基于多视图架构深度神经网络的图像威胁识别
2020-11-14叶晴昊涂岱键秦飞巍葛瑞泉
叶晴昊,涂岱键,毕 奇,秦飞巍,葛瑞泉,白 静
(1.杭州电子科技大学 计算机学院,杭州 310018; 2.武汉大学 遥感信息工程学院,武汉 430079;3.北方民族大学 计算机科学与工程学院,银川 750021)
0 概述
维持公共区域安全是保障社会和谐稳定和人民群众生命财产安全的一项重要工作。毫米波图像方法被广泛应用于机场和地铁站等公共区域的安检威胁识别任务中[1-2],该方法应用于威胁识别过程中时,要求精度好、效率高和误报率低[3]。然而,在威胁识别过程中采集到的毫米波图像存在形状、大小和位置未知的隐藏物体,导致图像处理方法存在较高的误报率。毫米波图像包括有源毫米波图像和无源毫米波图像2种类型。有源毫米波图像通过区分目标物体周围辐射强度的差异来生成扫描图像[4-6],能够以相对较快的速度生成图像,但该方法生成图像的分辨率较低且识别精度较差。无源毫米波图像通过解析目标的毫米波能量来生成扫描图像,可生成高分辨率的图像,适用于公共场所的高精度威胁识别。文献[7]提出一种改进的双基址结构,有效减少了扫描时间,同时提高生成图像的质量。目前,关于无源毫米波图像的研究常采用超分辨率方法来提高图像分辨率[8-10],以提高识别准确率。文献[11]提出一种基于高斯混合模型的方法,并将期望最大化算法用于分类阶段,虽然其结果准确性有所提高,但该方法会产生无关联区域。文献[12]提出一种双重阶段算法,该算法的准确率高,但是过程复杂且耗时长,难以投入到实际应用中。文献[13]提出一种多重阶段算法,通过优化图像处理速度,有效减少算法耗时,且可达到较高的准确率。
近年来,卷积神经网络(Convolutional Neural Network,CNN)已被广泛应用于识别、分类和分割等任务[14-16],且CNN具有通过非线性映射来区分数据独立特征的性能[17-19],因此在图像识别领域的应用较为广泛。文献[20]使用CNN-DL分类器检测毫米波图像中对象的可行性,并指出提高毫米波图像识别精度的2个重要因素:模型的深度和图像的完整性。由于训练样本较少、样本间类别不平衡问题显著,目前深度学习方法在威胁识别领域中的应用仍然较少。针对扫描对象的多角度视图,多视图间的特征信息联系显得尤为重要。文献[21]并未考虑多视图间的直接联系,导致存在较高的漏检率。因此,在威胁识别任务中存在隐藏物体形状、大小和位置未知的问题,且不是每个角度都能检测到危险物品,多视图角度下的区域重叠问题将会导致模型的误报率增大。与此同时,在实际安检过程中,由于多数检测对象都为无威胁样本,仅有少数样本为危险样本,从而引起数据不均衡问题。
针对以上问题和挑战,本文构建一种基于多视图的深度神经网络模型PSS-Net用于毫米波图像的威胁识别。该模型针对扫描图像多视角问题进行多视图建模,从而增强各区域在不同角度之间的关联程度,增强扫描对象的整体表征能力,并使用稠密性连接对单一视图的表征能力进行增强。与此同时,该模型运用注意力机制以及焦点损失函数解决扫描对象样本中存在的数据不均衡问题。
1 面向威胁识别的多视图深度神经网络
1.1 简述
针对输入的人体扫描对象生成16个视图,将每个视图划分为17个区域,随后各视图数据分别发送至残差连接卷积神经网络进行特征提取,且将通过注意力机制提取的多视图卷积特征作为时序特征,通过基于稠密连接的长短期记忆模型强化威胁区域的特征表达。基于焦点损失函数优化整个网络,构成一个端到端的可训练框架,从而对单个扫描对象的各个区域进行危险预测。本文方法的应用场景如图1所示。
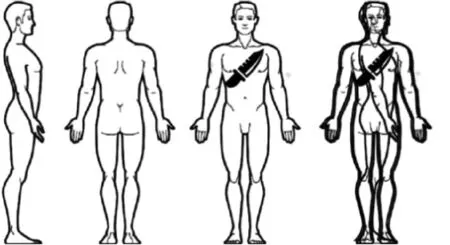
图1 威胁识别人物场景
1.2 多视图架构
图像序列建模[22-23]问题使得基于毫米波图像的威胁识别任务更加困难。图像序列建模[24]基于各扫描对象通常会生成多角度视图。由于图像部分区域重叠,使得识别难度增大,在这种情况下,多视图[23]之间的关联性显得尤为重要。与此同时,长短期记忆(Long Short Term Memory,LSTM)网络[25]在处理序列问题上具有广泛应用,可以较好地建立序列之间的关系。根据以上问题与解决方案,构建一个多视图卷积神经网络模型架构,如图2所示。其中,每个视图被发送到参数相同的预训练ResNet-50[26]网络中,以获取像素之间的关系并提取空间位置上的特征。此外,在最终特征图上,该模型采用一种基于稠密连接的长短期记忆注意力机制,特征映射由具有不同步幅和内核大小的卷积层处理。考虑到多视图信息序列的处理问题,通过LSTM对扫描对象的多个视图进行空间邻域上的扫描,并对扫描信息建模,从而对各个视图在不同扫描角度下的特征进行关联性建模,提高区域的表征能力。PSS-Net模型架构中的参数设置如表1所示。
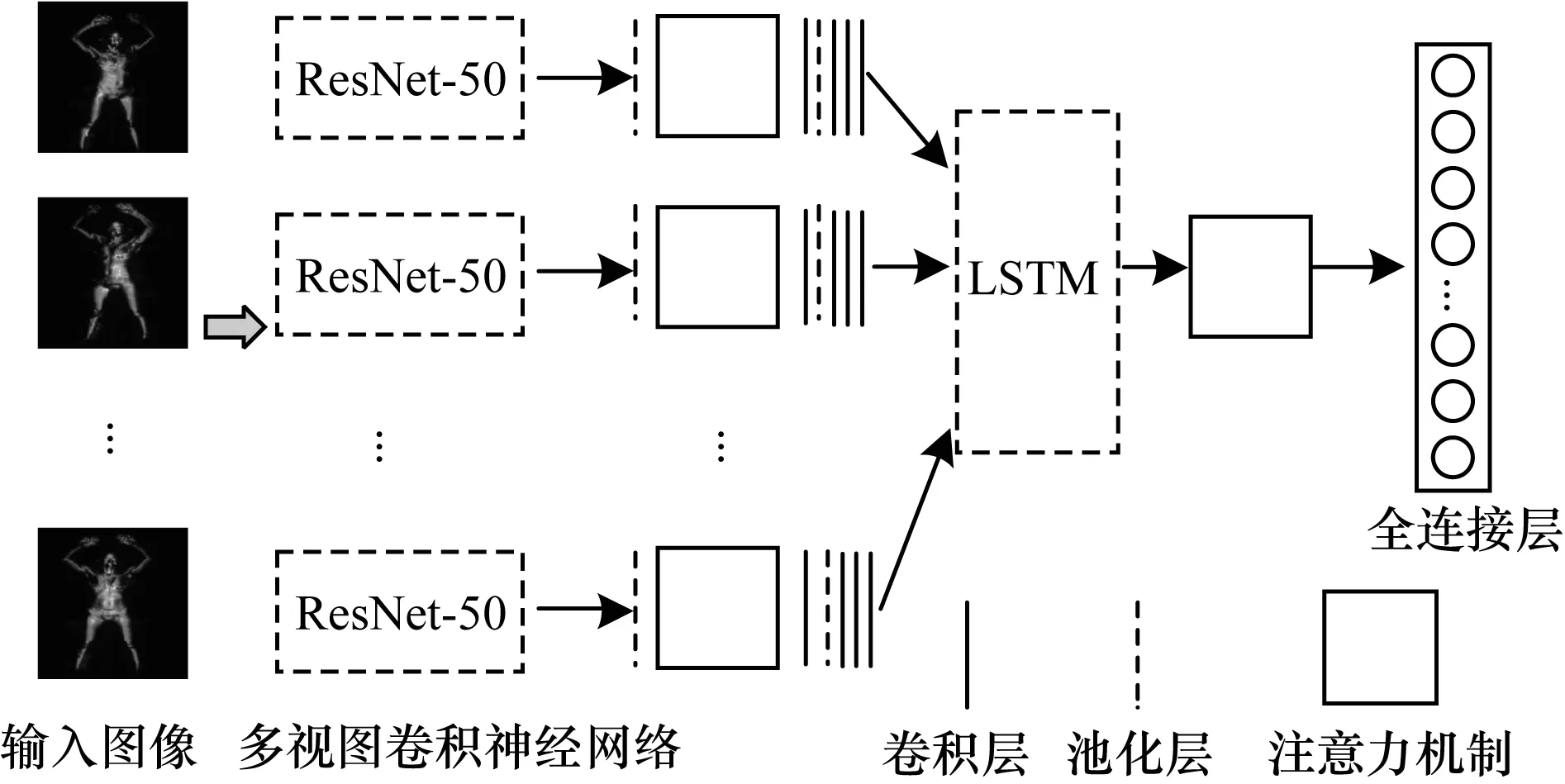
图2 PSS-Net模型架构
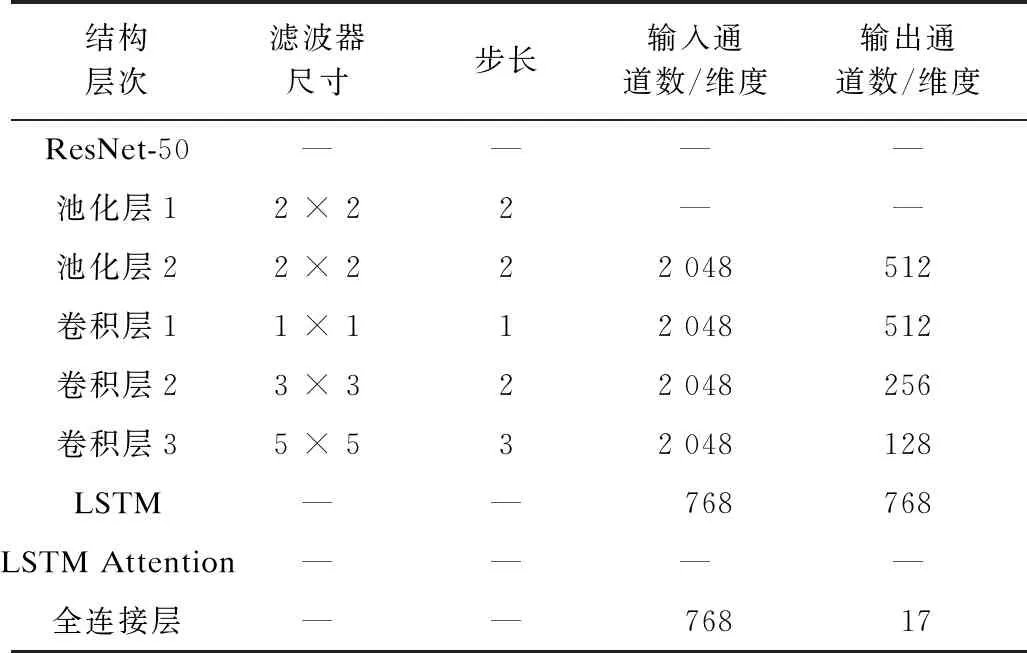
表1 PSS-Net模型架构中的参数设置
1.3 损失函数
利用模型对一个样本中的17个区域分别进行危险概率的预测,即对于N个样本,模型将输出17×N个概率。通常情况下,模型考虑使用交叉熵损失函数作为目标函数对模型进行优化,其表示方法如式(1)所示:
(1)
由于在毫米波图像威胁识别任务中存在危险的样本数量较少,从而带来数据不均衡问题,导致模型的识别召回率较低。因此对损失函数进行加权,以缓解样本不均衡带来的影响,具体如式(2)所示:
(2)
其中,α为样本调节因子。
上述问题仅解决了样本不均衡问题,并未考虑难分类样本在任务中的重要性。文献[27]提出一种焦点损失函数,可有效解决数据不均衡问题。在收敛速度和性能方面,焦点损失函数优于先前的损失函数,具体如式(3)所示:
(3)
其中,γ与α为可调节的超参数(预设γ=2.0,α=0.750)。
PSS-Net模型选取焦点损失函数为最终损失函数,并对模型进行优化。
1.4 注意力机制
注意力机制可增强图像全局信息的表达,降低局部信息对结果的影响,使得连接特征映射更加紧凑。CNN注意力机制通过全连接层进行特征映射变换,考虑了单个视图下的图像特征。LSTM注意力机制通过增加目标的权重并强调重要的区域,模拟人类观察多角度物体的过程,从而有效减少信息损失。LSTM注意力机制根据M(本文设置为16)个图像的全局信息重要性对每个扫描视图进行加权,并输入序列x=(x1,x2,…,xM),LSTM注意力机制计算输出序列zi=(z1,z2,…,zM),具体如式(4)所示:
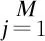
(4)
采用Softmax函数计算每个权重系数βij,具体如式(5)所示:
(5)
其中,βij表示第j个视图的注意力权重,Wxij是线性变换层,输入维度为768,输出维度为17。
2 实验结果与分析
2.1 数据集
本文方法旨在预测指定身体区域(来自17个全身区域)存在威胁的概率,每次扫描包含17个标签,对应于17个身体区域中是否存在威胁。
HD-AIT毫米波人体威胁扫描数据集中的每个人类扫描对象包含16个视图,且每个视图被分成17个身体区域,具体如图3所示。该数据集包含由新一代毫米波扫描仪获得的11 470个扫描对象。不同对象穿着不同服装类型(含夏季服装和冬季服装),具有不同的体重指数,含有不同的威胁数量和不同类型的威胁。
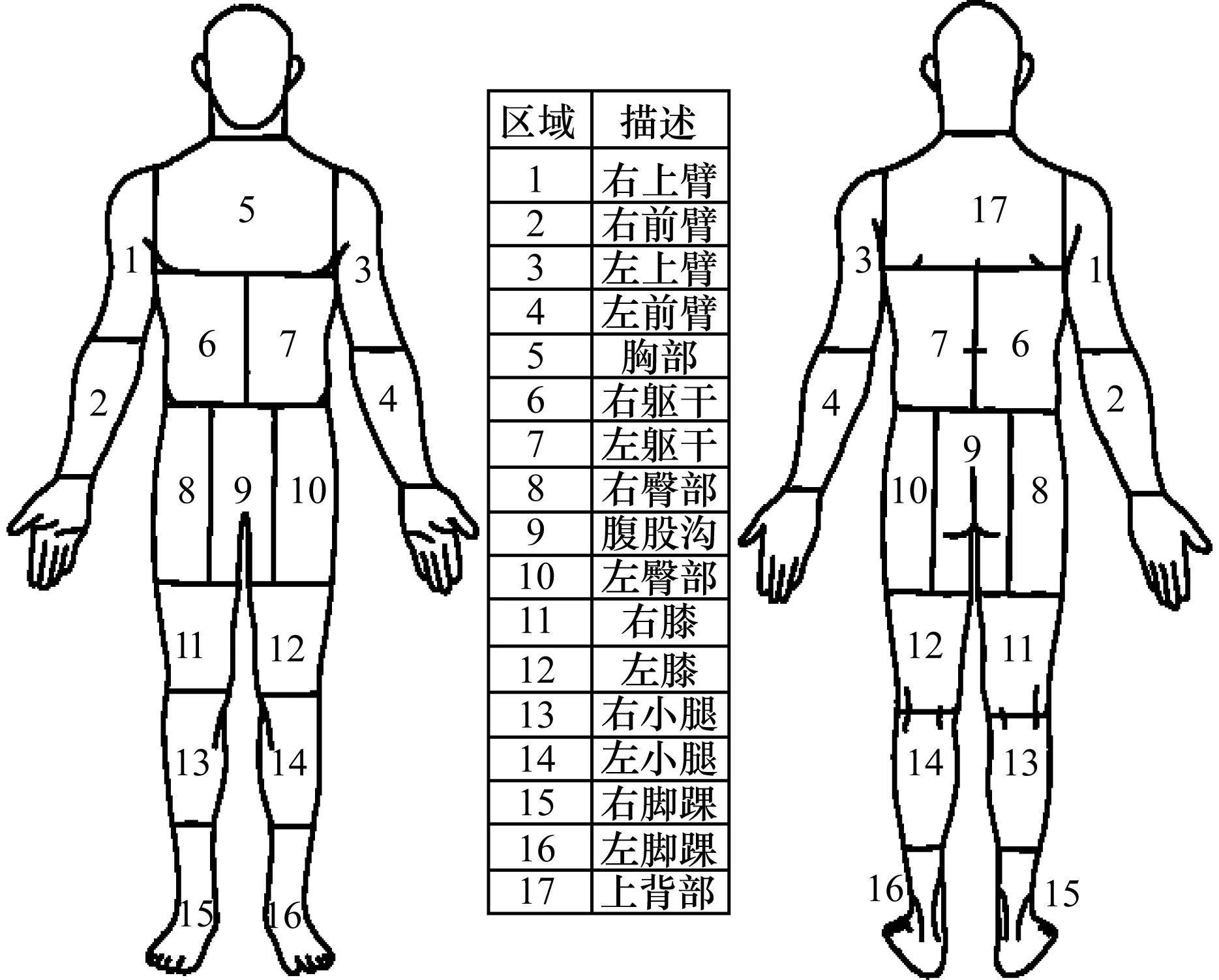
图3 人体扫描图像身体区域分布
2.2 评价指标
实验选择60%数据作为训练集,20%数据作为验证集,20%数据作为测试集。对于焦点损失函数,预设γ=2.0,α=0.750,并使用余弦学习率衰减策略对模型进行训练,初始学习率设置为0.1。基于Ubuntu 16.04 LTS系统,CPU采用36核2.6 GHz Intel Core i9-9870XE,内存大小为94 GB。使用4块GeForce GTX 1080Ti 型号GPU用于加速训练,总共训练150个Epoch,训练共计120 h。PSS-Net模型在PyTorch框架上训练,实验过程中模型在训练集和验证集上的损失可视化如图4所示。从图4可以看出,当训练到80个~100个Epoch时,损失函数已经降低到相对较低水平且基本收敛。
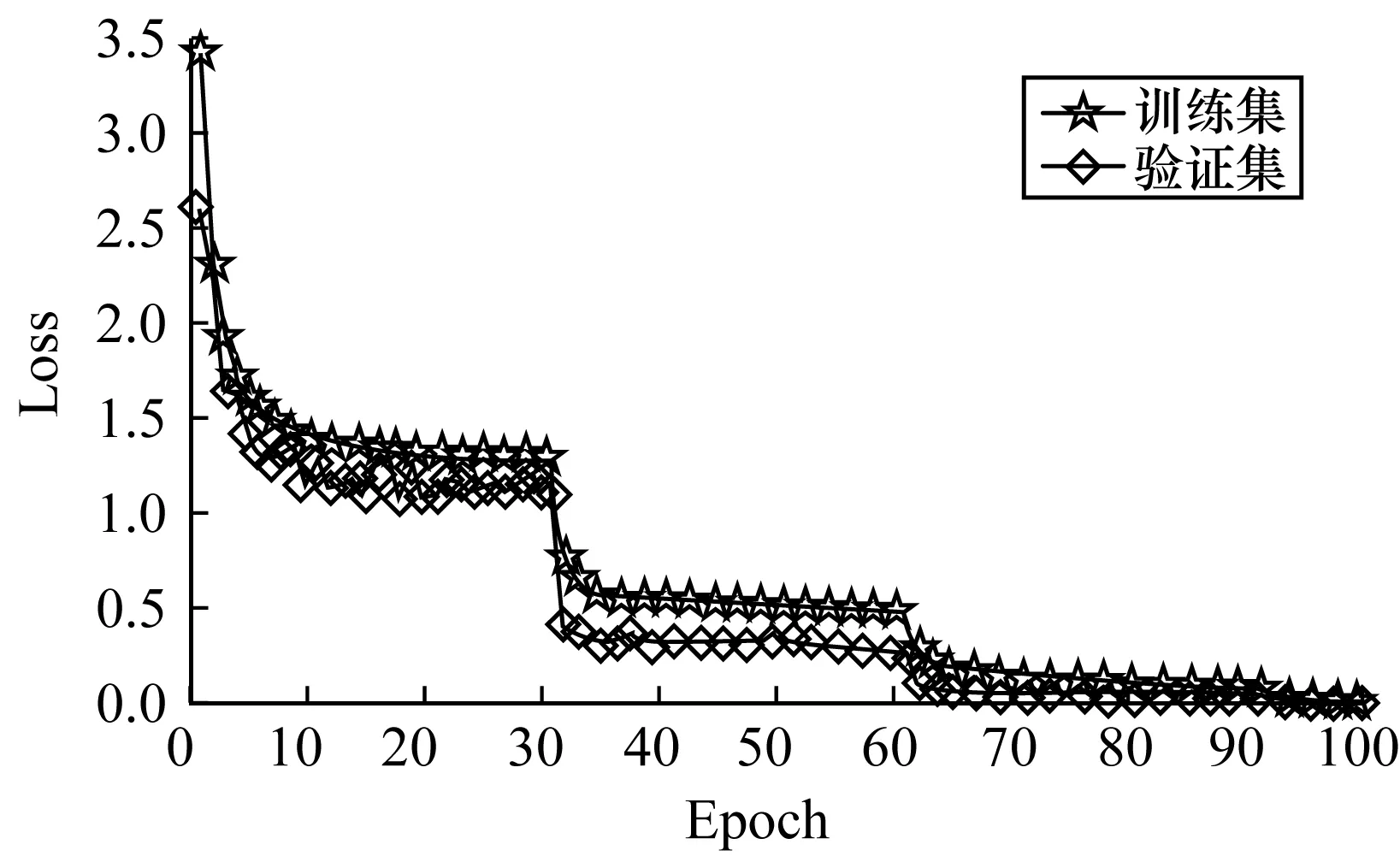
图4 训练集与验证集的损失函数
本文以准确率(Accuracy)、精确度(Precision)、召回率(Recall)、特异性(Specificity)和假阳性率(False Positive Rate,FPR)作为评估指标,计算方法分别如式(6)~式(10)所示:
Accuracy=(TP+TN)/(TP+TN+FN+FP)
(6)
Precision=TP/(TP+FP)
(7)
Recall=TP/(TP+FP)
(8)
Specificity=TN/(TN+FN)
(9)
FPR=1.00-Specificity
(10)
其中,TP表示非威胁样本中检测为无威胁样本的个数,FP表示非威胁区域中误检为威胁样本的个数,FN表示威胁样本中未能成功检测出威胁的个数,TN表示威胁样本中正确检测为威胁样本的个数。
2.3 测试结果
由于损失函数中的超参数对实验结果有不同的影响,实验研究了不同参数的α对焦点损失函数的性能影响,结果如表2所示。从表2可以看出,随着α的增大,焦点损失函数的准确率和召回率均呈现先增大后降低的趋势,当α为0.750时达到最优。实验进一步研究了不同的γ与α组合对焦点损失函数的性能影响,结果如表3所示,在实验过程中,当测试γ时,对应的α均取实验中的最优值。从表3可以看出,当γ=2.0时性能达到最优,因此实验选择γ=2.0,α=0.750作为损失函数的超参数。
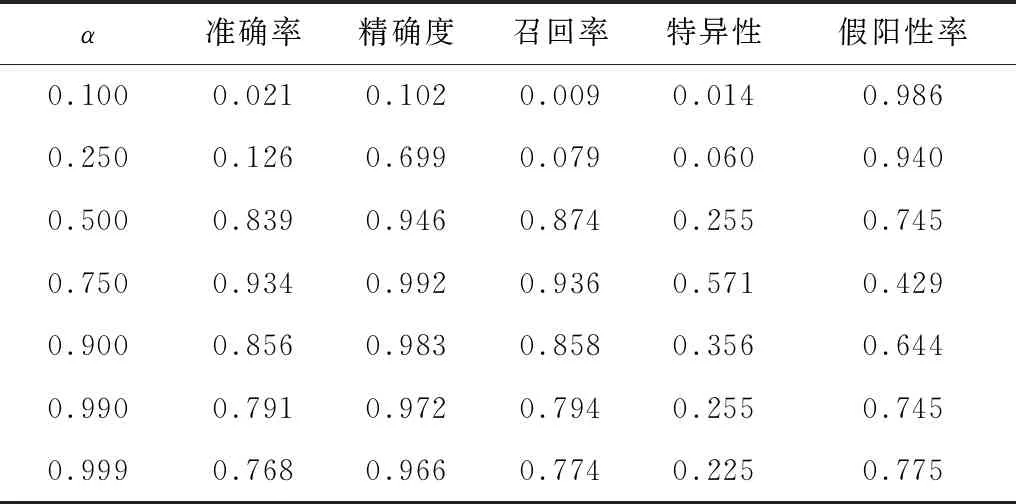
表2 超参数α对焦点损失函数的性能影响(γ=0)Table 2 Effect of super parameter α on the performance of focal loss function(γ=0)
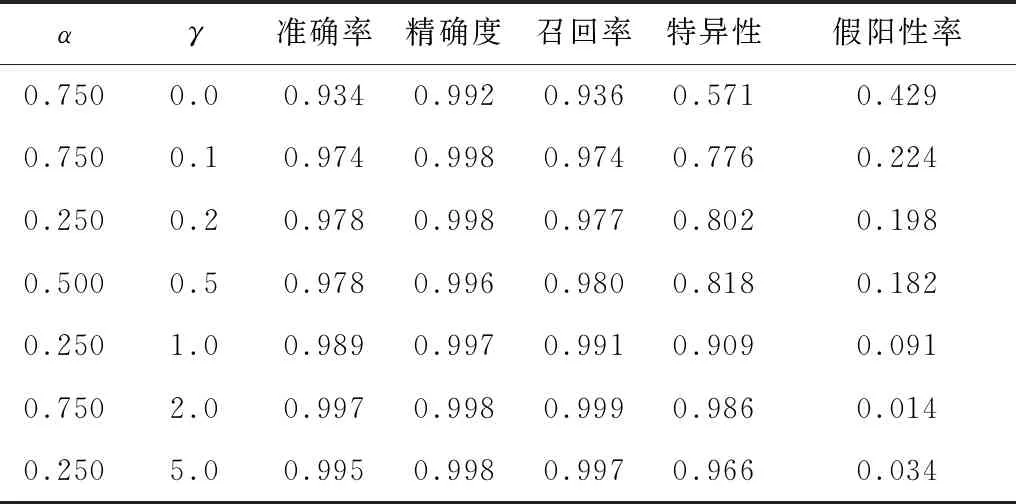
表3 超参数α与γ对焦点损失函数的性能影响Table 3 Effect of super parameter α and γ on the performance of focal loss function
为了有效对比各种模型在威胁识别方面的性能,实验对文献[26-28]中的基线模型与本文模型进行性能对比,结果如表4所示。从表4可以看出,本文提出的PSS-Net模型在测试集上的表现均高于其他基线模型,且该任务主要识别危险图像。同时,PSS-Net模型在召回率上相比其他方法提升更多。
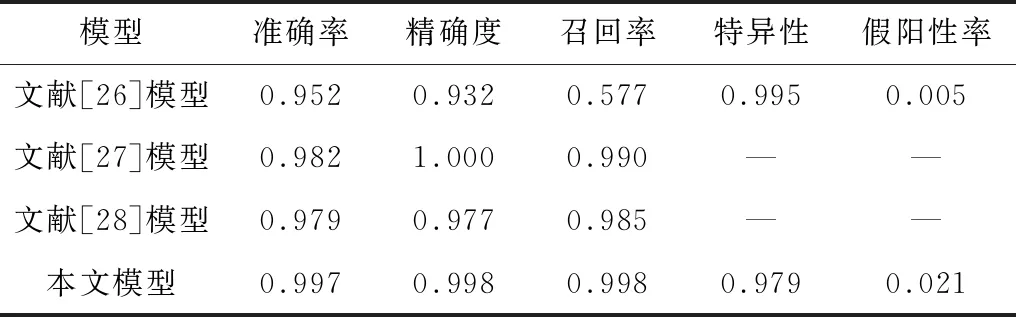
表4 4种模型的测试结果对比
2.4 结果分析
每个区域的测试结果如表5所示。由表5可知,误判集中在区域15(右脚踝)和区域16(左脚踝)中,误判主要源于人体生理结构的差异,考虑到数据集中多数样本不存在局部病变的情况,因此当目标身体存在畸变时将干扰判断,尤其是过于严重的生理形状病变可能导致误判。
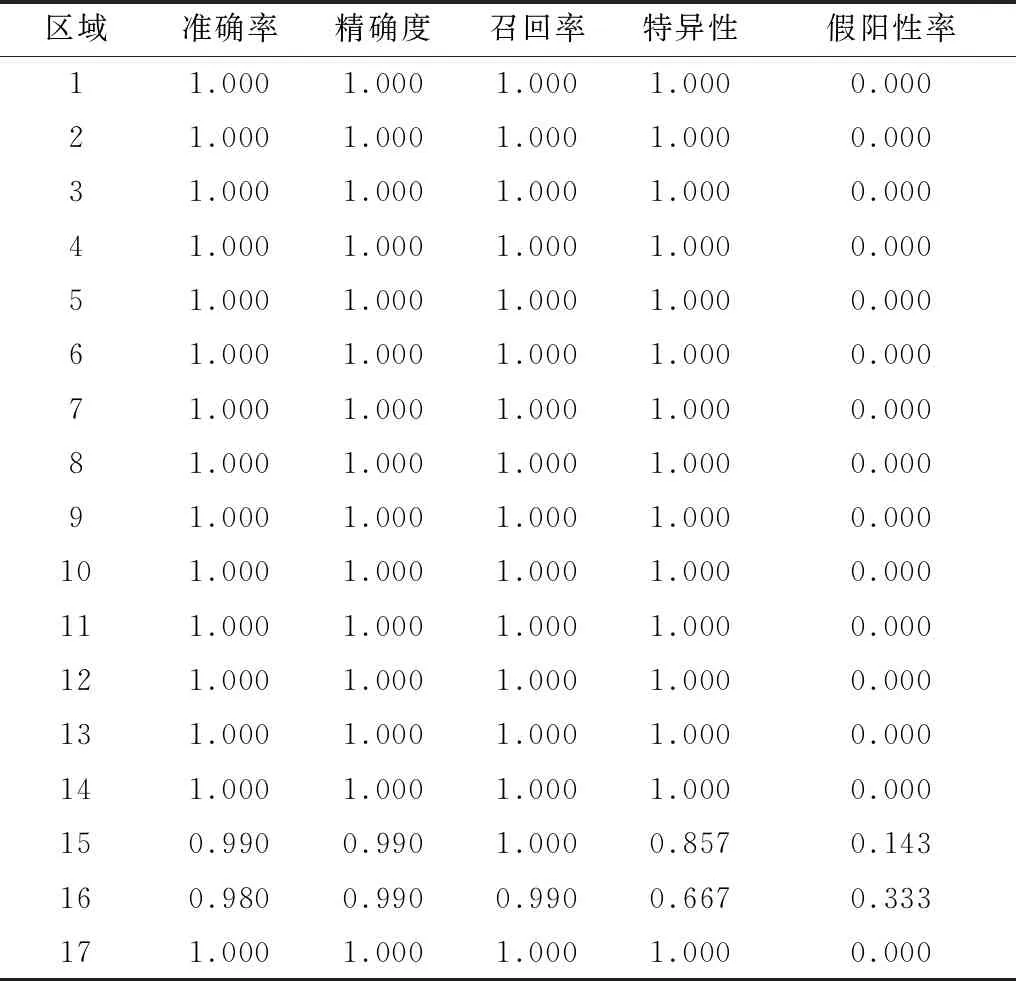
表5 各区域的测试结果
2.5 消融研究
为比较模型中不同模块对于性能的贡献,本文设计了消融实验进行研究,分别比较了LSTM、多视图卷积神经网络、注意力机制和焦点损失函数模块的测试结果,如表6所示。其中,实验1、实验2分别仅使用以ResNet-50和LSTM为基础的模型,实验3使用以ResNet-50为基础的多视图架构,实验4在实验3的基础上加入LSTM以用作序列处理。在多视图架构和LSTM的模型上,实验5加入注意力机制,实验6同时加入了注意力机制和焦点损失函数。从表6可以看出,对于不包含多识图架构的模型(LSTM和ResNet-50),从准确率角度而言,其结果均超过0.9,但召回率方面存在明显不足,加入多视图架构后,测试结果显示召回率至少提升了0.28,将注意力机制加入模型后,准确率和召回率均达到了0.97,最终PSS-Net模型在测试集上的准确率为0.997,召回率为0.999。
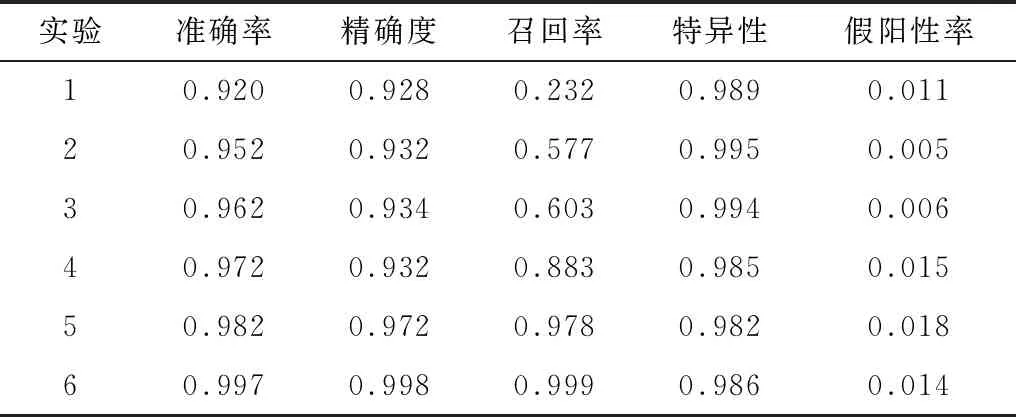
表6 消融研究测试结果
3 结束语
本文提出一种基于多视图的神经网络模型PSS-Net用于毫米波图像威胁识别。多视图架构解决了扫描对象的多方位问题,注意力机制显著提升召回率,在实际应用中可有效降低误判率。该模型在HD-AIT毫米波人体威胁扫描数据集中取得较高的识别精度,验证了其在威胁识别领域的有效性,有助于危险物品的精细化识别,对于提升公共区域安全具有重要意义。后续将针对不同对象的生理畸变进行研究,以提高本文模型在几何变形严重场景下的识别准确率。
