BeeGFS并行文件系统性能优化技术研究
2020-11-05宋振龙李小芳谢徐超魏登萍王睿伯
宋振龙,李小芳,李 琼,谢徐超,魏登萍,董 勇,王睿伯
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
超级计算机的发展已进入E级时代。E级计算机的存储系统总空间将达到500~3 000 PB,峰值聚合I/O带宽将达到100~200 TB/s,持续I/O带宽也将超过10 TB/s,同时支持数亿并发度的I/O需求。大数据和人工智能时代,大数据和人工智能应用程序开始在高性能计算HPC(High Performance Computing)系统上运行。新兴的深度学习应用程序具有批量小文件随机输入特点,导致HPC存储系统的I/O模式更趋复杂,I/O瓶颈问题日益突出。
超级计算机的存储系统和I/O性能越来越引起重视,2017年世界超算大会首次发布了对高性能存储系统进行排名的IO500排行榜。为了综合反映存储系统I/O性能,IO500测试分为2部分,一部分采用IOR程序测试I/O带宽,另一部分采用mdtest程序和find等命令进行元数据测试。测试又分为easy和hard 2种模式,其中easy模式观察存储系统最容易满足的I/O模式,hard模式则用来反映当前存储系统最不适应的I/O模式。IO500的推出倡导业界更加关注存储系统性能,基于IO500的I/O性能已成为衡量超级计算机性能的重要指标。
近两年IO500排名前10的系统中,Lustre、BeeGFS 和GPFS(General Paralle File System) 3种并行文件系统占有明显的优势。Lustre文件系统采用基于对象存储的集中共享式并行存储架构,通过客户端Cache和大数据块传输协议提高文件访问带宽,在HPC领域应用最为广泛。IBM公司研发的GPFS文件系统,广泛应用于IBM公司研发的超级计算机中。新兴的BeeGFS文件系统由欧洲的E级计算项目DEEP-ER研发,提供开放源代码和免费软件,在HPC领域具有良好的应用前景。业界对Lustre和GPFS等不同的并行文件系统进行了长期深入的研究,但对新兴的BeeGFS的研究却很少。
本文对BeeGFS的 I/O堆栈各个层次进行了性能评测、性能损耗分析,分析确定了影响性能的关键因素,并从多个方面探索并行文件系统性能优化的关键技术,包括元数据管理模块优化设计、并行I/O处理模型优化设计和网络通信性能优化等关键技术。
2 相关工作与挑战
2.1 相关工作
为HPC系统提供可靠、高效且易于使用的存储和文件系统是当前构建高性能计算机系统面临的主要问题之一,因为各种各样的科学应用程序都会生成和分析大量数据。文件系统提供了到基础存储设备的接口,并将标识符(例如文件名)链接到存储硬件的相应物理地址。在HPC系统中,通过部署并行分布式文件系统可以将数据分布在众多存储设备上,并结合特殊功能以提高吞吐量和系统容量。随着存储系统数据量的迅速增加,HPC系统需要更复杂、更高效的数据管理方法来处理大量信息。同时,如何利用功能更强大的存储和网络技术,如高速存储介质、100 Gbps高速远程直接数据读取RDMA(Remote Direct Memory Access)网络,也对HPC存储系统的构建提出了挑战。
在并行文件系统研究方面,基于闪存固态盘SSD(Solid State Drive)[1 - 5]和非易失性存储器NVM(Non-Volatile Memory)[6 - 11]优化设计的并行文件系统软件尝试利用存储硬件功能来减少软件开销,但系统整体性能仍不理想。
在文件系统的元数据组件上,现有工作设计了利用类似LevelDB的Key-Value来实现单机的文件系统,如TableFS[12]利用LevelDB实现了用户空间文件系统,但TableFS只是简单地介绍了FS层次结构到键值KV(Key Value)存储的映射,没有解决重命名以及文档夹移动等问题。BetrFS[13]则将类似的思路搬到了内核空间,研究并设计了重命名、移动文档夹等操作的实现。IndexFS则是将环境放到了分布式文件系统下面,主要是用KVS存储分布式文件系统的元数据,但IndexFS仍未发挥KVS的性能,比如将一个文件的文件元数据全部存储在单个值中,仅修改一部分值时,必须重置键值存储中的所有值,这会导致不必要的(反序列化)开销,造成性能降低[14]。Linux 5.1采用了由Jens Axboe开发的一个新的异步I/O框架io_uring[15]及实现技术,有效解决了Linux内核中原生AIO低效的问题,更适合高性能NVMe SSD,在部分场景性能高于Intel 的SPDK(Storage Performance Development Kit)的性能。

Table 1 Key-value used by/dir/file表1 获取/dir/file过程中的Key和Value

Table 2 System performance of original BeeGFS表2 改进前的BeeGFS性能测试结果

Table 3 System performance of optimized BeeGFS表3 改进后的BeeGFS性能

Table 4 System performance comparison表4 改进前后的性能对比
LocoFS[16]可以看作是从IndexFS改进而来的一个架构。架构上一个主要的变化就是目录的元数据和文档的元数据分开保存,但目录元数据结点存在扩展性问题,同时这类方案还面临rename效率问题。Intel的分布式异步对象存储DAOS(Distributed Asynchronous Object Storage)[17]采用了SPDK Bulk数据并且在用户空间中完全绕开操作系统。I/O操作绕过Linux内核,从而节省了时间。而元数据构建在Optane DIMM非易失内存上,通过PMDK(Persistent Memory Development Kit)提供低延时的元数据索引与查询。在Lustre 2.10.X中实现了多轨MR(Multi-Rail)[18]功能,它允许结点上的多个相同类型的接口在同一个网络(例如tcp0、o2ib0等)下分组一起使用。
当前最流行和广泛使用的并行分布式文件系统包括Lustre、GPFS、OrangeFS、Ceph和GlusterFS,主要是面向带宽型业务和磁盘介质,存在性能缺陷。Lustre文件系统的主要缺点是其使用串行元数据访问模型,使得超量的并发文件操作非常慢,即便新版本提供分布式命名空间模型仍未完全解决并发文件操作在所有应用场景中存在的问题。Ceph以对象存储为核心,复杂的软件栈影响性能。GlusterFS在写入较小时存在严重问题,包括写小文件和小写大文件,另外GlusterFS在递归操作(ls,du,find,grep等)上非常慢,使得它几乎无法用于大型文件系统上的交互操作。当前这些并行分布式文件系统已很难满足未来E级计算高性能存储的需求。
近几年BeeGFS尝试解决性能问题,BeeGFS的优点是可以分离元数据,提供更快的元数据访问,同时还能够以简化的方式跨元数据结点分配每个目录和子目录的元数据操作。与GPFS一样,BeeGFS可以根据需要添加更多元数据目标(服务器),提供了很好的系统扩展性,且设置比Lustre MDS(Meta Data Server)更简单。另外,BeeGFS能够使用内置队列来线程化元数据/对象请求服务器,并能够根据需要指定在每个元数据/对象服务器上产生多少线程。当对文件系统上的小文件进行数百万次的超量请求时,可以避免串行请求瓶颈。
图1为BeeGFS的系统架构,包含元数据服务器MDS、对象存储服务器OSS (Object Storage Server)、客户端和网络模块 4个重要组件。当前,尽管BeeGFS在小块I/O以及元数据访问方面具有优势,但实际测试表明BeeGFS仍存在性能瓶颈,有待进一步深入改进优化性能。

Figure 1 System architecture of BeeGFS图1 BeeGFS并行分布式文件系统架构
2.2 文件系统读写瓶颈
BeeGFS是一款并行分布式文件系统,其核心组件MDS和OSS均是以结点内的本地文件系统来承载元数据、数据的存储。针对BeeGFS高效组织管理本地数据是BeeGFS性能优化的关键点之一。
通过对NVMe SSD裸设备和文件的对比测试,我们发现如下规律:
(1) 单盘SSD的带宽性能与单盘上的文件系统的性能相当;
(2) 单盘文件系统XFS 的IOPS是SSD性能的38%(读取)和36%(写入);
(3) 10个盘文件系统(XFS)的带宽是SSD性能的77%(读取)和93%(写入);
(4) 10个盘文件系统(XFS)的IOPS是SSD性能的16%(读取)和31%(写入)。
从上面的数据可以看出,XFS在带宽上相对SSD裸设备损耗较少,而IOPS只有裸盘SSD的31%以下,IOPS性能损失巨大,如何针对闪存构建高IOPS、高带宽文件系统是性能提升的一个研究方向,如果针对BeeGFS的数据存储格式进一步构建私有文件系统,则能进一步提升性能。
为了分析并行文件系统BeeGFS对性能的影响,本文构建了5个客户端同时访问1个存储端的环境,客户端与存储端均通过单个Intel公司的Omni-Path 100 Gbps网卡进行通信。测试结果表明,单个客户端带宽最高为2.8 GB/s,不到物理带宽11 GB/s的25%,一方面BeeGFS自身网络处理影响了带宽,另一方面单网卡限制了带宽;并行文件系统的读写IOPS仅为本地文件系统的18.6%(读取)和18%(写入)。底层SSD繁忙度只有20%。而在BeeGFS的loop模式下,也就是数据并未写入或未从本地文件系统读取,loop模式与本地文件系统的带宽相当,但此时的IOPS仅为本地文件系统的48%(读取)和42%(写入)。
总之,当BeeGFS处于高负载状态时,本地文件系统的压力依然不足,底层SSD的利用率也偏低,需要对其进行改进优化。
2.3 元数据瓶颈
分布式文件系统中主要有4种元数据管理方案:单个元数据服务器(单MDS)方案(例如HDFS)、具有基于哈希分布的多元数据服务器方案(multi-MDS)(例如Gluster[19])、基于目录的方案(例如CephFS[20])和基于条带的方案(例如Lustre DNE,Giga+[21])。
与基于目录的方案相比,基于散列和基于条带的方案具有更好的可伸缩性,但牺牲了单个结点上的本地性。原因之一是,即使这些请求位于同一服务器中,多MDS方案也会向MDS发出多个请求,那么文件系统中的递归操作(ls,du,find,grep等)非常慢,严重情况下将使得它几乎无法用于大型文件系统上的交互操作。
另外,在分布式文件系统中,经常出现热点数据,主要包括:(1)文件系统中的某个目录是大目录,该目录下有几万、几十万甚至上百万个文件。(2)文件系统同时出现多个热点目录和热点文件,在该目录下频繁地进行文件和子目录的创建、删除、修改、查找等操作。当文件系统的这些热点数据同时出现在某个服务器上时,将会导致该服务器负荷非常重,而其他服务器负荷很轻,从而出现严重的负载不均,大幅降低整个文件系统的总体性能。
针对BeeGFS进行元数据方面的性能测试与分析,部署5个Client端,分别测试4个和5个MDS组成的元数据集群,文件创建、查看文件状态和文件删除的性能测试结果如图2所示,其中横坐标轴表示每个Client的进程数,纵坐标轴表示IOPS。

Figure 2 Metadata performance of BeeGFS图2 BeeGFS元数据性能测试
测试结果表明,文件创建性能最高为98 341 IOPS,查看文件状态最大性能为384 449 IOPS,文件删除最高性能为20 510 IOPS,根据BeeGFS的元数据分布方式:目录随机分布到元数据结点,文件仍然由父目录所在的服务器处理,这些元数据操作大部分发生在单结点中,是利用本地文件系统的文件attr属性来存储约128字节的元数据。而在键值存储中,比如著名的RocksDB,在单结点中对100万条记录对(Key:16 Bytes,Value:100 Bytes)进行处理,其性能为随机写631 222 IOPS,随机读2 577 505 IOPS,而在pmemkv这类键值存储中,性能更高。
对比KV存储的随机性能,分布式文件系统BeeGFS的元数据操作性能不到KV存储性能的16%,因此BeeGFS利用本地文件系统的文件属性来存储元数据,存在较大的性能瓶颈。
3 BeeGFS的优化
通过测试和分析,本文认为BeeGFS当前的主要性能瓶颈包括:
(1)BeeGFS利用本地文件系统的文件属性来存储元数据,存在较大的性能瓶颈,需要优化元数据IOPS。
(2)本地文件系统的IOPS能力不足,需要BeeGFS的OSS组件提升文件并行读写效率,需要优化I/O处理流程。
(3)大量的消息传递和小块数据包导致网络性能瓶颈,远没有使高速网络的带宽饱和,还需要针对网络进行优化。
针对上述BeeGFS性能瓶颈,本文基于KV实现元数据管理,以优化元数据的性能,更适配高速非易失存储介质;重新设计了数据I/O处理模型,提升了数据处理并发度;借鉴多轨机制优化通信网络,支持多网卡以提升通信带宽。
3.1 KV元数据
对于BeeGFS的一个元数据结点而言:目录和文件的创建、删除、stat等操作基于本地文件系统,效率低下,原因一是遵循POSIX语义而频繁进行文件open、close等系统调用,元数据存取进行getattr、setattr系统调用,频繁的用户态、内核态切换导致性能低下;二是传统I/O软件栈和块设备文件系统产生的系统开销,块设备文件系统(如EXT4)需要经过诸多针对块设备的软件层次,例如I/O调度层、通用块层和块设备驱动层,而且文件系统自身定位数据复杂,诸多软件层次会造成数据在各级缓冲区中的多次拷贝,造成大量额外的系统管理开销及性能损失,特别是在新型存储介质上,比如NVDIMM,不能发挥非易失性内存的性能。
当前有一些解决方案引入KV store来构建文件系统[23-26]。它们不仅向用户导出简单的接口(即get和put),而且在存储中使用有效的数据组织(例如日志结构化的合并树[27])。由于数据值是独立的并且以这种简单的方式进行组织,因此KV存储使小对象能够被有效地访问并提供出色的可伸缩性,这使其成为了文件系统元数据服务器最有前景的技术。在小型对象的文件系统元数据(例如inode和dirent)中已经利用了KV存储的优点[23,24]。
本文采用键值KV存储来存取元数据,并采用策略性的目录、文件元数据放置方法,有如下3点:
(1)可配置目录分布。默认情况下,目录将随机分布到元数据结点。支持用户在创建目录前设置规则策略。
(2)充分利用本地性,文件仍然由父目录所在的元数据服务器处理。
(3)在元数据服务器内部,采用键值存储KV替换低效的本地文件系统。
对比基于散列的元数据分布方式,散列方式虽可以有效地利用键值访问性能,但是目录列表、重命名目录等操作引发了这种基于散列设计的性能问题。本文选择RocksDB键值存储,因为RocksDB可以将磁盘写入与prefix查找和范围扫描结合在一起,同时可以更好地发挥高速存储介质的性能。
文件系统树表示为索引结点和边缘的图。索引结点包含有关文件或目录的元数据,并由64位ID键索引。边缘在文件系统树中定义父子关系。key是父级的64位inode ID,与孩子的名称串联在一起,而值是孩子的inode ID。 这种表示方式允许高效地创建、删除和重命名。根据上述规则,基于 KV 元数据结构获取/dir/file路径,解析过程如表1和图3所示。

Figure 3 Path to /dir/file based on KV metadata图3 基于KV元数据结构获取/dir/file
算法1基于KV元数据结构获取/dir/file
输入:/dir/file文件路径。
输出:/dir/file文件内容。
步骤1root 的 inode ID为1,那么系统将 dir对象和其父对象的 inode ID进行组合,得到一个 key 〈1,dir〉。
步骤2系统根据步骤1得到的 key 〈1,dir〉,获取dir 对象的 inode ID。从图3可以看出,dir 对象对应的 inode ID为2,对应图3的步骤i。
步骤3系统需要得到 file 对象的 inode ID,同样也是构造一个key,得到 〈2,file〉,从而确定file 对象的 inode ID,这里为 3,对应图3的步骤ii。
步骤4系统直接根据 inode ID为 3,读取file 的内容,对应图中的步骤iii。
3.2 多轨网络通信机制
在高性能计算系统中,网络通常为高速以太网、IB(InfiniBand)、Omni-Path等,由于结点间大量的消息传递,通常采用RDMA技术实现零拷贝通信。对于分布式并行文件系统,同样如此,通过RMDA启动多个数据服务器的读写操作,这使得客户端能够以接近RDMA峰值带宽的速率访问数据。因此,提升网络带宽有利于提升文件系统的性能,但是,添加更快的接口意味着要替换大部分或全部网络。本文采用多轨网络通信机制向服务器添加更多的网络接口来增加带宽和IOPS。
BeeGFS支持TCP/IP网络,并基于OFED(Open Fabrics Enterprise Distribution) ibverbs API实现了对Infiniband、RoCE (RDMA over Converged Ethernet)和Omni-Path的RDMA协议的支持。但是, BeeGFS仅支持单网卡的并发数据传输和网络通信,从测试数据来看,这严重限制了系统的网络带宽。本文通过增加网络接口卡和修改客户端模块,支持客户端到元数据服务器、对象存储服务器的多网卡并行数据传输和多轨通信。同时,通过设置配置文件,灵活实现了使用多个网络接口连接到同一个网络、使用多个网络接口连接到多个网络、接口可以同时使用3种功能。
3.3 异步I/O模型
在BeeGFS系统中,OSS服务构建在用户态上,通过多线程策略来提升I/O并发度,但这些线程的处理步骤比较冗长,而且由于每个阶段的结果与下一阶段的执行有关系,效率仍然低下,并未实现流水线操作。BeeGFS的OSS对文件数据的I/O处理流程如图4所示。对于大量的小文件I/O,消息传递会创建许多小的请求,每个工作线程的处理步骤很多,同步处理这些请求资源开销很大。

Figure 4 Original I/O flow in BeeGFS OSS图4 BeeGFS原有OSS文件I/O处理流程
一种优化思路是将任务的处理分解为若干个处理阶段,将其中缓慢的读写文件系统步骤通过异步I/O分离出来,上一个阶段任务的结果交给下一个阶段线程来处理,这样每个线程的处理是并行的,可以充分利用时间重叠和分时共享资源,提高并行处理效率。优化后的I/O处理流程如图5所示。优化I/O处理模型摒弃了传统的aio调用,采用了io_uring全新的syscall和全新的异步async API接口来对接高性能NVMe SSD,以获得更高的IOPS性能和更好的兼容性。高吞吐异步I/O模型如图6所示。可以进一步地分离读写I/O请求,构建不同的sq_ring/cq_ring对来提升整体性能。同时针对多核CPU对线程进行分组绑核,减小在不同的核上切换调度造成的开销,进而提升线程的运行效率。

Figure 5 Optimized I/O flow in BeeGFS OSS图5 OSS存储服务器I/O处理优化流程
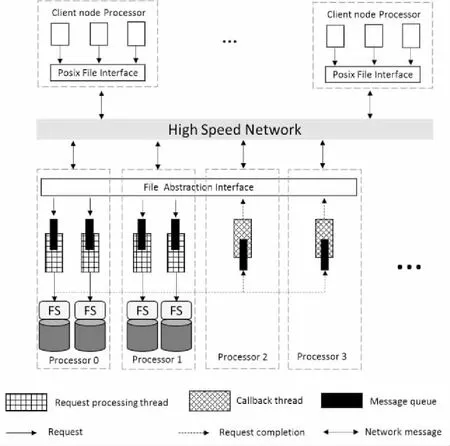
Figure 6 Asynchronous I/O parallel processing model图6 异步I/O并行处理模型
4 实验与评估
本文基于验证系统对BeeGFS并行文件系统进行了分析评测,采用IO500-dev测试项对优化前后的I/O性能进行了对比测试。BeeGFS文件系统开发验证系统结构如图7所示,由10个计算结点和42个存储结点组成,同一存储结点同时承担元数据服务器(MDS)与对象存储服务器(OSS)角色,通过100 Gbps Omni-Path网络进行集群系统互连与数据传输,通过以太网络对集群进行监控管理。
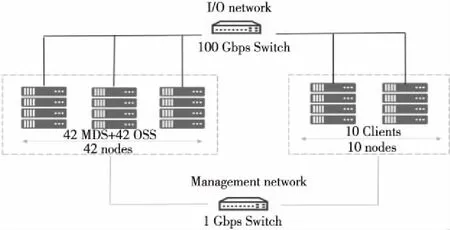
Figure 7 Networking configuration of BeeGFS图7 BeeGFS组网图
存储服务器配置:2个Intel Xeon Gold 6134 CPU,16核,主频 3.20 GHz,396 GB DDR4内存,配置12块紫光NVMe SSD硬盘,单盘容量1.6 TB,单盘读写带宽可分别达到2.8 GB/s和1.4 GB/s。操作系统为CentOS Linux 7.7,内核版本为3.10.0- 1062.4.3.el7。
在上述开发验证系统中,采用IO500-dev测试项对改进前后的BeeGFS并行文件系统进行了分析评测,测试结果分别如表2和表3所示。其中测试负载:pre_node_process=64,mdtest_create_file_nun=500000,mdtest_numtarget=1,ior_numtarget=464。
通过分析发现,本文改进方法可以有效提升BeeGFS的性能。在IOPS的测试方面,find等操作的IOPS性能提升122%,这主要是KV 元数据的改进带来的效果,而delete 和read 的性能提升主要由异步I/O的设计优化提供,因为这些操作还需要访问文件数据,异步I/O的优化可以提升
此操作。但是,easy_stat和hard_stat性能稍有下降,在3%以内,可能是测试差异造成的,也可能是KV元数据的设计中路径寻找开销过大造成的,后期将会继续进行相关的研究。另外,在带宽方面引入的多轨的设计,使得文件系统的带宽提升非常明显,如表4所示分别提升了55%,3 600%,41%和126%。
5 结束语
新兴的BeeGFS并行文件系统在HPC领域具有良好的应用前景。本文对BeeGFS各个I/O栈层次进行性能评测和性能损耗分析,确定影响BeeGFS系统性能的关键因素,并从多方面探索并行文件系统性能优化的关键技术。设计实现了基于键值存储的元数据管理模块以优化元数据IOPS,基于异步I/O和多线程技术的并行I/O处理模型以提升I/O处理并发度,并采用多轨通信机制以提高网络通信带宽。构建了IO500性能评测环境,在相同的配置环境下,I/O带宽和元数据2类基准测试结果表明,I/O带宽由25 GB/s提升为93 GB/s,提高了3.7倍;IOPS由994.4 KIOPS提升为1 190.2 KIOPS,总分由157.97分提升为332.6分,改进后的并行文件系统在元数据、数据读写性能方面有大幅提升,IO500测分是原有系统的2倍以上。
下一步工作将探索如何进一步提升BeeGFS并行文件系统性能,一方面构建新的本地数据存储引擎,取代通用的本地XFS文件系统;另一方面将本地文件系统放入高速存储层,实现比分层存储管理更好的集成管理。
