基于类卷积交互式注意力机制的属性抽取研究
2020-11-10尉桢楷周夏冰李志峰邹博伟姚建民
尉桢楷 程 梦 周夏冰 李志峰 邹博伟 洪 宇 姚建民
(苏州大学计算机科学与技术学院 江苏苏州 215006)(20185227064@stu.suda.edu.cn)
属性抽取(aspect extraction)是属性级情感分析的子任务之一[1],其目标是:对于用户评价的文本,抽取其中用户所评价的属性或实体.表1给出了3条评价文本样例,前2条为餐馆领域评价文本,其中“cheesecake(奶酪蛋糕)”、“pastries(糕点)”、“food(食物)”、“dishes(菜肴)”为待抽取的属性,粗体显示;最后一条为电脑领域评价文本,其中待抽取的属性为“screen(屏幕)”、“clicking buttons(点击按钮)”,粗体表示.
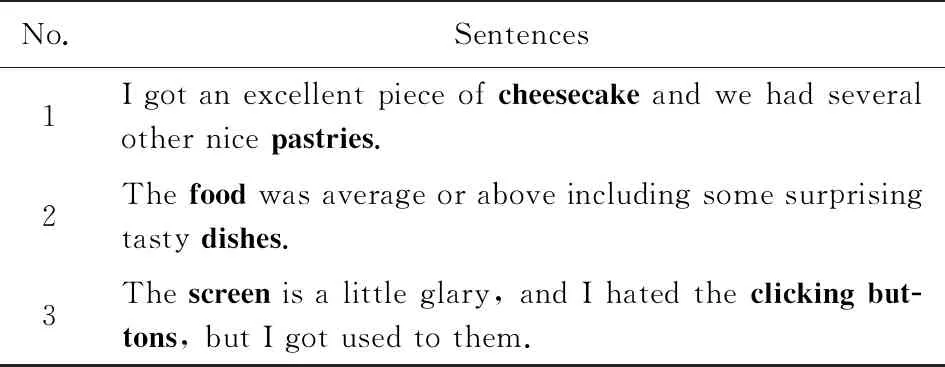
Table 1 Example of User Review
目前,针对属性抽取的研究方法主要分为3类:基于规则的方法、基于传统机器学习的方法和基于深度学习的方法.基于规则的方法依赖于领域专家制定的规则模板实现属性抽取.例如,Hu等人[2]首次提出使用关联规则实现属性抽取,并且只抽取评论文本中显式的名词属性或名词短语属性.Li等人[3]使用依存关系从影评中抽取“评价对象-评价意见”单元对.Qiu等人[4]利用依存关系获得属性词与评价词之间的关系模板,从而根据属性词抽取评价词,根据评价词抽取属性词.以上基于规则的方法迁移性差,无法抽取规则之外的属性.在基于传统机器学习的方法中,通常将属性抽取任务指定为序列标注任务.其中,Jakob等人[5]首次将条件随机场(conditional random field, CRF)应用于属性抽取的研究,并融合了多种特征,在属性抽取的任务上取得了较好的效果.Xu等人[6]在CRF的基础上引入浅层句法分析和启发式位置特征,在不增加领域词典的情况下,有效地提高了属性抽取的性能.然而,基于CRF的模型通常依赖于大量的手工特征,在特征缺失的情况下性能将会大幅下降.
深度学习的方法可以避免大量的手工特征,自动学习特征的层次结构完成复杂的任务,在属性抽取的任务上取得了优异的效果.例如,Liu等人[7]首次将长短期记忆网络(long-short term memory, LSTM)应用于属性抽取任务,与使用大量手工特征的CRF模型相比,该方法取得了更优的性能.Toh等人[8]提出将双向循环神经网络(bidirectional recurrent neural network, Bi-RNN)与CRF相结合的方法,在2016年SemEval属性级情感分析评测任务中性能达到最优.
目前,注意力机制(attention mechanism)已被应用于属性抽取的研究.Wang等人[9]提出一种多任务注意力模型,将属性词和情感词的抽取与分类进行联合训练,从而实现学习抽取和分类过程中的特征共享,进而实现抽取和分类的相互促进,该模型应用的注意力机制为静态注意力机制.Cheng等人[10]在基于双向长短期记忆网络的CRF模型(BiLSTM-CRF)中着重利用门控动态注意力机制,所使用的注意力机制为自注意力机制.BiLSTM-CRF的架构[11-13]既捕获了句子中上下文的分布特征,又有效地利用上下文标记预测当前的标记类别,鉴于此本文将BiLSTM-CRF的架构作为基线模型.
目前面向属性抽取的注意力机制存在2个局限性.其一,注意力机制多为全局式注意力机制(本文将自注意力机制统称为全局式注意力机制),全局式注意力机制在每个时刻(处理每个目标词项时)将与之距离较远且关联不密切的词分配了注意力权重.例如,评论句子“The service is great,but the icecream is terrible.”(译文:服务很好,但冰淇淋糟糕),当目标词为“service(服务)”时,“terrible(糟糕)”距离目标词“service”较远且关联不紧密,若对“terrible”分配较高的注力权重,则为目标词“service”的注意力分布向量带来噪音.其二,目前面向属性抽取的注意力机制多为单层,注意力机制单层建模后缺少交互性.
针对上述局限,本文提出面向属性抽取的类卷积交互式注意力机制(convolutional interactive attention, CIA).该注意力机制在每个时刻(处理每个目标词时)都通过滑动窗口控制目标词的上下文词的个数,例如图1,当前时刻的目标词为“icecream(冰淇淋)”时,在滑动窗口内计算“icecream”的注意力分布向量.在此基础上,再将目标词的注意力分布向量与句中各个词进行交互注意力计算,将获得的交互注意力向量与目标词的注意力分布向量拼接,由此获得最终的注意力分布向量.
本文提出在BiLSTM-CRF的基础上着重利用CIA的模型CIA-CRF,CIA-CRF是针对属性抽取任务形成的一种综合神经网络和CRF的架构,在该架构中配以一套新型的注意力机制CIA.总体上,本文的贡献包含2个方面:
1) 提出类卷积交互式注意力机制(即CIA),该注意力机制分为类卷积注意力层和交互注意力层,旨在解决目前面向属性抽取的全局式注意力机制将不相关的噪音带入注意力向量的计算以及注意力机制缺少交互性的局限.
2) 利用Bi-LSTM对句中所有的词提取字符级特征,将字符级特征与各自的词向量拼接,以此获得含有字符级特征的词向量表示.字符级特征有助于未登录词的识别.
本文在国际属性级情感分析公开数据集SemEval 2014[1],2015[14],2016[15]上对CIA-CRF进行测试,在4个数据集上F1值均获得提升.
1 模 型
1.1 属性抽取任务
与Yu等人[16]方法类似,本文将属性抽取任务指定为序列标注任务,使用的标签模式为BMESO.对于包含多个词的属性,B代表属性的开端,M代表属性的中间,E代表属性的结尾;对于单个词的属性,则用S表示;O统一代表非属性词.序列标注样例如表2所示:

Table 2 Example of Sequence Labeling
1.2 模型总体结构
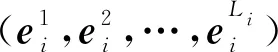

2) 将S=(s1,s2,…,sn)输入Bi-LSTM层,通过Bi-LSTM的编码,借以获得各个词包含上下文信息的隐藏状态H=(h1,h2,…,hn);
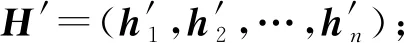
4) 将H′经过交互注意力层,按序逐词地对各个单词的上下文所有词分配注意力权重,进而通过注意力权重和类卷积注意力矩阵H′计算交互注意力矩阵Q=(q1,q2,…,qn),最后将类卷积注意力矩阵H′与交互注意力矩阵Q拼接,由此获得双层注意力矩阵表示R=(r1,r2,…,rn);
5) 经过注意力层的表示学习后,本文继承Cheng等人[10]的工作,将双层注意力矩阵R输入到门控循环单元(gated recurrent unit, GRU)中更新,从而获得更新后的注意力矩阵U=(u1,u2,…,un),并经过全连接降维后输入到CRF层进行属性标记,最终获取各个单词对应的预测标签L={l1,l2,…,ln},其中li∈{B,M,E,S,O}.

Fig. 2 General structure of system
1.3 词语表示层

(1)
(2)
(3)
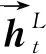
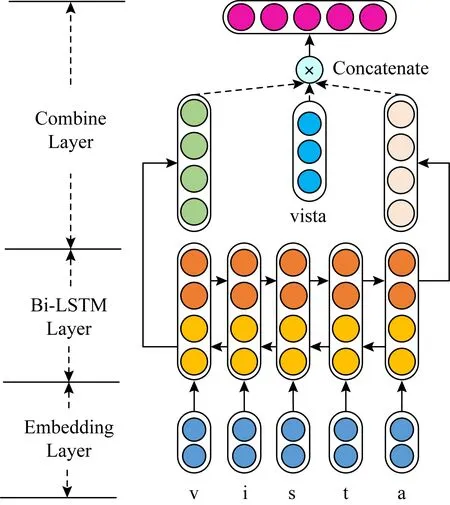
Fig. 3 Structure of word representation layer
1.4 Bi-LSTM层
由1.3节可以获得各个含有字符特征的词矩阵S=(s1,s2,…,sn),本文采用Bi-LSTM对词矩阵S进行编码.
Bi-LSTM由前向LSTM和后向LSTM组合而成.其中,LSTM有3个输入,分别是当前时刻的输入st、上一时刻LSTM的输出ht-1、上一时刻的记忆单元状态ct-1,LSTM的输出有2个,分别是当前时刻的输出ht和当前时刻的记忆单元状态ct.LSTM的内部结构由3个门组成,依次为遗忘门ft、输入门it、输出门ot.3个门控的功能各不相同,遗忘门选择通过的信息量,输入门控制当前输入对记忆单元状态的影响,输出门控制输出信息.LSTM的计算公式为:
ft=σ(Wsfst+Whfht-1+bf),
(4)
it=σ(Wsist+Whiht-1+bi),
(5)
ot=σ(Wsost+Whoht-1+bo),
(6)
ct=ft⊙ct-1+it⊙tanh(Wscst+Whcht-1+bc),
(7)
ht=ot⊙tanh(ct),
(8)
式中σ为sigmod激活函数,tanh为tanhyperbolic激活函数;W表示权重矩阵,b表示偏置项.
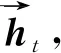
1.5 类卷积交互式注意力机制
本文针对属性抽取任务,提出一种面向属性抽取的类卷积交互式注意力机制方法.该注意力机制为双层注意力机制.第1层为类卷积注意力层,旨在降低全局式注意力机制在计算注意力向量时带入的噪声;第2层为交互注意力层,是在类卷积注意力层降噪的基础上引入的.之所以提出交互注意力层,是由于在类卷积注意力层中,滑动窗口大小为固定的超参数,所以窗口外可能存在与当前词关联密切的词.基于类卷积注意力向量,与所有词做进一步地交互注意力计算,从而获得对于类卷积注意力向量而言重要的全局信息.因此,类卷积交互式注意力机制既满足了降噪,又获得对于类卷积注意力向量而言重要的全局信息.
总之,类卷积注意力层布置于交互注意力层之前,专用于去噪.从而再次使用交互注意力层时,噪声已获得类卷积注意力层的处理,同时保留了交互注意力层自身的优势.下面将分别详细介绍类卷积注意力层和交互注意力层.
1.5.1 类卷积注意力层
Kim[18]首次将卷积神经网络应用于文本分类任务,通过卷积核获取每个目标词的上下文特征.我们将这种卷积思想迁移到注意力机制的计算,设置类似于卷积核的滑动窗口,通过滑动窗口的大小限制每个目标词的上下文词的个数,从而在滑动窗口内计算每个目标词的类卷积注意力向量.类卷积注意力层如图4所示:

Fig. 4 Convolutional attention layer
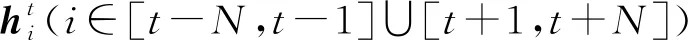
(9)
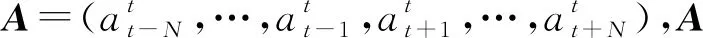
(10)
(11)
(12)
1.5.2 交互注意力层
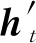
(13)
其中hj为第j个词的隐藏状态,j∈[1,n].

Fig. 5 Interactive attention layer
(14)

(15)

(16)
(17)
ut=gru(ut-1,rt,θ),
(18)
其中,gru为GRU模型,θ为gru的参数矩阵.
1.6 CRF
CRF最早由Lafferty等人[19]于2001年提出,是一种判别式模型.线性链条件随机场被广泛应用于序列标注任务,其优越性已被多次证明.CRF的主要作用是进一步增强前后标签的约束,避免不合法标签的出现,例如标签M的前一个标签是O,即为不合法标签,CRF输出的是合法并且概率最大的标签组合.CRF原理为:

(19)
其中,T是转移特征函数的数量,S是状态特征函数的个数,u为降维后的类卷积交互式注意力向量,Y为输出标签,p(Y|U)表示在输入为U的情况下标签为Y的概率,Z(U)是归一化因子.tk(yi-1,yi,u,i)为转移特征函数,其依赖于当前位置yi和前一位置yi-1,λk是转移特征函数对应的权值.sl为状态特征函数,依赖于当前位置yi,μl是状态特征函数对应的权值.特征函数的取值为1或0,以转移特征函数为例,当yi-1,yi,u满足转移特征函数时,则特征函数取值为1,否则取值为0.状态特征函数同样如此.
在训练CRF时,使用极大似然估计的方法训练模型中的各个变量,对于训练数据(U,Y),优化函数为:
(20)
经过训练使得Loss最小化.测试时,选取概率最大的一组标签序列作为最终的标注结果.
2 实 验
2.1 实验语料与实验设置
本文的实验数据来自SemEval 2014—2016属性级情感分析的4个基准数据集,数据集分为电脑(laptop)领域和餐馆(restaurant)领域.4个基准数据集分别为:2014年语义评测任务4中的电脑领域(SemEval 2014 task 4 laptop, L-14)、2014年语义评测任务4中的餐馆领域(SemEval 2014 task 4 restaurant, R-14)、2015年语义评测任务12中的餐馆领域(SemEval 2015 task 12 restaurant, R-15)、2016年语义评测任务5中的餐馆领域(SemEval 2016 task 5 restaurant, R-16).实验过程中,随机从训练数据中选取20%的样本作为开发集.各个数据集的训练集、开发集以及测试集的样本数量如表3所示.此外,表3还统计了各个数据集训练样本的平均长度.
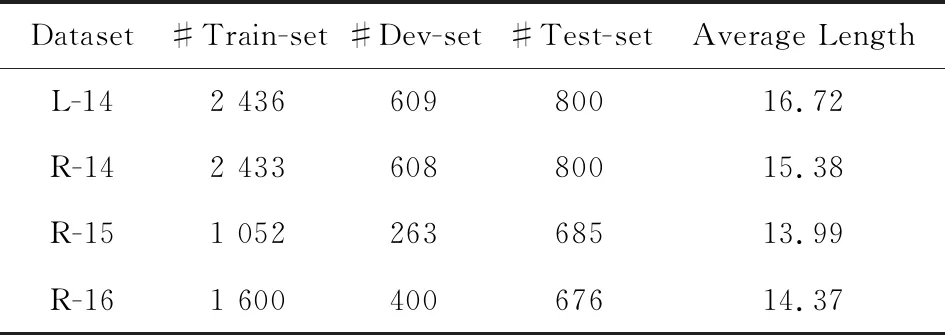
Table 3 Statistics of Datasets
本文使用的预训练词向量的来源为Glove,词向量的维度为100维,将词的隐含变量(hidden size)以及更新注意力的GRU神经网络隐含变量(GRU size)同设为100维,字符的隐含变量(character size)、注意力向量维度(attention size)分别设为20和200,学习率(learning rate)的大小设为0.001,批量大小(batch size)设为20,各个目标词项的上文(下文)词的个数(N)设为5.为了防止过拟合,在各层间加入dropout,设dropout=0.5.梯度优化使用adam优化器.
2.2 评价标准
与Yu等人[16]相同,本文采用F1值作为评价标准,评价过程采用精确匹配,只有当模型预测的结果与正确答案完全匹配才看作正确预测答案,换言之,预测答案从起始位置到结束位置的各个词必须与正确答案的各个词对应相同.例如,真实的答案为“sardines with biscuits”,如果模型预测的答案是“biscuits”,则不是正确答案.
2.3 实验对比模型
为了验证本文提出模型的有效性,本文设置3组对比模型.
第1组对比模型为传统的融入大量手工特征的模型,具体模型为:
1) HIS-RD,DLIREC,EliXa.分别为L-14,R-14,R-15属性抽取排名第一的评测模型.其中HIS-RD[20]与DLIREC[21]基于CRF,EliXa[22]基于隐马尔可夫模型,并且它们都使用了大量的手工特征.
2) CRF.融合基本特征以及Glove词向量[23]的CRF模型.
第2组对比模型是将深度学习的方法应用于属性抽取任务,对比模型为:
1) LSTM.Liu等人[7]使用LSTM对词向量编码,并通过最后一层全连接获得每个词的概率分布.
2) DTBCSNN+F.Ye等人[24]提出基于依存树的卷积堆栈神经网络的方法,该方法提取的句法特征用于属性抽取.
3) MIN.Li等人[25]提出一种基于LSTM的联合学习模型,使用2个LSTM联合抽取属性词和评价词,使用第3个LSTM判别情感句和非情感句.
4) MTCA.Wang等人[9]提出一种多任务注意模型,该模型是属性抽取和属性分类的联合学习模型.
5) GMT.Yu等人[16]提出基于多任务神经网络全局推理的模型,该模型联合抽取属性词和评价词.
第3组对比模型是本文的基线模型以及在基线模型基础上引入全局式注意力机制:
1) BiLSTM+CRF.在Toh等人[8]提出的基Bi-RNN的CRF模型上,将Bi-RNN替换为Bi-LSTM.本文将BiLSTM+CRF作为基线模型.
2) GA-CRF.在BiLSTM+CRF模型的基础上,以一种全局式注意力的计算方式,对Bi-LSTM的输出进行全局式注意力计算.
3) CA-CRF.在BiLSTM+CRF模型的基础上,集成本文提出的类卷积注意力层.
4) CIA-CRF.在BiLSTM+CRF基础上,集成本文提出的类卷积交互式注意力机制和字符级特征.
2.4 实验结果与分析
本文提出的模型以及对比模型的实验结果如表4所示.从表4中可知,本文的模型CIA-CRF在L-14,R-14,R-16数据集上取得了最优的F1值.
本文将CIA-CRF与现有方法进行比较分析.为了验证类卷积注意力层的有效性,本文在基线模型的基础上分别引入全局式注意力机制和类卷积注意力层,并进行比较分析.由于类卷积注意力层中的滑动窗口大小是重要超参数,所以本文比较分析滑动窗口大小对实验性能的影响.随后分别分析交互注意力层的有效性和字符级特征的有效性.将预训练模型BERT(bidirectional encoder representations from transformers)[26]分别与基线模型以及引入类卷积交互式注意力机制的基线模型进行结合,从而在结合BERT的前提下验证类卷积交互式注意力机制的有效性.

Table 4 F1 Performance Comparison
2.4.1 与现有传统模型和深度学习模型比较
在表4中,本文将CIA-CRF与现有传统模型和深度学习模型进行了比较.与融入多种手工特征的传统模型(HIS-RD,DLIREC,EliXa,CRF)相比,本文的模型CIA-CRF在L-14,R-14,R-15数据集上均取得了最优的性能并且优势明显.传统模型(HIS-RD,DLIREC,EliXa,CRF)都使用将近10种不同的手工特征,然而在Bi-LSTM结合CRF的架构下引入本文提出的类卷积交互式注意力机制和字符级特征,取得了比融入大量手工特征的传统模型更优越的性能.
对近年来的深度学习模型进行比较分析.相比于LSTM模型,CIA-CRF在4个数据集上分别提升了3.41,2.9,2.25,3.27个百分点.LSTM模型将各个词进行5分类(标签模式为BMESO),然而最后的输出可能会出现语法错误的情况,例如标签E后的标签为M,语法错误是LSTM模型的性能低于CIA-CRF的重要原因.相比于DTBCSNN+F,CIA-CRF在L-14,R-14数据集上的性能分别提高3.46和0.94个百分点.DTBCSNN+F依靠依存句法信息和堆栈神经网络,而本文提出的卷积交互式注意力机制能够更直接捕获到文本中重要的信息(即属性信息),是DTBCSNN+F不具备的优势.
在本文所对比的深度学习模型中,还包含了联合学习模型.相比于属性词与情感词的联合抽取模型MIN和GMT,CIA-CRF在L-14和R-16数据集上取得了最优的F1值,并在R-15上取得了与GMT可比的性能.MIN和GMT均利用了情感词信息,而本文方法CIA-CRF是单一的属性抽取任务,然而在缺少情感词信息辅助的条件下,CIA-CRF在大部分数据集上仍优于MIN和GMT.
MTCA为属性词与情感词抽取以及分类的联合学习模型.CIA-CRF与MTCA相比,在L-14,R-16数据集上取得更优的效果;而在R-15数据集上,CIA-CRF性能低于MTCA.经过分析表3可知,R-15的训练集数据量较少.因此,在训练数据偏少时,MTCA借助情感词抽取以及属性词与情感词分类的辅助信息,从而促进了属性词抽取性能的提升.
本文的模型CIA-CRF与基线模型BiLSTM+CRF相比,在4个数据集上分别提升了2.21,1.35,2.22,2.21个百分点.可见,本文提出的类卷积交互式注意力机制应用于属性抽取任务具有一定的优越性.
2.4.2 与全局式注意力模型对比分析
由表4可知,在BiLSTM+CRF架构下,结合类卷积注意力层并且不引入词的字符级特征(CA-CRF),与基于全局式注意力机制的GA-CRF相比,CA-CRF在4个数据集上的性能均得到了提升,分别提升了0.5,0.83,0.22,0.61个百分点.经过分析,全局式注意力机制按序(从句首到句尾)动态地对目标词的上下文的所有词分配注意力权重,而距离目标词较远且关联不密切的词就会为目标词的注意力向量带来噪音.为了便于观察评论文本中的注意力分布,我们将一条评论文本样例的每个时刻(t1~t10)注意力得分输出,绘制如图6所示的注意力分布图.在图6的t2时刻,此时目标词为“service”,全局注意力机制为目标词上下文所有的词都分配了注意力权重,而“terrible”这个词距离“service”较远且不相关,却分配了较高注意力权重,从而对目标词“service”的注意力向量带来噪音.
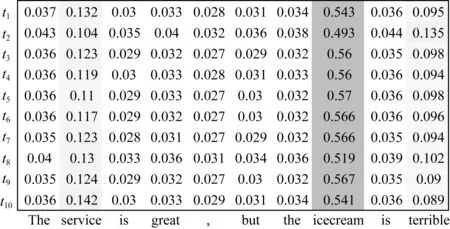
Fig. 6 Attention distribution
本文提出的类卷积交互式注意力机制中的类卷积注意力层可降低上述噪音,通过设置滑动窗口限制目标词的上下文词的数量,给予窗口内各个词注意力权重,从而获得受噪音干扰较小的注意力向量.实验结果表明,CA-CRF性能优于GA-CRF,在属性抽取上,类卷积注意力层获得的注意力向量更优.
2.4.3 滑动窗口大小设定分析
类卷积注意力层中滑动窗口的大小是重要的超参数,本文将目标词项的上文(下文)词数指定为窗口大小.为了验证滑动窗口大小对实验结果的影响,本文将窗口大小分别设为2,5,8进行模型训练,实验过程中保存开发集上F1值最优的模型,最后使用最优模型在测试集上进行测试,实验结果如表5所示:
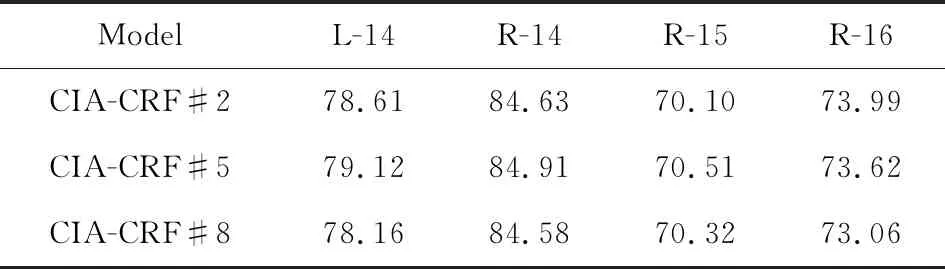
Table 5 F1 of Different Window Sizes
从表5中可知,当窗口大小为2时(CIA-CRF#2),在数据集R-16上取得较优的性能;当窗口大小为5时(CIA-CRF#5),在L-14,R-14,R-15等数据集上性能较优.结合表3可发现,R-15和R-16的训练数据平均长度较短,而L-14和R-14的训练数据平均长度较长.因此,可推测当训练语料的平均长度较短时,应选用较小或稍大的滑动窗口;而当训练语料的平均长度较长时,应选用稍大的滑动窗口.实验中将滑动窗口大小设为8时(CIA-CRF#8),在4个数据集上的性能均未达到较优的效果,因为较大的滑动窗口会将较多的噪音带入类卷积注意力向量.所以,实验中滑动窗口的大小不能设置过大.由于在大部分数据集上,窗口大小设为5都取得了较优的性能.所以,本文在4个数据集上统一选择窗口大小为5的实验结果作为性能的对比和相应分析.
2.4.4 交互机制对比分析
为了进一步验证类卷积交互式注意力机制中交互注意力层的有效性,本文在CIA-CRF的基础上去掉交互注意力层(CIA-CRF-NOI),实验结果与CIA-CRF进行对比,如表6所示.
从表6可发现,在CIA-CRF基础上去掉交互注意力层,在4个数据集上性能都出现下降,分别下降了0.94,0.59,0.73,0.6个百分点.可见,交互注意力层有助于属性词的预测.原因在于,类卷积注意力层按序(从句首到句尾)通过滑动窗口控制每个词(目标词)的上下文词的数量,由于滑动窗口的大小固定,且每个目标词的上下文中与之关联密切的词分布迥异,所以窗口外可能存在与目标词关联密切的词,类卷积注意力向量可进一步优化.在类卷积注意力向量的基础上,从交互注意力层可获得对于类卷积注意力向量而言重要的全局信息,从而有助于属性词的预测.

Table 6 F1 of Interactive Attention
2.4.5 字符级特征对比分析
为了验证词的字符级特征对实验结果的影响,本文在CIA-CRF的基础上不使用字符级特征(CIA-CRF-NOC),与使用字符级特征的CIA-CRF进行对比,对比实验结果如表7所示:

Table 7 F1 of Character Feature
从表7分析可知,在CIA-CRF的基础上去掉字符级特征,在4个数据集上性能均下降,分别下降了0.41,0.29,0.89,0.42个百分点.对于不加入字符级特征的模型CIA-CRF-NOC,未登录词的表示采用随机初始化的方法.若未登录词为待抽取的属性词或者与属性词有重要关联的词,随机初始化的方法不利于模型对属性词的预测.与随机初始化的方法相比,从未登录词的本身获得的特征表示更有利于模型对未登录词的识别,进而有利于属性词的预测.表8统计了4个数据集中登录词和未登录词的数量.

Table 8 Statistics of Login Words and Un-login Words
2.4.6 结合BERT的对比分析
预训练模型BERT[26]已经在多个自然语言处理任务上取得了优越性能.鉴于此,本节在4个数据集上使用BERT进行实验.此外,本节还将BERT与基线模型BiLSTM+CRF结合(BERT+Baseline).同样,本节在BERT+Baseline的基础上与类卷积交互式注意力机制结合(BERT+Baseline+CIA).基于以上,进行实验对比,实验结果如表9所示:
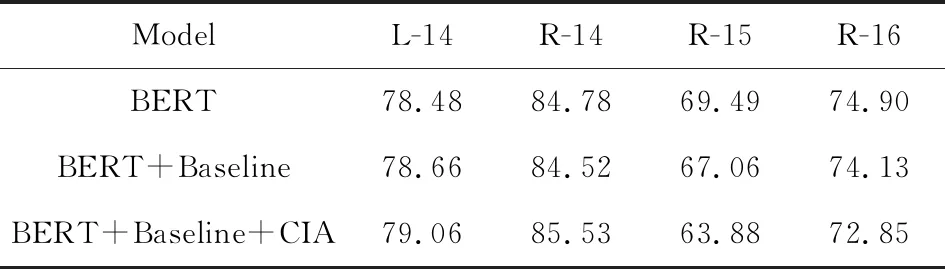
Table 9 F1 of Combining BERT Models
从表9可知,在R-15和R-16数据集上,与BERT相比,BERT+Baseline和BERT+Baseline+CIA的性能均下降.结合表3分析可知,R-15和R-16的训练数据较少,而 BERT+Baseline和BERT+Baseline+CIA的模型复杂度较高.对于数据量较少的训练数据,复杂度较高的模型容易对其产生过拟合,从而测试性能较差.因此,BERT+Baseline和BERT+Baseline+CIA在R-15和R-16数据集上,性能均未达到较优.
相比于R-15和R-16,L-14,R-14的训练语料的数据量较多.在L-14和R-14数据集上,与BERT+Baseline相比,BERT+Baseline+CIA的性能分别提升0.4和1.01个百分点.因此,在训练语料的数据量较多的情况下,在BERT+Baseline的基础上引入类卷积交互式注意力机制,性能可获得进一步提升,从而也证明了类卷积交互式注意力机制的有效性.
3 总 结
本文提出一种基于类卷积交互式注意力机制的属性抽取方法.该注意力机制包含2层注意力,第1层是类卷积注意力层,第2层是交互注意力层.相比于全局式注意力机制,类卷积注意力层在滑动窗口内为每个词的上下文分配注意力权重,从而获得受噪音干扰较小的类卷积注意力向量.在类卷积注意力层降噪的基础上,通过交互注意力层获得对于类卷积注意力向量而言重要的全局信息.此外,本文提出的模型融入词的字符级特征,字符级特征有助于识别未登录词,从而有助于属性词的预测.实验证明,本文提出的方法在4个数据集上性能均有提升.
