守正创新
——近60年武汉大学信息管理学院学术论文研究主题的演变
2020-11-10曹树金岳文玉
曹树金,岳文玉
0 引言
春华秋实,武汉大学信息管理学院(以下简称“学院”)迎来百年华诞。经历百年,学院已发展成为我国规模最大、实力最强的信息管理学科教学和研究基地。回顾学院发展,我们深深感受到她是一个能够创造奇迹、化一般为神奇的学术圣地。并不聪明绝顶的学生们,经过她的培养,可以大比例地成为栋梁之材,神奇的“7901”(指武汉大学79级图书馆学专业班,该班因出了较多的学界业界人物而在本领域闻名)就是一个例子。她为什么有此能耐?“守正创新”可能就是答案之一。为此,笔者从学院师生所发表学术论文的主题发展角度呈现她守正创新的特征。
从文献中挖掘研究主题和发展趋势,一般有两类方法[1]:基于共词分析的主题挖掘方法和基于概率模型的主题挖掘方法。共词分析法的主要原理是统计关键词在文献中同时出现的次数,构建共词矩阵进行聚类,以坐标或网络形式进行可视化,进而分析研究领域的主题结构和研究热点,具有操作灵活和易于解读的优点,应用于多个领域。Wei Wen-Juan等[2]利用共词分析法分析人类神经干细胞的研究主题趋势和知识结构;吴桐等[3]对中国知网收录的我国医院财务管理文献进行共词聚类分析,得到4个研究类团,在此基础上分析医院财务管理存在的问题及其解决方案;李纲等[4]从共词分析过程中术语的高词频选择等方面对共词分析的优缺点做主客观评价,为该方法的完善提供借鉴。
在基于概率模型的主题挖掘研究中,LDA主题模型有较强的主题识别能力,因而在对不同载体文本语料的主题挖掘研究中受到普遍关注。Zhu Lin等[5]运用社会网络分析和LDA模型分析医疗不良事件的潜在行为,得出良好的信息共享和反馈机制能预防医患问题;Luo L X等[6]提出结合LDA模型和卷积神经网络的文本舆情分析方法,以提高网络舆情分析的性能;刘雅姝等[7]选取网络舆情突发事件评论数据构建知识图谱,利用LDA模型对图谱中实体的话题属性进行划分,以多维视角追踪舆情话题演化情况;关鹏等[8]结合LDA和生命周期理论,提出主题语义演化分析方法,深度揭示学科领域发展过程中继承、分裂和融合的语义演化模式。
综上所述,基于LDA主题模型的研究多从全局语料库进行主题抽取,局限是未能深入揭示学科领域研究主题内容的演变。笔者结合共词分析法,在利用LDA模型主题挖掘的基础上进行高频关键词共词分析,深入探究热点主题不同历史时期的演变过程。本文通过系统采集1958~2019年CNKI数据库收录的学院论文,探析学院学科领域研究热点的演变,探寻学院发展至今不断闪耀的学术光芒。
1 相关理论
1.1 LDA主题模型
潜在狄利克雷模型(latent Dirichlet allocation,LDA)的本质是基于“文档-主题-词”的三层贝叶斯概率模型,是可实现文本聚类的主题生成模型。其生成过程为:首先,基于语料库中的每篇文档,从主题分布中抽取一个主题;接着,从该主题的词项分布中抽取一个词;最后,重复以上流程直至遍历文档中的所有词。通过模型训练,形成从文本到主题、从主题到词的多项式分布[9]。每个词在一篇文档中出现的概率[8]如下:
p(特征词|文档)=∑主题p(特征词|主题)×p(主题│文档)
论文主题提取是论文主题演化研究的基础。LDA 模型具有高效的抽样推理算法和模型泛化能力,将该方法应用于学术论文研究的主题挖掘有助于在文档语义层面实现海量文献基于主题的文本建模,对学术论文主题的提取与演化分析更精确。
1.2 主题发现相关概念
(1)主题隶属概率。依据LDA模型的主题识别结果,能得出不同主题在每篇文献下的主题概率分布,其作为度量标准用来衡量文献的研究主题[10]。若某主题在该文献呈现较高的主题隶属概率,说明该文献研究内容与此主题有较大关联;反之,说明该文献研究内容与此主题联系较弱。通过LDA模型生成文档主题隶属概率θd,k表示,θd,k代表第d个文档中主题k的概率。
(2)主题热度。通常用主题与文档间的关联程度反映主题热度,同一主题可能在各个文档中呈现不同的主题隶属概率,同一文档中各个主题的隶属概率也各不相同。一个主题在不同文档中的主题隶属概率总和相较于其他主题越高,则表明其热度越高。主题热度的演化分析即通过计算某一主题在不同时间段中的主题热度来反映随时间变化的主题热度趋势。主题热度的计算方法[11]为:计算某一主题在所有文档中主题隶属概率的平均值。主题Tk在某一时间段的热度可表示为:

其中,∣D∣表示文档集合D 中的文档数量,d表示文档集合中的一篇文档,θd,k表示主题Tk出现在文档中的主题隶属概率。
2 研究设计
2.1 主题抽取与演化分析框架
利用LDA主题模型和共词分析法进行主题抽取与演化分析的流程可概括为3个阶段:一是数据采集与预处理阶段;二是构建LDA主题模型和计算阶段;三是主题分析和可视化阶段。整体流程见图1。

图1 主题抽取与演化分析框架
(1)数据采集与预处理阶段。数据采集来源于CNKI数据库,LDA模型中的主题由特征词概率构成,需要对采集的文本进行预处理,包括中文分词、删除停用词、加入用户自定义词典等。
(2)构建LDA主题模型和计算阶段。有3个步骤:一是在建模前设置适用的参数和确定最优主题数目;二是对原始语料文本进行LDA建模,得到模型文档-主题概率分布、主题-词项概率分布等输出结果;三是过滤原始主题,删掉无意义主题。
(3)主题分析与可视化阶段。基于LDA主题模型输出的文件,进行热点主题分析和主题演化分析。一方面依据主题强度分析不同时间段内的热点主题,挖掘学院不同时期研究的热点领域;另一方面,引入时间因素,绘制不同主题强度变化的折线图,进行热点主题演化趋势可视化。在进行主题演化趋势分析时,结合共词分析法,利用社会网络分析软件Ucinet 和Netdraw揭示不同主题内高频关键词的共词关系,从可视化角度来定量探讨热点主题在不同时期的研究热点。
2.2 数据采集与预处理
2.2.1 数据采集
1920年代初韦棣华、沈祖荣等共同创办武昌文华大学图书科,标志着我国近代图书馆学产生,1929年图书科单独建校为武昌文华图书馆专科学校[12]。在之后的研究发展中,创办《文华图书馆学专科学校季刊》,出版《普通图书编目法》(黄星辉,1934)、《标题总录》(沈祖荣,1938)等图书馆学专著,在图书馆界引起反响。1956年成立武汉大学图书馆学系,成为我国图书馆学教育的重要基地。本文选用CNKI数据库作为数据源,检索作者单位“武昌文华图书馆专科学校”,未检索到相关文献,表明未收录此时期文献。检索作者单位“武汉大学图书馆学系”,检索到相关文献始于1958年。因此,本文使用检索策略“作者单位:武汉大学图书馆学系or武汉大学图书情报学院or武汉大学传播与信息学院or武汉大学大众传播与知识信息管理学院or武汉大学信息管理学院”进行检索,得到1958~2019 年9 月14 日的文献记录10,860条,抽取每篇论文的时间和摘要作为主题识别和分析的语料。为获取科学、规范的语料来源,对获取的文献进行处理,包括删除武汉大学传播与信息学院中新闻与传播类文献、摘要缺失的文献记录以及对文献题录进行去重等,添加在相关论文搜集过程中发现的署名单位为武汉大学实际是学院师生发表的文献记录。通过清洗数据,将得到的10,179条文献记录作为实验的候选语料库。
2.2.2 数据预处理和参数设置
为提高实验结果准确性,对采集到的原始数据进行预处理。采用中国科学院ICTCLAS分词工具,对标题和摘要文本进行汉语分词处理,并在用户自定义词典中加入“高校图书馆”“竞争情报”“数字出版经济”“档案治理”等相关词语。将“的”“已经”等功能词、文本中应用广泛的词和标点符号等作为停用词,进行过滤处理。数据预处理阶段是一个持续重复的过程,依据模型输入需求,需对用户自定义词典进行不断扩充,直至得到满意的处理结果,最后基于开源包JGibbLDA实现LDA主题模型的参数训练。
在试验阶段,将主题划分为10~17类,对每一类中词的隶属概率进行分析。研究发现,将主题分为11~15类时,每一类中词项的隶属概率逐渐提高,但主题间区分度不强,在分为15类主题时输出的实验结果较好,在分为16类时词项的分布概率下降。因此,将主题数目设置T=15,超参数设置为α=0.01,β=0.05,迭代次数niters=1,000 次,抽取各主题下概率最高的前10 个词,利用Gibbs Sampling进行参数估计和推断。
3 研究主题动态演化分析
3.1 发文量分布情况
图2呈现学院1958~2019年发表文献数量的年代分布。至2019年9月14日,学院不同历史时期发表的论文大体经历3个阶段:第一阶段为1958~1983年,自数据库收录武汉大学图书馆学系的第一篇文献至1984年建立图书情报学院前。论文数量增长缓慢,变化曲线几乎与坐标轴重合平行,主因是CNKI数据库只对1993年前的部分期刊进行回溯。第二阶段为1984~2000年,即2001 年更名为武汉大学信息管理学院前,论文数量增长加快。第三阶段为2001~2019年,更名为武汉大学信息管理学院后,发文量呈现递增趋势,局部有小幅度波动,2014年达到峰值630篇。

图2 发表文献数量年代分布
3.2 研究主题划分
通过LDA主题模型计算结果分析以及过滤1个摘要结构信息的主题,得到最优主题数目为14。为提高主题划分的准确性,结合每个主题下高概率词项,对主题的定义进行验证。删去主题下无参考意义的词项,如“程度”“性质”,最终输出每个主题下的主要词项,见表1。发现词项与主题高度相关。比如,“图书馆服务与管理”主题下,“参考咨询”“服务质量”“图书馆管理”等均与主题高度相关,说明LDA模型在提取潜在研究主题方面是有效的。
3.3 各时期热点研究主题内容分析
面对1958~2019年学院数量庞大、主题丰富的研究成果,选取各阶段出现频次占比均值较高的前4个主题进行分析,利用主题强度方法挖掘学院不同时期研究的热点主题,以时间窗口T=1958-1984、1985-2000、2001-2019观察研究的热门主题,用颜色填充方法标出热门主题,见表2。
根据表2~3可知,在1958~1983年学院研究成果发表的第一个阶段,研究集中于“主题2”“主题1”“主题3”“主题4”。分析每个领域在该阶段的研究内容,主题2主要涉及目录学和文献组织中文献分类与编目基础理论、方法等。陈传夫[13]对苏联目录学基本理论、书目工作方法进行综合概述;彭斐章、谢灼华[14]提出在实现“四个现代化”的背景下,目录学研究面临的研究对象、目录学史等问题;周继良[15]提出对“马克思列宁主义、毛泽东思想”列为图书分类法五大部类之一的理解。“主题1”主要涉及图书馆管理的理论与方法、业务管理和人力资源管理。黄宗忠[16]从人才学基本观点出发,探讨图书馆管理队伍建设问题。“主题3”主要涉及情报检索语言的基础理论和情报检索系统等。张琪玉[17]提出一种纯标识检索系统的方案,然后就其实用价值作出分析;陈光祚[18]介绍学习计算机情报检索的意义,以及如何利用情报检索系统查找资料;王昌亚[19]论述科技情报检索刊物体系存在的缺点,认为根源是指导思想和方向不明确,建议加强管理、集中编制检索刊
物。“主题4”主要涉及在社会主义现代化建设新时期,图书情报教育如何用新思路进行改革等。1980年代初起,谢灼华致力于图书馆史学学科建设研究,建议在本科课程教学基础上建立完整的图书馆史教育层次,通过教材建设构建图书馆史学科体系[20]。1983年在国家科委和武大支持下,严怡民等联合创办全国第一个科技情报培训中心,我国情报教育基地建设迈上新台阶[21]。

表1 研究主题及主要概率词项

表2 不同时间窗口t下的热点主题

表3 不同时期top4热门主题
在1984~2000年学院研究成果发表的第二个阶段,研究主题包括“主题2”“主题7”“主题1”“主题10”,编辑出版学和信息经济学成为该时期研究热点。在“主题2”中,目录学与文献分类的编目理论研究不断深化,关于计算机分类、编目的研究增多。陈传夫[22]论述现代“新目录学”的基本流派;司莉等[23]探讨因特网资源编目的特点,介绍OCLC网上资源编目计划。“主题7”主要涉及电子出版物、网络出版物、出版经济、高校出版类课程建设等研究。彭建炎[24]论述出版业的价格、税收、信贷等出版经济政策的作用与制定;方卿[25]提出推进平衡书业的产销关系整合等举措以推动书业产销关系平衡;徐丽芳等[26]界定网络出版,将其区分为主题讨论型、定期或不定期型、数据库型、综合型4 类。在“主题1”中,随着信息技术发展,研究主题转向图书馆管理与服务的信息管理系统、自动化管理等方面。黄宗忠[27]针对图书馆管理体制不健全等问题,提出由封闭管理型转向开放管理型等思路。“主题10”主要涉及信息经济学概念、信息经济学与情报经济学关系、微观经济学等。马费成[28]讨论信息经济学涉及的主要领域,以此为基础进一步阐明信息与情报等概念在我国情报工作中的背景,专著《信息经济学》连续多年被评为经济学、情报学领域的高被引图书。
在2001~2019年学院研究成果发表的第三个阶段,研究主题集中于“主题2”“主题3”“主题11”“主题4”。信息组织依然是关注的主题,随着21世纪信息化、网络化发展,数字信息资源建设、网络信息计量、信息素质教育成为新的研究热点。“主题2”研究集中在信息组织理论、网络信息组织、本体、语义网、自动标引和分类等方面。胡昌平等[29]从个性化服务的资源定位等多重定位出发,构建以需求为导向的信息资源组织目标控制体系;周耀林等[30]基于本体理论,构建非遗信息资源组织与检索研究框架。在“主题3”中,引文分析理论文章减少,应用研究增多,包括期刊引文分析、文献需求分析、数据库开发应用、网络信息资源定性评价、网络测评大学等。邱均平等[31]讨论了网络计量学的研究对象、工具及其5个主要应用。“主题11”主要涉及资源整合、数据库建设、网络信息资源开发与利用、信息资源共建共享等。肖希明等[32]剖析数字阅读在资源结构等方面对图书馆信息资源建设的影响,提出图书馆应本着虚实并重的方针开发网络资源,推动公共数字文化资源整合;李纲等[33]比较垂直型、水平型、网络型3 种信息资源共享模式,对馆际互借、网络检索等共享模式进行社会收益成本分析。“主题4”研究方向发展为研究信息素质教育、数字信息素质教育课程模式、网络环境下用户信息素质培养等方面。黄如花团队发表“信息素养教育与MOOC”系列专题论文,全面调研MOOC 环境下的课程开设现状和需求,推动整个行业对MOOC教学模式有更深入的了解[34]。
3.4 研究主题演化趋势分析

图3 热门主题演化趋势图
为从宏观上展示研究主题的演化趋势,本文呈现实验所得热门主题强度值。受篇幅限制,选取主题强度排在前5 位的主题,包括“主题2”“主题6”“主题7”“主题1”“主题3”,绘制不同主题1958~2019年强度变化的折线图,见图3。
依据主题强度变化,得出以下结论:总的来说,前期各主题强度值的跨度较大,同一时期不同主题之间的强度差异较大,而后期主题之间强度差异缩小,并趋于平衡和稳定。以2000年为对比关键点,2000年前的波动幅度较2000年后的波动高,说明学院的主要研究方向越来越明确,对各主题有更好的把握。
具体来说,“主题2目录学与信息组织”热度维持高水平,关注度保持稳定。武汉大学是最早研究信息组织的机构之一,多与北京大学、南京大学等研究机构合作,是信息组织研究的重要力量[35]。1990 年代前对馆藏文献进行整序和整合,研究文献分类和编目,相关研究为图书分类法、书目工作、布鲁塞尔分类法等。1983 年严怡民主编的《情报学概论》出版,以情报组织与利用为主线,融合情报学各领域研究成果构建情报学体系,是国内第一部系统论述情报学主要研究领域的著作[21]。1986 年彭斐章等翻译出版《目录学普通教程》,是全面研究书目情报理论的开端[36]。1990 年代掀起中图法研究热潮,并出现计算机在分类领域的应用,涉及术语有中图法、自动标引、联机编目等。目录学在书目实践中不断创新,书目情报理论逐渐建立并成熟,彭斐章的现代目录学思想为创立中国特色的现代目录学做出了贡献[37]。目录学涉及术语有现代目录学、机读目录、数目数据库等,见图4。21世纪“图书分类学”“文献分类学”逐渐被信息组织替代,随着网络普及,研究网络信息分类和元数据编目的论文增多,研究内容从基于元数据的信息组织向基于本体的知识组织方向发展。随着大数据时代到来,目录学新观点和新理念层出不穷,见图5。
“主题1图书馆服务与管理”“主题7编辑出版学”总体上呈下滑趋势,其中“图书馆服务与管理”研究在1980年时热度排名第一,21世纪后跌至第五。究其原因,学院对这两大热点主题的研究相对成熟,主题强度略有降低。

图4 21世纪前的目录学与信息组织关键词共现图

图5 21世纪以来的目录学与信息组织关键词共现图

图6 21世纪前的图书馆管理与服务关键词共现图

图7 21世纪以来的图书馆管理与服务关键词共现图

图8 21世纪前的编辑出版学关键词共现图
改革开放后,“图书馆服务与管理”研究逐渐由经验主导向理性与经验相结合转变,论文中多涉及“读者服务”“读者工作”等,见图6。随着数字化、网络化发展,图书馆服务功能从单一型文献传递服务向多元化信息服务方向发展,自动化技术和网络技术对图书馆管理产生重要影响,传统的科学管理逐渐演变为信息资源管理。21 世纪以来,学者的研究关注用户需要解决的问题,依据用户情景,建立知识服务和知识管理核心能力,促进图书馆服务与管理理论体系的成熟,相关术语主要涉及“数字图书馆”“个性化信息服务”“知识管理”“数字参考咨询”,见图7。胡昌平长期从事信息服务与用户研究,他认为包括图书馆在内的信息机构在进行信息资源组织开发的活动中,最终必须面向用户[38]。
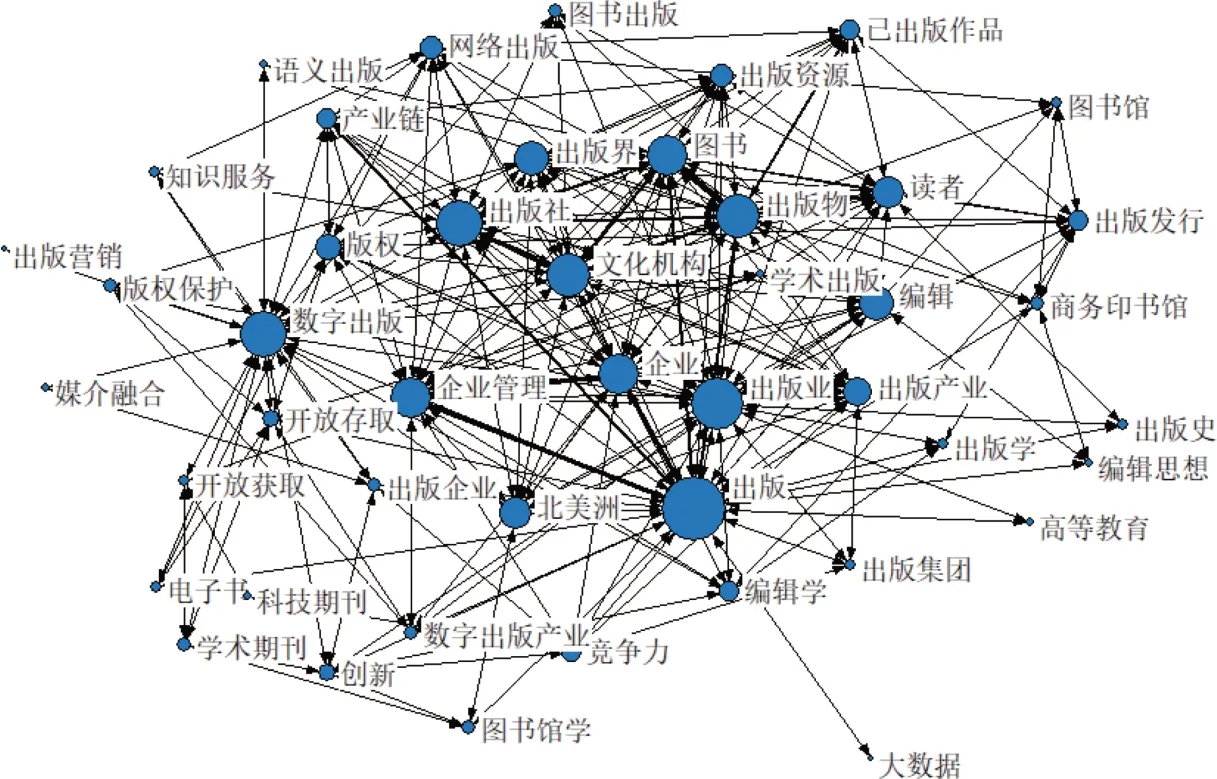
图9 21世纪以来的编辑出版学关键词共现图

图10 21世纪前的信息检索关键词共现图

图11 21世纪以来的信息检索关键词共现图
在“主题7 编辑出版学”领域,1983年孙冰炎领头创建全国第一个图书发行专业[39],填补了高校专业建设的空白[40]。21世纪前“编辑出版学”形成出版学基础理论与管理、网络与电子出版、出版物市场营销、编辑出版史与出版文化4 个研究方向[41]。新世纪以来“编辑出版学”研究朝着互联网环境下出版业现状与问题研究、出版产业数字化转型及其版权保护等方向发展,涉及术语有“数字出版”“版权保护”“出版产业”等,见图8~9。1998年以来,学院在出版营销领域发文量居全国第一。21世纪以来,方卿、张美娟等长期关注出版营销,贡献突出[42]。黄先蓉等在数字出版产业政策等领域有较高参与度,为核心研究人员[43]。
“主题3信息检索”“主题6信息计量”在个别年份有比较小的波动,但从总体看强度变化并不大,一直稳定发展。改革开放初期,信息检索研究主要围绕检索工具的使用和分类。如图10所示,到20 世纪八九十年代,由于引入新的标引技术和联机服务,出现一批以自动标引和联机检索为主题的研究成果,推动信息检索研究达到一个小高峰。21世纪后,信息检索研究趋向于网络搜索核心技术和知识化的信息检索服务,“信息检索”与“搜索引擎”“本体”“互联网”“元数据”共现次数最多,见图11。陆伟、吴丹是知识检索研究的重要力量,发文量较多,贡献较大[44]。

图12 21世纪前的信息计量关键词共现图

图13 21世纪以来的信息计量关键词共现图
信息计量研究,21 世纪前集中于三大经典定律、对期刊的统计分析、引文分析方面,讨论曲线的参数取值、文献半生期半衰期、学科发展趋势等问题,见图12。1980年代,马费成系统讨论布拉德福文献分布概率模型、布鲁克斯情报学的基本理论模型,其成果成为我国文献计量学和信息计量学研究的基础。1990年代,他敏锐地提出信息计量从语法层次向语义和语用层次发展,该理论成为我国20多年来学科发展 的 基 线[45]。21 世 纪后,网络计量分析、引文分析应用研究逐渐成为增长点,主要讨论网络信息计量学的研究对象和研究内容、期刊评价、学科引文评价等,见图13。邱均平研究团体贡献大,他是国内信息计量与科学评价研究主要学术带头人[46]。
4 结论
本文运用LDA主题模型和共词分析法相结合的方法,揭示学术论文在不同时期研究热点的内容发展和主题演变特征。以1958~2019年CNKI 数据库收录的学院论文为研究对象,抽取14个主题;分析不同时期主题强度排在前4 位的主题,绘制综合主题强度排名前五位的主题演化趋势图,构建不同时期的关键词共现图。研究发现:武汉大学信息管理学院在守正中不断实现新突破,在守正创新中保持强劲发展态势;在继承和发扬前辈学者的治学作风和科研精神的基础上,学院在不同时期都会出现新的研究热点,且在各个领域都有突出成就,守正不渝,创新不止,不断开创信息管理领域育人和科研新局面。
经过百年年薪火相传,文华图专发展成信息管理学院,每个时代皆成就斐然。如今武汉大学信息管理学院已成为拥有图书馆学、情报学、档案学、出版科学、信息管理与信息系统、电子商务、信息资源管理、管理科学与工程等学科的综合性研究型信息管理教育与研究机构[47]。由于武大信息管理学院历史悠久,名师荟萃,鸿儒云集,成果丰硕,内容宽广,本文无论是数据还是分析,难免挂一漏万。
谨以此文恭贺武汉大学信息管理学院百年华诞,祝愿学院实现更大飞跃,迈上新高峰!
