基于特征加权的深度学习Android恶意检测系统研究
2020-11-14葛文麒廖俊国何羽轩
葛文麒,杨 清,廖俊国,何羽轩
(湖南科技大学 a.计算机科学与工程学院; b.潇湘学院 计算机系,湖南 湘潭 411201)
0 概述
移动终端因其便利性在人们生活中应用逐渐广泛,其安全问题也成为学者们关注的热点。从2008年9月第一部Android移动智能手机发布至今,移动终端的发展日趋迅猛,目前全球Android移动设备已超过25亿台[1]。由于移动终端是执行各类应用程序的开放平台,因此成为众多恶意攻击者的首选目标。自2013年以来,恶意应用程序在移动终端的增长速度远高于PC端[2]。
2018年IDC报告显示,Android系统以85.1%的市场份额位居操作系统榜首,其在操作系统市场已占据主导地位[3]。与其他移动操作系统相比,Android系统具有开源性,其允许用户从第三方应用商店下载应用程序。然而有许多应用商店缺乏检测机制来识别恶意应用程序,导致此类应用程序呈增长趋势,对Android移动设备的安全性造成严重威胁。
目前研究人员主要采用基于数据跟踪的动态分析方法与基于反编译文件的静态分析方法对应用程序进行检测。动态分析方法需要在沙箱中运行应用程序,监视代码所有特征行为以及网络流量捕捉、文件加载等动态特性,该过程会消耗大量资源和时间,无法对应用程序进行快速检测。而静态分析方法是对应用程序安装包进行安全检测,无需运行程序。该方法通过逆向工程技术获得应用程序行为特征并从整体对应用程序进行分析,可快速高效识别恶意应用程序,但是不能运行应用程序做动态检测。在当前恶意应用程序数量快速增长的趋势下,与动态分析方法相比,采用静态分析方法对应用程序进行大规模分析更便捷,因此通常采用静态分析方法提取海量应用程序的行为特征,但是所提取特征中较多噪声与不相关行为特征会影响应用程序的检测性能[4-6]。
由于深度学习方法在图像与语音识别等领域具有优异性能,为消除上述行为特征中的噪声与不相关因素,本文采用基于深度学习的改进特征加权方法,分别从恶意与良性应用程序中提取行为特征,分析该行为特征并消除其中噪声与不相关的行为特征来构建特征向量,同时建立双向长短期记忆(Bidirectional Long Short-Term Memory,Bi-LSTM)神经网络模型对所提取特征信息进行自主学习,对参数进行优化分析以达到最佳检测性能,并对比了不同属性特征的检测效果。
1 相关工作
以下对用于检测Android系统中恶意应用程序的基于数据跟踪为主的动态分析方法、基于反编译文件分析为主的静态分析方法以及基于深度学习的检测方法的相关工作进行介绍。
1.1 静态分析方法
文献[7]针对目前Android系统防御机制不足的问题提出轻量级检测方法,但该方法利用应用程序的特征信息只能进行简单检测。文献[8]受生物学DNA序列比对思想启发,采用文本比较算法和套袋法相结合来评估系统所调用特征序列的相似性,对已知的恶意应用程序具有良好检测效果。文献[9]设计出Android多标准应用可信度评估器MAETROID,仅利用程序元数据而无需分析代码,大幅降低检测复杂性,同时采用层次分析法对应用程序进行多标准决策组合分析并为用户提供安装建议。然而该检测方法仅针对权限特征来检测Android系统中恶意应用程序,无法全面反映行为信息。文献[10]采用静态分析技术从应用程序中提取检测信息,并利用多数表决法将多个分类器以投票的方式进行应用程序检测。该方法在游戏类应用程序检测中取得较好效果,但对其他类别应用程序检测效果很差,无法对未知应用程序进行全面检测。文献[11]提出贝叶斯分类检测模型,通过静态分析方法检测未知的Android恶意应用程序,该模型选取特征类型单一,无法进行全面有效检测。文献[12]开发出Android权限控制和推荐系统RecDroid,从用户中广泛收集应用程序权限授予决策,同时采用贝叶斯学习模型评估用户专业水平并收集其权限控制决策,从而为其他用户提供依据。
1.2 动态分析方法
文献[13]在文献[12]的基础上,采用动态分析方法并将支持向量机(Support Vector Machine,SVM)与K最近邻(K-Nearest Neighbor,KNN)机器学习算法相结合构成应用程序评估模型,提升恶意应用程序检测性能,然而该模型会增加额外开销并占用大量资源。文献[14]提出M0Droid恶意应用程序检测模型,通过Spearman等级相关系数对恶意与良性应用程序中系统调用的行为信息进行相似性判别,但是若行为信息相近或恶意应用程序为未知,则不能进行有效检测。文献[15]构建基于应用程序行为特征的恶意应用程序动态检测模型Crowdroid,通过众包搜寻应用程序在用户移动终端的运行状况,并在Android应用程序的文件系统、内核系统调用与事件检测模块捕获恶意应用程序的动态行为,该模型对使用频率较高的应用程序检测较准确,但无法判别使用频率较低的应用程序。文献[16]基于文献[17]的思想将隐私数据作为污染源,用动态污点分析技术监控移动终端的敏感信息并跟踪多个敏感数据源,以区分相同版本的良性与恶意应用,然而该方法在检测过程中会占用大量资源,且不能进行准确安全评估,无法快速有效地检测出恶意应用程序。
1.3 深度学习检测方法
传统恶意应用程序检测方法均为浅层结构,无法对恶意应用程序进行全面有效检测,由于深度神经网络(Deep Neural Networks,DNN)在图像识别和人工智能领域具有良好的检测性能,因此研究人员将深度学习方法应用于恶意应用程序检测。文献[18]提出DeepClassifyDroid检测系统,通过静态分析提取特征集,采用词嵌入技术将所提取特征输入卷积神经网络(Convolutional Neural Networks,CNN)对应用程序进行分类检测,然而该系统仅选取静态特征建立特征集作为特征向量,未分析特征且增加检测开销。文献[19]采用长短期记忆(Long Short-Term Memory,LSTM)神经网络对恶意与良性应用程序的系统调用序列进行训练,通过计算其相似度评分对应用程序进行评估。文献[20]提出一种Android检测系统,使用深度卷积神经网络(Deep Convolutional Neural Networks,DCNN)检测原始操作码序列,减少人工提取特征造成的误差。
上述基于深度学习的检测方法仅从应用程序提取特征信息,未对特征信息进行充分分析,降低了应用程序检测准确性。此外,由于动态分析方法会增加训练模型时间、占用大量计算资源等额外开销,无法对未知应用程序进行快速检测,因此本文采用静态分析方法构建基于特征加权的深度学习Android恶意检测系统,以消除冗余与不相关特征,增强恶意应用程序区分能力并减少额外开销,同时全面检测应用程序,自动挖掘其深层特征并分析特征之间的信息,以对Android应用程序进行快速准确检测。
2 系统设计
本文系统主要包括特征提取、特征选择、特征嵌入和分类检测4个部分,系统结构如图1所示。其中:特征提取是对应用程序进行广泛静态分析,通过逆向工程技术从中提取6种不同类型静态行为特征作为特征集,以防止行为特征单一导致检测准确率较低;特征选择是在提取行为特征过程中,为消除行为特征冗余与不相关性,利用改进特征加权的方法,将TF-IDF算法与信息增益相结合,按照权重选择行为特征构成特征集;特征嵌入是将不同维度的特征按权重高低选择特征并映射到联合向量空间;分类检测是在传统机器学习模型缺乏有效行为特征学习能力且无法有效分析大量行为特征信息的情况下,将转换得到的多维度特征向量作为输入,通过双向长短期记忆神经网络利用隐藏层节点学习到本质行为特征后,对未知应用程序进行分类,最终实现Android恶意应用程序检测。
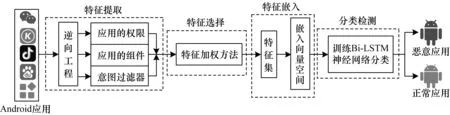
图1 本文系统结构
2.1 特征向量构建
2.1.1 特征选择
为有效检测Android系统恶意应用程序,本文从Android系统恶意与良性应用程序中提取全面而独特的行为特征,使用APKTOOL工具对Android系统应用程序的安装文件进行反编译生成AndroidManifest.xml文件,从中提取Android系统应用程序静态行为特征如下:
1)权限。权限是Android系统应用程序重要的安全机制之一。用户在安装Android系统应用程序时进行授权,使应用程序可访问不同类型的安全相关资源与数据。与正常应用程序相比,Android系统恶意应用程序会请求申请更多权限以获得尽可能多资源和数据,因此,部分恶意应用程序可通过权限申请进行识别。
2)应用组件。Android系统应用程序组件包括活动、数据通信、服务与广播。Android系统应用程序可在系统清单文件中申请多个不同类型组件,其中恶意应用程序会在用户不知情的情况下通过服务组件在系统后台运行某些服务进程来执行恶意行为。
3)意图过滤器。Android系统根据应用程序所配置意图过滤器的动作和类别进行比配,寻找响应意图的组件或服务,该机制为Android系统恶意应用程序监控用户移动终端提供便利,恶意应用程序在移动终端重启后会直接执行恶意行为。
2.1.2 选择算法
在提取的行为特征中,由于存在大量冗余与不相关特征导致恶意应用程序检测准确率降低,因此需要对行为特征进行分析。本文采用特征加权方法,结合TF-IDF算法与信息增益,考虑恶意与良性应用程序中每个行为特征的重要程度,并考虑上述行为特征与恶意或良性应用程序的关联程度。通过减少均匀存在于恶意与良性应用程序中调用行为特征的权重,来增强特定存在于恶意与良性应用程序中的行为特征。
假设恶意与良性应用程序所提取行为特征Si被调用的频率分别为T(Si,M)与T(Si,B),表达式分别如下:
(1)
(2)
其中,N(Si,M)与N(Si,B)分别表示行为特征Si在恶意与良性应用程序集中被调用的次数,i=1,2,…,n,N(M)和N(B)分别表示行为特征Si在恶意与良性应用程序集中被调用的总次数,n表示收集的行为特征总数。
将应用程序总数N分别除以恶意与良性应用程序中系统调用的行为特征Si,所得结果取对数得到的D(Si,M)与D(Si,B)分别表示行为特征Si在恶意与良性应用程序中重要程度,表达式分别如下:
(3)
(4)
其中,n(Si,M)与n(Si,B)分别表示恶意与良性应用集中调用特征Si的应用程序个数。
将T(Si,M)与D(Si,M)相乘可得到行为特征Si在恶意应用程序中权重,同理求出其在良性应用程序中权重,并将该权重与恶意应用程序中权重相减求绝对值,所得W(Si)表示行为特征Si对区分恶意与良性应用程序的重要性,计算公式如下:
W(Si)=|T(Si,M)×D(Si,M)-T(Si,B)×D(Si,B)|
(5)
本文中信息增益代表每个行为特征在恶意与良性应用程序集中带来的信息数量,信息数量越多,该行为特征越重要,其熵值也越高。对行为特征Si而言,其在应用程序分类中熵值会发生变化,熵值在变化前后的差值表示行为特征在应用程序检测中重要程度,表达式如下:
(6)
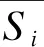
综上所述,通过行为特征Si在恶意与良性应用程序之间重要程度W(Si)以及行为特征Si区分恶意与良性应用程序的关联程度IG(Si)可得到行为特征Si的权重φ(Si),计算公式如下:
φ(Si)=W(Si)×IG(Si)
(7)
通过上述特征加权方法可求得不同特征集中每个行为特征Si的权重φ(Si),用其表示行为特征Si对应用程序检测影响程度,并由此选择行为特征。
2.1.3 特征向量
应用程序的恶意行为会反映在系统调用特征集的行为特征上,因此,在检测恶意应用程序时,可使用单一特征集或者组合特征集。在使用组合特征集时,需将不同维度特征集组合为统一形式。使用特征加权方法计算得到不同特征集中每个行为特征Si对检测影响的权重φ(Si),按照权重φ(Si)由大到小从不同特征集中选出特征形成新特征集S,表达式如下:
S=S(φ(Sp))∪S(φ(SI))∪S(φ(Sc))
(8)
其中,Sp表示权限集合,SI表示意图过滤器集合,Sc表示活动、数据通信、服务、广播四大组件集合。
本文将特征集S定义为具有|Si|维数的布尔表达式,并将其嵌入向量空间X中得到统一形式。假设恶意应用程序F在特征集中使用某些特征,则该特征集是1的向量,其位置为0。因此,将任意应用程序转换为向量空间X,表达式如下:
X={S1,S2,…,Sk}
k∈|Si|
(9)
通过上述方式,可将不同的特性集嵌入到统一的联合向量空间,利用组合特征集进行范围更广泛的检测。
2.2 改进的Bi-LSTM算法
2.2.1 检测模型
Bi-LSTM算法是应用较广泛的深度学习算法,其由多个长短期记忆网络组成,在图像识别、文本分析等领域具有良好的检测效果,因此,本文将Bi-LSTM设计为分类网络结构,对使用特征加权方法生成的特征向量进行分类,从而深层分析上下文行为特征之间的信息,同时解决梯度消失与爆炸问题,并通过Bi-LSTM分类模型检测恶意应用程序,该模型结构如图2所示。首先使用特征加权方法构造特征向量作为输入,分析向量输入参数与系统恶意应用检测准确率的关系,并通过不断调节向量大小实现对恶意应用程序全面检测,然后分析不同属性特征向量对系统恶意应用程序的检测性能并选出最佳特征向量。Bi-LSTM分类模型的隐藏层部分由Bi-LSTM组成,由于Adam算法是利用迭代次数和延迟因子对梯度均值与梯度平方均值进行校正,能准确预测梯度变化,收敛速度很快,因此本文训练Bi-LSTM网络时使用Adam算法通过迭代更新权重对其进行优化,并不断选取和调试Bi-LSTM网络隐藏层单元数以达到最优检测效果。在隐藏层后构造全连接层,由于整个过程执行分类检测任务,因此将全连接层输出作为分类层的输入,通过Sigmoid分类器对应用程序进行检测分类,最终使用二进制交叉熵损失函数评估检测模型预测效果。

图2 Bi-LSTM检测模型结构
2.2.2 Bi-LSTM算法
LSTM网络[21]由遗忘门、输入门、输出门和记忆单元构成,主要作用是对行为特征信息进行筛选、保存与更新,其结构如图3所示。为提升检测准确性,从前后两个方向分析所提取的信息,采用双向LSTM将上一个记忆单元状态(细胞状态)同时引入到输入门、遗忘门与更新计算中。
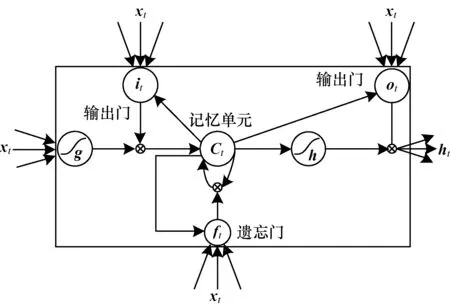
图3 LSTM网络结构
在图3中,遗忘门对上一层细胞状态进行筛选,留下有用信息并遗忘无用信息,计算公式如下:
ft=σ(Wf×[ht-1,xt]+bf)
(10)
其中,Wf和bf分别为遗忘门的权重和偏置,ht-1为上一层隐藏状,σ为Sigmoid激活函数。遗忘门通过采用Sigmoid函数控制遗忘门,使其根据上一时刻输出ht-1和当前输入xt产生ft值,并决定是否让上一时刻所得信息Ct-1通过。
利用输入门对信息进行判断,将重要信息送入细胞状态更新处以完成细胞状态更新,计算公式如下:
it=σ(Wi×[ht-1,xt]+bi)
(11)
Ct=ft×Ct-1+it×tanh(Wc×[ht-1,xt]+bc)
(12)
其中,Wi和bi分别为输入门的权重和偏置,Wc和bc分别为细胞状态的权重和偏置,it代表输入层,Ct-1和Ct分别为原细胞状态和更新后细胞状态。
确定更新信息的过程由两阶段组成:1)利用Sigmoid函数确定需更新加入到细胞状态的信息;2)利用tanh激活函数将需更新的信息转换为可加入到细胞状态的候选向量Ct-1,通过这两阶段生成新细胞状态Ct。
输出门包含当前输入、上一个隐状态、当前细胞状态等,主要是控制该层细胞状态输出,计算公式如下:
ot=σ(Wo×[ht-1,xt]+bo)
(13)
ht=ot×tanh(Ct)
(14)
其中,Wo和bo分别为输出门的权重和偏置。使用Sigmoid激活函数确定需输出的信息ot,然后用tanh激活函数对细胞状态值进行缩放作为信息筛选条件,并对信息ot筛选后输出所需信息ht。
3 实验与结果分析
3.1 数据集
为检测本文模型的有效性,从VirusShare网站和Android官方商店下载应用程序,删除无法使用和重复的应用程序后分别得到4 000个和3 500个应用程序,将其依次标记为恶意与良性应用程序,上述两部分应用程序组成本文实验的数据集。
3.2 评价指标
本文实验所用处理器为Intel®CoreTMi3-2130,CPU为3.40 GHz,内存为16 GB(RAM),采用Windows 7操作系统。以精确率(P)、召回率(R)、F1值(F)和准确率(A)作为本文系统检测效果的评价指标,计算公式如下:
(15)
(16)
(17)
(18)
其中,TP为正确预测的恶意应用程序数量,TN为正确预测的良性应用程序数量,FP为错误预测的恶意应用程序数量,FN为错误预测的良性应用程序数量。
3.3 参数设置
在Android系统应用程序数据集中随机选取2 500个良性应用程序与3 000个恶意应用程序,从不同方面分析Bi-LSTM神经网络的结构性能。选择隐藏层单元数时,如果隐藏层单元数太少,则无法对数据进行训练或者造成检测性能很差无法准确检测应用程序;如果选择隐藏层单元数过多,则训练数据时容易陷入局部极小值而无法得到最优性能,并在训练时出现过拟合问题。在选取同一特征向量长度作为输入时,由于隐藏层单元数为300时系统检测性能较好,因此从隐藏层单元数为300时开始测试。图4为系统检测准确率与召回率随隐藏层单元数的变化曲线,可以看出在不同隐藏层单元数下系统准确率和召回率均分别达到0.93和0.90以上,准确率和召回率较高。当隐藏层单元数为900时,系统准确率和召回率分别为0.947 5和0.943 2,相较其他隐藏层单元数下更高,因此本文选择900作为隐藏层单元数。
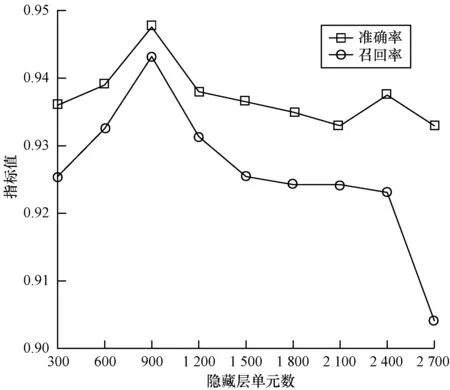
图4 系统准确率与召回率随隐藏层单元数的变化曲线
考虑到所输入特征向量长度对系统检测性能的作用,本文研究了不同特征向量长度对Android系统应用程序检测准确性的影响。由于输入特征集过少不能覆盖所有恶意和良性行为对检测效率的影响,而输入特征向量过长行为特征会受到额外的噪声干扰,由于特征向量长度为1 000时系统检测效果较好,因此将所输入特征向量长度初始值设置为1 000。利用特征向量长度对Android系统恶意应用程序检测性能的影响,选出分类任务最优的特征向量。图5为系统检测准确率与召回率随特征向量长度的变化曲线,可以看出不同特征向量长度下系统准确率和召回率均达到0.91以上,准确率和召回率较高。当特征向量长度为8 000时,系统准确率和召回率分别为0.953 1和0.958 6,相较其他特征向量长度下更高,因此本文选择8 000作为特征向量长度。

图5 系统准确率与召回率随特征向量长度的变化曲线
3.4 特征集选择
为评估本文系统在不同特征集中对应用程序的检测效果,以使用逆向工程技术提取的6类不同静态行为特征作为特征集,将所有特征集放入联合向量空间形成组合特征集,并通过式(9)构建特征向量以更全面地分析。表1为不同特征集得到的评估结果,可见组合特征集对恶意应用程序检测效果最好,指标值高于其他单一类型特征集,这是因为单一类型特征集对应用程序检测提供信息较少,无法实现准确检测,因此本文选择全部特征构成的特征集检测应用程序。
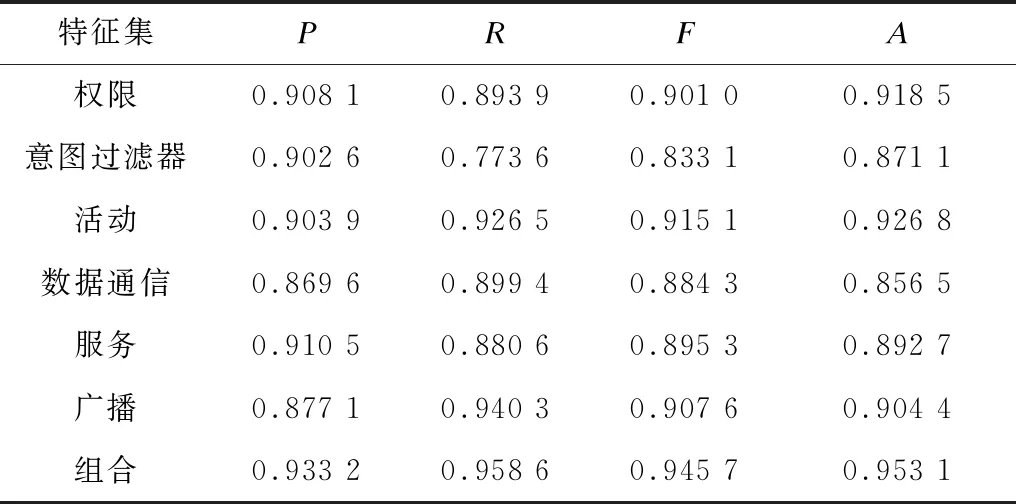
表1 不同特征集所得评估结果
3.5 实验结果
为验证本文提出的基于特征加权深度学习算法的Android恶意检测系统检测效果,将SVM、Logistic、Decision Tree、Naive Bayes等机器学习算法与RNN、LSTM、Bi-LSTM等深度学习算法的恶意应用程序检测性能进行对比,结果如表2所示。可以看出上述两类算法的检测准确率分别超过0.87和0.94,均具有良好的检测效果。而本文系统采用的Bi-LSTM算法所得指标值较其他算法更高,有效提升了恶意应用程序检测性能。
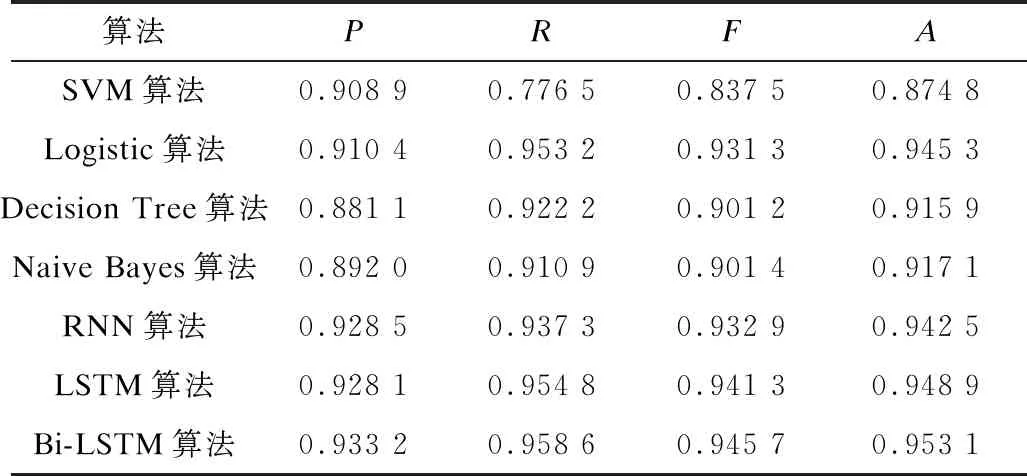
表2 不同算法所得系统检测性能指标结果
4 结束语
本文提出一种结合特征加权方法和双向长短期记忆神经网络的Android恶意检测系统。采用静态分析技术从Android系统应用程序中提取静态行为特征,利用特征加权方法分析行为特征和恶意与良性应用程序的关联程度,以去除冗余与不相关行为特征,并使用长短期记忆神经网络算法对所提取特征信息进行学习、分类与参数优化。实验结果表明,该系统具有较高的检测准确率,对恶意应用具有较强的识别能力,可大范围检测Android系统恶意应用程序。下一步将根据功能划分应用程序类别,提取对应的行为特征,并在特征集中扩展加入网络流量、动态文件加载等动态特征,以全面有效地提高系统检测准确率。
