双目视觉的匹配算法综述
2020-11-13杨丽丽王振鹏
陈 炎,杨丽丽,王振鹏
(中国农业大学信息与电气工程学院,北京 100083)
立体视觉是机器认识世界的重要手段。利用2幅图像形成的视差可以计算得到像素点的深度,从而获得三维的立体感知[1-2]。其工作流程主要包含4步:双目标定、图像校正、立体匹配和三维重建,而立体匹配是关键的步骤[3]。
立体匹配算法可以实现2幅图像像素级的匹配,在该过程中,由于存在光照不均匀、遮挡、模糊以及噪声等的影响,给提升匹配精度带来了巨大的挑战[4]。在双目视觉的应用中,如自动驾驶、机器人等领域[5-6],需要具备实时、准确的深度估计,因此对于系统的处理速度和精度提出了很高的要求。在以往的综述性文章中[3,7-9],研究者们对基于人工特征算法的原理及性能进行了总结,近年出现了许多基于深度学习的优秀算法,其在实时性和准确性上都有很大的提升。为了给相关研究人员提供参考,本文讨论了各种立体匹配算法的发展,对基于深度学习和人工特征的算法特点加以分析,并给出了立体匹配算法的发展方向。
1 基于人工特征的匹配算法
立体匹配算法实现流程主要分为4步:代价计算、代价聚合、视差计算和视差求精[7],流程如图1所示。代价计算是对匹配区域像素点和参考区域进行相似度计算。由双目相机的成像原理可知,人们只需要计算处于同一水平线上的左右图像的像素相似值[10],这一要求基于对极约束[11]来实现。极约束在立体匹配中起重要作用,其将对应关系的搜索限制为一行而不是整个图像空间,从而减少了所需的时间和搜索范围。代价聚合阶段通过设置能量函数,将中心像素点的相似度值用某个范围内的像素点代价计算结果替代。常用的相似性评价方法包括绝对差之和(sum of absolute difference, SAD)、平方差之和(sum of squared differences, SSD)、归一化互相关(normalized cross correlation, NCC)、秩变换(rank transform, RT)和普查变换(census transform,CT)[9]。视差计算阶段,可选取参考区域内相似度最高的像素点来计算。视差求精的目的是减少错误匹配的像素点,优化视差图。优化步骤包括正则化和遮挡填充或插值[12]。

图1 立体匹配算法流程Fig. 1 The framework of stereo matching algorithm
按照代价函数约束范围的差别,立体匹配算法可分为全局匹配法和局部匹配法[8]。
1.1 全局立体匹配算法
全局匹配法的能量函数整合了图像中的所有像素,以尽可能多地获取全局信息。函数的表达式为
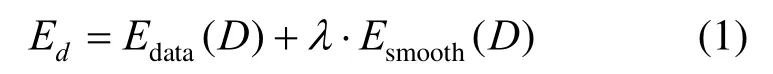
其中,Edata(D)为数据项,表示全部像素的匹配代价;Esmooth(D)为平滑项,表示相邻像素对视差值的一致性;λ为权值参数,取正值;Ed为全局能量函数。根据Ed优化方法的不同,全局匹配法又可分为动态规划法(dynamic programming, DP)、置信度传播法(belief propagation, BP)和图割法(graph cut, GC)[10]。
SUNG等[13]在求解Ed的过程中,应用极线间的相关性,构建了多路径自适应的动态规划求解方法。LI等[14]为了缓解动态规划法引起的横条纹效应,从左侧和右侧图像分别提取改进的SIFT算法描述作为特征点完成匹配,有效地减少了这一现象。LEUNG等[15]使用四叉树对动态规划进行快速迭代,提高了算法的运行速度。BLEYER和GELAUTZ[16]使用图割法,假设深度均匀变化,且深度变化边界与图像特征边界重合,在初始视差段聚集形成一组视差层,通过全局成本函数的最小化选取最佳视差层,在大规模无纹理区域取得了良好的匹配效果。LEMPITSKY等[17]设计了多重标记的马尔科夫随机域图形分割,提高了运行速度。WANG等[18]将图形分割后的点分为可靠和不可靠点,在遮挡和无纹理区域的不可靠区域,使用可靠区域的迭代信息进行优化,结果比经典图割法效率提高了90%。
1.2 局部立体匹配算法
局部匹配法将参考图像分为若干图像块,再求取匹配图像内预期相似度最高的图像块,生成深度图[19]。局部匹配法与全局匹配法相比,能量函数只有数据项,而没有平滑项,因此只能求取局部最优解[20]。算法原理如图2所示,随机选取左图像中m×n的待匹配图像块,搜索右图像视差(-d,d)的范围,选取相似度最大的区域作为匹配单元。
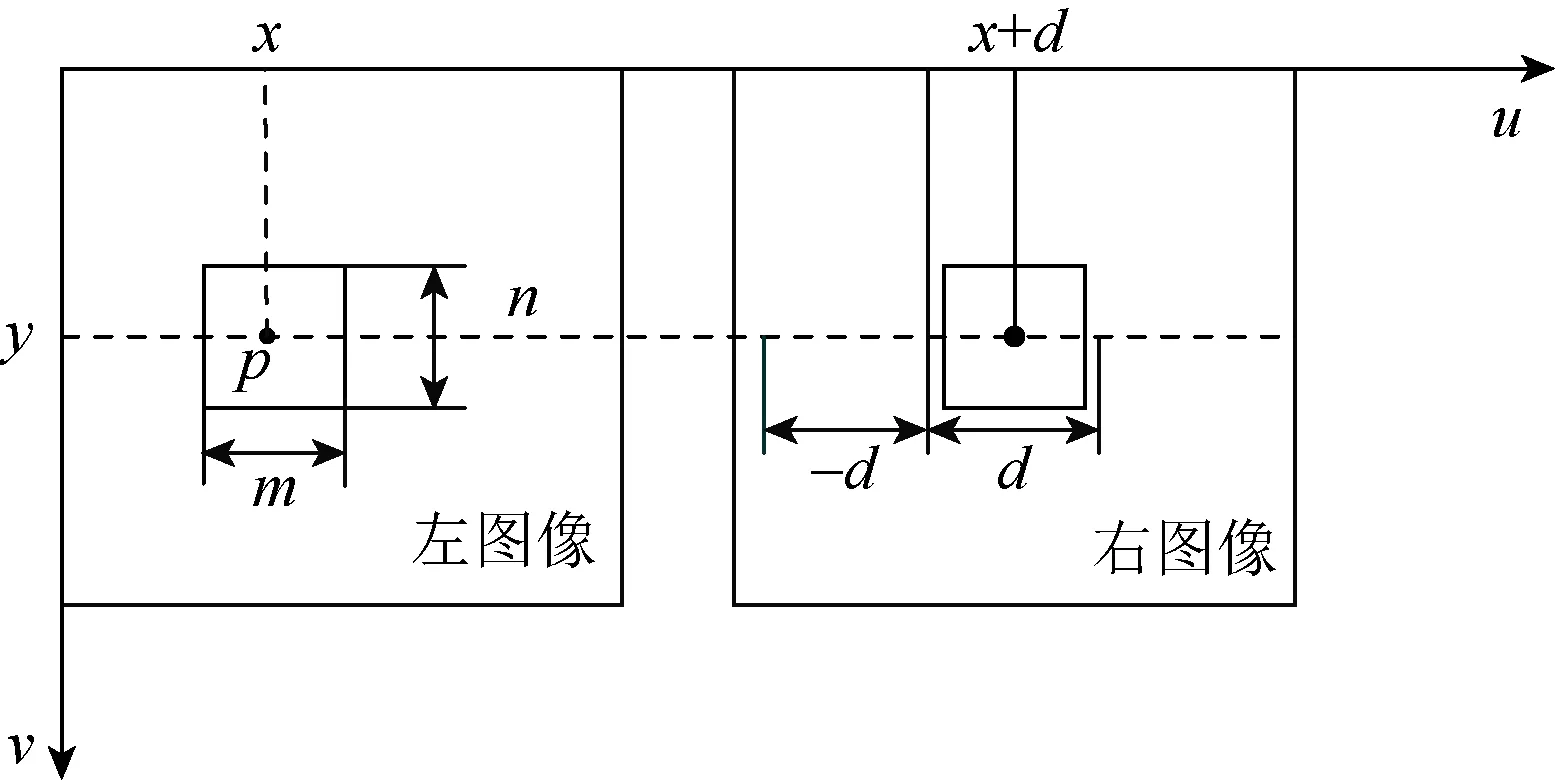
图2 局部立体匹配算法Fig. 2 Local stereo matching algorithm
局部匹配法带来了效率上的提升,但由于缺乏全局参数,生成的视差图不甚理想。为了提升匹配效果,在代价计算阶段可以使用更优的方法。HIRSCHMULLER[21]提出了半全局匹配方法,主要包含2点:一是基于互信息匹配的分层计算,二是使用一维最优求解全局能量函数,半全局匹配在保证算法运行效率的同时大大提升了匹配效果。WANG和ZHENG[22]在构建局部能量函数的过程中引入区域间的合作竞争机制,获得了良好的视差效果。HOSNI等[23]提出在局部匹配时采用分割算法选取待匹配区域,可以提升视差图的质量,在分割选取待匹配区域时,以距离中心像素的远近分配不同的权重,改善了分割效果。YOON等[24]针对各分割区域,提出了一个非线性的基于扩散的权重聚合方法,有效改善了遮挡区域匹配效果。ZHANG等[25]提出自适应匹配的概念,并开发了具有任意自适应形状的支撑区域,实现了很高的匹配精度。
局部匹配算法在提升效果的同时,不可避免的会带来效率上的降低。为此,DI等[26]在匹配中引入特征点选择,为了进一步提高运算效率,匹配图像中的特征点进行WTA匹配,非特征点只进行简单验证,提高了边缘的匹配效果。MATSUO等[27]在匹配成本计算阶段使用基于AD算法和Sobel算子的局部方法,通过多次迭代和JBF固定窗口生成了精确的视差图。
2 基于深度学习的匹配算法
手工设计的人工特征,缺乏对上下文信息的获取,经验参数的选择对匹配效果影响很大,不适合在复杂环境下应用。深度学习通过卷积、池化、全连接等操作,对图像进行非线性变换,可以提取图像的多层特征用于代价计算,对提取的图像特征进行上采样过程中设置代价聚合和图像增强方法,从而实现端到端的图像匹配。深度学习的方法更多地利用了图像的全局信息,通过预训练获得模型参数,提高了算法的鲁棒性。用于立体匹配的图像网络主要可分为金字塔网络、孪生网络(siamese network)和生成对抗网络。
2.1 图像金字塔网络
为了保证输入图片尺寸的一致性,常常需要对图片进行裁剪、缩放等操作。为了解决这个问题,HE等[28]在卷积层和全连接层之间设置空间金字塔池化层,将不同尺寸的图片特征转化为固定长度的表示,避免了卷积的重复计算,在图像分割、图像匹配等领域获得了极大的提升效果。ŽBONTAR和LECUN[29]首次提出使用卷积神经网络提取图像特征用于代价计算,设置跨成本交叉的代价聚合,运用左右一致性检查消除错误的匹配区域,其标志着深度学习开始成为立体匹配的重要手段。CHANG和CHEN[30]将金字塔池化模块引入到特征提取中,使用多尺度分析和3D-CNN结构,有效地解决了梯度消失和梯度爆炸的问题,在弱纹理、遮挡、光照不均匀等条件下获得了良好的效果。DUGGAL等[31]提出一种全新可微的Patch Match算法。首先获得稀疏的视差图,以减少代价计算的复杂度,再推算出剩余像素点的匹配范围,并在KITTI和SceneFlow数据集上实现了每对图片62 ms的匹配速度。TONIONI等[32]构建了模块化、轻量化的神经网络,网络子部分可独立训练,使用无监督算法模型,使网络可以不断更新,在不降低质量的前提下,达到了每秒40帧的处理速度。GUO等[33]构建了分组代价计算,ZHANG等[34]设计了半全局聚合层和局部引导聚合层,都可以代替3D卷积层,提高计算效率。
2.2 孪生网络
孪生网络的概念最早由BROMLEY等[35]提出,其基本结构如图3所示。通过设置2个权重共享的卷积神经网络,分别输入左、右图像,通过映射函数将卷积得到的特征转化为特征向量,衡量2个特征向量间的L1距离就可以拟合2张图片的相似度。文献[36]对原有的孪生网络进行了改进,使用RELU函数和小卷积核加深卷积层,提高了匹配精度。文献[37]使用孪生网络从左右图像提取特征,首先在低分辨率的代价卷积中计算视差图,再使用分层细化网络引入高频细节,利用颜色输入作为指导,可以生成高质量的边界。LIU等[38]提出通过连接2个子网络获取多尺度特征。第1个子网络由孪生网络和3D卷积网络构成,可以生成低精度的视差图;第2个子网络是全卷积网络,将初始视差图恢复成原始分辨率,2个网络用金字塔池化进行连接。文献[39]在低分辨率的视差图上对深度不连续区域进行改进,在视差求精阶段恢复成原始分辨率,取得了良好的效果。
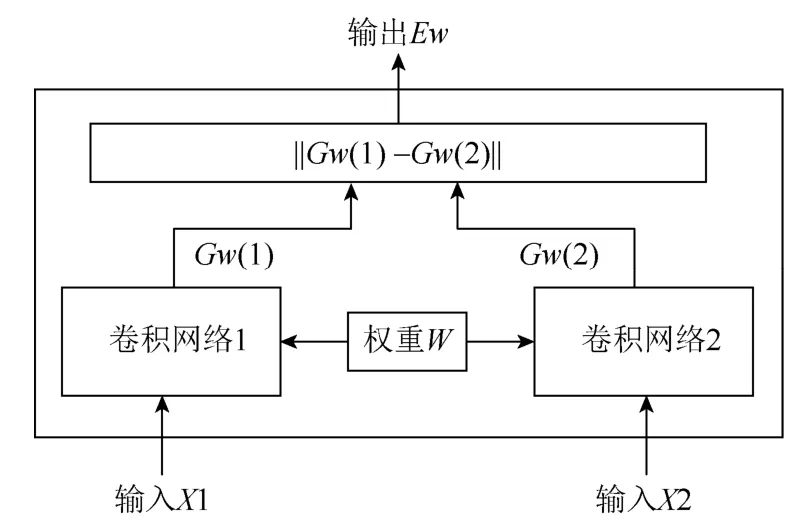
图3 孪生网络结构Fig. 3 Siamese network structure
2.3 生成对抗网络
在博弈论的基础上,文献[40]构建了生成式对抗网络(generative adversarial networks, GAN)。网络由生成模型和判别模型构成。生成模型学习样本特征,生成图像与原图像相似,而判别模型则用来分辨“生成”图片与真实图片。这个过程不断迭代运行,最终判别结果达到纳什均衡,即真假概念均为0.5。PILZER等[41]提出了基于双目视觉的GAN框架,其由2个生成子网络和1个判别网络构成。2个生成网络在对抗学习中分别被用来训练重建视差图,通过相互制约和监督,生成2个不同视角的视差图,融合后输出最终数据。实验表明,这种无监督模型在光照不均匀的条件下可以得到良好的效果。文献[42]使用生成模型对遮挡区域进行处理,恢复得到了良好的视差效果。文献[43]提出了深卷积生成对抗模型,可以通过相邻帧获得多幅深度图,进一步改进了遮挡区域的深度图效果。文献[44]通过左右相机拍摄的2幅图像,生成一幅全新的图像,用于改进视差图中匹配效果较差的部分,实验表明,该方法对于光照强度较差的区域视差图提升效果明显。
3 算法测试与评估
3.1 算法测试框架
目前,立体匹配算法主要有Middlebury和KITTI 2个测评数据集,主要对算法的误匹配率和运行时间进行准确的测评,并提供算法的排名。这2个数据集都构建了标准的视差图,可用于计算误匹配率。KITTI提供了统一的云平台运行算法,保证了算法运行时间测评的硬件一致性。
Middlebury[7,45-48]由卡内基梅隆大学双目实验室创建,评价系统可以求取整张图片、遮蔽和深度不连续区域的误匹配率,并对提交的算法进行横向对比排名。
2011年,德国的卡尔斯鲁厄理工学院和芝加哥丰田技术研究所联合创立了Kitti立体匹配测试平台,并在2015年进行了更新[49-50]。数据集包含车载相机采集的市区、乡村和高速公路图像,旨在为自动驾驶提供技术准备和评估。
3.2 算法测试指标
目前,立体匹配算法的主要评价标准为视差图精度和时间复杂度。视差图精度的评价指标有误匹配率,平均绝对误差和均方误差。误匹配率的计算式为

其中,dc(x,y),dGT(x,y)分别为生成视差图和真实视差图的像素值;δd为评价阈值需设置,当差值大于δd时,此像素记为误匹配像素;N为视差图的像素总数。平均绝对误差式为
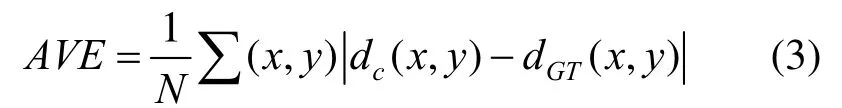
均方误差的计算式为

其中,N为所有像素的总数和非遮挡区域的像素数量。
部分算法的评价结果见表1。

表1 部分立体匹配算法评价结果Table 1 Some stereo matching algorithm evaluating results
3.3 2种不同类型的算法评估
基于人工特征的立体匹配算法,将数学原理的发展广泛应用于实际需求,推动了双目视觉系统在各行各业的应用。其拥有完整的数学模型和方便可调的参数,模型的可调整性和堆叠性较好,在鲁棒性要求不高的应用场景中,通过多次实验,可以得到良好的视差效果[8,51-52]。
基于深度学习的立体匹配算法,可以提取更多的图像特征用于代价计算。相比于人工特征,深度学习可以获取更多的上下文信息,提高算法的鲁棒性,使用GPU加速技术,得到更快的处理速度[30]。在自动驾驶、机器人等领域,深度学习通过大量数据对网络进行训练,可以获得高精度的视差图,满足了精度和实时性的要求[32]。
人工特征中的局部匹配算法误匹配率较高,一般在10%~30%之间[7],运行时间上最快的BM算法处理一对1432×1004大小的RGB图片只需0.05 s,误匹配率为32.45%[23],精度和速度平衡性较好的SGBM算法处理一对相同大小图片用时大约为0.53 s,误匹配率为18.36%[21]。全局匹配算法的精度比局部匹配法要高,误匹配率一般在10%左右[7],但运行速度较低,处理图像的时间较长。KITTI平台中的精度排名最高的全局匹配算法误匹配率为5.12%,运行时间达到65 s。基于深度学习的匹配算法通过大量数据训练可以达到很高的精度,KITTI平台中精度排名最高的深度学习算法误匹配率只有1.41%,在仅使用单核CPU运算的条件下运行速度为0.52 s,表现出深度学习强大的应用前景。对于基于人工特征和深度学习的匹配算法的特点总结见表2。

表2 算法特点对比Table 2 Comparison of algorithm features
4 结 论
立体匹配是实现双目视觉的核心点,匹配的效果直接影响后续的目标识别、三维建模等工作。
基于人工提取特征的立体匹配算法由于数学解释性高,堆叠性好等优点,目前广泛应用于固定场景的识别。通过多种方法进行融合,可以取得良好的效果。
基于深度学习的立体匹配算法已成为自动驾驶、机器人领域的主流,目前要解决的难题主要分为以下3个方面:
(1) 提高算法的实时性和准确性。对于自动驾驶领域尤为重要,但目前算法在这2方面很难做到兼顾。
(2) 增强算法的鲁棒性。深度学习算法受限于数据集的训练,这使得算法对于农田、山地等陌生环境的匹配准确率有所降低。
(3) 提高算法的适应性。现实世界中雨雾天气下拍摄的图像可能存在反光、模糊、噪声等各种问题,这对算法提出了较高的要求。
人工特征的应用有助于深度学习网络的完善,而近年来,强化学习、图神经网络等领域的不断发展,也都为立体匹配算法的改进提供了参考。
