基于稀疏表示的无参考型超分辨图像质量评价方法
2020-10-29张婷悦张凯兵
张婷悦,张凯兵
(西安工程大学 电子信息学院,陕西 西安 710048)
0 引 言
图像分辨率是评价图像的重要指标。一般而言,图像分辨率越高,所承载的信息越丰富,视觉质量越高。图像超分辨是一种有效提高图像分辨率的技术,该技术能突破成像设备物理分辨率的限制,生成具有丰富更多细节的超分辨图像[1]。因此,如何评价超分辨图像质量,进而优化超分辨重建算法,对研究图像超分辨技术尤为重要[2-3]。
根据评价主体的不同,图像质量评价(image quality assessment, IQA)方法可分为主观质量评价和客观质量评价。主观质量评价在规定实验情境下对多位观测者给出的质量评分进行处理,将MOS作为超分辨图像的质量。该方法可信度高,但费时费力,一般不能在图像超分辨重建系统中直接应用[4]。客观质量评价方法通过设计计算模型对超分辨图像质量进行自动评价。根据评价过程中所用到的原始图像信息的多少,大体分为全参考型(full-reference, FR)、部分参考型(reduced-reference, RR)和无参考型(no-reference, NR)[5]3种类型。峰值信噪比(peak signal to noise ratio, PSNR)和结构相似性(structural similarity, SSIM)[6]是广泛应用于评价超分辨图像的质量,不过这2种指标在评价超分辨图像质量时,没有考虑超分辨图像的自然度,评价结果与人类主观感知质量的一致性较差[7]。由于FR-IQA和RR-IQA在评价超分辨图像质量时,均需要原始图像或原始图像的部分信息,然而,在实际中原始高分辨图像难以获得,使得FR-IQA和RR-IQA方法不适合用于评价超分辨图像的质量。
相比之下,NR-IQA方法在评价图像质量时,不需要原始图像作为参考。LIU等提出了空间光谱熵质量(spatial-spectral entropy-based quality, SSEQ)方法[8],该方法提取失真图像中的局部空间和光谱熵特征度量图像失真程度,使用支持向量回归预测图像质量分数。SAAD等提出BLIINDS-Ⅱ方法[9],利用多元高斯分布模型对从失真图像中提取到的离散余弦变换(discrete cosine transform, DCT)统计域特征进行拟合,利用建立的分布模型预测图像质量分数。KANG等提出了一个5层的卷积网络模型预测图像的失真程度[10]。尽管上述方法在自然图像数据库上能有效地反映出图像的失真程度,然而,利用自然图像质量评价方法并不能适用于超分辨图像的质量评价。相比于自然图像的失真,超分辨图像的失真呈多样化,不同超分辨算法生成的超分辨图像包含不同类型的失真。针对超分辨图像,MA等提出了一种基于随机森林回归和脊回归的2层超分辨图像质量评价模型[11]。BARE等根据残差网络的特性[12],构建了一种基于跨连接的超分辨图像质量评价方法。文献[13]在AlexNet基础上[14],构建了一个基于纹理特征和结构特征的双流网络,实现超分辨图像质量评价。在大量的训练样本可用的情况下,基于深度学习的IQA方法能取得很好的评价性能。然而,在训练样本不足的情况下,基于深度学习的质量评价模型容易导致过拟合。
由于人类视觉感知系统具有稀疏性,人眼在评价图像质量时,并不考虑图像的全部信息,而是根据某些区域的退化程度来判断图像质量的好坏,基于人类视觉系统的上述特性,本文提出了一种基于稀疏表示的NR-SRIQA方法。在训练阶段,该方法从超分辨图像中提取影响图像质量变化的感知统计特征表征图像质量,利用超分辨图像训练集特征和MOS构成超完备字典。在评价图像质量时,将测试集中超分辨图像的感知特征表示为超完备字典中少数基原子的稀疏线性组合,利用得到的稀疏表示系数对相关原子的MOS进行加权求和,即为测试集中超分辨图像的预测分数。
1 稀疏表示
人类视觉系统对于图像信息感知具有稀疏性[15]。本文利用稀疏表示模型建立超分辨图像的质量评价模型。
1.1 稀疏表示方法
基于稀疏表示的超分辨图像质量评价方法首先构造由超分辨图像的视觉感知特征和MOS主观质量分数构成的超完备字典[16]:
M=[m1,m2,…,mi,…,mk]
(1)
D=[x1,x2,…,xi,…,xk]
(2)
式中:M为训练集图像对应的MOS;mi∈R为第i幅超分辨图像的主观质量分数;k为原子的总个数;D为提取训练集图像特征构造得到的超完备字典;xi∈Rn是字典D中的第i个原子,对应于训练集中第i幅图像的视觉统计特征。基于信号的稀疏表示理论,可以用字典中基原子的稀疏线性组合重构测试图像的特征,其代价目标函数表示为
(3)
式中:y为测试图像的视觉统计特征;DαT为字典与稀疏表示系数重构的特征;λ为用于平衡重构误差与稀疏度的正则化参数;‖·‖1为l1范数。通过求解满足式(3)的稀疏表示系数α,利用稀疏表示系数对M进行线性加权,即可得到测试图像的预测质量分数为
S=Mα
(4)
式中:S为测试图像的预测质量分数。
1.2 稀疏表示模型
本文提出的超分辨图像质量评价方法的总体框架如图1所示。

图 1 基于稀疏表示的无参考型超分辨图像 质量评价方法的总体框架Fig.1 Framework of NR-SRIQA based on sparse representation
由图1,本文方法分为训练和测试2个阶段。在学习过程中,将数据库中的图像进行随机划分,将80%的图像用作训练,20%的图像用作测试。
在训练阶段,首先提取训练集中超分辨图像的视觉感知统计特征,分别将提取的视觉统计特征和对应的主观质量构成超完备字典D和M,且D中的每个列向量对应从训练集中提取的超分辨图像视觉统计特征。
在测试阶段,任意给定一幅测试图像,首先提取视觉感知特征向量y,然后求解其关于D的稀疏表示系数α,利用得到的稀疏表示系数对M进行稀疏线性组合,即为测试图像的预测分数。通过分析测试集图像的预测分数与MOS之间的误差,调整模型参数λ,使建立的超分辨图像质量评价模型的预测效果达到最优。
1.3 视觉感知特征
提取能有效反映超分辨图像质量的视觉感知统计特征,是建立与人类视觉感知质量具有较好一致性的质量评价模型的首要关键问题。为有效表征超分辨图像质量,本文选取局部频域特征和全局频域特征进行融合,以构造超完备字典。
局部频域特征f1:将超分辨图像从空间域转换到DCT域,通过广义高斯分布拟合DCT系数,表示为
(5)

全局频域特征f2:采用高斯尺度混合模型(Gaussian scale mixture,GSM)拟合邻域小波带的小波系数,用于描述自然图像的边缘和联合统计特征[17],从而构成45维的全局频域特征f2。
对局部频域特征和全局频域特征按如式(6)进行特征融合,用于表征超分辨图像的质量,即:
F=[f1f2]
(6)
通过融合局部频域特征和全局频域特征表示超分辨图像的质量,有利于获得与人眼感知质量具有更好一致性的质量评价模型。在基于稀疏表示的超分辨质量评价模型中,正则参数λ的大小影响稀疏表示解向量中非零元素的个数,从而对质量预测模型的精度具有一定的影响。如果λ过大,α中非零元素较少,则建立的质量评价模型预测的质量分数与实际MOS相差较大;反之,中非零元素较多,会导致模型过拟合,而且会增加质量评价模型的计算复杂度。经过参数选择实验,本文选定正则参数λ为0.01。
2 实验结果及分析
本文使用文献[11]建立的超分辨图像数据库和文献[4]建立的超分辨图像质量评价数据库(quality assessment database for SRIs, QADS)验证所提出的NR-SRIQA方法的有效性,并对实验结果进行比较和分析。
2.1 超分辨图像数据库
文献[11]的超分辨图像数据库从伯克利分割数据库(Berkeley segmentation dataset, BSD200)[18]中选取30幅具有代表性的高分辨率图像,通过下采样和模糊运算将原始图像退化为低分辨图像,利用Yang13[19]、Yang10[20]、Dong[21]、SRCNN[22]、BP[23]、Glasner[24]、Tim13[25]、双立法插值和Shan[26]9种超分辨算法,6种不同的放大因子(2、3、4、5、6、8)和6种不同高斯核(0.8、1.0、1.2、1.6、1.8、2.0),生成1 620幅超分辨图像。对生成的超分辨图像进行主观质量评价实验。在一个高分辨率的播放器上每次同时播放同一幅低分辨图像(利用9种不同的超分辨算法生成的超分辨图像),受试者被要求基于视觉偏好给出[0,10]的分数。每幅图像收集50个分数,去掉10个离群值求剩余40个分数的均值,作为对应超分辨图像的MOS值。
QADS的原始图像来源于多损失图像数据库(multiply distorted image database, MDID)[27],从该数据库中选择具有较大范围空间信息和色彩信息的20幅高分辨率图像进行实验。所有参考图像分辨率为504×384。对高分辨率图像, 分别使用3种不同的尺度因子k(k=2,3,4)进行双立方下采样得到对应的低分辨率图像,使用21种超分辨算法(包括4种基于插值的方法,11种基于字典的方法和6种基于深度学习的方法)生成超分辨图像。对生成的超分辨图像裁剪为500×380的分辨率。QADS共980幅超分辨图像,由100个受试者参与主观实验,去掉主观质量评分的离群值后平均得到MOS值。
2.2 评价指标
准确性指标:使用均方根误差(root squared error, RMSE)计算MOS和算法预测分数之间的均方根误差,该值越小,则代表预测的质量越准确[4]。
相关性指标:使用皮尔逊线性相关系数(Pearson linear correlation coefficient, PLCC)计算预测分数和MOS之间的相关性,该值越大就表明质量评价算法的性能越好。
单调性的指标:Spearman秩相关系数(Spearman′s rank ordered correlation coefficient, SROCC)分别将预测分数和MOS按照升序排列,通过分析图像在2个数据集中序号之间的关系来评价超分辨图像质量评价方法的性能。而Kendall秩相关系数(Kendall rank ordered correlation coefficient, KROCC)通过对比2个数据集中序号一致的图像数量和序号不一致的图像数量之间的相关性来评价预测分数与MOS之间的单调性,从而度量超分辨图像质量评价算法的性能。SROCC和KROCC 2种指标值的范围为[0, 1],它们的值越大,则表明质量评价算法的性能越好。
2.3 特征融合实验
为验证融合局部频域特征和全局频域特征对超分辨质量评价的有效性,分别将融合特征和单独使用局部频域特征和全局频域特构造3个不同的超完备字典。表1给出了3种特征在超分辨图像数据库上实验对比结果。

表 1 特征融合实验Tab.1 Experiment of feature fusion
由表1的对比结果可以看出,与全局频域特征相比,局部频域特征具有较好的性能,而将局部频域特征和全局频域特征进行融合后获得的性能优于单个特征构造超完备字典建立评价模型的性能,能获得与人类视觉感知质量一致性更高的评价结果。
2.4 不同方法的对比实验
为进一步验证基于稀疏表示的超分辨图像质量评价方法的有效性,使用文献[11]和QADS 2个超分辨质量评价数据库进行对比实验,对比方法包括2种FR-IQA方法SSIM、FSIM[28]和3种NR-IQA方法SSEQ、BLIINDS-Ⅱ、文献[11]方法。其中SSIM方法是文献[6]提出的图像结构相似性评价方法,该方法综合考虑了原始图像和失真图像之间的亮度、对比度以及局部结构3方面的相似度来量化失真图像的质量分数。文献[28]在SSIM的基础上,将失真图像分块,提取块的相位一致性和梯度特征信息并计算相似度,使用相位信息加权块图像的相似度计算整体图像的质量分数。SSIM、FSIM直接对超分辨图像和原始图像进行计算,将预测的分数归一化后计算评价指标。
SSEQ、BLIINDS-Ⅱ、文献[11]方法以及本文方法使用五倍交叉[5]。五倍交叉验证将数据集均匀分成5份,分别使用其中4份作为训练集,剩余1份作为测试集。循环5次后,样本中的每个数据都被预测了1次,最终可以得到整个数据库的预测结果。表2给出了在超分辨图像数据库上的对比实验结果,表3给出了在QADS上的对比实验结果。

表 2 文献[11]超分辨图像数据库上的质量评价 算法的性能比较Tab.2 Comparative result of different IQA methods on the super-resolution image database of reference[11]
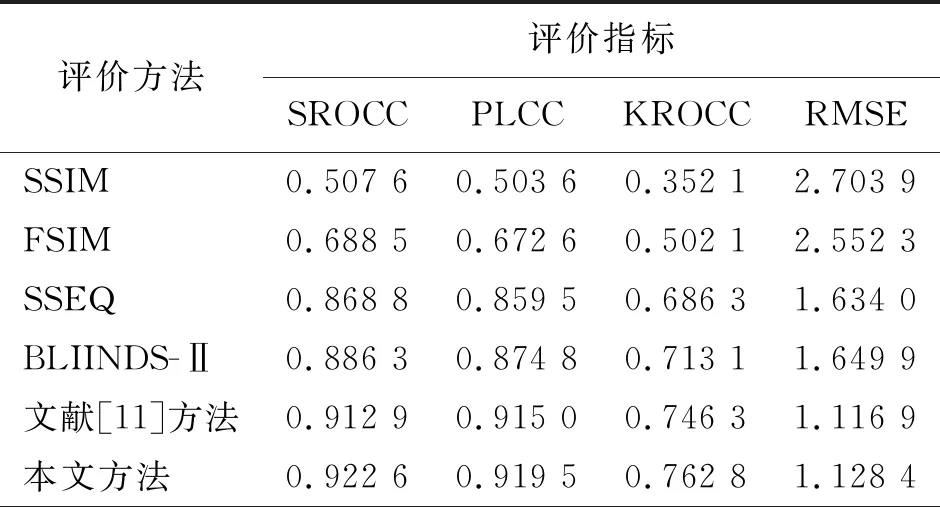
表 3 QADS上质量评价算法的性能比较Tab.3 Comparative result of different IQA methods on the QADS
从表2和表3的实验结果可以看出,相比于FR-IQA方法,NR-IQA方法均能获得更优的评价效果。这是由于FR-IQA方法只考虑了参考图像和超分辨图像之间的相似性度量,忽略了与人类主观感知的一致性因素。在另外4种NR-IQA方法中,除在RMSE指标上略低于文献[11]方法外,本文提出的基于稀疏表示的NR-SRIQA方法的性能均优于其他方法。而且相比文献[11]方法,本文方法在性能指标上具有明显的优势。需要注意的是,QADS的主观质量分数在[0, 1]之间,为便于比较,将MOS值放大到[0, 10]。由于QADS中的样本数量较少、样本类型复杂,对本文方法的正则参数进行微调,λ选为0.011。在表3中,尽管本文方法性能有所下降,仍具有一定的优势。在相关性和单调性的指标上都高于文献[11]方法。
为定性分析不同质量评价模型的预测分数与主观分数之间的一致性,图2和图3分别给出了这6种方法在文献[11]超分辨图像数据库和QADS上的散点图。

(a)SSIM (b)FSIM (c)SSEQ

(d)BLIINDS-Ⅱ (e)文献[11]方法 (f)本文方法图 2 超分辨图像数据集上质量评价算法预测图像质量的散点图Fig.2 Scatter plot of image quality predicted by quality evaluation algorithm on the super-resolution image database
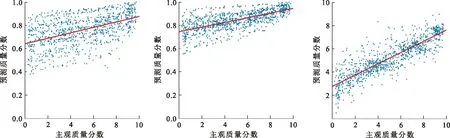
(a)SSIM (b)FSIM (c)SSEQ

(d)BLIINDS-Ⅱ (e)文献[11]方法 (f)本文方法图 3 QADS上质量评价算法预测图像质量的散点图Fig.3 Scatter plot of image quality predicted by quality evaluation algorithm on QADS
在图2和图3的散点图中,蓝色点代表样本点,横轴是超分辨图像的主观质量分数,即MOS值,纵轴代表不同IQA算法预测的质量分数。散点图中红色直线反映了样本点的线性拟合情况,如果预测分数和MOS越一致,则样本点越靠近拟合直线y=x。从图2结果可以看出,相比于FR-IQA方法,基于NR-IQA的方法(如图2(c)~(f))中样本点更靠近拟合直线,预测的质量分数与MOS的一致性更好。而在所有对比结果中,本文方法的散点图2(f)和图3(f)中的样本点分布最靠近拟合直线,离群点明显少于其他方法。对比图3和图2得出,在QADS上,各种方法的性能均会有所下降,但本文方法的结果仍优于其他方法。上述2个不同的超分辨图像质量评价数据库上的对比结果可以明显看出,基于稀疏表示的NR-SRIQA模型所获得的质量分数与人类视觉感知质量一致性最好,在总体性能上均优于其他方法。
3 结 语
针对NR-SRIQA任务,提出了一种基于稀疏表示的NR-SRIQA方法。该方法通过建立超分辨图像的视觉感知特征与其MOS一一对应的超完备字典,将测试超分辨图像的视觉统计特征表示为该字典中基原子的稀疏线性组合,利用获得的稀疏表示系数与相关字典原子的线性组合预测超分辨图像的质量。实验结果表明,本文提出的方法能获得与人类视觉感知质量较好的一致性。在未来的研究中,该方法可以考虑对2个方面加以改进:一是利用深度神经网络学习超分辨图像中更符合人眼稀疏特性的视觉特征构建超完备字典;二是增加数据库的样本数量和类型,提升超完备字典中基原子的表征能力,以提高模型的泛化能力。
