Preserving Data Privacy in Speech Data Publishing
2020-10-27SUNJiaxin孙佳鑫JIANGJin蒋进ZHAOPing赵萍
SUNJiaxin(孙佳鑫),JIANGJin(蒋进),ZHAOPing(赵萍)
College of Information Science and Technology, Donghua University, Shanghai 201620, China
Abstract: Speech data publishing breaches users’ data privacy, thereby causing more privacy disclosure. Existing work sanitizes content, voice, and voiceprint of speech data without considering the consistence among these three features, and thus is susceptible to inference attacks. To address the problem, we design a privacy-preserving protocol for speech data publishing (P3S2) that takes the corrections among the three factors into consideration. To concrete, we first propose a three-dimensional sanitization that uses feature learning to capture characteristics in each dimension, and then sanitize speech data using the learned features. As a result, the correlations among the three dimensions of the sanitized speech data are guaranteed. Furthermore, the (ε, δ)-differential privacy is used to theoretically prove both the data privacy preservation and the data utility guarantee of P3S2, filling the gap of algorithm design and performance evaluation. Finally, simulations on two real world datasets have demonstrated both the data privacy preservation and the data utility guarantee.
Key words: speech data publishing; data privacy; data utility; differential privacy
Introduction
A large amount of speech data has been released to support voice-based services,e.g., voice assistants and voice authentication. However, the published speech data entail users’ data privacy disclosure, thereby disclosing more sensitive information. Unfortunately, so far, several works[1-2]focused on privacy protection in speech data publishing. However, they did not consider the corrections among content, voice, and voiceprint of speech data when they processed the speech data. As a result, it is vulnerable to inference attacks and linkage attacks. For instant, in Fig. 1(a), the speech data of a child “I have to go to kindergarten now” are sanitized to the speech data of a grandmother “I have to go to work now”. When the processed speech data are released for statistics on the children’s admission rate, the data utility of the child’s speech data is not protected. Likewise, in Fig. 1(b), when the child’s speech data are published with the sanitized one, attackers identify the child’s speech data, since the content, voice, and voiceprint of the sanitized speech data are not consistent[3-5].
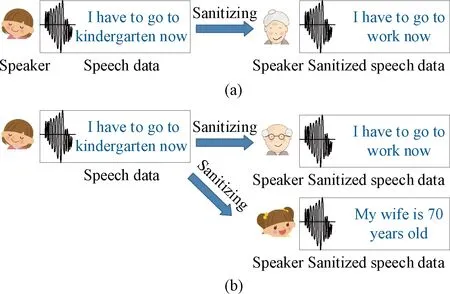
Fig. 1 Example of speech data publishing and data privacy disclosure: (a) illustration of the data utility unguaranteed; (b) illustration of the data privacy unprotected
In this paper, we design a privacy-preserving protocol for speech data publishing (P3S2) that takes the corrections among content, voice, and voiceprint into consideration when it sanitizes speech data. Moreover, we theoretically prove both the data privacy preservation and the data utility guarantee. Finally, we compare the proposed P3S2with the state of art techniques.
1 Attack Model
As shown in Fig. 2, the server is considered as semi-trusted[6-7]. That is, it honestly returns the voice-based services to users and performs the P3S2. However, it publishes the sanitized speech data to advertisers, research institutions, attackers,etc. The third party is also untrusted. It concentrates on distinguishing the speech data of each user to breach the users’ privacy[8-9]. And users are trusted. Since users do not communicate with each other, a particular user’s speech data cannot be disclosed to other users. So, in this paper, we only focus on protecting data privacy against both the server and the third party.

Fig. 2 Attack model
2 Goal of Design
The above attack model motives the need for a privacy-preserving scheme that offers the following features.
(1) Data privacy preservation
Each user’s speech data is protected against both the server and the untrusted third party. Namely, each user’s speech data cannot be identified by the server and the untrusted third party.
(2) Data utility guarantee
Specifically, in the analysis tasks, the errors between the statistical features corresponding to the speech dataset of users and the statistical features corresponding to the sanitized speech dataset should be as small as possible.
It can be seen that the two goals, namely the data privacy preservation and the data utility guarantee, are in conflict. In other words, to protect data privacy, users’ speech data are sanitized, but it definitely results in the loss of data utility. In this paper, we try to achieve the better balance of both the data privacy preservation and the data utility guarantee.
3 Design of Proposed P3S2
3.1 Feature set selection
The speech data of the specific useruiisxi, the set of all users isU, and the set of all users’ speech data isX. The content, the voice and the voiceprint, are denoted byC,V, andP, respectively. We classify the users intonsetsU1,U2, …,Un, and the corresponding speech data areX1,X2, …,Xn. Denote the sets of the features of speech dataXi(i=1, 2, …,n) in the dimensions (i.e.,C,VandP) asXiC,XiVandXiP, which are obtained by feature learning.
In each dimension, it first randomly selects a set {xik} fromXi, which is regarded as the initial feature setXij(j=(C,V,P)). Then, it conducts subset evaluation using the evaluation functionG(·).
(1)
whereρτis the proportion ofxijτin the setXijand |Xij| is the cardinality of the setXij. Thereafter, it literately adds a specific featurexilinto the setXijwhen it brings in information gain, until the |Xij| features are searched.
3.2 Speech content sanitization
We propose two steps to sanitize the speech content. (1) Identify the key terms (e.g., gender, job and interests) of the speech dataxiof a particular useruiin the contentCdimension, using the named-entity recognition[10]. Assumeui∈Ui. (2) The corresponding features are picked out in the feature setXiCto replace the key terms.
We first define the inverse document frequency of term frequency valueTFIDFof a wordwin the speech content as
(2)
wherecwis the counts of the wordw,Nrefers to the number of words in the text,nwrefers to the number of texts that contains the wordw, andKrefers to the total number of texts in the speech database. Then, we use named-entity recognition[10]to identify the key words. When theTFIDFof a wordwis larger than the pre-defined threshold, the wordwis regarded as a key term.
Thereafter, we select features in the feature setXiCto replace the key terms. Specifically, we select the words which are the most similar to the key terms from the feature setXiCto replace these key terms. The similarity between the selected words and the key terms is quantified by whether theTFIDFvalue is similar.
3.3 Voice sanitization
In the voiceVdimension, we first randomly select a voice from the feature setXiV, and then we perform the targeted voice conversion[11]utilizing the selected voice. To concrete, a warping function is used to distort the frequency axis so as to change the speaker’s voice. The warping function is
(3)
where,f,fmandf′ are the original frequency, the max frequency and the new frequency, respectively;αquantifies the degree of distortion;ais a constant. By varying the parameterα, the voice is converted to the selected voice from the feature setXiV.
4 Security and Utility Analysis
4.1 Data privacy preservation analysis
We first investigate the privacy preservation which P3S2provides, and we get the following results.
Theorem1P3S2provides the (ε,δ)-differential privacy for the speech data of a specific userujin each dimension, whereρ=1/nz(z=(C,V,P)), andnzis the number of featuresxizl∈Xizthat meet
(4)
ProofMotivated by the composition property of differential privacy, we propose to prove that P3S2provides the (ε,δ)-differential privacy for the speech data of a specific userujin each dimension. We first prove the security in the content dimension.
SincenCfeatures meetFC(xi,C,l)=FC(xi,C), each of these features is selected with a probabilityρ=1/nC. Denotef(τ,nC,ρ) as the probability of gettingτheads innCtrials, and the trial succeeds with the probabilityρ. P3S2sanitizing the speech data is like a game of coin toss. Thus, we get the following results.
(5)
SincenC≥τandε≥-ln(1-ρ), the following inequation holds:
(6)
WhennC(1-ρ)/(nC-τ)>eε, we get the constraintsτ≥aandnC≥τ>nCv=(eε-1+ρ)/eε. Thus, we get:
(7)
Therefore, P3S2provides the (ε,δ)-differential privacy in the content dimension. Likewise, we can prove the security in other two dimensions.
In summary, Theorem 1 holds.
4.2 Data utility analysis
Then, we proceed to prove the data utility guarantee. Similar to the (ε,δ)-differential privacy, in the (a,ε,δ)-differential privacy[11], the error of the output is statistically bounded byεwith the probability 1-δwhen any tupleais removed from or added to the datasetD. That is, the error of the output is bounded by both parametersεandδ. Inspired by the definition of the (a,ε,δ)-differential privacy, we propose to use the parametersεandδto quantify the data utility guarantee, and we get the following results.
Theorem2 P3S2guarantees the data utility of the speech data of any a specific userujin each dimension via providing the (a,ε,δ)-differential privacy, where
ProofWe first prove that P3S2in the content dimension guarantees the data utility. To this end, we only need to prove:
(9)
whereTis the set of any tuplea. Obviously, the following equation holds:
(1-ρ)a-1.
(10)
Similarity, the data utility in other two dimensions can be proved.
In summary, Theorem 2 holds.
5 Performance Evaluation
5.1 Experiment setup
We use two real-word speech datasets, namely TED talks[11]and LibriSpeech[12]. In addition, we compare P3S2with the existing study by Qianetal.[1]and the baseline (hereafter Baseline). Baseline directly releases the exact speech data of users. Furthermore, we use the two kind of attacks, namely linkage attacks[1]and membership attacks[13]to prove the data privacy preservation. Likewise, we consider the two kinds of analysis tasks, top-50 hot topic extraction and top-50 influential person extraction, to evaluate the data utility guarantee. Additionally, we use two metrics, namely a success rate of linkage attacks or membership attacks and an error of statistical features. The first metric is the rate of users whose speech data is breached by attackers.
The second metric is
(11)
5.2 Simulation results
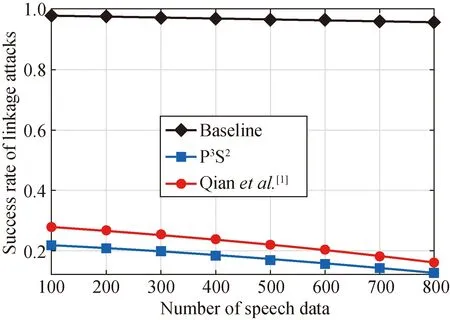
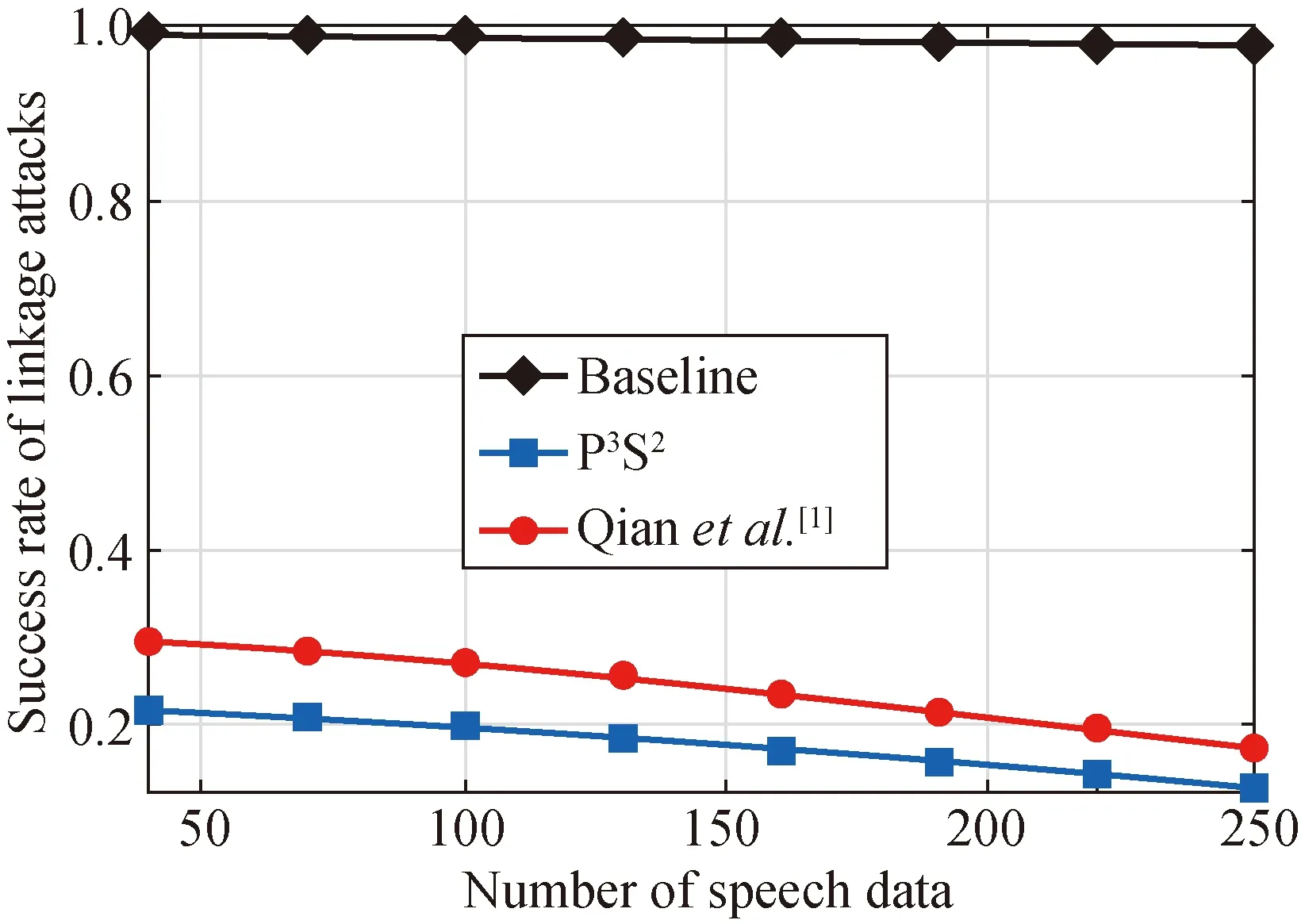
Figures 3 and 4 show the success rates of linkage attacks and membership attacks in the two datasets. We can see that, both the success rates of the two kinds of attacks in the two datasets decrease, as the number of speech data is increased. Moreover, the success rates of the two kinds of attacks in Baseline are larger than those in Ref.[1] and P3S2. It is attributed to that Baseline releases speech data without protecting the data privacy. Furthermore, the success rates of the two kinds of attacks in P3S2are much lower than those in Baseline and Qianetal.[1]. It is because that P3S2considers the consistence among the three dimensions.
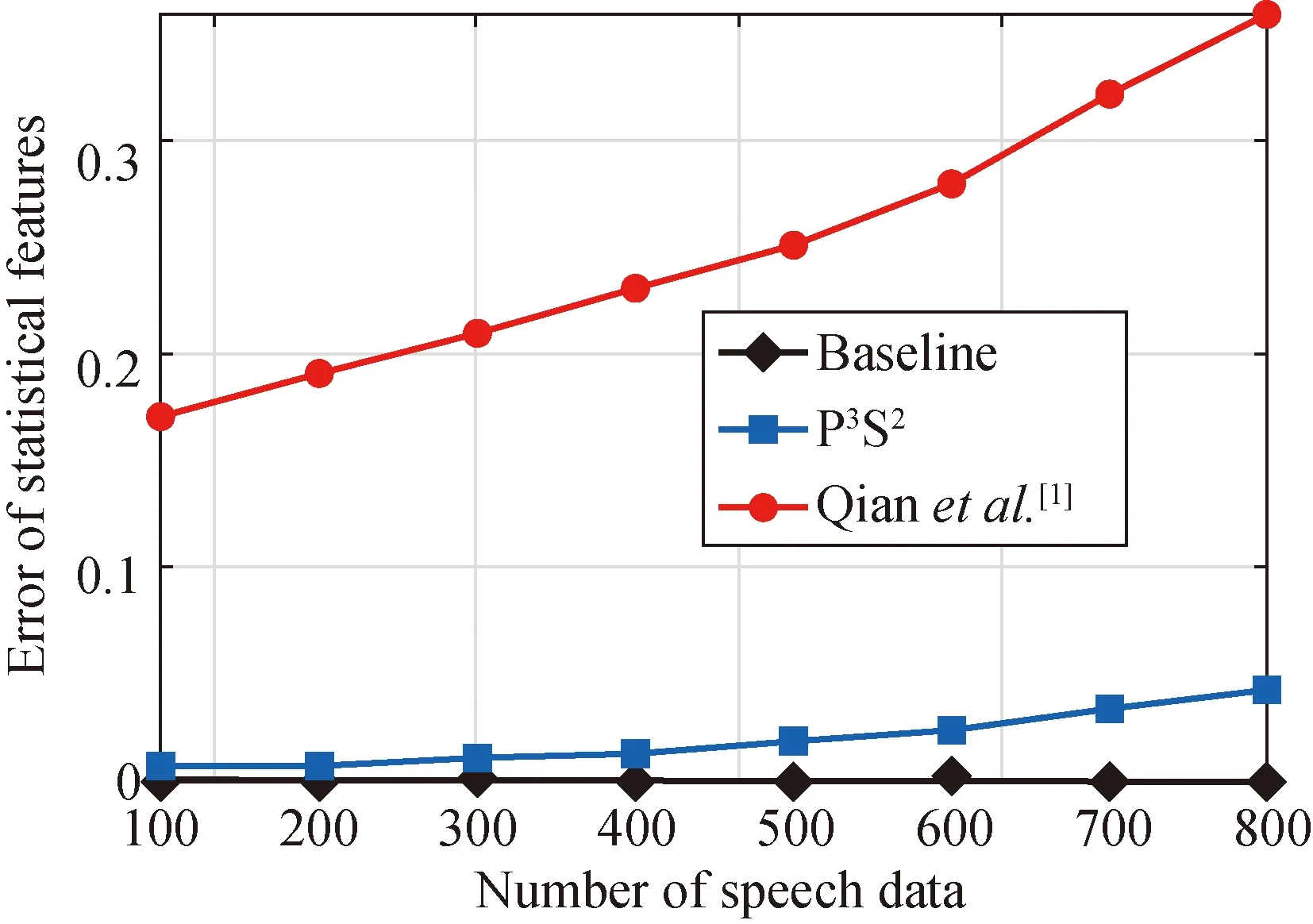
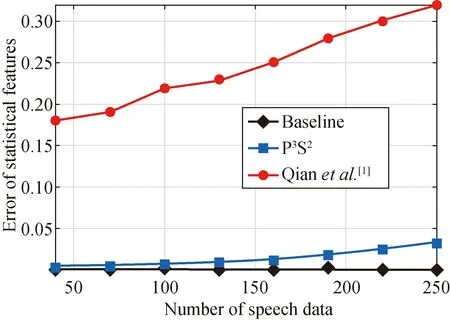
The errors of statistical features in the two analysis tasks are shown in Figs. 5 and 6. It shows that, in the two analysis tasks, the errors of statistical features increase
(a) (b)


(a) (b)

(a) (b)
with the number of speech data, because of the error accumulation effect. In addition, the errors of statistical features in Baseline equal 0, as Baseline does not inject any noise into the users’speech data. Furthermore, the errors of statistical features in Qianetal.[1]are higher than those in P3S2. It is attributed to that, in each dimension, P3S2selects the feature that exhibits the same utility to the users’ speech when sanitizing speech data.

(a) (b)
6 Conclusions
A privacy-preserving protocol in speech data publishing is designed in this paper. Then, we use two real world datasets to evaluate the performance of the proposed protocol. The simulation results validate our work protect data privacy and data utility at the same time.
猜你喜欢
杂志排行

Journal of Donghua University(English Edition)的其它文章
- Emergency Evacuation Plan of the Louvre Based on Cellular Automata Superposition Model
- Undrained Stability Analysis of Three-Dimensional Rectangular Trapdoor in Clay
- Comprehensive Evaluation Method for Safety Performance of Automobile Textiles
- Method for Detecting Fluff Quality of Fabric Surface Based on Support Vector Machine
- Zero-Sequence Current Suppression Strategy for Open-End Winding Permanent Magnet Synchronous Motor Based on Model Predictive Control
- Improved Fibroblast Adhesion and Proliferation by Controlling Multi-level Structure of Polycaprolactone Microfiber