煤炭上市企业营运资金管理风险预警分析
2020-11-09周英山西焦煤焦炭国际交易中心股份有限公司
周英 山西焦煤焦炭国际交易中心股份有限公司
一、样本的选取
本文研究对象选取的是煤炭企业上市公司,为了保证研究的客观和准确,在对煤炭企业上市公司样本选取时遵循以下原则:一是,由于A 股和B 股上市公司在编制财务报告时,选取不同的会计准则,从而导致A股和B 股上市公司财务报表数据之间缺乏可比性,综合分析之后只运用A 股上市公司;二是,选取2015-2019 年持续经营的上市公司的财务数据,数据选取了较新,能够满足研究的需要。根据上述需要遵循的原则,在剔除掉不符合的样本企业后,最终选取中国神华、上海能源等31 家企业作为研究样本。
二、主成分分析
(一)主成分的确定
对于主成分的提取主要有以下两种方法,一是提取所有特征值大于1 的成分作为主成分,二是依据累计贡献率所达到的百分比进行提取。通过综合分析,本文研究选取特征值大于1 的成分作为主成分。根据表1所示,可以提取出4 个主成分且4 个主成分的方差累计贡献率达到87.711%,由此可见,提取的4 个主成分足以能够代替原来的变量,能够包含原变量中大部分的财务信息。
(二)计算因子得分
在因子变量确定之后,计算各因子在具体样本上的具体得分数值。在计算出因子得分之后,对因子变量替换原有变量进行数据分析,进而实现降维和简化的目标。各因子可以表示为原财务比率的线性表达式,因子得分矩阵如表2 所示:
(三)计算综合得分
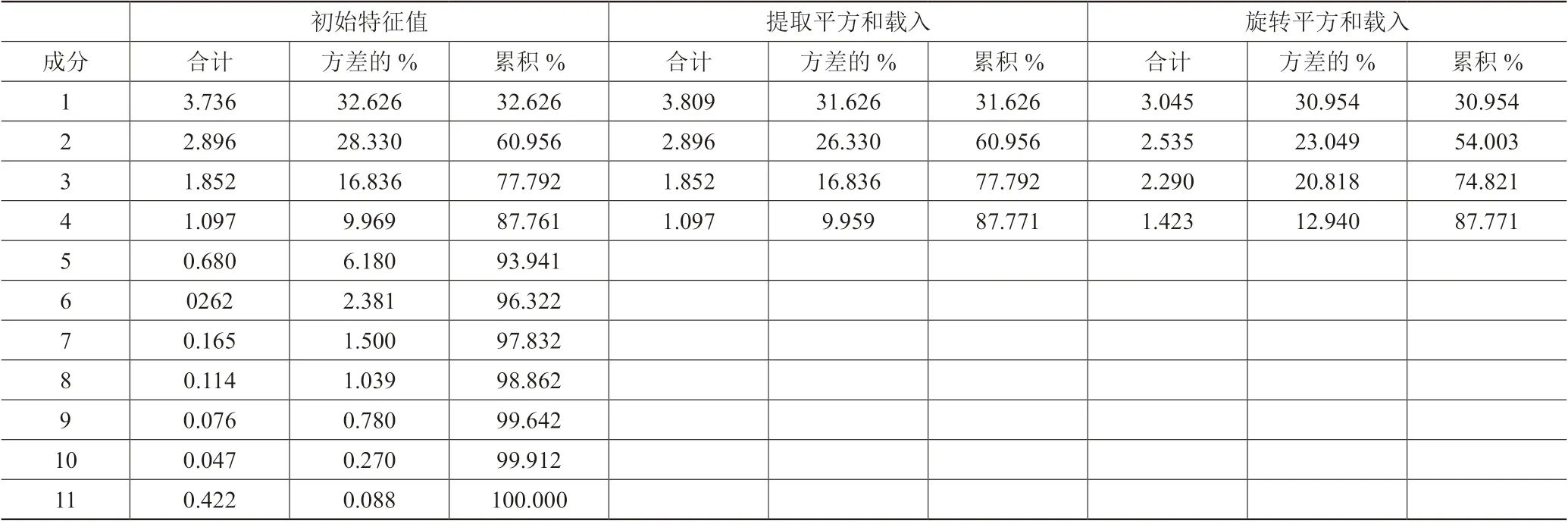
表1 总方差解释表

表2 成分得分系数矩阵
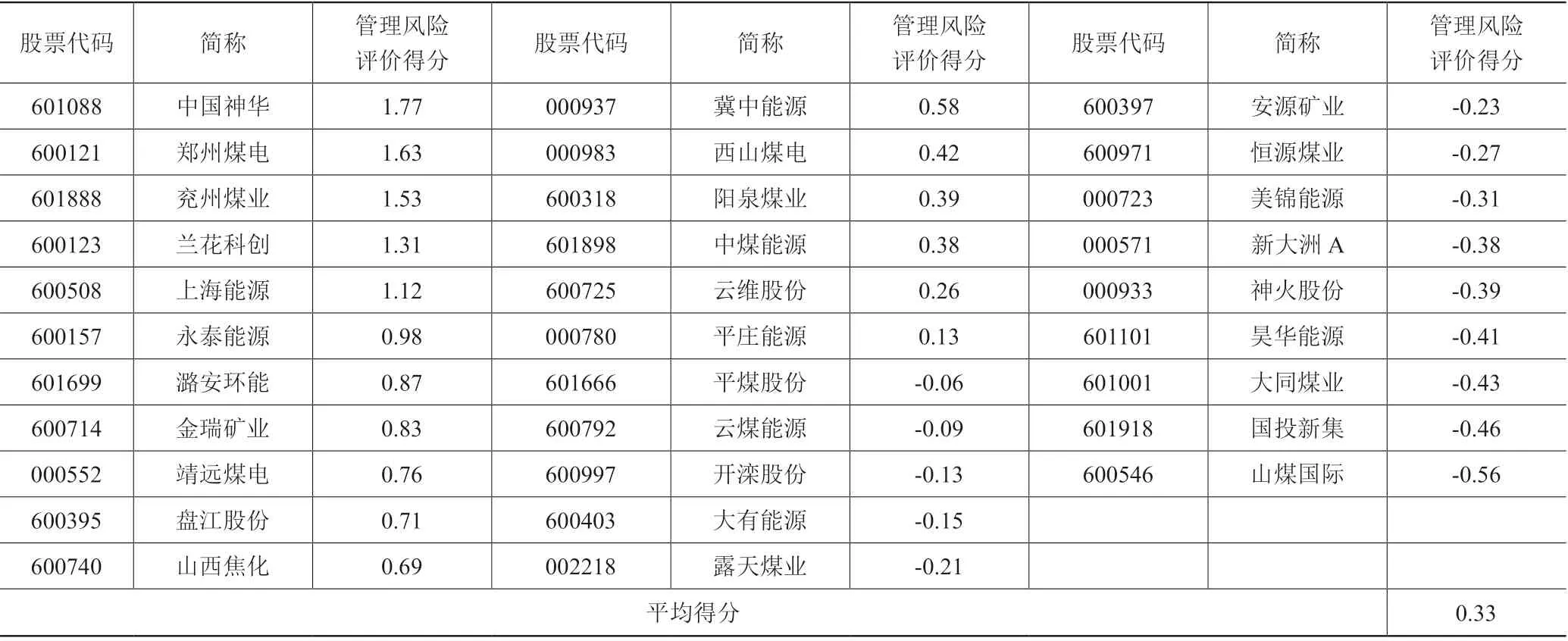
表3 2015-2019 年煤炭上市企业营运资金管理综合评价得分

表4 模型的拟合检验
利用旋转主成分变量系数矩阵,四个主成分的表达式为:
F1=0.147X1+0.257X2-0.024X3+0.048X4-0.040X5-0.009X6-0.133X7+0.037X8+0.156X9+0.089X10+0.536X11
F2=0.027X1-0.013X2+0.020X3+0.039X4+0.049X5+0.315X6-0.011X7+0.289X8-0.013X9+0.011X10-0.156X11
F3=-0.051X1-0.159X2+0.029X3+0.066X4+0.027X5+0.120X6-0.077X7+0.033X8-0.033X9+0.412X10-0.196X11
F4=0.328X1+0.023X2+0.081X3-0.053X4+ 0.038X5-0.260X6-0.232X7-0.129X8+0.017X9-0.025X10-0.057X11
对上述主成分的表达式进行分析,得出指标变量系数需要采用绝对值进行表示,才能更全面的体现出代表的实际意义。
通过对四个主成分进行经济解释,可以看出,四个主成分从不同的方面反映了企业营运资金管理风险状况,但是不能从整体上把握企业的营运资金管理风险,因此,研究以表3 中各主成分的贡献率大小为权数,计算煤炭上市企业营运资金管理综合得分水平,其表达式Y 为:
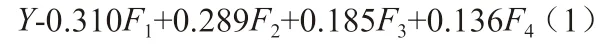
将附表标准化后的数据代入建立的营运资金管理综合得分计算公式中,计算得出2015-2019 年煤炭上市企业营运资金管理综合得分,如表3 所示:
从表3 可以看出,超过营运资金管理综合平均得分的企业有15 家以及低于平均得分的企业有16 家。将综合得分高于平均分的企业划分为“稳健性企业”,将综合得分低于平均值的企业划分为“高风险企业”。因此本文得到的煤炭上市公司营运资金管理风险预警模型所需要的15 家“稳健性煤炭上市公司”和16 家“高风险煤炭上市公司”,从而完成了对样本数据的划分,得到了两组研究样本。
三、模型预警效果检验
主要选取我国A 股股票市场中2015 年至2017 年预披露年报中显示被“特别处理”(ST)公司(国投新集、神火股份、山煤国际),和非ST 公司(中国神华、兖州煤业、阳泉煤业、盘江股份、上海能源、永泰能有)为研究对象。
三年的样本数据进行结束后,再对Logistic 回归模型进行拟合检验,得到结果如表4:
分析模型的拟合检验结果可知,2017年的负2 倍对数似然值和McFadden 最小,并且Cox 和Snell、Nagelkerke 的值最大,验证了在2015 年模型的预警具有很好的效果,在最靠近被ST 处理的年份时,公司的财务风险发生的概率是最高的,与现实实际情况是符合的。
四、结论
本文通过对已有营运资金管理风险预警模型的分析,选取深沪两市2015 至2019 年31 家煤炭企业A 股上市的企业为样本,借助了SPSS19.0 软件,运用因子分析法,计算煤炭上市企业营运资金管理综合得分;通过Logistic 回归分析建立起营运资金管理风险预警模型,并且验证了模型的预警效果,得出以下结论:越靠近被预警处理最近的年份,模型越具有较高的预警效果。也在一个侧面反映出煤炭企业上市公司的营运资金管理风险是一个持续积累的过程,越靠近被预警处理的时间,模型越具有较高的预警效果。
