“动态”近红外光谱结合深度学习图像识别和迁移学习的模式识别方法研究
2020-11-06孙禧亭袁洪福宋春风
孙禧亭,袁洪福,宋春风
(北京化工大学 材料科学与工程学院,北京 100029)
山羊绒与山羊绒/羊毛混纺织物,以及纯棉与丝光棉织物均为化学组成非常接近且形态复杂的样品,且类内变化较大,同类织物在捻度、质地结构、染整工艺等方面均有明显的差异。由于类间化学组成变化引起的近红外光谱差别相对小,而类内形态变化引起的光谱差异较大,即噪声对有用信息的淹没作用较大,导致采用“静态”近红外光谱结合常用的多元分析方法,难以将其有效区分,是近红外光谱分析领域中尚未解决的分类难题[1]。
近红外光谱判别分析过程一般包括光谱预处理、特征提取和模式识别等步骤。常用的光谱预处理方法包括导数[2]、多元散射校正(MSC)[3]、标准正态变量变换(SNV)[4]、小波变化等[5]。特征提取包括主成分分析(PCA)[6]、线性判别分析(LDA)[7]、独立成分分析(ICA)[8]和基于流型学习等方法[9]。簇类独立软模式识别(SIMCA)、偏最小二乘判别分析(PLS-DA)和支持向量机(SVM)[10]是最常用的光谱模式识别方法。这些识别方法对于光谱差异较为明显的样品是有效的,已被广泛用于诸多领域[11- 12]。但对于上述化学组成差异小、形态或环境因素变化干扰大的样品,基于近红外光谱的上述判别方法难以获得满意效果。因此,研究解决上述问题的方法具有重要的理论和应用意义。
本文旨在建立一种全新的光谱分类方法,采用外部扰动光谱和二维相关光谱方法,构造能够区分样品细微差别的“化学图像”,借助同时具有自动特征提取与分类功能的深度卷积神经网络(Convolution neural network,CNN)方法对化学图像数据进行分类[13-14]。采用迁移学习方法,将实际成熟的CNN图像分类模型适应于本研究的近红外光谱分类问题,以期解决近红外光谱分类识别形态复杂且组成高度相似的不同类样本的分类难题。
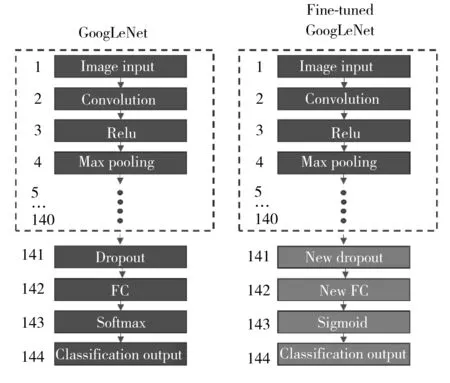
图1 GoogLeNet网络架构和迁移学习示意图Fig.1 The architecture of GoogLeNet model and its transfer learning
1 实验部分
1.1 实验方法
对于化学组成高度相近且形貌差异大的不同类样品,凭借其“静态”光谱所包含的有效分类信息量,使用常用的多元分析判别方法不足以将它们有效分类。基于它们对外部扰动(如纤维吸水性)存在差异的现象,对样品施加(水分)扰动,同时采集其随外部扰动产生的“动态”光谱。一般可根据样本特性,选择施加不同的外部扰动,如温度、电压、磁场或化学扰动。采用它们的二维相关光谱图构造一张化学图像。与单张“静态”红外光谱(向量)相比,新构造的化学图像明显增加了数据尺寸(矩阵)和信息量,可放大样品的类间光谱差异。常用的光谱分类方法使用的特征提取和分类方法(适合处理向量)不再适用于化学图像(矩阵)分类。如图1所示,GoogLeNet是Google开发的一种深度CNN框架[15],同时具有特征提取和图像识别功能,在ImageNet数据集上取得了超越人眼的识别正确率,是当今最先进和最成熟的深度学习方法之一。本文提出采用GoogLeNet对化学图像数据进行分类。深度CNN网络需使用大数据样本进行训练,而光谱分析能收集到的样品通常属于小样本数据,难以满足其训练要求。本文将GoogLeNet的图像识别模型(在1 000类图像大数据库中学习到的特征提取能力)向化学图像分类迁移[16],使用化学图像数据仅对GoogLeNet网络最后4层结构进行训练,保留其它层结构不变,使迁移后的GoogLeNet 适应于当前研究的光谱分类,从而实现形态复杂且化学组成高度相近的不同类样品的有效判别。
1.2 样 品
本文使用两个组分高度相近的不同类样品分类与识别案例为研究对象:①山羊绒与山羊绒/羊毛混纺织物及纯羊毛织物的识别;②纯棉和丝光棉织物的识别。从中国几个省份的织物生产企业和市场共收集234个织物实际样品。其中,64个山羊绒,70个山羊绒/羊毛混纺(羊毛含量为 51.5%~100%,包括20个纯羊毛织物),50个纯棉和50个丝光棉织物。它们在厚度、颜色和质地(机织或针织)上各不相同。每个样品的类别由显微镜分析法确定。其中,山羊绒/羊毛混纺样品中的羊毛含量采用国标方法GB/T 2910.4-2009[17]测得。根据样品的近红外光谱,采用Kennard-Stone方法[18]对每类样品分集,其中训练集占80%,剩余样品作为验证模型判别能力的测试集。
1.3 不同含水量样品的制备
首先将样品在105 ℃真空烘箱中连续烘干3 h得到干基样品,再将干基样品放入相对湿度(RH)100%、恒温20 ℃的密室中吸潮。在不同吸附时间取出,制备不同含水量的样品。采用精度为0.1 mg的分析天平称重,并计算标准条件(25 ℃和RH 65%)下样品的回潮率(含水量):回潮率=(Wc-Wd)/Wd×100%。其中,Wc和Wd分别为样品吸水后的重量和干重。样品的最大回潮率设定为16.3%。每个样品制备4个不同的含水量(包括0、5.4%、11.2%和16.3%),共得到936个不同含水量的样品。
1.4 光谱采集
使用配有积分球附件的Nicolet Antaris Ⅱ FT-NIR光谱仪在恒温恒湿的条件下采集样品的漫反射近红外光谱。内置的金箔用于采集背景光谱。将每块大小约0.5 m2的样品折叠成4~6层后,直接放置在积分球的窗口上并用铁块压住,使其与窗口表面紧密接触。光谱采集参数为:分辨率4 cm-1,扫描数32,光谱范围10 000~4 000 cm-1。每次光谱采集约1 min,每个样品重复采集3张光谱,计算平均光谱作为该样品的光谱。
2 结果与讨论
2.1 光谱分析
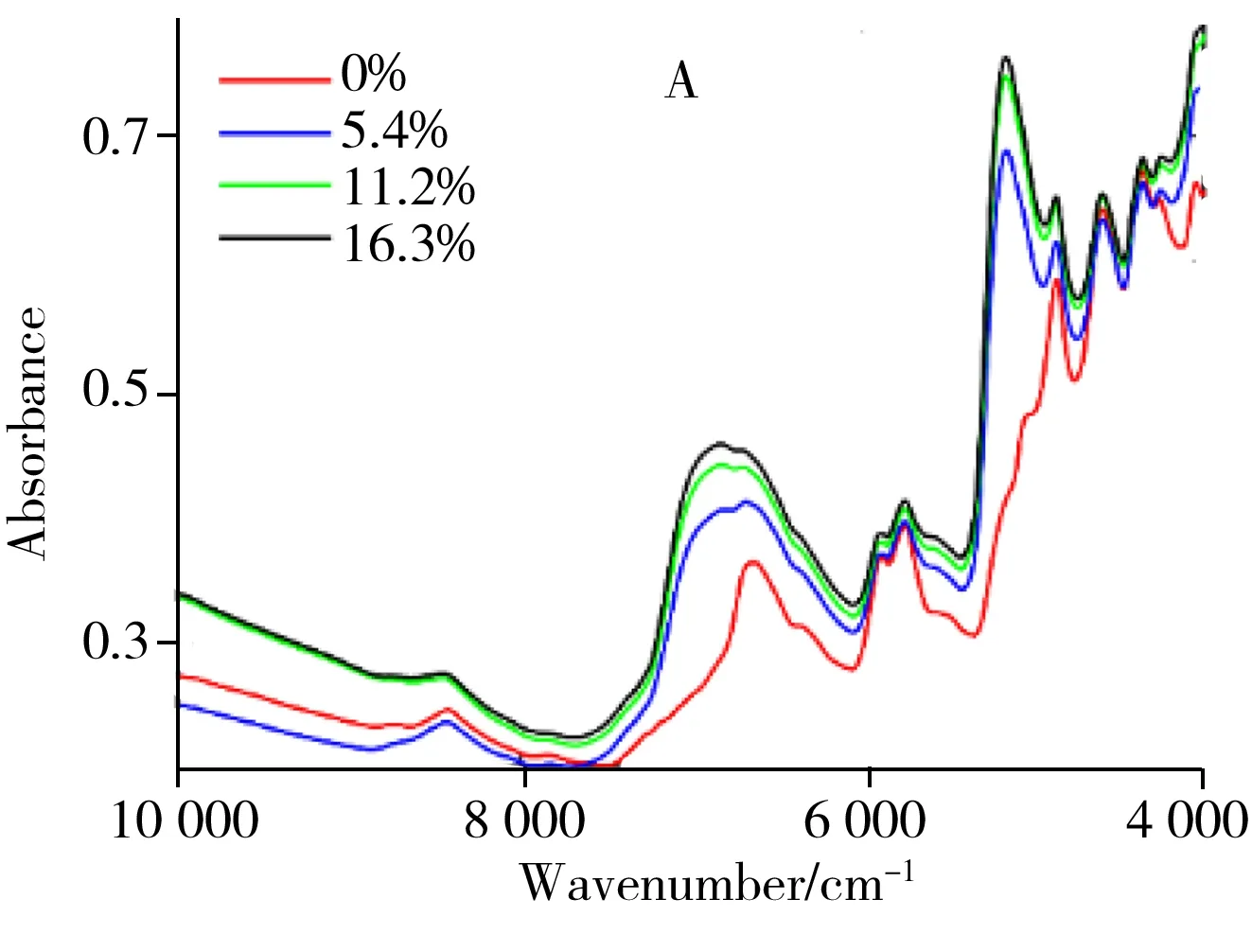
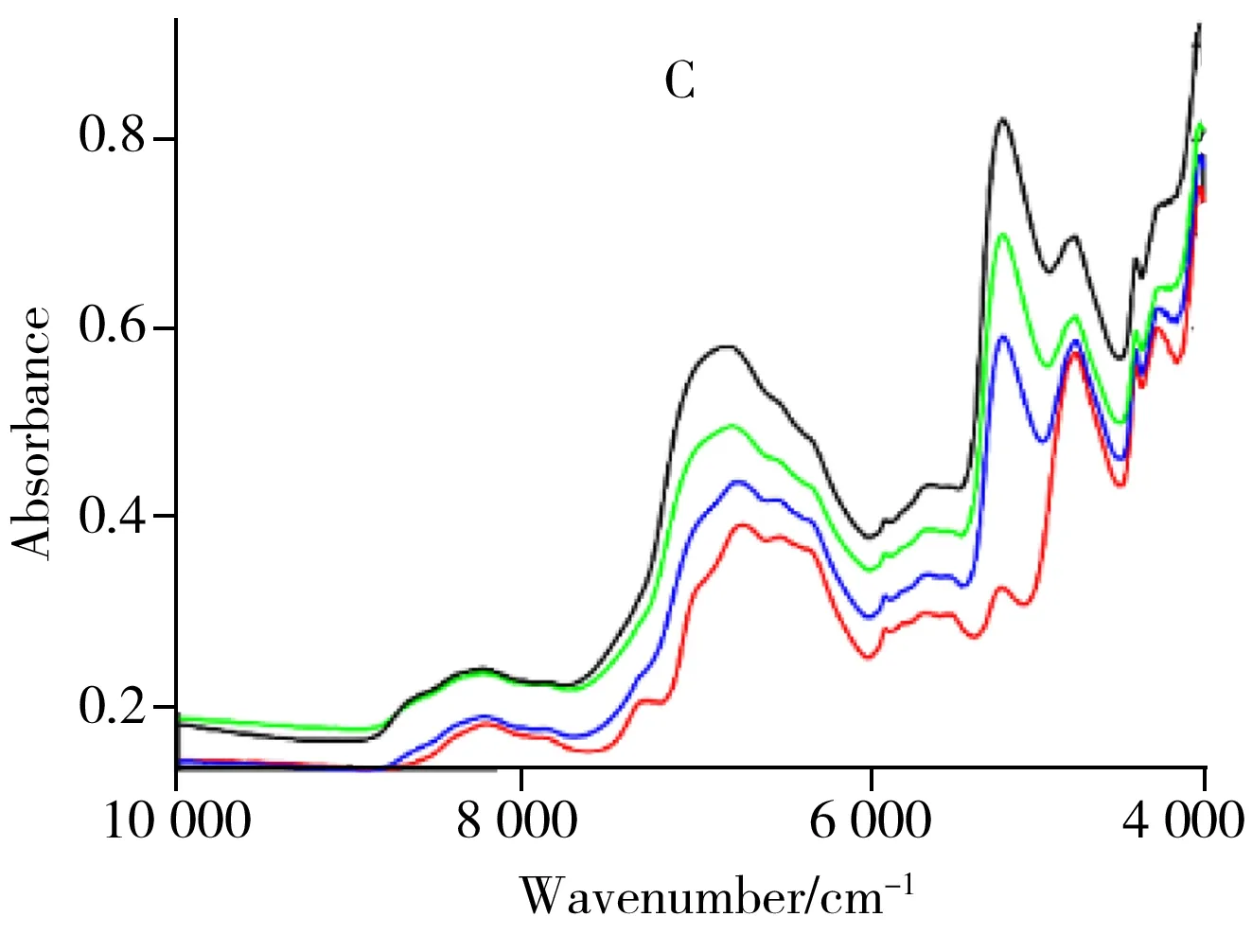
山羊绒和羊毛纤维在组成上高度相近,均由蛋白质和脂类等组成。图2A显示了所有烘干山羊绒、山羊绒/羊毛混纺织物的近红外光谱。不同样品之间的光谱基线严重漂移,主要原因包括:样品质地差异引起的光散射效应不同,颜色差异引起的吸收不同。对图2A进行二阶导数处理,有效消除了基线漂移,且光谱特征峰表观分辨率获得明显改善(图2B)。可以看出,一方面山羊绒织物与山羊绒/羊毛混纺织物的近红外光谱含有丰富的组成信息,另一方面,这两种织物的近红外光谱很相近。纯棉和丝光棉织物的情况也类似,主要组成均为天然纤维素,其烘干样品的近红外光谱及二阶导数光谱如图3A和图3B所示。
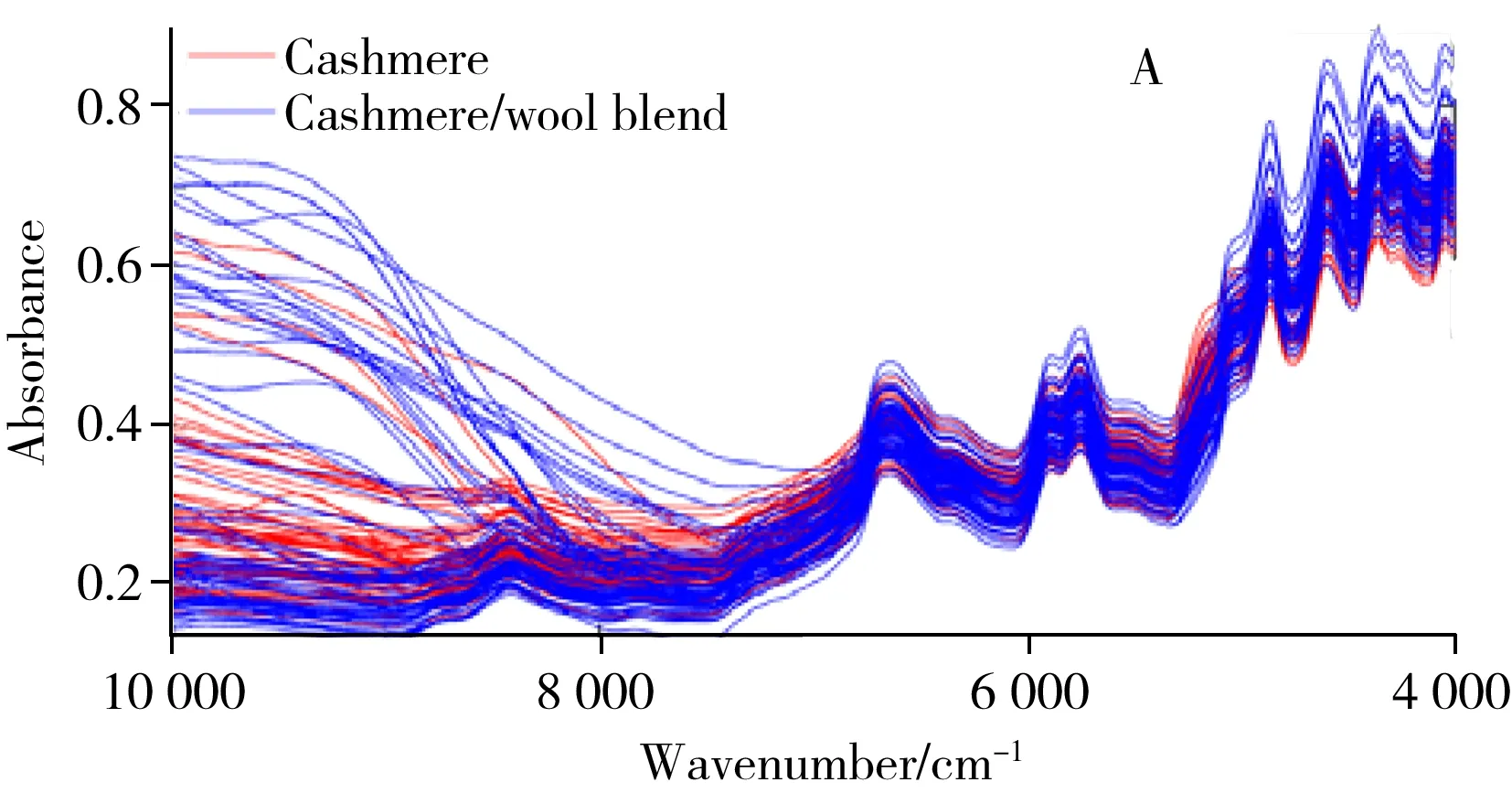

表1 山羊绒-山羊绒/羊毛混纺织物SIMCA 模型的统计指标Table 1 The statistics of SIMCA models for cashmere and cashmere/wool blend textiles respectively using the raw spectra and the pretreated spectra by different pretreating methods
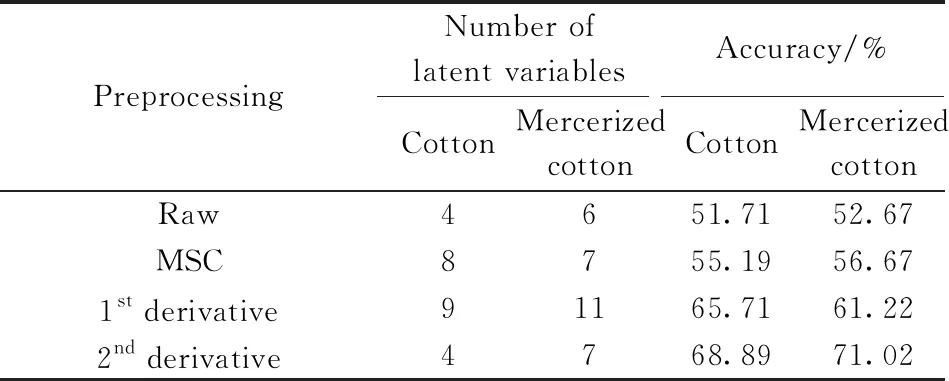
表2 纯棉和丝光棉织物SIMCA 模型的统计指标Table 2 The statistics of SIMCA models for cotton and mercerized cotton textiles respectively using the raw spectra and the pretreated spectra by different pretreating methods
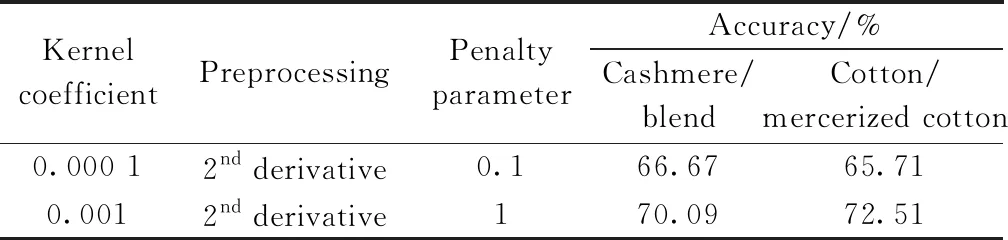
表3 织物样品SVM模型的统计指标Table 3 The statistics of the SVM models for textiles
2.2 线性方法分类
在近红外光谱定性分析常用的线性分类方法中,SIMCA方法的效果较好,实际应用也较多。在SIMCA中,首先建立每类样本的主成分光谱空间(模型),然后计算被测样本与各类主成分光谱空间的距离,根据该距离确定其归属。本文建立的SIMCA模型中,分别采用MSC、一阶导数和二阶导数不同光谱预处理方法,留一交互验证法结合QvsHotelling's T2图,确定每类模型的最优主成分数,逐一建立了烘干山羊绒与山羊绒/羊毛混纺织物、烘干纯棉和丝光棉织物的多个SIMCA模型,其统计参数如表1和表2所示。与原始光谱相比,使用3种预处理方法后,模型的预测正确率均有明显提高。其中,二阶导数预处理方法取得了最优结果:山羊绒与山羊绒/羊毛混纺织物的预测正确率分别为60.48%和63.33%,纯棉和丝光棉织物的预测正确率分别为68.89%和71.02%。
2.3 非线性方法分类
SVM是近红外光谱判别分析常用的一种分类方法,其解决非线性问题的能力优于线性分类判别方法。该方法使用核函数将线性不可分的原始数据映射到更高维空间中,使其可分。本研究使用径向基函数(RBF)作为核函数,通过交叉验证法生成决策函数(Decision function)以抑制过拟合。应用格子搜索法(Grid search)同时优化惩罚系数(Penalty parameter)和核系数(Kernel coefficient),它们的取值范围分别限定在如下两个列表中:[0.01,0.1,1,10,100,1 000]和[0.001,0.000 1]。表3列出了SVM模型的统计数据。与表2对比可知,其模型性能与SIMCA模型相近,表明SVM同样也不能有效区分组成高度相近的不同类织物。
综上所述,使用传统的光谱模式识别方法,无论线性判别方法,还是非线性判别方法,均难以快速准确地判别组成高度相近的不同类织物。
2.4 化学图像构造
本文对样品施加外部水分扰动,从而扩大了不同类样本的差异信息。以烘干样品为基础,分别制备水含量为5.4%、11.2%、16.3%的样品,并采集其水分扰动近红外光谱。从每类样品中随机选1个样品,它们在不同水含量下的“动态”光谱如图4所示。可以看出,与干燥样品相比,潮湿样品的近红外光谱图中均出现2个较宽的水峰。其中,7 100~6 800 cm-1波段归属于ν1+ν3 振动模式(ν1为对称伸缩振动,ν3属于非对称伸缩振动),吸光度变化最大的5 150~4 950 cm-1波段归属于ν2+ν3 振动模式(ν2为弯曲振动)。由此可见,水分扰动显著增加了光谱数据量和信息量,放大了不同类样品之间的近红外光谱差异。
二维相关光谱分析是一种提取扰动光谱变化信息的有力方法,广泛用于复杂体系分析。为此,对不同类织物的水分扰动光谱进行二维相关分析,得到同步二维相关光谱图(图5A1~5D1)和异步二维相关光谱图(图5A2~5D2)。在视觉上,与近红外光谱相比,二维相关光谱图更加明显地反映了组成高度相近的不同织物的光谱信息差异。
由于二维相关光谱图具有对称性,为此,对同一个样品,取其同步图主对角线上半部分和异步图主对角线下半部分,合成一张既反映同步相关变化又包含异步相关性的融合光谱化学信息图像,如图5A3~5D3所示。与近红外光谱图相比,在视觉上,融合化学图像能更直观和更明显地反映山羊绒与山羊绒/羊毛混纺织物的光谱差异。
2.5 新方法分类
从信息量角度看,上述化学图像数据更有利于组成高度相似样品的分类鉴别。但常用的光谱(向量)模式识别方法,并不适合直接处理化学图像(矩阵)数据。本文提出通过迁移学习方法将GoogLeNet图像识别模型进行迁移,使其适合组成高度相近的不同类织物化学图像的分类与识别。
迁移学习过程需要设置各种超参数(Ultra-parameters)。其中,InitialLearnRate指定了在损失函数的负梯度方向上的初始步长,MiniBatchSize是在每次迭代中使用的训练集子集的大小,MaxEpochs表示用于训练的最大epoch数。目前尚无调节神经网络超参数的通用规则。本研究通过trial-and-error方法确定了GoogLeNet模型的6个超参数(InitialLearnRate、1e-4、MiniBatchSize、15、MaxEpochs、20)。使用训练集样品训练模型,然后通过用迁移后的 GoogLeNet模型预测验证集样品来评估模型的性能。山羊绒与山羊绒/羊毛混纺织物以及纯棉与丝光棉织物分类模型的训练和验证过程如图6所示,随着epoch增大,训练集的交互验证正确率不断上升,10个epoch后稳定在90%左右;而损失函数的误差值不断减小。经过20个epoch的迭代训练后,在验证集上,山羊绒织物与山羊绒/羊毛混纺织物的总体判别正确率为92.59%,纯棉/丝光棉织物的为94.74%(表4),具备了实际应用的价值。因此,将在大数据库训练的GoogLeNet模型经迁移学习后,用于组成高度相近不同类织物的判别是可行的。
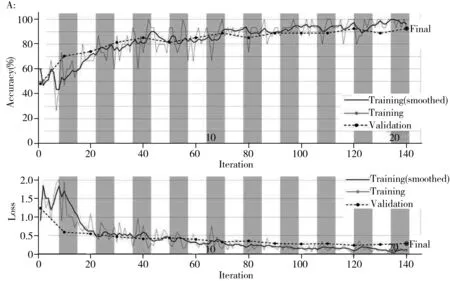
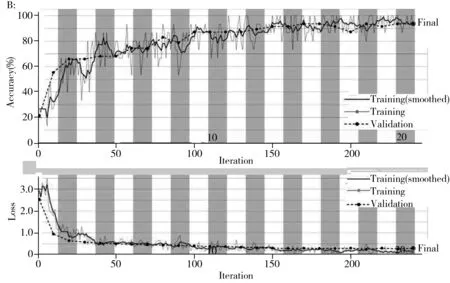
图6 山羊绒和山羊绒/羊毛混纺(A)以及棉和丝光棉(B)迁移学习模型的训练过程

表4 织物样品迁移学习模型的统计指标Table 4 The statistics of the transfer learning models for textile samples
3 结 论
本文通过采集样品的“动态光谱”,以二维相关光谱构造化学图像,使用深度卷积神经网络结合迁移学习,建立了一种光谱分类与识别方法。研究结果表明,新方法对山羊绒与山羊绒/羊毛混纺织物的分类正确率为92.59%,纯棉与丝光棉织物的为94.74%,实现了对织物的高精度识别。“动态”光谱结合深度学习图像识别和迁移学习方法,解决了近红外光谱过程分析中形态复杂且组成高度相似的不同类样本的分类难题,进一步拓宽了近红外光谱分析方法的适用范围,具有重要的理论意义和实际价值。
