“神威·太湖之光”上Tend_lin应用的并行优化研究
2020-11-05姜尚志唐生林高希然
姜尚志,唐生林,高希然,花 嵘,陈 莉,刘 颖
(1.山东科技大学计算机科学与工程学院,山东 青岛 266590;2.中国科学院计算技术研究所计算机体系结构国家重点实验室,北京 100190)
1 引言
随着全球变暖的不断加剧,气候问题成为关系到人类社会生存与发展的重大战略议题,受到各国政府、机构和学术界的高度重视。西方发达国家纷纷开发具有更高精度的气候模拟程序,如CAM5(Community Atmosphere Model version 5)[1]、ECHAM5(European Center HAmburg Model version 5)[2]、MRI-AGCM(Meteorological Research Institute Atmospheric General Circulation Models)[3]、BCC_AGCM(Beijing Climate Center Atmospheric General Circulation Model)[4]。我国也联合多家研究机构研制了中国科学院地球系统模式CAS-ESM(Earth System Model of Chinese Academy of Sciences)[5]。本文关心的IAP AGCM[6]是中国科学院大气物理研究所IAP(Institute of Atmospheric Physics)研发的大气环流模式AGCM(Atmospheric General Circulation Model),是CAS-ESM的5个主要分量模式之一[7],也是整个CAS-ESM中运行时间占比最大的分量模式。IAP AGCM自20世纪80年代发布第1代[8]以来,已历经4代,气候模拟能力得到了显著提升[6,9,10],并亟需移植到新一代超级计算机上以进一步提高其模拟速度。
E级超级计算系统将于2020年出现,各国都将全球气候变化的模拟列为重点应用领域。近年来,由于访存墙、指令墙、并行墙和功耗墙等因素的限制,异构众核已成为超级计算机的主流体系结构构架。如何把复杂的气候模拟程序移植到新一代的超级计算机上并取得更好的并行性能具有重要的现实意义。“神威·太湖之光”是我国自主研发的超级计算机,也是全世界第1台峰值性能超过100 PFLOPS的超级计算机,曾4次蝉联TOP500榜首,其计算结点采用国产异构众核处理器申威26010[11],是典型的异构众核加速结构。研究气候模式应用在“神威·太湖之光”上的并行优化,对于将来应用到国产E级计算机的并行优化具有借鉴意义。
在大规模异构众核的并行计算系统上,程序员主要使用MPI+X的混合编程模式进行并行编程,其中MPI负责进程级的并行和通信,而模型X对应进程内异构加速的并行编程模型,X的选择有OpenMP[12]、OpenACC[13]、OpenCL和CUDA等。基于制导的编程模型,比如OpenACC和OpenMP,因为把异构加速代码的生成交给编译器,降低了程序员负担而广泛用于MPI应用到大规模异构众核并行计算系统的迁移。但是,现有主流的异构众核编程模型对用户标记的待加速循环,主要以fork-join的锁步推进模式进行加速,而难以发掘不同循环间的并行性。
近年来,数据驱动的任务编程模型受到国际学术界的广泛关注,它因为能自然地表达并行性而有利于应对当代多核、众核系统上的可编程性挑战和性能挑战。数据驱动的任务编程模型将应用表示为以任务为节点、任务间数据依赖关系为有向依赖边的有向无环图DAG(Directed Acyclic Graph),用户只需提供每个任务的数据访问信息,而依赖关系的构建和任务调度执行则交由底层运行时库完成。这类编程模型有OpenMP (4.0以上)、StarPU[23]、OmpSs[24]、Cilk和AceMesh[25]等。
地球系统模式到大规模异构众核平台的移植和优化得到了广泛的研究。Yang等人[14]利用神威众核线程加速库Athread实现了MPI+Athread的高效并行;Fu等人[15,16]在“神威·太湖之光”上借助OpenACC、自研的循环变换工具、内存足迹分析优化工具对CAM的动力框架CAS-SE进行了代码重构和并行,加速效果显著,部分热点取得了22倍的加速;李镔洋等人[17]和吴琦等人[18]分别实现了海冰模式和区域海洋模式在“神威·太湖之光”上的并行化。肖洒等人[4]和魏敏等人[19]先后对国家气候中心大气环流模式BCC_AGCM的部分核心段在“神威·太湖之光”上使用OpenACC进行异构众核加速;傅游等人[20]提取IAP AGCM-4的动力框架热点模块Tend_lin构建了独立的测试程序,在“神威·太湖之光”上使用OpenACC实现了最高1.4°分辨率下的异构众核加速,单核组多线程获得6倍以上加速。
在并行算法优化方面,Xiao等人[21]针对IAP AGCM的动力框架,为计算流推导出新的基本操作,通过引入近似项等方式,提出了通信避免算法,大规模降低了集合通信和点到点通信的频率,同时也最大化了通信隐藏的机会,最终把整个模式的执行时间降低了54%。针对二维经纬网格的分解并行扩展性低的问题,Wu等人[22]为IAP AGCM的动力框架引入三维区域分解及自适应高斯滤波方案,使得0.5°分辨率的模拟在“天河二号”上可扩展到32 768个CPU核。本文的工作集中在进程内的多线程并行,以及自动地实现通信-计算重叠,与以上2个进程间的并行算法优化是互补的。
本文面向“神威·太湖之光”并行计算平台,选择IAP AGCM-4中动力框架过程的适应过程Tend_lin,分别利用OpenACC和中国科学院计算技术研究所研发的数据驱动的任务并行编程接口AceMesh对其进行并行优化,获得了比较好的性能加速。本文贡献包括:
(1)针对高分辨率模拟的并行特点,利用OpenACC对Tend_lin进行众核并行的优化,指出了OpenACC的局限性。
(2)利用数据驱动的任务并行编程接口AceMesh对Tend_lin进行异步并行的优化。具体包括AceMesh并行区中全局数据分块的选择,计算循环和通信代码的任务并行方法,并针对Tend_lin应用中计算/通信比低、进程内并行度不足的特点,讨论了放松通信资源共享的通信去串行化,以及单层任务图和嵌套任务图下的任务映射优化。
(3)在“神威·太湖之光”平台上对Tend_lin的并行优化进行了评估和性能分析。测试表明,相比OpenACC并行版本,AceMesh在16~1 024进程的不同并行配置下均得到了平均2倍以上的性能提升。本文还详细分析了性能收益的来源。
2 Tend_lin过程和Tend_lin程序
大气环流模式(AGCM)是由最初的数值天气预报模式演变而来的,是地球系统模式中最为复杂的分量模式,计算量占地球系统模式中全部计算量的50%以上。IAP AGCM-4[6]是中国科学院大气物理研究所研发的第4代大气环流模式,采用均匀经纬格点的有限差分数值方法,目前最高支持到0.25°分辨率,主要包括物理过程和动态框架2个过程。其中,物理过程在IAP AGCM-4中的时间占比随着CPU核数的增加而降低,在2进程时时间占比23.8%,在1 024进程时时间占比仅12.0%。自主设计的动力框架过程是IAP AGCM-4模式中最耗时的模块之一,是用来求解关于时间的偏微分方程组。
动力框架的计算在空间上是三维的,每一格点的计算都可能与周围的很多格点有关。动力框架方程组[6]如下所示:
(1)
其中,各参数的含义请见参考文献[6]。
方程组中涉及平流过程(Tend_adv)和适应过程(Tend_lin)2个主要的差分计算,其中适应过程的调用频率很高。
本文关注适应过程(Tend_lin),该过程主要是对经纬圈和垂直层上的温度、风向模拟变量等进行数值差分计算,得到U(纬向)、V(经向)、T(温度)、P(气压)的倾向值。动力框架采用纬度、高度的二维区域分解进行MPI多进程并行。为了保证数值计算的正确性和有效性,在其中插入滤波和平滑过程(Filt、Smoother),剔除计算中偏差大的数值。
Tend_lin过程要计算4个模拟变量,这些变量都会经历2个阶段的计算,分别是差分方程的计算和模拟结果的滤波平滑。后文把2个阶段分别简称为stencil阶段和滤波阶段。这4个模拟变量的计算过程中还存在一些共用的变量和通信,整个适应过程可以用图1的模块依赖关系图进行抽象。
从图1所示的依赖关系图中可以看出,DU/DV2个变量总是一起计算,而DT和DPsa在计算过程中也存在一定的关联性,比如它们的极点区域是在一起计算的,极点区域的DT/DPsa的计算涉及一些变量在高度方向的归约求和。而TT1则要对DIV和TT2个变量在每个高度通信域上进行mpi_allgatherv收集,涉及的通信量很大。在差分计算阶段有很多纬度方向的近邻通信。关于平滑处理,DU/DV采用的是一维纬向平滑方法(SHAP1),计算量较小,也不需要进程间的通信。而DT/DPsa采用二维平滑方法(SHAP2),需要纬度方向的近邻通信。

Figure 1 Diagram of dependencies between modules computed with four variables图1 4个变量计算模块之间的依赖关系图
3 数据驱动的AceMesh并行优化
3.1 AceMesh任务并行编程接口
AceMesh是基于制导的、数据驱动的任务并行编程接口,其编译器是一个基于rose框架的、源源变换的编译器,变换后的源代码将再经过目标平台上的本地编译器编译、并链接AceMesh运行时库得到可执行代码。AceMesh编译系统目前支持X86的多核平台和国产神威平台。
AceMesh支持增量并行化,表1列出了它的主要制导。begin/end制导用于指定一个待并行化的程序代码区域,这个单入单出的代码块也称为任务并行区,因为并行化后的程序以有向无环图的任务图方式执行,这个并行区也称为DAG并行区。AceMesh提供了2种类型的任务制导(task制导和do制导),让用户描述相关任务的数据依赖信息。DAG区内的源代码分为任务代码和任务构建代码2类。任务代码是那些出现在任务制导动态范围内的代码,它们将被外联为任务函数,这些任务的执行被推迟,推迟到什么时刻在哪个计算核心上执行取决于运行时库。任务构建代码由主线程执行,负责构建任务并行区内的所有任务,包括构建其任务对象和参数、任务之间的依赖关系、实现任务之间的同步等。由于并发任务相对于构图阶段而言是延迟执行的,用户应该保证不存在从任务代码到任务构建阶段的数据依赖关系,否则需要追加taskwait制导实现同步。arrayTile以数据分块的方式提供了DAG并行区中的并行模板。AceMesh允许出现嵌套的DAG并行区,也就是在一个并发任务内部,还可以定义tasks,使用do制导,声明arrayTile、taskwiat制导。task/do制导的map子句的参数可以是master或acc,分别表示并发任务将在主线程上执行,或者在加速器中执行。

Table 1 Summary of AceMesh’s directives表1 AceMesh主要制导
对于并行循环,我们使用的do制导如下所示:
!$acemesh do [map(master|acc)] tasktile(loop_tile_list) in() out() inout() nested [if()] [nested] [private()] [firstprivate()] [lastprivate()] [reduction()] [label〈string〉]
tasktile子句描述了如何将相关循环的迭代空间划分为块,并将每个块封装到一个数据流任务中。do/task制导的nested子句指示该任务内部存在嵌套的任务依赖关系图。in/out/inout子句描述每个任务的数据访问区域,其列表项可以使用变量和数组区域。数组区域的每个下标可以是一个三元组' [lo_expr]:[up_expr]:[step] ',其中lo_expr和up_expr是tasktile子句中循环索引量的仿射表达式,我们还使用一个特殊的*表示整个维展区间。实际上,很多时候数组访问区域可以简化为一个数组名,因为具体的数组访问区域通常可以由AceMesh编译器自动推导出来。label是图形化工具展示用的,提供task_graph和loop_graph上的循环标记。
对于do制导,AceMesh编译器会根据tasktile子句提供的循环分块信息对并行循环进行分段变换,每个循环分块对应一个并发任务,并按照map子句的指示,生成主核任务代码或者从核任务代码。
3.2 全局数据分块和计算循环的任务并行方法
用户在对任务并行区进行并行的时候,要先对并行区进行全局分析,确定主流的数据分块模式,尽量让每个并行循环套的并行策略与数据分块模板对齐。然后根据数据分块的模式,具体决定每个并行循环的任务分块方法。
(1)stencil阶段的并行化。
stencil阶段(也就是差分计算阶段)的多数计算模式是对纬度-高度-经度组成的三维网格空间进行扫描计算,大多数循环套在3个轴向都是可并行的,只有少数几个循环套的高度维不能并行而是要做复杂的规约计算。对整个阶段而言,本文选择对纬度空间进行一维数据分块,采用default子句为大多数数组声明其分块方式。然后对每个循环套进行并行时,让循环的任务分块尽量与数据分块对齐。算法1是其中一个典型循环套的并行化算法。DT数组的allocate语句是从其他文件中提取出来的,用来展示数组维展。第1~2行给出的是数据分块制导,其中纬度分块尺寸是tilej。第3行给出的是循环的任务并行方法,因为DT和ST的数组下标表达式的仿射系数都是1,所以循环分块的尺寸与对应数组维的分块尺寸相同,这样每个任务正好为一个数据分块进行定值,而in/out子句的列表项,本文采用简化写法,只给出数组名,由编译器推导任务访问的数据区域。
算法1数据分块制导和stencil阶段第14循环的任务并行算法
allocate (DT(NX,beglev:endlev,beglatdynex:endlatdynex) )
… …
1 !$acemesh arrayTile dimtile(*,tilej) default
2 !$acemesh arrayTile dimtile(*,*,tilej) default
3 !$acemesh do tasktile(j:tilej) inout(DT) in(ST)
4doJ=beglatdyn,endlatdyn
5doK=beglev,endlev
6doI= 1,NX
7DT(I,K,J) =DT(I,K,J)+ST(I,K,J)
8enddo
9enddo
10enddo
11 …
(2)滤波阶段的并行化。
本阶段调用一个FILT2D函数对每一个经纬平面进行滤波和平滑处理。算法2展示的是DT数组的滤波过程的任务并行算法,对于每个高度,先把待滤波的经纬面拷贝到一个临时数组WW,滤波处理后再拷贝回原始数组。由于这里没有使用nested制导,我们称这种任务并行方法为单层任务图。在FILT2D函数内部,有多级函数调用,其中的多数循环只有纬度方向可以并行分块。算法3给出的是其中一个典型循环——低纬度滤波循环的任务并行情况。
算法2DT变量滤波的任务并行算法
1dok=beglev,endlev
2 $acemesh do tasktile (j:tilej) in(DT) out(WW2)
3doj=beglatdyn,endlatdyn
4WW(:,j)=DT(:,K,j)
5enddo
6 CallFILT2D(WW,0,1,IBCFFT)
7 !$acemesh do tasktile(j:tilej) out(DT) in(WW2)
8doj=beglatdyn,endlatdyn
9DT(:,K,j)=WW(:,j)
10enddo
11enddo
算法3滤波阶段一个循环的AceMesh并行算法
1 real(r8),intent(inout) ::CH(NX,NY)
2 !$acemesh arrayTile dimtile(*,tilej) default
3 !$acemesh do tasktile(j:tilej) inout(CH)
4doJ= max(JBL,beglatdyn),min(JEL,endlatdyn)
5X0=ZERO
6doI= 1,IM,2
7X0 = (CH(I,J)-CH(I+1,J))+X0
8enddo
9X0=X0/FIM
10doI= 1,IM,2
11II=I+1
12CH(I,J) =CH(I,J)-X0
13CH(II,J)=CH(II,J)+X0
14enddo
15 callperiodp(CH(1,J))
16enddo
3.3 利用嵌套任务图优化计算任务的从核映射
本小节主要优化滤波阶段的并行性。滤波阶段的代码隐含了变量之间、高度之间、纬度之间3个层次的并行性,AceMesh编程接口可以自然地发掘这3个层次的并行性。
单层任务图的任务映射缺陷如算法2所示,每个高度上都会进行滤波计算,由于AceMesh根据任务的数据访问区域决定亲和性,而不同高度上的滤波都是在局部数组CH上进行,在AceMesh看来它们的纬度区间是重叠的,这就导致这些并行循环上的并行任务总是映射到同样的从核子集,而没有均匀分散到从核阵列,于是丢失了第1层和第2层的滤波并行性。同时,AceMesh编译器的运行时系统还没有在“神威·太湖之光”上支持任务窃取,从而滤波阶段的并行度没有得到充分的发挥。
利用嵌套任务图优化滤波阶段:算法4利用AceMesh的嵌套任务图(后面简称嵌套图)对滤波阶段进行并行化。相比算法2的单层任务图(后面简称单层图)风格的代码,这里新增加了第1行的数据分块——对DT数组进行纬度为tilej、高度为1的二维分块,第2行的do制导对k循环进行任务分块,分块尺寸是1——与数据分块的尺寸相同。需要指出的是k循环内的并行化制导以及FILT2D函数内的制导都不需要修改(与算法3的版本一致)。第2行的并行循环将对应很多并发任务,这里每个任务本身又是一个任务图,从而形成嵌套的任务图。AceMesh编译系统对第2行进行处理时,根据每个任务的DT访问区域对每个任务分配对应的从核集合。编译系统遇到算法2的二级任务时,将在一级任务所确定的从核集合中进行从核映射。采用嵌套任务图的并行方法后,滤波阶段3个层次的并行性得到充分挖掘。
算法4用嵌套任务图并行化滤波阶段
1 !$acemesh arrayTile dimtile(*,1,tilej) dim(NX,beglev:endlev,beglatdyn:endlatdyn) arrvar(DT)
2 !$acemesh do tasktile(k:1) inout(DT(*,k,*)) private(WW) nested
3dok=beglev,endlev
!original loop body
4enddo
3.4 用task制导实现通信和计算的动态重叠
原程序对点到点通信实现了一定程度的通信-计算的重叠优化,但是没有对集合通信做通信隐藏的优化(实际上静态的代码调度很难隐藏这些优化)。stencil阶段对点到点通信的发起尽量前提,而把通信等待延迟到使用时。而filter阶段的通信调度更加局限,没有与计算进行重叠,而仅仅是对每一对通信的收、发进行了调度。
AceMesh版本对所有点到点通信和集合通信都进行了任务并行的优化。算法5给出的是通信发起操作的任务并行制导,因为消息接收是对消息缓冲的写操作,而同时建立一个通信句柄,也就是通信句柄也是写操作。算法6给出的是wait操作的任务并行制导,根据MPI规范的语义通信句柄是inout参数,所以该句柄的数据流属性是既读又写。
对于MPI集合通信,AceMesh任务并行方法与此类似,不再赘述。需要指出的是,AceMesh自动把连续出现的通信发起代码和通信等待代码在调度时分开,尽可能早地提前发起通信操作,而对通信等待任务进行不断轮询,避免线程在mpi_wait上等待而浪费处理器的时间,也避免了由此带来的MPI死锁。
算法5非阻塞通信的post操作的AceMesh并行算法
1if(myid_y.ne.0)then
2 !$acemesh task map (master) private(ierr) out(rbuf(*))out(rreq(2))
3rreq(2)=MPI_REQUEST_NULL
4 call mpi_irecv(rbuf,leng,mpir8,myid_y-1,10+myid_z,comm_y,rreq(2),ierr)
5 !$acemesh task end
6endif
算法6非阻塞通信的wait操作的AceMesh并行算法
1 !$acemesh task map (master) inout(req(*))
2 call mpi_waitall(2,req,status,ierr)
3 !$acemesh task end
3.5 利用tag私有化降低通信之间的串行化依赖
通信信封和通信保序:MPI为了实现通信行为的确定性,用通信信封对点到点通信进行消息配对。通信信封是个四元组〈源进程、目的进程、通信标签、通信域〉。信封相同的消息在配对的时候要保持原来的发起顺序,先发起的先配对,也就是说P1进程发给P2进程的信封相同的2个消息会按照确定的顺序进行,在P2进程上接收顺序与P1上的发送顺序一致。对于非阻塞通信,序关系作用在通信发起操作(比如mpi_irecv)之间。
Tend_lin应用中有4个变量需要进行滤波处理,其中DT和DPsa2个变量的滤波过程中需要二维平滑处理,从而引入纬度方向的近邻通信。FILT2D函数内这些通信均采用了相同的通信标签和通信域,从而导致不同高度、不同变量的滤波通信之间必须保序,也就是所有向左的通信必须串行化发起,所有向右的通信也必须串行化发起,这就降低了应用中的任务并行性。
通过使用更多的通信标签(tag)进行去串行化:可以用2种方法来放松通信信封带来的序关系:(1)复制出更多的通信域;(2)使用个性化的通信标签。因为通信域的复制会带来很大的开销,本文选择对通信标签进行重构。对通信标签进行基于计数器的资源池管理,提供一定数量的、不同的通信标签,降低通信发起操作之间的串行化趋势,提高通信推进的自由性。后文把这个优化称为tag私有,而原来的版本则称为tag共享。目前最终测试中每个轴向通信的标签总数是20。
3.6 从核任务代码的数据传输优化
从核任务代码的质量在很大程度上影响到AceMesh程序的性能。AceMesh编译器所生成的从核任务代码已经对变量进行了LDM(Local Data Memory)局部存储优化。但是,在跨语言对比的时候,仍然发现了AceMesh编译器从核代码优化的不足,本文对此进行了手工补充。
非整除块的reshape优化:AceMesh的tasktile与OpenACC的循环映射的分块语义不一样,并行循环的第1个分块和最后1个分块都可能出现非完整分块的情况。若并行分块循环对应到数组的非最高维,则非完整的循环分块导致LDM数组中的目标区域在地址上不连续,从而DMA数据传输被迫分成多次进行,将会明显降低传输性能。由于AceMesh编译器采用了源源变换的方法,用户可以查看变换后的从核任务代码,并进行进一步的手工优化。对于主存源数组区域的内存地址连续的情况,本文采用一次DMA通信把整块数据传递到LDM,然后在片上进行数组转置。类似地,这种非完整分块的数据写回也采用“先reshape-后DMA传输”的方式。
4 性能评估
实验平台:“神威·太湖之光”计算机系统的每个结点采用 申威26010异构众核处理器,该处理器集成4个运算核组,每个核组包含1个运算控制核心(主核)和64个运算核心(从核),从核以8×8的Mesh结构组成运算核心阵列(从核阵列)。每个从核拥有64 KB大小、SPM形式的高速局部存储空间。
神威平台的结点内提供athread和OpenACC 2种异构编程模型。其中OpenACC是一个面向多核、异构众核平台的并行编程接口,支持C、C++、Fortran编程语言,支持多种硬件架构。神威平台的OpenACC*基于OpenACC2.0标准,针对申威26010处理器结构特点进行了适当的精简和扩充。一些有特色的扩展包括:(1)针对带跨步的数组传输,提供pack/swap等子句,利用数据打包、数组转置优化DMA数据传输效率;(2)为data制导扩展index子句,允许用户设置数据打包和转置的放置点,把数据打包和转置动作进行外提。
本节在“神威·太湖之光”平台上分别对OpenACC和AceMesh实现的2个Tend_lin并行版进行性能评估和分析。本文采用2种分辨率,其三维网格空间分别是720×361×30的0.5°×0.5°(50 km)和1440×721×30的0.25°×0.25°(25 km)。
对于OpenACC版本,本文检查了源源变换后的每个从核代码,确保变量都进行了LDM优化。
参数调优:对于OpenACC和AceMesh 2个版本,本文对每个并行循环设置了不同的分块参数,以方便调优。MPI二维区域分解中,不同进程布局对性能影响较大,本文对进程数进行因式分解的穷举测试;对以上输入采用调优参数配置文件的形式完成批量测试,测试完成后自动在测试结果中选优。
4.1 Tend_lin的OpenACC优化
OpenACC并行化基于傅游等人[20]的前期工作,此前已经进行了循环分布的预处理,实现了OpenACC循环映射、数据传输的优化以及函数调用的从核化等几方面程序变换,对于1.4°分辨率得到了良好的性能加速。本文面向100、1 000进程的结点并行,考虑0.5°和0.25°高分辨率下的大规模众核并行。
4.2 滤波阶段的优化评估与分析
由前可知,Tend_in应用包含了stencil阶段和滤波(filter)阶段2个阶段。其中,滤波阶段的并行度很高,其AceMesh版本与OpenACC版本的行为差异很大,AceMesh相对加速比很高,因此本小节单独对这个阶段代码的并行优化方法进行对比分析。
滤波阶段主要有2个AceMesh优化:影响任务映射的是单层图和嵌套图2种并行方式,影响通信并行度的是tag共享和tag私有2个不同的通信标签处理方式。以上2种优化组合起来总共形成4个独立的AceMesh版本,其特征描述如表2所示。表2中,“子图”特指单个高度的滤波计算对应的任务图。简单分析后可以知道,这4个版本按照性能由低到高的顺序是tag共享的嵌套图、tag共享的单层图、tag私有的单层图、tag私有的嵌套图。

Table 2 Description of four AceMesh versions of the filter phase表2 Filter阶段4个AceMesh版本的介绍
下面对比4个AceMesh版本相对OpenACC的加速比,由于tag共享的嵌套图性能太差,本文没有对其进行测试,在此只展现后面3个版本的性能提升的情况。每种进程数下,OpenACC和AceMesh版本采用相同的进程网格分解方式(都选择AceMesh版整体性能最优的进程分解方式),给出AceMeshi/OpenACC的相对加速比,其中AceMeshi表示AceMesh的第i个优化版本,i=2,3,4。图2所示为0.5°分辨率下,16~1 024进程时,3种AceMesh并行版本的相对加速比的差异。
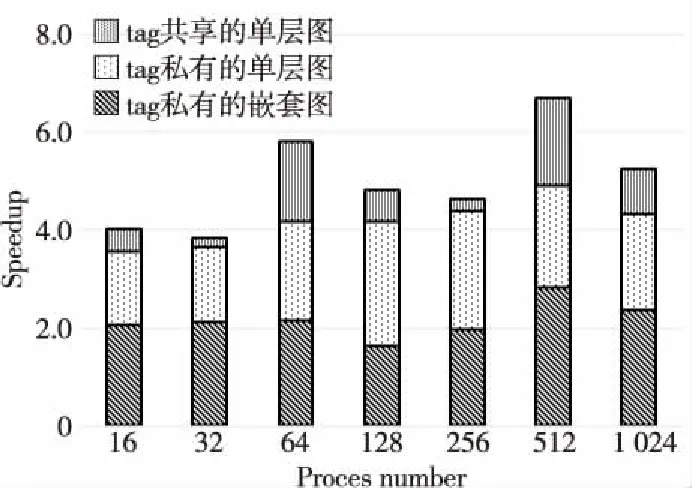
Figure 2 AceMeshi/OpenACC speedups in the filter phase,i∈{2,3,4}图2 滤波阶段3个AceMesh优化版本的AceMeshi/OpenACC加速比,i∈{2,3,4}
首先,tag共享的单层图也实现了子图之间一定程度的并行性。由于多个高度间属于同一层任务依赖图,当一个高度的任务图推进由于通信等待而被阻塞时,计算资源可以分配给其他高度滤波的就绪任务,从而不同高度间的任务也存在并行机会,也挖掘了通信和计算的重叠。相比OpenACC只能挖掘循环内不同纬度间的并行性,tag共享的单层图相比OpenACC平均加速1.18倍。
其次,作为一个典型的通信密集型应用,Tend_lin在滤波阶段尤其表现出计算量小、通信密集的特点,通信之间的并行性、通信-计算之间的并行性对性能影响很大。tag私有的单层图因为消除了通信之间的序关系,在保证部分高度并行的同时,为多个通信的并行创造了条件,在各种进程配置下都获得了较为明显的加速效果,把相对加速比进一步提高,平均再提高了0.64倍。此时不同高度之间尚未完全并行,仍然存在性能提升空间。
最后,tag私有的嵌套图由于实现了不同高度子图间的完全并行,性能进一步提高。在一些进程配置下性能提升还比较显著。该版本相比OpenACC得到了最高6.7倍的加速,以及超过3.9倍的平均加速。
4.3 全程序性能评估与分析
图3给出了2种分辨率下Tend_lin全程序在“神威·太湖之光”平台上的性能测试结果,无论在何种进程下,Tend_lin测试程序的AceMesh版的总性能都优于OpenACC的。在0.5°分辨率下,AceMesh得到最高3倍,平均2.17倍的加速;在0.25°分辨率下,AceMesh得到最高2.86倍,平均1.98倍的加速,获得了较好的加速效果。为理解性能数据,本文分别测量stencil阶段和滤波阶段。

Figure 3 AceMesh/OpenACC performance comparison图3 AceMesh/OpenACC性能对比
从分项测试数据来看,stencil阶段的计算时间较长,滤波阶段的计算时间较短,所以stencil阶段的性能对程序总性能提升效果影响更大。stencil阶段相比滤波阶段数据足迹和计算量较大,当进程数较少(小于32进程)时,进程内并行度足够,OpenACC同步式的推进方式容易产生集中的DMA访问,导致带宽受限,而AceMesh的异步调度方式能够有效地将DMA和计算错峰调度,获得更好的DMA性能。随着进程数的增加,进程内并行度和带宽压力的降低,DMA调度带来的性能提升随之下降。当纬向的进程数超过32时,进程内的并行度成为主要矛盾,此时将任务分块因子从2调整到1,可以增加任务个数,降低从核的空置率,stencil阶段依然能保持性能的稳定。OpenACC只能在本地循环嵌套中并行,随着进程数增加,面临的并行度不足问题越来越严重,即便使用collapse合并多层循环,达到的加速效果仍然有限。尤其作为通信密集型应用,OpenACC并不能提供良好的通信优化手段。不足的并行度和密集的通信成为限制OpenACC性能提升的关键,而这也是AceMesh并行的主要收益来源。0.5°分辨率下,stencil阶段在1 024进程时加速效果上升,其实是因为OpenACC并行度极低状态下,空转的线程产生了负面影响,导致绝对性能变差。
需要注意的是,滤波阶段的数据与4.2节的数据存在很大的不同。4.2节为了评估不同优化效果的影响,OpenACC和AceMesh采用了相同的进程网格分解方式。但是,图3中滤波阶段的进程网格分解方式与并行编程接口整体最优性能下的进程网格分解方式一致,从而其数据与图2的数据存在很大的不同。可以看出,AceMesh加速效果随着进程数量的增加而增加,这是因为随着进程数量的增加,每个循环中剩下的工作越来越少,较低的并行度成为OpenACC的主要性能瓶颈。AceMesh则可以利用不同数组、不同高度和不同纬度之间隐含的3层并行性,相对充分地利用众核计算资源,得到更好的加速效果。当进程数超过256时,AceMesh的加速效果急剧提高。
5 结束语
本文基于国产超算平台“神威·太湖之光”,研究了大气环流模式热点Tend_lin的异构并行优化方法,指出了OpenACC在并行优化方面的局限性,利用数据驱动的任务并行模型AceMesh对其进行并行优化,并探讨了通信去串行化、嵌套任务图的并行优化方法。最后对2个不同的并行编程接口进行性能对比,结果表明MPI+AceMesh并行获得平均2倍左右的性能提升,本文还详细分析了AceMesh性能收益的来源。
未来将进行以下2项工作:(1)利用AceMesh并行编程环境把最新的IAP AGCM 5.0热点移植到“神威·太湖之光”平台上,同时把数据流并行扩大到该模式代码的更大范围,以进一步提高模拟的并行性能;(2)在AceMesh编译系统中自动实现本研究中提出的编译优化技术,比如非整除块的reshape优化,提高编译系统的性能。
