基于聚类距离计算的船舶轨迹异常检测方法∗
2020-10-30
(厦门大学嘉庚学院信息科学与技术学院 漳州 363105)
1 引言
国际海事组织在2000年强制规定总吨位在300t以上的国际船舶、500t以上非国际航行船舶以及所有吨位的客运船必须安装AIS系统。至2015年我国已经建立全天候高频度的船舶轨迹数据交换中心,超过15万艘船装配AIS设备。如何充分利用庞大的船舶AIS数据进行数据分析已成为当前一个焦点问题。
轨迹异常检测通过对大规模轨迹数据集中的孤立数据、偏离数据、例外数据乃至新颖数据点或点集进行检测,进而对异常模式进行发现与解释,在交通管理以及安全监控方面有重要应用价值。AIS数据作为一类典型的位置大数据,具有不确定性、不完整性、分布不均匀、规模大、更新快等特点,对其进行异常检测存在诸多困难。当前方法可分为两大类:预测建模法和统计建模法。预测建模法预测某一艘船未来状态,然后比较真实数据和预测值来判断异常。如基于支持向量机的异常轨迹检测方法[1],基于贝叶斯网络的方法[2]。统计建模法用给定的数据集建立正常行为的统计模型,然后应用统计模型对目标实例进行判断,包括基于分类的异常检测方法[3~4]、基于历史轨迹相似性的异常检测方法[5~7]、基于距离的异常检测方法[8~9]和基于网格数据特征统计的异常检测方法[10~11]。基于分类的异常检测方法在训练阶段使用训练集生成分类器,然后利用分类器对轨迹数据进行分类。这类方法精度较高,但是需要充足的训练数据集和先验知识。基于历史轨迹相似性的异常检测方法通过对历史轨迹数据进行频繁模式的挖掘,进而利用该特征模式组织方法对异常模式进行检测。此类方法不需要训练数据,基于大量的历史轨迹数据可以获得相当高精度的异常检测方法。但是由于轨迹的特征选择对于检测效果影响极大,如何选取合适的特征来计算轨迹的异常是一个困难的问题。同时由于大量的轨迹实时数据的流入,历史数据的不断重新计算开销极大。基于网格的统计方法把空间划分成若干区块,通过统计区块中的某些特征数据来检测出轨迹的异常。如基于网格内车辆数量似然比的异常检测模型[10],基于网格内轨迹方向和密度的统计模型TOPEYE[11]。基于距离的轨迹异常检测方法直接把与大多数轨迹有较远距离的轨迹检测为异常,此类方法直接有效,但是由于需要大量计算轨迹点间的距离,开销较大,需要采用辅助方法来降低计算规模。
针对AIS数据的特性和实时监控需要,本文提出一种基于聚类距离的AIS轨迹数据异常检测模型。该模型在历史AIS数据的聚类结果上,提取移动轨迹重心向量GV(Gravity Vector)和采样停止点SSP(Sample Stop Points),提出了聚类相对距离CRD(Cluster Relative Distance)和聚类角度距离CAD(Cluster Angular Distance)两个距离用于计算轨迹点与移动点聚类重心向量GV的相似度。通过这种方法,大大降低了轨迹间距离计算的运算量,提高了效率。基于真实AIS数据的实验表明,提出的方法是一个有效的AIS轨迹数据异常检测方法。
2 AIS轨迹聚类与特征提取
对轨迹数据进行聚类的目的是为了降低原始AIS数据的规模,便于后续异常检测算法的快速计算。根据航迹点的速度将原始AIS数据分为停止点和移动点两类,轨迹数据经聚类之后,移动点聚类一般可以反映出常用航道分布,停止点聚类一般反映出停泊区、低速作业区等停止区域。有关AIS轨迹的聚类方法目前有很多,本文选用的是基于密度的轨迹聚类算法DBSCAN[12],算法中,在计算ɛ邻域时,停止点邻域根据点间欧氏距离计算,移动点邻域不仅判断数据之间的欧氏距离,还加入了对其航向和速度的相似性判断。
聚类产生的结果本身可以反映轨迹模式,但在每个聚类中使用所有轨迹点来计算距离的运算量是巨大的。引入重心向量GV和停止采样点来提取聚类的特征。
定义1移动点聚类C的重心向量GV是一组向量,各分量内容为
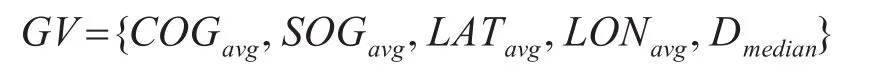
重心向量GV是移动点聚类C的特征提取结果,通过把一个聚类划分成多个部分来提取,每个类可以包含多个GV。重心向量GV由五个分量组成:平均航向COGavg,平均航速SOGavg,重心纬度LATavg、经度 LONavg,和中值距离 Dmedian。图 1 给出了一个从聚类中提取GV的例子。图中蓝色箭头代表相同聚类的轨迹点,例子中,类划分为6个网格,聚类的特征输出就是6个重心向量的集合。
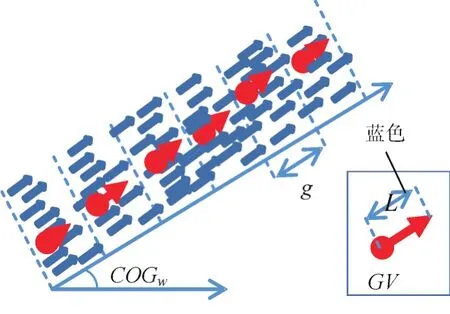
图1 移动点聚类中重心向量GV的提取
重心向量GV的计算步骤如算法1。
算法1:
Step1.计算整个聚类的平均方向,令其为COGw。
Step2.根据给出的网格宽度g,顺着COGw的方向划分聚类中所有的轨迹点。
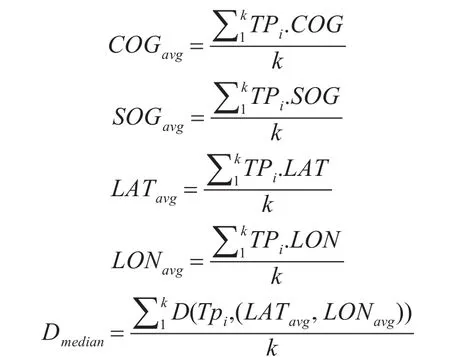
Step3.对于划分的每个网格,生成网格的重心向量。
假定某一网格中有k个轨迹点,TPi是第i个轨迹点,通过下面的公式来计算分量。
定义2停止点聚类C的抽样集SSP是一个点集,采用随机采样的方式生成,其个数n由采样半径r和停止区域的面积area(C)决定。
如图2所示,SSP为若干随机选取的停止点集合,用以代替聚类中的全部点进行计算。
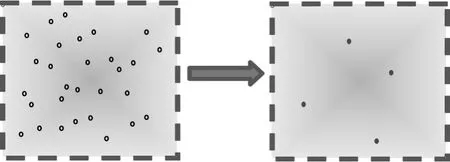
图2 停止点聚类的随机采样集SSP的提取
算法2给出了根据停止点聚类点集生成SSP的过程。
算法2:
Step1.寻找整个点集在空间上的边界点,计算面积。根据给出的抽样半径r,计算抽样点数目n。
Step2.随机选取抽样点p,并计算p与SSP中所有已选抽样点的距离,如果p与所有已选抽样点距离均大于抽样半径r,则将p加入已选抽样点集SSP,否则重新选取p。
Step3.重复Step2,直到SSP中点数目等于n。
3 聚类距离计算
定义3地理距离D用于计算停止点间的距离:
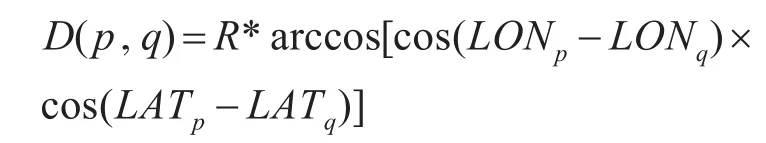
对于待检测轨迹数据P,若p为停止点,直接计算p与SSP中各点的地理距离即可,由于AIS位置数据以经纬度表示,需要进行坐标变换,式中R为地球半径。
定义4聚类相对距离CRD用于计算移动点到聚类GV间的相对距离。
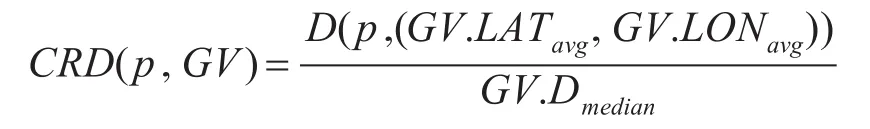
对于移动轨迹点p,由于移动点的聚类在地理上会形成一定的宽度。聚类相对距离CRD的含义是:点p到聚类重心向量的重心距离与聚类中所有点到中心的的距离均值的比值。这种相对距离的意义在于衡量相对于聚类的大小,点p的距离远近程度。
定义5聚类角度距离CAD用于计算移动点到聚类GV间的角度距离。
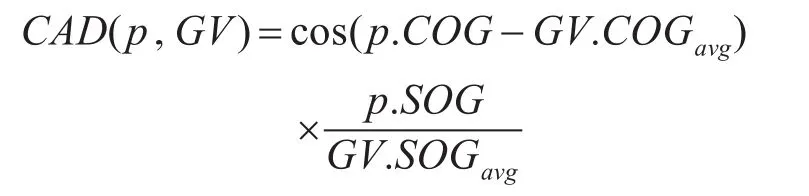
目标点p和重心向量GV之间的聚类角度距离CAD用于计算两个轨迹的航向角度差和速度差,在涉及移动对象的方向和速度时使用。CAD在计算中结合了航向COG和航速SOG。用于发现方向异常和速度异常,如图3所示。
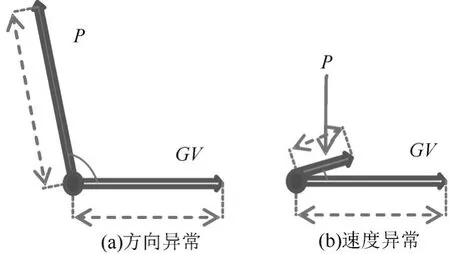
图3 移动点的CAD距离异常
4 异常检测模型
基于聚类距离的AIS轨迹数据异常检测模型如图4所示。首先历史AIS数据通过使用聚类算法生成轨迹聚类结果,包括停止点聚类和运动点聚类。之后,模型对聚类重心向量GV和采样点集SSP进行提取。在计算轨迹点与聚类间的距离时,模型采用地理距离D计算停止点与SSP之间距离,采用聚类相对距离CRD和聚类角度距离CAD来计算移动点与聚类重心向量GV间距离。通过计算训练数据集中各个轨迹点与GV的和SSP的聚类距离,生成用于检测判定的距离阈值,然后根据阈值对待检测轨迹点进行异常点检测。最后,根据目标轨迹中异常点的占比,评估轨迹的异常,最终检出结果。

图4 基于聚类距离的轨迹异常检测
5 实验结果与分析
1)数据准备
实验数据选取自琼州海峡地区2012年1月1日到1月5日五天的AIS数据实际数据,数据集的每一行代表某一艘船的一个特定轨迹点,每个点选取了6个属性:海上移动识别码(MMSI),时间戳(TIME),经度(LON),纬度(LAT),航速(SOG)和航向(COG)。清理后共50000条记录,在这些数据中,选取了其中1月1日至3日30000条记录(20000移动点,10000停止点)进行聚类与提取实验。余下的20000条数据作为训练数据集,用于计算距离阈值。选取2012年1月10号的AIS数据作为目标数据集,进行异常检测,共15261条数据。
2)轨迹聚类与提取结果
聚类后,获得1个停止点聚类,7831个停止点,6个移动聚类,共13312个移动点,如图5所示。
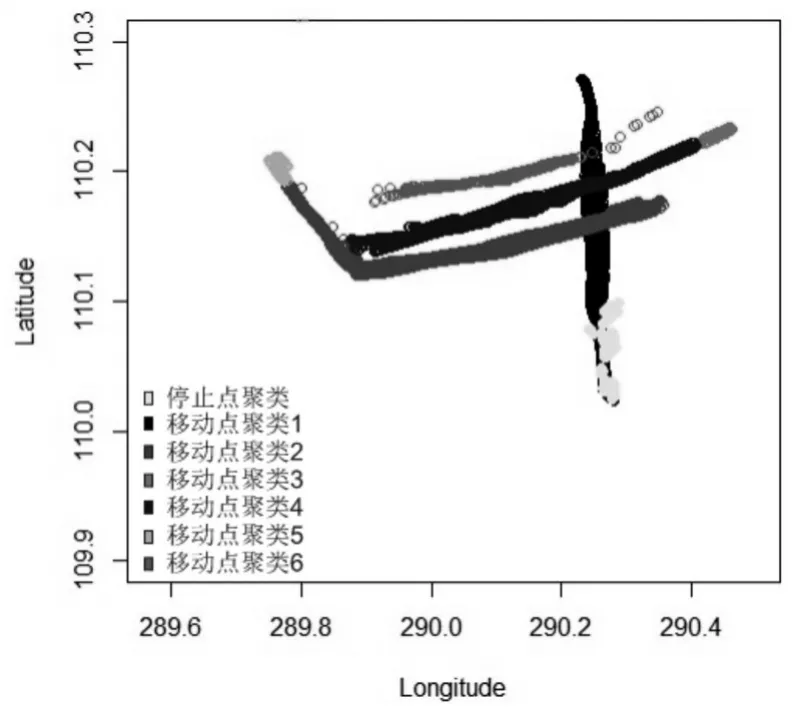
图5 实验数据集的聚类结果
对聚类结果进行提取,得到701个GV和5个停止点采样点SSP,如图6所示。图中提取结果基本可以反映海峡的交通模式,同时大大减小了数据规模。
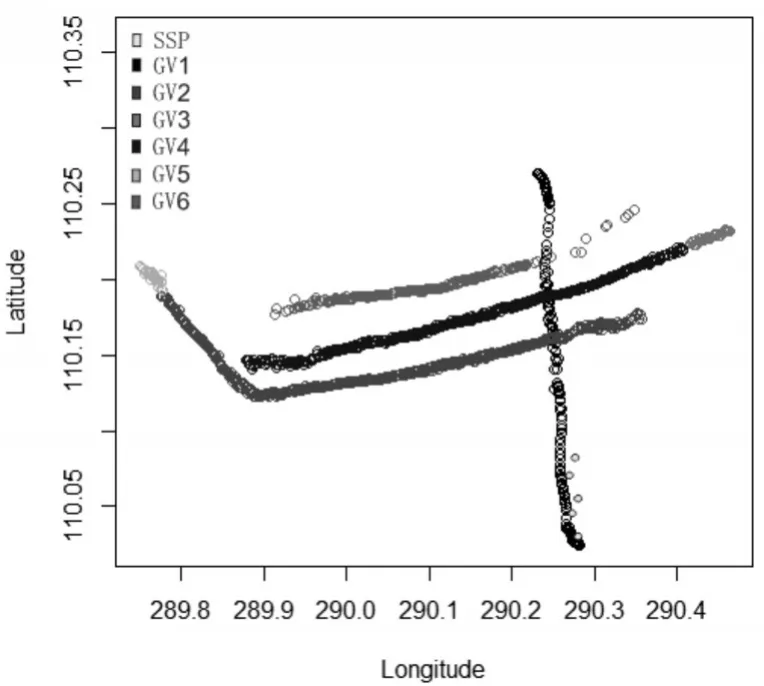
图6 GV和SSP提取结果
表1列出了轨迹数据的聚类以及提取之后的数据规模对比。
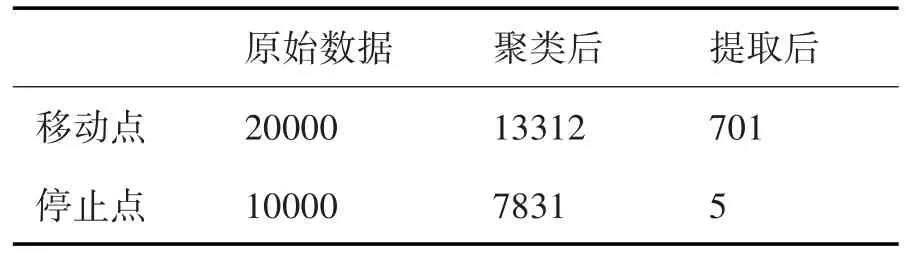
表1 数据规模对比
3)距离阈值训练
针对训练数据集,分别计算其与GV和SSP的聚类距离,得到各距离的统计情况如表2所示。
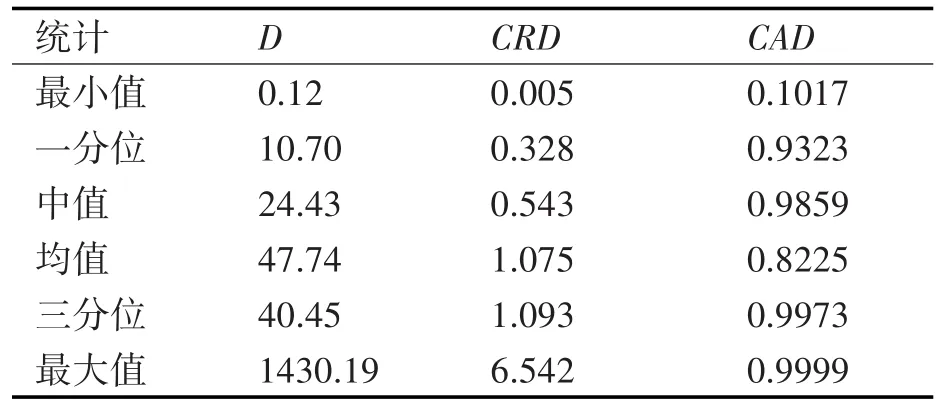
表2 距离统计
根据训练数据的距离统计分布,选择距离阈值,使得训练样本中95%以上的轨迹点满足距离阈值约束,获得D、CRD和CAD的阈值(169.73,1.243,0.5118)。
4)异常点检测
导入目标数据集进行异常检测,获得目标数据中的异常点如图7所示。在2012年1月10日目标海区内的15261个轨迹点中,算法检出1482个异常点,其中有932个距离异常点(蓝色点),550个速度或方向异常点(红色点)。
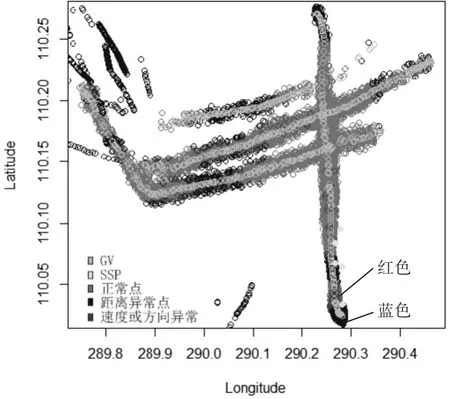
图7 异常点检测结果
5)异常轨迹的检出与解释
由于环境复杂,在船舶航行的过程中,船舶可能突然加速、减速或者变向以进行规避机动,导致部分轨迹点被判决为异常,因此只有当航迹中有一定数量以上的异常点时,才认为该航迹是异常的。实验选取30%作为最小置信度,即当轨迹的异常率大于30%时,判定该轨迹为异常轨迹。根据船舶的MMSI在目标数据中得到103条轨迹,其中有15条异常率超过30%被标记为异常。在其中选取了三条典型轨迹异常进行解释,如图8所示。
图8 三条典型异常轨迹
在图8(a)中,异常轨迹有32个距离异常点的停止点,严重偏离停止区域。检测其AIS报文信息,发现在相应时刻有搁浅信息。图8(b)中异常轨迹有8个正常点,22个距离异常点,可解释为偏航情况。图8(c)中,异常轨迹有12个正常点,4个距离异常点,14个速度方向异常点,可解释为船只航行过程中持续或频繁的变向变速。
6 结语
与其他轨迹数据来源相比,船舶在海6航行的航迹局部受限相对更少,自由度更大,由于航行速度限制,正常船只的AIS轨迹数据相对较稳定。同时由于水文地理环境影响,船舶AIS数据更加稀疏,分布更呈现偏态性。通过大量历史数据的聚类来描述船舶的航道和停泊区域再采用基于距离的异常检测方法对于船舶AIS来说是直接的、适合的。针对船舶AIS数据,本文提出了一种基于距离的异常检测方法,该方法通过提取移动点聚类的重心向量和停止点的随机采样点,把大量的轨迹点间的距离计算减少为与少量重心向量和采样点之间的距离计算,从而大大降低了运算规模。通过计算轨迹点与重心向量之间的地理距离、聚类相对距离以及聚类角度距离,不仅可以检出距离异常,还可以检出航向异常与航速异常。在真实AIS数据集上的实验结果表明,该方法是有效的。
由于硬件条件限制,本文中只选取了数据在一个很小的海区范围内进行了异常检测实验。应用成熟的并行化方法或大数据计算架构进行适当改进,可以有效地实现在更大范围内的轨迹异常点检测与监控。这也是本文下一步的改进方向。另外,结合其他数据来源,对船只异常行为进行综合判断也是一个重要的研究方向。
