纠删码存储系统数据更新方法研究综述
2020-11-10储佳佳翁楚良
张 耀 储佳佳 翁楚良
(华东师范大学数据科学与工程学院 上海 200062)(zhangyao@stu.ecnu.edu.cn)
在分布式存储系统中,节点故障已成为常态,根据文献[1],Facebook数据仓库每天平均有50个节点不可用.通常分布式存储系统会采用数据冗余的方式来保证系统的可用性,以免机器宕机、网络分区等故障带来的数据丢失、请求不能正常响应情况的发生.目前数据冗余的方式主要有2种:一种是多副本,另一种是纠删码.随着大数据时代的到来,每天都会产生大量的数据,这给存储系统带来了更大容量的需求,随之产生的成本开销也越来越大.根据Facebook统计数据显示[2],数据中心中每PB的数据每个月所产生的经济开销大约是200万美元.多副本机制的使用无疑使这种情况更加恶化.随着CPU、网络设备等新硬件技术的快速发展,人们逐渐把目光从多副本方式转向纠删码.相比于多副本方式,纠删码能够在保证相同甚至更高的系统可用性的同时,将存储开销降低为原来的50%,甚至更低,这节省的经济开销无疑是巨大的.目前越来越多的分布式存储系统开始支持纠删码方式的存储,像HDFS[3],Windows Azure[4],Ceph[5],f4[6]等.
但是纠删码本身也存在缺点.和多副本直接将原始数据完整拷贝多份作为冗余信息不同,纠删码之所以能够将存储开销降低,是因为其利用特定的编码规则对原始数据进行特定的结合,计算后生成少量的冗余信息,冗余信息和编码规则结合能够恢复出出错的数据.当原始数据中的一些数据被更新时,对应的冗余信息也同样需要更新来保证数据与冗余信息之间的一致性.可以看出,编码、解码、更新过程都需要计算消耗CPU资源.而且,解码和更新操作都需要读取相应的数据和冗余信息,这会消耗更多的网络带宽和硬盘IO.和多副本机制相比,纠删码的写、更新、恢复数据过程更加复杂,导致纠删码的性能相对较差.为了兼顾系统性能和存储效率,目前纠删码方式多是用于冷数据或者温数据的存储.像热数据这种需要频繁读、写、更新,并且对性能要求很高的场景还是用多副本方式存储.很多研究工作致力于改善纠删码的性能,这些工作大多只是专注于其中一个方面.但是对于热数据存储来说,读、写、更新3种操作对性能的要求都很高,只有当纠删码在这3个方面的性能达到和多副本同样性能甚至更好时,才能真正替换掉多副本机制,获得更高的存储效率.近年来不断发展的非易失性内存(non-volatile memory, NVM)技术能够极大地改善计算机的计算能力和存储性能,消除了硬盘IO开销,使得纠删码用于热数据存储成为可能.
目前国内外存在少量的纠删码技术的研究综述.文献[7]从纠删码的编码、解码、更新3个方面对现有的研究工作做了概括性的总结分析,文献[8]仅关注了再生码和本地修复码2种编码的技术进展,文献[9]主要介绍编码方面的相关工作,文献[10]专注于数据恢复方面的工作,还没有专门一篇介绍纠删码更新这一重要工作领域的综述.文献[7]也仅仅是从更新规则角度介绍了纠删码几种基本的更新方法,并没有全面分析和纠删码更新有关的工作.所以本文将专注于纠删码存储系统中的数据更新操作,从硬盘IO、网络传输、系统优化3个方面对现有的纠删码更新的相关工作做了深入分析,并对目前具有代表性的编码方案的更新性能做了对比分析,最后指出纠删码未来的研究方向.
1 纠删码基本原理和背景知识
本节主要介绍了纠删码的编码、解码、更新的基本原理,分析了和多副本机制相比,纠删码更新的额外开销.
1.1 基本原理
在分布式存储系统中,数据通常以固定大小的块的形式存储起来,存储数据的块被称为数据块(data block),存储冗余信息的块被称为冗余块,在纠删码中也被称为校验块(parity block).存放数据块的节点和存放校验块的节点被分别称为数据节点和校验节点.纠删码存储系统中数据块和校验块被统称为编码块.存储开销和容错能力是分布式存储系统中非常重要的2个指标,本文对存储开销和容错能力的定义为:
1) 存储开销.指冗余块和数据块大小之和与数据块大小的比值,以3副本为例,其存储开销是3.
2) 容错能力.指存储系统在能够正常提供服务的前提下允许发生故障的机器的最大数目,还是以3副本为例,其容错能力为2.
纠删码作为数据存储中除了多副本之外的另一种保护数据可用性的方法,在提供相同容错能力的同时,能够极大地降低存储开销.因为目前大多数存储系统使用最广泛的是线性纠删码,所以本文将只关注线性纠删码.线性纠删码的编码、解码重构操作都能通过在有限域内的线性操作来完成.编码的基本原理是将原始数据以w位为单位在有限域(2w)[11]内线性结合得到对应的校验信息,w通常为8,也就是1 B[12].通常来说,存储系统会将被编码的数据划分成k个固定大小的数据块,通过编码生成m个校验块,然后将这k个数据块和m个校验块分别存储到不同的故障隔离域内.k个数据块和m个校验块组成1个逻辑条带(stripe),这是维护数据可用性的基本单元,能够允许1个条带内同时出现m个编码块损坏(容错能力为m),这样一种编码被称为(k+m,k)码.(k+m,k)码的基本原理的数学形式为
(p0,p1,…,pm-1)T=G×(d0,d1,…,dk-1)T,
(1)
其中,pi为校验块(0≤i≤m-1),dj为数据块(0≤j≤k-1),G为生成矩阵.在大多数存储系统中采用的纠删码都有这样一个特性:条带内的数据块以原生的形式存放,这样使得系统能够不用执行任何编码操作直接响应请求.图1是著名的RS(Reed-Solomon)编码[13]的编码过程的图形化表示.假设第1个和第2个数据块出现损坏,利用生成矩阵构造出解码矩阵(去除生成矩阵第1行和第3行后的方阵的逆矩阵),执行相应的矩阵运算即可恢复出损坏的数据块.
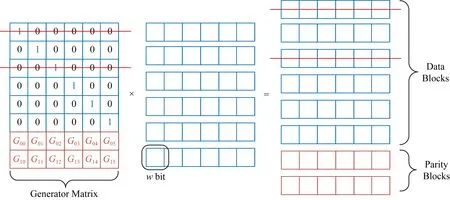
Fig. 1 A pictorial representation of erasure coding encoding principle
1.2 纠删码基本更新方法
从图1可以看出,校验块的生成是每个数据块对应位置的数据在有限域内的线性结合,当数据块发生变化时,校验块也需要相应地更新,如此才能在后期数据出现损坏或不可访问时利用相应的解码规则恢复出正确的数据.
最直接也是最传统更新校验块的方法,就是重新执行一遍编码.重新编码是一个非常耗时的过程,这需要将条带内所有的数据块读出,重新计算出校验块.以RS(5,3)为例,当更新数据块d0时,需要消耗5x网络IO(读出d1,d2,写回新编码块硬盘读写(读出d1,d2,写入但是在3副本中只需要3x的网络IO和硬盘写.当被更新的数据很小时,这种差距更明显.这种更新方法适合于条带内大多数数据都被更新的情况.如果只有1个数据块,甚至是1个数据块内的一部分被更新,这种方式的开销无疑是巨大的.
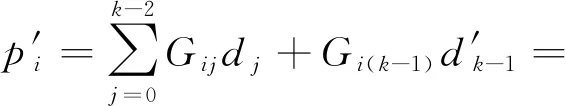
(2)
根据其推导过程可以看出,系统只需要计算出更新增量来更新校验块.图2展示了增量更新的流程,客户端将新数据发送到存储系统,存储系统需要读出原始数据块,计算出增量,并将增量发送到相应的校验节点.校验块节点再读出原始校验块,根据式(2)计算出最新校验块并持久化,这时存储系统才能将更新的数据覆盖原始数据,响应客户端.和重新编码的更新方式相比,这种方式消除了很多不必要的网络IO、硬盘IO,很适合被更新的数据较小的负载.但是可以看出,更新流程仍然很复杂,和基于多副本的数据更新性能有较大差距.多副本机制的数据更新过程类似于数据写入过程,只需要将更新数据发送到相应节点写入即可.而纠删码机制的更新过程涉及到数据块和校验块2种数据,会产生额外的网络IO、硬盘IO和更多计算.所以,针对基于纠删码机制的分布式存储系统,需要设计一个高效的数据更新方法来改善更新效率.
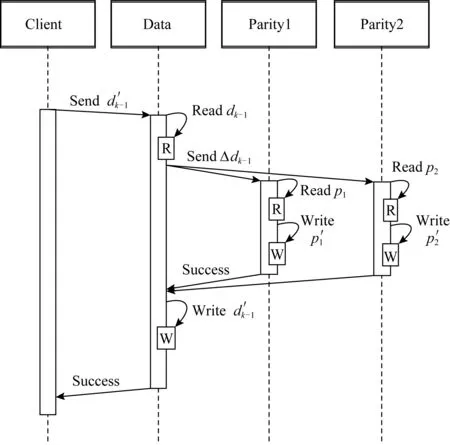
Fig. 2 Incremental update process
2 纠删码更新优化的研究进展
纠删码本身并不是针对存储系统设计的容错技术,最早是用在通信行业解决数据传输中的数据损耗问题[14-15],所以分布式存储系统中的一些限制因素比如硬盘IO、网络IO并没有被考虑进来,导致纠删码在用于分布式存储系统中时不可避免地产生很多冗余开销.这些开销主要体现在读、写、更新3种操作的性能方面.读、写操作主要因为编码、解码所产生的开销,已有相关综述对这些方面做了详细的分析总结,在此不再赘述.本节接下来将专注于更新方面的研究工作,根据这些研究工作的优化角度可将其划分为3类:第1类是针对硬盘IO开销的优化工作,从图2可以看出纠删码更新流程中都有“读后写”操作,这是导致硬盘IO开销比多副本大的一个主要原因,这类研究工作主要针对这一问题进行优化;第2类是针对网络传输的优化工作,这类工作主要根据纠删码数据更新的特点减少网络中的数据传输量,从而改善纠删码更新性能;第3类工作是针对自身分布式存储系统特点利用纠删码基本更新方法优化系统更新性能,这部分工作虽然改善了自身存储系统的更新性能,但是并没有对纠删码本身的更新性能做出改进优化,本文将这类工作称为系统优化.基于这3个分类标准,表1对纠删码更新优化工作中具有代表性的工作进行了分类总结,本节接下来会详细介绍.

Table 1 Classification Summary of Erasure Coding Update Related Work
2.1 硬盘IO优化
如1.2节所述,纠删码主要有重新编码和增量更新2种方法.重新编码会消耗大量的网络带宽、硬盘IO,不适合于被更新数据长度较小的情况.对MSR Cambridge traces[16]数据集分析可以发现平均每个更新操作涉及的数据长度普遍很小,超过60%的更新操作的数据长度小于4 KB.Harvard NFS traces数据集也具有类似的特征[17].所以目前的研究工作基本上都是基于增量更新做优化,尽可能减少更新过程中网络IO、硬盘IO的消耗.
增量更新方法一般使用就地更新方式,即新数据块和校验块直接写入旧块所在位置[18-19].相比于重新编码,增量更新方法能够很大程度上减少更新过程中参与的数据量,并且就地更新方式能够有效保证条带内数据的一致性.但是每一次更新操作都需要读取原始数据块和校验块,计算新校验块后方可写入新数据,这些“读后写”操作使得其性能仍然比多副本更新性能差.
为了在更新操作的关键路径上避免冗余的硬盘读开销,存储系统可以利用日志追加形式将新数据和校验块更新增量顺序写入到硬盘内来消除更新路径上原校验块的硬盘读,同时将随机写转换为顺序写,改善更新效率.这种方法被用于很多企业集群的存储系统内,像GFS[20],Azure.但是这种方式对读操作不友好,每次读取数据时都需要查找随机分布在日志中的所有更新增量得到最新数据,无法顺序读取数据,严重影响读操作的性能[21].此外,当有数据损坏需要执行纠删码恢复操作时,需要先合并数据,削弱了纠删码的恢复性能[22-24].日志追加的形式导致系统中同时存在着旧数据和新数据,也一定程度上降低了存储效率.
为了兼顾数据读操作和更新操作的性能,可以对校验块更新采取日志追加形式,数据块仍然采用就地更新方式.这种方式最先被Stodolsky等人[25]用于解决磁盘冗余阵列中的小写问题.他们提出PL(parity logging)方法,对校验块增量利用日志追加形式写入到硬盘内,对新数据使用就地更新方式,从而消除硬盘查找新数据和读取原校验块时间.纠删码存储系统也可以应用这种方法,但是这种方法仍然存在着恢复性能差的问题,因为恢复时需要查找并读取校验块增量来得到最新校验块信息.为了能进一步改善这个问题,Chan等人[26]提出PLR(parity logging with reserved space)方法.这种机制会在硬盘内紧挨着校验块的位置分配一些额外空间来存储未来的校验增量,确保每个校验块和它的更新增量可以被顺序访问,从而消除硬盘查找开销,将随机读转化为顺序读,改善恢复性能.这种方式虽然消除了校验块的“读后写”问题,但是数据块的“读后写”问题仍然存在,成为纠删码更新性能的一个瓶颈.
为了解决数据块的“读后写”问题,进一步减少更新过程中的硬盘IO开销,Li等人[27]提出PARIX方法,是一种预测部分写模式的方法,将“读后写”问题转变为单纯写操作.假设1个条带内的某个数据块dj被更新多次,代表数据块dj第r次更新,代表对应的校验块.通过式(3):
(3)
上述工作都是致力于改善纠删码更新过程中的“读后写”问题,可以看出相比于基本的纠删码更新方法,这些工作都对纠删码更新的硬盘IO开销做出了一定程度的优化,但是“读后写”问题并没有被彻底解决,和多副本方式的更新性能相比还是有一定差距.如何进一步优化硬盘IO开销,获得和多副本相近的更新性能仍需要研究人员继续探索.
2.2 网络传输优化
2.1节提到的工作都只是专注于条带内的单个数据块更新操作的优化.当1个条带内有多个数据块被更新或者多个条带同时被更新时,这些更新可以共享数据传输或者数据计算来减少网络传输的数据量,改善更新效率.此外,以上提到的优化工作所涉及的更新模式都采用星型结构来完成更新流程,所有被更新的数据节点连接到校验节点,数据节点或者校验节点会成为星型结构的核心,这会成为更新时的计算瓶颈或者网络瓶颈.Zhang等人[28]从负责计算任务处理的节点位置角度出发,提出PUM-P,PDN-P两种方式.通过将计算子任务尽可能放在距离数据近的节点上处理,来减少在网络中需要传输的数据量,从而改善更新性能.PUM-P方法将计算任务交给1个中心节点update manager,其负责计算出校验块增量,然后将校验块增量发送到各个校验节点上,由校验节点负责新的校验块的计算.这种方式相比于将所有计算任务交给update manager的方式,节省了原始校验块的网络传输.PDN-P方式将计算校验块增量的任务交给被更新数据块所在节点,减少原始数据块和更新后的数据块的网络传输,进一步减少更新过程中数据的网络传输.
PUM-P和PDN-P更新流程采用的便是典型的星型结构模式,相关研究[29-30]表明即使存在可用带宽更高的空闲链路,星型结构也无法充分利用其来改善数据传输效率.Pei等人[31]针对此问题提出一种基于树形结构的自顶向下的更新模式T-Update,来充分利用节点间的网络带宽,改善更新效率.T-Update通过一种机架感知的树形构建算法RA-TREE构建一棵最优更新树,其核心思想是尽可能选择较为临近的节点作为连接节点,以保证节点之间数据传输的高效性.Wang等人[32]在T-Update的基础上设计了一种更加通用的自适应更新模式,TA-Update,来改善T-Update的通用性.精心构建的树形结构相比于星型结构能够充分利用网络带宽来改善数据传输效率,但是这些工作仍然只是针对单点数据更新场景下的优化,单点问题依然存在.
Pei等人[33]针对多点更新提出一种分组流水线的更新模式Group-U,进一步优化更新效率,减少更新开销.Group-U将被更新的节点分成若干组,每组选择1个数据节点负责组织组内从其他数据节点发往校验节点的数据流,通过这种方式,将数据传输和计算限制在每一个分组内,从而改善更新效率.Huang 等人[34]也采用了分组的思想,通过改善多个数据块更新的并行性来改善分布式内存存储系统的更新延迟.
Shen等人[35]给出了不一样的解决纠删码多个数据块更新的思路.在真实的存储工作负载中,数据之间存在着关联性,这些关联的数据在访问负载中占有很大比例,通常会被一起访问.如果关联的数据分散在多个不同的条带中,那么对这些数据的1次更新操作就需要更新相应条带中的所有校验块.将这些关联的数据放在同一个条带内的话,就可以减少需要更新的校验块数目,降低网络带宽的占用,从而改善更新性能,所以文献[35]提出了一种基于数据关联性的条带组织算法CASO,通过检测数据块的被访问特征确认数据块的关联性,然后将数据块划分为关联和不关联2类.对于关联的数据块,CASO构造一个关联图来评估它们的相关程度,将条带组织问题转化为一个图分区问题.
在数据中心中,机架与机架之间的通信开销相比于机架内部的通信开销较大,通常1个节点的可用跨机架带宽在最坏情况下是机架内部带宽的15到120,这会成为限制系统性能的一个瓶颈.在纠删码存储系统中,为了增强容错能力,1个条带内的数据块和校验块通常会放置在不同机架内的节点上,这会导致在更新时产生大量的机架间数据传输.受限的跨机架网络带宽成为影响纠删码更新操作性能的一个瓶颈.针对这个问题,Shen等人[36]提出一种跨机架感知的更新机制——CAU,来减少跨机架的数据通信量.由式(2)可以看出,系统可以将条带内每个被更新的数据块的数据增量发送到校验节点更新校验块,也可以让条带内1个数据节点负责计算出校验增量,然后发送给校验节点更新校验块.这2种方式在不同的数据分布和更新负载下会有不同的跨机架数据通信量.所以CAU采用选择性的校验块更新方法,基于当前的数据分布和更新模式选择一个最优方式进行更新.此外,CAU会进行数据重定位,将同一个条带内更新的数据块尽可能部署在1个机架内,进一步减少机架间的数据通信.
以上这些研究工作优化了纠删码存储系统更新过程中需要网络传输的数据量,减少了网络带宽的开销,进一步改善了更新性能.如果将分组、跨机架感知、数据关联等特性融合在一起,相信会有一个更好的性能改进.
2.3 系统优化
还有一些研究工作是从分布式存储系统的自身特点出发,结合纠删码更新特点,优化更新性能.
Esmaili等人[37]在采用CORE编码[38]的HDFS中实现了增量更新方法,并和重新编码方法做了对比.CORE是一种将RS码和奇偶校验码简单耦合的编码,在数据恢复时优先使用奇偶校验码,改善恢复性能.在数据更新时,需要将更新增量发送到所有校验节点更新校验块.实验结果表明当1个条带中有小于一半的数据块被更新时,增量更新性能比重新编码好,反之比重新编码差,所以在实现系统更新策略时需要结合当前更新负载特征,灵活选择合适的更新方法来更新数据.
此外,在HDFS中写入的文件会被划分成多个固定大小的块,这些块通常很大,比如64 MB或者128 MB.这使得更新操作发生时,需要读取的数据量很大,极大地增加了网络IO和硬盘IO开销.Subedi等人[39]针对此问题提出了一种FINGER(fine grained erasure coding scheme)的想法来改善HDFS-RAID中的写操作和更新操作的性能.为了在不增加元数据大小的同时改善更新性能,他们在块内执行纠删编码而不是块与块之间,减少写和更新过程参与的数据量.Zhou等人[40]提出的采用数据页(page)粒度的SEDP模型和Zakerinasab等人[41]提出的基于字节优化的OptDUM都是采用了类似的思想来处理云系统内的频繁更新,减少更新过程中的计算开销和网络IO、硬盘IO开销,改善更新性能.
Chen等人[42]观察到分布式内存键值存储系统中大量零散的元数据需要被频繁更新.如果直接将纠删码机制移植到这类系统中,必将带来零散元数据更新开销大的问题.所以他们采用了一种混合存储方式,对元数据采用多副本机制,对数据采用纠删码方式,避免了元数据被频繁更新的开销,同时获得更高的存储效益.但是当数据对象也很小时[43],混合存储方式带来的存储效率收益就很低了,所以Yiu等人[12]针对由小对象负载主导的分布式内存存储设计了MemEC,按照固定块大小的方式来组织对象和元数据,并设计了2阶段索引来改善数据访问性能.Chen等人[44]采用了类似的思想设计了一个分布式文件系统来存储大量的小文件(比如应用中的大量图片).
本节介绍的这些研究工作结合了分布式存储系统的不同特点和纠删码更新特点,采用了不同对策来改善系统性能,但是纠删码本身的更新问题依然存在.
3 现有编码方案的更新性能
目前已有的一些研究工作通常是考虑优化纠删码的一个方面.但是某些场景下,比如热数据的存储,系统对读、写、更新3种操作的性能需求都很高.有些工作对纠删码数据恢复性能做了优化工作,但是使得更新操作的流程更加复杂.为了能够在降低热数据存储开销的同时达到和多副本一样的性能,需要从纠删码的编码、解码、更新3个方面去考虑优化.本节对目前一些比较有代表性的编码方案进行了分析,这些编码方案大多是为了优化数据恢复性能而专门设计的.为了衡量它们的更新性能,本节主要从网络开销和硬盘IO开销2方面与多副本做对比.网络和硬盘IO开销具体指的是对条带内1个数据块就地更新时所需要传输和读写的数据量,如表2所示.不失一般性,更新模式采用PUM-P方式,利用1个专门的中心节点update manager来处理更新请求.

Table 2 Comparison of Update Cost of Codes
RS编码是最流行的一种MDS码,在很多分布式存储系统中使用,比如Atlas[45],Colossus[46],f4.在RS(4,2)编码中,更新条带内的1个数据块,通常采用增量更新方式来更新校验块.update manager从相应的数据节点读出原数据块计算数据增量,将增量发送到2个校验节点,每个校验节点分别读出原校验块,计算最新校验块后写到硬盘内,整个过程产生3个编码块的硬盘读和写以及4个编码块的网络传输,比3副本多了3个编码块的硬盘读操作和1个数据块的网络传输.
由于RS编码将条带内k个数据块进行线性结合生成校验块,数据恢复时需要读取剩余的k个块才能执行解码操作.为了减少数据恢复过程中需要的数据量,局部修复码(local reconstruction codes, LRC)[47]被提出.LRC在RS编码的基础上引入局部校验块,在恢复数据时优先使用局部校验块,从而减少恢复过程需要的数据量.
图3展示了LRC(6,2,2)编码,其中k=6代表6个数据块(d0,d1,d2,d3,d4,d5),l=2代表2个局部校验块(p0,p1),r=2代表2个全局校验块(p2,p3).6个数据块被分为2组,分别对分组内数据块线性结合得到局部校验块p0(由第1组d0,d1,d2线性结合得到),p1(由第2组d3,d4,d5这3个数据块线性结合得到).p2,p3由所有数据块计算得到.在修复时优先使用局部校验块,从而减少数据恢复需要的数据量,改善纠删码恢复性能.当某个数据块被更新时,需要更新对应的局部校验块和全局校验块,其产生的开销和RS(6,3)编码一样.由于LRC只需要在标准RS编码的基础上引入局部校验块,实现简单,所以已被Azure[48],Facebook[49]使用.需要注意的是,LRC编码本身不是MDS码,数据恢复只能访问固定的节点集合.相比于RS编码,LRC编码引入的局部校验块虽然可以降低恢复开销,但是当不同分组内的数据块被同时更新时,会引入额外的硬盘IO和网络数据传输开销.
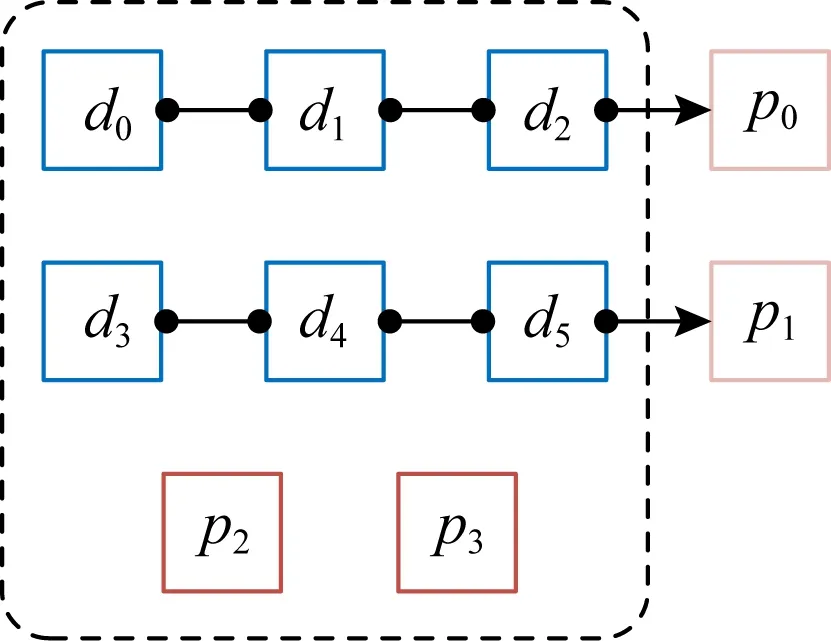
Fig. 3 LRC(6,2,2) code
再生码(regenerating codes)[50-51]RGC(n,k,x)是另一种减少纠删码恢复过程中网络数据传输开销的编码,其能够通过任意k个块恢复整个条带的数据,任意x(k≤x≤n-1)个节点能够恢复单个节点故障.虽然RGC编码需要更多的节点参与数据恢复,但是总的数据传输量更少,从而减少网络开销.由于在恢复过程中需要从更多的节点上读取数据,虽然总的网络传输的数据量减少,但是显著增加了硬盘IO开销和计算开销.RGC编码主要分为2类:一类是MSR码,与RS编码相比有同等存储开销,具有更低的网络开销;另一类是MBR码,通过存储更多冗余数据获得更低的网络开销.由于MBR的存储利用率较低,所以对其不做考虑.EMSR(4,2,3)码[52]是一种MSR码,利用干扰对齐技术同时消去多个不需要的变量,如图4所示,每个数据块划分为2个子块,每个校验块也包含2个校验子块.如果数据块d0损坏,d1,p0,p1三个块分别将子块求和合并成单个子块,然后发送到修复节点,修复节点通过对接收到的3个子块进行计算得到d0.整个修复过程中,网络中只需要传输3个子块,若是RS(4,2)编码,则需要传输4个子块.若d0块被更新,与其子块a0,b0相关的所有校验子块都需要被更新.虽然EMSR(4,2,3)在更新过程中传输和读写的数据量和RS(4,2)相同,但是由于在校验节点上更新校验子块的操作更复杂,导致其比RS(4,2)编码消耗更多计算资源和硬盘IO资源.
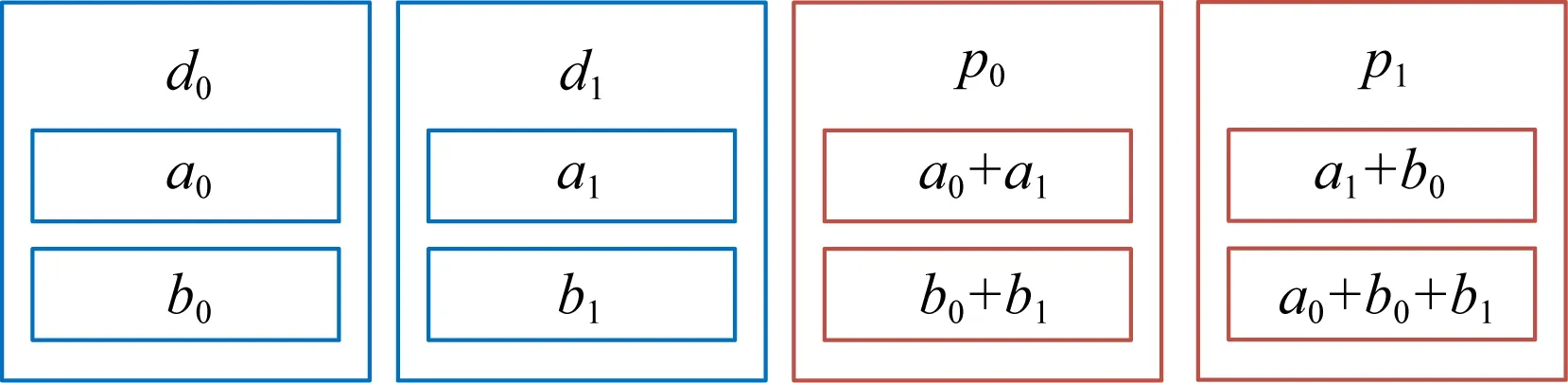
Fig. 4 EMSR(4,2,3) code
Hitchhiker-XOR码[18]是在现有的RS码基础上对其改造,将RS编码中的2个条带组合成1个更大的条带.2个子条带之间通过一些冗余信息产生关联,从而减少恢复时所需要的数据量.如图5所示,Hitchhiker-XOR(4,2)码先对每个子条带进行RS(4,2)编码,然后将第2个子条带内的第2个校验块与第1个子条带内的数据块进行异或运算.若a0,b0两个数据块出现损坏,可以先用b1,f1(b)恢复出b0,然后用b0和b1计算出f2(b),最后利用f2(b),a1和f2(b)+a0+a1恢复出a0.整个过程需要4个块参与,这虽然与RS(4,2)编码相同,但是这仅限于此实例.当子条带内块数量较大时,比如说10个数据块、4个校验块时,恢复a0,b0只需要13个块,相比于RS(14,10),数据量减少了35%.由于一个子条带内的某些数据块信息会关联到另一个子条带内的校验块,所以更新开销会相应增大.比如说更新a0,需要更新f1(a),f2(a),f2(b)+a0+a1三个校验块,更新b0则只需要更新f1(b),f2(b)+a0+a1两个校验块.虽然Hitchhiker-XOR码减少了数据恢复所需要的数据量,降低了网络传输开销和硬盘IO开销,但是却导致了更新性能的削弱.
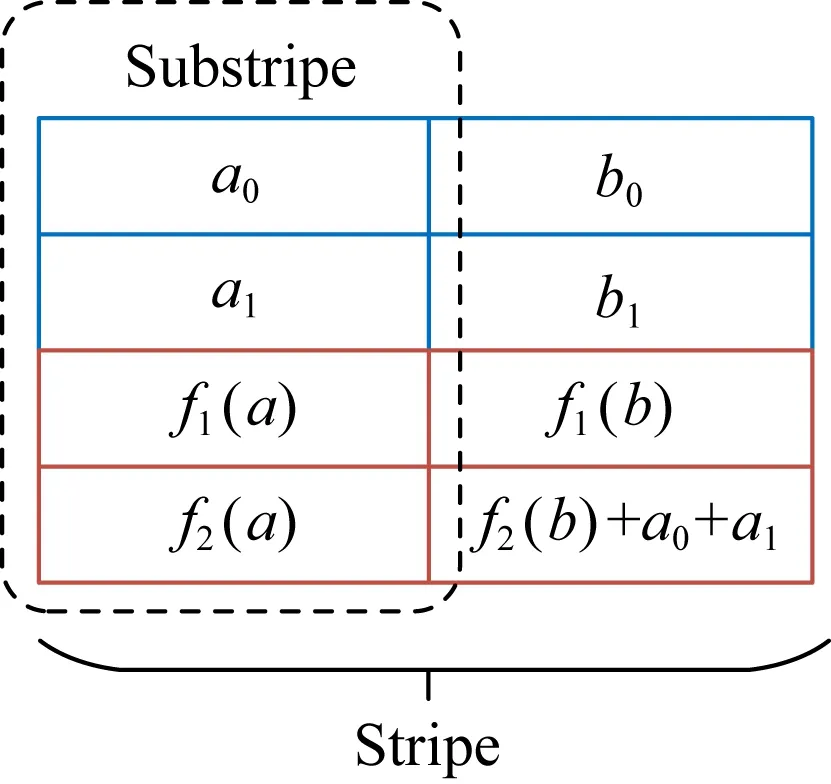
Fig. 5 Hitchhiker-XOR(4,2) code
因为多副本机制的数据更新过程类似于数据写入过程,只需要将更新数据发送到相应节点写入即可.以3副本为例,更新过程只需要3x的网络传输和硬盘写操作.表2中对比了各编码方案的更新开销,可以看出,优化了纠删码恢复性能的各类编码都导致了纠删码更新性能的削弱,使得纠删码更新性能比多副本机制更差.由于目前纠删码的读、写、更新3种操作的性能都弱于多副本,使得热数据存储这种对性能要求较高的场景无法使用纠删码容错机制,只能使用多副本来保证数据高可用,导致热数据的存储开销很大.
4 未来研究趋势
从第3节的分析可以看出,目前纠删码更新操作的性能仍然无法与多副本机制相媲美,所以纠删码大多用于冷数据或者温数据这种一次写入后很少被访问和更新的场景,需要频繁访问和更新的热数据仍然使用多副本机制来存储.如何应用纠删码改善热数据存储开销的同时,满足系统性能需求是一个值得深入研究的方向.
伴随着非易失性内存技术的不断发展,计算机计算能力和存储性能得到了质的提升.比如新兴的电阻式随机存取存储器(RRAM)[53-54]不仅可以提供非易失性存储,还可以提供矩阵向量乘法的内在逻辑.磁畴壁存储器(domain-wall memory)[55],又被称为赛道存储器(racetrack memory)[56],它在提供非易失性特性的同时,能够提供和DRAM非常接近的访问延迟、密度和功耗.笔者现有工作[57-58]利用其构建了内存计算架构极大地改善了系统的吞吐量、延迟和功耗.可以看出NVM的特性能够很好地消除纠删码更新过程中的硬盘IO开销,降低纠删码存储系统的计算开销和功耗,使纠删码用于热数据存储成为可能.但是NVM本身也具有一些缺点,比如在数据一致性方面,当节点因故障重启后,NVM内部之前的数据还在,这些数据中有可能存在脏数据,这要求使用NVM的系统需要专门的管理机制来管理数据.再加上纠删码自身的编码规则和特点,这势必会增加系统设计的复杂度.如何结合NVM新硬件和纠删码自身特点,构建一个安全、高效的分布式存储系统是一个值得深入研究的方向.
目前很多分布式存储系统,尤其是云系统都是采用追加式更新的方式来更新数据.更新数据以新数据的形式写入,原有数据被标记为无效数据.这样将随机写转化为顺序写操作,来优化写的性能.这种日志结构存储方式避免了纠删码更新所带来的问题,但是引入了一个新的问题,就是无效数据所占用的空间回收问题.为了释放掉无效数据占用的空间,垃圾回收功能被引入进来.垃圾回收是一个代价比较昂贵的操作,需要消耗大量的计算机资源,所以垃圾回收功能通常在节点空闲时被触发,避免对系统性能产生影响.但是在热数据的存储场景中,更新操作频繁,如果触发垃圾回收的周期太长,就会使得大量无效数据聚集,降低存储效率,频繁触发垃圾回收又会影响系统性能.而且,采用纠删码机制的日志结构存储系统中的垃圾回收和传统的基于多副本机制的日志结构存储系统的垃圾回收有所不同.为了方便描述,本文将前者称为ECGC(erasure coding garbage collection),后者称为MRGC(multiple replication garbage collection).MRGC和ECGC主要有3点不同:
1) 在MRGC中,垃圾回收的粒度通常以段(segment)或者块(block)为单位.segment内的有效数据拷贝到新的位置后即可回收旧segment.但是在ECGC中,垃圾回收需要以条带为粒度.由于1个条带内数据块和校验块之间存在着关联性,为了保证条带内数据的高可用,只有当条带内所有有效的数据都安全地拷贝到新的位置后才可以回收旧条带内的数据.
2) 条带内的数据块通常位于不同节点,如图6所示,2个条带内的数据块和校验块均匀分布在集群内的每个节点上,如果对这2个条带内的无效数据进行回收,就需要将条带内的每个有效数据块从相应节点上读出,重新编码持久化到不同节点,然后才可以删除原来的条带.这个过程涉及到集群内的每个节点,如果不仔细设计垃圾回收机制,ECGC有可能影响到整个集群处理上层请求的能力.MRGC则不存在这个问题.
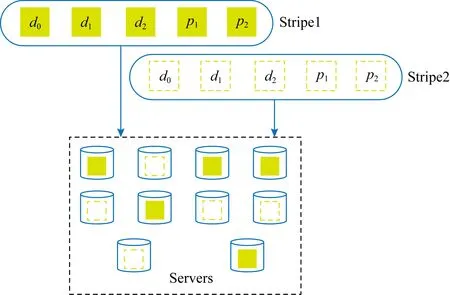
Fig. 6 Data stripe distribution in erasure-coded storage systems
3) MRGC中1次回收的有效数据没有长度限制,但是在ECGC中1次回收的有效数据的长度通常需要k个数据块的整数倍,因为只有满足(n,k)编码的长度要求时才能进行编码并持久化.这要求ECGC在选择条带进行垃圾回收时需要考虑到该特点.
为了不影响系统的延迟和吞吐量,使用纠删码机制的日志结构存储系统需要一个针对纠删码优化的高效的垃圾回收机制,但是目前这方面的研究工作非常少.Li等人[59]设计了一个启发式垃圾回收算法,其基本想法是将无效数据占用比例最大的条带内的有效数据迁移到无效数据占用比例最小的条带内,尽可能减少垃圾回收过程中数据块的移动数量.为了进一步减少数据块的移动,改善垃圾回收效率,他们利用工作负载中键倾斜分布的特点,对客户端发来的数据按照热度进行排序,将热度相近的数据放置在相同的条带内.因为热度相同的数据更容易被一起访问,被更新时无效数据就会更多地聚集在1个条带内.如图7所示,条带1内有2个无效数据块,条带2内有1个无效数据块,将条带1内剩余的1个有效数据块迁移到条带2内,然后即可删除条带1.启发式垃圾回收一定程度上减少了垃圾回收过程中数据的传输和读写,但是垃圾回收过程中所产生的数据迁移,相当于触发了更多的数据更新请求,这些请求会和上层应用请求交错在一起,占用系统网络带宽、硬盘IO等资源,使系统吞吐量和延迟产生波动.

Fig. 7 Heuristic garbage collection
以日志结构方式来更新数据消除了纠删码更新所导致的性能削弱,但是纠删码条带内部数据一致性的特征导致垃圾回收活动有可能波及到存储系统内的每个节点,导致系统性能波动,尤其是在热数据存储场景下.针对纠删码的特点设计一个高效的垃圾回收机制,在不影响系统响应上层请求能力的同时,降低存储开销值得深入探讨.
5 总 结
随着数据量的与日俱增,分布式存储系统的开销越来越大,多副本容错机制使得这种情况更加严重.伴随着硬件技术的不断发展,越来越多的存储系统将目光从多副本机制转向纠删码,但是纠删码本身复杂的规则导致其性能较差.本文专注于纠删码存储系统中的数据更新操作,从硬盘IO、网络传输、系统优化3个方面对相关工作进行了总结分析,并对目前具有代表性的编码方案的更新性能做了对比分析,最后展望了未来研究趋势.与多副本机制相比,现有纠删码更新方案会产生更多网络IO、硬盘IO开销,导致纠删码存储系统的更新操作的性能较差.如何结合新硬件技术特点,从纠删码编码规则本身和系统架构角度对其优化,还存在巨大技术挑战.目前较优的一种避免纠删码更新开销的方案是采用日志结构追加式更新,但是如何设计一个高效的垃圾回收机制来应对热数据这种频繁更新的场景仍需探索.
