天河超级计算机上超大规模高精度计算流体力学并行计算研究进展
2020-11-05徐传福车永刚李大力王勇献王正华
徐传福,车永刚,李大力,王勇献,王正华
(1.国防科技大学高性能计算国家重点实验室,湖南 长沙 410073;2.国防科技大学计算机学院,湖南 长沙 410073;3.国防科技大学气象海洋学院,湖南 长沙 410073)
1 引言
计算流体力学CFD(Computational Fluid Dynamics)通过数值求解各种流体动力学控制方程,获取各种条件下的流动数据和作用在绕流物体上的力、力矩和热量等,从而达到研究各种流动现象和规律的目的。CFD是涉及流体力学、计算机科学与技术、计算数学等多个专业的交叉研究领域。随着高性能计算机的飞速发展,CFD研究和工程实践都取得了很大进步,20世纪90年代以来,基于雷诺平均Navier-Stokes方程求解的CFD技术已经广泛应用于航空、航天、航海、能源动力、环境、机械装备等诸多国民经济和国防安全领域,取得了很好的应用效果。在航空航天领域,CFD已逐渐成为与理论分析、风洞实验并列的流体力学3大主要方法之一。美国国家航天局(NASA)预测,21世纪,高效能计算机和CFD技术的进一步结合将给各类航空航天飞行器的气动设计带来一场革命[1]。
高性能计算技术的迅猛发展为大规模复杂CFD应用提供了重要支撑,当前,CFD已经成为高性能计算机上最重要的应用之一。随着应用问题复杂度的增加,CFD要求的几何外形、数值方法、物理化学模型等也日益复杂、精细,对大规模计算提出了更高要求。CFD对大规模计算的需求可以从能力计算(Capability Computing)和容量计算(Capacity Computing)2方面概括。容量计算指的是利用超级计算机同时完成大批量生产性业务,在CFD中通常用于复杂工程问题的设计与优化,例如飞行器全包线数据库生产等。有学者在1997年估计,商业飞机巡航一秒钟的计算,用每秒万亿次计算机需要数千年,高保真度全包线气动数据库的生产被认为是CFD一个长期的重大挑战问题[2,3]。能力计算通常指的是利用超级计算机全系统计算能力求解单个大型任务,在CFD中通常用于简单外形、复杂流动问题的基础研究,例如采用直接数值模拟开展湍流流动机理研究等。据美国波音公司Tinoco博士2009年估计,以当时高性能计算机的发展速度,直到2080年左右才可能进行民航客机全机的DNS模拟;即便是进行大涡模拟也要等到2045年左右[4]。
CFD巨大的计算量对于超级计算机研制和超大规模并行计算研究提出了迫切需求,异构并行架构是当前构建超大规模高性能计算机系统的重要技术途径之一[5]。异构超级计算机主要包括异构加速器和异构众核2种实现方式。例如,我国的天河系列超级计算机采用了异构加速器,其中天河一号的加速器为通用GPU(Graphics Processing Unit),而天河二号的加速器为Intel集成众核MIC(Many Integrated Cores)(升级后的天河二号采用了国产加速器Matrix2000);神威太湖之光则采用了“申威26010”异构众核处理器,每个处理器包括4个主计算核,每个主计算核配有一个8×8的计算阵列(64个从计算核)。在2020年6月发布的世界超级计算机排行榜(TOP500)中,排名前10的超级计算机有8台是异构超级计算机。异构超级计算机具有明显的性能价格比、性能功耗比等优势,但异构超级计算机具有异构的计算、存储和通信能力以及编程环境,极大增加了高效、大规模CFD应用软件开发的难度。在CFD应用领域,传统CPU平台并行计算主要采用分区并行方法,每个分区独立进行求解,利用消息传递通信实现分区之间的任务并行以及共享存储实现单个分区内部的线程并行[6 - 9]。异构超级计算机具有多层次、多粒度的异构并行性,应用并行性开发需要同时利用消息传递任务级并行、计算结点内CPU与加速器之间的协同并行、CPU/加速器上的共享存储线程级并行和CPU/加速器上的向量化指令级并行,需要针对异构并行体系结构特征,设计多层次可扩展并行算法,才能实现CFD应用、算法与并行体系结构的“最佳适配”,充分挖掘超高性能计算机潜力。
国防科技大学不仅是我国高性能计算机系统研制的基地,也是我国高性能计算应用软件研发的基地。长期以来,国防科技大学CFD应用软件团队依托天河/银河系列超级计算机开展了超大规模复杂CFD并行计算和性能优化研究,突破了异构协同并行计算等关键技术,实现了HPC与CFD的深度融合,有力支撑了我国几套重要的In-house CFD应用软件在天河/银河系列超级计算机上的大规模并行计算。本文归纳总结了作者团队基于自主高精度CFD软件,面向航空航天气动数值模拟,在天河超级计算机上开展的超大规模高精度CFD并行计算研究,并对未来E级超级计算机上CFD并行应用开发进行了分析展望。
2 研究现状
近年来,随着P级超级计算机的研制成功,欧美日等发达国家在这些最高端的计算平台上针对湍流等复杂流动机理研究开展了超大规模CFD并行计算。例如,2013年,德克萨斯州州立大学研究人员实现了P级高雷诺数槽道流的直接数值模拟,并行规模达到约78万处理器核[10]。瑞士苏黎世联邦工学院、IBM苏黎世实验室等单位联合完成了基于有限体积法的无粘可压两相流模拟,最大网格规模达13万亿网格点,获得了11PFLOPS的持续性能,达到系统峰值性能的55%,该项工作获得了2013年度戈登·贝尔奖[11]。
高性能异构并行体系结构发展至今,很多学者在GPU、MIC等异构超级计算机上开展了大规模CFD异构并行计算研究,取得了不错的加速效果。GPU出现的早期,研究人员通常仅移植一些简化的CFD代码,以二阶精度和一些简单的流动问题模拟为主,计算平台通常也仅包含1块或几块GPU卡。通过早期实践验证GPU计算的加速效果后,大规模GPU异构并行逐渐成为CFD并行计算研究的热点。例如,Jacobsen等[12]实现了一个支持GPU集群的不可压CFD求解器,在美国国家超级计算应用中心的Tesla集群上利用64个结点(共128块Tesla C1060 GPU卡)进行了测试,相对于8 CPU核获得约130倍的加速比。他们同时在256块GPU上开展了顶盖方腔管道湍流的大涡模拟[13],采用了1维区域分解,对比了MPI+OpenMP+CUDA 并行和MPI+CUDA并行实现,但实际上他们的工作并未实现CPU-GPU协同,OpenMP仅用于代替结点内MPI通信。作者团队在天河一号超级计算机上设计了基于MPI+CUDA+OpenMP的CPU-GPU异构协同并行算法,成功实现了当时世界上最大规模CPU-GPU协同并行高精度计算,模拟了三段翼构型高精度气动声学问题和大型客机C919的高精度气动力预测问题,问题规模达8亿网格单元,并行规模达1 024个计算结点[14 - 17]。MIC架构产品的出现晚于GPU,相关CFD问题应用优化与并行算法研究工作相对较少。德国宇航中心于2011年启动了名为“面向众核架构的CFD代码高效实现HICFD(Highly Efficient Implementation of CFD codes for HPC many-core architectures)”的研究项目[18],面向众核高性能计算机研究新的方法与工具,最优地利用系统的全部并行层级,包括在最高层使用MPI,在众核加速卡级使用高度可扩展的MPI/OpenMP混合并行,在处理器核级高效利用SIMD部件。随着天河二号超级计算机的发布,作者团队又开展了MIC平台上CFD并行计算和性能优化研究,设计了基于MPI+Offload+OpenMP+SIMD的CPU-MIC异构协同并行算法,实现了数十亿网格规模的可压缩拐角直接数值模拟,并行规模扩展到百万异构计算核心[19 - 24]。
整体而言,国内多数CFD并行计算规模为数十到数百核,与国外相比仍然有较大差距。长期以来国内多数CFD软件更加关注CFD自身的专业性,与高性能计算机系统的研制相互脱节,CFD软件适应新型高性能并行体系结构的能力较弱,迫切需要开展CFD算法、应用和系统的深度融合研究,充分发挥新一代超级计算机系统的潜能。
3 CFD方法、软件和计算平台
3.1 数值方法和软件
这里以一个In-house多区结构网格高精度CFD软件为例,简要介绍高精度CFD数值方法和软件实现。直角坐标系下强守恒形式控制方程表示为:
上述方程通过坐标变换(x,y,z,t)→(ξ,η,ζ,τ)转换为曲线坐标下方程:

该结构网格高精度CFD软件中实现了WCNS(Weighted Compact Non-linear Scheme)[25]、HDCS(Hybrid cell-edge and cell-node Dissipative Compact Scheme)[26]等我国自主发展的有限差分高精度计算格式,这里以5阶显式WCNS格式WCNS-E-5沿方向无粘通量导数离散为例,其内点格式可以表示为:

高精度CFD软件计算流程如图1所示。迭代(定常时间步迭代或非定常子迭代)开始施加边界条件,之后交换虚网格单元和奇异网格单元原始变量值,接着在计算和交换原始变量梯度之前计算谱半径增量和时间步。WCNS、HDCS等高精度格式在右端项(粘性项和无粘项)计算中实现,右端项计算结果也需要进行交换。软件中实现了常见的LU-SGS、PR-SGS等隐式方法以及显式Runge-Kutta方法,求得守恒变量增量后更新原始变量及残差,循环结束。

Figure 1 Flowchart of the structured high-order CFD图1 高精度结构网格CFD软件计算流程
3.2 异构计算平台
图2给出了采用加速器的异构计算平台。图2中每个计算结点包含若干共享内存的多核CPU,计算结点间通过高速互连网络进行通信,每个计算结点包含若干加速器ACC(ACCelerator),加速器通常具有片上存储,通过PCI-e与CPU进行数据交互。以天河一号为例,每个计算结点包含双路Intel Xeon X5670 CPU和1个NVIDIA Tesla M2050 GPU;天河二号每个计算结点则包含双路Intel Xeon E5-2692 v2 CPU和3块MIC协处理器(Intel Xeon Phi 31S1P)。图2同时给出了异构计算平台各层次对应的编程模型。计算结点间通常采用消息传递接口MPI(Message Passing Interface)实现分布式并行,计算结点内各CPU核上通常采用OpenMP实现共享存储并行。不同加速器通常需要采用不同的编程模型,既有GPU专用的CUDA和MIC专用的Intel OffLoad编程模型,也有同时支持GPU、MIC等多种计算平台的OpenACC、OpenMP4.X等编程模型。CFD应用只有综合利用上述并行编程模型,才能实现多层次并行算法。
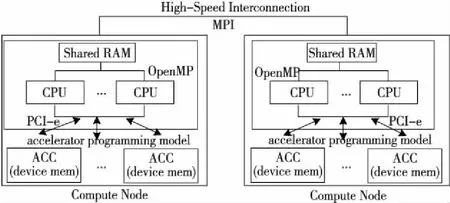
Figure 2 Accelerator-based heterogeneous computing platform and its programming models图2 加速器异构计算平台及其编程模型
4 超大规模异构协同并行计算
4.1 异构并行区域分解
区域分解是开展并行算法设计的第1步。图3以三维多区网格CFD计算为例,给出了支持多层次异构协同并行算法的区域分解示意图。图3中CFD流场区域首先根据负载均衡策略划分为多个网格块(为了满足大规模并行计算及其负载均衡需求,通常需要对原始生成的单块或多块网格进行二次剖分),每个MPI进程负责1个包含若干网格块的分组,为了简化编程,通常1个计算结点分配1个MPI进程。结点内网格块分组需要根据CPU和加速器的计算、存储能力在两者之间进行均衡分配,考虑到编程复杂度和PCI-e通信开销等,通常以整个网格块作为分配单位。对于CPU或MIC,每个网格块内沿着特定维度划分为数据片(data chunk)分配给计算核实现OpenMP线程并行。MIC计算核较多,网格块规模较小或所划分的维度网格单元均较小时,可以采用嵌套OpenMP对网格块的第2个维度进行进一步划分。在CPU或MIC上,针对每个线程处理的数据片内的网格线可以实现向量化并行。
GPU上的任务分配则较为复杂。图3中给出了一种2层分配策略,由于当前GPU均支持流处理,首先将网格块分配给GPU流实现GPU上的任务级并行;进一步,在每个网格块内,若CFD算法模型在计算中各网格单元没有依赖关系,则可以设置三维的GPU线程块,每个GPU线程处理1个网格单元。如果某一维度网格单元之间存在依赖关系,则可以考虑采用二维GPU线程块。作者团队在天河一号上针对多区结构网格高精度CFD软件实现了这种2层策略,这种方法不仅可以充分挖掘GPU的多层次并行,同时可进一步利用流处理对GPU计算的区块进行分组,克服了GPU存储空间小对计算规模的限制,实现了CPU与GPU之间负载的灵活控制(CPU计算能力弱但存储容量大,GPU计算能力强而存储空间小)。

Figure 3 Domain decomposition for multi-level heterogeneous collaborative parallel computing图3 多层次异构协同并行区域分解示意图
在区域分解过程中,网格剖分通常采用独立的工具实现,CPU或加速器上的计算任务分配需要在CFD求解器代码中实现。与同构CPU平台相比,异构并行平台对区域分解和负载均衡提出了更新的要求。例如,为了更好的负载均衡,异构计算结点通常要求剖分的网格块更多,考虑到加速器丰富的并行能力,分配给加速器的网格区块又不宜太小。
4.2 异构协同并行
异构加速器极大地提升了异构超级计算机整体性能。以天河一号为例,每个计算结点CPU双精度浮点性能约140 GFLOPS,GPU双精度浮点性能约500 GFLOPS,在异构超级计算机上开展大规模CFD计算不仅需要用好CPU,更需要用好加速器,使得两者能够实现高效协同并行。本文归纳总结了2种协同并行模式[14]:基于嵌套OpenMP的协同和基于ACC异步执行的协同,如图4所示。以每个计算结点配置1个加速器、网格包括NBLKCOMS个分块为例:基于嵌套OpenMP的协同首先在CPU上创建第1层2个OpenMP线程,其中第1个线程控制编号为[1,ACC_BLOCK_NUM]的分块在ACC上的计算,在第2个线程内创建嵌套OpenMP线程,启动其他CPU核计算编号为[ACC_BLOCK_NUM+1,NBLKCOMS]的分块。基于ACC异步执行的协同则利用了加速器异步编程模型和异步调度执行机制,CPU主线程异步启动ACC计算任务后,控制权立刻返回CPU主线程,此时启动CPU上的多线程计算。在上述2种模式中CPU与ACC上都能够同时运行计算任务,从而实现协同并行。CFD计算过程通常涉及边界处理、边界数据交换等操作,为了保证CPU上具有最新的计算结果,协同并行结束时需要在CPU与ACC之间进行数据传输、同步等。
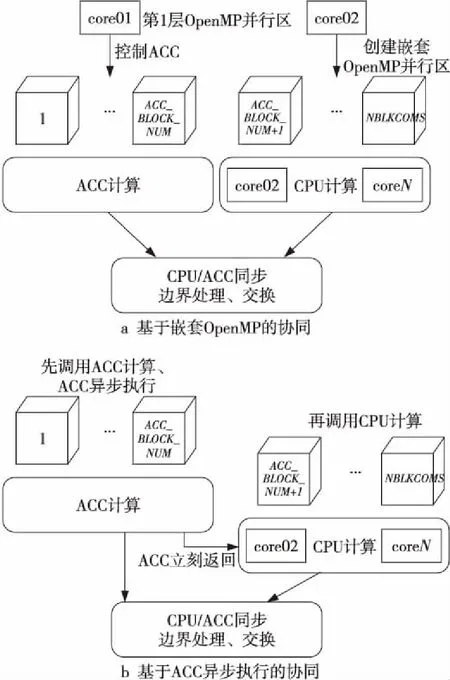
Figure 4 Two heterogeneous collaborative parallel modes图4 2种异构协同并行模式
上述2种协同并行模式编程实现均较为简单,目前GPU、MIC等异构加速器及CUDA、OpenMP4.X、OpenACC异构编程模型都支持异步执行和数据传输,开发人员可以在实际CFD程序中实现2种并行模式后针对不同的算例测试异构协同并行效果。尽管理论上基于ACC异步执行的协同并行似乎较为高效(无需专门留出CPU核控制ACC,所有CPU核均可参与计算),但在作者过去的实践中,基于嵌套OpenMP的协同并行效果更佳。
4.3 GPU并行
MIC上的OpenMP并行与CPU上的类似,这里重点介绍作者团队针对多块网格CFD计算提出的2层GPU并行算法[14]:网格区块内基于CUDA的细粒度数据并行算法和网格区块间基于CUDA流处理机制的粗粒度任务并行算法,如图5所示。图5左边给出的多块网格CFD计算过程包含nblk个网格分块的块循环(block-loop),以及(K,J,I)三维大小为(NK,NJ,NI)网格分块(虚边界扩充ngn个网格单元)内的单元循环(cell-loop);右边给出了2层并行算法实现的伪代码,其中对网格区块的循环(block-loop)和对网格单元的循环(cell-loop)分别映射到CUDA中的流处理循环(stream-loop)和CUDA计算核函数(CUDA kernel),这里假设GPU流的数量为num_stream。

Figure 5 Schematic diagram of two-level GPU parallel algorithm for multi-block structured CFD图5 多区结构网格CFD计算2层GPU并行算法示意图
细粒度并行算法根据CFD不同计算过程所包括的循环内部对网格单元的处理是否具有数据依赖关系而设计。对于网格单元间完全独立的计算过程(例如Jacobi迭代、谱半径计算等),网格区块采用三维分解,计算过程实现为三维的CUDA kernel,根据索引每个GPU线程可独立计算1个网格单元。对于网格单元间存在依赖关系的计算过程(例如各方向的无粘、粘性通量计算),由于CUDA不支持全局线程同步,因此可以采用二维分解,实现为二维CUDA kernel,每个GPU线程计算1条网格线。
在多区网格CFD中,任意2次流场边界信息交换之间的不同网格分区之间的计算是独立的,可以并行处理。CUDA通过流处理(Streaming)机制支持任务级并行,允许用户将应用问题分为多个相互独立的任务,每个任务或者流定义了一个操作序列,同一流内的操作需要满足一定的顺序,而不同流则可以在GPU上乱序执行。粗粒度并行算法将每个GPU流绑定到一个网格区块,同时在GPU上执行多个GPU流,实现多个网格区块的并发处理。流机制的引入一方面满足了应用问题多层次并行性开发的需求,另一方面很好地适应了GPU的硬件资源特点,提高了资源利用效率。在多GPU流处理机制上进一步设计了分组多流机制GBMS(Group-Based Multiple Streams)[14,15],图6a给出了多GPU流并发处理多个区块时的状态图,可以看出多GPU流能够重叠多个分区的拷入、计算和拷出,隐藏CPU和GPU间数据传输开销;图6b GBMS将4个流/分区分为2组,这种方式可有效克服天河一号Tesla M2050存储容量小的限制,允许GPU计算更多网格区块。

Figure 6 Schematic diagram of multi-stream parallel execution and GBMS for 4 grid blocks图6 4个分区时多流并发执行和分组多流并行示意图
4.4 OpenMP并行
若计算过程中网格单元之间没有依赖关系,则网格分区内的OpenMP并行可以通过沿着网格单元循环(通常为最外层循环)添加OpenMP编译指导语句实现,较为简单,本节重点介绍作者团队针对CFD中常用的具有强数据依赖关系的Gauss-Seidel迭代类算法(例如LU-SGS)改进的共享存储并行算法。以三维结构网格为例(如图7所示),在LU-SGS算法向前(下三角矩阵)扫描时,网格点(i,j,k)的更新计算需要依赖小号邻居点(i-1,j,k)、(i,j-1,k)和(i,j,k-1)的更新值,反之向后(上三角矩阵)扫描过程中则需要依赖大号邻居点(i+1,j,k)、(i,j+1,k)和(i,j,k+1)的更新值。由于这一数据依赖特点,无法直接添加OpenMP指导语句实现LU-SGS的共享存储OpenMP并行。

Figure 7 Data dependence in forward computing of LU-SGS algorithm 图7 LU-SGS算法向前扫描时的数据依赖关系
为了实现LU-SGS的OpenMP并行计算,NASA等机构的学者提出了对角-超平面和流水线2种并行算法[32,33],主要思想是开发LU-SGS算法中各个不同网格面和网格线上计算没有依赖关系的网格点进行并行计算。在早期的多核处理器上,流水线LU-SGS并行算法取得了很好的并行加速比,然而我们的测试分析表明,在MIC新型众核加速器上,228线程时并行效率急剧下降到25%以下,对于较小规模的算例甚至低至1%以下。其原因在于流水线并行效率受流水线建立和排空过程的限制。随着流水线深度(线程数)增加,流水线建立和排空的开销也随之增加。对于外层循环长度小于流水线深度的网格块而言,甚至没有足够的计算任务充分填充所有的流水线级。另一方面,随着线程数的增加,各个线程上的计算负载均衡性也会越来越差。
为了破解传统流水线并行LU-SGS在MIC加速器上的并行扩展性瓶颈,作者团队针对三维网格(3个维度记为K、J、I,KmJn指的是K、J维的第m、n个网格单元)提出了一种改进的基于线程嵌套的2层流水线并行LU-SGS算法(简称TL_Pipeline[22 - 24]),如图8所示。其基本思想就是通过将原来的1条长流水线(深度为dp)转换成相对较短的2条嵌套的流水线,从而进一步开发原先每个线程上二维子任务(子平面)内蕴含的并行性。TL_Pipeline外层(第1层)流水线的深度为dp1,在每个流水线阶段内又包含1个嵌套深度为dp2的内层(第2层)流水线,并且dp1×dp2=dp。其中内层流水线是在Jsub子平面上构造的,子任务中Jsub维各网格线组成流水线任务队列,每一条网格线沿着I维静态地剖分成dp2个子网格线。图8给出的是算法的负载剖分和任务调度示意图,其中dp1和dp2均为4,即共有16个并行线程。以第1层流水线的K4J1子任务为例,该子任务将进一步被划分为若干更细粒度的子任务JmIi(i=1,2,3,4),然后在内层流水线上进行调度执行。
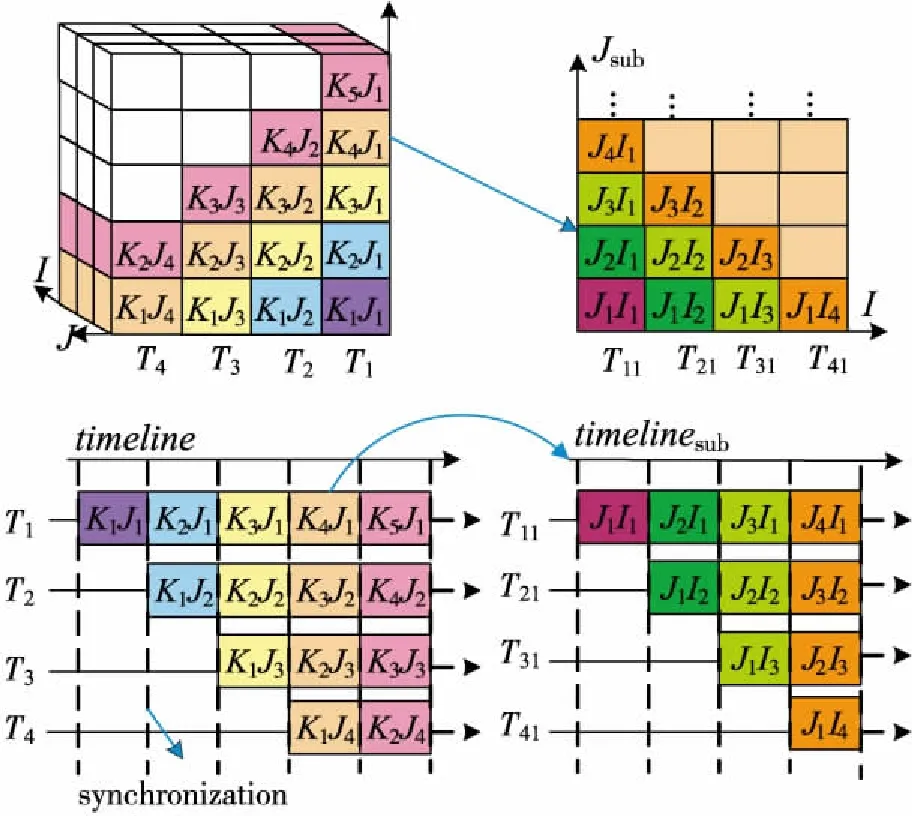
Figure 8 Illustration of task decomposition and execution timelines for the pipeline approach (left) with 4 threads/pipeline-stages,and the two-level pipeline approach (right) with 4 threads/pipeline-stages in the sub-pipeline图8 4个线程/流水段时传统流水线方法(左)和两层流水线方法(右,子流水线也包含4个流水段)的任务分解和执行过程
4.5 向量化并行
当前很多CPU和加速器(例如MIC)均采用了宽向量设计(例如天河二号CPU的双精度向量宽度为4,MIC 的双精度向量宽度为8),如果没有充分利用向量化并行,则应用的实际浮点性能将下降为峰值性能的1/v(设v为向量宽度)。对于一些复杂的CFD计算过程,直接添加向量化指导语句难以实现编译器自动向量化或者向量化效率较低,需要对CFD计算及访存特征等进行深入分析,必要时对数据结构进行重构并采用intrinsic向量化指令实现高效向量化并行。这里简单介绍一下作者团队针对高阶精度有限差分格式WCNS在MIC架构上开展的向量化并行化研究[34]。
图9给出了5阶显式WCNS格式(WCNS-E-5) 半节点重构模板计算特点。测试表明,250万网格规模时半节点重构计算约占了总计算时间的1/3,说明这部分是整个计算的性能热点。作者团队采用MIC平台特有的intrinsic向量化指令对WCNS-E-5代码进行了重写,使用的 intrinsic 语句主要包括_mm512_load_pd(对齐取数据,可一次访存取8个双精度浮点,有效降低访存次数)、_mm512_fmadd_pd/_mm512_fmsub_pd(乘加/乘减,可通过运算指令融合提升性能)、_mm512_storenrngo_pd(对齐写数据,将向量寄存器的8个双精度浮点数写入内存不缓存,对于只写访问有很好的Cache优化效果)等。此外,为了使WCNS-E-5更好地适应向量化计算,还对相关数据结构做了相应的调整。如图10所示,首先将数据结构由结构体数组AOS(Array Of Structure)调整为数组结构SOA(Structure Of Array)形式,使得数组能够大跨度地连续访问;其次为了访存的对齐,对原数组做扩充填补,保证数组的对齐(只写)访问。
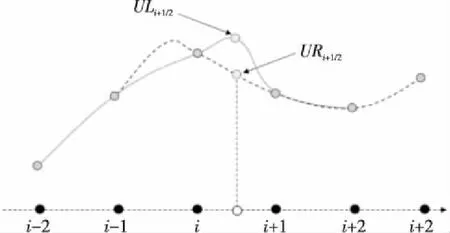
Figure 9 WCNS-E-5 interpolation template图9 WCNS-E-5插值模板

Figure 10 Data structure adjustment图10 数据结构调整
4.6 实验结果
本节将给出在天河系列超级计算机上的部分测试结果。首先定义协同效率CE(Collaborative Efficiency)以评估CPU-GPU协同并行中的效率损失:
其中,SPCPU和SPGPU分别是仅实现CPU和GPU并行时的加速比,SPCPU+GPU是CPU-GPU协同并行获得的加速比(以SPCPU作为基准)。例如,SPCPU+GPU=1.8,SPGPU=1.3时,协同效率CE为1.8/(1.0+1.3)×100%≈78.3%,意味着协同并行中的效率损失约为22%。
表1给出了天河一号超级计算机的单块Tesla M2050 GPU上不同流实现策略时的加速比。网格规模固定为128×128×128,网格分区数由2增加到8,以单流实现的性能作为基准。可以看出,采用CUDA多流在GPU上同时执行多个网格分区可提升25%~30%的性能。由于CPU-GPU同步以及一些变量的PCI-e传输,GBMS有一定的额外开销,相对于多流有一定的性能损失(最多28%左右),但作者团队设计的GBMS策略可以将高精度CFD软件运行在单个M2050 GPU上的最大模拟容量从2百万网格单元提升到4百万网格单元,这为后续CPU-GPU协同并行的负载均衡奠定了基础。

Table 1 Performance comparison of different CUDA stream implementations表1 GPU上不同流实现策略时的加速比
图11给出了天河一号超级计算机单个计算结点内GPU并行、CPU-GPU协同并行以及实现GBMS策略时的加速比和协同并行效率。由于GPU存储容量限制,仅针对前4个相对较小规模的网格给出了GPU并行加速比,对于网格规模256×128×128(约4百万网格单元),必须采用GBMS策略,SPGPU由1.3降到1.05,对于前面4个小规模网格问题,协同并行不需要GBMS,SPCPU+GPU和CE分别可达到1.8和79%,协同并行相对于纯GPU并行(GPU-only)提升了约45%的性能。对于更大规模的网格(大于4百万网格单元),GBMS对于提升协同并行加速比和协同效率非常重要。以256×256×18(约8百万网格单元)网格规模为例,如果不采用GBMS策略,则GPU只能模拟其中的2百万网格单元,其他的6百万网格单元只能在CPU上进行模拟,由于严重的负载不均衡,SPCPU+GPU仅为1.3,CE仅为57%。采用GBMS策略后,CPU和GPU均可以模拟4百万网格单元,SPCPU+GPU和CE分别提高到1.79和89%。采用GBMS负载均衡情况下,高精度CFD软件在一个天河一号计算结点上的模拟容量由3.5百万网格单元提升到8百万网格单元,提升了约2.3倍。进一步增加问题规模会导致协同并行加速比和效率明显下降,原因是即使采用GBMS,GPU模拟负载最多仍然为4百万网格单元。

Figure 11 Intra-node collaborative speedup and efficiency图11 计算结点内协同并行加速比及效率
图12给出了天河二号MIC加速器(Intel Xeon Phi 31S1P)上针对LU-SGS设计的2层流水线OpenMP并行算法TL-Pipeline与传统流水线OpenMP并行算法的加速比。可以看出,传统流水线并行的最大加速比仅为15.5(此时对应的问题规模为64×64×64,线程数为57),当使用MIC全部的228个线程时,加速比降为5.0(32×64×128),7.1(64×64×64)和6.2(128×64×32),表明在众核加速器上,随着线程数量增加,传统流水线并行存在严重的可扩展性瓶颈。与此同时,对于上面3个问题规模,即使采用全部228个线程,TL-Pipeline加速比也可分别达到69.1,82.3和98.3。注意到TL-Pipeline加速比的提升对于不同dp1×dp2的组合变化较大,这是因为流水线开销以及线程/流水段负载均衡随不同模拟变化较大。总之,TL-Pipeline为在MIC这样的众核加速器上实现LU-SGS等高数据依赖求解方法的可扩展OpenMP并行提供了新的方法。

Figure 12 Improvements of TL-Pipeline over the traditional pipeline approach for three grids dimensions on Intel Xeon Phi图12 3种网格规模下MIC上2层流水线并行相对于传统流水线并行的性能提升
本文采用规模为256×256×256的算例,在天河二号的MIC协处理器上测试对比了WCNS半节点重构计算的基准版本和intrinsics向量化优化版本的性能改进(如图13所示)。基准版本在MIC端当线程数为224的时候性能达到最优,相对MIC上单线程计算的加速比约为83.8倍。采用深度intrinsics向量化优化实现之后,在线程数规模不大的情况下,intrinsics优化实现同样具有很好的线程可扩展性。得益于MIC更宽的向量位宽,深度intrinsics优化将最优性能提升到基准实现的4.5倍左右,在112线程时取得最大加速比,说明向量优化之后MIC上的宽向量部件性能得到了更充分的开发。

Figure 13 Performance comparison of baseline and intrinsic implementation for WCNS-E-5 interpolation on MIC图13 WCNS半节点重构基准版本和intrinsic版本在MIC上的性能对比
5 结束语
当前,天河系列、神威太湖之光等超级计算机已多次排名世界第一,标志着我国超级计算机系统研制能力已进入世界前列。与此同时,国内很多单位在这些国产超级计算机上开展了大量CFD并行应用软件开发和性能优化工作,取得了不错的成果。长期以来,国防科技大学CFD应用软件团队以天河/银河系列超级计算机为依托,开展了超大规模复杂CFD并行应用开发和性能优化研究,突破了新型异构协同并行计算等一系列关键技术,初步实现了HPC与CFD的深度融合,有力支撑了国产CFD软件在天河/银河系列超级计算机上的高效超大规模并行应用。
当前高性能计算发展的下一个里程碑是E级计算(Exascale Computing,百亿亿次浮点运算/每秒),美、日、欧洲、俄罗斯等都制定了E级超级计算机研制计划。例如,2016年美国能源部正式启动了E级计算计划ECP(Exascale Computing Project)[35]。ECP特别强调应用软件开发,将其作为第1个重点关注领域。我国也将E级超级计算机研制纳入了国家“十三五”规划,目前国防科技大学、江南计算技术研究所、中科曙光3家单位牵头开展的E级超算原型系统研制项目已通过验收,实际的国产E级超级计算机系统预期在2021年左右研制成功。我国E级计算计划中同样非常关注与E级计算机配套的高性能计算应用软件研制,国家重点研发计划中已部署了一批应用软件研发项目,其中包括数值飞行器原型、数值发动机原型等CFD相关项目。可以预见,基于CFD与E级计算机融合的“数值风洞试验”“数值优化设计”“数值虚拟飞行”将给航空航天飞行器设计带来革命性的变化,并将推动流体力学和空气动力学等学科的创新发展[36]。当前,E级系统CFD应用开发面临巨大挑战。一方面超级计算机体系结构异构、众核、宽向量趋势明显,目前大多数CFD应用软件只能在纯CPU系统上运行,通常仅支持MPI并行计算,尚不具备利用新型异构众核宽向量并行体系结构的能力,难以充分发挥超级计算机的多层次异构并行性能潜力。另一方面,CFD数值模拟实际浮点计算性能不高、并行可扩展性差的情况仍然普遍存在。对真实复杂CFD应用而言,机器浮点效率常常低于10%甚至5%,扩展到千核以上并行效率严重下降。如何高效地利用大量宽向量计算核心和异构体系结构,获得实际计算的高性能,是一个严峻的挑战,“应用墙”问题依然突出。因此,迫切需要从大规模CFD数值模拟应用的数值模型和算法特点出发,紧密结合新型异构众核体系结构特征,针对性地开展并行算法研究工作,使应用程序充分发掘大规模新一代并行计算机性能,支撑实际CFD应用的高效能计算,满足国家航空航天飞行器等重大型号工程气动设计需求。
