基于文本分析的高速铁路道岔故障分类模型研究
2020-11-03杨连报沈翔李新琴董兴芝薛蕊徐贵红
杨连报,沈翔,李新琴,董兴芝,薛蕊,徐贵红
(中国铁道科学研究院集团有限公司,北京100081)
1 概述
道岔作为高速铁路信号地面设备的重要组成,是列车进出站实现进路转换的重要关键设备。通过对近十年来高铁信号地面设备故障发生数量统计分析,道岔故障占比约为1/3,是影响高铁行车组织和安全的重要因素。
目前,我国主要采用微机监测系统实时监测道岔动作电流的模拟量数据和道岔状态的开关量数据,并由现场作业人员根据电流动作曲线的异常来判断道岔发生的相关故障类别进行处置。在学术上,国内外专家学者进行了相关研究。文献[1]提出应用时间延迟网络(Time-Delay Neural Network,TDNN),通过对道岔有关动作电流和受力情况的分析实现道岔故障诊断和预测;文献[2-3]采用Fisher准则实现对道岔动作电流的特征提取,并通过计算待测样本和故障模式之间的灰关联度实现故障诊断;文献[4]通过建立模糊神经网络,输入为特征抽取后的道岔动作电流,输出为各类特征向量对应的典型故障类型,然后经过对神经网络的训练并结合专家经验实现道岔故障诊断;文献[5]通过对定量的道岔动作电流曲线的转化为定性的趋势片段,实现基于定性趋势分析的道岔故障诊断;文献[6]采用转辙机拉力参数为训练数据,实现基于粒子群算法优化支持向量机(PSO-SVM)的道岔故障诊断。文献[7]通过建立道岔转辙机故障分析与故障诊断监测系统,实现ZD6转辙机多种故障识别。
与以道岔动作电流或转辙机拉力变化的结构化数据进行道岔故障诊断方法不同,提出一种新的基于非结构化道岔故障的文本描述和原因处置过程故障诊断方法。首先对道岔故障发生的文本描述进行预处理和特征提取,主要包含文本停用词去除、中文分词、特征向量生成、道岔故障编码等,然后通过应用支持向量机(Support Vector Machine,SVM)实现道岔故障分类模型的学习,从而为现场作业人员提供一种客观的、基于海量历史数据的故障诊断模型。
2 高速铁路信号设备
我国高铁通过“引进、消化、吸收、再创新”的技术路线,走出了一条通信信号系统快速发展的道路。目前,我国高铁主要采用CTCS-3级列控系统和CTCS-2级列控系统保障列车安全、可靠、高效运行。CTCS-3级列控系统是基于GSM-R无线通信基础,实现车-地信息双向传输,并采用无线闭塞中心(RBC)生成行车许可,采用目标距离连续速度控制的列控系统;CTCS-2级列控系统是基于轨道电路和应答器,传输列车行车许可信息,并采用目标距离连续速度控制模式监控列车安全运行的列控系统。CTCS-3和CTCS-2级列控系统均包括车载设备和地面设备,两类设备构成如下。
(1)车载设备。我国高速铁路列控车载设备主要包括CTCS3-300T型ATP车载设备、CTCS3-300H型ATP车载设备、CTCS3-300S型ATP车载设备、CTCS2-200C型ATP车载设备、CTCS2-200H型ATP车载设备等。其中CTCS3-300T型ATP车载设备是我国最早投入商业运营的CTCS-3级列控车载设备。目前已广泛应用在京沪、京广、哈大、沪宁、沪杭、郑西等高速铁路。
(2)地面设备。我国高速铁路信号地面设备主要包含以下4类:①信号基础设备。主要包括信号机、转辙机及其安装装置、轨道电路、电源、电缆电线等。②列控地面设备。主要包括列控中心(含LEU)、临时限速服务器(TSRS)、无线闭塞中心(RBC)、应答器等。③计算机联锁系统。④CTC/TDCS系统。道岔是机车车辆从一股道转入或越过另一轨道时必不可少的线路设备,主要包含基本轨、尖轨、翼轨、辙叉心、护轨等部分,同时道岔的动作需要转辙机来提供动力。道岔具有构造复杂、养护维修投入大的特点,按功能和用途主要分为单开道岔、对称道岔、三开道岔、交叉渡线、复式交分道岔5种类型。
通过对我国高铁近十年来地面设备中的故障数量统计和分析,道岔故障件数居首位(故障占比39.0%)。道岔故障责任原因较多,主要包括材质、检修不良、尖轨卡物等。同时,根据现场数据,道岔故障率和季节有关系,极端的天气如雨雪等对道岔的正常运转有较大影响(如冰雪造成道岔卡阻、季节变换导致钢轨材质的热胀冷缩)。由于高铁作业均在夜间,因昼夜温差导致道岔适应性调整不当,道岔缺口动态变化超过转辙机的缺口变化允许范围。
3 基于SVM的高铁道岔故障分类
通过正则表达式进行道岔故障文本描述数据中有关日期、时间、地点、特殊字符、标点和英文符号的预处理,应用融合铁路领域词典的中文分词工具Jieba进行分词,并通过Word2Vec和TF-IDF分别生成特征向量,最后应用SVM模型实现道岔故障的智能分类。
3.1 故障分类文本数据预处理
高铁道岔故障文本数据记录了道岔故障发生的时间、线路、区间和道岔故障原因及处理过程,示例数据见表1。
传统的分类是由业务人员根据道岔故障概况和原因分析的文本描述,实现道岔故障分类。这种方式主要依靠业务人员对文本描述的理解和个人经验进行判断,造成分类的不客观、不准确。同时,在应对海量文本描述数据时,存在效率低下等问题。通过文本分析的方式,计算机可以根据道岔故障文本的描述,实现道岔故障的自动分类。

表1 高铁道岔故障记录文本数据示例
(1)通过定义高铁道岔故障分类的标准,生成道岔故障分类编号,以便计算机识别(见表2)。
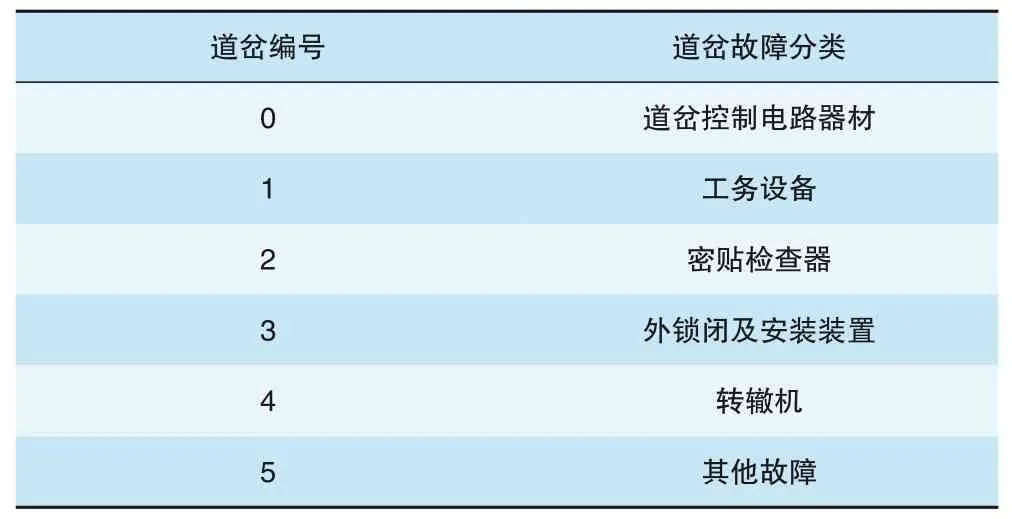
表2 高铁道岔故障分类标准
(2)通过定义常用停用词和标点符号的词典,如“的”“地”“但”“但是”“,”“:”等实现自动过滤;并通过定义高铁道岔故障描述相关的常见词汇如:“转辙机”“密贴检查器”“卡阻”“定位无表示”等实现高铁道岔故障文本的中文分词,为文本特征向量表示做好准备。
3.2 文本特征向量表示
针对分好的中文词汇,文本特征向量表示最常用的方法为TF-IDF(Term Frequency-Inverse Document Frequency)和Word2Vec。TF-IDF是一种基于统计的常用加权方法,广泛应用于检索与文本分析中[8]。Word2Vec是Google于2013年开源的词向量分布式表示算法[9-10],可以在百万数量级的词典和上亿数据集上进行训练,成为目前文本向量分布式表示的主要方法。
Word2Vec算法的实质为一个浅层神经网络,主要包含CBoW(Continuous Bag-of-Words Model)和Skipgram模型。CBoW模型利用给定上下文的向量表示,预测目标词的向量表达。Skip-gram模型则是根据目标词的向量表示,获得上下文的向量表示。二者均是用学习到的权重系数来表示所有词的向量。Skip-gram模型的整体架构见图1。

图1 Skip-gram模型整体架构
输入层为某个给定词的1×N维的文本,one-hot为向量;隐含层是由V个隐含层神经元组成,输出层为N个Softmax输出神经元归一化,获得的权重系数为每个词的向量表示。
Skip-gram模型最终目标是通过神经网络学习隐含层中的权重,根据给定词one-hot词向量预测输出词的概率最大。神经网络的隐含层像1个word embedding查找表,其输出的1×V维的向量就是词向量。主要采用Word2Vec中的Skip-gram模型生成每个中文分词的词向量,然后将每一条高速铁路道岔故障记录文本中的词向量加权求和,表征每一条文本记录向量。
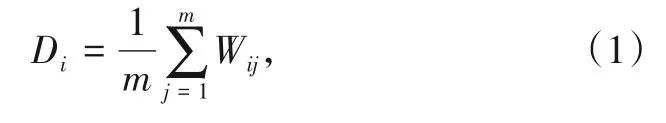
式中:Di为某条高铁道岔故障文本记录的向量;m为该条记录中分词的数量;Wij为该记录中每个中文分词的向量表示。
3.3 SVM分类模型
在获得高铁道岔故障文本记录的特征向量表示后,需要设计分类模型实现高铁道岔故障分类,研究选择SVM分类模型。通过构造1个超平面f(x),使得该函数能够表示类别y与样本向量x的关系。定义线性x不敏感损失函数为:
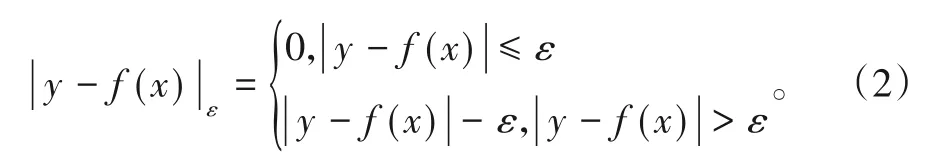
如果存在1个超平面:
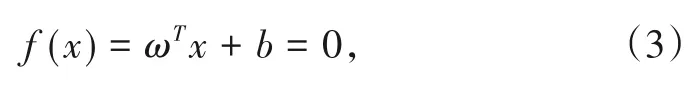
其中ω∈Rn,b∈R,使得:

则称样本集D是ε线性近似的,f(x)为线性回归估计函数。样本点{xi,yi}到超平面的距离为:
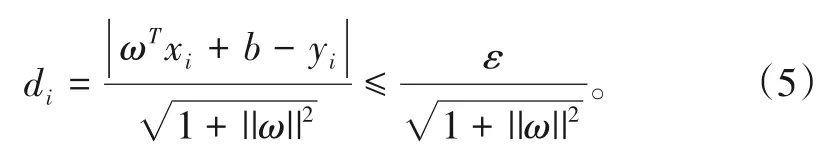
为得到最优的超平面分类,转换为一个优化问题,即使||ω||2最小。
针对非线性问题,SVM分类模型通过非线性映射φ(x)将样本映射为高维特征空间,并通过核函数的方式计算内积。此时优化问题的目标函数可表示为:

式中:ξi、为超平面不同分类界限的松弛变量;C为惩罚因子(C越大表示对误差大的样本惩罚越大,调整C可改变SVM的泛化能力)。
4 试验验证
选取2018年我国高铁道岔故障记录数据为试验数据,其中80%作为训练,20%作为验证数据集,主要采取准确率(Precision)、召回率(Recall)和F-score作为模型评价和对比的指标。
Precision计算公式为:
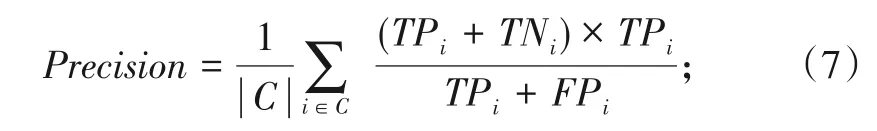
Recall计算公式为:
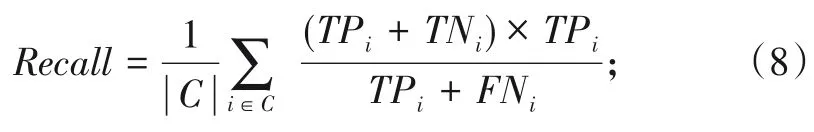
F-score计算公式为:
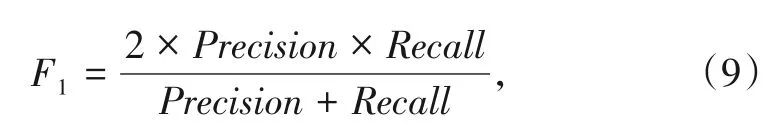
式中:TPi为被正确分到此类的实例个数;TNi为被正确识别不在此类的实例个数;FPi为被误分到此类的实例个数;FNi为属于此类但被误分到其他类的实例个数;C为所有类别的总数。
在SVM分类模型选择线性核函数,C=1的情况下,通过比较不同的道岔文本特征向量提取的模型表现如下:
(1)当应用TF-IDF进行道岔故障文本特征向量提取时,在验证集上的总体准确率达到86.4%。但对于“工务设备”“密贴检查器”的故障样例数据较少,分类效果不理想,二者的F1值在60%左右(见图2)。
(2)当应用Word2Vec进行道岔故障文本特征向量提取时,在验证集上的总体准确率达到78.2%,对于故障样例数据较少的“工务设备”“密贴检查器”的分类效果不理想,二者的F1值在22%左右。对于原因不明的分类没有较好的区分,说明应用Word2Vec特征提取时,效果整体不如TF-IDF的特征提取效果(见图3)。
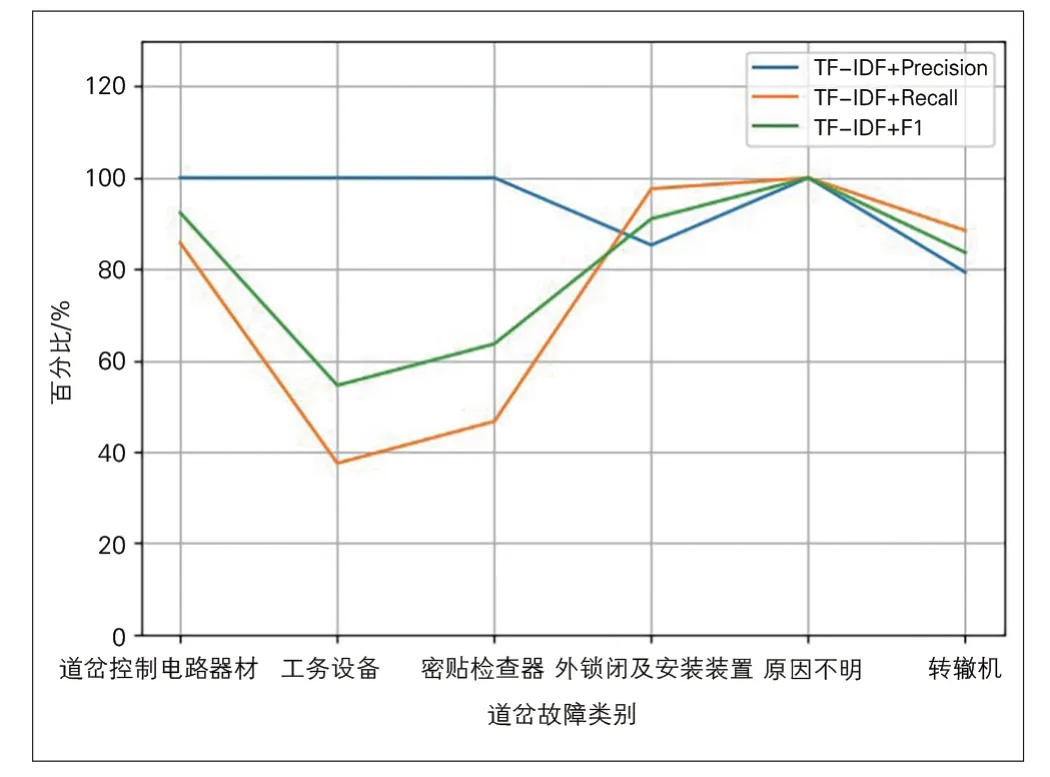
图2 基于TF-IDF特征提取的道岔故障诊断模型训练结果

图3 基于Word2Vec特征提取的道岔故障诊断模型训练结果
针对高铁道岔故障样本数据,选取的特征提取模型不一定是非常复杂的Word2Vec模型,需要结合数据特点选择合适的特征提取方法;针对高铁道岔故障样本数据类别不平衡的问题,可以通过自动生成较少样本数据的方式以及分类模型融合的方式进行解决,此次不做深入研究。
5 结束语
高速铁路道岔故障文本分类是典型的垂直行业文本分类问题,提出基于SVM的高铁道岔故障分类模型,弥补了对非结构化道岔故障文本数据分析缺乏等问题,避免了依靠个人经验进行道岔故障分类的弊端,为高铁电务安全管理提供一种客观和科学高效的技术手段,对规范高铁道岔故障管理、提高作业标准和道岔设备运用质量具有重要意义。然而,在道岔故障文本数据量较少的情况下,通过TF-IDF和Word2Vec等特征工程获得的向量表示,可为故障自动分类提供参考。考虑到道岔故障文本数据量较大时,传统的SVM、逻辑回归等分类器难以取得较好效果,基于深度学习方法进行特征的自动学习是未来的研究方向。
