基于机器视觉的苹果缺陷快速检测方法研究
2020-11-06辉马国峰刘伟杰
高 辉马国峰刘伟杰
(1. 郑州铁路职业技术学院人工智能学院,河南 郑州 451460; 2. 河南工业大学机电工程学院,河南 郑州 450001)
缺陷检测是水果等级划分的重要组成部分,而水果缺陷多样复杂,所以水果缺陷的快速检测一直是研究的热点问题[1]。目前,中国苹果分拣仍以手工为主,成本高、效率低。随着计算机视觉技术的不断发展,在农产品的检测中应用越来越广泛。机器视觉工作模式更加主动,质量判断标准更加客观具体,具有较强的可执行性和非接触工作模式[2]。
近年来,国内外的研究人员对水果缺陷检测技术进行了大量研究,并取得了许多优异的成果,但很少有研究能够快速检测出水果缺陷。项辉宇等[3]使用基于Halcon的图像处理方法对苹果的大小、颜色和缺陷进行研究,完成了水果轮廓的提取及面积的计算。结果表明,该算法对苹果大小、缺陷等检测效果较好。薛勇等[4]提出了一种基于Google Le Net的深度迁移模型来检测苹果缺陷,并将Google Le Net与浅层卷积神经网络和传统机器学习技术进行了比较。结果表明,与常用的苹果缺陷检测算法相比,该方法具有更好的泛化能力和鲁棒性。李红娟等[5]将混沌多空间算法应用于苹果的缺陷检测,利用逻辑映射对个体进行混沌优化,利用改良的Otsu算法分割苹果的缺陷区域。经试验验证该算法对苹果表面缺陷检测效果清晰,各种缺陷检测准确率高。刘云等[6]将卷积神经网络应用于苹果缺陷检测中,背景分割算法基于RGB颜色分量,并使用渐进学习方法确定训练样本的数目。经试验验证该算法的检测速度为5次/s,准确率高达97.3%。上述研究为基于机器视觉的快速缺陷检测技术提供了理论依据,但存在分级过程复杂、效率低等缺点。
基于上述研究,文中拟提出一种基于机械视觉的苹果缺陷快速检测方法,采用自动亮度校正技术消除苹果表面亮度的不均匀性,根据缺陷候选区域的数量对苹果进行初步判断,并使用加权相关向量机进一步对有缺陷的苹果进行判断,以期为苹果缺陷检测技术的发展提供依据。
1 机器视觉系统概述
为了解决手动分类精度差的问题,国内外制造商已开始使用机器视觉对苹果质量进行分类。机器视觉技术具有高速、高精度和性能稳定等优点[7]。在医学和农业等领域应用广泛,并取得了巨大的经济效益。
常规识别中,首先通过照相机捕获样本图像,然后将图像发送到处理单元(例如计算机)。通过数字处理可以掌握目标区域的颜色、纹理、大小和形状等特征[8]。然后通过一系列判断条件获得识别结果,从而实现机器视觉系统的识别功能。机器视觉系统通常由相机、光源、计算机和图像处理软件等组成。图1为系统结构图。
2 缺陷检测
缺陷检测过程[9]如图2所示。
2.1 图像预处理和背景分割
缺陷检测的正确性除了取决于特征选择,还取决于图像质量。在图像处理前采用3×3高斯滤波器降低噪音对特征提取和选择的影响[10]。为了提高处理速度和降低环境干扰,得到了苹果图像的掩模图像,掩模图像仅包含苹果本身,背景被分割并移除。由于试验图像背景为黑色,背景亮度低于苹果区域的亮度[11]。考虑到NIR图像中背景和苹果区域亮度对比度明显,将苹果NIR图像进行二值化(阈值28),构建苹果掩模图像。同时,使用形态填充算法来消除背景分割的缺陷区域。在试验过程中,<500像素的连接区域被视为较小的连接区域,这些区域被填充。
通过式(1)可以得到NIR苹果图像的背景分割。
(1)
式中:
IMGBgr(x,y)——背景移除图片;
IMGOrg(x,y)——原始彩色图像;

1. 相机 2. 光源 3. 被检测物体 4. 输送结构
IMGMask(x,y)——掩膜图像。
2.2 亮度校正
苹果可以近似地看成朗伯体。根据朗伯反射定律,苹果表面任意一点的亮度ID为入射光的强度IL与点法向量和光源形成的角θ余弦值乘积,如式(2)所示[12]。
ID=IL×cosθ。
(2)
在机器视觉系统中,苹果入射光强度近似相等,夹角θ为苹果表面亮度不均匀的最主要原因。亮度校正方法如图3所示。苹果表面不同区域的点是不同的,苹果边缘区域的点θ值小于中心区域。因此,边缘的亮度低于中心亮度。这与苹果图像中心亮度高、边缘亮度低的现象是一致的。以朗伯体顶部中心为圆心,半径r和宽度Δr的圆环A内近似的认为所有元素的亮度相同。
因此,可以根据式(3)计算出环A中所有像素的平均亮度[13]。
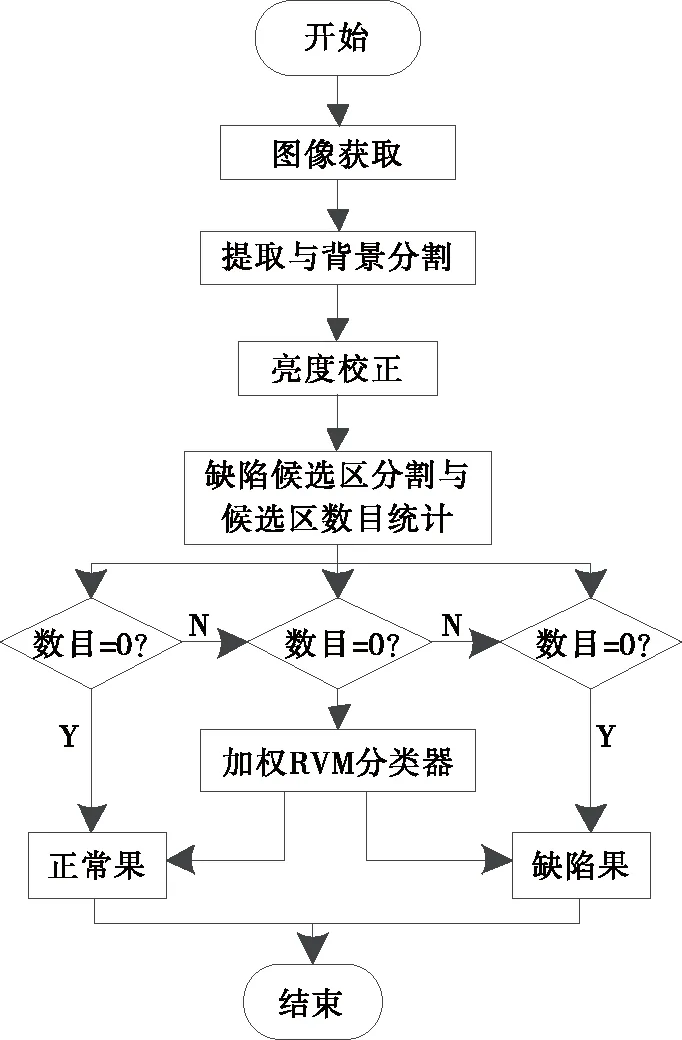
图2 缺陷检测流程
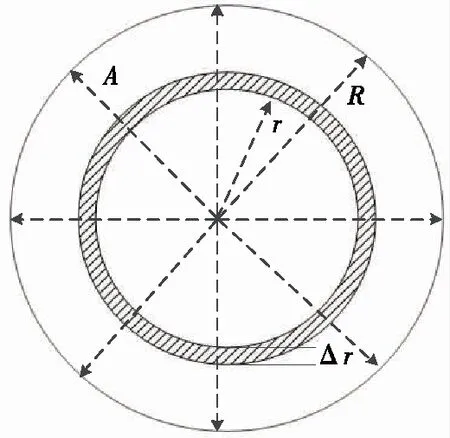
图3 亮度校正方法
(3)
式中:
IM——圆中所有像素的平均强度;
Ii——圆A中第i个元素的亮度值;
N——圆A中像素的总个数。
环A中像素的亮度校正通过式(4)计算[14]。
(4)
式中:
IRi——第i个像素通过校正的亮度值。
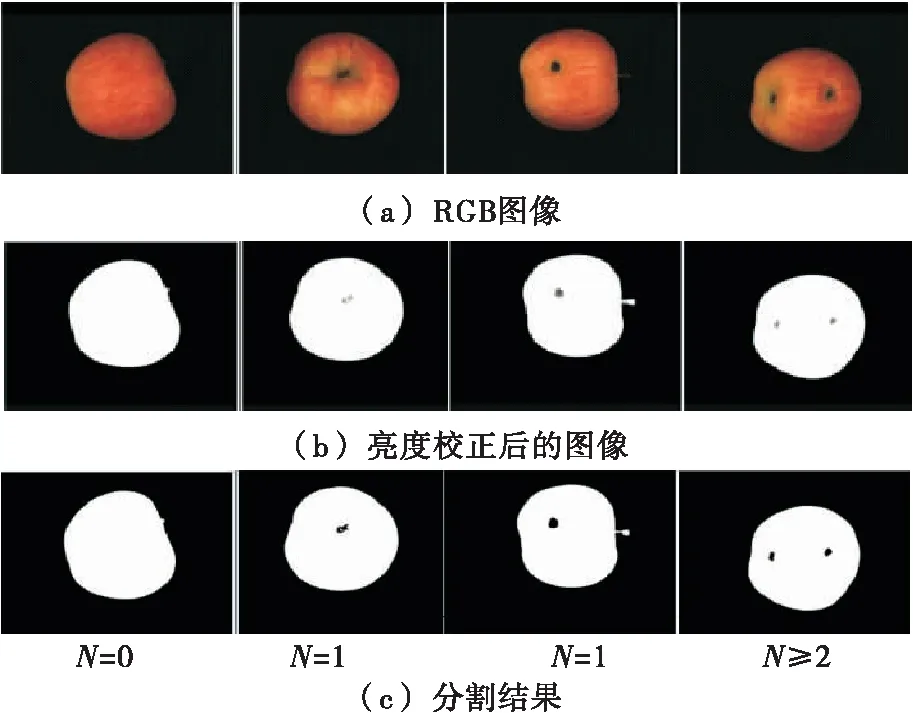
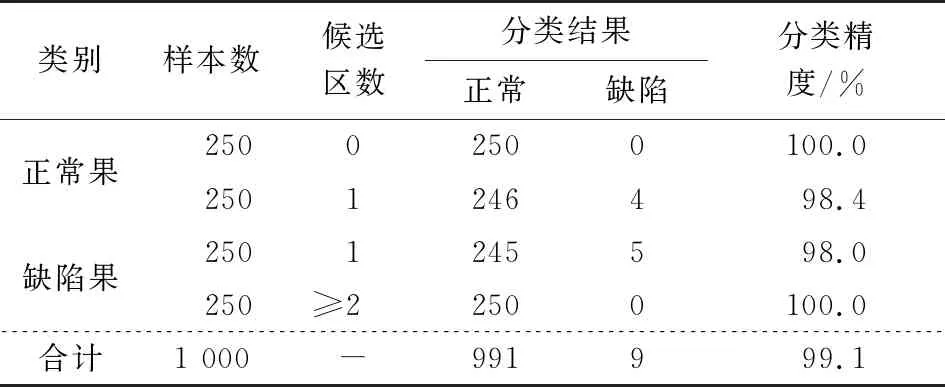
当Ii>IM时IRi=255,当Ii 校正后,缺陷、花梗和萼片这些区域亮度较低,正常区域亮度增加。试验过程中,将真正的苹果、果梗和花萼等作为苹果初步分类的候选区域。采用单阈值分割算法可以轻松地从修改后的图像中分割出候选缺陷区域[15]。 根据从苹果图像分割的缺陷候选区域的数量可以预测苹果是否存在缺陷。如果候选缺陷数量为2个或更多,该苹果存在缺陷;如果候选缺陷数量为1个,则无法确定苹果是否存在缺陷。 为了将缺陷候选区域与实际缺陷、果梗和花萼区分开,需要提取特征进行训练,文中选择6个平均颜色特征、1个R通道图像统计特征和5个纹理特征。 从样品的彩色RGB图像中,通过直接或颜色空间转换可以得到缺陷候选区域的6个颜色特征(R、G、B、H、S、I分量的平均值)。可以从对应像素的RGB分量中得到H分量的值,如式(5)所示[16]。 (5) θ通过式(6)求得。 (6) 饱和度分量S通过式(7)求得[17]。 (7) 强度分量I通过式(8)求得。 (8) 候选区域的统计特征选择与缺陷候选区域相对应的R分量的标准偏差,特征统计量如式(9)所示。 (9) 式中: ti——缺陷候选区域对应的通道图像中第i个像素的灰度值; M——缺陷候选区域中的像素数。 在R通道图像中,通过灰度共生矩阵提取纹理特征。包括熵、能量、相关性、转动惯量和局部平稳性。 文中选择相关向量机为缺陷候选区域分类算法。相关向量机(Relevance Vector Machine,RVM)是由Michael E. Tipping在贝叶斯模型基础上提出的监督式机械学习算法[18]。 ti=y(xi;w)+εi。 (10) 则目标值遵循高斯概率分布,如式(11)所示。 p(ti|x)=N(ti|y(xi;w),σ2), (11) 式中: N(ti|y(xi;w),σ2)——正态分布函数,其分布由ti、y(xi;w)以及方差σ2决定; y(xi;w)——核函数确定的值,核函数由训练样本Φi(x)≡K(x,xi)确定,如式(12)所示[19]。 (12) 假设ti彼此独立,在w和σ2条件下目标值t的完整概率如式(13)所示。 (13) 式中: t=[t1,t2,…,tN]T——目标函数向量; w——wi组成的权向量,w=[w1,w2,…,wN]T; Φ——N×N的设计矩阵,Φ=[Φ(x1),Φ(x2),…,Φ(xN)]T。 (14) 对于每个权重,式(14)都有一个独立的分布参数,可以降低先前分布的复杂度。 式(13)中,为了与最终函数匹配,需要在超参数α中加入噪声函数σ2。该函数满足如式(15)所示的伽马分布比例函数。 (15) 为了保证这些参数无先验知识,通常将其定为a=b=0。遵循基于贝叶斯定理的样本先验和似然分布,可以通过式(16)获得w后验概率分布。 (16) 式中: Σ=(σ-2ΦTΦ+A)-1; μ=σ-2ΣΦTt; Ω=σ-2I+ΦA-1ΦT; A=diag(α0,α1,…,αN)。 RVM算法中的模型权值的最大后验估计依赖于参数α和方差σ2,通过最大似然边界分布得到α∧和σ2∧。最优权值的不确定性可以表示模型预测中的不确定性。预测目标值如式(17)所示。 (17) 在此,需要通过最大后验估计来预测α和σ2,如式(18) 所示[20]。 (αMAP,σ2MAP)=argmaxα,σ2p(t|α,σ2), (18) 式中: 通过将获得的参数α和σ2估计值引入公式中,可以获得如式(19)所示的目标值。 p(t*|t)=N(t*|y*,σ2*), (19) 式中: y*=μTΦ(x*); 为了验证校正与分割的效果,以不同尺寸、形状和外观缺陷不同的苹果为例,验证了亮度校正和候选缺陷分割算法的有效性。校正与分割图如图4所示。 从图4(a)可以看出,试验样品存在不同的缺陷位置和数量,并且苹果姿势是随机分布的。边缘也有缺陷存在且接近正常表皮的亮度,使其难以直接分离。 为了对亮度效果进行加强,直接在R中使用阈值分割方法,未校正即从通道图像中提取缺陷候选区域,结果如图4(b)所示。由于苹果图像的亮度分布不均,通常无法检测出苹果图像边缘区域的缺陷。并且很容易被错误地判定为缺陷。 从图4(c)可以看出,即使对亮度进行了校正,缺陷、果柄和花萼的亮度仍然较低,缺陷与正常果皮对比度增加。特别是在边缘区域,对比度更大,这在提取缺陷候选区域方面是有利的。 图4(d)为亮度校正后苹果图像中缺陷候选区域的分割结果。相比之下,该方法可以准确地识别出果实、果梗和花萼,可以很好地识别出苹果边缘缺陷,不会误分割果实的边缘。 先对缺陷候选区域进行分割,然后对缺陷候选区域的数量进行计数,标记为N。将苹果样品可分为3类:正常水果(N=0),缺陷水果(N≥2)和待处理水果(N=1)。这3种典型形式,以及原始RGB图像、亮度校正和分割结果如图5所示。从图5可以看出,经过校正和分割后,苹果图像第一列中的候选区域数量为0。即在相机的视场中没有真实的缺陷、果梗、花萼等低亮区域,初步判断样品正常。 图4 校正与分割 第2列和第3列分割缺陷候选区域后,分割的候选区域数N=1,缺陷可以为实际缺陷、果梗、花萼等。因此,不可能预先确定这种苹果是否有缺陷或正常。因此,需要进一步的判断。在苹果图像的第4列中,经过亮度校正和缺陷候选区域分割。分割出的候选区域的数量为N=2。 考虑到果梗和花萼不能在相机的同一视野中出现。苹果样品可以初步确定为有缺陷的水果。选择区域数≥2的苹果样本也可以初步判断为缺陷果。果梗和花萼在同一视野中无法同时出现。经证实,苹果样品是有缺陷的水果。 为了检验算法的性能,分别测试了500个无缺陷苹果、250个只有一个缺陷的苹果和250个不同缺陷数量的苹果。每个苹果采集一个图像,然后人为控制水果的位置和姿势。测试结果见表1。根据候选区域数N=0,在算法的初始识别阶段,将照相机视场内的所有(250个)无果梗和花萼的苹果正确判定为正常水果。当N≥2时,所有(250个)缺陷苹果均被判定为有缺陷的水果。当N=1时,进一步判断250个仅在相机视野中具有果柄或花萼的苹果,其中,有246个为正常果实,有4个被判定为有缺陷苹果。该检测算法还确定了相机视野中的250个缺陷苹果,其中245个是缺陷水果,5个误判为正常水果。在1 000个样本中,有991个被正确分类,总体识别准确率达到99.1%。 图5 品质初步判断 表1 检测结果 将自动亮度校正技术和加权矢量机相结合,实现了基于机器视觉的苹果缺陷快速检测。该检测方法对1 000个测试样本的识别准确率为99.1%。表明该方法对苹果缺陷检测效果较为清晰,各种缺陷检测准确率比较高。考虑到试验装置和数据的规模,这项研究仍处于起步阶段。后续将不断改进和完善基于机器视觉的苹果缺陷快速检测方法。2.3 初步分类


2.4 进一步分类
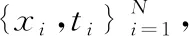


3 试验结果与分析
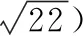

4 结论
