机器学习的安全问题及隐私保护
2020-11-11魏立斐陈聪聪李梦思陈玉娇
魏立斐 陈聪聪 张 蕾 李梦思 陈玉娇 王 勤
(上海海洋大学信息学院 上海 201306)
依托于云计算、物联网、大数据技术的发展,以数据挖掘和深度学习为代表的人工智能技术正在改变人类社会生活,并成为先进科技应用的代表和社会关注的热点.作为引领未来的战略性技术,人工智能技术被世界各国纷纷提升为发展国家竞争力、维护国家安全的重大战略.
机器学习是一种实现人工智能的方式,是近些年主要研究的领域.目前机器学习方案在很多领域都有着成熟的应用,如天气预报、能源勘探、环境监测等,通过收集相关数据进行分析学习,可以提高这些工作的准确性;还有如在垃圾邮件检测、个性化广告推荐、信用卡欺诈检测、自动驾驶、人脸识别、自然语言处理、语音识别、搜索引擎的优化等各个领域,机器学习都扮演着重要的角色.然而,蓬勃发展的机器学习技术使数据安全与隐私面临更加严峻的挑战,因为机器学习的更精准模型需要大量的训练数据为支撑.
自2013年斯诺登的“棱镜”事件以来,全球信息泄露规模连年加剧,引起社会的广泛关注.2016年9月Yahoo被曝出曾被黑客盗取了至少5亿个用户账号信息;2017年微软Skype软件服务遭受DDOS攻击,导致用户无法通过平台进行通信;2018年3月美国《纽约时报》和英国《卫报》均报道:剑桥分析(Cambridge Analytica)数据分析公司在未经用户许可的情况下,盗用了高达5千万个Facebook的用户个人资料[1].2019年美国网络安全公司UpGuard发现上亿条保存在亚马逊AWS云计算服务器上的Facebook用户信息记录,可被任何人轻易地获取;IBM在未经当事人许可的情况下,从网络图库Flickr上获得了接近100万张照片,借此训练人脸识别程序,并与外部研究人员分享[2].2020年4月《华盛顿邮报》报道视频会议软件Zoom存在的重大安全漏洞:数以万计的私人Zoom视频被上传至公开网页,任何人都可在线围观,很多视频都包含个人可识别信息,甚至是在家里进行的私密谈话[3].信息泄露的途径主要分为内部人员或第三方合作伙伴泄露、信息系统无法杜绝的漏洞、机构本身的防护机制不健全、对数据的重要程度不敏感,以及对安全配置的疏忽大意等.可见,数据隐私的泄露已不单单是满足某些外部人员好奇心所驱使,而是已成为一种重要的商业获利而被广泛关注,其中不乏内外勾结、合谋获取用户的隐私等行为.
由此可见,机器学习中的安全与隐私问题已经非常严重.目前,研究人员提出了许多解决机器学习中的隐私问题的方法.本文将全面介绍机器学习中的安全问题和隐私威胁,并重点介绍隐私保护方法.
1 机器学习及敌手模型
1.1 机器学习概念
机器学习(machine learning, ML)是人工智能的一个分支,主要是研究如何从经验学习中提升算法的性能[4],它是一种数据驱动预测的模型.它可以自动地利用样本数据(即训练数据)通过“学习”得到一个数学模型,并利用这个数学模型对未知的数据进行预测.目前机器学习被广泛应用于数据挖掘[5-6]、计算机视觉[7-8]、电子邮件过滤[9-10]、检测信用卡欺诈[11-13]和医学诊断[14-15]等领域.
机器学习主要可以分为监督学习、无监督学习、半监督学习和强化学习[16],总结如表1所示.监督学习就是给定一个包含1个或多个输入和输出(标签)的数据集,通过监督学习算法得到一个数学模型,该数学模型可以用来对给定的数据进行预测.常见的监督学习算法包括支持向量机、神经网络、回归分析和分类等,常用于对电子邮件进行过滤等应用.无监督学习是给定无人为标记标签的数据集,通过无监督学习算法可以识别出数据的共性,再根据数据的共性对每个数据是否存在此类共性做出反应.常见的无监督学习算法包括聚类,通常无监督学习用于聚类分析、关联规则和维度缩减等.监督学习和无监督学习的区别就是训练数据集的目标是否标记(含有标签)过.半监督学习介于监督学习和无监督学习之间,当未标记的数据与少量标记的数据结合使用时,可以大大提高模型的准确性.而强化学习强调如何基于环境而行动(与环境进行交互或者说是利用奖惩函数进行训练),以取得最大化的预期利益.常见强化学习算法如Q-Learning[17]等,该算法常应用于自动驾驶、游戏等领域.
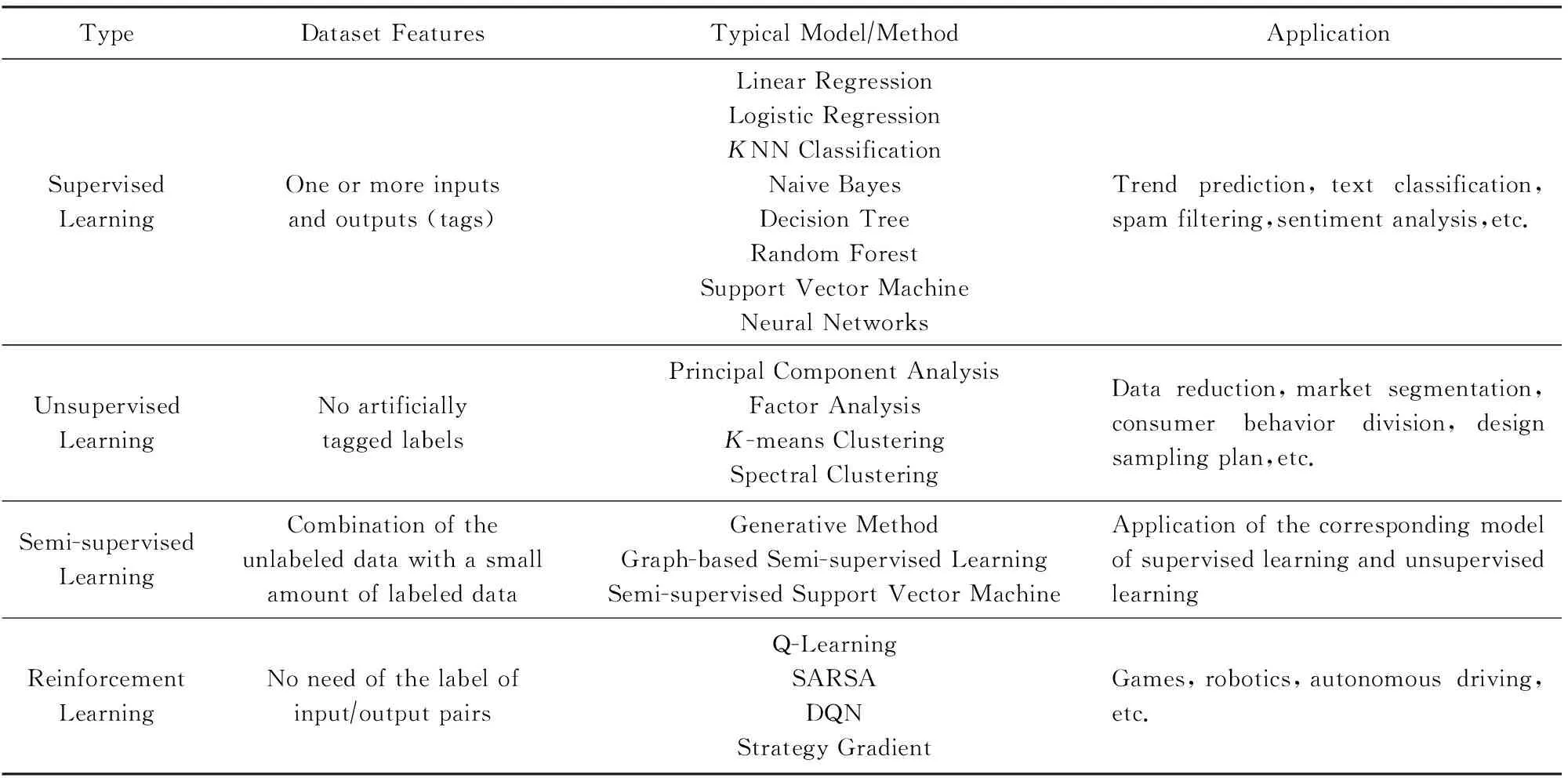
Table 1 Machine Learning Classification表1 机器学习分类
1.2 机器学习中的敌手模型
在机器学习安全中,常常利用敌手模型来刻画一个敌手的强弱.Barreno等人[18]在2010年考虑了攻击者能力、攻击者目标的敌手模型.Biggio等人[19]2013年在Barreno等人的基础上完善,提出了包含敌手目标、敌手知识、敌手能力和敌手策略的敌手模型,这也是目前普遍接受的敌手模型或攻击者模型.从这4个维度刻画敌手,能够比较系统地描述出敌手的威胁程度[19-21].
1.2.1 敌手目标
敌手期望达到的破坏程度和专一性称为敌手目标.破坏程度包括完整性、可用性和隐私性,专一性包括针对性和非针对性[19].破坏完整性目标就是未经过数据拥有者的同意对数据进行增删、修改或破坏,如对个人的医疗数据进行篡改,最后将训练得到的模型进行预测得到错误的疾病类型.破坏可用性目标就是使目标服务不可用,如在训练数据集中注入大量不良数据使训练出来的模型无用[22],从而达到服务不可用的目的.破坏隐私性目标可以理解为窃取隐私数据,如将训练数据集的信息窃取等.而专一性中的针对性目标和非针对性目标则是可以产生针对性的目标破坏或者非针对性的破坏,如对医疗数据可以产生针对性的窃取某个客户的隐私信息或者对数据的完整性产生非针对性的破坏[23].
1.2.2 敌手知识
敌手知识是指敌手对目标模型或目标环境拥有的信息多少,包括模型的训练数据、模型结构及参数和通过模型得出的信息等.根据敌手拥有的信息量,可以将敌手拥有的知识称为有限知识和完全知识[21].而在机器学习的攻击中,可以根据敌手掌握的知识量将攻击方式划分为白盒攻击和黑盒攻击.白盒攻击是敌手掌握模型的一部分数据集或者完全数据集,了解模型结构、参数以及一些其他信息.而黑盒攻击则是敌手不了解模型的相关信息,但是敌手可以访问目标模型,因此敌手可以通过精心设计的输入来根据模型输出推断模型的信息[24].
1.2.3 敌手能力
敌手能力是指敌手对训练数据和测试数据的控制能力,可以将敌手对数据的影响定义为诱发性的(对数据集有影响)或者探索性的(对数据集无影响).或者将敌手能力定义为敌手是否可以干预模型训练、访问训练数据集、收集中间结果等.根据敌手对数据、模型的控制能力可进一步将敌手分为强敌手和弱敌手[20].强敌手是指敌手可以一定程度地干预模型训练、访问训练数据集和收集中间结果等;而弱敌手则只能通过攻击手段获取模型信息或者训练数据信息[25].
1.2.4 敌手策略
敌手策略是指敌手根据自身的目的、知识和能力为了对目标达到最优的结果所采取的攻击方式.敌手策略通常在机器学习的不同阶段采用不同的攻击方式,如在训练阶段常采用的攻击方式为投毒攻击,在预测阶段常采取的攻击方式为对抗攻击、隐私攻击等.
2 机器学习中常见的安全及隐私威胁
机器学习目前广泛应用于数据挖掘[5-6]、计算机视觉[7-8]、电子邮件过滤[9-10]、检测信用卡欺诈[11-13]和医学诊断[14-15]、生物特征识别[26-28]、金融市场分析[29]等领域.机器学习在各个领域广泛使用的同时也带来了很多安全及隐私威胁,如在2019年Kyushu大学的Su等人[30]发现仅更改1个像素就可以欺骗深度学习的算法;研究人员还发现了可以干扰道路交通标志牌的方法,使自动驾驶的汽车进行错误标志牌划分[31-32];在2019年Heaven[33]发现对神经网络(neural network, NN)的对抗攻击可以使攻击者将自己的算法注入到目标AI系统中.
为了破坏机器学习模型,攻击者可以破坏其机密性(confidentiality)、完整性(integrity)和可用性(availability),这些性质构成了CIA安全模型.在该安全模型中[22],针对机密性的攻击目标是从ML系统中获取敏感数据,如攻击者想要知道某个特定的数据是否属于某个特定的训练数据集,如攻击者可以根据出院的信息(包含患者在各个医院呆过的时间、治疗方案等)[34]获取敏感数据.针对完整性的攻击目标比较多,如使目标分类错误(将“恶意类”分类为“良好类”)、针对性的错误分类(如将停车标志分类为限速标志等)、误分类(将某个类分到另一个类里面)、置信度降低(降低模型的置信度)等.针对可用性的攻击目标是降低ML系统的可用性,如在训练数据集中注入大量不良数据,使训练出来的模型无用.如果能够保证CIA模型的这3个性质,那么这个系统或者协议将是安全的.
机器学习主要分为训练和预测2个阶段.一般在训练阶段前面有数据收集、清洗等工作,在训练阶段和预测阶段中间有测试阶段等,但是主要的工作还是在训练和预测阶段.常见的安全及隐私威胁也在训练和预测阶段出现,如图1所示:
本文将从数据训练阶段和数据预测阶段分别论述机器学习中存在的安全及隐私威胁.其中,在训练阶段常见的安全及隐私威胁包含训练数据的隐私泄露和投毒攻击,在预测阶段常见的安全及隐私威胁包含对抗攻击、隐私攻击和预测数据的隐私泄露[22].
2.1 数据训练阶段存在的安全及隐私威胁
在数据训练阶段存在的隐私威胁主要为训练数据集的隐私泄露.在训练数据时,往往采用集中式学习(centralized learning)、分布式学习(distributed learning)或者是联邦学习(federated learning)的方式[20].其中,集中式学习[35]的方式就是将各方的训练数据集中到一台中央服务器进行学习;分布式学习[36]的方式就是将训练数据以及计算都分布到各个服务器节点进行学习,最后由中央服务器进行整合;联邦学习[37-39]的方式就是在保持训练数据集的分散情况下客户端与中央服务器联合训练一个模型.
联邦学习和分布式学习的方式类似,区别在于联邦学习没有数据收集阶段,分布式学习是首先进行数据收集,为了加快训练速度,将数据分发给多个服务器,然后由中央服务器协调进行迭代,从而训练出最终模型;而联邦学习是在各客户端本地进行学习得到子模型[40],然后交由中央服务器聚合得到最终模型.3种形式的学习如图2所示.
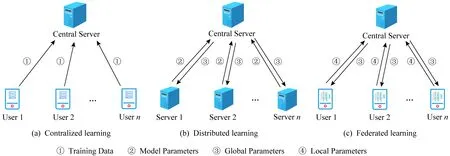
Fig. 2 The schematic diagram of three learning methods[20]图2 3种学习方式示意图[20]
根据这3种学习的方式,不论从数据收集还是训练方式的角度出发,在模型训练阶段都不可避免会造成数据隐私的泄露.
在数据训练阶段存在的安全威胁主要为投毒攻击(poisoning attack)[41],投毒攻击的例子可以追溯到2004年[42]和2005年[43]逃避垃圾邮件分类器的例子.投毒攻击就是敌手可以通过修改、删除或注入不良数据,改变原有数据集,使模型训练的结果产生偏差.最常见的投毒攻击就是使模型边界发生偏移,如图3所示:
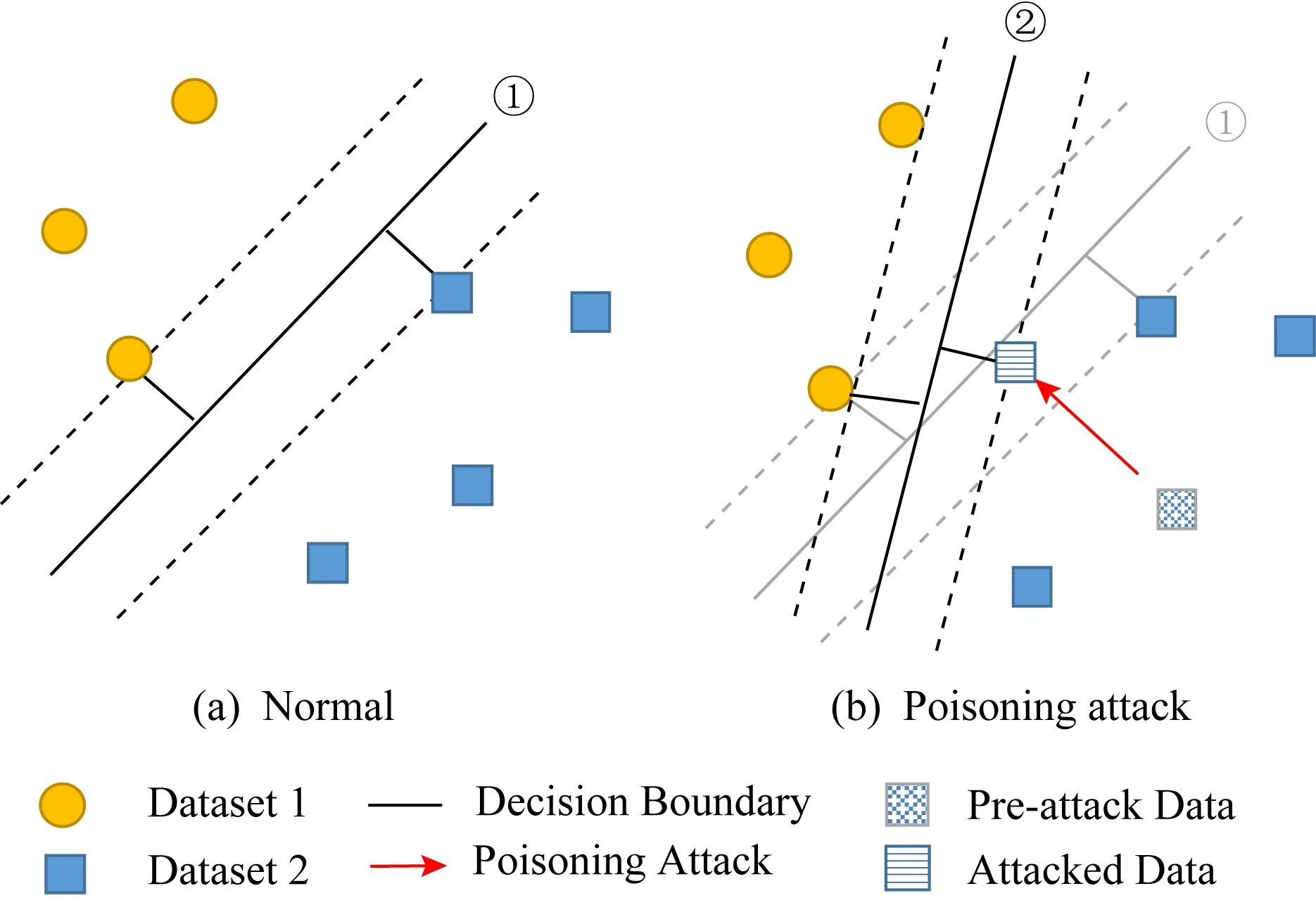
Fig. 3 The linear SVM classifier decision boundary[44]图3 线性SVM分类器决策边界[44]
2.1.1 训练数据的隐私泄露
训练数据的隐私泄露,就是在模型训练时可能发生数据泄露问题.目前大多数公司或者模型提供商都是使用集中式学习的方式训练模型,因此需要大规模的收集用户数据.但是对于收集用户数据时保护用户隐私没有一个统一的标准[21],所以在收集用户数据时可能会造成用户的数据隐私泄露的问题.在2018年图灵奖得主Goldwasser[45]在密码学顶级会议CRYPTO 2018上指出了安全机器学习中密码学的2个主要发展方向:分布式模型训练和分布式预测,通过安全多方计算(secure multi-party computation, SMC)实现隐私保护机器学习.
在大数据驱动的云计算网络服务模式下,Jiang等人在国际顶级安全会议ACM CCS 2018上提出了基于机器学习的密态数据计算模型[46],具体是由数据拥有者、模型提供商和云服务提供商组成.其中,数据拥有者对数据的拥有权和管理权是分离的;而云服务提供商也通常被假定为诚实且好奇(半可信)的,即在诚实运行设定协议的基础上,会最大程度发掘数据中的隐私信息,且该过程对数据拥有者是透明的.
使用机器学习对海量数据进行信息挖掘和学习,在安全模型增加模型提供商和云服务提供商后也变得更加复杂,这就需要考虑多方参与情形,构建隐私增强保护的数据计算模型和协议.
具体来说,在密态数据计算模型已经衍生出众多多方场景,例如:1)多方云服务提供商.数据拥有者通过秘密共享的方式将隐私数据信息分别分散到各个服务器(如亚马逊、微软、谷歌等多个服务提供商)上进行计算,各个服务器分别返回相应的计算结果,多个云服务提供商之间不进行主动合谋,最终由数据拥有者进行汇聚并得到结果.Shokri等人[47]提出了与不同数据持有者合作的机器学习协议、分布式选择性随机梯度下降算法,以便在训练数据不共享的前提下展开联合机器学习模型的训练.在学习模型和学习目标协调的情况下,参与者可以训练自己的局部模型,并有选择地在每个局部随机梯度下降阶段异步交换其梯度和参数.2)多方数据拥有者.当前的企业组织多采用协作学习模型[48]或联邦学习模型[49].比如,分发相关疾病疫苗时,医疗组织希望基于大数据利用机器学习确定高爆发的地区,这就需要不同区域医疗组织的数据,但往往处于法律和隐私考量,数据无法完成及时共享.
2.1.2 投毒攻击
投毒攻击有2个目标:1)破坏完整性;2)破坏可用性.破坏完整性目标就是敌手通过选择一个精心构造的恶意数据注入你的训练数据集中,通过这个精心构造的恶意数据,敌手可以得到一个“后门”,因此破坏完整性目标的投毒攻击也称为“后门”攻击.破坏可用性目标就是敌手通过注入很多不良数据到你的训练数据集,使得到的模型边界基本上变得无用[50].下面就2种不同的投毒攻击进行介绍.
2.1.2.1 破坏完整性目标的投毒攻击
对于破坏完整性目标的投毒攻击,也称“后门”攻击.对于此类攻击,模型拥有者可能无法发现模型已经被植入“后门”,但是敌手可以利用这个“后门”达到他的目的.例如一个敌手使分类器将含有某些特殊字符的文本划分为正常文本,那么敌手可以在自己编写的恶意软件中插入某些特殊字符完成任何攻击.这种攻击带来的后果非常严重,它甚至可以使ML系统完全被敌手控制[50].
Liu等人[51]提出了一种针对神经网络的攻击方法.该方法具有很强的隐蔽性,他们首先利用逆神经网络生成一个通用的触发器,然后用反向工程的训练数据重新训练模型,从而向模型注入恶意行为.恶意行为仅由带有触发器的输入激活.使用该攻击模型,可以造成严重的后果,如在自动驾驶领域可造成交通事故等[50].
2.1.2.2 破坏可用性目标的投毒攻击
破坏可用性目标的投毒攻击主要是使模型不可用.该类攻击主要是通过破坏原来训练数据的概率分布,使得训练出的模型决策边界偏离或者使得模型精度降低.在现实生活中,训练数据一般都是保密的,并且不会轻易被攻击者修改、删除等.但是因为数据的不断更新,模型也需要不断更新,这就使得攻击者可以注入大量的恶意数据,达到使模型不可用的目的.如生物特征识别、搜索引擎、电子邮件过滤、金融市场分析等领域的模型,需要进行定期更新,因此这类系统面临的破坏可用性的投毒攻击风险也更大[23].
Steinhardt等人[52]的研究表示,即使拥有强大的安全防御方案,在训练数据集中注入3%的中毒数据也可以使得模型的训练误差从12%提高到23%.目前已经存在针对情绪分析[53]、恶意软件聚类[54]、恶意软件检测[55]、蠕虫签名检测[56]、入侵检测[57-59]等投毒攻击的研究.
2.2 数据预测阶段存在的安全及隐私威胁
在模型训练完成后,通常会将训练好的模型用于预测特定的结果,以便人们做出高效的决策.因此,在预测阶段被敌手恶意攻击产生的后果往往会更加严重.预测阶段存在的安全及隐私威胁主要可以分为对抗攻击、隐私攻击和预测数据的泄露.其中,机器学习中的安全威胁为对抗攻击(adversarial attack),而隐私威胁则是隐私攻击(privacy attack).
2.2.1 对抗攻击
对抗攻击也称逃逸攻击(evasion attack)[19,60-61],是指敌手在模型原始输入上添加对抗扰动构建对抗样本(adversarial examples)从而使模型对预测结果或者分类结果产生偏差.例如,垃圾邮件发送者经常通过混淆垃圾邮件和恶意软件代码的内容来逃避检测,使得他们的垃圾邮件或者恶意软件代码是合法的.对抗攻击的过程中,选择和产生对抗扰动是非常关键的,对抗扰动一般是微小的并且有能力使模型产生错误输出.
2013年Szegedy等人[62]首次提出了对抗样本的概念;之后Goodfellow等人[63]最早提出了对抗攻击的防御方法,他们提出了一种快速梯度符号(fast gradient sign method, FGSM)的方法来生成对抗样本,FGSM用于扰动模型的输入;Moosavi-Dezfooli等人[64]基于迭代且线性近似的方案提出了一种计算对抗样本的方法DeepFool,他们利用DeepFool来更精确地生成对抗样本进行对抗训练可以有效提高分类器的鲁棒性;在2016年Papernot等人[65]提出了JSMA算法,JSMA构建一种针对性更强的对抗性样例;2017年Carlini等人[66]提出了一种更加高效的方法产生对抗样本;2020年Ru等人[67]将贝叶斯优化与贝叶斯模型选择结合优化对抗扰动和搜索空间的最佳降维程度,提高模型的鲁棒性;同年Zhou等人[68]提出了一种不需真实数据的替身模型训练的方法,他们表明该方法在黑盒攻击时具有较好的效果.
2.2.2 隐私攻击
隐私攻击是专注于隐私的一类攻击,包括模型的隐私和数据的隐私.其中模型隐私包括模型参数信息、模型结构、模型本身等关于模型的隐私信息,数据的隐私包括训练模型所用的数据集等.因此,总结常见的隐私攻击类型,可以将针对模型隐私的攻击称为模型提取攻击(model extraction attack),将针对数据隐私的攻击称为数据提取攻击(data extrac-tion attack)和成员推理攻击(membership inference attack).
2.2.2.1 模型提取攻击
模型提取攻击的目的就是敌手通过对已经训练好的模型进行应用程序接口(application programming interface, API)查询来非法窃取模型参数、模型结构,构建一个替代模型甚至非法获取模型本身的一种攻击方式[69],其流程图如图4所示.ML系统中的模型是非常有价值的一部分.首先,对于一个组织、机构或者公司来说,模型的训练过程可能涉及到大量的数据,这些数据可能是组织、机构或者公司通过很大的代价获得并处理的,然后经过大量的时间和金钱来训练模型[70].其次,敌手可以通过模型提取攻击来获取模型参数、模型结构等信息,敌手获得这些信息之后可以更加方便地实施投毒攻击、对抗攻击等恶意攻击.因此,一旦模型泄露,可能对这些组织、机构或者公司带来巨大的损失.
Tramer等人[69]证明了模型提取攻击对支持向量机、决策树、神经网络在内的大多数算法都有非常好的效果,并且表明对于1个N维模型,理论上只需要通过N+1次查询就能够提取该模型.Shi等人[71]通过深度学习高精度地提取了朴素贝叶斯和SVM分类器,并可以通过获取到的信息重构一个等价的模型.Wang等人[72]提出一种针对超参数攻击的方法,通过实验表明,该方法使用了线性回归、逻辑回归、支持向量机和神经网络等算法,成功获取模型的超参数.
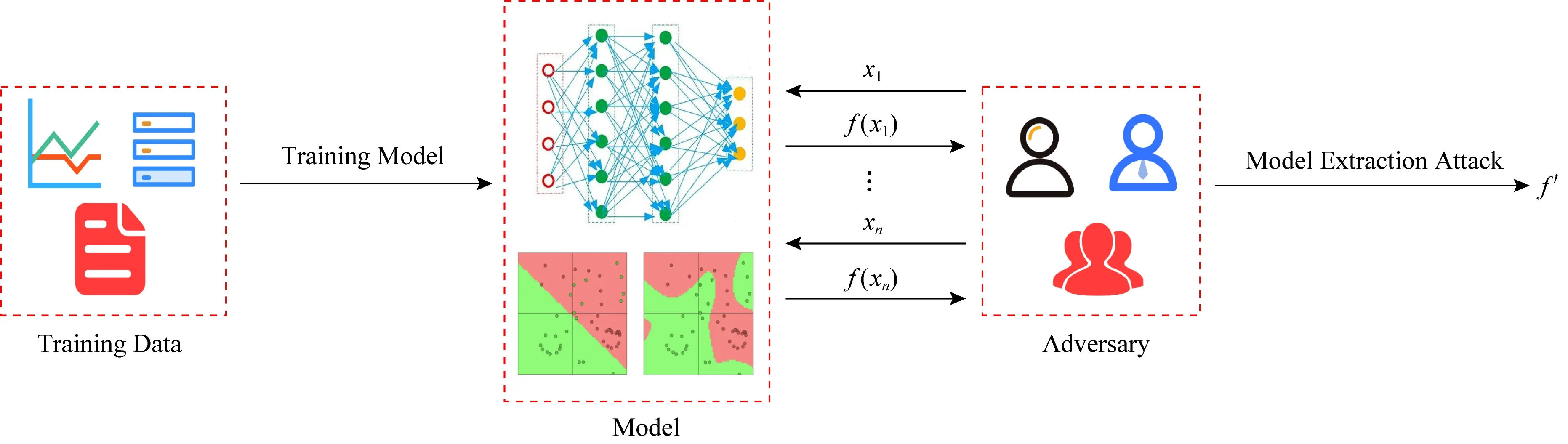
Fig. 4 The diagram of model extraction attack图4 模型提取攻击流程图
2.2.2.2 数据提取攻击
数据提取攻击也称模型逆向攻击(model inver-sion attack),由Fredrikson等人[73]首次提出,是指敌手通过访问模型API,通过一系列的查询来获取模型训练数据里的隐私数据的一种攻击手段.数据提取攻击造成的隐私数据泄露可能会造成巨大的威胁,如针对训练的模型提取了病人的基因组信息[74],并且可以使药物错配,从而导致生命威胁.
Fredrikson等人[73]通过训练好的模型,成功通过数据提取攻击重构了人脸图像;Ateniese等人[75]构建了一种分类器使它可以攻击其他分类器并获取训练数据;Song等人[76]证明了训练好的模型会“记忆”大量隐私信息,如果存在恶意ML算法的模型训练者,那么模型可能泄露训练数据集的信息;Carlini等人[77]描述了一种可以提取隐私信息的算法,他们通过不断查询模型来获取如信用卡号码、ID号码等隐私信息.
2.2.2.3 成员推理攻击
成员推理攻击指敌手通过访问模型API获取足够数据,然后构建一些“影子”模型来模仿目标模型,最后通过构建一个攻击模型来判断某些特定的数据是否在训练数据集中[34].成员推理攻击也可能造成个人敏感数据的泄露,如Shokri等人[34]通过成员推理攻击成功判断了特定病人是否已出院.
Pyrgelis等人[78]对集合数据发起成员推理攻击,从而确定特定的用户是否在集合数据中;Yeom等人[79]的研究表明,不管模型稳定的算法还是容易过度拟合的算法,都容易受到成员推理攻击;Song等人[80]设计了一种可审计的自然语言文本深度学习模型,用于检测是否使用特定用户的文本数据来训练预言模型.Truex等人[81]证明了ML模型何时以及为什么容易受到成员推理攻击;Hayes等人[82]通过生成对抗模型(generative adversarial network, GAN)检测过拟合和识别出训练数据中的一部分,并利用鉴别者的能力了解分布的统计差异,在白盒攻击情况下,100%推断出哪些样本用于训练模型;在黑盒攻击情况下,成功率也达到了80%.
2.2.3 预测数据的隐私泄露
预测数据的隐私问题与训练阶段的隐私问题类似,主要是数据的隐私泄露,但预测数据的泄露主要发生在人们利用模型进行预测时.对于恶意的攻击者,可能会获取到用户的隐私信息.目前有很多工作都考虑了预测数据的隐私问题,接下来的隐私保护方法涉及到该类介绍,在此不再赘述.
2.3 小 结
本节从训练阶段和预测阶段2个角度出发,分别介绍了机器学习过程中常见的安全隐私威胁.如表2所示,总结了机器学习中常见的攻击手段所破坏的CIA安全模型的性质.在训练阶段中,训练数据的隐私泄露破坏了机器学习CIA安全模型的机密性;投毒攻击则破坏了其完整性和可用性,在一定程度下可能致使目标模型偏离甚至完全错误导致模型无用.在预测阶段中,对抗攻击则是通过添加对抗样本的方式破坏模型的完整性,导致模型可以分类错误的样本;隐私攻击和预测数据的隐私泄露破坏了CIA安全模型的机密性,其中隐私攻击可以在预测过程中泄露模型及训练数据的隐私.对于影响CIA性质中机密性的情况,可以归结为机器学习中的隐私威胁.

Table 2 The Nature of the CIA Affected by the Attack表2 攻击手段所影响的CIA性质
3 机器学习中常见的安全防御方法
3.1 针对投毒攻击的防御
投毒攻击常见的防御方法有异常检测、对模型进行准确性分析等[50].投毒攻击是在训练数据中注入异常数据,所以我们可以对数据进行分析,检测数据的分布情况,从而分离出异常数据[83].Baracaldo等人[84]于2017年提出了一种使用数据集中数据点的来源和转换的上下文信息来识别有毒数据的方法,从而使在线和定期再训练的机器学习应用程序能够在潜在的使用投毒攻击的敌对环境中使用数据集.
但是,攻击者可能生成与真实数据分布非常相似的异常数据,最后可以成功误导模型.Koh等人[83]提出了3种新的攻击方法,它们都可以绕过常见的投毒攻击防御手段,包括常用的基于最近邻的异常检测器、训练损失(training loss)和奇异值分解等.他们设计的攻击仅仅增加3%的有毒数据,就可以成功地将垃圾邮件检测数据集的错误率从3%增加到24%,将IMDB情感分类数据集的错误率从12%增加到29%.
因此,我们可以在训练新添加的样本数据时对模型进行准确性分析.如果收集的输入是有毒的,那么它最终的目的是破坏模型在测试集上的准确性.通过在将训练的新模型投入到生产环境之前对模型进行分析,我们可以避免投毒攻击给我们带来的影响.Suciu等人[85]提出的FAIL模型就是使用这种方法.
3.2 针对对抗攻击的防御
对抗攻击的防御方法有对抗训练[86-88]、梯度掩码[89-90]、去噪[91]、防御蒸馏[92-94]等.对抗训练(adver-sarial training)是通过在训练数据中引入对抗样本来提升模型的鲁棒性,是对抗攻击最有效的防御方式之一.梯度掩码(gradient masking)就是通过将模型的原始梯度隐藏起来达到抵御对抗攻击的目的.去噪(denoising)则是在输入模型进行预测之前,先对对抗样本去噪,尽可能地使对抗样本恢复成原始样本,从而提高模型鲁棒性.防御蒸馏(defensive distillation)首先根据原始样本训练一个初始的神经网络,得到一个概率分布,然后再根据这个概率分布构建一个新的概率分布,最后利用整个网络进行预测或分类,从而达到抵御对抗攻击的目的.
4 机器学习中常见的隐私保护方法
隐私保护机器学习(privacy-preserving machine learning, PPML)方法最早可追溯至2000年,Lindell等人[95]提出了允许两方在不泄露自己隐私的前提下,通过协作对联合数据集进行提取挖掘的方法,Agrawal等人[96]允许数据拥有者将数据外包给委托者进行数据挖掘任务,且该过程不会泄露数据拥有者的隐私信息.早期关于PPML的研究工作主要集中在决策树[95]、K-means聚类[97-98]、支持向量机分类[99]、线性回归[100-101]、逻辑回归[102]和岭回归[103]的传统机器学习算法层面.这些工作大多都使用Yao[104]的混淆电路(garbled circuit, GC)协议,将问题化简为线性系统的求解问题,但这不能推广到非线性模型,而且需要比较大的计算开销和通信开销,因此缺乏实施或评估案例.
在机器学习训练过程中,模型提供商会对一些训练数据进行记录,而这些训练数据往往会涉及到用户个人的隐私等信息.在训练阶段,机器学习基于训练数据集展开模型训练,基于所学习数据的内在特征得到决策假设函数,而预测阶段目标模型的有效性则依赖于属于同一分布的训练数据集和预测数据集,但是攻击者仍可以通过修改训练数据的分布从而实施目标模型的攻击,在基于ML的医疗健康系统中,攻击者不仅可以窃取病人隐私还可以发起恶意数据注入或数据修改攻击,从而对病人的用药剂量产生影响.在机器学习预测过程中,攻击者无法修改训练数据集,但仍可以通过访问目标模型从而获得有效的参数信息发起攻击,使模型在预测阶段发生错误.
因此,采用隐私保护的手段保护数据和模型的安全是必不可少的,本节介绍密码学中保护机器学习中隐私的常见技术,主要包括同态加密技术、安全多方计算技术和差分隐私技术.相关工作的对比如表3所示:
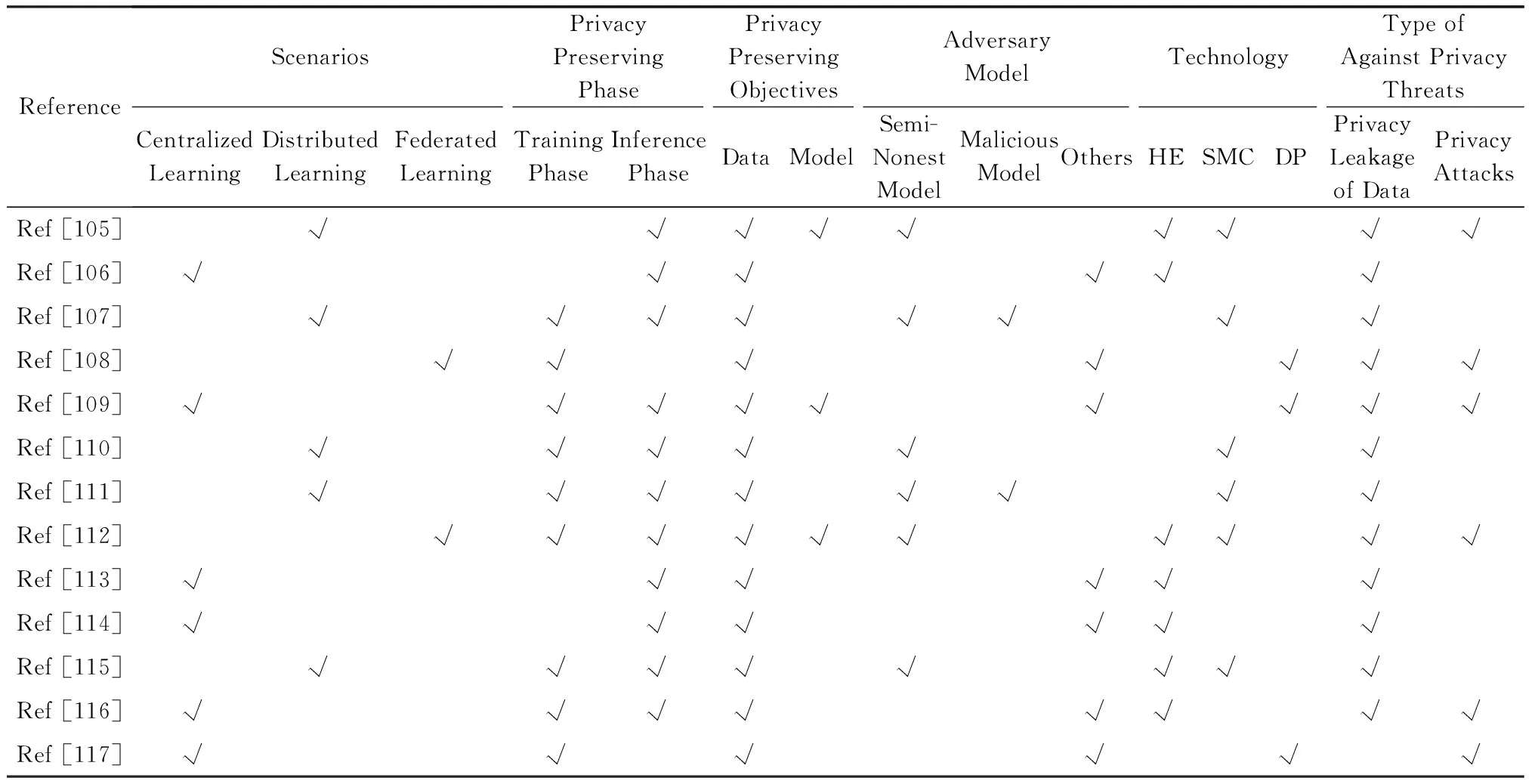
Table 3 The Comparison of the Related Work表3 相关工作的对比
4.1 同态加密技术
同态加密技术(homomorphic encryption, HE)允许直接在密文上做运算,运算之后解密的结果与明文下做运算的结果一样[118].同态加密技术常用于保护隐私的外包计算和存储中,主要是首先将数据加密,然后将加密的数据发给云进行存储或者计算,云直接在密态数据上进行操作,这样既不会泄露隐私又满足了需求.同态加密技术又可以分为全同态加密(fully homomorphic encryption, FHE)[119-125]、部分同态加密(partially homomorphic encryption, PHE)[126-127]、类同态加密(somewhat homomorphic encryption, SHE)[119-120,128-129]、层次型同态加密技术(leveled homomorphic encryption, LHE)[130-131]等.FHE可以计算无限深度的任意电路;PHE支持评估仅包含一种门类型的电路(如加法或者乘法);SHE可以计算加法和乘法电路,但只支持有限次的乘法;LHE支持对有界(预设)深度的任意电路进行计算.不同加密方案适用的场景如表4所示.
Gentry基于理想格,构造了第一个理论上可行的FHE方案[119-120].该方案同时支持对密文上的加法和乘法运算,并可以构造执行任意计算的电路.这种构造首先设计了一个SHE方案,它的深度是有限的,因为每个密文在某种意义上都是有噪声的,而且这种噪声随着密文的增加而增加,直到最终噪声使得得到的密文无法辨认.Gentry 之后通过改进该方案提出自举技术,使得SHE可以转换为FHE.之后也有很多人在Gentry的方案上进行改进,提出了更快、噪声更少的SHE方案和可以不使用自举技术就能评估有界(预设)深度电路的LHE方案[130-131].使用广泛的RSA[126]和ElGamal[127]等加密系统都是PHE方案.
接下来主要介绍全同态加密技术.全同态加密技术一直被认为是进行隐私保护机器学习的一项重要技术.FHE主要分为层次型全同态加密技术(leveled fully homomorphic encryption, LFHE)和自举型同态加密技术(bootstrapping full homomor-phic encryption, BFHE)[129].其中LFHE即前文提到的LHE.

Table 4 The Application Scenarios of Different Homomorphic Encryption Schemes表4 不同同态加密方案对应的场景
2016年Gilad-Bachrach等人[113]提出了Crypto-Nets可以借助神经网络对加密数据进行相应推断,此后也有使用层次型同态加密方案对预先训练好的卷积神经网络(convolutional neural network, CNN)模型提供隐私保护性质,但是层次型同态加密技术会使得模型精度和效率严重下降.同时,模型中平方级的激活函数会被非多项式的激活函数和转换精度的权重代替,导致推导模型与训练模型得到的结果会有很大不同.此后,Hesamifard等人[114]采用低阶多项式近似逼近的方法对CryptoDL方案进行了改进,Chabanne等人[132]采用近似的激活函数和归一化操作改进加权值.Chillotti等人[133]、Bourse等人[134]则分别提出了相应的自举FHE方案,该方案均比层次型同态加密方案效率更高,值得注意的是自举FHE方案可以更加贴近实际地对单个实例进行预测.Jiang等人[46]则提出了一种基于矩阵同态加密的通用算术运算方法,提出在一些用户提供的密文数据上云服务提供商进行模型训练,该方法可以将加密模型应用到更新后的加密数据上.2019年Zheng等人[48]利用门限部分同态加密实现了Helen系统,该系统能够允许利用多个用户的数据同时训练模型,但不泄露数据.与之前的方案相比,Helen能够抵御m方中m-1方都为恶意的对手.但是该系统不能抵御投毒攻击、数据提取攻击和拒绝服务攻击.
尽管从理论层面认为FHE技术可以进行任意计算,但受当前相关实际方案约束,FHE普遍仅能支持整数类型的数据;同时,电路深度需要固定而不能进行无限次的加法和乘法运算;除此之外,FHE技术不支持比较运算操作.虽然,目前存在一些实数上计算并有优化的FHE方案,但数据规模大幅扩张、计算负载不断加剧、非线性激活函数的拟合计算误差等原因导致FHE的方案效率无法得到进一步提升.由此可见,FHE技术与机器学习算法的简单结合,将无法保证相关机器学习算法对密文数据进行操作.
4.2 安全多方计算技术
在基于安全多方计算技术的隐私保护机器学习[45]方面,SMC允许互不信任的各方能够在自身私有输入上共同计算一个函数,其过程中不会泄露除函数的输出以外的任何信息.但是,传统的SMC协议往往需要较为庞大的计算量和通信复杂度,导致其难以在实际机器学习中得以大规模部署.目前,常见的基于SMC的PPML解决策略有:1)基于混淆电路、不经意传输等技术的隐私保护机器学习协议,并执行两方SMC协议来完成激活函数等非线性操作计算;2)基于秘密共享技术允许多方参与方参与机器学习网络模型训练或预测,且该过程不会透露数据或模型信息.SMC主要方案的发展历程如图5所示.
4.2.1 两方隐私保护机器学习协议
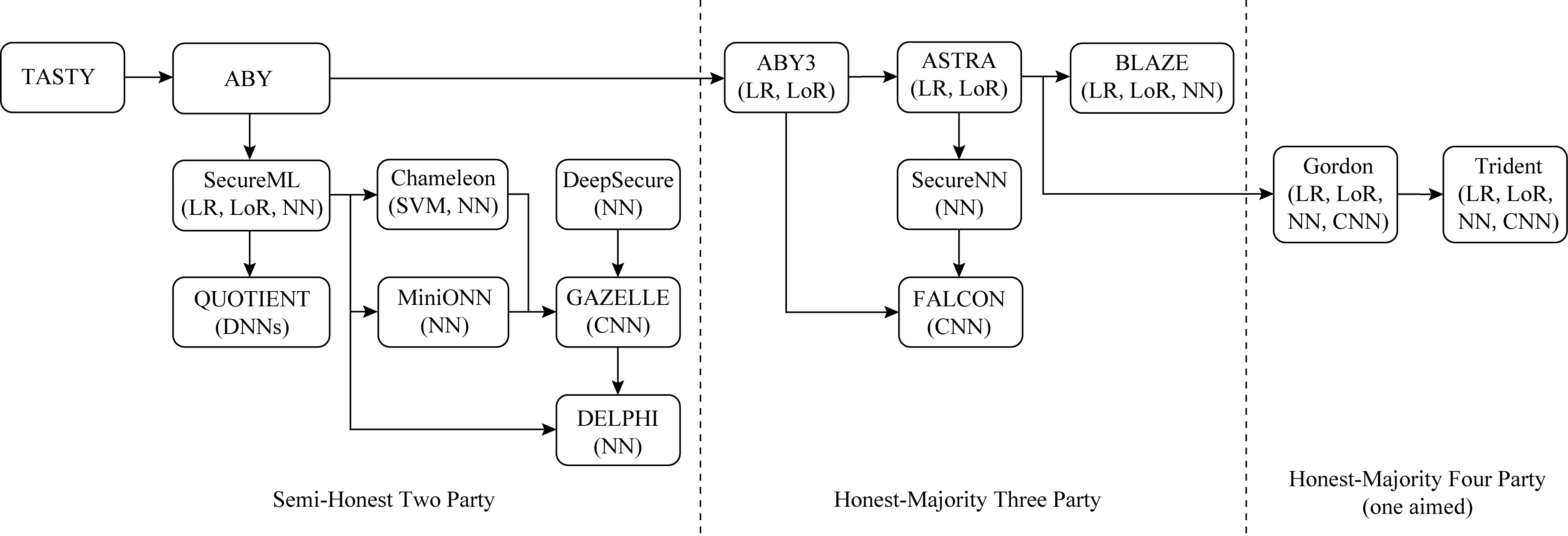
Fig. 5 Development of privacy preserving machine learning based on secure two-partymulti-party computation图5 基于两方安全多方计算的隐私保护机器学习发展历程
典型的两方隐私保护机器学习协议包括TASTY[135],ABY[136],SecureML[115],MiniONN[105],DeepSecure[137]和 GAZELLE[138]等.其中,ABY[136]利用高效乘法协议、快速的转换技术以及预处理的密码操作,构造用于两方计算环境的基于算术共享、布尔共享和Yao混淆电路的安全计算方案.值得注意的是,SecureML[115]是在两方计算环境中训练神经网络的隐私保护方法,该方案基于线性回归、逻辑回归和神经网络等模型提出一种高效的截断协议,相较于ABY提出的PPML算法更加高效.ABY和SecureML则均利用Beaver所提出三元组技术来实现部分乘法操作,但方案通信成本仍不理想.由于三元组会降低协议的效率,Chameleon[139]利用一个半诚实的第三方替代三元组从而减少了三元组的使用,另外,该方案基于ABY实现了加法秘密共享、GMW和GC的混合,大幅改进ABY的实用性和可扩展性.最近,QUOTIENT[140]和DELPHI[141]则分别基于两方安全的神经网络完成对数据的训练和预测.这些两方的协议主要考虑在非共谋服务器情况下的安全保障需求:假设云服务器是诚实且好奇的被动攻击模型,在云服务器互不合谋情况下保证数据的安全性与机器学习方案的可用性.
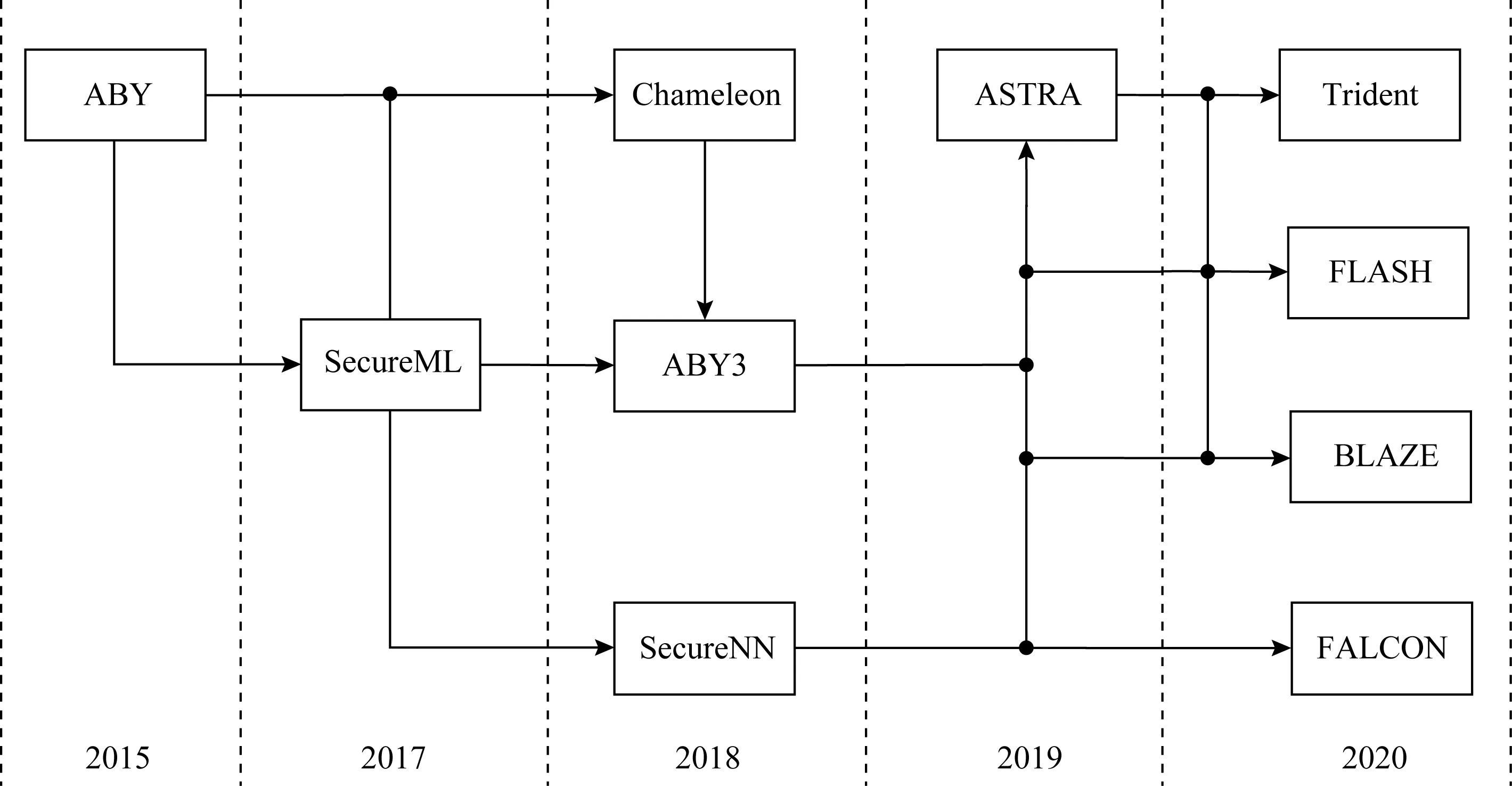
Fig. 6 Development of privacy preserving machine learning schemes involving multi-party图6 多方参与的隐私保护机器学习相关方案的发展历程
为免受半可信参数服务器的攻击,MiniONN[105]基于简化的同态加密技术并将其应用于交换权重和梯度问题,把原始神经网络转换为遗忘神经网络再进行网络模型训练,并将混淆电路作为近似非线性激活函数.DeepSecure[137]基于Yao混淆电路[104]对深度学习模型上的加密数据进行计算和推理,并完成相应的安全证明.Juvekar等人[138]指出MiniONN,DeepScure等工作表明同态加密在矩阵向量乘法具有明显的优势,但在线性运算方面并不明显.需要注意的是,虽然这些混合协议可以提高识别率,但带宽和网络延迟方面的效率并不理想.技术上来说,这些协议均是采用同态加密方法对标量乘法进行计算,采用安全多方计算对激活函数进行计算.
4.2.2 多方隐私保护机器学习协议
利用传统分布式机器学习算法[142-143],典型的多方参与的PPML方案有ABY3[107],SecureNN[110],ASTRA[144],FLASH[145],Trident[146],BLAZE[147],FALCON[111],如图6所示.
ABY3[107]提出一种在半诚实环境和恶意环境下的新方案,可以完成三方之间的算术共享、布尔共享和Yao共享,它对SecureML中的近似定点数乘法进行改进,使其得以在三方环境下可以使用,并相应设计了一种计算分段多项式函数的协议.最终在两方和三方的情况下分别将效率提升93倍和8倍,但是SecureNN[110]仅考虑了神经网络训练方案的设计.ASTRA[144]基于ABY3考虑了半诚实环境和恶意攻击环境,提出一种新的更加安全的三方PPML协议,它构建了一个公平的重构协议,解决了发送者在无广播频道情况下通过私人频道向其他参与方发送不同消息所可能导致的混乱,保证了当且仅当诚实方接收到输出时,恶意攻击方才会接收到输出.对于分类任务,ASTRA[144]充分运用秘密共享方案中的不对称性性质,放弃SecureML和ABY3中一些消耗较高的混淆电路或并行前缀加法器,最终提出一种新的安全比较协议.在半诚实的环境中,ASTRA则是将33%的整体通信开销转移到离线阶段,而在恶意环境基于高效的点积协议进一步提升在线通信效率.然而,ABY3[107],SecureNN[110],ASTRA[144]等方案均是专注于半诚实环境下的PPML框架,进行相关点积计算是与向量大小成线性关系,在恶意环境下向量点积、最高标记位的提取和截断的效率都会不同程度地降低.
虽然,ABY3和SecureNN提出使用Abort的安全构建组件,且ASTRA[144]将Abort的安全性提升到公平性,FLASH[145]则进一步实现了保证输出传递的最强安全概念(无论对手的行为如何,各方都获得输出)的四方PPML框架,且健壮性仅需要对称密码原语来实现.与文献[148]方案不同,FLASH不需要使用数字签名、广播等密码原语,它在协议中引入一个新的诚实参与方大大提升协议效率.Trident[146]提出了最多可以容忍一方腐败的四方PPML协议,其中第四方在除输入共享和输出重构的阶段外,所有的在线阶段均为非活动状态.在使用新的秘密共享方案后,Trident方案中25%的在线通信阶段部分转移到了离线阶段部分,在线效率得以充分提升.BLAZE[147]则是效率较高的一个PPML协议,在3个服务器的情形下可以容忍1个恶意腐败方的存在,并得到了更强的公平性保证(所有诚实方和恶意攻击方都获得相同的输出),基于所提出的点积协议、截断和位操作方法,方案效率比ABY3和ASTRA等方案更加高效[149].因此,仅有少数PPML方案考虑到了恶意攻击环境,当恶意攻击者存在情况下,还需考虑协议的公平性与一致性.
2020年微软、普林斯顿大学、以色列理工学院和Algorand基金会的研究人员基于SecureNN和ABY3推出了一个名为FALCON[111]的框架.该框架支持批归一化(batch normalization, BN)并且保护隐私的安全框架,它可以支持训练像AlexNet和VGG16这样的大容量网络.FALCON只使用算术秘密共享而避免使用转换协议(在算术、布尔和乱码电路之间)来实现针对非线性运算的恶意安全协议.
这些方案的详细比较如表5所示:
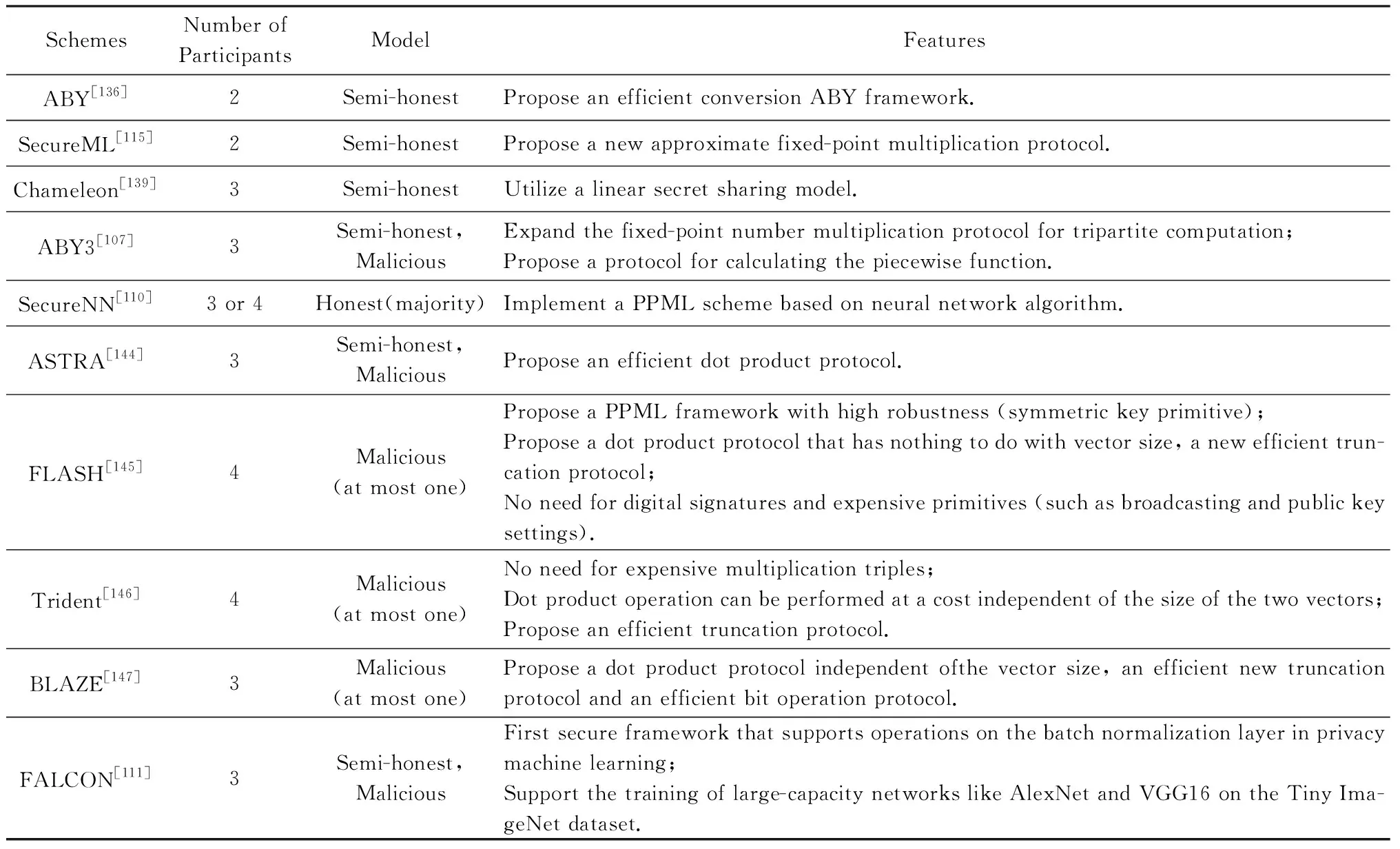
Table 5 Comparison of Privacy Preserving Machine Learning Schemes Based on Multi-party Computation表5 多方参与的隐私保护机器学习相关方案的具体比较
4.3 差分隐私技术
差分隐私技术(differential privacy, DP)是通过添加噪声来保护隐私的一种密码学技术[150],因为加入少量噪声就可以取得较好的隐私保护效果,因此从它被Dwork等人[150]提出来就被广泛接受和使用.相比于前面2种密码学技术,差分隐私技术在实际场景中更易部署和应用[151].在机器学习中一般用来保护训练数据集和模型参数的隐私.DP技术主要分为中心化差分隐私技术和本地化差分隐私技术,中心化差分隐私技术主要采用拉普拉斯机制[150](Laplace mechanism)、指数机制[152](exponential mechanism)等方法,而本地化差分隐私技术则采用随机响应[153-154](randomized response)方法.差分隐私技术保护用户隐私查询过程如图7所示:
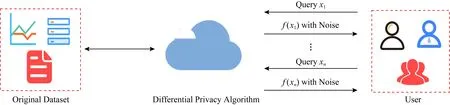
Fig. 7 Query process of schematic diagram of the differential privacy technology图7 差分隐私技术查询过程
Dwork等人[150]提出的差分隐私技术在数据发布[155-156]、数据分析[157]、数据查询[158-159]、数据挖掘[150,152]等领域都受到了广泛的应用.Bindschaedler等人[160]提出了一种合理可否认性(plausible deni-ability)的标准,保证了敏感数据的隐私.Huang等人[117]提出了一种基于差分隐私的ADMM分布式学习算法DP-ADMM,该算法在迭代过程中将近似增强拉格朗日函数与时变高斯噪声相结合,保证了良好的收敛性和模型准确性.Wang等人[108]提出一种新的本地差分隐私机制来收集数值属性,并将其扩展到可以同时包含数字和类别属性的多维数据.他们实验证明,该算法可支持许多重要的机器学习任务,并比目前方案更加有效.
4.4 小 结
本节介绍了机器学习中常见的3种隐私保护技术,即同态加密技术、安全多方计算技术、差分隐私技术.并且根据各个技术的发展介绍了一些典型的隐私保护机器学习算法.随着深度学习的兴起,人工智能也迎来了发展契机,但是随着人工智能的广泛应用,其安全与隐私问题也越来越引起人们的关注,安全与隐私问题已经成为阻碍人工智能发展的绊脚石.
同态加密技术、安全多方计算技术和差分隐私技术是目前使用的比较广泛的技术,从通信、算力、隐私等多个角度考虑,这3种隐私保护技术各有本身适用的计算场景.同态加密技术具有计算开销大、效率低、可用性差、使用场景广的特点,它适合集中式学习、外包计算等场景;安全多方计算技术具有可用性高、通信开销大、效率低的特点,它适合分布式学习、联邦学习等场景;差分隐私技术具有计算开销小、效率高、可用性差的特点,它适合训练数据的收集、模型参数保护等场景.具体如表6所示:

Table 6 Applications Scenarios of the Three Privacy Preserving Technologies表6 3种隐私保护技术适合应用的场景
5 总 结
综上所述,随着机器学习算法和人工智能应用领域的研究逐步深入,机器学习算法的特殊性给用户数据和网络模型的隐私保护带来巨大挑战,迫切需要进一步考虑更高的安全及隐私威胁,特别是可以实施恶意攻击的攻击者.
针对安全威胁,我们还需要进一步探索针对投毒攻击、对抗攻击等攻击手段的防御技术,提高模型的鲁棒性,研究更强攻击的防御手段.针对隐私威胁,全同态加密一直被认为是隐私保护机器学习的首选技术,但由于其具有数据扩张、计算负载、激活函数拟合误差等不利因素,使得基于安全多方计算的隐私保护机器学习得到了迅速发展.然而,现有隐私保护机器学习方案往往假设云服务器是诚实且好奇的被动攻击模型,考虑在云服务器互不合谋情况下数据的安全性与机器学习的可用性;并且,在更高的安全等级推广到多方场景下,还需考虑存在恶意攻击者情形下的公平性与一致性.因此,针对目前所提的方案,还需要再提高精度、效率,降低误差,并考虑更强的威胁场景,如恶意场景等.因此,未来的研究方向建议如下:
1) 建立完善统一的安全评估标准.对于大部分隐私数据,可在源头上控制好这些数据的使用范围和收集过程.但是由于目前缺乏合理完善的安全评估标准,各类机构对于隐私数据的使用和收集都没有统一的标准,因此不可避免地会造成隐私的泄露[21].建立完善统一的安全评估标准势在必行、刻不容缓.
2) 研究具有更强鲁棒性的隐私保护的机器学习模型.随着如对抗攻击、投毒攻击等攻击手段的发展,普通模型已经不能够满足隐私需求,模型的泄露给组织、机构带来的损失不可估量.研究能够抵抗更强攻击手段的高鲁棒性机器学习模型是未来的工作.
3) 考虑更强威胁场景的机器学习方案.分布式、联邦学习的场景是目前的趋势,但是对于大多数分布式的方案来说,它们都是考虑半诚实的威胁模型.因此需要将目前的半诚实模型推广到恶意模型,使机器学习方案在恶意攻击者存在的情况下依然能够保持公平性和一致性.
4) 提高现有方案的精度、效率.目前的大部分隐私保护方案都是基于同态加密、安全多方计算和差分隐私的,目前这几类技术的通信、计算等开销比较大,这大大降低了算法的效率,带来了不必要的资源浪费.并且这些方案存在精度丢失的问题,因此研究更加高效、精度更高的隐私保护方案是一个重要的研究方向.
