基于开放环境下关联数据的偏好查询系统设计
2020-11-14赵羽晗
赵羽晗,胡 磊
(南京航空航天大学 计算机科学与技术学院,江苏 南京 211100)
0 引 言
如今关联数据的个性化偏好查询研究工作已经从各个角度展开[1-5],而且RDF也成为越来越多领域中产品的存储框架[6]。所以,开发一套相对完善的查询系统对这些数据进行快速准确的查询便成为首先要完成的任务[7]。
在实际操作中,普通用户对底层数据的存储方式与模型框架并不了解,中间的查询处理过程也是对用户透明的[8],而很多情况下他们又会想要在查询中表达自己的偏好,这就使最终结果集有了模糊性[9-11]。考虑到现有的对RDF数据进行查询的语言特性,文中以经典RDF查询语言SPARQL为基础,面向用户的个性化偏好处理,将SPARQL柔性扩展,设计并开发了一套关联数据个性化偏好查询系统。
1 SPARQL扩展
1.1 模糊术语表达
模糊术语即在表达意图时带有不确定信息的词语[12]。使用梯形隶属函数[13]来构造有序语言值的子域,即属于该子域的某个元素有隶属区间的上限值和下限值,在该隶属区间内有一个子区间隶属度为1。函数图形如图1所示。
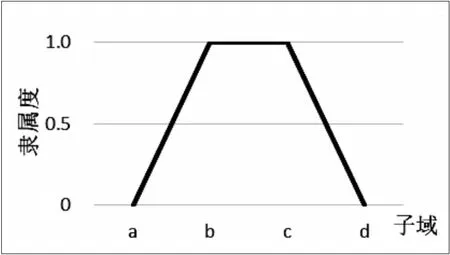
图1 梯形隶属函数图
在SPARQL查询语言中,允许模糊项存在的FILTER约束的基本形式是FILTER(?XθFT) [WITHα]。其中FT表示模糊项,例如“胖”或“最近”,与一个模糊数值所对应;θ是运算符之一,包括>,<,=,>=,<=,!=,between和not between。需要注意的是,如果操作符θ是between或not between,则FILTER约束的语法有一点不同,例如FILTER(?X between FT1 and FT2) [WITHα]。可选参数[WITHα]表示必须满足[0,1]中最小隶属度阈值的条件。用户选择适当的α值来表达条件所符合的程度。如果未指定,则默认使用1。
1.2 扩展SPARQL语法
经过扩展SPARQL后的模糊查询语言主要是对原有语法中的“Query”和“Constraint”元素进行了扩充,以及增加了“Preference”关键字。
(1)Query元素:每一个以“SELECT”指定的查询中,都使用元素QueryType对其进行扩展,它用来表示此查询是不是模糊查询。可以根据是否使用k分为两种情况:一种是用#FQ#来表示此查询的形式为模糊查询,最终返回所有符合模糊查询条件的结果;另一种使用#top-k FQ# withk来表示此查询为模糊查询,最终返回前k个最符合用户指定偏好的结果。
(2)Constraint元素:通过附加的“Flexible Expression”元素进行扩展,此元素定义了模糊术语和模糊关系的约束,是一个模糊表达式的形式。经过扩展之后,它主要包括了“FuzzyTermExpression”、“FuzzyOperatorExpression”和“FuzzyRelationExpressio-n”,分别用来表示模糊词、模糊运算符和模糊关系的表达式。
(3)Preference元素:由于添加的“Preference”关键字是为了区别用户定义偏好的权重以便按最优顺序返回结果,所以它与“Order”关键字同被归于SolutionModifier元素中。它的语句构成中,AtomicPreference表示简单偏好,可以附带有序语言值。
1.3 查询重写
前文中介绍了允许模糊词存在的FILTER约束的基本形式是FILTER(?XθFT) [WITHα]。很明显,需要先确定语言值的子域,即隶属度区间,并根据上限值a和下限值b得到隶属函数对应的区间[a,b],则该模糊词的约束语句即表达为a≤F(u)≤b,F(u)是隶属函数。此时经过计算就可以得到隶属函数中变量u的取值范围[x,y]。于是可以得到如表1所示的重写规则。

表1 简单模糊词重写规则
复合模糊词由简单的模糊词或通过and、or、not等连接的修改的模糊词组成。当两个模糊词FT1和FT2以and连接时,可以先通过对每个模糊词计算隶属度区间,得到变量总取值范围为[a,b]∪[c,d],之后进行如表2所示的重写规则。

表2 复合模糊词重写规则
当两个模糊词以or连接时,分别计算其隶属度区间和,若交集不为空,则求其交集作为最终隶属度区间并按表2所示规则重写。
当模糊词进行了not操作,可以先对运算符进行取反,例如<变为≥,然后再按照表2所示规则重写。
2 系统设计与实现
2.1 系统框架
本次查询系统所依托的数据框架为当前应用比较广泛的Lehigh University Benchmark (LUBM)数据集[14]。此数据框架包含了20多个与高校相关联的本体资源,例如FullProffesor、GruaduateStudent、Publication、Course等;还有一些用来表达对象之间关系的属性,例如teacherof、worksfor、takecourse等。UBA是一个可以生成大量LUBM数据集的数据生成器[15]。本次查询系统的开发通过LUBM数据集生成器UBA1.7生成了包含2 400 k个三元组的数据集,以本体文件的形式存储,共约200 MB。
系统最主要的功能模块有以下五项:用户接口模块、偏好分析模块、查询重写模块、查询执行模块以及结果排序模块。
系统的整体框架如图2所示。
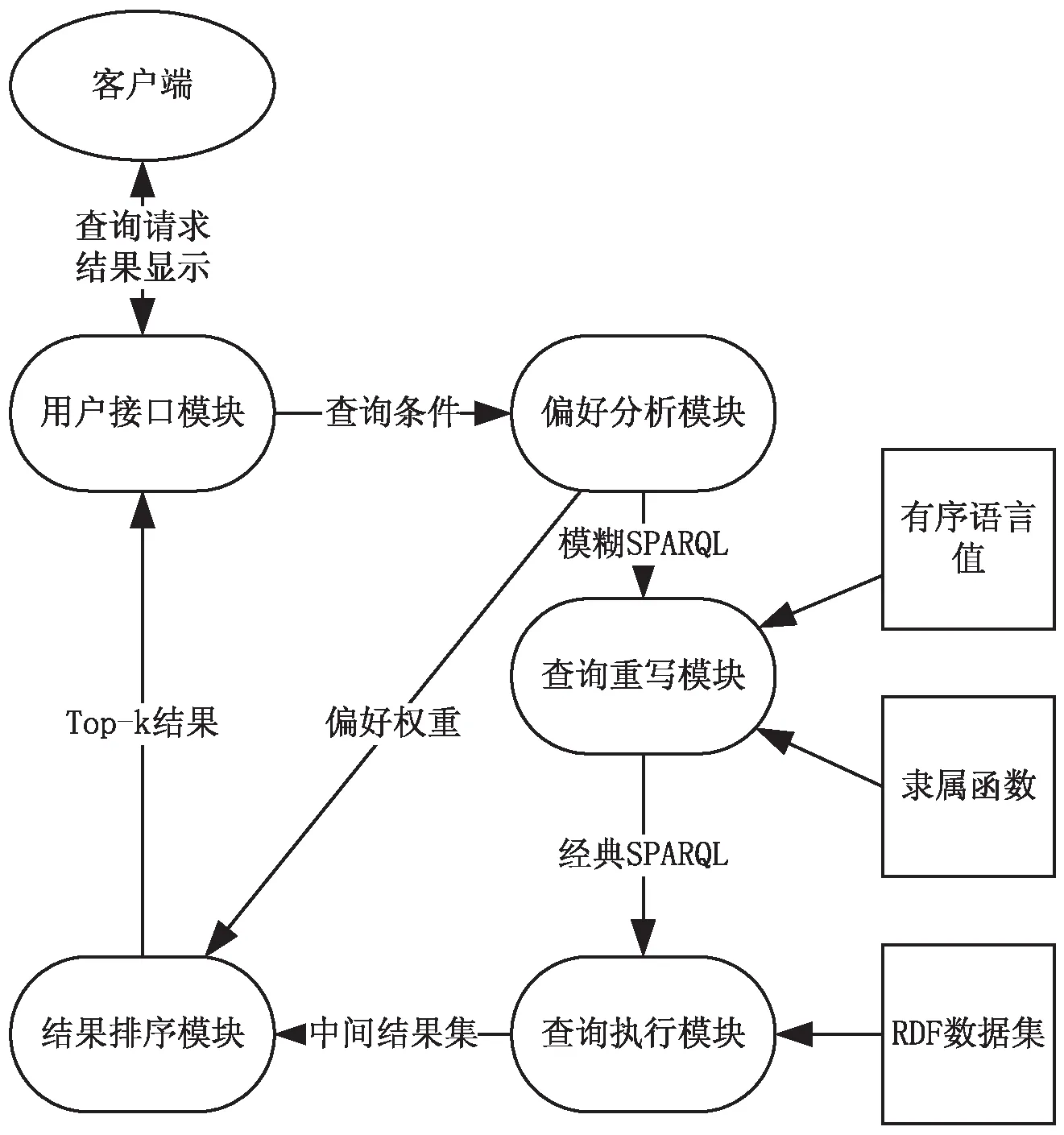
图2 系统整体框架
该框架完整表现了系统查询的整体运行过程。其中,查询重写模块需要根据不同条件属性的隶属函数以及有序语言值的子域来执行转换规则,经典SPARQL查询直接对存有RDF数据的本体文件执行查询,在结果排序模块也需要用到偏好分析模块中给出的用户偏好的权重以及条件的隶属度,最终结果显示在用户交互界面上。
2.2 系统功能模块
2.2.1 用户接口模块
用户接口模块的功能主要是以图形化交互界面为载体来体现的。在系统的界面中,用户选择自己的查询条件并设定偏好,然后将查询请求提交给系统后台进行分析处理,最终的查询结果也通过此模块显示在系统界面上。本次系统设计允许用户查询的目标为教师与学生。对于教师的查询,可选项为职位、工作状态、著作成就以及查询条件的优先级;对于学生的查询,可选项为学历、学习状态、发表的论文数以及查询条件的优先级。查询条件不能为空,当用户未选择查询条件时系统会弹框提示。
2.2.2 偏好分析模块
偏好分析模块的功能主要是将系统接收到的查询选项组合成模糊SPARQL查询语句,并提交给查询重写模块。
在上一小节中介绍了本次系统查询主要以数据集中的教师和学生作为目标。针对教师查询,有一个精确查询条件“职位”,以及两个模糊查询条件“工作状态”和“著作成就”。按照LUBM数据集的标准,在“职位”条件中提供了四个选项:教授、副教授、助理教授和讲师。在模糊查询条件中,有“条件描述”项以及针对该条件的符合程度可以选择,“工作状态”的条件描述项分别为“忙碌”和“清闲”,与该教师所教课程及所带学生数量有关;“著作成就”的条件描述项分别为“高”、“低”、“不高不低”、“接近十篇”、“多于十篇”、“不超过十篇”共六项,与该教师署名发表的论文数量有关。两个模糊条件的符合程度都分为“极其”、“非常”、“比较”、“有点”、“一般”五种,并且可以选择这两项模糊条件的优先级。
针对学生的查询中,也有一个精确的查询条件“学历”和两个模糊的查询条件“学习状态”和“论文发表”。“学历”选项中包括了“研究生”和“本科生”两项;“学习状态”中包括了“忙碌”和“清闲”两项,与该学生所选课程数量相关;“论文发表”包括了“高”、“低”、“不高不低”、“接近三篇”、“多于三篇”、“不超过三篇”共六项,与该学生署名发表的论文数量有关。和对“教师”的查询相同的是,这两个模糊条件的符合程度都分为“极其”、“非常”、“比较”、“有点”、“一般”五种,并且可以选择这两项模糊条件的优先级。
根据用户所选的上述条件中的具体选项,可以形成模糊SPARQL语句。每一项条件属性所对应的隶属函数以及符合程度所对应的有序语言值将在查询重写模块中讲述。
2.2.3 查询重写模块
在查询重写模块中,主要是将经过分析后的模糊SPARQL语句转换为可用现有工具执行的经典SPARQL查询语句。
上一小节中介绍了针对教师和学生的查询分别有两个模糊查询条件,而每个模糊条件又有具体的描述项以及符合程度项可以选择。针对教师查询的“工作状态”条件,定义“忙碌”与“清闲”的隶属函数分别如下:
其中,x表示该教师所教授的课程数量,y表示该教师所指导的学生数量。
对教师查询的“著作成就”条件,定义“高”、“低”和“不高不低”的隶属函数分别如下:
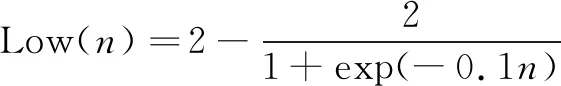
其中,n表示该教师所署名发表的论文数量。
2.2.4 查询执行模块
查询执行模块的主要功能是将重写后的经典SPARQL语句借助Jena ARQ引擎对目标RDF数据集进行查询。本次系统所查询的LUBM标准的RDF数据集由uba数据生成器随机生成,存储在本体文件中。查询产生的无序中间结果集将被送往结果排序模块产生最终符合用户偏好的k个结果。
2.2.5 结果排序模块
结果排序模块的主要功能是将查询执行模块产生的无序中间结果集进行Top-k排序,选出最符合用户偏好的k个结果。本次系统中,将k的值设为30,按照传统Top-k算法,分两步计算出每个结果的最终综合评分,并将所得30个结果返回给用户查询界面。
3 系统实现流程
本次所开发的关联数据个性化偏好查询系统的执行流程为:用户在交互界面中编辑查询条件及条件偏好,系统接收到用户提供的查询条件之后经过偏好分析得到模糊SPARQL语句,再根据查询重写的规则将模糊SPARQL语句转换为可执行的经典SPARQL语句,并在查询执行模块对目标RDF数据集进行查询,得到一个无序的中间结果集,然后结合偏好分析得出的隶属度以及偏好权重,对中间结果集进行Top-k查询操作,最终在用户界面呈现最满足偏好的k个结果。查询示例如图3所示。

图3 系统查询示例
4 结束语
随着语义Web的不断发展,互联网中的资源将越来越广泛地以关联数据RDF框架来表达和存储,所以针对RDF关联数据的检索是首先需要解决的问题[16]。文中将模糊查询条件中的信息大致分为模糊术语和模糊关系,根据其自然语言表达形式以及扩展的用户偏好权重表达,将经典SPARQL语言扩展为模糊SPARQL语言。文中还设计了一套转换规则,将模糊SPARQL语言重写为可被现有工具直接编译的经典SPARQL查询语言。通过对一系列子句的查询重写,得到了最终的查询语句并利用Jena ARQ引擎对目标RDF数据集进行查询。最后,对实现的关联数据个性化偏好查询系统并进行了可用性验证。结果表明,该系统是可用的,且能较好地在查询中体现用户个性化偏好。
