大规模高性能互连拓扑性能分析
2020-11-05蒋句平董德尊齐星云常俊胜庞征斌
蒋句平,董德尊,唐 虹,齐星云,常俊胜,庞征斌
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
随着各行各业对高性能计算需求的持续增长,高性能计算机的性能不断提升。根据TOP500发布数据,1993~2012年,高性能计算机的性能以每10年1 000倍的速率提高。从2013年起,性能上升速率变缓,如果没有重大突破,将降为每10年只提高100倍左右。互连网络是连接处理器、存储器、I/O设备的重要组成部分,通常用于实现不同处理节点间的同步和通信,是HPC系统全局设计的基础设施,已经成为HPC可扩展性和性能提高的关键要素。当前高性能计算机正迈向E (Exascale) 级计算时代,系统规模不断扩大,应用领域不断扩展,包括微处理器、加速器等的广泛采用对互连网络拓扑结构提出了许多新的要求[1]。目前高性能互连网络主要面临着如下挑战:(1)规模。随着E级计算时代的到来,网络规模需扩展至十万量级以上,这对网络拓扑结构设计和网络可靠性提出了更高的要求。(2)性能。HPC计算性能不断攀升,互连网络需要提供与计算性能相匹配的高互连带宽。(3)网络直径。规模的扩大需要设计更小的网络直径以降低网络延迟。(4)功耗。系统规模的扩大使互连网络的功耗提升,高功耗将严重制约系统设计和使用。高性能互连网络设计中,网络所采用的拓扑结构和路由算法是影响网络性能的关键,从根本上决定了大规模并行的效率,这使得高性能互连网络的设计在HPC系统中愈加重要。
为了应对高性能互连网络所带来的挑战,目前大部分HPC系统均采用高阶路由器来搭建高性能互连网络,Kim等人[2]也在实验中证明了在大规模互连网络中,使用高阶路由器将会减少网络直径和平均跳步数,能获得更低的传输延迟,使用更少的路由器和互连链路,网络设计成本和功耗也显著降低。基于高阶路由器设计高性能系统互连网络已成为互连网络设计的主流趋势。
本文针对目前主流的高性能互连网络拓扑结构进行分析,并对这些网络拓扑的可扩展性进行分析,最后通过自主研发模拟器评测了Torus结构从低维到高维的网络性能,以及其它几种大规模拓扑结构在不同通信负载与路由策略下的性能。
2 高性能互连拓扑结构
随着高性能计算机的不断发展,国内外许多研究小组都致力于高性能互连网络的拓扑结构研究与设计,如早期高性能计算机主流拓扑Torus、以蝶形网络为代表的拓扑FT(FatTree)[3]、层次化全互连拓扑结构DF(Dragonfly)[4]、由Dragonfly和Clos结构变形而来的拓扑结构MF(MegaFly)[5]、根据图论中MMS图设计的拓扑结构SF(SlimFly)[6]。下文将对上述拓扑结构进行介绍与分析。
2.1 Torus
高性能计算机系统发展的初期,以Torus为代表的k元n立方体一直是互连网络的主流拓扑。比如,Crayd的T3D[7]、T3E[8]均采用了3D Torus结构,由于早期硬件条件不成熟,这种结构无法扩展至高维,目前随着硬件条件的提升,高维Torus结构已经被许多主流的高性能计算机系统使用。Fujisu公司推出的K computer[9]和PRIMEHPC FX0采用的互连网络Tofu是6D Torus 结构。Tofu网络由2类3D Torus组成:ABC 3D环状网和XYZ 3D环状网。而Fujisu公司计划开发的下一代超级计算机Post-K将继续采用该结构进行互连[10]。
构建高维Torus最大的优势是可以减少每一维的路由节点数量,提高网络的吞吐量,并且Torus网络具有较优临近通信性能、扩展能力和容错能力等优点。但是,对于高维的Torus网络,其延迟也随着增加,降低了网络的性能;其次,高维Torus所带来的死锁问题相对比较复杂。
2.2 FatTree
FT结构是最早的大规模低直径高性能互连网络拓扑结构[3]。我国自主研制的高性能计算机“天河一号”“天河二号”以及“太湖之光”均采用该结构。FT是一个灵活性和扩展性都较好的拓扑结构,随着网络规模的增加,二分带宽也随之等规模增加。图1是一个2元3层的FT结构,网络中路由节点分为2类,1类为非叶子层的路由节点,负责链接上下层的路由节点,完成报文转发传输;另1类为叶子层的路由节点,不仅链接上一层的路由节点还链接终端。每个路由节点的度数为2k,需要(2n-1)kn-1个路由器,可支持2kn个终端,网络直径为2(n-1)。
相比于Torus结构,FT网络路由算法更易实现,有更低的网络直径,网络性能较优。但是,FT网络也存在限制因素,扩大至更高规模需要增加网络层数,链路数随之指数增长,造成更大的资源开销。
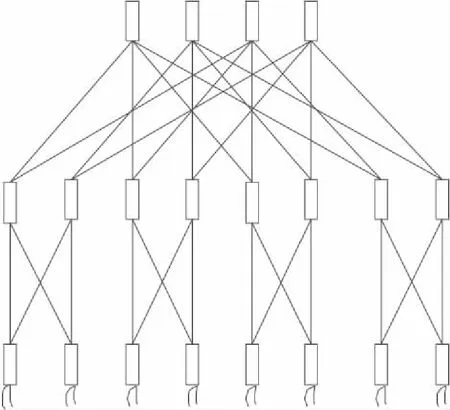
Figure 1 FatTree(2,3)图1 2元3层胖树结构
2.3 Dragonfly
DF是2008年在ISCA(International Symposum on Computer Architecture)会议上提出的新型高性能互连网络[4],是大规模低直径高性能互连网络的典型代表。2017年11月和2018年6月 TOP500中排名第3和第6的高性能计算机Piz Daintr 互连网络采用的就是DF。另外,IBM和联想都采用了该结构设计高性能计算机系统。如图2所示,DF是层次式全互连结构。DF(t,a,h)是一个3级的层次结构,第1级是单个路由节点,第2级是多个路由节点互连而成的超级节点,第3级是多个超级节点互连而成的网络。每个路由节点有3种不同的链接类型:(1)每个路由器引出t条链路连接终端;(2)在同一个超级节点内每个路由器引出a-1条链路连接其余路由器;(3)每个路由器引出h条全局链路连接其余超级节点内的路由器。因此,每一个路由节点的度数为k=t+a+h-1。DF网络需要a(ah+1)个路由器,最大可支持at(ah+1)个终端。DF因为任意2组之间都有1条全局链路,转发1个报文最多只要经过2条本地链路和1条全局链路,所以任意2个终端通信最多只要经过3跳。DF结构利用全互连的思想分层构建,不仅网络直径小,而且相比FT拓扑结构网络扩展性更好,成本开销更低。在满足a=2t=2h条件下,DF可扩展至最大规模,且能达到均衡配置的要求。

Figure 2 Dragonfly network图2 Dragonfly网络
2.4 MegaFly
MF是2017年在HiPINEB(High-Performance Interconnection Networks in the Exascale and Big-Data Era)会议上提出的,也称为Dragonfly+[5],其结构如图3所示。MF 也是一个层次结构,类似于DF,由多个由全局链接连接的组构成。与DF不同的是,MF组内是1个2层的Clos结构,叶子层的路由节点不仅链接上1层的路由节点,还链接k个终端。非叶子层路由节点不仅链接叶子层路由节点,还链接了其他k个超级节点。 因此,每一个路由节点的度数为2k。MF需要k(kk+1)个路由器,MF网络可支持kk(kk+1)个终端。在使用相同端口数的情形下,MF可支持的网络规模是DF结构的近4倍。

Figure 3 MegaFly network图3 MegaFly 网络
2.5 SlimFly
SF是2014年在SC(Supercomputing Conference)会议上由瑞士学者提出的[6]。如图4所示,SF是采用代数图论的MMS图[11]构造的一个近似最优拓扑结构的高性能互连网络结构,该拓扑结构由2个子图构成,每个子图内由相同数目的子组组成。SF拓扑的构造取决于素数幂q,q满足q=4w+δ,其中δ∈{-1,0,1},w∈N。一个路由节点的度数k=(3q-δ)/2+(3q-δ)/4,可支持2q2*(3q-δ)/4个终端。相比其他结构,SF的端口利用率高,在直径为2的约束下,使用尽可能少的路由器端口数可构造更大规模的拓扑结构。SF结构是继DF结构之后又一个标志性拓扑结构,满足了低直径大规模的要求。

Figure 4 SlimFly network图4 SlimFly 网络
3 模拟器介绍
研究大规模互连网络一直都是很具有挑战性的工作,模拟一个有数千个结点的系统可能需要大量的资源和时间,许多研究者也开发了相应的模拟器,比如基于时钟精确的互连网络Booksim模拟器,但其只支持串行仿真,难以模拟大规模网络。因此,设计一个可并行执行的模拟器是非常有必要的。Mubarak 等人[12]研究并仿真了多达一百万结点的Torus,实验结果也表明,大规模并行仿真对于高性能计算机系统的研究至关重要。
本文采用自行研发的模拟器对大规模拓扑结构进行仿真分析。该模拟器是基于离散事件平台开发的一款支持微片级模拟仿真平台。模拟器实现了对网络拓扑、路由建模的性能评估。该模拟器系统主要分为3部分:拓扑模块、网络接口卡模块和路由器模块。拓扑模块:是整个系统开发的设计基础,将路由器与其他结点连接起来构成互连拓扑,在模拟器中可支持多种拓扑参数配置,从而形成大规模互连网络拓扑结构。网络接口卡模块是路由器和计算结点的接口,它负责根据负载模式生成报文,注入到网络中,并负责接收从路由器转发的报文。路由器模块包括路由预计算模块和标准路由器模块,转发到标准路由器的报文先经过路由预计算模块进行与拓扑相关的静态路由计算,然后再发送到标准路由器模块。标准路由器模块是输入队列虚通道路由器模型,由输入、路由计算、分配器和输出调度4个模块组成。报文头Flit进入输入单元后会向路由计算模块提出路由计算请求,得到一组输出端口和输出虚通道(静态路由算法在路由预计算模块完成,动态路由算法在该模块完成)。头Flit完成路由计算后,多个请求进入虚通道分配器,在头Flit获得某条虚通道的使用权后,进入交叉开关分配器,请求输出端口。交叉开关分配器产生控制信号连接交叉开关的输入和输出端口,将切片发送到下游路由器。输出模块记录下游路由器的虚通道使用情况。
4 仿真与分析
本文的并行模拟仿真实验环境采用广州超算中心的“天河二号”,其系统配置CPU为Intel Xeon E5-269212C 2.200 GHz,采用 THExpress-2 高速互连的刀片结点,每个结点有24核,64 GB内存。
本节对FT、DF、SF、MF网络的网络扩展性进行理论分析,并通过自主研发模拟器对这几种拓扑的通信模式、路由算法进行模拟仿真分析。文中的符号缩写说明如表1所示。

Tabel 1 Symbols used in the paper表1 符号说明
在模拟中路由计算模块、虚通道分配模块、交叉开关模块以及传输处理模块的延迟均设为1个时钟周期。报文的默认长度是1个Flit。采用虚通道避免死锁,每个输入端口有8个VC(Virtual Channel),每个VC的缓冲区容量是300个Flit。拓扑链接提供了2种链路传输延迟配置,路由器到计算结点之间的链路延迟设为5个周期,路由器与路由器之间的链路传输延迟设为50个周期。
模拟的过程分成预热阶段、稳定阶段和排空阶段。其中预热阶段运行10 000个周期,稳定阶段运行5 000个周期,排空阶段运行5 000个周期。网络延迟数据采集的是稳定状态下的值。
4.1 网络可扩展性
本节主要分析不同拓扑的可扩展性,比较在相同路由器基数(Router Radix)情况下,网络的可扩展性。对于Torus结构可通过扩维方式构建更大规模的网络,比如,对于6D的Torus,路由器的端口数量为13,当每一维度有5个路由结点,网络规模达到1万量级,每一维度有7个路由节点,网络规模可扩展到10万量级。对于Torus结构,当维度确定时,路由器基数也随之确定,因此在本节不考虑Torus结构。其它几种拓扑结构的可扩展性如图5所示。
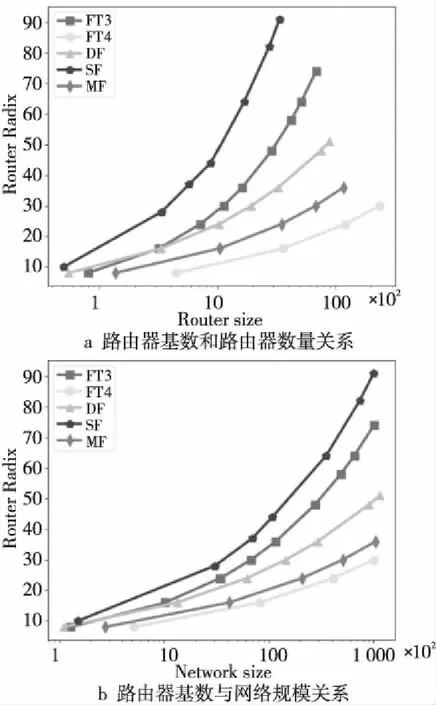
Figure 5 Router/network size vs router radix图5 路由器数量和网络规模随路由器基数变化的关系
从图5a和图5b中可以看出,FT可通过扩展层数来支持更大的网络规模,但同时会需要更多的路由器,增加了报文的传输路径。对比DF、SF和MF,在相同的路由基数条件下,MF可支持更大规模的网络。SF采用更高阶的路由器,可使用最少的路由器来支持更大的网络规模。当网络规模扩展到10万量级时,SF需要90个路由端口,3千左右路由器时,DF需要50个左右的路由端口,路由器数量比SF多26%,MF只需要36个路由端口,路由器数量比SF多33%。
4.2 Torus不同维度的性能分析
本节讨论相同规模的Tours从低维扩展到高维网络的性能。仿真参数如表2所示。

Tabel 2 Parameters in different dimensions表2 不同维度参数
Torus采用维序路由算法Dor(Dimensional order routing)。实验结果如图6所示。从表2中得出,当网络规模相同时,随着维度的增加Torus网络直径减小。从图6也可以看出,对比低维结构,高维Torus结构性能有较大的提高。随着硬件条件的提升,高性能互连网络可以采用高维Torus结构搭建互连网络。

Figure 6 Performance comparison of different dimensions图6 Torus不同维度性能对比
4.3 不同通信模式下性能对比
本节主要在模拟器中针对不同通信负载模式进行仿真,其中,Torus采用Dor路由算法,FT采用最近公共祖先路由算法NCA(Nearest Common Ancestor routing)、其它3种拓扑均采用最短路径路由算法MIN(MINimum path routing)。具体拓扑参数配置如表3所示。
表3中,uniform:随机负载,每个源结点的流量等概率地发送到任意目的结点,是网络测评中最常使用的负载模式;asymmetric:非均衡负载,把终端分为2组,组内的终端不相互发送数据,2组之间相互发送数据;randperm:随机置换负载,随机选择一个目的结点,每个源结点将其所有的流量都发送给同一个目的结点,置换负载可以测试拓扑或路由算法的承压能力。实验结果如图7所示。

Table 3 Traffic pattern configuration表3 通信模式参数配置
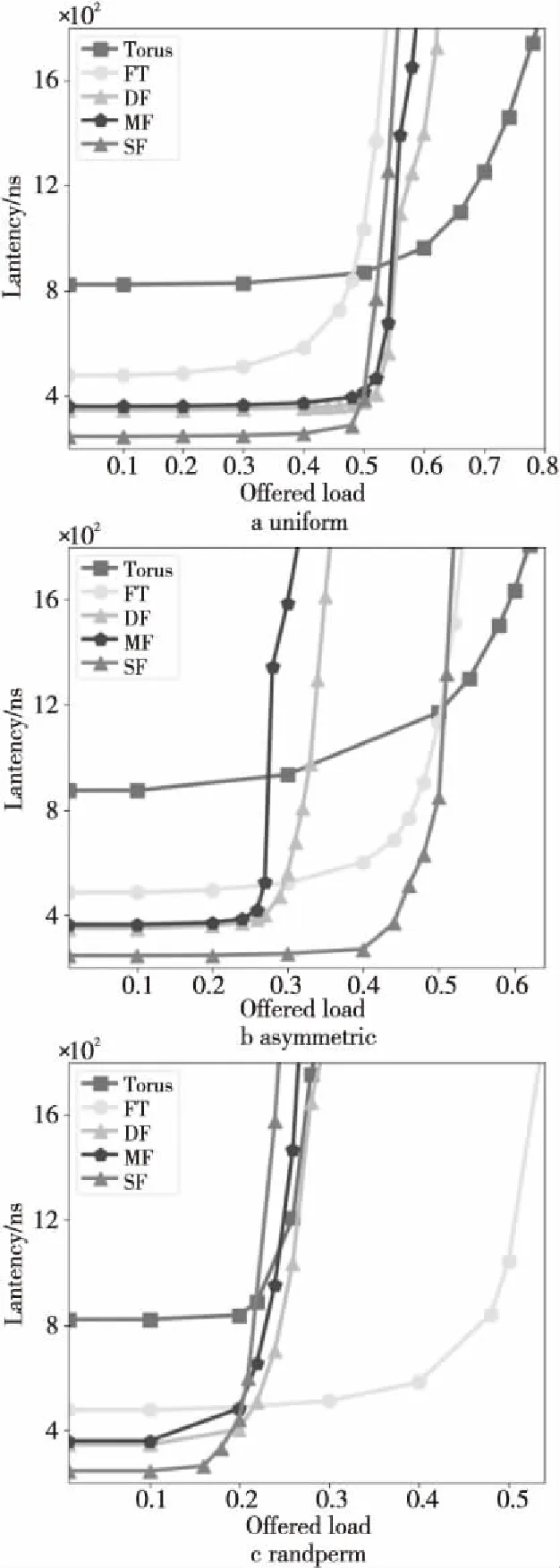
Figure 7 Lantency of different routing algorithm with different traffic patterns图7 不同通信模式下不同路由算法的网络延迟
如图7所示,随着注入率的增加,网络延迟也会增加,由于Torus的网络直径最大,对应的零延迟也最大,SF网络直径最小,对应的零延迟也最小。对于uniform和asymmetric负载模式,随着注入率的增加,Torus网络饱和速度最缓,主要原因是Torus采用高维结构。对于其他高阶网络拓扑,如图7a所示,在uniform模式下,负载均衡,DF、MF和SF网络拓扑直径较小,性能都优于FT的。如图7b所示,在asymmetric模式下,SF网络表现出更优的网络性能,主要原因在于网络平均划分为2部分的终端互发消息,使得网络中链路两等分之间的全局链路集中拥塞影响了网络的性能,而DF和MF任意2个超级节点之间都只有1条全局链路,性能较差。SF采用对称的2个子图,有更为丰富的全局链路,而对于FT有更多的路径选择,所以性能表现更优。如图7c所示,在randperm模式下,FT表现出更优的抗压能力,主要原因是每一个源结点都发给特定的目的结点,DF、MF、SF采用最短路径路由算法,负载过于集中很容易造成拥塞,而FT路由算法可选择的路径优于其他拓扑结构,使得网络中流量相对比较分散,不容易阻塞,从而表现出更优的性能。
4.4 混合通信模式路由算法性能对比
本节使用DF(4,8,4)拓扑,网络规模约0.1万,比较在混合通信模式下采用MIN路由算法和自适应路由算法UGAL(Universal Globally Adaptive Load-balance routing)的性能。混合通信模式由均匀随机负载和热点模式组成。其结果如图8所示,其中图8a表示2%的结点作为热点区域,图8b 表示选取10%结点作为热点区域。左上角图例X-Y-Z,其中X表示采用的路由算法,Y表示在生成负载时产生热点的概率,Z表示选取结点作为热点区域的比例。比如,MIN-10%-2%表示选取2%结点作为热点区域,混合负载由10%的热点通信模式和90%的均匀随机负载通信模式组成。

Figure 8 Lantency of different routing algorithm with mixed traffic pattern图8 混合通信模式下不同路由算法的网络延迟
在图8a中,当热点区域所占的比例较小时,MIN和UGAL路由算法的性能没有太大差异。在图8b中,随着热点区域的增多和通信负载注入速率的增加,UGAL路由算法凭借更优的链路选择表现出了更优的性能。
5 结束语
高性能计算机系统规模不断扩大,速度不断攀升,给高性能互连网络带来了新的挑战。本文对主流的高性能互连拓扑进行了介绍,如高维Torus结构、典型的FatTree和Dragonfly结构、由Dragonfly和Clos结构变形的MegaFly结构以及根据图论设计的SlimFly结构。对各拓扑结构的可扩展性进行了分析,通过分析得出,SlimFly可以使用更少的路由器来支持更大规模的网络规模,MegaFly可以使用更少的端口数来支持更大的网络规模。最后,通过自主设计的模拟器测试平台对不同规模不同维度Torus性能、拓扑在不同通信负载模式下延迟走势、Dragonfly混合模式下路由算法的性能进行了大规模仿真分析。仿真结果表明,Torus网络可以通过扩维来提高网络性能;SlimFly能获得更低的网络延迟;在混合通信模式下,Dragonfly的自适应路由算法能获得较好的网络性能。
