改进SSD无人机航拍小目标识别∗
2020-10-30
(西北机电工程研究所 咸阳 712000)
1 引言
随着无人机和计算机视觉的快速发展,无人机航拍图像在军事和民用领域的应用越来越广泛,如侦察搜索、地形勘探、空地协同等。由于背景复杂、干扰较多、目标所占像元数少、俯瞰视角造成目标特征不明显,且拍摄过程中无人机自身的快速移动,与一般图像相比,航拍目标检测更为复杂。因为航拍图像具有以上特点,很难人工提取到合适的目标特征,采用传统检测方法难以得到好的结果。近年来,随着深度学习的快速发展,一系列基于卷积 神 经 网 络 的 网 络 模 型 如 AlexNet[1],VGG[2],GoogLeNet[3]和 ResNet[4]等,克服了传统的 SIFT 、HOG等特征存在的不足,显著提升了目标检测的准确率。因为深层网络可以学到浅层网络所学不到的高层特征,神经网络逐渐从AlexNet的5层卷积网络发展到当前ResNet1001层卷积网络。然而随着网络结构的加深,在提高模型精度的同时带来了巨大的计算量和参数量,如VGG16有133M参数,占用了大量存储空间和计算资源[5~6]。针对航拍目标检测任务,受无人机自身硬件和功耗的限制,直接在其上部署这样的深层网络模型是不实际的,因此,对深度学习模型进行优化和改进,使之适合无人机等嵌入式平台部署是非常必要的。
本文在Single Shot Detector(SSD)[7]算法模型的基础上,对特征提取网络和损失函数进行了改进:采用宽残差网络(WRN)[8]代替VGG16,参数大小仅为2.7M;采用焦点损失函数[7]代替交叉熵损失构造目标函数,提高了困难样本的检测效果。
2 SSD网络模型
Single Shot Detector(SSD)是目前主流的检测框架之一,是直接在特征提取网络上进行卷积预测的端对端网络模型[9]。SSD采用特征金字塔结构进行检测,以多层特征图的组合作为最终分类和回归的基础,传递给卷积预测层进行分类。由于SSD在多特征图上提取特征,因此在多尺度检测中具有很好的效果。
SSD使用VGG-16网络作为其特征提取网络。VGG网络在迁移学习任务上的表现优于ILS⁃VRC2014的冠军googLeNet。VGG通过不断使用小卷积滤波器来提高性能,进一步深化网络结构,将Top-5的错误率降低到7.3%。但VGG的卷积参数量高达133M,需要大量的存储空间,且网络较深,不适合并行计算,导致训练耗时长,资源消耗大,占用了整个SSD约80%的用时。SSD结构框架如图1所示。
为了获得更快的训练速度和运行速度,本文采用一种更适合并行计算的特征提取网络——宽残差网络(Wide Residual Network,WRN)。WRN是一个改进的ResNet网络,与VGG网络的133M参数量相比,WRN只有2.8M,且在CIFAR-10和CI⁃FAR-100上的性能要好于VGG网络。表1是WRN与VGG16和ResNet在CIFAR-10和CIFAR-100上的性能对比。
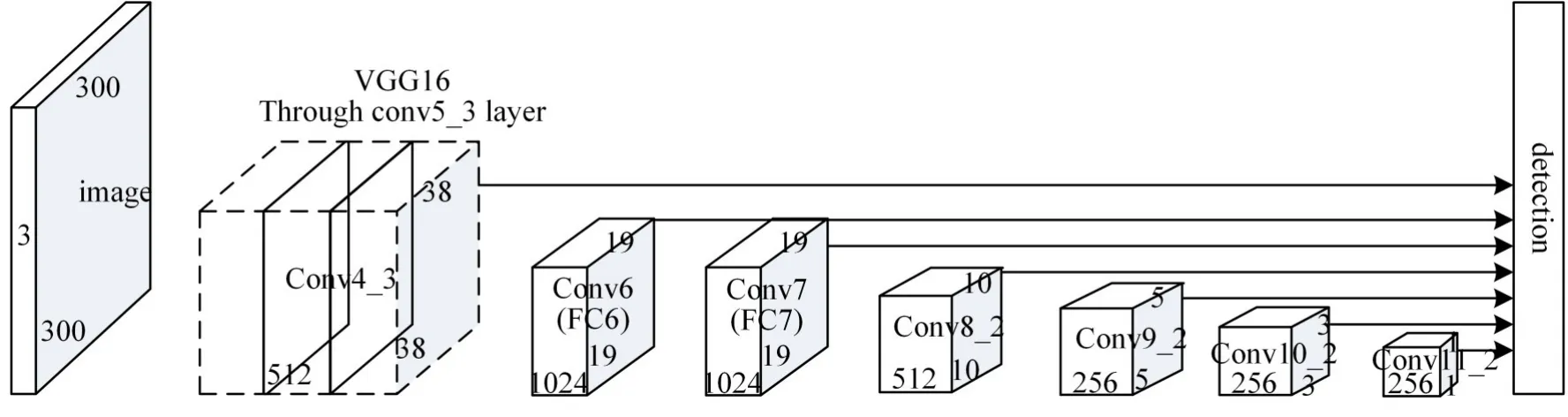
图1 SSD结构框架
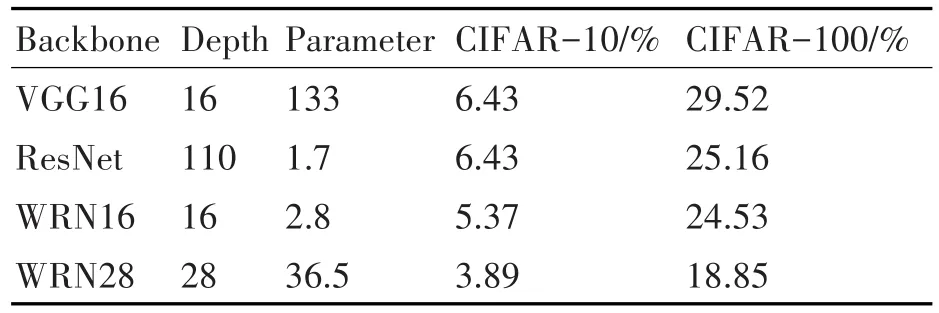
表1 网络性能对比
3 宽残差网络模型
WRN是一个改进的ResNet网络,ResNet增加了网络的深度,而WRN增加了网络的宽度。残差模块直接将低层特征图xl映射到高层特征图xl+1,假设原始网络的映射关系为F(xl+ωl),则高层特征图可以表示为

残差模块包括两种残差结构:Basic结构包含两个3×3卷积,卷积后面都跟BN及ReLU,如图2(a)和(c);Bottleneck结构包含两个1×1卷积和一个3×3卷积,两个1×1卷积分别用来降维和升维,如图2(b)。
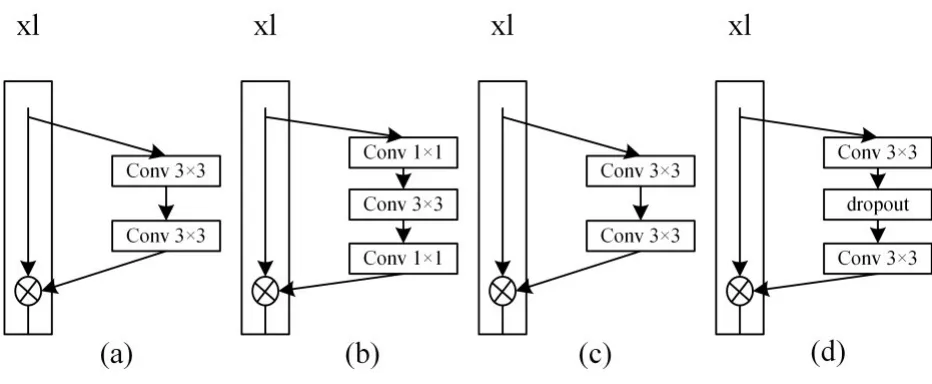
图2 残差模块结构
用B(3,3)表示图2(a)中两个3×3卷积核串联的基本结构,图2(c)和(d)表示WRN中使用的残差结构。与ResNet相比,WRN在原始的残差模块的基础上加上了一个系数k,从而拓宽卷积核的个数。根据文献[7],不仅降低了网络层数,同时还加快了计算速度,提高了性能。
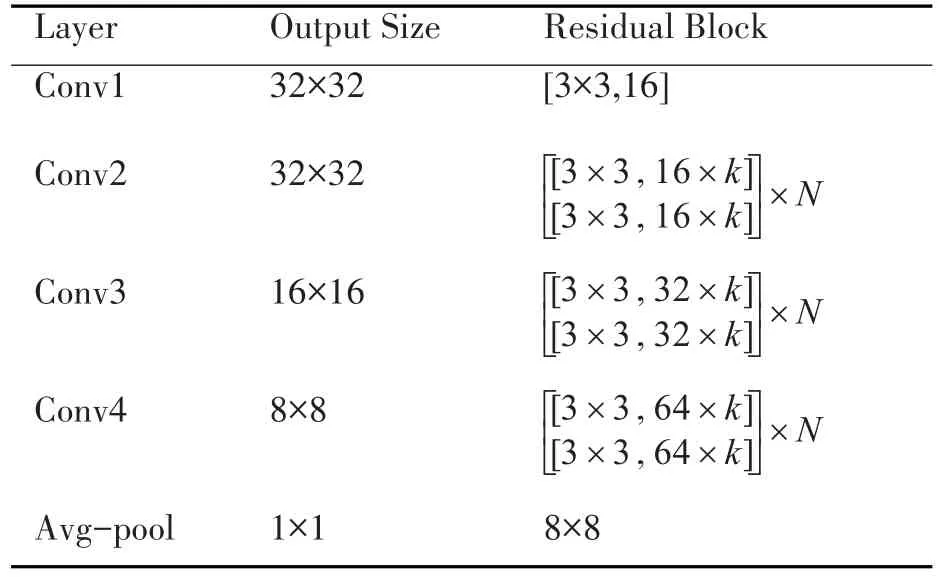
表2 WRN16-k网络结构
k为残差模块中卷积核的倍数,N为B(3,3)结构的个数,WRN16-k表示宽度为k的16层WRN网络。本文采用表2中WRN16-4网络代替最后一个全连接层,并在网络的最后添加额外的卷积层,如表3所示。卷积层逐层减少,从而得到多尺度特征图,后接的池化层用于降维。
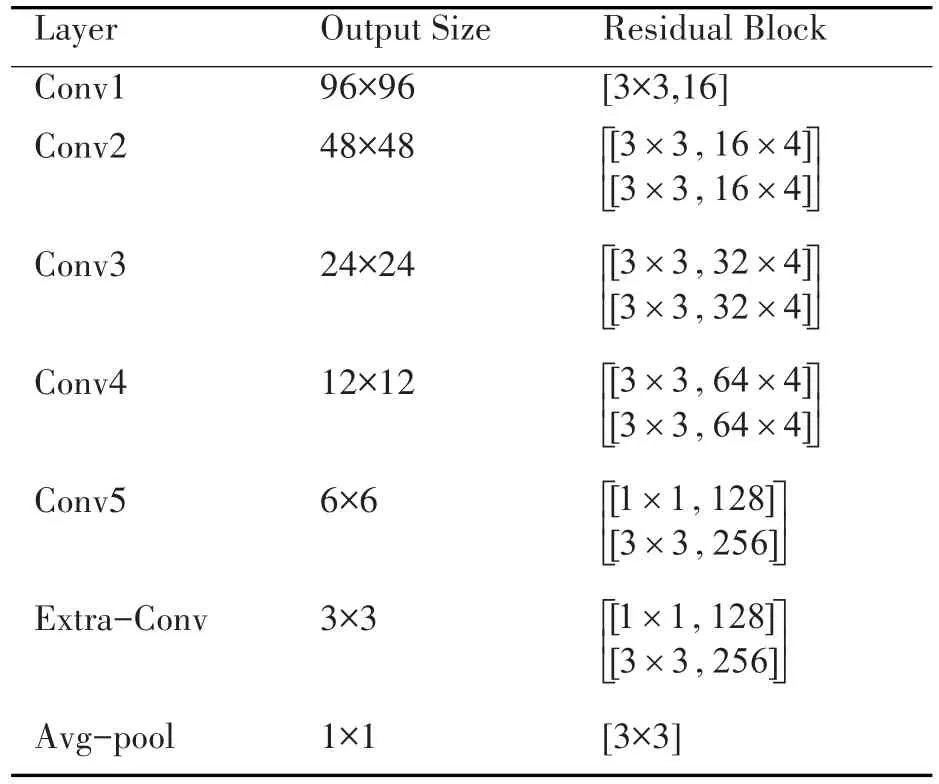
表3 改进的WRN16-4网络结构
其中Conv3、Conv4、Conv5、Extra-Conv 和Avg-pool用来做预测,得到一系列相对于默认候选框的置信度得分和位置偏移量。最后,综合这些得分信息和坐标偏移信息,得到目标所属的类别以及对应的坐标。
4 目标函数
4.1 焦点损失函数
SSD采用的交叉熵损失函数是训练模型时最常用的损失函数,定义如式(2)[11],通过数据增强和数据挖掘使正、负样本保持1:3的比例。
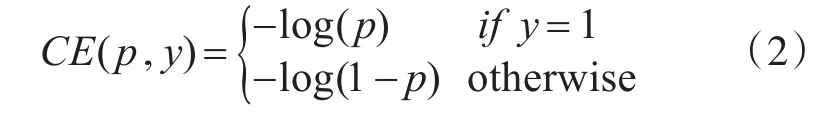
文献[6]认为,YOLO、SSD系列的One-stage算法不如RCNN系列的Two-stage算法的主要原因在于训练期间存在前景—背景样本严重不平衡(比例约为1:1000),可以通过重新构造交叉熵损失来解决这类不平衡问题,从而降低样本分配给检测结果带来的影响。
在训练过程中,大部分样本都是容易分类的,导致模型的结果更倾向于检测易于分类的样本,而忽略难以分类的样本。为了提高检测的准确率,本文采用焦点损失函数代替交叉熵损失函数,将训练更多地集中在一系列困难样本上,防止大量负样本在训练过程中影响算法学习效果。
标准焦点损失函数(Focal Loss,FL)定义为[12]

文献[7]提出焦点损失函数需要增加一个权重αt来降低易分样本的权重,从而平衡正负样本,更专注于训练难以分类的负样本,提高检测精度。因此实际焦点损失函数为

4.2 目标函数
本文训练模型的目标函数结构与SSD的目标函数一致,为置信度损失Lconf和坐标位置损失Lloc的加权和。置信度损失采用焦点损失计算得到,坐标位置损失通过预测框和真实框之间的L1范数计算得到。目标函数L(x,c,l,g)如下。

5 实验结果与分析
实验平台为Ubuntu16.04操作系统,Intel Core i7-6700 CPU@2.60GHz,Nvidia GTX 950M。编程环境Python3.6.2+OpenCV3.4.0+Caffe,并在Nvidia Jetson TX2嵌入式平台上进行了部署测试。
Jetson TX2[13~14]是基于 Nvidia Pascal架构的嵌入式AI计算设备,外型小巧,性能强大,节能高效,具有多种标准硬件接口,易于集成到产品中,非常适合无人机、机器人、智能摄像机等智能终端设备。为了测试平台性能,实验开始前,先将基于Pascal VOC2007+2012 数据集训练得到的 YOLOv3[15]模型部署在Jetson TX2上,通过其板载摄像头拍摄视频并实时进行检测,检测速率稳定在4.3FPS。
本次实验采用的是VisDrone2018-Det数据集[8]。VisDrone2018-Det数据集包含由无人机在不同位置、不同高度拍摄的7019张图像,训练集和验证集分别包含6,471和548张图像。数据集包含10类目标,分别为 pedestrian,person,car,van,bus,truck,motor,bicycle,awning-tricycle,tricycle。本文算法和SSD算法模型都在训练集上进行训练,并在验证集上进行评价。部分测试结果如图3和图4所示。
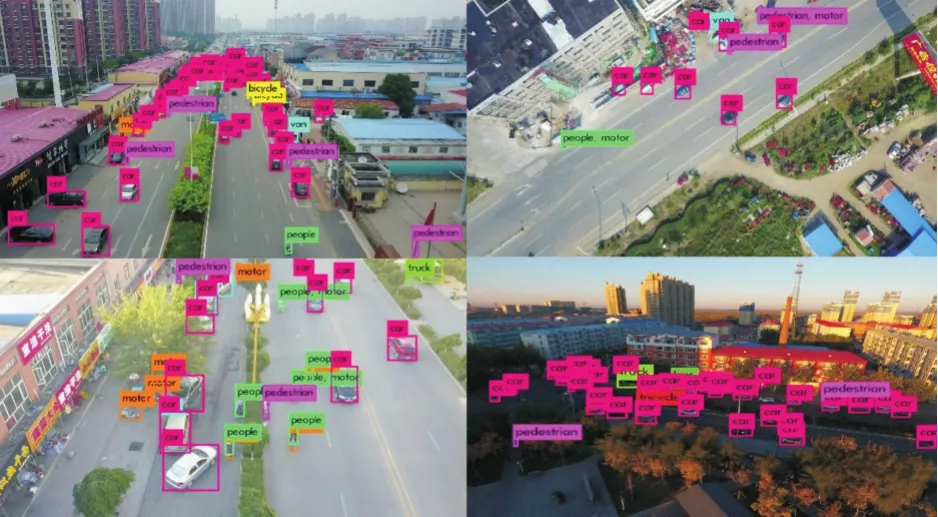
图3 VisDrone2018-Det数据集部分样本测试结果(SSD(WRN))

图4 VisDrone2018-Det数据集部分样本测试结果(SSD)
实验结果表明,SSD在所占像素较小、姿态较多的目标(如行人、骑自行车的人、骑摩托车的人)上出现了严重的漏检和误检情况;对自顶向下角度拍摄图像的检测结果较差,各类目标都漏检严重,说明算法对拍摄角度很敏感,鲁棒性不好。而通过WRN多尺度特征提取和调整焦点损失函数权重,本文算法对航拍小目标的检测准确率明显提升,大大减少了漏检和误检情况;并且WRN特征提取网络降低了参数量,使模型更适合部署在无人机等嵌入式平台上。

表4 VisDrone2018-Det数据集上的算法对比
6 结语
本文提出了一种针对无人机航拍小目标的改进SSD算法,通过WRN宽残差网络提取目标的多尺度特征,降低模型的参数量;通过改进的目标函数提高对航拍小目标的检测准确率。实验结果表明:在Jetson TX2嵌入式平台上,本文算法针对航拍数据集达到了0.76mAP,在检测速度上达到16FPS,与SSD相比均有了显著提升。如何在无人机自身硬件和功耗的限制条件下进一步提高检测速率和准确率,满足工程应用中的要求,将是下一步的研究方向。
