一种操作系统内存初始化优化算法
2020-11-05迟万庆
何 森,迟万庆
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
在高性能处理器芯片的研发和仿真验证过程中,为了满足处理器对访存高带宽、低延迟的要求,通常采用一种基于数据亲和性的多核处理器体系结构。吴俊杰[1]对所谓“数据亲和性”进行了相关定义,可以认为若CPU对某个数据单元更具有“亲和性”,则CPU访问这个数据单元所需要的时间周期更短。在这种体系结构下,需要对CPU进行专门设计。本文所验证的CPU就是将其中的多个核划分为若干分组(panel),每个panel又分为若干簇(cluster)。根据每个panel与整个存储空间中各个物理存储设备的亲和性(如物理链路距离)不同,将存储空间分成若干大空间,每个大空间对应一个panel,组成这个大空间的这些存储设备与对应的panel中的CPU具有最高亲和性。进一步地,又根据一个panel中各个cluster对这个大空间内各个存储设备的亲和性不同,将这个大空间划分为若干子空间,每个子空间对应一个cluster。根据CPU对存储单元“数据亲和性”的不同而将存储设备和CPU进行分组,就形成了一种NUMA结构[2,3]。当多核处理器中的CPU访问所在cluster或者panel对应的具有“亲和性”的存储设备空间时,将具有高带宽、低延迟的特点。
操作系统作为硬件资源的管理者,必须为用户提供高效的支持方式以充分利用NUMA特性。一般而言,操作系统内核与系统固件通过约定方式,如ACPI、设备树等方式获取CPU的NUMA信息。本文开展的工作是通过读取Boot-Loader传入的设备树文件,从中获取每个NUMA结点包含的CPU和物理内存等资源信息。其中,物理内存信息是通过连续物理内存地址区域和物理内存大小来描述的。设备树文件中一个典型的内存区域信息描述如下所示:
memory00{
device_type="memory";
reg=〈0x0 0x0 0x2 0x0〉;
numa-node-id=〈0x0〉
};
memory01{
device_type="memory";
reg=〈0x80 0x0 0x2 0x0〉;
numa-node-id=〈0x0〉
};
memory02{
device_type="memory";
reg=〈0x100 0x0 0x2 0x0〉;
numa-node-id=〈0x0〉
};
memory03{
device_type="memory";
reg=〈0x180 0x0 0x2 0x0〉;
numa-node-id=〈0x0〉
};
此代码段指定了一个NUMA结点中的4个内存区域的起始地址、连续长度和所属的NUMA结点。内核在读取设备树信息的同时,会根据连续内存区域的起始地址、大小以及相互之间的相交性进行一定的调整和规划,确保每个NUMA结点中的连续内存区域按照起始地址从小到大的顺序排列,确保彼此之间不存在相交的区域。
内核对内存的初始化过程是依据设备树文件中对NUMA结点的划分进行的。而一个结点的内存空间范围,就是从所含的第一个内存区域的起始地址开始,到最后一个内存区域的结束地址结束(包括内存区域之间存在的空洞)。同时,如李慧娟等[4]所指出的,内核对整个内存空间按照功能又进行了一次分区,如图1所示,内核将8 192 GB内存地址空间划分为DMA区和NORMAL区。
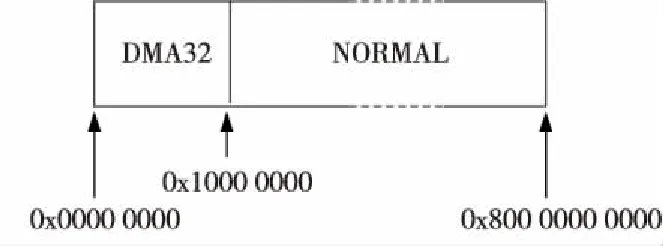
Figure 1 Functional zones of memory space 图1 内存空间功能分区
此时,以设备树文件规划的内存布局为例的一个NUMA结点内存空间布局的示意图如图2所示。

Figure 2 Layout of system memory space 图2 系统内存空间分布示意图
内核对NUMA结点内存的初始化过程可以概括为:顺序处理每个结点,并为每个NUMA结点内的物理内存页面建立内核数据结构,完成内存的初始化工作。
本文第2节揭示了操作系统内核在初始化NUMA结点内存,尤其是在虚拟仿真平台上进行验证时存在的问题,并提出可行的解决方案。第3节将给出该解决方案的算法描述,并辅以流程图加以说明。 第4节则通过实验对所提出的解决方案进行了验证。
2 问题与研究
2.1 问题的产生
高性能计算机系统通常需要大量物理内存空间来支持高性能计算。为了满足这种需求,并且兼顾未来继续扩充物理内存的可能性,在采用上述“基于数据亲和性”的NUMA架构的处理器中,通常为每个CPU核或panel划分巨大的“亲和性”地址空间。
如本文所研究的CPU硬件设计[5],将整个CPU 64位地址空间划分到多个本地目录控制部件DCU(Directory Control Unit)上,每个DCU管理一段连续的CPU地址空间,并且将每4个CPU和2个DCU组成一个panel,通过一个访存控制器MCU(Memory Control Unit)访问存储设备。而一个panel中所有DCU管理的地址空间就是这个panel的“亲和性”地址空间,即构成了panel中各个CPU所属的NUMA结点内存地址空间。这样,在实际访存时根据目标地址的相关位域将访存的最终目的分配到各个DCU管理空间中。具体如何划分CPU地址空间给各个DCU,则取决于不同的策略。如Diener等[6]提出的一种根据目标地址划分的常规策略,即依据访存目标虚拟地址的一些关键位域(如64位地址中的[42:39]位),将CPU地址空间划分为相同大小的连续地址块(512 GB),每个DCU管理一块,然后将相邻的几个DCU组成一个panel,即构成一个NUMA结点的内存地址空间。
由于目前分配到NUMA结点的实际物理内存容量不足以填满整个NUMA结点中多个DCU管理的CPU地址空间,这种CPU空间划分方式导致了在位于相同NUMA结点中、不同DCU管理空间的物理内存设备在CPU地址空间中的范围彼此之间不连续并且存在巨大空洞。例如,按上述DCU划分以及panel组织方式,假设第1个16 GB的物理存储设备位于NUMA结点0的第1个DCU管理内存空间分区(512 GB)中,则在设备树中配置其地址空间为[0x0,0x400000000),第2个16 GB存储设备位于NUMA结点0的第2个DCU管理内存空间分区(512 GB)中,则配置其地址空间为:[0x8000000000,0x8400000000)。这2个存储设备的地址空间之间就出现了多达496 GB的地址空洞,即NUMA结点0中出现了496 GB的地址空洞。此外,文献[7]也指出,由于物理实现上的原因,使用NUMA结构的CPU体系在NUMA结点中通常存在内存空洞。
上述NUMA结点中出现的巨型空洞,会导致现行Linux内核在NUMA结点内存初始化过程中花费大量的时间,造成系统启动缓慢。这种现象在虚拟仿真平台(如Vinay 等[8]使用的Synopsis公司的ZEBU仿真平台)上进行芯片验证时带来的负面影响更为严重。这是由于虚拟处理器芯片工作频率(如1 MHz)比实际芯片的频率(如1 GHz)低,因NUMA结点内存空洞引起的启动时间过长问题更加突出,给CPU的研发带来巨大的时间损耗。
2.2 问题的研究
现行Linux内核针对内存连续性情况采取了3种不同的内存管理模型,分别是平坦内存模型(FLAT Memory Mode)、非连续内存模型(Discontiguous Memory Mode)和稀疏内存模型(SPARSE Memory Mode)。其中,平坦内存模型通常用于UMA架构的处理器,所有CPU共享一段连续的公共物理内存空间。非连续内存模型针对整个内存地址空间中存在空洞,导致物理内存呈现多个大段连续区域、区域之间不连续的情形,常见于一般性NUMA架构的处理器内存模型。稀疏性内存模型则是针对热插拔内存(hotplug memory)或者内存地址空间中有效物理内存区域过于稀疏、大面积存在空洞的情况。
针对CPU研发验证过程中出现的NUMA结点内存巨大空洞所造成的Linux内核启动缓慢问题,本文首先采用了SPARSE内存模型来试图解决该问题。但是,经过实验发现,通过Linux内核配置开启SPARSE模型功能模块,对于含有巨大内存空洞的NUMA结点初始化并没有优化加速效果,在虚拟仿真平台上Linux内核启动仍然极为缓慢。
通过研究现行Linux内核发现,开启SPARSE模型功能模块后,在内核初始化过程中仅会为实际物理内存空间按1 GB大小建立映射表,便于后续初始化后内核管理物理页帧。而对于实际物理页面的初始化仍然按照非连续内存模型的情况进行处理,即按照NUMA结点的顺序,对每个NUMA结点内的所有物理页面(第一个有效物理内存区域的起始地址,到最后一个有效物理内存区域的结束地址之间)进行遍历式初始化。这个过程对有效物理页面进行初始化,建立相关的内核数据结构,对于无效的内存空洞则进行识别并跳过。
内核的非连续或稀疏型内存模型在初始化过程中采取了“穷举”遍历式方法初始化每个NUMA结点的内存,当遇到含有巨大内存空洞的NUMA结点时,内核在海量的空洞页面上进行了无意义的处理。即使这些“处理”只是识别后跳过,但因空洞页面数量巨大,以上述496 GB大小的空洞为例,会有130 023 424个4 KB大小的物理页面需要遍历处理,带来了巨大的时间损耗。
2.3 解决方案
根据前述的研究可知,目前Linux内核中非连续内存模型以及稀疏内存模型都无法解决NUMA结点内存巨型空洞导致的NUMA结点内存初始化缓慢问题,因此要解决该问题只能从Linux内核的内存初始化算法入手。Linux内核是一个完整且复杂的源码体系,一般的内核开发是基于内核提供的接口进行驱动开发、模块开发等二次开发,要实现NUMA结点初始化算法的优化,就必须直接对内核本身进行修改,并且避免影响内核的接口以及相关数据结构。
本文提出了一种针对Linux内核NUMA结点内存初始化的改进优化算法。该算法基于常规的NUMA结点内存初始化算法,在保证原有的初始化行为正常实施的情况下,分析识别并跳过内存空洞,仅针对性地处理有效的内存区域,从而避免了对空洞进行无意义的识别和处理,最终节省了大量的初始化时间,加快了内核的启动过程。
3 NUMA结点内存初始化优化算法
为了确保优化算法对Linux内核的影响最小,本文选择直接在内核源代码的相关初始化函数中进行函数逻辑和功能上的调整,来实现所需要的“空洞跳过”功能。
3.1 优化思路
在现有Linux内核中,NUMA结点内存初始化过程发生在内存区域记录完毕之后。内核遍历所有NUMA结点、并按照内核对内存实地址空间的功能分区顺序初始化每个结点。在处理每个结点内存的过程中,将该结点内存空间中与每个内存功能分区相交的空间区域进行遍历初始化,即逐一初始化每个有效/空洞物理内存页。通过这个过程分析可以看到,现有内核对结点内存的初始化,实际上是对结点中所有有效物理内存页以及空洞所在内存页进行逐一遍历并进行相关初始化工作。
本文对上述流程进行优化,避免内核对NUMA结点内存中的空洞做出无意义的识别和处理。优化的原则是在不修改Linux内核实质性操作的基础上,对结点内存初始化过程加以优化和提速。优化算法的基本原理和依据如下所示:
(1)设备树中规划的每个内存区域都是连续的,并且是一个左闭右开区间,描述的是一段有效物理内存区域,并且注明了所属的NUMA结点ID号;
(2)经过内核读取、处理后,不论是在整体上或是在所属的NUMA结点中,保存在内核中的各个内存区域之间具有逻辑顺序,即第i号内存区域的起始地址必然小于第i+1号内存区域起始地址,且第i号内存区域的空间范围必然与第i+1号内存区域空间范围不相交;
(3)依照上述内存区域的排列顺序,对每个结点内的所有内存区域进行针对性处理,即可处理完结点中的所有有效物理内存页面。
3.2 算法描述
根据上述原理和依据,优化算法流程图如图3所示。
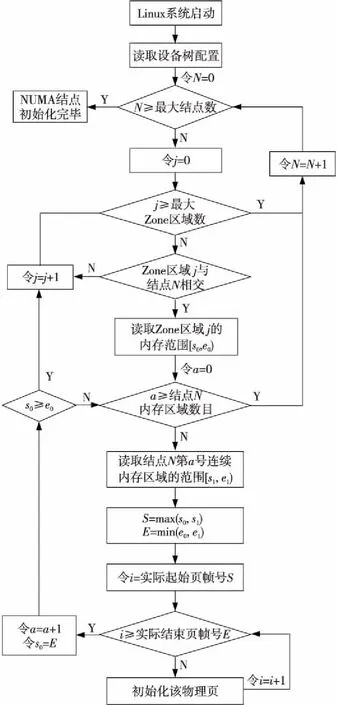
Figure 3 Flow chart of improved algorithm 图3 优化算法流程图
算法步骤如下所示:
(1)内核读取设备树信息,并建立相关数据结构,包括NUMA结点、连续内存区域等对象。
(2)内核针对每个内存结点,对比其内存空间范围与内存实地址空间内所有功能分区的相交性,记录所有产生的相交区域Zone,保存在内核结点的数据结构中。
(3)针对步骤(2)中记录的、属于该结点的每个相交区域(Zone)的内存进行有效化处理:
① 顺序遍历设备树中记录的、属于该NUMA结点所有连续内存区域;
② 对每个连续内存区域求取与当前处理的Zone的交集A;
③ 若A存在且不为空,则集合A所记录的内存空间都是有效物理内存,直接进行初始化处理。
(4)继续处理后续结点。
这里以图1和图2所示的内存空间为例说明上述算法流程。图2中第0个NUMA结点与图1所示的系统内存空间功能分区相交,得到Zone DMA32和Zone Normal 2个相交区域。当按上述算法步骤(2)初始化结点0时,会先后处理这2个相交区域。当按上述算法的步骤(3)处理相交区域Zone DMA32时,只会找到连续内存区域Memory00,并且只初始化Memory00的[0,0x1000 0000)范围。然后按算法步骤(3)处理相交区域Zone Normal时,则会先后找到连续内存区域Memory00~Memory03,并逐个初始化它们位于相交区域Zone Normal中的物理页面。
3.3 算法核心实现
按照算法原理和流程图,本文在Linux内核NUMA结点内存初始化等部分中实现了所提算法,其中算法核心部分如下所示:
void_meminit memmap_init_zone(unsigned longsize,intnid, unsigned longzone, unsigned longstart_pfn, enum memmap_contextcontext, struct vmem_altmap*altmap)
{
unsigned longend_pfn=start_pfn+size;
unsigned longregion_start,region_end;
unsigned longreal_start,real_end;
inti;
pg_data_t*pgdat=NODE_DATA(nid);
unsigned longpfn;
unsigned longnr_initialised=0;
struct page*page;
#ifdefCONFIG_HAVE_MEMBLOCK_NODE_MAP struct memblock_region*r=NULL,*tmp;
#endif
real_start=start_pfn,real_end=end_pfn;
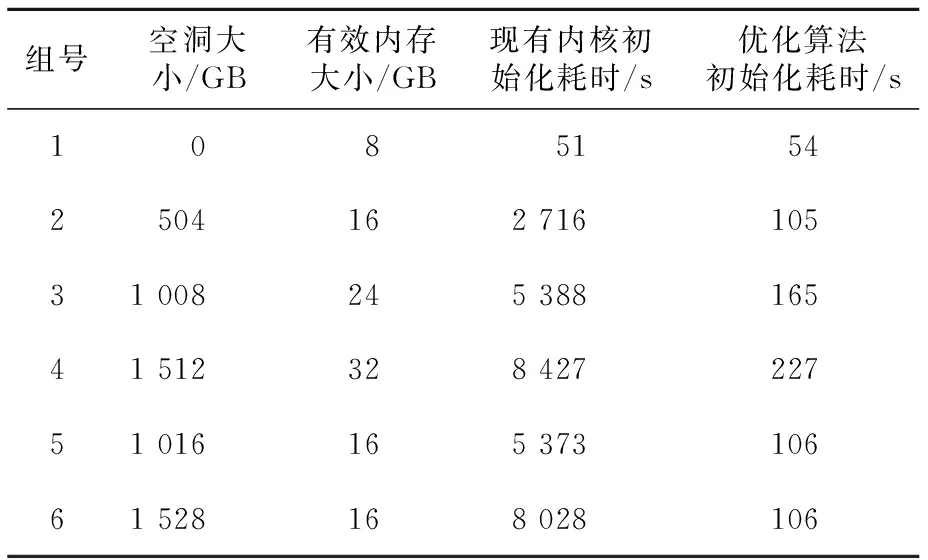
if(highest_memmap_pfn highest_memmap_pfn=end_pfn-1; if(altmap&&start_pfn==altmap→base_pfn) start_pfn+=altmap→reserve; #ifdefCONFIG_SKIP_NUMA_HOLES for_each_mem_pfn_range(i,nid,®ion_start,®ion_end,NULL) { if(real_start==end_pfn) break; if(region_end<=real_start) continue; real_start=max(real_start,region_start); real_end=min(end_pfn,region_end); #else real_start=start_pfn; real_end=end_pfn; #endif for(pfn=real_start,pfn { ⋮ } #ifdefCONFIG_SKIP_NUMA_HOLES real_start=real_end; } #endif } 为验证本文所提出的优化算法,在如下环境中进行实验:将按上述解决方案修改好的内核源代码进行编译后,在ZEBU虚拟仿真平台上搭建的16核CPU、主频1 446 KHz的虚拟机器上运行该内核。通过修改设备树文件,测试在不同内存空间布局下对NUMA结点初始化的速度。通常情况下,操作系统是要初始化多个NUMA结点(以本实验为例,结点数目为1~8个)的内存,但实际上根据本文第2节描述的目标CPU的特性,本实验每个NUMA结点的内存大小、布局特性相同,结点内部空洞也类似,因此,在实际的验证工作中针对一个NUMA结点内存的初始化过程进行测试对比,即可验证本文优化算法对所有NUMA结点初始化效率的增益影响。 实验设置如下几组内存布局: (1)1个NUMA结点,1个8 GB的连续内存区域,无空洞; (2)1个NUMA结点,2个8 GB连续内存区域,如图2中由Memory00+Memory01组成的内存布局,存在504 GB大小的空洞; (3)1个NUMA结点,3个8 GB连续内存区域,如图2中由Memory00+Memory01+Memory02组成的内存布局,存在1 008 GB大小的空洞; (4)1个NUMA结点,4个8 GB连续内存区域,如图2中由Memory00+Memory01+Memory02+Memory03组成的内存布局,存在1 512 GB大小的空洞; (5)1个NUMA结点,2个8 GB连续内存区域,如图2中由Memory00+Memory02组成的内存布局,存在1 016 GB大小的空洞; (6)1个NUMA结点,2个8 GB连续内存区域,如图2中由Memory00+Memory03组成的内存布局,存在1 528 GB大小的空洞。 在上述实验组中,组(2)、组(5)和组(6)用于测试在相同有效内存情况下,随着空洞大小的增加,优化算法和现有Linux内核初始化算法的效率差异情况。组(3)和组(5)、组(4)和组(6)测试在内存空洞基本相同的情况下,有效内存的增加对优化算法和现有Linux内核初始化算法的耗时影响情况。实验结果如表1所示。 Table 1 Analysis of time of NUMA node initialization 表1 NUMA结点初始化用时分析 实验结果分析如下: (1)在相同有效内存的情况下,随着空洞的不断增大,现有Linux内核的初始化算法耗时显著增加,而本文优化算法对结点初始化的耗时则不受内存空洞大小的影响; (2)在空洞大小基本相等的情况下,有效内存的增加对现有Linux内核初始化和本文优化算法初始化的耗时影响基本相同,即本文优化算法对于有效内存的初始化效率与现有Linux内核保持一致,不会对原有的初始化算法带来负面影响。 本文讨论了Linux内核由于可能存在的物理内存巨大空洞而导致的内核启动缓慢问题。这种内存空洞可能是由于硬件设计如CPU的“数据亲和性”模型带来的,也可能是由其他因素引起的。本文针对该问题提出了一种解决方案,该方案对现有Linux内核中NUMA结点初始化算法进行优化,在不影响对有效物理内存正确初始化的前提下,能够有效识别并跳过内存空间中的空洞,避免了对空洞内物理页面的无意义遍历,实现了快速高效的结点初始化,加快了内核启动过程,尤其是在此类CPU的仿真验证阶段,可以带来明显的效率提升。 需要指出的是,文中所研究的系统物理内存空洞是由于CPU基于数据亲和性模型建立的NUMA体系结构引起的,实际情况中可能存在因其他原因导致的物理内存空洞现象。但是,本文所提算法并不区分引起内存空洞的原因,而是直接针对初始化过程中的内存空洞这一现象进行优化。4 实验结果
5 结束语
