基于Q-learning的工业互联网资源优化调度
2020-11-11张延华吴文君杨睿哲司鹏搏
张延华, 杨 乐, 李 萌, 吴文君, 杨睿哲, 司鹏搏
(1.北京工业大学先进信息网络北京实验室, 北京 100124;2.北京工业大学信息学部, 北京 100124)
当前,第5代(the fifth generation, 5G)移动通信网络技术已经从概念逐渐步入商用,并将对我们的智能生活产生重大而深远的影响[1],5G的普及将为各类以网络为支撑的移动互联网应用带来广阔的发展前景和机遇. 与此同时,5G高速率、低时延、广连接的特点也将为用户提供更优质、更高效的服务,从而满足用户不同的网络需求和服务质量(quality of service, QoS).
与传统的无线通信网络相比,网络中包含有数量庞大的机器类型通信设备(machine-type communication devices, MTCDs)将是5G网络场景中最显著的特征[2]. 作为工业互联网与物联网(Internet of things, IoT)的重要载体,多功能、多种类、多QoS需求的MTCDs将成为5G网络中的重要组成部分,它们在承载、提供各种网络应用的同时,也将带来海量的网络资源占用、数据计算与传输以及系统能耗开销等. 与此同时,5G的网络通信成本也是一个不可忽视的问题. 面对5G等数据网络可能产生的高昂使用费用,WiFi仍是网络接入的重要选择之一. 在大量机器类通信设备网络接入的背景下,网络连接的成本问题也成为需要考虑的因素之一.
为应对工业互联网设备计算能力有限、网络拥塞等问题,移动边缘计算(mobile edge computing, MEC)技术在5G与工业互联网场景中将扮演重要的角色[3]. MEC可实现在网络边缘为用户提供计算服务,其服务器的计算能力远大于工业互联网设备. 同时,相比于传统的云计算,MEC虽在计算能力方面稍显不足,但可大幅度减少网络传输时延,并有效缓解网络拥塞等问题,也降低了网络负载开销[4].
然而,在一定范围内,工业互联网设备数量极其庞大,当这些设备同时发送计算服务请求时,将超出MEC服务器的计算负载. 另一方面,由于地理位置的限制,一些偏远位置的设备不易更换电池,导致此类设备自身能量有限,无法承受计算能耗过大的任务[5],存在大量计算任务卸载到其他数据计算服务器协助执行的需求. 并且,庞大的设备数量决定了网络连接以及计算成本也是必然要考虑的要素. 因此,在不超出MEC服务器负载的前提下,以尽可能小的能耗、经济等开销处理工业互联网节点产生的计算任务,成为当下的热门研究问题. 针对以上问题,Li等[6]主要研究了工业互联网场景中云计算与MEC协作的计算任务卸载策略,提出一种节能型数据卸载和资源分配框架,可有效减少系统能耗. Guo等[7]针对物联网设备计算密集型与计算资源受限相冲突的问题,提出了一种基于博弈论的联合卸载框架,实现MEC和云计算的合作卸载,可使物联网设备充分利用分布式MEC服务器和中心云服务器的计算资源,有效减少运行成本和能耗. 然而,传统方法在应对工业互联网设备计算任务卸载的问题时还存在一定局限性,例如,无法适应复杂多变的网络环境以及无法支持网络中庞大的用户数量.
与此同时,针对这类状态变化频繁、不易建模的动态系统,强化学习(reinforcement learning, RL)逐渐成为一类热门的解决方法. 强化学习中agent通过对环境施加动作,并得到环境返回的动作评价,逐渐学习到在复杂环境中一些问题的最佳解决方案[8]. 基于强化学习无模型学习的优势,并针对计算任务卸载中复杂、时变的网络环境,近年来结合强化学习算法优化卸载策略的研究逐渐增加. Fakhfakh等[9]基于Q-learning算法,依据用户的位置,获得最佳的WiFi连接策略. Le等[10]基于强化学习实现对用户多任务卸载的决策优化,有效减少用户设备能耗. 此外,在文献[11]中,Ho等利用马尔可夫决策过程及适当的奖励机制实现了WiFi网络与移动网络的混合任务卸载,节省了无线传输时的能耗. Zhang等[12]从移动用户任务卸载的角度研究了在WiFi卸载过程中时延、能耗和成本的平衡问题,并利用强化学习的算法对其进行优化.
尽管上述研究基于强化学习算法优化了网络连接或多任务卸载等策略,但仍存在只考虑信道、服务器状态等单一环境因素或只局限于对能耗、时延等单一因素优化的问题,并未深入研究多种环境因素的影响或是对多种开销的联合优化. 综上所述,本文将面向工业互联网场景中MTCDs的计算任务卸载问题,提出一种基于Q-learning的计算任务卸载决策方法,综合考虑工业互联网通信设备卸载过程中的网络环境和服务器状态,并联合优化设备卸载过程产生的时延、能耗和经济开销,也可根据实际需求调整加权参数,对三者之一进行补偿优化. 仿真结果显示,本文方法可有效减少工业互联网通信设备计算任务卸载系统的时延、能耗和经济花费三者总开销.
本文的结构安排如下:第1部分介绍本文方法适用的场景和系统模型,包括网络模型、时延模型、能耗模型和经济开销模型;第2部分针对场景构建策略优化问题建模,并基于Q-learning算法对所提优化问题求解;第3部分分析和讨论所提方法的仿真实验结果;最后是对本文工作的总结与展望.
1 系统模型
1.1 网络模型
本文所提工业互联网网络结构模型如图1所示. 此场景下包含N个用户和M个WiFi节点. 同时,小区内还部署1个装配有MEC服务器的基站. 假设用户需处理一批计算密集型任务,可选择于本地处理,也可选择卸载至MEC服务器或中心云服务器处理. MEC服务器的最大计算负载量为L. 用户上传任务数据时,既可选择通过移动网络传输,也可通过WiFi网络传输.
本文暂不考虑移动网络与WiFi网络的相互干扰. 在上传任务数据时,每个用户都拥有相同的信道带宽. 当用户通过移动网络传输时,拥有固定的传输速率rb. 当用户通过WiFi网络传输时,首先在一定范围内获取区域内WiFi节点的传输功率pw1,pw2,…,pwm,…,pwM,根据
pw=max{pw1,pw2,…,pwm,…,pwM}
(1)
选取区域内传输功率最大的WiFi节点作为固定上传节点,避免于不同WiFi节点间切换造成额外能耗. 其中,传输功率pwm[13]为
(2)
式中:ptm为WiFi节点m的发射功率;Gtm为发射增益;Gr为接收增益;c为真空下光速;dm为WiFi节点m与用户的距离;其余为常数.
此外,当某一WiFi节点同时连接的用户增加时,相应的传输速率rw将会下降. 用户通过移动网络及WiFi网络上传数据的速率分别由
(3)
(4)
得到[14]. 式中:Bb、Bw分别为移动网络和WiFi网络的信道带宽;pb、pw分别为用户在移动网络信道和WiFi网络信道下拥有的传输功率;hb、hw分别为移动网络和WiFi网络信道的信道增益;Nb、Nw分别为移动网络和WiFi网络信道中存在噪声的功率谱密度;u为同时连接该WiFi节点的用户数量.
1.2 时延模型
设小区内用户在某时间段T内存在多个计算任务待处理,可选择于本地处理或卸载处理. 计算任务主要与2个参数有关,分别为任务数据量d和复杂程度c[15]. 任务数据量d主要包含任务的计算参数、数据等,复杂程度c表示CPU在处理该任务时所需花费的计算总轮数. 本文中,计算任务仅考虑只能全部在本地处理或全部卸载到数据服务器处理.
用户于本地处理任务时,其时延Dl只包含任务的处理时延. 假设用户设备CPU的计算能力为Fl(CPU每秒完成的计算轮数),则本地处理时延为
(5)
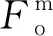
(6)
(7)
式中,根据文献[16],用户向云服务器上传数据时,存在额外等待时延,为计算方便,设其为一固定时间tc.
(8)
(9)
1.3 能耗模型
用户于本地处理任务产生的能耗El为
El=zn·c
(10)
式中,根据文献[17],zn为CPU每轮处理过程消耗的能量,且
zn=10-27(Fl)2
(11)

(12)
(13)
式中ps为用户等待回传结果时的待机功率.
(14)
(15)
此外,用户卸载任务时,遇到移动网络或WiFi网络状况不佳的情况,可选择切换网络,但会产生额外的切换能耗et.
1.4 经济开销模型
用户在处理计算任务时,不仅需考虑时延、能耗的问题,系统开销也是不可忽略的一部分. 本文假设用户于本地处理任务时,不产生任何经济开销. 同时,用户通过WiFi网络上传数据时也不会负担额外的开销,而当用户通过移动网络上传数据时,运营商会根据上传的数据量收取费用. 此外,用户卸载任务至MEC服务器或云服务器时,2种服务器将根据存储资源和计算能力的差异收取相应费用,该费用与被上传任务的数据量和计算复杂度有关[3,18-19].
用户于本地处理任务产生的经济开销Ml为0.
(16)

(17)

(18)
(19)

Al=Wd·Dl+We·El+Wm·Ml
(20)
(21)
(22)
(23)
(24)
式中Wd、We、Wm分别为对应于时延、能耗和经济开销的权值参数,且服从0≤Wd≤1、0≤We≤1、0≤Wm≤1及Wd+We+Wm=1.

(25)
2 基于Q-learning的计算任务卸载决策方法
本节将对上文提出的小区内多用户任务卸载问题提出优化目标,并基于强化学习对所提问题进行建模,设定强化学习在优化过程中的3个关键要素——状态、动作和奖励,随后应用强化学习中的经典算法Q-learning对优化问题进行求解.
2.1 优化目标
本文将时间T内小区中用户的任务卸载选择视作一个决策优化问题,优化目标是将时间T内小区中所有用户的任务处理总开销Asum降至最低,即
(26)
式中:N为小区内的用户数量;T为该时间段的截止时间点.
2.2 问题建模
在决策优化问题上,强化学习拥有明显的优势,智能体agent通过与环境信息的交互(对环境施加动作),从动作评价中得到与优化目标相关的奖励并不断进行探索学习,最终获得任务的最佳处理决策,完成问题优化.
在强化学习中,有3个关键要素需要首先确定,分别是优化问题中的环境状态、agent的可执行动作和环境对动作的评价方式reward. 本文结合用户任务卸载决策问题的特点,对这3个要素做了针对性的设置.
状态:在时间段T内,设其中有多个时间点t1,t2,…,tT. 在每个时刻,都有如下状态分量.
·L:MEC服务器的计算资源占有情况.
这些状态分量构成在时刻t的状态集合
(27)
动作:在每个状态st,都有如下不同的动作分量可选择.
这些动作分量构成在时刻t的动作集合
(28)
奖励:在每个时刻t下的每个状态st中,都有动作空间at可被选择,智能体agent在每个状态下完成选择的动作后,都会从环境中得到一个即时奖励rt用于评判agent采取的动作,进而指导agent的学习过程. 本文设置的优化目标是寻求将时间段t0-tT内小区中所有用户计算任务处理的总开销降至最低. 因此,本文将每一步动作后对agent的奖励设置为负相关于agent完成动作后产生的系统损耗,动作产生的损耗越小,获得的奖励越高. 据此,本文将奖励函数定义为
(29)
式中:Alocal(t)为该时刻t下所有用户任务都放置于本地处理的总开销;A(st,at)为时刻t时状态st下做出动作at产生的总开销.
2.3 优化问题求解
Q-learning是强化学习中一种经典的优化方法,在处理离散过程中的决策问题上具有明显优势.Q-learning算法中,存在一张Q表负责记录和更新agent在每个状态下做每个动作时的Q值[8]. 结合本文优化问题,agent将在不同网络状态和服务器状态下选择任务处理动作,并依据动作产生的系统损耗从环境中获取奖励.Q表更新完成后,agent将基于Q值执行动作,在每个系统状态下都将选择Q值最大的动作,作为此优化问题的决策. 此外,Q值并不是每个动作得到的奖励,而是一个考虑到未来收益的迭代值,其计算公式为
Q(s,a)←Q(s,a)+α[r+γmaxQ(s′,a′)-Q(s,a)]
(30)
式中:Q(s,a)为在状态s下做动作a时的Q值;α为学习效率,影响Q表的更新速度;r为即时奖励;γ为奖励延迟,表示后续动作的Q值对此步的影响,当γ趋近于0时,agent会更注重当前动作获得的收益,当γ趋近于1时,agent会更考虑后续动作的收益;maxQ(s′,a′,)为下一状态中可选动作中的最大Q值. 基于Q-learning的计算任务卸载决策流程如下:
基于Q-learning的计算任务卸载决策方法
Initialize
for each episode:
选择一随机网络/服务器状态st
{
fromt1
产生0-1的随机数x
ifx>ε:
随机选取卸载动作at
ifx≤ε:
选取该状态下Q值最大的动作at获取当前(st,at)的系统损耗A(st,at)
according tort=(Aloacl(t)-A(st,at))/(Aloacl(t)+A(st,at))
获得即时奖励rt,并观察下一个状态st+1
according toQ(st,at)←Q(st,at)+α(rt+γmaxQ(st+1,at+1)-Q(st,at))
获取此次迭代Q值,并更新Q表
st+1←st
enter nextt
}
untiltT
end for
此外,在基于Q-learning的计算任务卸载决策算法运行过程中,本文逐渐将贪婪系数ε调高使系统逐步稳定于选择收益较高的动作. 当贪婪系数ε趋近于0时,agent在选择每一步动作时会更随机,适用于在agent探索初期时,对状态动作空间进行尽可能多的广泛探索;当贪婪系数ε趋近于1时,agent将更倾向于在每一个状态选择Q值更大的动作,适用于在agent探索后期逐步稳定于执行收益最大的策略.
3 仿真实验及结果分析

本文将基于Q-learning的计算任务卸载策略与其他5种已有方法进行比较,5种已有方法包括全部任务本地处理、通过WiFi-MEC处理、通过BS-MEC处理、通过WiFi-Cloud处理和通过BS-Cloud处理.
图2展示了本文方法中2种不同奖励延迟系数的收益曲线对比. 如图2所示,奖励延迟系数为0.5的卸载策略最终在每个周期中获得大约1 500的总收益,奖励延迟系数为0的卸载策略最终在每个周期中获得大约1 250的总收益. 不同奖励延迟系数策略获得的收益差异说明,agent在此场景下进行决策时,不仅需考虑当前状态动作收益,还需考虑未来动作收益,才可学习到获得最大收益的策略.
图3展示了本文所提框架及其余5种已有方法在处理相同任务时产生的系统总开销与任务数据量的关系曲线,任务的复杂度为固定数值1 300 Mc. 随着任务数据量的提升,4种上传策略产生的总开销逐渐增加,而本地处理因不存在数据传输,系统总开销不变. 由图3可知,本文基于Q-learning的计算任务卸载策略产生的总开销始终低于其他策略,源于本文所提框架基于Q-learning,迭代学习最佳卸载策略,联合优化了卸载总开销. 此外,当任务数据量继续增长时,基于Q-learning的计算任务卸载策略将更倾向于本地处理的策略,以减少因过多数据传输产生的系统额外开销.
图4展示了本文所提框架及其余5种已有方法在处理相同任务时产生的系统总开销与任务复杂度的关系曲线,任务数据量为固定值500 kbit. 随着任务复杂度的增加,基于Q-learning的计算任务卸载策略与其他5种已有方法产生的系统总开销均有所增加. 其中,本地处理总开销的上升趋势最快,其原因为本地计算在面对更复杂的计算任务时,处理效率偏低,大大增加了处理消耗. 在所有曲线中,基于Q-learning的计算任务卸载策略产生的系统总开销同样始终低于其他策略产生的总开销.
图5展示了本文所提框架及其余5种已有方法在处理相同任务时,系统产生的任务平均时延、经济开销与任务数据量的关系,任务的复杂度为固定值1 300兆轮. 如图5所示,本地处理策略产生的任务平均时延和经济开销均保持不变. 其余卸载策略产生的任务平均时延和经济开销随任务数据量增加均有所增长,且每种策略有各自的优势和劣势. 例如,BS-MEC和BS-Cloud两种策略产生的任务平均时延低于其他策略,但其产生的任务平均经济开销又明显高于其他策略. 本文优化目标在于将一定时间内计算任务卸载的系统总开销降至最低,但其中各单项开销的优化效果并不一定最好. 若考虑着重对某项开销(例如任务时延、能耗和经济开销)优化,可根据实际需求调整其权值参数,以达到针对单项开销更理想的优化效果.
图6分别展示了本文所提基于Q-learning的计算任务卸载策略产生的任务平均时延、能耗和经济开销受加权系数的影响,任务的复杂度为固定值1 300兆轮. 上文中提到,总开销Asum由时延、能耗和经济开销分别与各自加权系数Wd、We、Wm相乘后相加得到,且各权值系数相加值为1. 如图6所示,各权值参数Wd、We、Wm分别设置为0.33、0.50和0.80,受此影响,卸载系统对各指标的优化程度均有显著差异. 权值参数越高,对于对应指标的优化程度越显著. 当匹配更高的权值参数时,同样的系统开销会被放大,agent因此会偏向于对该指标的优化. 以图6中任务平均经济开销为例,当权值达到0.80时,系统卸载策略甚至倾向于将全部任务置于本地处理,以减少其产生的经济开销. 但可预见,在提高某一项权值参数进行补偿优化时,其开销虽明显减少,但其余种类开销将有所增加. 因此,在实际场景中,需根据实际需求和限制调整各指标所对应的权值参数.
综上所述,相比于无优化的5种已有卸载决策方法,本文框架可有效减少任务处理时产生的加权总开销,并可根据实际需求调整对应的权值参数,着重优化时延、能耗、经济开销中的某一特定开销.
4 结论与展望
1) 面向工业互联网场景中MTCDs的计算任务卸载问题,提出了一种基于Q-learning的计算任务卸载决策方法,将小区内用户设备的计算任务卸载建立为一个决策优化问题.
2) 以最大程度降低计算任务卸载过程中产生的时延、能耗和经济开销的三者总开销为目标,通过执行基于Q-learning计算任务卸载决策方法,获得可供执行的最优策略.
3) 相比于无优化的5种已有卸载决策方法,该框架可有效减少整个计算任务卸载系统的总开销,并可根据实际需求调整权值参数,对时延、能耗和经济开销三者之一进行补偿优化.
4) 未来的工作将基于本文提出更复杂的网络模型框架,并结合神经网络等方法,进一步优化训练模型的运算速度,同时,也将在所提方法中考虑网络间干扰、频谱资源分配等.
