基于Hadoop平台电力数据服务匹配查询性能研究
2020-11-14滕爱国单新文王鹏飞陶晔波顾玉皎
滕爱国,单新文,王鹏飞,陶晔波,闾 龙,顾玉皎
(国网江苏省电力有限公司,江苏 南京 210016)
0 引 言
随着电力信息化的推进和智能变电站、智能电表、实时监测系统、现场移动检修系统、测控一体化系统以及一大批服务于各个专业的信息管理系统的建设和应用,电力系统的数据的规模和种类快速增长,这些数据共同构成了智能电力大数据[1]。这些电力系统大数据不仅包括电力设备的运行状态参数数据,也包含了电力设备台账、电力系统周边气象环境、设备所处于的地理信息等相关数据。由于电力系统大数据的数据量大、涉及的结构类型多、数据增长快的特征,传统的大数据存储技术已经无法适应电力系统大数据环境下的存储查询需求,目前国内外研究者主要是基于Hadoop 平台的分布式文件系统为海量数据提供服务匹配查询[2-7]。当前不少研究是将语义网思想引入大数据处理能力的云计算Hadoop技术[8-9],其主要针对Hadoop平台的RDF数据存储和服务匹配查询方法。RDF是用于语义Web数据管理的定向标记图和数据模型,RDF的每个语句都将主语,谓语和宾语表示为三元组,表示用于创建SPARQL查询。创建SPARQL查询语言并与URI匹配并生成新的RDF图,对于新的RDF图,将创建SPARQL查询并执行MapReduce作业描述逻辑[10-13]。此外部分研究首先通过定义相关概念来表示应用程序域的知识域,然后使用概念来指定域中发生的对象和个体的属性[13-16]。为了减少存储在HDFS(Hadoop分布式文件系统)中的电力数据集,当前主要研究使用了MapReduce框架[17-19]。部分研究是通过资源描述框架(RDF)存储和表示数据的有效模型,其使用RDF框架将结构化数据转换为机器可读形式[20-22]。但是由于电力市场数据数据结构复杂、种类繁多,除传统的结构化数据外,还包含大量的半结构化、非结构化数据,如服务系统的语音数据,检测数据中的波形数据、直升机巡检中拍摄的图像数据等。提取用户输入的准确信息是电力大数据中信息匹配检索系统的主要缺点和难点。
为了克服匹配问题,文中基于描述逻辑提出一种匹配模型,该模型的描述逻辑包括TBox和ABox,其模型将个体和普遍分开量化。该模型可以匹配用户输入本体数据库,并能正式化电力信息域作为类和实例。DL结构化数据和非结构化信息格式通过Hadoop处理以获得最佳格式匹配服务平台,SPARQL查询用于查询存储在Mongodb中的数据进行匹配处理查询。文中提出的匹配系统在查询响应时间方面有所改进,在迭代时间上大幅度降低。
1 Hadoop和MapReduce
为了有效地处理和存储大量RDF数据,文中使用了Hadoop框架。Hadoop[12]是一个开源实现,支持跨商品服务器集群分布式处理大型数据集。它能够连接和协调集群内的数千个节点。Hadoop框架有两个组件,如HDFS[6]和MapReduce[13]。Hadoop平台生态系统包括两部分:分布式存储和并行计算机。Hadoop系统平台主要使用名字节点作为分布存储的主控节点,其目的用名字节点来存储和管理分布式文件系统的元数据。Hadoop系统使用数字节点作为实际存储大规模数据的从属节点,每个从属节点存储实际的电力大数据。在并行分布计算架构上,Hadoop系统使用JobTracker作为MapReduce的并行计算框架主控节点,其目的用来管理、调度作业的执行。MapReduce的并行计算框架是基于HDFS之上建立的,其框架包含一个JobTracker和若干TaskTracker。
为了提高大数据处理的效率,Hadoop系统首先让每个TaskTracker处理存储在本地数字节点的数据。MapReduce是Hadoop平台的最核心的组件之一。MapReduce技术是采用对数据“分而治之”的策略实现并行化处理。每一个Map的任务根据不同的键值对产生新的键值对,然后将这些新产生的键值对传递给Reduce,之后再由每个Reduce根据所提出的需求分别执行相应的任务,最后,Hadoop系统汇总所有Reduce任务的数据结果。Hadoop平台的主控节点主要负责作业的调度和处理,同时将任务进行分割和分配从属节点,和重新启动已经失败的任务等各种工作。从属节点与数据节点一般都是配置在同一个节点上,其主要目的是负责执行JobTracker分发下来的任务和管理各自节点上的任务,并与JobTracker进行交互通信。任务一般分为Map Task和Reduce,且由TaskTracker启动。JobTracker与TaskTracker是通过心跳进行实际通信的。
使用DataNode创建并与NameNode匹配的SPARQL查询,并生成RDF图。为RDF图创建SPARQL查询语言,并从HDFS中检索数据。Gapstetep有两个节点,如主节点和工作节点[5]。主节点拆分数据并分配数据keyvalue对。主节点选择空闲工作器并为每个工作服务器分配一个映射任务以设置HDFS专为数据存储而设计,MapReduce用于数据处理。MapReduce用于执行SPARQL查询并在大量节点上提供并行处理以简化数据[11]。将密钥值对发送回主节点。主节点存储有关数据位置的详细信息。Reduce函数采用中间键值对,并缩减为较小的解。基于较小的解决方案,再次创建SPARQL查询语言[15-16]。
2 基于描述逻辑服务匹配架构模型
本体是通过概念之间的交互关系来进行描述概念的一种语义,也是一种能够有效表达概念层次结构和语义的模型。 目前本体模型广泛应用于计算机科学的各个领域。最近几年国内外主要流行的本体语言有很多种,但是每种流行的本体语言各有其不同特点,在这些流行的本体语言中以W3C最为代表性。目前OWL是W3C的最新标准。OWL语言主要分为三个子语言,分别是OWL-Lite、OWL-DL和OWL-Full。其中OWL-DL是基于DL的语言,OWL-DL不同可以用来自动推理,而且也可以用来判别本体中的分类层次和概念的一致性,其表达能力最为丰富。
文中基于描述逻辑提出一种服务匹配架构模型,如图1所示。该架构包括用于存储和查询RDF数据的几个组件。描述逻辑基于RDF框架的格式将结构化数据转换为DL。处理结果通过Hadoop组件生成SPARQL查询语言,查询语言与Mongodb匹配输出处理结果。在该体系模型结构中,转换用户输入非结构化的数据是通过匹配用户输入来构造本体数据库并将信息形式转化为类。用户输入通过匹配转换为结构格式用户输入,并以本体数据库形式化信息作为类和实例。模型中的说明语言转换器使用TBox和ABox来描述概念定义,包含和断言。OWL DL公理是基于RDF框架来形式化数据,同时基于Hadoop框架存储和查询RDF数据。
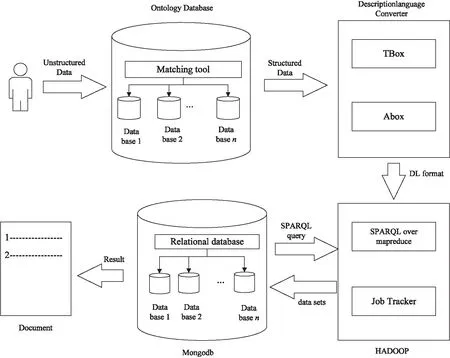
图1 基于描述逻辑的服务匹配模型架构
通常描述逻辑表示知识库主要是由TBox和ABox两部分组成。其中TBox主要定义了特定知识领域的结构和包含一系列公理,包括通过已有概念构成新的概念。而ABox则主要包含TBox中概念的实例。一般来说TBox具有分类的能力,而ABox主要是将与TBox中的类相对应的实例写入,其所建立的实例必须符合TBox中类设计的限制和属性。一般来说这些类的实体称为实例,主要因为这些实例能够将原来只具有概念的架构,组合成具体实体知识关系的架构。其中TBox可以描述领域结构的公理的集合引入概念的名称,例如表示类(一元谓词){x|Byaqi(x)}。此外TBox还可以声明包含关系的公理(属性,二元谓词){
HBase平台是采用与传统关系数据库类似的表概念来表达,在HBase中HTable行键是行的唯一标志符,HBase数据库对行键提供与B+树类似的高效索引[14]。由于三元组所表达的三个成分的谓词数量比较少,如果在实现过程中不进行切分,容易导致以谓词作为HTable的行键的表过宽,最终导致列名和值进行匹配耗时,从而影响HBase数据库的查询效率。因此在实际实现中将每个谓词对应两张HTable,这样以谓词的三元组主语/宾语作为行键,另外的一成分为列名。这样做的好处是,对固定的三元组谓词进行查询的时候,能快速匹配出结果,但对于谓词不固定的三元组,不得不需要遍历所有的数据表,导致匹配的速度变慢。为了解决这个问题,文中在上述基础上增加 CP_O、PO_C和OC_P三张索引表,目的是加速响应不固定的三元组谓词匹配,从而达到快速匹配效果。谓词表行的结构采用如下表达方式。
Row Key:主体1 {
Column变压器 {
Column:客体1
Column:客体2
Column:客体3
…
}
}
文中在CP_O表行结构中采用如下形式表达,即把主语和谓词的有序对作为行键对。其中PO_C和OC_P的表结构与CP_O类似。
Row Key:(主体1,Predicate1) {
Column变压器 {
Column:客体1
Column:客体2
Column:客体3
…
}
}
3 实 验
3.1 实验环境和实验设置
采用Hadoop2.6和HBase2.0版本在五台PC机(Intel酷睿核CPU,内存8 GB)上进行实验,将Hadoop作为运行平台,HBase用来存储RDF数据。实验基于电力网地理数据集。生成了地理数据集,并将RDW模型中的本体类型以OWL格式表示。收集了9个RDF类和14个属性,收集数据集的RDF三元组以表示OWL-DL格式。来自用户的查询用OWL表示以找到语义关系。出于实验的目的,使用SPARQL查询语言。这是因为实验测试了使用本体匹配为查询提取准确信息的性能。用于评估的示例查询显示如表1所示。
表1中,电力地理数据集拆分大小可提高使用复制模型的Hadoop性能。SPARQL查询的大量三元组作为文件存储在HDFS中,并且使用了更多的空间。实验基于信息检索(IR)的语义搜索。在搜索引擎中,IR基于关键字并返回不太相关的文档。提出的搜索方法是使用本体匹配技术和MapReduce来开发信息检索的有效查询。该模型通过应用MapReduce,本体模型基于语义相似性给出相关的RDF数据集。可以在特定的reducer中加入相关的RDF数据集,因此,在搜索引擎中准确地检索相关信息以用于用户输入。三个查询分别作用在三元组250 K,1 M,5 M,及其相对应的RDF数据37 M,158 M,782 M。文档分别是11,43,202,每个文档的行数是25 000。

表1 查询集
上述最佳分割尺寸地理数据集,以减少文本数据的大小。第一列表示查询,第二列表示三元组的集合。作为三倍数大小增加RDF数据大小,文档和行每个文档的大小也会增加。三倍大小为250 K,1 M和5 M,提供了25 000英寸的一致结果。观察到文件的分割大小减少了响应查询的时间。
3.2 实验结果与分析
实验基于语义搜索信息检索(IR)。在搜索引擎中,IR基于关键字和返回不太相关的文件。该模型的搜索方法是使用本体匹配技术和MapReduce开发高效查询信息检索。通过应用MapReduce,本体模型给出了基于语义相似性的相关RDF数据集。可以加入相关的RDF数据集在特定的减速机中,因此,相关信息是在搜索引擎中准确检索用户输入。
3.2.1 查询处理的迭代时间
为电力地理数据集生成了SPARQL查询,并以秒为单位计算了迭代时间。在图2~图4中,X轴表示数据格式,Y轴表示以秒为单位的迭代时间。对于X轴,有四列分别显示非结构化数据格式,OWL格式,OWL-DL和OWL-DL与Hadoop实现的结果。实验中,OWL和OWL-DL计算迭代时间基于SPARQL查询中的三元组数。在图2中,非结构化数据格式的后续迭代需要9.3秒,而使用Hadoop的OWL-DL需要0.5秒。图2和图3中的结果表明,非结构化数据格式提供了最差的迭代时间,而使用Hadoop的OWL-DL提供了最佳的迭代时间。在图4中,查询大小增加,第1列中的后续迭代时间为591.5秒,第4列为123.4秒。观察到OWL-DL与Hadoop的性能在大型地理数据集中也很有效。查询Q4中的FILTER条件减少了图4中的迭代时间,并且提高了性能。因此,这些结果表明,带有Hadoop的OWL-DL为地理数据集提供了最佳的迭代时间。
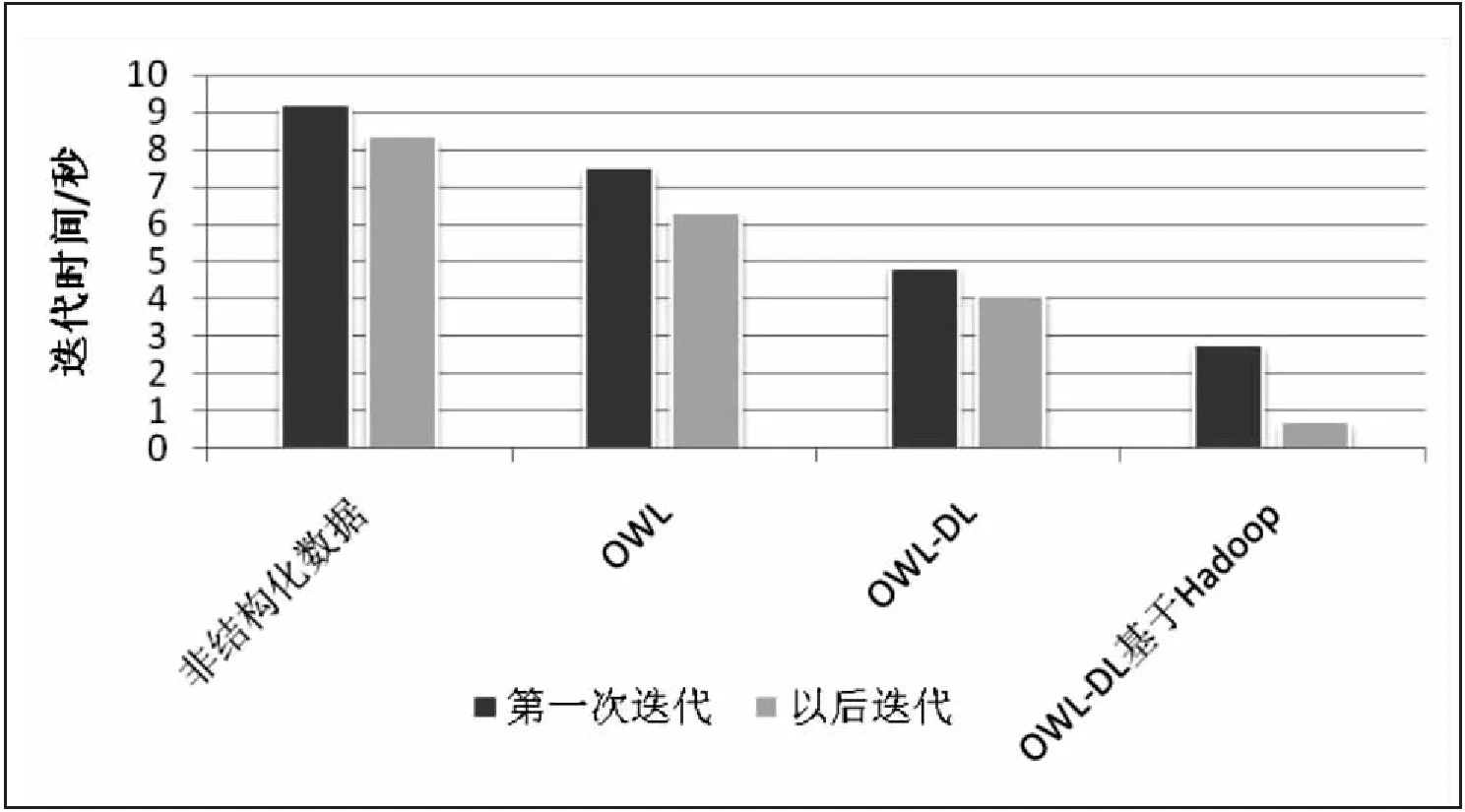
图2 第一个查询的迭代时间
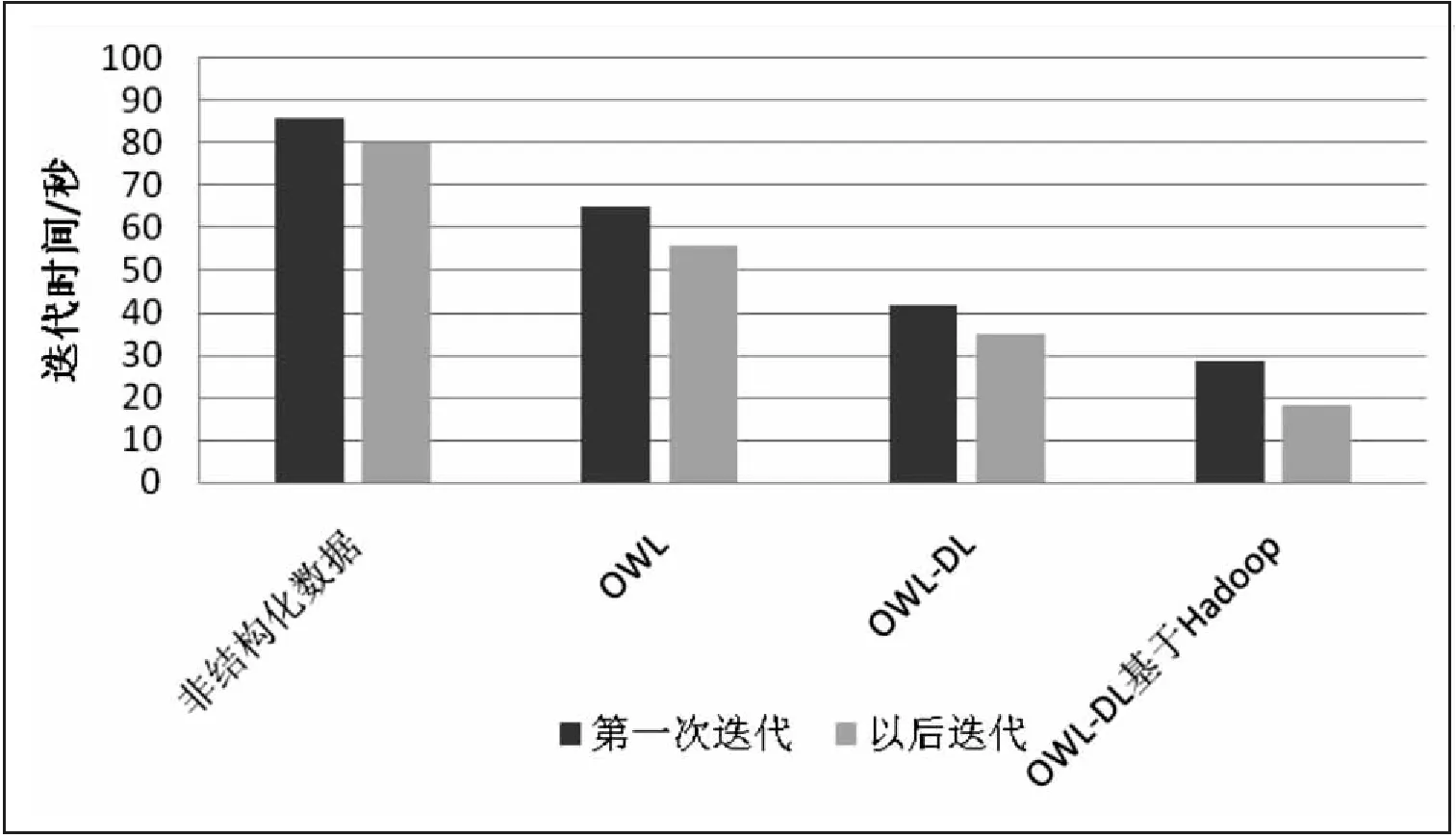
图3 第二个查询的迭代时间

图4 第三个查询的迭代时间
3.2.2 查询处理的响应时间
测量了电力地理数据集的不同SPARQL查询的响应时间。在图5~图7中,X轴表示数据格式,Y轴表示以秒为单位的响应时间。该实现显示了不同数据格式的性能比较,以秒为单位。MapReduce在OWL-DL中与Hadoop一起使用,以减少数据集并提供最佳响应时间。
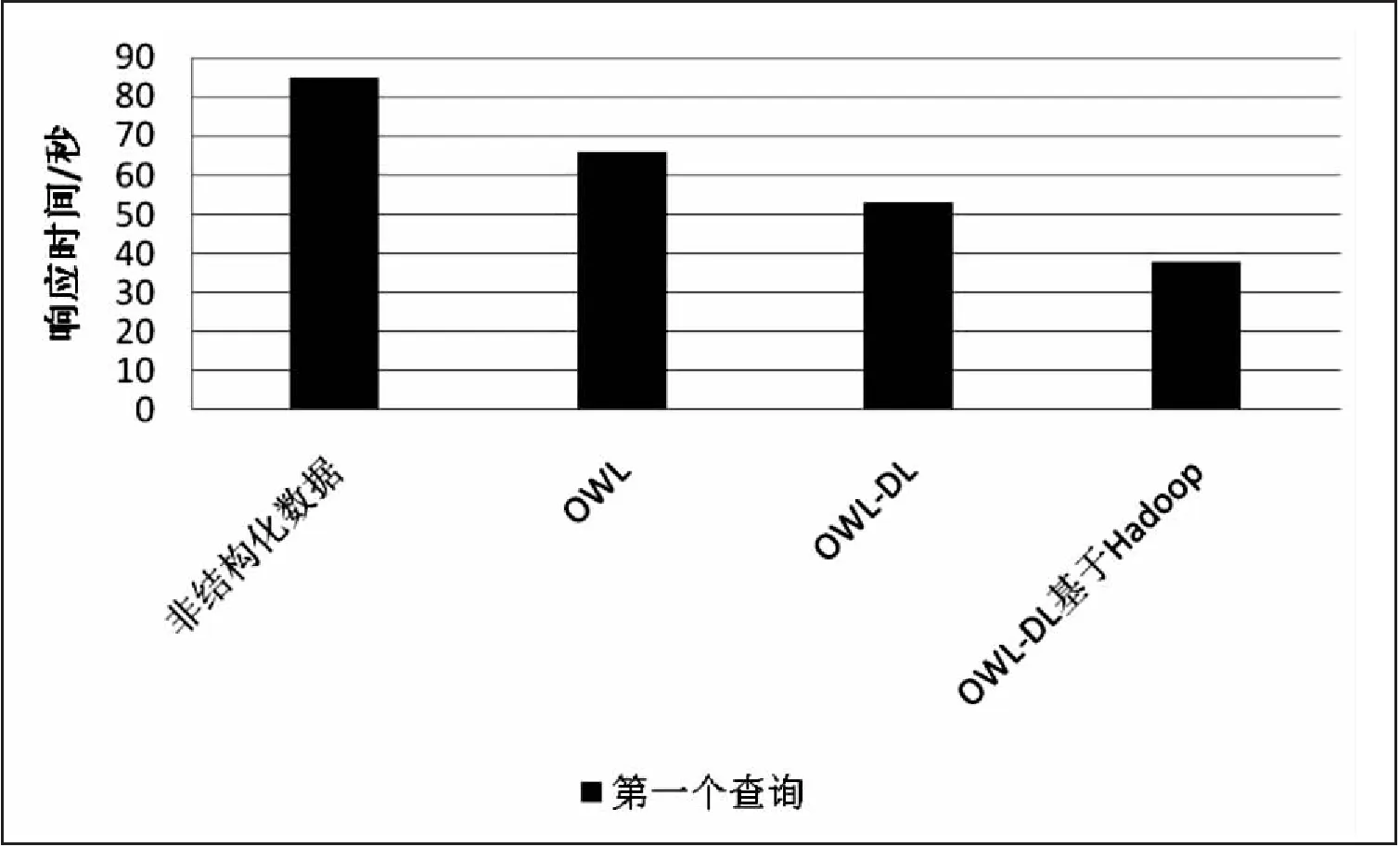
图5 第一个查询的响应时间
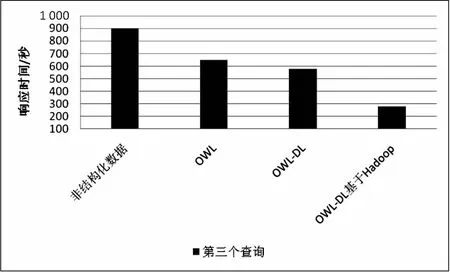
图7 第三个查询的响应时间
在图5中,非结构化数据格式需要80.3秒,而带有Hadoop的OWL-DL需要39.1秒。结果表明在使用Hadoop的OWL-DL中实现了有效的查询处理,并且与其他格式相比,响应时间较短。
图6、图7显示每个SPARQL查询的查询时间因线性大而增加,因为大型RDF数据集显示了使用Hadoop的OWL-DL中的最佳响应时间。观察到X轴的第一列显示最差响应时间,最后一列显示最佳响应时间。带有Hadoop的OWL-DL使用MapReduce并减少不需要的数据集。
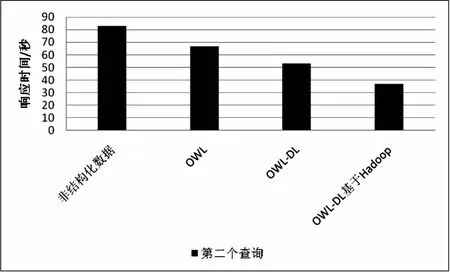
图6 第二个查询的响应时间
3.2.3 查询地理数据集的运行时间
电力地理数据集的查询运行时间基于三元组的数量计算。表2显示了从地理数据集收集的不同数量的三元组的查询时间。 第一列表示三元组的数量,范围在1 200万到6 000万之间。第2列到第6列表示来自表1的5个选定查询并计算运行时间。查询Q1很简单,120万次三重奏需要67.4秒,1 200万次传输需要242.8秒。由于查询大小的增加,查询Q5花了68.5秒到220.8秒。观察到三元组的数量增加了,回答查询的时间也增加了。
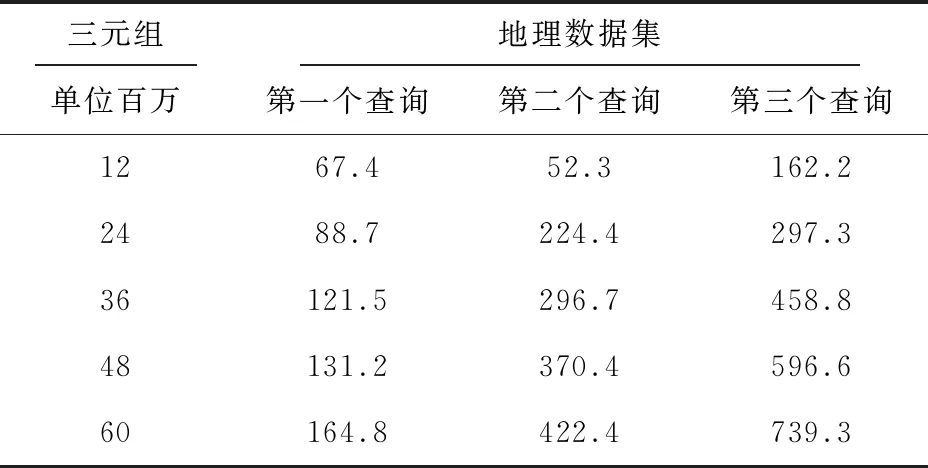
表2 地理数据集查询运行时间
4 结束语
针对电力大数据呈现的复杂性和异构性以及地理图数据在服务匹配查询中困难的问题,提出基于Hadoop平台电力数据服务匹配查询模型,该模型是基于TBox和ABox组件的描述逻辑。该模型采用描述逻辑使得MapReduce操作在执行Hadoop简化了查询和匹配过程,其查询DL结构化数据存储在Mongodb中。最后基于实际数据进行大量实验,结果证明了所提出的系统模型提供了最小的搜索时间和最佳的匹配准确度。下一步的工作包括扩展DL模式通过集成Hyperclique和Lattice模式进行匹配。
