基于数据挖掘建立北京地区牛、羊肉串掺假风险预测模型
2020-10-28高晓月董雨馨李贺楠郭文萍
范 维,高晓月,董雨馨,李贺楠,王 琳,郭文萍
(中国肉类食品综合研究中心,北京食品科学研究院,北京 100068)
近年来,随着肉类消费量的快速增长,肉类掺假事件屡见不鲜[1-3]。不法商贩以价格低廉的鸡肉、鸭肉、猪肉或其他动物肉类冒充价格较高的牛肉、羊肉,赚取高额利润[4-5]。这种欺诈行为不仅损害消费者利益、危害消费者身体健康,还会破坏市场秩序[6-7]。而肉类制品通常经过加工处理,以依靠感官与经验的传统肉类形态学为主的鉴别手段已无法准确鉴别其源性。因此,国内外已经开发出多种肉类掺假鉴别检测技术,例如免疫和质谱技术[8]、聚合酶链式反应(polymerase chain reaction,PCR)技术[9]以及光谱、传感器等无损检测技术[10]。目前,我国主要采用实时聚合酶链式反应(real-time PCR)法进行源性成分检测,该方法不受加工处理及待鉴定基质中复杂干扰成分的影响、鉴定结果准确且灵敏度高[11-12]。检测技术作为一种监控手段,对于食品安全保障必不可少,但是如何实现食品安全的源头防控和主动预防,也是值得认真思考的方向。
我国当前对食品安全风险预测的手段限于数理统计、不合格样品信息通报等,而对于大量检测数据的深入分析与挖掘缺乏有效的手段[13]。通过对发达国家构建的监测与预警系统(如国际食品安全当局网络、欧盟食品与饲料快速预警系统)研究可以发现,基于数据挖掘分析的食品安全监测与预警模型可以有效达到风险预测的目的,进而促进监管前移[14]。数据挖掘技术是指将潜在的、隐含的信息从庞大的、不完整的、有干扰的数据中挖掘出来,提取隐含在其中的有效信息的过程[15]。而人工神经网络(artificial neural network,ANN)模型是一种重要的数据挖掘工具,通过模拟生物学中相互连接神经元组成的复杂网络进行建模。目前,常见的ANN模型为反向传播(back propagation,BP)神经网络,由于其能够通过训练,精准地发现数据中隐含的规律,进而有效识别、记忆食品危险特征,已被成功应用到食品安全风险预警领域中[16-17]。
目前,国内对食品安全风险调查及风险预测研究多集中在常规检测项目,如食源性致病菌、农兽药残留等,对肉类掺假调查分析较为少见。本实验对2019年北京市销售的牛、羊肉串掺假情况进行调查分析,旨在获得不同销售渠道的肉串制品具体掺假情况及相关数据,并在此基础上运用数据挖掘技术发现隐藏在检测数据中有价值的信息,构建牛、羊肉串掺假风险预测模型。以期为建立高效的食品安全风险预测机制和风险预警系统提供强有力的技术手段。
1 材料与方法
1.1 材料与试剂
1.1.1 建模样品采集
样品于2019年7—8月份采集。用于对照/质控的猪、牛、羊、鸡、鸭肉取于屠宰场,均为整块纯肉。采集的200 份样品包括100 份牛肉串(编号1~100),100 份羊肉串(编号101~200);采样渠道含盖了包括网络购买、超市、农贸市场、餐饮饭店等10 种不同渠道;本次样品采集所涉及的销售单位共计100 家,每种销售渠道各10 家,参照大型∶中型∶小型=2∶3∶5的比例进行选择,每家采集羊肉串、牛肉串各1 份。各渠道采集的20 份样品,按照生制品∶熟制品=1∶1的比例进行选择。具体采集信息见图1。
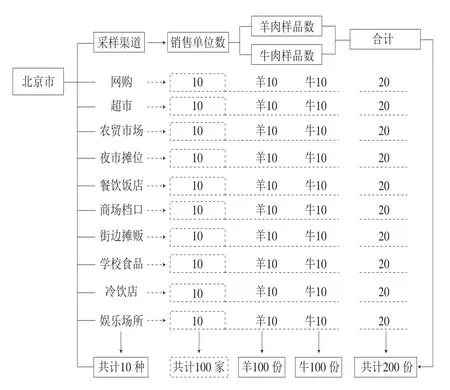
图1 样品信息网Fig.1 Information network about the samples used in this study
1.1.2 试剂
组织基因组DNA提取试剂盒 广州迪澳生物科技有限公司;2×PCR Premix ExTaqTM大连宝生物科技有限公司;引物、探针合成 上海英潍捷基科技有限公司。
1.2 仪器与设备
FTC-3000P型实时荧光PCR仪 加拿大Funglyn公司;微量核酸蛋白测定仪 美国BioTek公司;3-30K台式高速冷冻离心机 德国Sigma公司;DK-80恒温金属浴 上海一恒仪器有限公司;Thermostat plus振荡器赛默飞世尔科技有限公司。
1.3 方法
1.3.1 质控样品制备
将从屠宰场自取的整块纯的猪、牛、羊、鸡、鸭肉分别进行搅碎并均质,以羊肉或牛肉作为基底源性,分别向其中掺入1%猪肉、1%鸡肉和1%鸭肉,制得质控样品1%牛/99%羊、1%羊/99%牛、1%猪/99%羊、1%猪/99%牛、1%鸡/99%羊、1%鸡/99%牛、1%鸭/99%羊、1%鸭/99%牛。为减少源性混合样品比例的误差,按比例将各源性样品直接取至离心管中,充分混合后直接进行DNA提取。每种质控制作5 组平行样。
1.3.2 样品DNA提取及浓度测定
采用清洗干净的剪刀、研钵等实验器具将样品进行剪碎或研磨成肉泥状,样品处理过程中将不同类型源性的样品分开处理,每种源性一把剪刀,防止不同动物源性交叉污染。按照组织基因组试剂盒说明书提取样品DNA并测定DNA纯度。选取OD260nm/OD280nm值在1.7~2.0之间的DNA,于-20 ℃保存备用。
1.3.3 引物和探针合成
猪、牛、羊源性引物和探针参照SN/T 2051—2008《食品、化妆品和饲料中牛羊猪源性成分检测方法 实时PCR法》[18];鸡、鸭源性引物和探针参照SN/T 2727—2010《饲料中禽源性成分检测方法 实时荧光PCR方法》[19]。
1.3.4 real-time PCR体系及程序
扩增体系体积为25 μL:2×PCR Premix ExTaqTM12.5 μL;上、下游引物(10 μmol/L)各0.5 μL;探针(10 μmol/L)1 μL;DNA模板(OD260nm/OD280nm值为1.7~2.0)2 μL;其余体积用灭菌双蒸水补足。
猪、牛、羊源性反应程序:95 ℃预变性10 s;95 ℃变性5 s,60 ℃退火20 s,40 个循环;60 ℃收集荧光信号。鸡、鸭源性反应程序:95 ℃预变性5 min; 95 ℃变性10 s,60 ℃退火32 s,40 个循环;60 ℃收集荧光信号。
1.3.5 样品检测
将纯肉样品、质控样品与采集的样品一同进行DNA提取。提取出的每个样品DNA均按照上述方法用real-time PCR进行猪、牛、羊、鸡、鸭5 种源性成分检测。
1.3.6 BP预测模型建立
使用IBM SPSS Modeler 18.0软件构建BP神经网络模型。IBM SPSS Modeler是一个提供多种算法和模型的预测性分析平台,可以实现数据自动处理、智能建模等多项数据分析工作,在食品安全数据挖掘中发挥极大的作用。运用IBM SPSS Modeler软件构建BP神经网络的过程包括:样品数据预处理、导入数据、设置类型节点、设置数据平衡节点、设置分区节点、设置神经网络节点、生成模型、参数优化、模型预测与分析[20-21]。
1.4 数据分析
使用SPSS 23.0统计软件进行数据整理和分析。采用ANOVA检验进行数据比较,P<0.05,差异显著。
2 结果与分析
2.1 建模数据的收集
2.1.1 质控样品检测结果
根据1.3.1节方法制备质控样品,将其与采集的样品一同进行DNA提取和源性成分检测。质控样品real-time PCR图谱见图2,检测结果见表1。根据SN/T 2051—2008中规定:real-time PCR法检出限可达到0.1 g/100 g(即100 g基底源性中掺入0.1 g其他源性即可检出),对应样品Ct值≤35.0时,报告该源性成分检出。而在实际检测过程中发现,正是因为real-time PCR法的高灵敏度,使得较多样品被检出Ct值不大于35.0(图3、4),但是无法判断是蓄意掺假还是无意沾染,这与李楠等[22]的研究结果相似。由于含量小于1%的源性掺入在经济效益和口感改善方面都没有掺假的意义[23],因此,本实验制备1%含量的质控样品并测定其Ct值,根据其Ct值制定源性成分报出限,用于本实验结果判定。

图2 质控样品检测示意图Fig.2 PCR amplification curves of quality control samples
从表1可知,纯肉样品Ct值在12.51~16.93之间,1%含量质控样品Ct值在24.51~27.83之间,两者存在显著性差异(P<0.05),与李楠[22]、Xu Rusu[24]等的研究结果相似。根据1%含量质控样品Ct值范围,为确保Ct值大于报出限后,源性成分含量小于1%,故设定报出限为Ct值28.0。当0<Ct≤28.0时,报出样品含有该源性成分;当28.0<Ct≤35.0,样品虽然检出该源性成分,但其含量小于1%,不具有掺假意义,不报出含有该源性成分;当Ct>35.0时,样品未检出该源性成分。

表1 质控样品Ct值Table 1 Ct values of quality control samples
2.1.2 建模样品检测结果
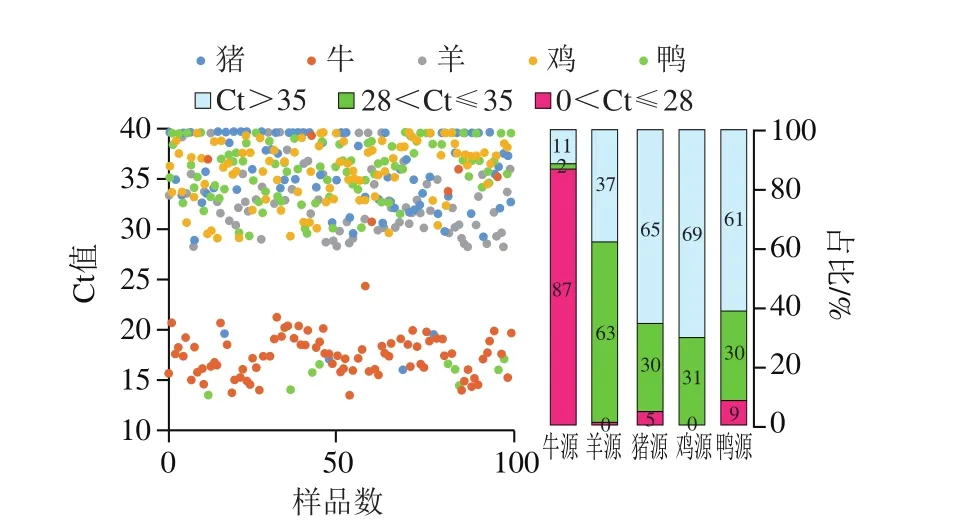
图3 牛肉串样品各源性Ct值分布情况Fig.3 Distribution of Ct values of adulterated meat species in beef kebab samples

图4 羊肉串样品各源性Ct值分布情况Fig.4 Distribution of Ct values of adulterated meat species in lamb kebab samples
根据质控样品报出限Ct值28.0和标准规定检出限Ct值35.0,将羊肉串和牛肉串样品中各源性Ct值进行分类,绘制样品各源性检测Ct值分布图(图3、4),并以报出限为结果判定依据将样品具体检测结果制成表2。通过统计结果可知,牛肉串样品中有87 个(87%)样品Ct值在0~28.0之间,可报出含有牛源性,其中86 个样品只含有牛源性,1 个样品含有牛源和猪源性,其余13 个(13%)Ct值大于28.0的样品(不报出牛源性),经检测发现4 个为猪源性、9 个为鸭源性,综上可知牛肉串的不合格率为14%;羊肉串样品中83 个(83%)Ct值在0~28.0的样品里有4 个样品既含有羊源又含有猪源,剩余17 个(17%)Ct值大于28.0的样品(不报出羊源性),其中12 个为猪源性、5 个为鸭源性,综上可知羊肉串的不合格率为21%。此外,以羊肉串为例,从图4可以看出羊肉串样品中分别有32%、11%和24%的样品其猪源、鸡源和鸭源检出的Ct值在28.0~35.0之间,但实际样品中掺入量不足1%,若将这些样品全部判定为不合格,对于商家而言是不公平的。因此,在实际检测过程中带入质控样品制定报出限,可以在一定程度上规避含量极少的样品判定为不合格的风险。

表2 样品检测结果Table 2Non-acceptance rates of samples
2.2 建模数据的挖掘
2.2.1 不合格样品分布情况分析
本次采样涵盖网购、夜市摊位、农贸市场、街边摊贩在内的10 个销售渠道,不合格样品分布情况见图5。除学校食堂外,其余渠道均有不合格样品;其中夜市摊位共采样20 份,不合格样品8 份,不合格率达40%,高于其他渠道(P<0.05)。此外,街边摊贩和网购的不合格率也较高,分别为30%(6/20)和25%(5/20)。因此,肉串销售渠道这一属性对源性成分掺假结果具有影响性。

图5 不合格样品分布情况Fig.5 Distribution of unaccepted samples
2.2.2 不合格样品来源情况分析
本次采样共涉及100 家销售单位,其中包括大型单位20 家,中型单位30 家,小型单位50 家。由图6可知,100 家销售单位中有73 家(73%)样品合格,27 家(27%)样品不合格。不合格的27 家单位中,无大型单位,有小型单位22 家(81.4%),中型单位5 家(19.6%)。由此可知,小型销售单位存在不合格样品的风险较高。因此,企业规格也是影响源性成分掺假结果的重要属性。性能和快速的训练速度。BP神经网络可以完成任意n维到m维的映射,具有高度的非线性映射能力[26],对于食品检测结果的预测实际上是寻找这种映射关系,将具有多维属性且取值不同的食品数据准确分类到合格或不合格的类别中,这与BP神经网络的训练方式相吻合。同时,BP神经网络既能处理连续型数据也能处理离散型数据,对训练集中的空缺值或错误值具有良好的健壮性,适用于分析类型繁杂且存在较多空缺值的数据集,这正好符合了食品安全抽检数据的特点。此外,BP神经网络是模仿人脑的学习方式,具有自行识别、记忆并解决复杂问题的能力,当训练数据充足时,BP神经网络能够将误差降至最低,使预测结果足够准确,满足预测食品安全风险的要求[27-28]。综上考虑,选取BP神经网络算法进行肉串样品的风险调查数据挖掘。
2.3.2 数据预处理
数据本身的结构、数量和特点直接影响到BP神经网络模型的预测效果,这就需要在建模时充分考虑模型结构和挖掘目的,选择合适的数据特征属性,确定适宜的输出结果。本研究数据挖掘的主要目的是训练BP神经网络模型反映肉串样品属性和源性掺假检测结果之间的相关性,因此需使用对肉串样品信息具有代表性的属性作为输入,以源性成分检测结果作为输出。综上,此次排除“样品编号、企业名称、样品规格、商标”等对样品不具代表性且对输出结果不具影响性的属性。最终选取“销售渠道、企业规格、加工日期、样品类型、样品属性、单价”6 个属性作为输入变量,以源性成分检测结果的“合格、不合格”为输出变量(目标变量)。将样品各属性按照IBM SPSS Modeler软件要求,在Excel中进行数据编辑,以便后期数据导入,数据框类型见表3。

图6 不合格样品企业规模情况Fig.6 Enterprise size distribution of unaccepted samples

表3 BP神经网络模型的数据框类型Table 3 Data frame types for BP neural network model
2.3 肉串样品风险调查数据挖掘与预测模型
2.3.1 BP神经网络
在众多的神经网络算法中,BP神经网络是应用最为广泛和成功的一种[25],它利用隐含层将误差从输出向输入逐层进行反向传播,在此过程中以最速下降法修改权值和阈值,使误差函数得以快速收敛,具有良好的算法
2.3.3 建模流程

图7 BP神经网络模型构建过程Fig.7 Flow chart of the establishment of BP neural network model
采用IBM SPSS Modeler软件进行建模,操作简便,具体流程见图7。首先通过源节点导入Excel整理好的数据;之后通过类型节点读取值与设置角色,将“结果”列为目标变量,其余列为输入变量;通过平衡数据节点,给予结果为“不合格”的数据平衡指令,将数据按一定比例进行平衡;通过分区节点将数据集分为训练集、测试集以及验证集;最后通过类神经网络节点进行建模。
2.3.4 建模参数设置
2.3.4.1 数据导入节点设置
数据导入后,选择自动数据准备,样本属性均为名义变量。对于已选定的分类变量,神经网络自动数据准备会将n个类别的分类型变量转化为n个取值为0或1的数值型变量后,采用二进制码将各变量编码,使其符合神经网络的输入要求。
2.3.4.2 平衡数据节点设置
本次采集样品200 份,每份样品检测项目数为5,共得到肉串样品原始数据1 000 条。其中不合格样本比例为6.5%(65/1 000),相对于合格样本而言,肉串不合格属于小样本。若直接将此数据用于模型构建,则会导致小样本类别预测效果较差,达不到预测效果。参考Linoff等[29]的方法,采用过抽样或欠抽样技术,增加样本中小样本事件比率,提高预测准确率。设置SPSS Modeler平衡节点为合格∶不合格=2∶1。
2.3.4.3 分区节点设置
将数据集分成训练集、测试集和验证集,以提高模型的稳定性和可重复性。在分区节点设置训练分区的大小为70%,测试集分区大小为20%,验证集大小为10%。
2.3.4.4 建模节点设置
建模时选择类神经网络节点。神经网络模型选取多层感知器,模型使用的停止规则为“无法进一步降低误差”,使用最大训练时间15 min。由于模型的训练为不断向样本学习的过程,因此可通过不断调整网络权值得到较小的预测误差。所有样本学习完毕后,若预测误差仍较大,则需改变建模参数重新进行学习,直到得到理想的精度或满足停止规则。
2.3.5 建模结果分析
最终经训练后得到的肉串样品源性成分掺假预测模型及模型概要见图8。形成的BP神经网络模型为3 层神经网络,隐藏层中神经元数量为9 个。预混比例2∶1分层挖掘数据得到的肉串样品源性成分掺假总预测准确率达90.3%。
利用训练集生成BP神经网络模型后,用测试集评价模型的预测准确性,用验证集对模型预测能力加以验证。从验证结果可知:建立的预测模型对于不合格样本,判定为不合格率为95.7%,错判为合格率仅为4.3%;对于合格样本,判定为合格率为87.6%,错判为不合格率为12.4%。总体而言,对于实际结果为不合格的样品,所建模型的预测准确率非常高,达95.7%,这正好满足了风险预测的目的,即尽可能准确地预测出不合格的问题样品;而对于实际结果为合格的样本,模型的预测准确率有所降低,这可能是由于样本数据不平衡或样本数据量较少所致[30],但是若用此模型进行初筛,虽然错判为不合格样品的概率较高,导致较多样品需进一步验证,但这并不会造成食品安全风险隐患,因此预测结果仍有参考和应用价值。此外,这一缺陷可通过进一步完善原始数据、加大数据统计量和调整数据集平衡比例等深入预处理得以改进[31]。
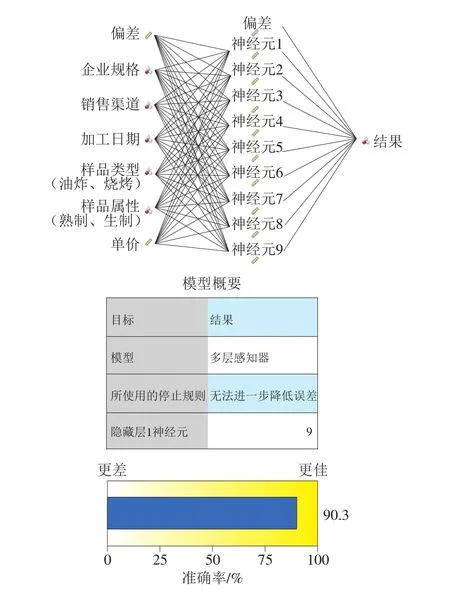
图8 BP神经网络图及模型概要Fig.8 BP neural network model with outline and accuracy evaluation

图9 各属性变量对BP神经网络模型预测结果的影响Fig.9 Influence of input variables on the prediction result of BP neural network modl
建立的BP神经网络模型,给出了各属性变量对预测结果影响的重要次序。由图9可知,“企业规格”和“销售渠道”对预测结果影响较大;“价格”对预测结果影响较小。这与2.2节中对建模数据深层挖掘的分析结果一致,说明该模型预测结果可靠。
2.3.6 模型应用
构建的模型在具体肉串样品掺假风险预测中的应用。若已经获得样品如下属性信息,如样品编号、销售渠道、企业规格、样品类型、样品属性、加工日期、单价等。则将相关属性导入IBM SPSS Modeler中,利用已训练好的BP神经网络模型预测出各样品结果(表4)。一方面对于检测机构而言,运用此模型,可以辅助检测人员有针对性地进行检测,避免漏检、错检情况的发生。检测人员可以参考预测结果对结论为“不合格”的样品进行重点检测。后期争取通过对模型的进一步改进,提升模型对合格样品的预测准确率,以实现对预测合格样本的免检,这样可有效节约人力、物力和财力。另一方面对于监管部门,在实施抽检行动前,可以先简单的收集样品信息,将这些信息导入到该模型中,对样品检测结果进行预测,之后根据预测结果制定及规划风险监测抽检方案。
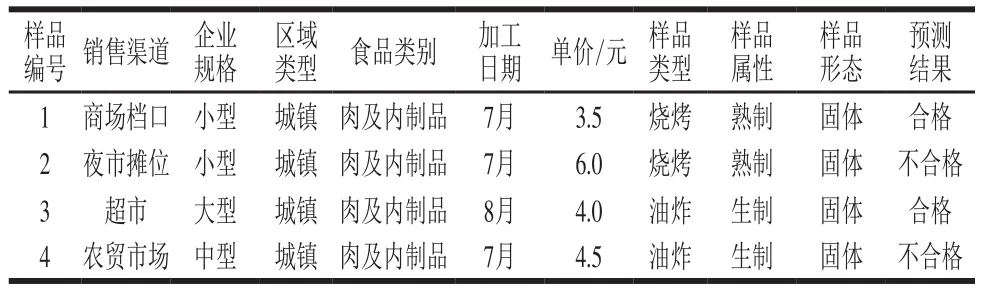
表4 样品预测结果Table 4 Prediction results for samples
3 结 论
本实验对2019年北京市10 个销售渠道,100 家销售单位的200 份牛、羊肉串样品源性成分掺假情况进行调查分析,考察影响源性成分掺假的主要风险因素,并通过对检测数据的深层挖掘构建牛、羊肉串源性成分掺假的BP神经网络预测模型。该模型以“销售渠道、企业规格、加工日期、样品类型、样品属性、单价”6个属性作为输入变量,以源性成分检测结果的“合格、不合格”为输出变量(目标变量)。通过IBM SPSS Modeler软件的自动模型验证与参数优过程,最终得到的3 层神经网络预警模型,其总预测准确率为90.3%,其中对实际不合格样品的预测准确率高达95.7%。该模型可用于检测机构样品的初筛预判以及作为监管部门制定抽检方案的依据,但是对预判合格的样品仍存在4.3%的错判率,故无法做到对预测合格样品实施免除检测。此次模型构建没有完全达到预期效果的主要原因在于源性成分掺假风险调查样品较少,导致可获得的数据量有限。因此,之后将在此基础上不断的收集样品数据,完善数据源,进一步提升模型的预测准确率,使其成为建立食品安全风险预测机制和风险预警系统的强有力手段。
