基于注意力机制的双层LSTM自动作文评分系统
2020-11-11夏林中罗德安管明祥张振久龚爱平
夏林中,罗德安,刘 俊,管明祥,张振久,龚爱平
深圳信息职业技术学院人工智能技术应用工程实验室,广东深圳 518172
一篇高质量作文不仅要关注单词、短语、句子及句法结构的使用,还要注重作文局部关键信息和上下文之间的逻辑结构与关系[1].要写出一篇高质量作文,大量练习必不可少,由此产生了大量需要即时评价并反馈的作文练习稿,为作文评分员带来极大的工作负担[2].
为了解决上述问题,研究发明了许多基于机器学习的自动作文评价方法[3-10].近些年出现的基于深度神经网络(deep neural network, DNN)的自动作文评分(automatic essay scoring, AES)方法,在自动作文评分领域取得了显著成效.为了进一步提升DNN处理AES任务的性能,研究也提出多种改进的DNN方法[11-19].DONG等[20]提出一种基于词向量的双层卷积神经网络(convolutional neural network, CNN)模型,该模型的第1个卷积层用来提取句子特征,第2个卷积层基于句子向量学习篇章级特征.TAGHIPOUR等[21]提出一种在本地数据集上训练词向量的基于双层长短时记忆(two-layer long short-term memory, LSTM)和隐层输出平均值(mean over time, MoT)的LSTM-MoT模型,本地数据集仅包含最常用的4 000个词汇,其他词汇均被定义为停用词,且该模型以所有LSTM隐藏单元输出之和的平均值作为最终作文表示.DONG等[22]提出一种基于注意力(attention-based)的LSTM-CNN模型,该模型充分利用CNN和循环神经网(recurrent neural network, RNN)的优势,并利用注意力机制(attention mechanism, AM)自动学习不同词或句子在作文中所占的相对权重,结果表明,该模型优于未使用注意力机制的方法,从而证明注意力机制的有效性.TAY等[23]提出SKIPFLOW-LSTM模型,当模型读取作文的各个词向量时,SKIPFLOW机制可以捕捉不同时间步对应的LSTM隐层输出间的关系,从而为AES提供特征依据.CHEN等[24]提出一种Topic-BiLSTM-attention模型,该模型不仅利用作文的主题相关性特征,还通过双向LSTM捕捉作文的上下文依赖关系,更好地为AES提供依据.LIANG等[25]提出一种连体双向长短时记忆神经网络结构(siamese bidirectional LSTM neural network architecture, SBLSTMA)模型,该模型能同时捕捉到作文的上下文语义和评分标准信息.
本研究为AES任务设计一种新颖的DNN结构,该DNN结构是一种增强的LSTM结构,由word embedding 层(使用谷歌文本库进行word embedding预训练生成词向量GWV)、双层(two-layer)LSTM层和AM层构成,称为基于注意力机制双层长短时记忆(attention-based two-layer LSTM with Google word vector as the input layer, GAT-LSTM)神经网络自动作文评分模型.使用这种结构的主要考虑如下:① 由于本地数据集规模较小,进行word embedding预训练生成的词向量(名称为LWV)在上下文语义信息表达能力上远弱于GWV,因此,本研究使用GWV作为双层LSTM层的输入,以提高上下文语义信息的表达能力;② 多层神经网络从数据中学习有用特征的能力更强大[26],因此,双层LSTM结构的下层可以抽取上下文语义信息和隐藏的上下文依赖关系,上层可以捕获更深层次的上下文依赖关系;③ 利用注意力机制增强对作文中关键字词的关注,并为其分配更大的注意权重.本研究主要依据二次加权kappa系数分析模型性能.
1 自动作文评分模型
基于GAT-LSTM 结构的AES模型如图1.该模型由word embedding层、双层LSTM层、AM层和softmax层组成.Word embedding层将作文中的单词转换成词向量,并将其作为LSTM层的输入;双层LSTM层用来抽取上下文语义信息和隐藏的上下文依赖关系;AM层自适应关注不同局部信息对评分的影响,并依据影响大小为不同局部信息分布相应注意权重,使作文特征在保留最有效局部信息的基础上,最大程度解决信息冗余的问题;softmax层是分类层,此处不同类别对应相应的作文得分.图1中,word embedding层的xt(t=1,2,…,L)代表输入的单词,et(t=1,2,…,L)代表对应单词的词向量;双层LSTM层中h1t代表双层LSTM的下层隐藏状态,h2t代表双层LSTM的上层隐藏状态; AM层中at代表每个隐藏状态的注意力权重系数,h′代表综合计算后的注意力权重系数;softmax层的yscore是模型最后预测的作文分数.
1.1 Word embedding
本研究中word embedding层分别生成LWV和GWV词向量.其中,LWV通过word2vec方法使用skip-gram模型训练本地数据集获得,LWV向量维度取100;GWV通过word2vec方法使用skip-gram模型训练谷歌文本库获得, GWV向量维度取300.
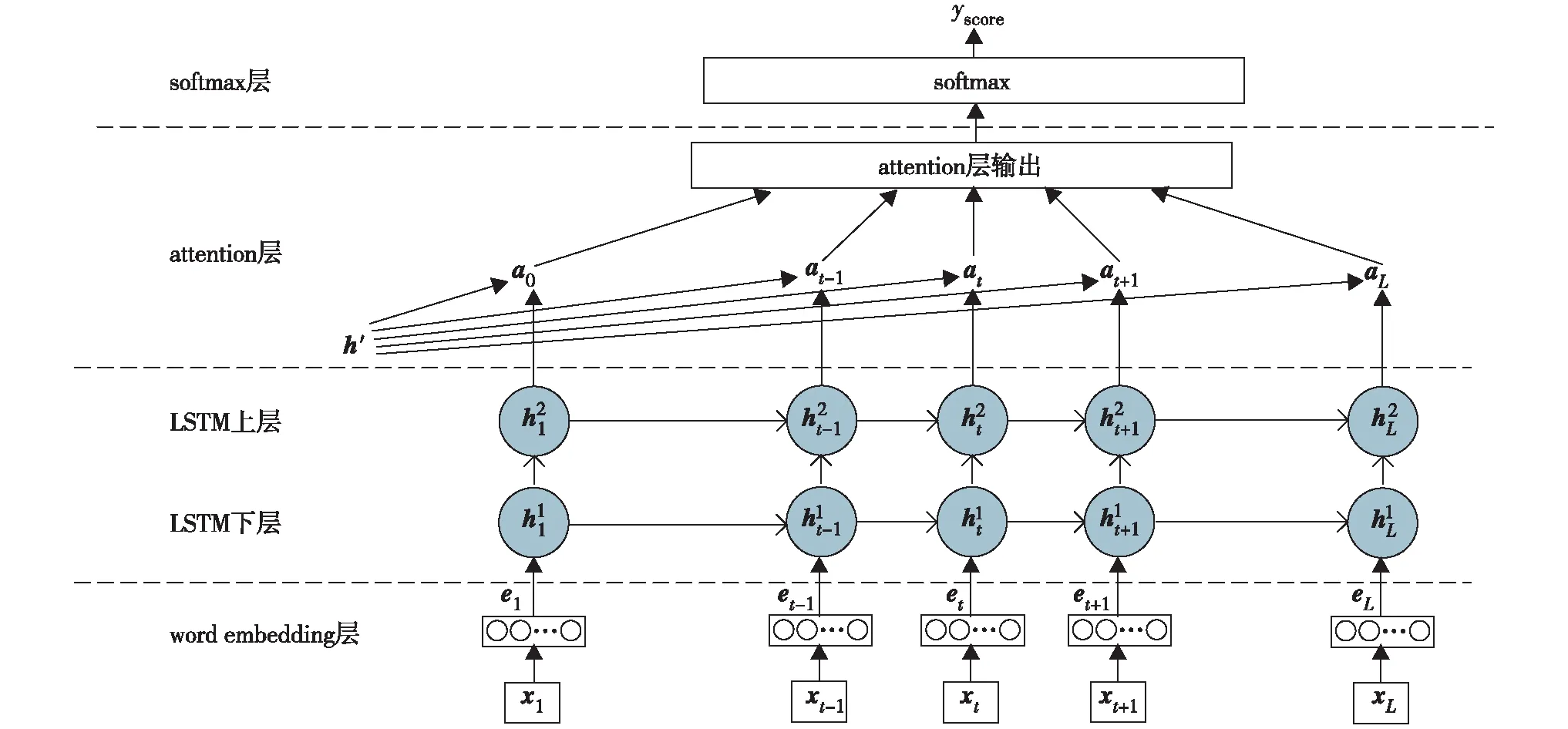
图1 GAT-LSTM结构图Fig.1 The architecture of the GAT-LSTM
1.2 长短时记忆神经网络
RNN适于处理类似文本的序列信息,其不仅可以对上下文关系建模,还可处理长度可变的序列信息.但在实际应用中,梯度消失导致RNN仅有短期记忆,无法实现信息的长期保存.LSTM是RNN的变体,通过添加内部的门控机制维持信息的长期保存,从而解决信息的长期依赖问题.
LSTM单元包括输入门it、 遗忘门ft及输出门ot, 如图2.LSTM隐藏层的输入和输出向量分别为xt和ht,记忆单元为Ct. 输入门用于控制当前输入数据xt流入Ct的数量,即保存到Ct中的输入信息数量;遗忘门控制信息的保留及遗忘,并以特定方式避免当梯度随时间反向传播时引发的梯度消失问题,即上一时刻信息Ct-1对当前时间步对应Ct的影响;输出门可以控制记忆单元Ct对当前输出值ht的影响,即在时间步t时控制记忆单元Ct的输出信息.输出ht不仅受Ct和xt的影响,还受ht-1的影响;记忆单元Ct不仅受ht-1和xt的影响,还受Ct-1影响.LSTM单元的计算方法为
it=σ(Wi·xt+Ui·ht-1+bi)
(1)
ft=σ(Wf·xt+Uf·ht-1+bf)
(2)
(3)
(4)
ot=σ(Wo·xt+Uo·ht-1+bo)
(5)
ht=ot*tanhCt
(6)

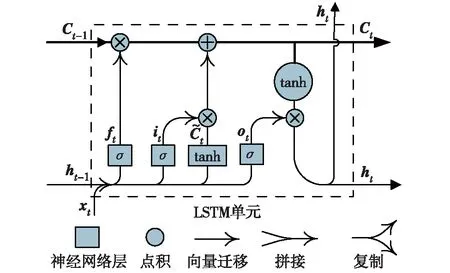
图2 LSTM单元示意图Fig.2 The LSTM cell
双层LSTM网络如图3.双层LSTM层的下层可以抽取上下文语义信息和隐藏的上下文依赖关系,上层可以捕获更深层次的上下文依赖关系.下层的隐藏状态h1t与上层的隐藏状态h2t进行全连接,最终可得上层隐藏状态输出为
h2t=Wm·h1t+bm
(7)
其中,Wm和bm分别是下层LSTM和上层LSTM之间的网络全连接权重矩阵和偏置向量.

图3 双层LSTM模型示意图Fig.3 The two-layer LSTM model
1.3 注意力机制
在自然语言处理中,基于LSTM隐藏状态进行作文分类的方法有两种:一种是将LSTM最终隐藏状态作为作文分类器的输入,但会丢失部分远离最终隐藏状态的信息;另一种是将所有时间步的隐藏状态相加后取平均值作为作文分类器的输入,但无法区分每个时间步的输入信息对作文分类影响的大小.为此,本研究提出使用注意力机制学习每个时间步输入信息的重要程度,从而捕获作文中的关键词语,并加大这些关键信息的注意力权重.
假设LSTM的输入向量为x1,x2x2…xt, 对每个向量输入对应的LSTM隐藏状态分别是h1,h2h2…ht, 则注意力机制的核心思想就是计算某个时间步对应的隐藏状态hi与最终隐藏状态h′的相似度Si.
Si=tanh(Wn·hi+bn)
(8)
其中,Wn和bn为网络的权重矩阵和偏置向量.每个时间步输入信息的注意力权重ai为
(9)
其中,h′是被随机初始化的超参数,在训练过程中通过学习获得.加入注意力权重后的LSTM隐藏状态向量v为
(10)
最后,将v输入分类层(作文不同得分对应不同类别),即使用softmax函数对作文成绩进行预测,预测函数为
yscore=softmax(Ws·v+bs)
(11)
其中,Ws和bs为网络权重矩阵和偏置向量.
2 实 验
2.1 实验设置
2.1.1 数据集
本研究所使用数据集由Hewlett基金会支持的学生作文自动评分大赛(automated student assessment prize, ASAP)提供,将发布的数据集划分为3部分:60%作为训练集;20%作为验证集;20%作为测试集.该数据集由8个子集组成,每个子集具体情况如表1.
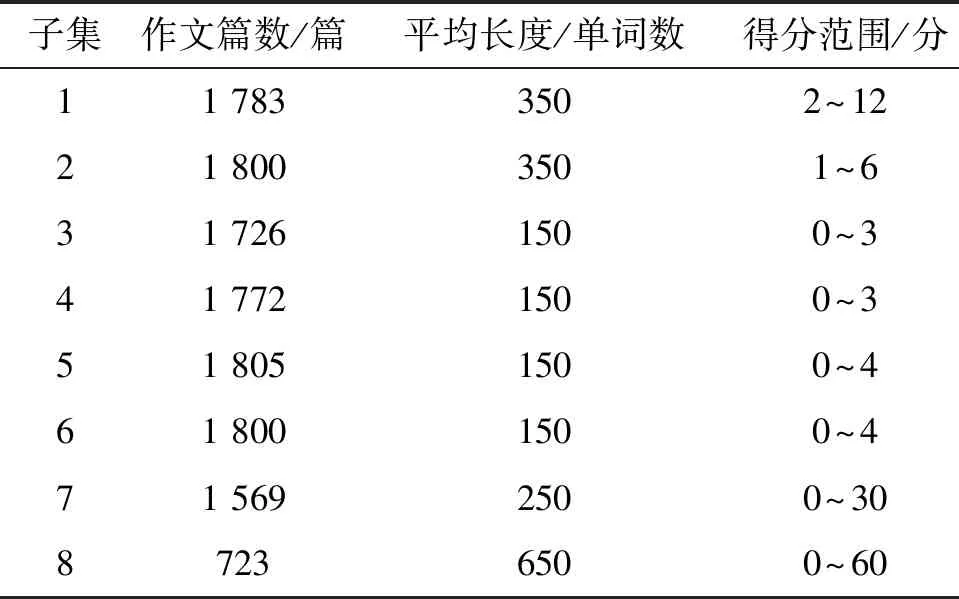
表1 ASAP数据集概况
2.1.2 评估方式
实验结果及ASAP中均使用二次加权kappa(quadratic weighted kappa, QWK)系数κ进行评估.κ定义为
(12)
(13)
其中,i和j代表不同的评分;N为评分等级数;Oi, j表示被评分员1评为i分以及被评分员2评为j分的作文篇数, {Oi, j}是一个N×N矩阵;假设评分之间不相关,是随机生成的,以相同方法可以构造出另一个N×N的矩阵{Ei, j}.κ是评估作文不同评分之间一致性的重要系数,其取值范围为[-1, 1],当κ=0时,表示作文不同评分之间的一致性完全随机;当κ=1时,表示作文不同评分之间的一致性完全相同.
2.1.3 参数设置
本研究采用Adam随机优化器及交叉熵损失函数.损失函数计算为
(1-y′)ln(1-yscore)}
(14)
其中,y′和yscore分别为作文的真实分数和预测分数. GAT-LSTM模型的超参数设置见表2.

表2 超参数设置
2.2 基准模型
采用表3的7种自动作文评分模型作为基准模型,对比研究GAT-LSTM模型性能.其中,所有基准模型均使用ASAP提供的数据集;HR1-HR2代表由2个人工评分员进行评分;DP+SCM模型[1]使用统计学方法抽取篇章级特征和语义连贯特征实现自动评分;其他模型基于深度神经网络方法进行自动评分.
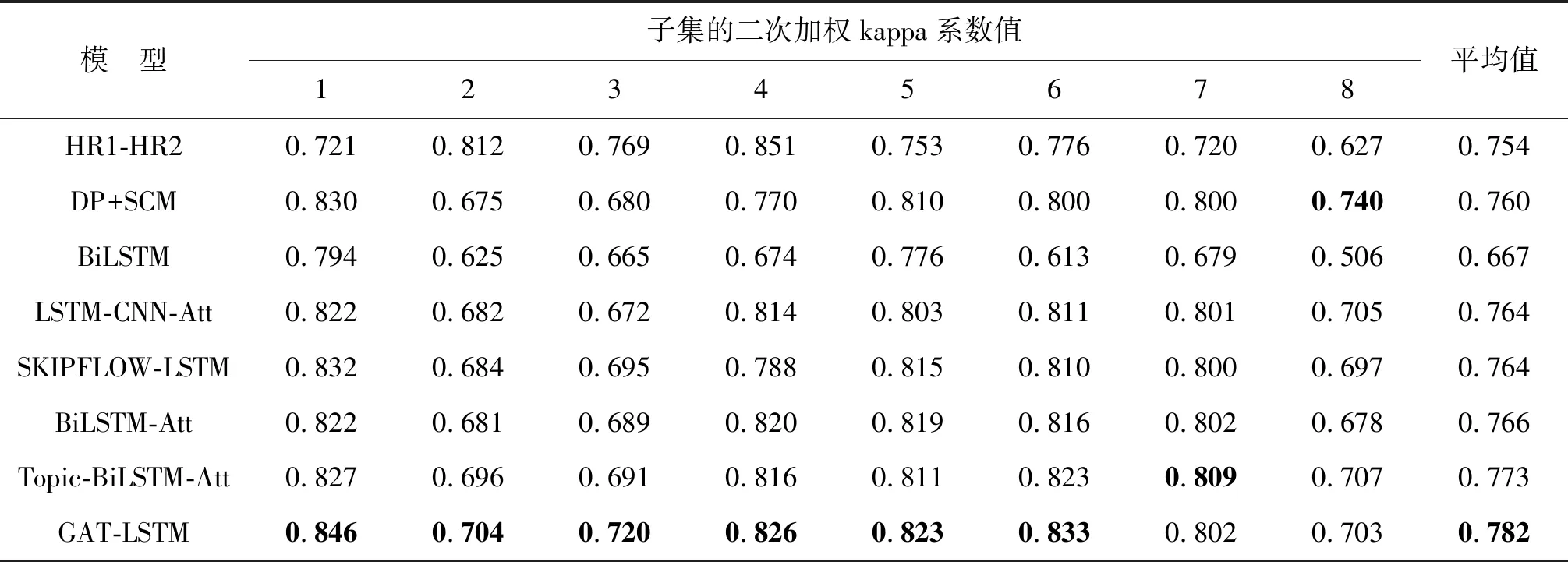
表3 基于ASAP数据集的不同模型的实验结果1)
2.3 实验结果
2.3.1 结果对比
表3的所有实验结果均使用二次加权kappa系数进行评估,表中加粗字体代表最好的实验结果.对比HR1-HR2和DP+SCM,基于深度神经网络模型的最大优势是无需繁琐的特征工程,就可以自动学习到相应的作文自动评分特征.
对比6种基于深度神经网络的模型可见, GAT-LSTM模型的κ平均值最高;对于子集1~6,GAT-LSTM模型取得最好κ值;相对于Topic-BiLSTM-Att模型,GAT-LSTM模型在子集1~6上的κ值分别得到1.9%、0.8%、2.9%、1.0%、1.2%及1.0%的提升.但在子集7和8上,Topic-BiLSTM-Att和DP+SCM模型的κ值略优于GAT-LSTM模型,主要原因是子集7和8的作文分值范围太大(表1).可见,GAT-LSTM模型的κ平均值优于其他基准模型, GAT-LSTM模型自动作文评分的整体性能优于表3中的基准模型.
2.3.2 GAT-LSTM模型各部分作用
为分析GAT-LSTM模型每个组成部分对模型性能提升的贡献,分别进行以下对比研究:以LWV为输入的LSTM(W-LSTM)模型;以LWV为输入的双层LSTM(WT-LSTM)模型;以LWV为输入的基于注意力机制的双层LSTM(WAT-LSTM)模型;以GWV为输入的LSTM(G-LSTM)模型;以GWV为输入的双层LSTM(GT-LSTM)模型.针对数据集的8个子集分别绘制了G-LSTM、GT-LSTM和GAT-LSTM 模型的二次加权kappa系数值的对比图,如图4.其中,子集1~2比较的是前75个epoches的迭代结果;子集3~7比较的是前50个epoches的迭代结果;子集8比较的是前100个epoches的迭代结果. 基于上述不同模型所获取的κ值如表4.可见,以GWV为LSTM层输入模型的κ值得到提升;基于注意力机制的双层LSTM模型结构明显优于单纯双层LSTM模型结构.
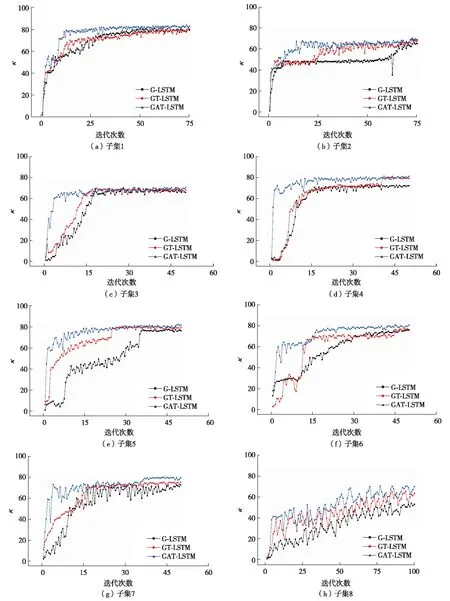
图4 模型G-LSTM、GT-LSTM 和GAT-LSTM分别在数据集不同子集时二次加权kappa系数的异同比较Fig.4 The QWK value of each prompt comparison under G-LSTM, GT-LSTM and GAT-LSTM
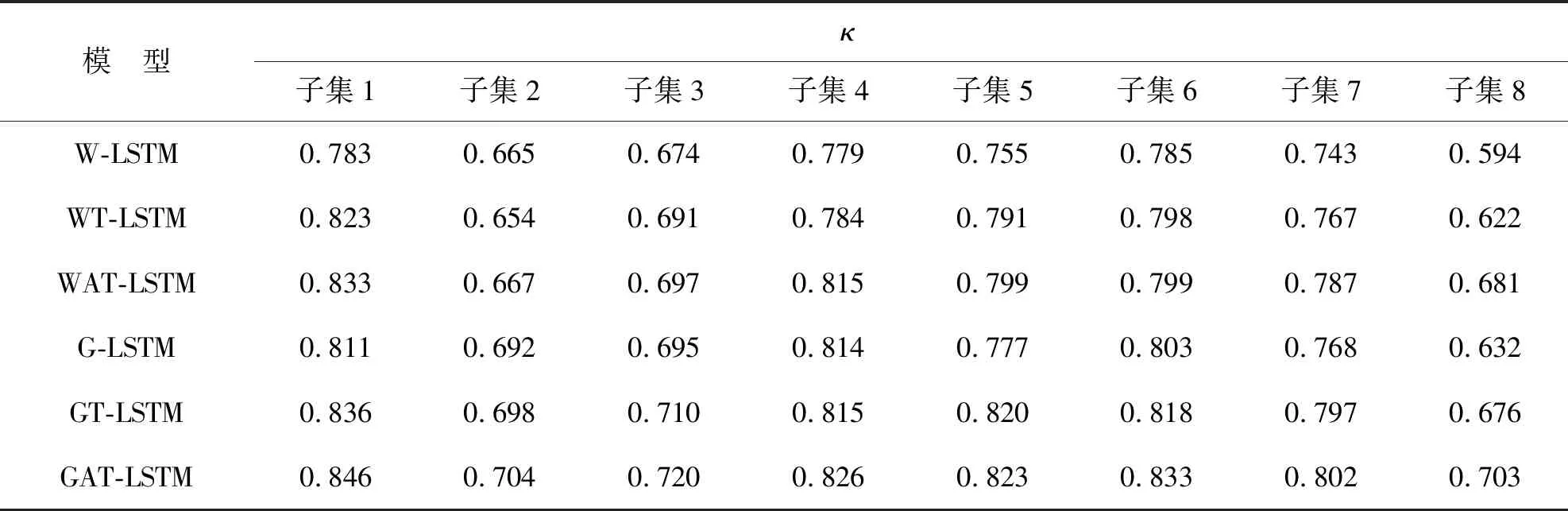
表4 不同模型的二次加权kappa系数值
由图4可见,与G-LSTM和GT-LSTM相比,GAT-LSTM的κ值上升速度最快,并能快速达到稳定状态.子集1与2的作文平均字数为350,其对应的迭代次数最大值是75;子集3至7的作文平均字数为150或250,其对应迭代次数最大值是50;子集8的作文平均字数为650,其对应的迭代次数最大值是100.由此推知,当κ值上升到稳定状态时,迭代次数值与作文字数成正比.同样,子集8的κ值上升速度和稳定性比其他子集差,主要是因为子集8所含作文数量最少、作文平均长度最长和评分范围最广(表1)导致.
结 语
本研究的AES模型通过使用GWV、双层LSTM和注意力机制可以很好提升AES性能.与LWV相比,GWV包含更丰富的词汇语义信息和上下文信息,实验结果表明,GWV对模型性能的提升具有重要作用.双层LSTM结构可实现在下层抽取上下文语义信息和隐藏的上下文依赖关系,在上层捕获更深层次的上下文依赖关系.注意力机制可以识别作文中的关键信息,并为这些关键信息分配更多的权重.与基准模型对比,GAT-LSTM模型不仅在大多数数据集的子集上取得最好评分效果,而且其整体评分效果优于基准模型.接下来的研究将着重在如何更有效地进行词向量生成,并设计出更高效、简洁的神经网络结构.
