基于语料库的翻译共性研究※
——以《生死疲劳》英译本为例
2020-11-05
内容提要:本文基于汉英可比语料库,利用语料库语言学检索软件,对莫言小说《生死疲劳》的英译本与英美小说语料库在词汇和句法两个层面进行差异性对比,尝试验证以小说为题材的英译本中翻译共性的表现程度。研究结果印证了大部分的翻译共性假说,但也证实了汉英语言差异、体裁限制、译者风格以及源语渗透效应等因素对于翻译共性特征有着重要的影响,汉语小说的英译文本具有独特的“翻译腔”,形成了一种特殊的文体特征。
语料库语言学研究诞生于1950年代,这种新的研究方式在很大程度上解决了传统语言学研究中个人主义倾向所带来的局限性。国内学者杨惠中曾提出:“语料库语言学是以真实的语言数据为研究对象,从宏观的角度对大数量的语言事实进行分析,从中寻找语言使用的规律;在语言分析方面采用概率法,以实际使用中的语言现象的出现概率为依据建立或然语法进行语法分析。”1基于语料库的翻译研究主要有两种维度:建立双语平行语料库和自建可比语料库。本研究选择通过建立可比语料库,观察翻译文本与非翻译文本之间语内类比的差异,将语料库语言学与描写翻译理论相结合,并进行有效的定量研究。英国曼彻斯特大学Mona Baker教授最先提出了运用语料库语言学工具对翻译过程进行研究,并建立了世界上第一个翻译语料库(Translation English Corpus,TEC),在此基础上Baker还提出了“翻译共性”的假设。经过20多年的实证研究积累,翻译共性被归纳为以下几个内容:简化(Simplification,简略化)、显化(Explication,明晰化)、范化(Normalization,规范化)以及整齐化(Leveling-out,平整化),这四个特点均会体现在翻译文本中的词语和句法当中。
Baker的学生Laviosa将翻译文本中所体现的翻译共性量化特征进行了深入的研究,进而提出假设:(1)翻译文本的词汇范围比非翻译文本的词汇范围窄;(2)翻译文本的实词与语法功能词的比例低于非翻译文本(特别是词汇密度或类符形符比更低);(3)翻译文本的句子平均长度比非翻译文本的句子平均长度短。2本文借鉴Baker和Laviosa所阐述的基于语料库的翻译批评定量分析方法,利用软件Word Smith Tools 7.0对《生死疲劳》英译本进行实证性研究,形成《生死疲劳》英语译文语料库,为了保障语料的可比性,并自建20世纪英美原创小说语料库。研究的最终目的是通过对比两个语料库语料的词语层面特征和句子层面特征,对莫言小说《生死疲劳》英译本Life and Death are Wearing me Out的翻译普遍性特征进行调查分析。
一 研究理论和方法
翻译共性(translation universal)指“译文中呈现的有别于原文的一些典型的、跨语言的、有一定普遍性的特征”3。学界将Baker在1993年发表的文章“Corpus Linguistics and Translation Studies:Implications and Applications”作为翻译共性研究的前语料库时期和基于语料库时期二者的分界线,Baker在文中首次提出了基于语料库的翻译普遍特征的假设,即“翻译文本而不是源语文本体现的典型语言特征,并且这些特征不是特定语言系统相互作用的结果”4。基于语料库的翻译普遍特征的假设包括六方面内容:(1)译文显化程度显著提高;(2)消歧和简化;(3)合乎语法性;(4)避免重复;(5)超额再现目标语语言特征;(6)翻译过程往往会导致某些语言特征表现出特定的分布类型。5自此,翻译共性研究不断深入,逐渐成为翻译学研究的热点。
显化这一概念最早是由维奈(Vinay)和达贝尔内(Darbelnet)从对比文体角度提出来的,他们认为译者将源语中隐含的信息添加一些标记在目标语中明示,这种情况可以在源文本中根据语境或情境获得。随后Shoshana Blum-Kulka和Baker等学者就翻译中衔接与连贯等问题进一步对显化现象进行研究,二者皆认为译文相较于原文内容冗长,是由于译文将原文中隐含的信息表达出来,形成了显化趋势。在翻译语言研究中,简化和范化与显化也密切相关。所谓简化就是译者在目标语文本中对源语文本中的词汇、句法和文体进行下意识的简化,其翻译过程受译者偏好和目的语语境规范等多种因素的影响。范化又可称为规范化和标准化,是指“遵循、甚至夸大目标语中典型模式和做法的倾向”6。显化、简化和范化对翻译共性研究的解释提供了多重视角。
近些年国内语料库翻译学研究多是从具体语言因素入手,研究主要探索语际、语内或者二者相结合的对比模式的方法,运用概率和统计的手段,观察分析英语译文或汉语译文的翻译语言特征是否能够符合翻译共性假设检验或是否能够泛化为“翻译的普遍性”。
本研究聚焦于《生死疲劳》的英译本,该书于2006年正式在国内出版后引起了巨大轰动,文学评论界纷纷进行了激烈讨论。随后由葛浩文翻译的英文版在美国出版,同样引起了西方主流媒体的广泛关注,接连获得香港浸会大学世界华文长篇小说奖“红楼梦奖”首奖和第一届美国纽曼华语文学奖。本研究使用的语料库分为两部分:《生死疲劳》英语译文语料库(简称为LAD)和英语小说语料库(简称为CEN),CEN中包含18部20世纪英美小说原著。两个语料库都做了词性附码,附码操作采用英国兰卡斯特大学计算机研究英语语言项目组研制的CLAWS词性附码器和CLAWS7附码集。笔者将LAD与CEN的词语丰富度、词长、词汇密度和形合度等方面问题进行对比分析,以此来探索《生死疲劳》翻译中的英语译文语言的规律性特征以及检验其是否符合翻译共性假设。
二 基于可比语料库的《生死疲劳》英译本语言特征分析与共性假设检验
(一)词语层面
1.词语的变化度
词语的变化性是指相同长度的语料中不同词语的数量可通过语料库的类符形符比(Type-token Ratio,TTR)来衡量。7类符形符比是指语料库中类符(type)与形符(token)之间的比例,在一定程度上能够体现语料的用词变化性,但当较长的语料文本出现时,类符形符比已经不能全面、直接地衡量词汇的变化程度了。这是由于语料篇幅的增加,一些功能词汇便会不可避免地重复增多,TTR的数值便会被稀释,故此时的类符形符比不具备可比性。因此,标准类符/形符比所得到的数值可以理解为是对TTR进行了标准化处理后所得到的数值,我们称之为标准形次比(Standardized Type-token Ratio,STTR)。通过STTR值的大小可以较为准确、可靠地体现语料中词语的词汇变化与丰富度。STTR值与特定语料库中的词汇变化度与词语丰富度呈正相关关系,即STTR值越大,特定语料库中的词汇变化度越大,词语也越丰富,词语的重复率越低,反之亦然。表1是笔者运用Word Smith Tools 7.0分别统计的LAD和CEN语料库基本信息:

表1 LAD和CEN中形符、类符数以及形次比
表1显示,LAD与CEN的容量差别较大,CEN的语料长度远远大于LAD,所以只有标准形次比才具备可比性。从STTR值来看,LAD的值(54.97)小于CEN的值(71.18)。这说明英语译文文本词语变化程度较英语原创文本偏低,在词语丰富度层面也低于英语原创文本。这一结果与Laviosa和Baker等人的研究结果相符合,符合简化共性假设。
2.词汇密度
单纯依靠标准形次比考察词语丰富度往往不够全面,词汇密度是实词与总词数比值的百分比,是文本信息量大小的一个衡量标准8,词汇密度可以衡量不同文本“在信息差异和难度的大小”9。本研究采用J.Ure提出的词汇密度计算公式:
词汇密度.=实词数/总词数×100
英语的实词包括四大类:名词、动词、形容词和副词,具有稳定的词汇语法语义;而英语的功能词(主要包括代词和连词等)并不具备稳定的语义。因此,本研究将主要统计分析实词的数量。词汇密度越高,说明该语料文本所使用的实词比例越高,信息量越大,难度也相应越大,反之则亦然。LAD语料库和CEN语料库都已通过CLAWS词性附码器附码,并使用了CLAWS7词性附码集。

图1 LAD和CEN语料库词汇密度统计
从图1可以看出,整体上LAD的词汇密度高于CEN(26.4%>22.5%)。表2中的卡方值显示LAD高于CEN,说明《生死疲劳》英译本使用了更多的实词。此结论与Laviosa以及国内学者的研究结论不一致。如Laviosa认为英语译文文本中词汇密度值相对偏低的假设。英源汉语译文方面也有类似发现。胡显耀通过比较翻译小说语料库CCTFC与兰开斯特汉语语料库LCMC后认为翻译小说的词汇密度较低,这说明从词语总体特征来看,翻译小说存在词语使用的简化特征。10王克非和肖忠华等学者也相继得出汉英对应语料库中母语语料库的词汇密度远大于译文语料库。
然而上述研究数据表明,《生死疲劳》英语译文语料库比英语小说语料库所使用的实词比例要高,这也说明了《生死疲劳》英语译文语料库文本信息量更大,文本难度也越大。这一结论不仅有悖于Laviosa的英语译文文本中词汇密度值相对偏低的假设,还与前文中词汇丰富度分析所得的数据结论不符。
再来关注具体词类分析结果,英语译文语料库的实义词使用比例均显著高于英语小说原创语料库,且在两库中的使用均存在显著差异。连淑能曾指出英美不少语言学者都曾指出英语有过分使用名词的习惯,而且英语还常用副词表达动词的意义。11由此可推,葛浩文实义词的超用现象具有明显的“范化”共性特征,即译文“遵循、甚至夸大目标语中典型模式和做法的倾向”12。
3.高频词汇使用情况
为了掌握两个语料库中高频词汇的使用情况,笔者利用软件Word Smith Tools7.0中的Wordlist对两个语料库中的词频系数进行统计。表2分别对《生死疲劳》英语译文语料库和英美小说原创语料库前30位、40位和50位高频词进行统计,对LAD和CEN两个库中词表表头统计结果显示:《生死疲劳》英语译文语料库中前30位高频词所占比率为33.56%,而英美小说原创语料库高频词所占比例为37.25%,根据log likelihood对数似然比的检验,两个语料库在前30位高频词使用上存在显著差异性(LL=4434.11,p<0.01)。同样按照上述方法对排在前40位和前50位的高频词所占比例进行计算,得出《生死疲劳》英语译文语料库前30位、40位和50位高频词所占比例均低于英美小说原创语料库,英文小说原著更倾向于使用高频词,且使用频率也均高于《生死疲劳》英语译文语料库这一结论。这里与Laviosa对于翻译文本中高频词汇相对于低频词汇比例偏高的论述恰恰相反,但与上文《生死疲劳》英语译文使用词汇更加丰富这一结论具有相似性。《生死疲劳》英译本译者葛浩文并非频繁运用耳熟能详的词汇,而是选择灵活多样的词汇来驾驭文学作品,传递给读者新奇、酣畅的阅读体验。

表2 前30位、40位和50位高频词条统计
接下来对于两个语料库排名前十位的高频词的使用频次进行排序,详情见表3。从表4的数据可以发掘到一些显著的特点:首先,10个高频词中有3个词的位置相同,分别为:THE,AND和TO;其次,两个语料库中互补重复的单词分别是英语译文语料库中的I,YOU和MY,以及英语小说语料库中的HE和SHE;最后,两个库综合比对使用频率最高的前5个词均为THE,AND,OF,A和TO,这几个词只是在顺序上稍有出入。
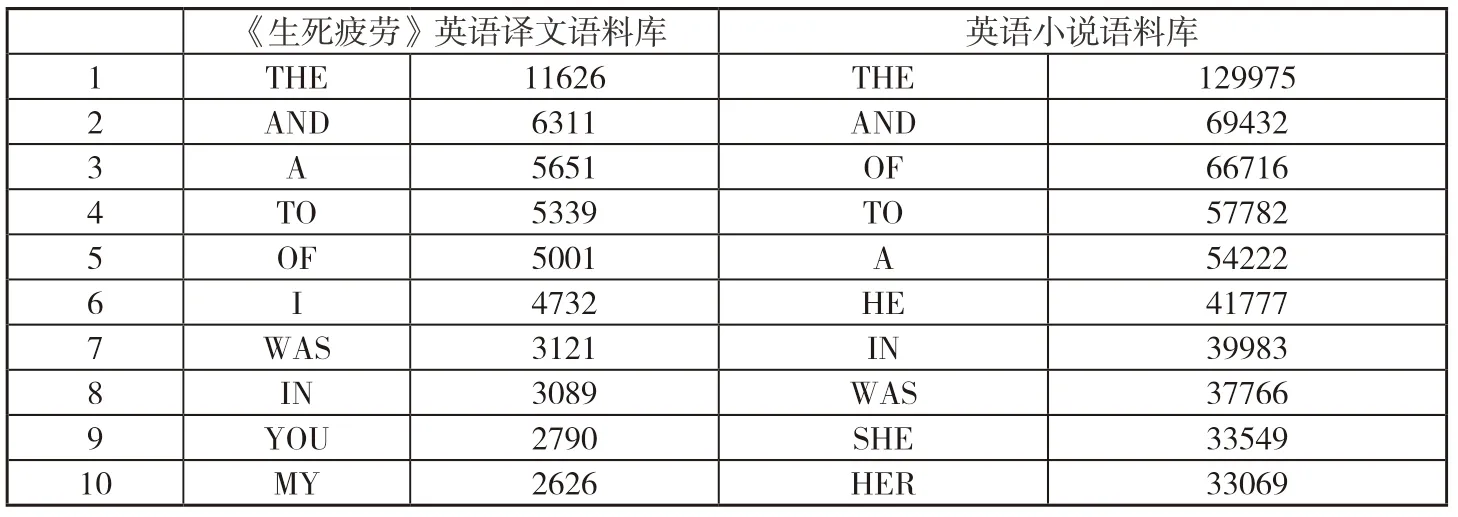
表3 两个语料库词表中前10个高频词的统计
为了进一步检验I,YOU和MY过度使用的原因,笔者利用Antconc软件中的FileView功能,分别以这三个词为检索词在《生死疲劳》英译本语料库中检索含有这三个词的原始语句,并摘选出具有代表性的、使用密度较大的语句片段,随后再利用Paraconc软件逐条搜索出相对应的汉英平行语句。下面是含I,YOU和MY的例句:
例 1:他们使出了地狱酷刑中最歹毒的一招,将我扔到沸腾的油锅里,翻来覆去,像炸鸡一样炸了半个时辰,痛苦之状,难以言表。
…in which I tumbled and turned and sizzled like a fried chicken...Words can not do justice to the agony I experienced…
例 2:江山就这样打下来了吗?就这样称王称霸了吗?
Is this how territory was won? Is this how you gained dominance?
例 3:翻了一个滚爬起来,头晕目眩,嘴巴里全是泥土。
A quick somersault and I was back on my feet again, but dizzy as can be and my mouth full of mud.
例 4:活动着筋骨,将嘴巴里的泥土咳出去,并顺便捡拾了几颗杏子。
Shook out my limbs; I spit out the mud in my mouth and, while I was at it, scooped up some apricots that blanketed the ground.
上述几个例句对应的汉语原文中,并没有出现一次“我”“你”和“我的”字样,而译文却将其“显化”为“I”“you”和“my”这三个词加以译出,目的是顺应目标语国家读者,加强语篇的连贯性,方便其理解原文中意译的传达,能够更顺畅地阅读。而例4中连用了两个my和两个I,我们追溯回原文会发现,对应为“活动着(我的)筋骨,(我)将(我的)嘴巴里的泥土咳出去,(当我在那儿的时候)顺便捡拾了几颗杏子”。加上括号里的词语使翻译语义更加清晰明了,指称也更明确。
再来关注《生死疲劳》英译本语料库中my右一位置的搭配频次排名情况,排在前几位的分别为brother,master,head,sister和eyes。而英美小说原创语料库则是dear,own和life等词语排在前几位。英语译文文本更倾向于在my后连接身体部位的词语,这与英美小说原创库对dear和own的偏爱有所不同,这与英美本土作家的习惯性用法不无关系,也说明《生死疲劳》英译本译者葛浩文充分考虑了源语国家的文化因素。值得关注的是,You大多数情况下会出现在小说文本主人公之间的对话或自言自语当中,在英语译文文本中反复出现与小说汉语原文有着不可分割的关系,属对等翻译。因此,这一现象也从侧面提醒我们,在考察某部作品或某一类作品的词汇共性特征时,在设置类比语料库进行研究的基础上应适当加入平行语料库的研究方法,将源语文本素材纳入研究范围,方能实现对于语际间词汇变化特征的审视更加全面化和动态化。
4.平均词长
平均词长被认为是验证简化特征的量化指标之一,词长越短内容越简单,文本越容易理解和阅读。语料库中字母总数/形符总数的比值即为平均词长,在一定程度上反映了用词的复杂程度。翻译文本与目标语原创文本相比较,往往是前者短于后者。
我们运用Word Smith Tools 7.0中的WST功能对两个语料库的平均词长数据进行统计,具体内容为分别统计出两个语料库中单词长度与各长度单词所占比例等信息。由表4可知,《生死疲劳》英语译文语料库的平均词长为4.12,英美小说原创语料库为4.29,LAD<CEN;5个字母以内的单词数所占比例为66.07%和63.33%,LAD>CEN。以上数据表明《生死疲劳》英语译文语料库的用词相对更简单一些,该语料库在一定程度上体现了简化共性特征。

表4 LAD与CEN的平均词长对比

图2 LAD与CEN两个语料库中1~12字母词数频率分布对比图
由图2可以直观地看到LAD与CEN两个语料库中1~12字母词数频率分布情况相当,长词与短词所占的比例没有显著差异。综合表4我们会发现,两个语料库的数值十分接近,说明词语简化的程度也十分有限。
(二)句法层面
Laviosa和国内学者黄立波曾就翻译共性在句法层面的表现程度提出了两种假设:1)Laviosa从平均句子长度入手,提出“翻译文本的句子平均长度比非翻译文本的句子平均长度短”13的假设;2)黄立波则将句子的连接成分作为切入点,提出“翻译文本在连接成分上使用频率高于非翻译文本”14的假设。以上两个量化标准都与翻译文本的显化和简化程度相关。简化又称简略化,Baker曾将其定义为译文中译者对于语言或者信息的简化,这种简化可以通过对比原文与译文间的平均句长以及对比原创文本和翻译文本间平均句长的差异加以验证。15接下来本研究将根据以上两个量化标准对《生死疲劳》英译本进行考察。
首先,笔者对LAD和CEN两个语料库的平均句长等信息进行归纳统计,结果见表5:

表5 两个语料库句子个数、平均句长以及句长标准差
通过表5可以看出,两个语料库在句长等信息的使用上差异较为明显:英美原创小说倾向于使用更为复杂、变化灵活的长句,而《生死疲劳》英译本则更加侧重于使用相对较短且固定的句子,这一结论与Laviosa的假设相符。
其次,为了验证黄立波的假设,利用Word Smith Tools 7.0中Concord功能本别对LAD和CEN进行检索,统计出连接成分相关的使用情况。但由于英语的连接成分分支较多,整体情况复杂,因此本研究将连接成分划分为以下三种模式:因果、转折和条件,考察结果如图3所示:
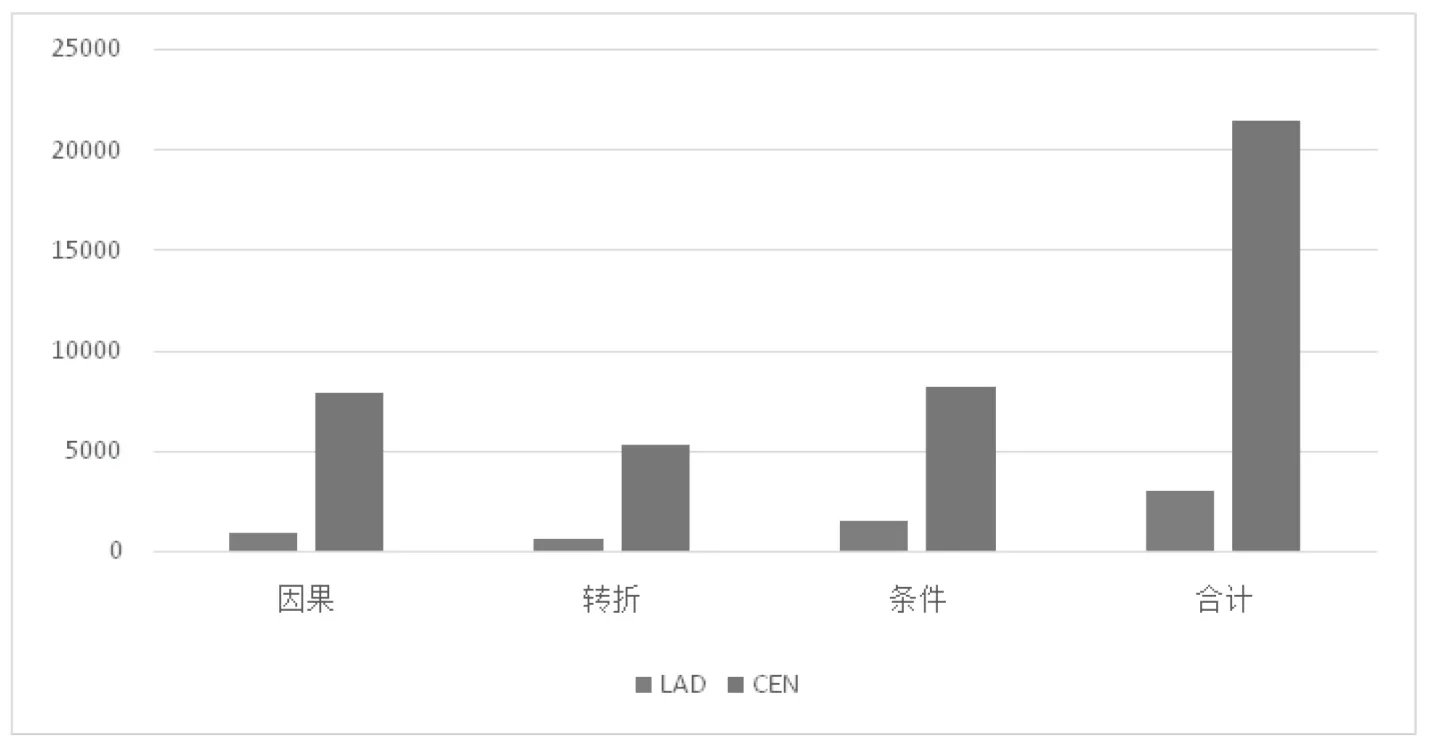
图3 两个语料库中三个连接成分的使用情况
图3显示,《生死疲劳》英语译文语料库中三类连接成分使用次数与英美小说原创语料库三类连接成分使用次数具有显著性差异,LAD低于CEN,这一结论与黄立波的假设相悖。究其原因,我们可参考上文表5的研究结果,英语和汉语的自身语言特点某种程度上决定了英语译文与原创小说句法特点的相异。汉语相对于英语而言,使用复杂长句的频次相对较少,而英语原创小说大家笔下的作品通常会使用极具创造性和复杂情感内涵的长句,而“连词”恰恰在长句子中起到的是“黏合剂”以及“承上启下的作用”,因此,英语原创小说中连词的使用势必会增加。而作为译入语的《生死疲劳》英译本译者葛浩文则将更多精力关注到如何让译文与原文最大化地等值,为了尽可能地再现原文语境,译文的创造性发挥与情感变化会大大低于英美原创小说,这便导致了《生死疲劳》英译本多以短句为主,连词的使用频率自然会降低。
另外值得关注的是,通过对《生死疲劳》英译本进行检索发现,相较于英美原创小说使用了范围广泛的连接成分,《生死疲劳》英译本在一些连接复杂长句的连接成分的使用上少得可怜(最多不超过3次),甚至根本没有出现在语料库中,如“ifonly”“however”和“inthat”等。这也从侧面反映出葛浩文对《生死疲劳》的翻译显现出简略化的特征。
最后,本文采取“语篇可读性”作为参数,对LAD和CEN两个语料库进行检验,从宏观角度考察《生死疲劳》英译本总体上是否存在简化趋势。通过对“语篇可读性”的检测,能够对《生死疲劳》英译本的难易程度加以衡量,影响“语篇可读性”参数值的两个变量为英语句子长度和词汇难易度。笔者采用现今较为权威的三种可读性信息统计方法:软件Readability Analyzer 1.0、The Automated Readability Index和Gunning Fog Index公式。
The Automated Readability Index计算公式为:4.71×(c÷w)+0.5×(w÷s2)-21.43-21.43,其中c表示characters,w代表words,s代表sentences。计算后得出的数值越高说明文本越复杂,代入到本研究中,通过计算得出结果:《生死疲劳》英译本数值为11.2,英美原创小说数值为28.8。
Gunning Fog Index计算公式为:FogIndex=0.4×[(单词总数÷句子总数)+(长单词×数量÷单词总数),Gunning Fog Index的测量结果主要揭示看懂该文本内容所需要的受教育年限。计算后得出的数值越低说明文本越简单(6代表容易,20代表难),同样代入到本研究中,根据Gunning Fog Index的计算得出结果:《生死疲劳》英语译文语料库数值为8.515,英美原创小说语料库数值为12.741。
Readability Analyzer 1.0是由北京外国语大学许家金和贾云龙共同开发的可读性文本分析软件,通过对两个语料库的弗莱士易读指数(Flesch Reading Ease)、文本难度(Text Difficulty)以及弗莱士难度级别(Flesch-Kincaid Grade Level)三个维度进行检验,研究结果如下表:

表6 弗莱士易读指数对比
Readability Analyzer 1.0软件的计算公式为:Flesch Reading Ease=206.835-(1.015×ASL)-(84.6×ASW),ASL代表平均句长,ASW代表单词的平均音节数。计算结果数值越大,文本难度就越小,越容易理解,反之亦然。数值在0~100区间浮动,由表6可以发现,《生死疲劳》英语译文弗莱士易读指数为77.3,英美原创小说弗莱士易读指数为67.6,说明《生死疲劳》英译本更易于理解,可读性更高。
从以上计算结果不难看出,三种统计方法的结果均表明《生死疲劳》英译本阅读难度低于英美原创小说。这也从另一个角度验证了《生死疲劳》英译本从总体上来看呈现简化特征的结论。
三 结语
自1993年Baker第一次提出翻译共性研究以来,基于语料库的翻译共性研究大量涌现,然而随着研究的不断深化,对于翻译共性是否存在、在多大程度存在的质疑也越来越多,其中,不乏一些实证性个案研究结果与共性假设相背离。16诺贝尔文学奖获得者莫言新世纪以后创作的《生死疲劳》的翻译是否也存在着某些共性?本文运用翻译批评的定量分析法,自建语料库,将《生死疲劳》英语译文语料库LAD与20世纪英美原创小说语料库CEN进行对比分析,分别从词汇层面和句法层面比较二者之间的差异,尝试在此基础上探索和分析《生死疲劳》英语译文在多大程度上呈现出了翻译的普遍性。研究结果表明,在词汇层面上,《生死疲劳》英译本除词汇密度的数据结果LAD比CEN偏高,不符合Laviosa等学者所提出的简化假设外,词语丰富度和词长方面都体现出明显的共性假设中的简化趋势;在句法层面,两个语料库验证了平均句长的简化假设:英美原创小说倾向于使用更为复杂、变化灵活的长句,而《生死疲劳》英译本则更加侧重于使用相对较短且固定的句子。本研究的结果证实了大部分的翻译共性假设,但也从侧面证实了汉英语言差异、体裁限制、译者风格以及源语渗透效应等因素对于翻译共性特征有着重要的影响,如本研究中两个语料库的词汇密度分析与翻译共性假设不符。诚如肖忠华所言:“源语对翻译的影响效果是非常明显的,翻译语特征也不同于译入语特征,不可避免地带有所谓的‘翻译腔’。”17所谓的“翻译腔”既与源语文本不同,又与译入语文本有所差异,它可以理解为由于源语渗透效应等因素的存在,使得译者在使用目标语对源语文本进行翻译时,充分考虑源语文化与语境,从而形成了一种特殊的文体特征。针对这一特殊的文体特征的细化研究有待于语料库翻译学研究学者在可比语料库研究的基础上开展平行语料库的双向探索,更加全面、客观和细致地揭示各种类型翻译文本的共性特征,才能真正认清翻译的本质。
注释:
1 杨惠中:《语料库语言学导论》,上海外语教育出版社2002年版,第4页。
2 13 Laviosa, S.Corpus-based Translation Studies:Theory, Findings, Application[M].Amsterdam:Rodopi, 2002.
3 柯飞:《翻译中的隐和显》,《外语教学与研究》2005年第4期。
4 5 Baker, M.Corpus Linguistics and Translation Studies:Implications and Applications[A].In M.Baker, G.Francis & E.Tognini-Bonelli(eds.)Text and Technology:In Honour of John Sinclair[C].Amsterdam:John Benjamins Publishing Company, 1993:233-250.
6 12 15 Baker, M.Corpus-based translation studies:The challenges that lie ahead[J].In H.Somers(ed.).Terminology, LSP and Translation[C].Amsterdam:John Benjamins, 1996:176-177.
7 9 胡显耀:《基于语料库的汉语翻译小说词语特征研究》,《 外语教学与研究》2007年第5期。
8 Baker, Mona.Corpora in translation studies:an overview and some suggestions for future research[J].Target,1995(2):223-243.
10 胡显耀:《当代汉语翻译小说规范的语料库研究》,华东师范大学博士学位论文,2006年。
11 连淑能:《英汉对比研究》,高等教育出版社1993年版,第97页。
14 黄立波:《基于汉英/英汉平行语料库的翻译共性研究》,复旦大学出版社2007年版,第89页。
16 吴昂、黄立波:《关于翻译共性研究》,《外语教学与研究》2006第5期。
17 肖忠华:《英汉翻译中的汉语译文语料库研究》,上海交通大学出版社2012年版,第158页。
