一种网络资源与环境耦合关系预测技术
2020-11-06刘颖罗涛杨灿
刘颖 罗涛 杨灿


【摘 要】
针对复杂多维环境下弹性网络资源受到气象、地形、电磁、时空等环境影响的问题,提出了一种网络资源与环境耦合关系预测技术,主要目的是实现网络资源与环境耦合关系预测,提升网络资源的利用率。通过实测验证了技术的可行性,满足实际网络通信过程中对网络资源与环境耦合关系的预测。
【关键词】弹性网络;网络资源;环境耦合
0 引言
在实际网络通信[1]过程中,由于设备故障、环境突变等问题,导致环境感知设备采集到不完整或不准确的数据,进而引发网络资源[2]状态的表征结果异常。网络资源状态的表征是否准确,对网络资源的利用率有很大的影响。
本文针对复杂多维环境下弹性网络资源受到气象、地形、电磁、时空等环境影响的问题,提出了一种网络资源与环境耦合关系预测技术,满足在实际网络通信过程中,对网络资源与环境耦合关系预测,提升网络资源的利用率。
在实际网络通信过程中,环境感知设备采集到大量不完整或不准确的数据,迫切需要解决通信信息的清洗与提炼、海量信息智能分析处理等关键问题。下面分别从数据预处理[3]、預测方法[4]综述现阶段研究现状。
由于设备故障、环境突变等问题,导致环境感知设备采集到不完整或不准确的数据,所以,需要对缺失值进行填充[5]。在数据清洗过程中,经常遇到空值问题。一般可分为两种空值问题类型:(1)数值的不完整;(2)数值为空(即空值)。数值不完整包括数据部分或所属字段没有值;空值的定义是实际不存在而空的值。处理方法有:(1)根据某种规则推导出某些缺失值;(2)用最小值、中值、最大值、平均值替换缺失值;(3)手动输入一个可接受范围内的值等。
目前有很多机器学习算法被用于预测的研究,常见的有K近邻(KNN, K Nearest Neighbors)[6]、决策树(DT, Decision Tree)[7]、支持向量机(SVM, Support Vector Machines)[8]等算法。
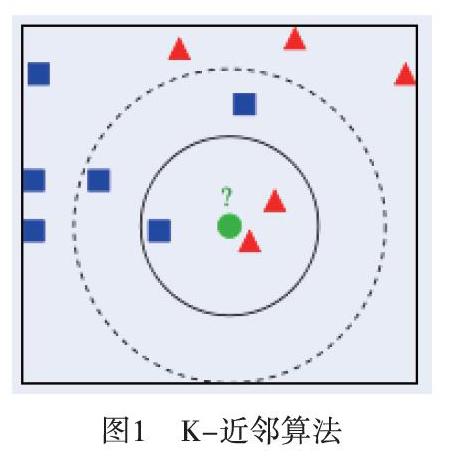
(1)K-近邻算法
K-近邻是测量特征之间的间距进行分类。已知训练集,对于新的输入数据,在训练集中找到与该数据最接近的K个数据,这K个数据的多数数据属于某一个类,就把该输入数据归类到这个子类中。如图1所示:
(2)决策树
决策树算法是一种归纳式的学习算法,目的在于从数据源中推理和归纳出树形结构的决策树表现形式。决策树的思想是“分而治之”,该算法从一个结点开始,根据一定的分支标准划分样本,一直加入新节点分割上一次分裂剩下的样本,直至所有样本被准确归类为止。决策树会训练模型根据特征一级级地分裂。而分裂的阈值会根据训练的数据学习得,最终实现预测。
(3)支持向量机
支持向量机是二分类模型,基本模型是在特征空间上的间距最大的线性分类器,间距最大使它有别于感知机,能较好解决非线性、小样本以及高维模式识别任务。
1 总体方案
本方案架构示意如图2所示。首先,通过基于多维模糊映射、服务扩充的方法对原始的不完整参数集进行预处理;其次,通过基于多维环境参数的特征表征方法,对数据进行特征构造,以获得具有更强表征能力的数据;然后,融合前向选择、后向选择、模拟退火[9]的方法对特征进行降维,降低各维度的变量空间及多维表征模型训练的复杂度;最后,采用基于决策树的模型训练方法,对数据进行训练学习预测,实现网络资源在复杂环境约束下的精确描述。
1.1 预处理阶段
针对当前实际网络通信过程中,由于设备故障、环境突变等问题,导致环境感知设备采集到不完整或不准确的数据,本文提出基于多维模糊映射、服务扩充的缺失值处理的补全方法,能快速准确地补全缺失值,达到提高模型效率的目的。该方法通过多维模糊推理,利用历史数据对缺失的环境参数进行预测,完成不完整参数集向完整参数集的映射过程。算法流程如图3所示:
对于一些特定的字段,通过第三方服务进行填充。例如根据时间、地点查找气象表填充天气。通过经纬度定位填充地形。对于这些特殊字段,服务扩充的方式能够更加精准地填充缺失值。通过气象服务填充天气示意图、通过地形检索服务填充地形示意图,如图4所示:
1.2 特征构造阶段
为了增强对环境资源的表征能力,本文提出了基于多维环境参数的特征构造方法,从而更准确地学习网络资源与多维环境的表征关系。通过对不同的特征进行交叉组合,使得特征之间可以相互联系相互作用,从而表达出单一特征所不具有的非线性性。交叉构造特征采用加、减、乘、除、平方、均值、方差等方式进行特征组合。即对于数值型特征,让两两特征在数值上进行加法、减法、乘法、除法等运算以及均值、方差等操作。特征构造方法如图5所示:
1.3 特征约简阶段
为了筛选特征构造方法产生的冗余特征,本文提出了基于前向搜索、后向搜索、模拟退火算法融合的特征约简方法。融合前向搜索、后向搜索方法的各自的优点。此外,引入模拟退火机制,该机制有效克服序列搜索算法容易陷入局部最优值的缺点。通过融合三种方法,本文增加了特征选择和特征约简的有效性,从而保留优良的特征。特征约简流程如图6所示:
1.4 模型训练阶段
为了增强模型的学习能力和泛化能力,本文采用集成学习的方式进行训练,提出了基于决策树的集成分类模型构建及训练方法。由于多维环境对网络资源的影响呈现非线性的关系,常规的拟合方法对多维非线性函数的预测结果精度较低。针对这一问题,本文采用了决策树的方法用来学习多维非线性函数的映射,将资源状态表征为多维环境因素的多元函数。决策树认为,物以类聚、人以群分,在特征空间里相近的样本,那就是一类。如果为每个“类”分配的空间范围比较小,那么,同一个类内的样本差异会非常小,以至于看起来一样。换句话说,如果我们可以将特征空间切分为较小的碎块,然后为每一个碎块内的样本配置一个统一的因变量取值,就有机会做出误差较小的预测。在本文任务中,每棵决策树根据我们提供的发射净空角、发生概率、干扰、海拔等特征,将特征空间切分很多小碎块,并为这些碎块提供因变量的取值。通过减小这个预测的取值和真实的取值的误差来引导优化。
2 实验
2.1 数据集
在实际网络通信过程中,记录了73 478条数据,数据中特征包括发射点、接收点、发射点海拔、接收点海拔、发射净空角(度)、接收净空角(度)等,标签为吞吐率[10]、丢包率、时延[11]。根据特征分别预测标签。
数据集经过特征构造后,通过随机采样的方式将其划分为训练集、验证集、测试集。使用训练集来训练模型,通过模型在验证集上的效果好坏来选择模型,然后在测试集上对模型方法进行评估[12]。数据集组成如图7所示:
2.2 评价指标
均方误差是最常用的回归损失函数,它通过衡量“平均误差”的方式来评价数据的变化程度,其值越小,说明预测模型描述实验数据具有更好的精确度。本文的任务中预测吞吐率、丢包率、延时都是回归任务,所以选取该指标作为本文实验的评价指标。
2.3 实验流程
实验流程见图8所示。实验步骤如下:
步骤1:载入73 478条数据;
步骤2:随机抽取其中的7 259条记录作为测试集,剩下的66 219条记录作为训练集,再在训练集中抽取7 000条记录作为验证集;
步骤3:选取原始特征;
步骤4:通过对多维环境参数进行特征构造;
步骤5:采用前向搜索、后向搜索、模拟退火算法融合的特征约简方法特征约简;
步骤6:构建基于决策树的模型;
步骤7:使用验证集选择最优模型;
步骤8:测试集数据输入模型中进行预测。
2.4 性能测试
模型训练及预测消耗的时间如表1所示:
通过性能测试结果显示,预测时间小于0.02 s,预测效率高,可实现批量预测。
2.5 测试结果
各模型预测的MSE值如表2所示:
均方误差是测试集的7 259条记录中预测结果和真实值的均方误差。其值越接近0,则预测值与真实值的偏差越小。“丢包率(%)”字段的MSE几乎为0,预测结果几乎达到了100%的准确率。为了更直接的展示预测效果,预测结果与真实值的拟合图如图9、10、11所示。
绿线代表预测值,红线代表真实值。对于“丢包率”,可以观察到预测结果与真实结果几乎完全拟合。
3 结束语
本文针对复杂多维环境下弹性网络资源受到气象、地形、电磁、时空等环境影响,提供了一种网络资源与环境耦合关系预测技术,实现网络资源在复杂环境约束下的精确描述,提升网络资源的利用率。同时MSE测试结果较低,预测结果准确率高,并且在性能测试中,预测时间短,能高效地预测。验证了一种网络资源与环境耦合关系预测技术的可行性,对实际应用具有较强的指导作用。
参考文献:
[1] 田孝华. 现代军事通信与通信新技术[J]. 无线通信技术, 1996(3): 54-57.
[2] 于骊,史子博,舒炎泰,等. 调度和拥塞控制相结合的无线网络资源分配模型[J]. 计算机应用, 2009,29(2): 487-490.
[3] 陈莉,焦李成. 基于混合优化算法的数据预处理算法Ⅱ[J]. 计算机应用与软件, 2007,24(3): 22-24.
[4] 李旭然,丁晓红. 机器学习的五大类别及其主要算法综述[J]. 软件导刊, 2019,18(7): 4-9.
[5] Jonathan T O, Gerald A M, Sandrine B. Special online collection: dealing with data[J]. Science, 2011,331(6018): 639-806.
[6] Cover T M. Rates of convergence for nearest neighbor procedures[C]//Proceedings of the Hawaii International Conference on Systems Sciences. 1968: 413-415.
[7] Quinlan J R. Induction of decision trees[J]. Machine learning, 1986(1): 81-106.
[8] 丁世飛,齐丙娟,谭红艳. 支持向量机理论与算法研究综述[J]. 电子科技大学学报, 2011,40(1): 2-10.
[9] 潘蔚. 模拟退火算法和应用[J]. 经济技术协作信息, 2008(32): 75.
[10] 刘凯,章欣. 多跳移动分组无线网络的吞吐率分析[J]. 西安电子科技大学学报, 2000,27(1): 70-75.
[11] 黎文伟,张大方,谢高岗,等. 基于通用PC架构的高精度网络时延测量方法[J]. 软件学报, 2006,17(2): 275-284.
[12] 范永东. 模型选择中的交叉验证方法综述[D]. 太原: 山西大学, 2013.
