在计算时间和存储容量充足的前提下,精确型算法可以确保找到问题的最优解,但由于TSP的NP-hard属性,问题的解空间规模呈指数级的爆炸式增长趋势,该算法所需时间往往呈现出指数级增长,这限制了其在大规模场景中的应用。然而,近似算法虽然不能保证找到问题的最优解,但是可以在多项式计算复杂度内严格保证所找到解的路径长度与最优解的路径长度之间的比值不超过一定的上限,该上限被称为近似度,且近似度越接近1,算法的性能越好。目前,较好的TSP近似算法为Christofides算法[6],其近似度为1.5。启发式算法与前2种算法不同,该算法不对解的优度进行严格保证,但一般可在较短的计算时间内找到优度可以接受的解。针对大规模算例,精确算法往往需要耗费指数倍的时间来求解,近似算法所得解与最优解相差甚远,启发式算法则成为兼顾算法优度和速度的切实选择。在该背景下,研究人员针对TSP设计出大量的启发式算法,如遗传算法[7]、蚁群算法[8]、粒子群算法[9]、模拟退火算法[10]、神经网络算法[11]以及混合算法[12-14]等。
尽管上述方法各有优点,但在TSP问题上,目前世界最领先的启发式算法是最为朴素的迭代局部搜索(Iterated Local Search,ILS)算法。基于TSPLIB[15]等国际标准算例集的测试结果表明,以LKH系列[16-18]为代表的ILS算法[19-20]在多数公开算例上保持着世界最优纪录,充分证明了其在求解TSP时的强大能力。ILS算法的典型搜索过程是从构造的初始解出发,采用某些操作算子对其进行局部变换操作,得到一系列邻域解,并选择其中某个改进解用于替换当前解[20]。迭代执行上述过程直至整个邻域中不存在改进解,即得到一个局部最优解,再构造新的初始解,并重复上述流程直至满足停机条件。
文献[21]表明初始解的构造方法是影响ILS性能的重要因素。一种良好的ILS初始解构造方法需要兼顾2个方面,一方面是优度较高,从而加快搜索速度,提高找到高质量解的几率。另一方面是具有足够的多样性,避免算法反复陷入同一个局部区域。为对比分析不同解构造方法的性能,本文针对对称TSP设计并实现4种不同的初始解构造方法,分别为基于距离的初始解构造方法、基于历史信息加以学习的全局构造方法、基于历史信息加以学习的局部构造方法、基于过滤网络及学习机制的初始解构造方法。其中,第一个方法为对比基准算法,仅利用算例的静态结构信息来构造解,后3种方法为基于强化学习[22]的学习型算法,尝试利用搜索过程中获取的有用信息指引解的构造过程。将上述4种初始解构造方法与基于2-Opt变换的局部搜索过程相结合,得到4个不同版本的ILS算法,并利用25个国际标准算例对其进行测试。
1 初始解构造方法
1.1 基于距离的构造方法(方法1)
采用逐步拓展的方式构造解,即从起始城市(假设为1号)开始,按如下方式迭代选择某个城市作为下一个待访问城市:将所有尚未被选中的城市视作候选城市集A,将各候选城市按其与当前城市的距离从近到远排序,距离第k近的城市被选中的概率为pk=α×(1-α)k-1,其中,α∈(0,1]为控制概率分布参数,且α越大,越倾向于选择距离较近的城市,否则初始解的多样性越强。距当前城市最远的城市被选中的概率与其他候选城市被选中的概率之和为1,迭代上述过程,直至所有城市都已访问,之后返回起始城市,即得到一个合法的TSP初始解。该方法不仅优先考虑距离较近的候选城市,还引入了随机性,使得每次生成的初始解具备一定的多样性。通过调整参数α的取值,可以适当控制所生成解的多样性。然而,该方法仅考虑城市间的距离等静态信息,未充分利用搜索过程中发现的有用信息。文献[23]研究表明,对于多数TSP算例而言,局部最优解中的边大部分也属于全局最优解。为验证该结论,本文采用TSPLIB[15]中的25个算例进行测试。采用方法1构造每个算例的初始解,然后采用基于2-Opt的局部搜索方法将其优化至局部最优,如此重复1 000次,计算局部最优解与全局最优解中重合边所占百分比。结果显示,在25个算例上,局部最优解中平均有80.9%的边属于全局最优解,验证了文献[23]的结论。
为充分利用上述结论,本文创建一个用来记录历史信息的n×n矩阵W,其元素wij表示边(i,j)在局部最优解中出现的次数。同时,用变量Num记录已经得到的局部最优解的个数(以上数值均初始化为0)。将ILS算法最开始的T个迭代周期作为预学习过程,期间每个迭代周期仍采用基于距离的构造方法来构造初始解,然后采用局部搜索方法将其优化为局部最优解,将变量Num加1,并采用以下方法更新矩阵W:若城市i和城市j在所得局部最优解中相邻,则wij和wji分别加1,否则仍保持不变。
经过预学习后,W中记录了有用的历史信息,可用于指导后续的初始解构造过程。基于此,在ILS的后续迭代周期内(应用阶段),可采用基于强化学习的方法来构造初始解。强化学习的基本原理为:若某个决策的效果好,则给予其正向激励,提升该决策被采纳的几率;反之则给予其负向激励,降低该决策被采纳的几率[22]。针对对称TSP,本文尝试3种基于强化学习的解构造方法用于解的构造过程。
1.2 基于历史信息加强学习的全局构造方法(方法2)
采用从初始城市出发逐步拓展的方式生成初始解,但各候选城市被选中的概率与基于距离的构造方法不同。假设当前城市为g,则对每个候选城市i∈A按式(1)定义一个权重系数:
(1)
各个候选城市i∈A被选中的概率为:
(2)
其中,q∈[0,1]为强化学习所需参数,q值越大,越倾向于选择出现频次最高的边,算法的集中性越强,反之则算法的疏散性越强。通过调整q值可以灵活控制算法的集中性和疏散性。
1.3 基于历史信息强化学习的局部构造方法(方法3)
与方法2不同,方法3不通过从头开始逐步拓展的方式构建一个初始解,而是在上一轮局部搜索所得解的基础上,通过局部变换得到一个新的初始解。假如上一轮局部搜索所得局部最优解为S(环路),在S中随机选择一段子路径(起始城市随机选择,路径长度为[n/6,n/4]之间的随机整数),将该子路径上的边全部删除,S中其余的边保持不变。从删除子路径的起始城市出发,采用与基于历史信息加强学习的全局构造方法类似过程进行迭代,按概率选择候选城市直至重新形成一个环路为止,并作为新一轮局部搜索的初始解。
以TSPLIB[15]中的eil51(包含51个城市)为例,图1展示了采用方法3构造初始解的示例过程。其中,图1(c)中的虚线为添加的边。

图1 采用方法3构造初始解的示例过程
1.4 基于过滤网络和强化学习的构造方法(方法4)
与方法3相似,方法4也在上一轮局部搜索所得局部最优解S的基础上,通过局部变换的方式得到一个初始解。两者的区别在于,方法4不再删除一段连续的子路径,而是通过一个过滤网络,基于频次矩阵W中的信息,过滤掉S中的若干条边。S中的每条边(i,i+1)被删除的概率为(1-wi,i+1)/Num,在局部最优解中出现频次越低的边,被删除的概率越大。按该方式过滤后,S将变成由若干段子路径或者孤立点组成的集合。在该基础上,通过逐步增加边的方式将其修复成完整的环路。为此,将所有度小于2的城市作为候选城市集A(包括每段子路径的端点以及所有孤立点),然后从A中任选一个城市作为出发城市,并迭代执行以下过程:若当前城市的下一个城市已确定(在过滤时未被删除),则将下一个城市作为当前城市,否则采用与方法2类似的规则,按概率从A中选择某个候选城市作为下一个城市,并用其替换当前城市。迭代上述过程,直至形成完整的环路,并得到一个新的初始解。
图2为采用方法4构造初始解的示例过程(以eil51为例)。

图2 采用方法4构造初始解的示例过程
值得注意的是,按方法2、方法3与方法4生成初始解后,都需采用局部搜索方法(详见下节)将其优化至局部最优,然后采用与预学习阶段相同的方法更新矩阵W中的元素及变量Num的值,从而实现持续学习。
2 迭代局部搜索算法流程
在TSP上,2-Opt是一个被广泛使用的操作算子,其基本思想是从当前解中删除2条边,然后再添加2条不同的边将其重新连接成合法解。采用2-Opt操作对解进行一次变换的过程如图3所示。

图3 采用2-Opt操作对解进行一次变换的过程
如图3所示,给定2个不相邻的城市i和j,删除边(i,i+1)和(j,j+1)后,添加边(i,j)和(i+1,j+1)是让其重新成为合法解的唯一方式,所对应的变换操作即为一个2-Opt操作,其操作复杂度为O(1)。不难发现,给定一个具有n个城市的环路,总共有O(n2)个可能的2-Opt操作。为降低总计算复杂度,选定城市i后,将城市j限定为与城市i距离最近的前10个城市,从而将可能的2-Opt操作数量控制在O(n)之内,通过牺牲优度来大幅提升计算速度。
为验证2-Opt操作的优化能力,实验仍采用TSPlib中的25个算例进行测试。对每个算例,使用方法1构造出初始解,再使用基于2-Opt操作的局部搜索算法对其进行优化,直至达到局部最优解,并循环执行1 000次。实验结果表明,初始解的总路径长度与全局最优解的总路径长度之间的平均偏差为47.7%,经过2-Opt操作优化后平均偏差减小至8.8%,说明2-Opt操作可有效优化初始解。虽然采用k-Opt(k>2)或者LK[16]等更为复杂的操作算子有希望取得进一步的改进,但由于本文的重点是研究初始解的构造方法而非局部优化方法,因此本文不采用上述复杂的操作算子。
在此基础上,为对比4种初始解构造方法对ILS算法性能的影响,将其分别与基于2-Opt操作的局部搜索过程相结合,得到4个不同版本的ILS算法。各版本ILS算法的框架相同,且统一如算法1所示,唯一的区别在于各版本ILS算法构造初始解的方法各不相同(算法1中的步骤2)。
算法1ILS算法
输入无向图G=(V,E)
输出TSP的合法解
步骤1将矩阵W中的各元素及变量Num初始化为0。
步骤2构造初始解S,预学习阶段统一采用方法1构造初始解,预学习阶段结束后分别采用方法1~方法4构造初始解。
步骤3对每一个候选的2-Opt操作,若执行该操作后所得解比当前解S更优,则执行该2-Opt操作,否则尝试下一个候选的2-Opt操作。
步骤4重复上述局部优化过程,直至通过2-Opt操作无法得到改进解,即得到一个局部最优解。
步骤5利用所得局部最优解的信息更新矩阵W中各元素的值,并令变量Num增加1。
步骤6若满足停机条件(迭代周期达到上限),返回搜索到的最优解,否则跳转至步骤2。
3 实验结果与分析
为对比分析不同初始解构造方法的效果,按上述方法得到4个版本的ILS算法,分别命名为ILS-V1、ILS-V2、ILS-V3、ILS-V4。从国际公开算例库TSPLIB[15]中选择25个具有代表性的算例作为测试集,对比分析4个版本ILS算法的性能。
3.1 参数设置
3种强化学习方法依赖于2个重要的参数,即控制预学习迭代周期数量的参数T,以及控制强化学习集中性和疏散性的参数q。为合理设置参数值,从25个测试算例中选取6个具有代表性的算例(城市数量分别为51、152、200、264、318及442),然后对比不同的参数取值在这6个算例上的表现结果,具体步骤为:
1)由于2个参数相关性较小,因此分别对其进行设置。首先调试参数T,令q=0.8且保持不变,令T从20开始,以步长为20逐步增大至500,得到25个不同的T值。在每个T值下,针对每个测试算例,分别采用ILS-V2、ILS-V3、ILS-V4迭代执行1 000个周期,并统计每次迭代所得的平均路径长度。实验结果表明,在总共18个测试场景下(6个算例,每个算例运行3种算法),T为[60,200]时,总体表现较好,参数T=100时,其中8个场景下的平均路径长度最小(具体数据可扫描首页OSID二维码,查阅附件2),整体表现最好。因此,本文设置T值为100。
2)类似地,为合理设置参数q,令T保持为100,令q从0.65开始,以步长为0.05逐步增大至0.95,得到7个不同的q值。针对每个q值,采用上述类似方法测试ILS-V2、ILS-V3、ILS-V4在6个算例上的平均路径长度。实验结果表明,最优q值与算例规模总体呈负相关关系。在18个测试场景下,q=0.8时,其中7个场景下所得的平均路径长度最小(具体数据可扫描首页OSID二维码,查阅附件3),整体表现最好。因此,本文设置q值为0.8。
综上所述,各版本ILS算法涉及参数及其取值如表1所示。
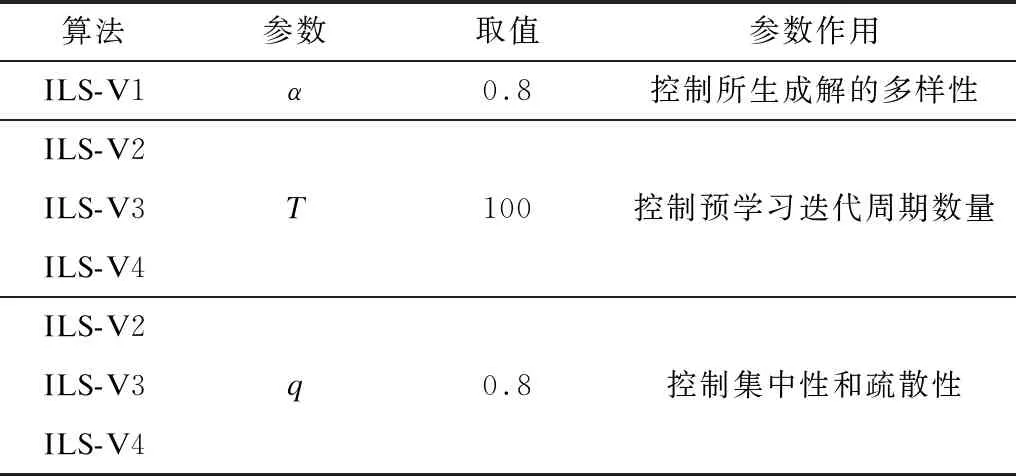
表1 各版本ILS算法涉及参数及其取值
3.2 实验结果
确定参数取值后,对于25个算例中的每个算例,采用4个版本的ILS算法分别迭代运行1 000个周期(计算平台统一为2.5 GHz CPU和8.0 GB内存),计算结果如表2所示。在表2中,第1列为算例名称,第2列为其全局最优解(记为Vopt),第3列~第7列为各算法的结果,且最优结果加粗表示,若与已知最优解持平,则用“*”标注。第4列和第5列为各种算法进行1 000次局部搜索所得最短路径长度(Vbest)及对应的最小偏差,第6列和第7列为各算法进行1 000次局部搜索得到的平均路径长度(Vavg)及对应的平均偏差。最小偏差和平均偏差计算方法为:
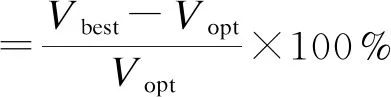
(3)
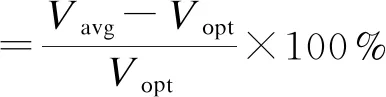
(4)

表2 4个版本ILS算法在25个测试算例上的计算结果

续表
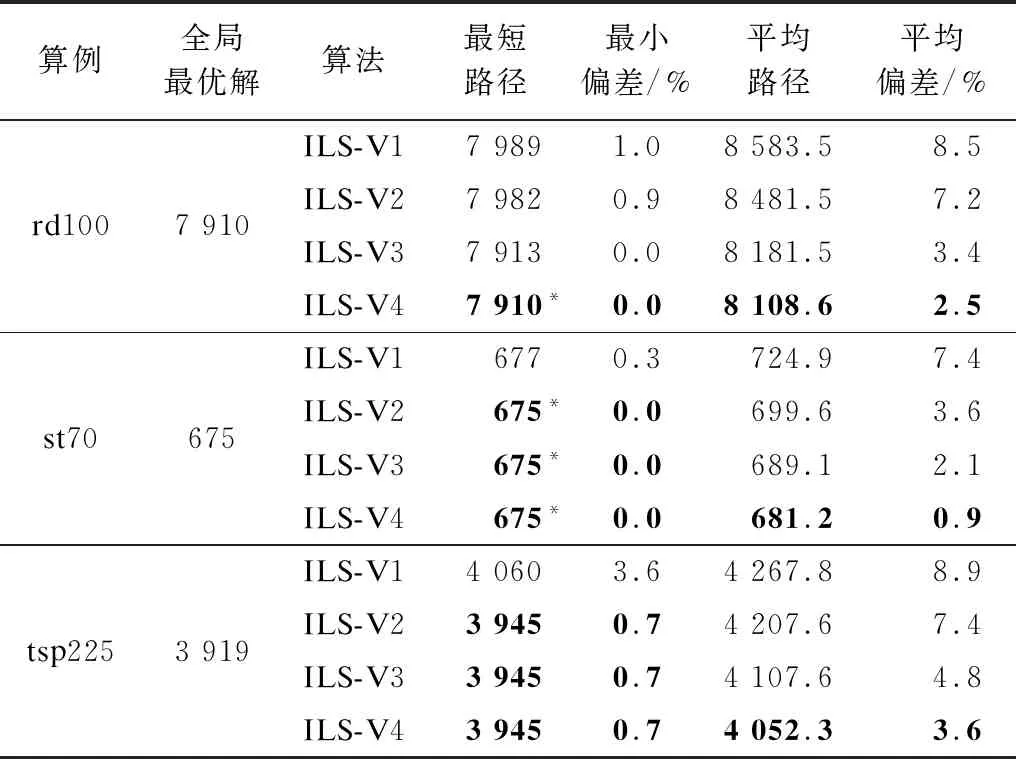
续表
从表2可以看出,在25个测试算例上,从最短路径长度Vbest角度而言,4个版本的ILS算法分别在1个、3个、14个、21个算例上表现最佳(部分并列最佳),且其对应的最小偏差的平均值(在25个算例上取平均)分别为2.11%、1.43%、0.56%、0.48%;从平均路径长度Vavg角度而言,4个版本的ILS算法分别在0个、0个、0个、25个算例上表现最好(ILS-V4在所有算例上均表现最佳),且其对应的平均偏差的平均值分别为8.83%、6.63%、4.09%、2.29%。
为检验各种算法之间是否存在显著统计性差异,对其最小偏差和平均偏差分别采用Wilcoxon检验,得到两两之间的p-value,具体如表3、表4所示。由表3、表4可以看出,从最小偏差的角度而言,ILS-V1与ILS-V2的表现无显著差异,ILS-V3与ILS-V4的表现较为接近,但前两者与后两者之间存在显著统计性差异;从平均偏差的角度而言,4个版本的ILS算法之间都存在显著统计性差异。

表3 各版本ILS算法基于最小偏差的p-value

表4 各版本ILS算法基于平均偏差的p-value
从25个测试算例中选取5个算例(城市数量分别为51、152、264、318、442)深入分析各版本算法的搜索过程。针对每个算例,分别记录各版本ILS算法在每个迭代周期结束时(总共1 000个周期)所得到的最短路径和平均路径,并给出其迭代收敛结果,具体如图4所示。

图4 各版本ILS算法在8个典型算例上的最短路径及平均路径的迭代收敛结果
从图4可以看出,在上述5个测试算例上,3种基于强化学习的ILS算法在收敛速度上明显优于ILS-V1,尤其是在平均路径长度维度上,随着迭代周期的增加,各版本ILS算法得到的平均路径长度均呈现逐渐降低的趋势,且ILS-V4的下降速度明显快于其他算法,这说明了过滤网络在构造初始解上的有效性,其主要原因有:1)相比于仅基于静态距离信息的ILS-V1,过滤网络可充分利用历史累积的有用信息,从而引导初始解的构造过程;2)相比于ILS-V2和ILS-V3,基于过滤网络的算法ILS-V4可识别出一定比例的潜力较小的边并将其过滤掉,同时保留大部分潜力较大的候选边,该筛选机制可在不严重破坏当前解结构的前提下,进一步优化新构造的解,从而提升构造解的质量。
4 结束语
本文针对TSP提出4种不同的解构造方法,包括一个仅利用算例结构等静态信息的基准方法和3种基于历史信息的强化学习方法,并将其与2-Opt操作相结合得到ILS算法。实验结果表明,通过学习和利用搜索过程中的有用信息,可有效提升ILS算法的整体性能,且基于过滤网络的强化学习方法整体表现最佳。后续尝试将基于强化学习的初始解构造方法与Lin-Kernighan[17]等经典局部搜索方法相结合,以得到性能更佳的ILS算法。
