基于多智能体协同强化学习的多目标追踪方法
2020-11-14王毅然经小川贾福凯孙宇健
王毅然,经小川,,贾福凯,孙宇健,佟 轶
(1.中国航天系统科学与工程研究院,北京 100048; 2.航天宏康智能科技(北京)有限公司,北京 100048)
0 概述
随着人工智能技术的不断发展,多智能体协同控制在军事应用中取得了重大突破[1-2],以无人机、无人车[3]和无人水面艇等为代表的无人智能体在执行军事作战中的侦察、护航、打击等任务时[4-6]通常以追踪问题为基础开展研究。而在现代战场环境下,由于任务和环境的复杂性,一般需要多个作战智能体协同完成对多个动态运动目标的追踪任务,因此智能体面对动态变化的战场态势,如何进行任务分工及采取何种行动策略将会影响智能体的作战质量和作战效率。
针对多目标追踪问题,学者们进行了大量研究并取得一定的成果。文献[7]提出一种合作团队追踪单一运动目标的方法,针对运动目标位置估计的不确定性,最大限度地缩小目标可到达空间。仿真结果表明,在位置不确定的情况下,该方法能通过追踪智能体捕获目标。文献[8]提出基于轨迹集和随机有限集的多目标追踪问题求解方法,通过多对象密度函数确定测量值的贝叶斯轨迹分布,其中包含所有轨迹的信息。
强化学习主要解决智能决策问题,其目前在单智能体决策领域取得了较大成功,如AlphaGo、AlphaGo Zero等。针对团队最优决策问题,学者们主要通过基于价值函数和概率这两种方法将单智能体强化学习扩展到多智能体强化学习。文献[9-11]基于价值函数的方法,采用Q-learning、DQN和IQL算法并结合奖励函数,仿真模拟了在完全协作、完全竞争及非完全协作/竞争环境下多个智能体的性能表现。但是,当环境较复杂及智能体规模较大时,上述算法的稳定性和可扩展性较差,且难以应对较大的连续动作空间,无法输出离散状态动作值。文献[12-14]基于概率的方法提出深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法,在动作输出方面通过网络拟合策略函数并直接输出动作值,可应对更大的动作空间以及连续动作的输出。针对上述方法存在的学习时间长、实时性差等问题,本文提出一种基于多智能体协同强化学习的多目标追踪方法(Multi-Target Tracking method based on Multi-Agent Collaborative Reinforcement Learning,MTT-MACRL)。
1 多目标追踪问题
1.1 问题描述
多目标追踪问题涉及追踪和目标智能体两方面,其主要的研究目标为多个自主追踪智能体的协同追踪策略[15-17]。目前,关于追踪问题的描述不一,本文将追踪问题定义为:假设在相同的有限二维空间内存在np个追踪智能体,则追踪智能体集合P={P1,P2,…,Pnp},假设在相同有限二维空间内存在ne个目标智能体,则目标智能体集合E={E1,E2,…,Ene},追踪智能体和目标智能体统称为智能体A,A=P∪E。OPi(i=1,2,…,np)代表追踪智能体Pi的中心,OEj(j=1,2,…,ne)代表目标智能体Ej的中心,VPi(i=1,2,…,np)代表追踪智能体Pi的运动速度,VEj(j=1,2,…,ne)代表目标智能体Ej的运动速度。
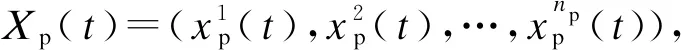
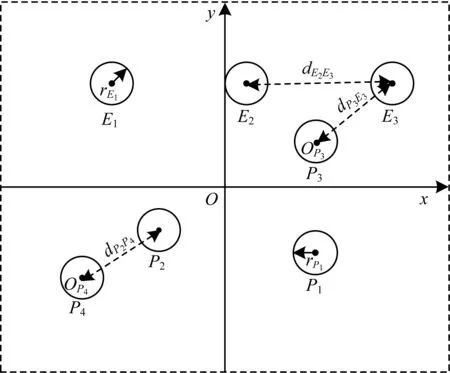
图1 多智能体追踪示意图
1.2 多目标追踪方法框架
多目标追踪方法主要包括环境建模、任务分配和追踪策略学习3个方面,具体框架如图2所示。先对追踪智能体、目标智能体、障碍数量及位置等环境信息进行建模,将追踪智能体、目标智能体作为多智能体多目标任务分配算法的输入,经过计算得到各个智能体的任务分配结果。根据各个智能体的任务分配结果和环境信息,对其进行奖励函数设置。在每一个时间步长中,各个智能体根据观察到的环境信息采取相应行动作用于环境,使得环境的状态发生变化,同时通过奖励函数从环境中获得奖励反馈并进行学习更新策略,然后多个智能体根据观察新的环境状态采取行动从中获得奖励再进行学习。重复上述过程,通过不断优化决策并更新策略库得到最优策略或较优策略。
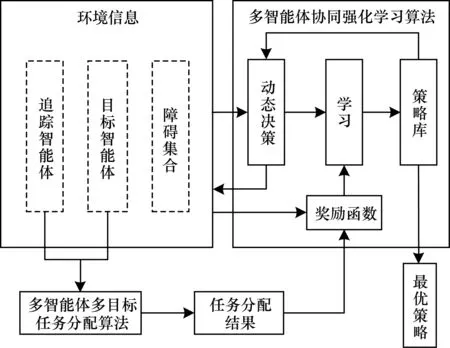
图2 多目标追踪方法框架
2 基于多智能体协同强化学习的多目标追踪
2.1 多智能体多目标任务分配算法
在多智能体多目标追踪问题中,多个智能体需要通过协调与协作完成对多个运动目标的追踪任务。本文假设多个智能体之间能够进行交流与通信,同时可获取各个运动目标的位置,以缩短目标智能体的总追踪路径为优化目标,根据参与任务的智能体数目与运动目标数目建立以下任务分配模型:
1)当追踪智能体数目与目标智能体数目相同时,即np=ne,其数学模型为:
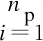
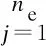
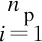
xPiEj=0或1,i=1,2…,np,j=1,2,…,ne
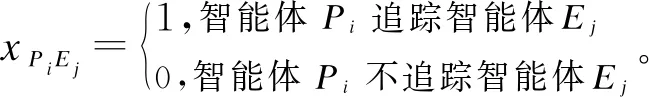
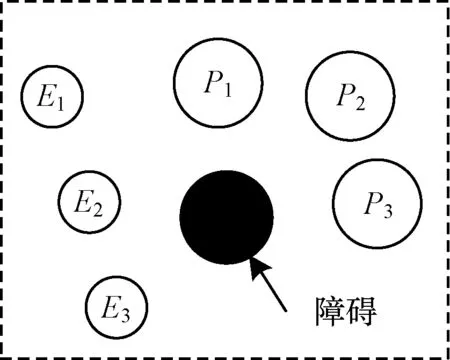
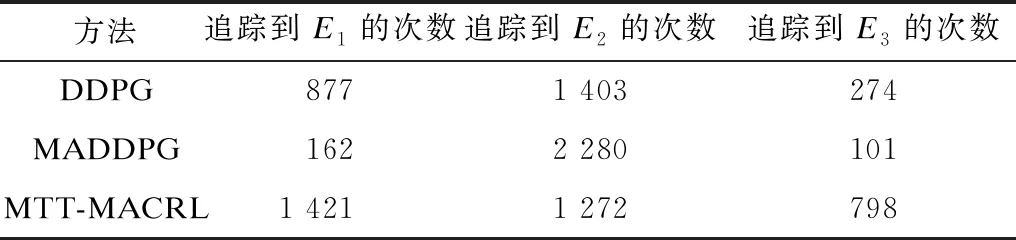
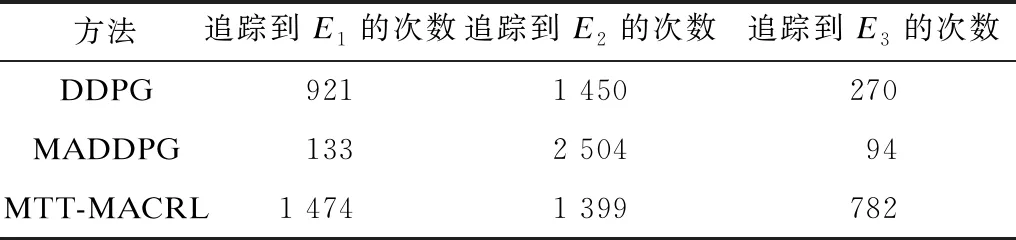
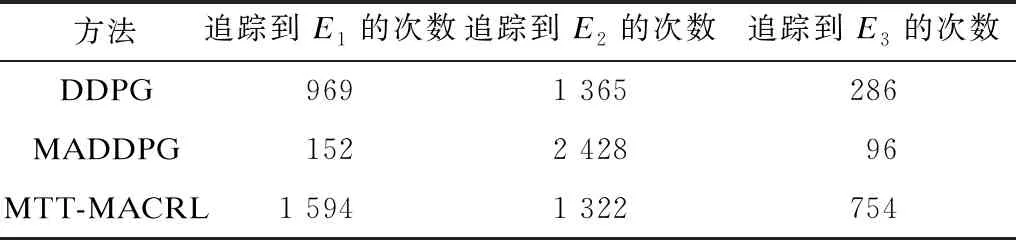
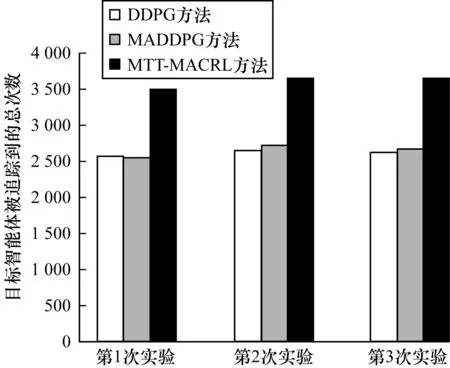
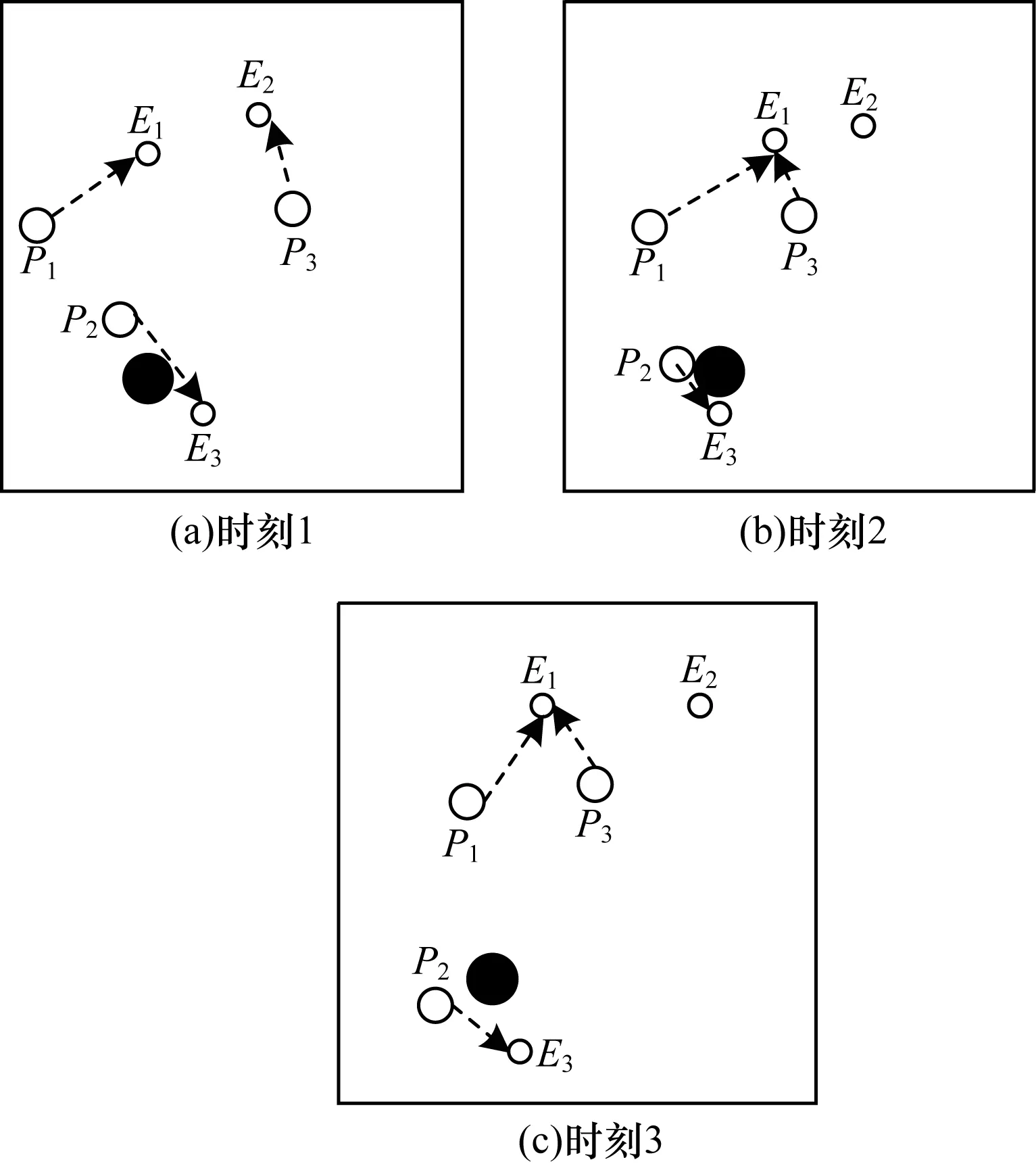
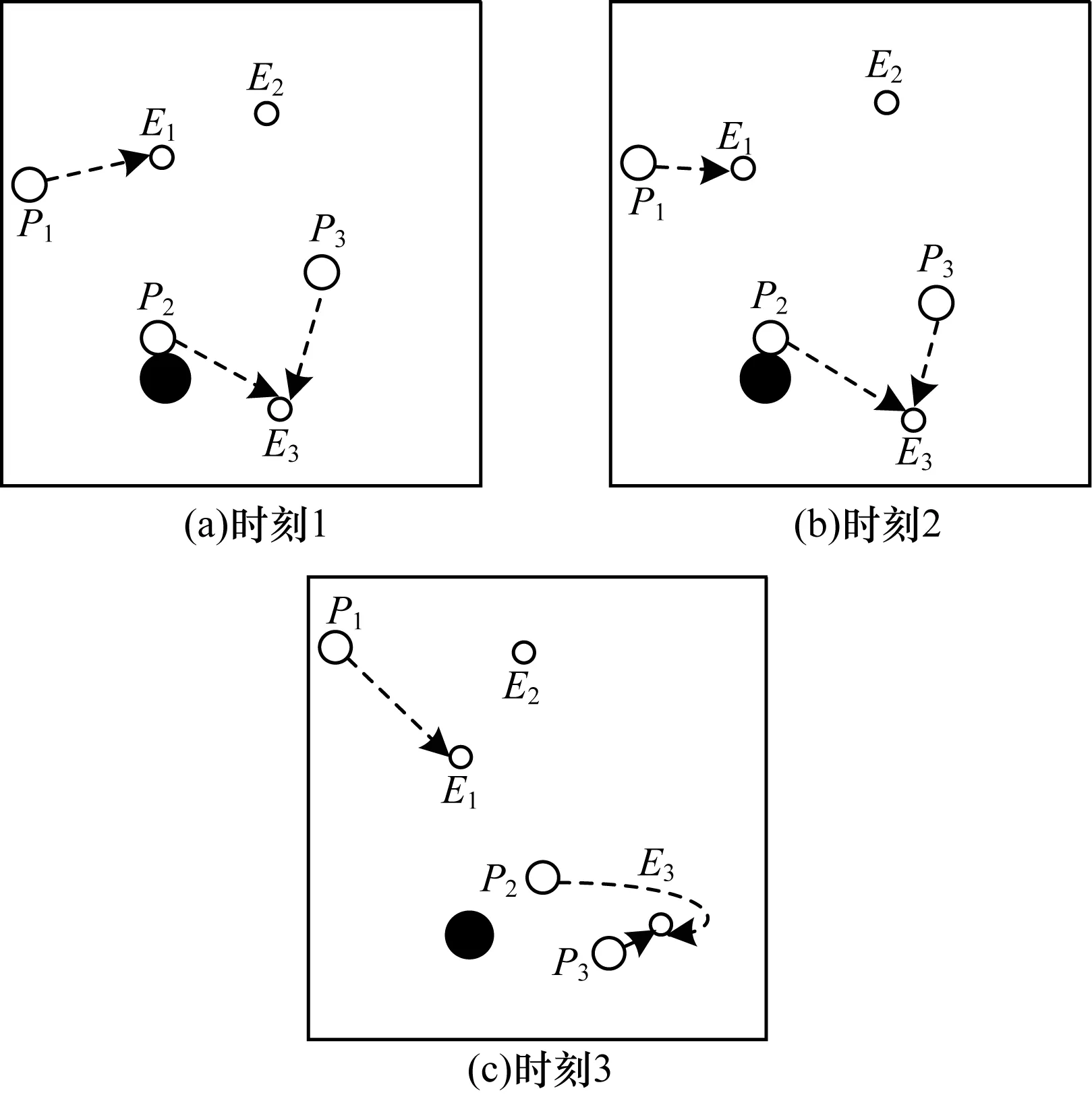
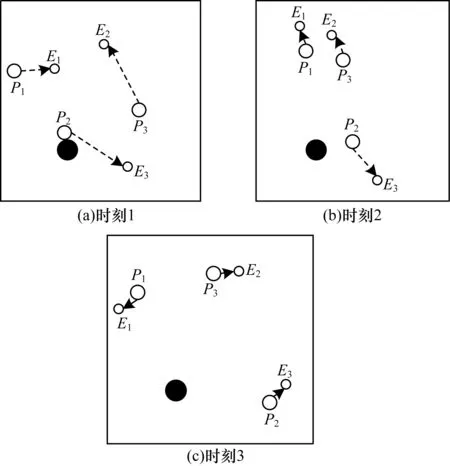
2)当追踪智能体数目小于目标智能体数目时,即np xPiEj=0或1,i=1,2…,np,j=1,2,…,ne 3)当追踪智能体数目大于目标智能体数目时,即np>ne,其数学模型为: xPiEj=0或1,i=1,2…,np,j=1,2,…,ne 多智能体多目标任务分配算法具体步骤如下: 步骤1初始化追踪智能体数目np、各个追踪智能体的位置Xp(t0)、目标智能体数目ne以及各个目标智能体的位置Xe(t0)。 步骤2依次计算追踪智能体与每个目标智能体之间的距离dPiEj组成距离效益矩阵D,计算公式为: 步骤3当追踪智能体数目np等于目标智能体数目ne时转步骤4;当追踪智能体数目np小于目标智能体数目ne时转步骤5;当追踪智能体数目np大于目标智能体数目ne时转步骤6。 步骤4运用匈牙利算法根据距离效益矩阵D对多个智能体的任务分配模型进行求解,转步骤7。 步骤5虚拟增加(ne-np)个追踪智能体,采用加边补零法将该非标准指派问题转化为标准指派问题,并利用匈牙利算法对多个智能体的任务分配模型进行求解,转步骤7。 步骤6虚拟增加(np-ne)个目标智能体,采用加边补零法将该非标准指派问题转化为标准指派问题,并利用匈牙利算法对多个智能体的任务分配模型求解,转步骤7。 步骤7输出多个追踪智能体的任务分配结果,算法结束。 2.2.1 状态和动作设置 在多智能体追踪问题中,每个智能体的行为都会导致环境状态的改变进而影响其他智能体的行动。多个智能体之间存在合作关系或竞争关系,每个智能体所获得的回报不仅与自身动作有关,而且与其他智能体的动作有关[18-20]。 在本文二维平面空间的多目标追踪问题中,任意时刻的状态可以表示为s={X,V},其中,X表示各个智能体的初始位置及障碍等的位置信息,V表示各个智能体的运动速度。智能体的动作空间为智能体在二维平面空间(x,y)中任意方向移动的距离。 2.2.2 奖励函数设置 本文采用多智能体多目标任务分配算法和多智能体协同强化学习算法进行多目标追踪,其核心工作包括:1)根据环境中各个追踪智能体以及目标智能体的位置信息,运用多智能体多目标任务分配算法确定多个智能体的任务分配结果;2)根据不同智能体的任务分配结果以及环境中的其他信息(如障碍位置、环境边界等)设计相应的学习模型,多个智能体与仿真环境交互并将其经验数据存储至样本池中,然后从样本池中随机取出一定数量的样本进行学习同时更新策略。在多个智能体的学习任务中,所有智能体的策略由参数θ={θ1,θ2,…,θn}确定,其策略集合π={π1,π2,…,πn},则单智能体i的期望收益梯度为: (1) (2) (3) 其中: (4) 多目标追踪的具体步骤如下: 1)参数初始化,设置环境的范围边界及追踪智能体、目标智能体及障碍的数量、位置、速度等信息以及样本池M的容量K和总训练回合数N。 2)根据任务目标设置智能体的奖励函数和动作空间。 3)设置初始训练回合数Episode=0、最小取样样本数Ns和已存储样本池数量Nb。 4)判断训练回合数Episode是否小于N,如果是,则执行下一步;否则算法结束。 5)根据当前状态st,每个智能体遵循当前策略选择动作ai。 6)执行动作a=(a1,a2,…),各个智能体得到奖励值ri,同时达到新的状态st+1。 7)存储(st,a,r,st+1)至样本池M,Nb←Nb+1。 8)判断Ns是否小于Nb,若是,则跳转至步骤11;否则执行步骤9。 9)对于每个智能体而言,随机从样本池M中取Ns个样本,根据式(4)计算yj,并利用式(2)和式(3)分别更新actor网络和critic网络。 10)更新目标网络。 11)赋值更新st←st+1,训练回合数Episode←Episode+1,返回步骤4。 为验证本文MTT-MACRL方法的可行性和有效性,在同一实验环境下将本文MTT-MACRL方法与DDPG方法[14]和MADDPG方法[21]进行对比。实验场景设置如图3所示,实验环境为连续的二维平面空间,其中存在3个追踪智能体、3个目标智能体和1个障碍,在同一离散时间内3个追踪智能体与3个目标智能体同时运动,由于目标智能体被限制在该环境中,因此追踪智能体可以追踪到目标智能体。在上述实验场景中的参数设置如表1所示。 图3 实验场景 表1 参数设置 3.2.1 学习速度和实时性对比 在多智能体追踪问题中,追踪智能体主要学习如何快速接近目标智能体以完成对多个目标智能体的追踪任务。图4为10 000个训练回合中,DDPG方法[14]、MADDPG方法[21]以及本文MTT-MACRL方法的目标智能体在平均每100个训练回合中被追踪到的总次数与训练回合数的关系。 图4 目标智能体被追踪到的总次数 可以看出,在10 000个训练回合中,本文MTT-MACRL方法平均每100个训练回合成功追踪到目标智能体的总次数为239次,DDPG方法和MADDPG方法平均每100个训练回合成功追踪到目标智能体的总次数分别为158次、153次。当平均每100个训练回合成功追踪到目标智能体的总次数达到145次时,运用本文MTT-MACRL方法、DDPG方法和MADDPG方法至少分别需要进行2 500个、8 000个和7 600个训练回合。综上所述,本文MTT-MACRL方法相比其他两种方法,学习速度更快,能够根据智能体的位置快速执行有效策略,且实时性更好。 3.2.2 有效性验证 为验证本文MTT-MACRL方法的有效性,将其与DDPG方法和MADDPG方法的学习策略分别在上述场景中进行3次实验。在每次实验中,追踪智能体和目标智能体的位置为随机生成,每个训练回合的最大时间步长为50步,共进行1 000个回合的测试,并统计3次实验中每个目标智能体被追踪到的次数以及所有目标智能体被追踪到的总次数,具体情况如表2~表4所示。 表2 第1次实验中追踪到目标智能体的总次数 表3 第2次实验中追踪到目标智能体的总次数 表4 第3次实验中追踪到目标智能体的总次数 在3次实验中,采用DDPG方法、MADDPG方法以及本文MTT-MACRL方法得到目标智能体被追踪到的总次数如图5所示。可以得出,利用DDPG方法、MADDPG方法和本文MTT-MACRL方法平均每次实验追踪到目标智能体的总次数分别为2 605次、2 650次和3 605次。本文MTT-MACRL方法对于目标智能体的成功追踪次数相比DDPG方法和MADDPG方法分别提高了38.39%和36.04%。 图5 3次实验中目标智能体被追踪到的总次数 3.2.3 协同情况对比 通过DDPG方法和MADDPG方法得到不同时刻追踪智能体及目标智能体的位置分布情况,如图6和图7所示。可以看出,多个追踪智能体未进行相互合作且出现了多个目标智能体同时追踪同一个目标智能体的情况,因此造成某一个目标智能体无智能体追踪,不能快速有效地完成追踪任务。 图6 DDPG方法在不同时刻的智能体位置分布情况 图7 MADDPG方法在不同时刻的智能体位置分布情况 通过本文MTT-MACRL方法得到不同时刻追踪智能体及目标智能体的位置分布情况,如图8所示。可以看出,多个追踪智能体经过学习训练能够与其他智能体相互协作进行任务分配,保证一个追踪智能体对应一个目标智能体。同时,根据追踪智能体与目标智能体的位置信息能够实时更新任务分配情况,保证参与追踪任务的智能体的总追踪路径最短。 图8 MTT-MACRL方法在不同时刻的智能体位置分布情况 本文提出一种基于多智能体协同强化学习的多目标追踪方法。根据追踪和目标智能体数目及其位置信息建立任务分配模型,运用匈牙利算法对其进行求解得到多个追踪智能体的任务分配情况,并结合环境信息为多个追踪智能体设置奖励函数,同时通过多智能体协同强化学习算法使其在复杂环境中不断重复执行探索-积累-学习-决策过程,最终从经验数据中学习决策策略完成多目标追踪任务。实验结果表明,与DDPG方法和MADDPG方法相比,本文方法的学习速度更快,且多个智能体通过相互协作能更有效地追踪目标智能体。2.2 多智能体协同强化学习算法
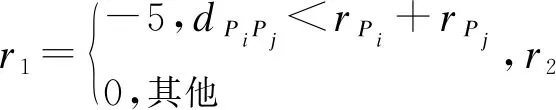
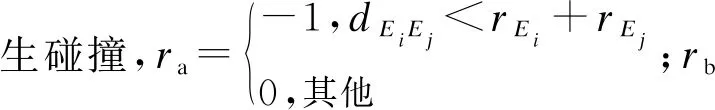
2.3 多目标追踪方法
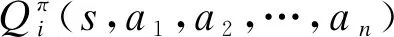
3 实验结果与分析
3.1 实验设置

3.2 结果分析

4 结束语
