特高拱坝运行初期变形监测预报模型及构建方法
2020-10-24胡江
胡 江
(南京水利科学研究院 水文水资源与水利工程科学国家重点实验室,江苏 南京 210029)
多座200~300 m 级特高拱坝蓄水后短期内均监测到上下游谷幅持续收缩,超出了已有工程经验和规律认知[1-2]。如当水库蓄水并水位长时间处于540~560 m 高程时,溪洛渡拱坝向上游变形,并表现出非线性和显著时效特征,蓄水完成后谷幅并未收敛,影响拱坝运行初期变形性态。除谷幅变形外,运行初期库水温垂直分层、水泥持续水化导致坝体温度场仍处于非稳定阶段。可见,运行初期高拱坝处于非稳定、非线性的环境和条件下。同时,根据国际大坝委员会的统计资料,运行初期失事大坝超总失事大坝数的一半。如Malpasset 拱坝蓄水造成坝基岩体非均匀大变形、坝体溃决,Vajont 拱坝蓄水诱发库岸滑坡,库水翻坝而过、大坝失事,两座拱坝从蓄水到发生事故分别只经过了5 年和3 年[3-4]。可见,建立科学的运行初期安全监测和预报模型,对掌握大坝安全状态、防患于未然意义重大。
变形是监测大坝安全状况的最主要效应量[5-6]。传统统计模型(Hydrostatic Season Time,HST)应用最广泛,但只适用于时效不显著、温度场稳定的运行期[5]。基于实测温度值的模型(Hydrostatic Temperature Time,HTT)采用代表性的温度测点温变作为温度变量,能在一定程度上弥补HST 模型的不足[6]。多元回归模型假设变量间独立,效应量是各变量分量的线性叠加,通过变量分离判断各变量对效应量的影响。当变量间多重共线性时,模型精度差。基于数据的非参数方法如神经网络、支持向量机(Support Vector Machines,SVM)能克服变量间共线性的影响,可建立高精度的非线性模型,在近30 年得到了大量应用[7-8]。但这些方法也存在难以解释大坝性态的缺陷。增强回归树(Boosted Regression Trees,BRT)方法除有非参数方法的优点外,还能在运算过程中随机抽取数据分析变量对效应量的影响,从而为安全监测和预报模型提供了新途径[9]。
本文研究特高拱坝运行初期变形监测预报模型。通过基于主成分的分层聚类法(Hierarchical Clusteringon Principal Components,HCPC)选取代表性温度测点,将其测值作为温度变量;引入包含徐变及其恢复项的时效变量表达式,论证其表达谷幅变形的能力;进而考虑库水位、实测温度、组合时效等变量,应用增强回归树方法提出特高拱坝运行初期变形监测和预报模型,并通过后向消减变量建立优化模型(Simple BRT,SBRT);采用相对影响(Relative Influence, IR)表示各变量对变形的影响,并借助部分依赖图(Partial Dependence Plot,PDP)探寻变量间相关关系及其对坝体变形的影响规律。将该模型应用于某特高拱坝,并将结果与SVM,HST 及HTT 模型对比分析,验证模型的可靠性和优越性。
1 监测预报模型
坝体温度变形在拱坝总变形中占较大比重。从力学观点看,温度变形与温度变化呈线性关系,温度变形分量应选择温度计测值作为因子[5]。当坝体和边界设置足够数量的温度计并连续观测时,实测值足以描绘坝体变温场。此时,温度变形分量δT可表示为:

式中:bi为待定系数;Ti为测点的温度值;N 为选用温度计的数量。
时效是运行初期变形的显著特征,其特点是蓄水后急剧变化,而后随运行时间的增长逐步稳定。时效包括刚固地基上坝体徐变、完整岩体徐变及岩体裂隙节理塑性变形等。同时,相关研究也表明,坝体和岩体的徐变在卸荷后有一定的恢复[5,10]。
徐变和塑性变形引发的时效变形δθ是随时间单调增加的函数,用一阶衰减微分方程的解来描述[5]:

式中:c,γ 均是待定常数;θ=t/100,t 为观测日至始测日的天数。
当库水位呈周期性变化时,徐变恢复项δr可表示为[5]:

式中:di,fi均是待定常数,i=1~2,这里取1。
综合式(1)~(3),并考虑水压变形分量可得到高拱坝蓄水后运行初期的变形预报模型为:
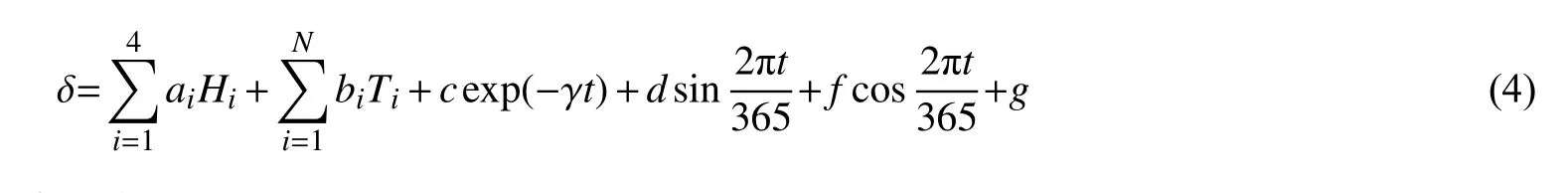
式中:H 为水库水深;g 为待定常数。
2 SBRT 的构建及实现方法
2.1 基于HCPC 的温度因子选取
HTT 模型可显著提高复杂温度条件时的模型精度[6]。但对于特高拱坝,埋设的温度计数量众多,如直接选取全部的库水温、坝体温度等实测数据,会引起过多冗余变量和多重共线性,降低模型的鲁棒性。采用HCPC 法,依据各点测值的变化规律,将测点分为不同的组,并选取各组中典型测点的温度测值作为模型的温度变量。
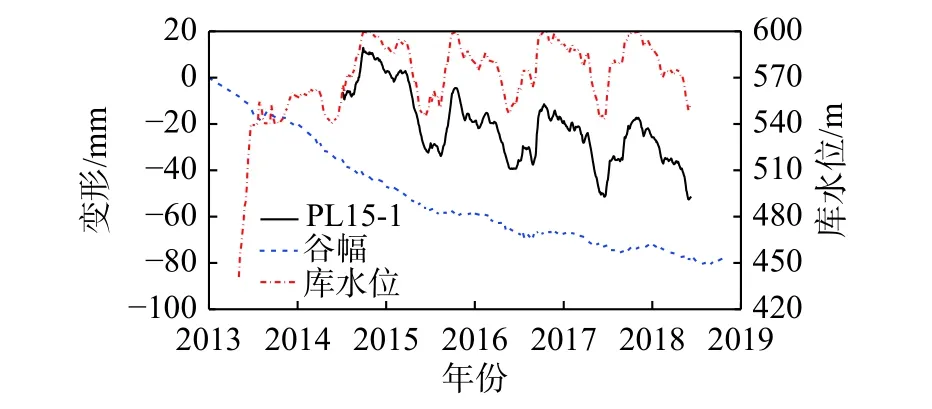
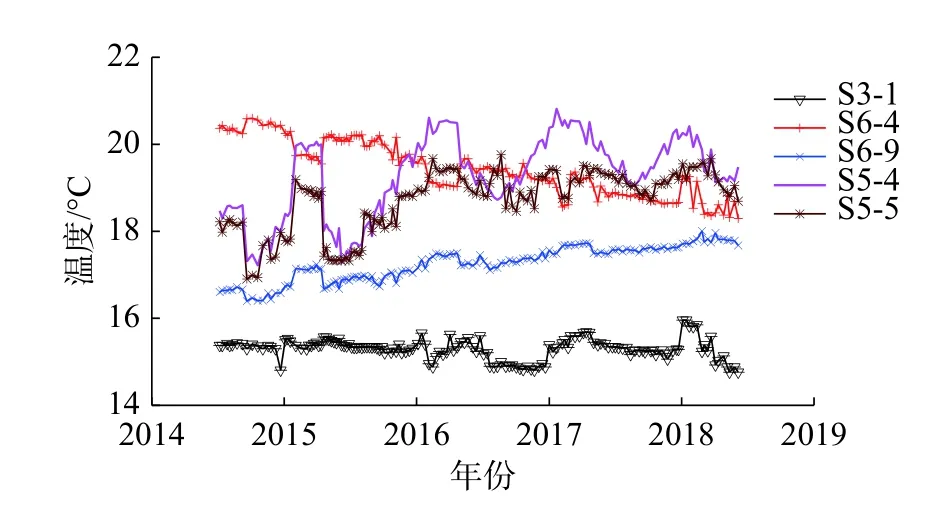
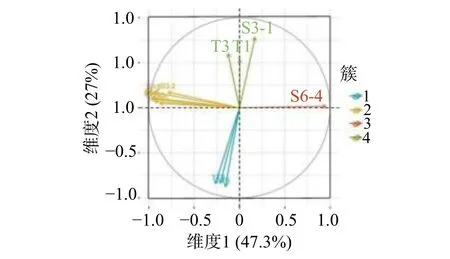
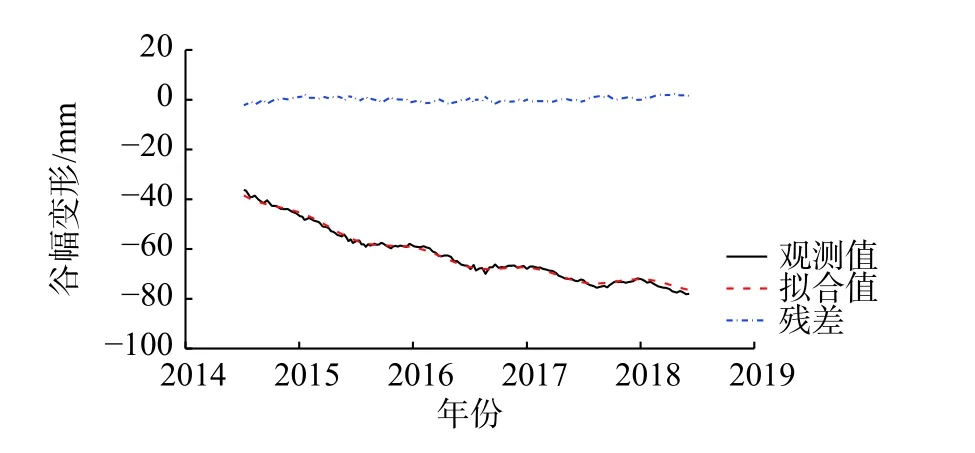
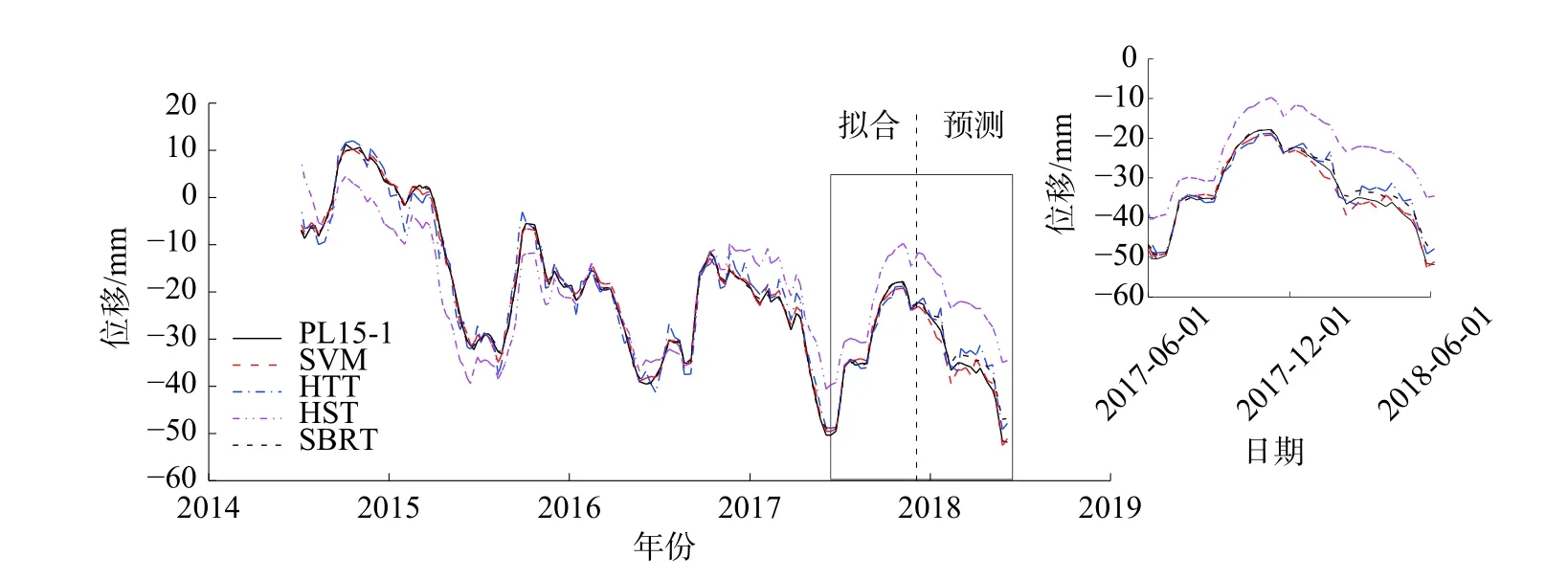
PCA 的基本原理可参考文献[11]。当PCA 和分层聚类均采用欧氏距离度量时,可融合得到HCPC 法,从而更好地描述变量间的关系。对于数据集XKI(K 为变量个数,I 为观测数),PCA 的核心思想是采用S 个(S 式中:xiqk为第q 组的变量i 在观测点k 的值;为各变量在观测点k 的平均值;为第q 组内各变量在观测点k 的平均值;Iq为第q 组内的观测数。 组内方差表征了组内变量的同质性,Ward 准则在聚类时使每个步骤中组内方差增长最小,即组间方差减少最小。确定分组数是聚类分析的核心问题。分层聚类本质是一种嵌套分区,最底层上每个变量均是一个小组,最顶层上所有变量都归属同一个大组。可根据组内方差的增长情况判断最优的聚类分组结果。当分组数从(Q−1)到Q 时的组间方差的增加值ΔQ 远大于从Q 到(Q+1)时的增加值Δ(Q+1)时,最优分组数为Q 组。可采用两种方法来获得最终的聚类分区,一是保持分层聚类得到的Q 个分组;一是借助Kmeans 算法,将分层聚类结果作为初始分区,通过若干次迭代获得改进的分区结果,迭代过程中通过组间方差的比值判断。通常,初始分区不会被完全替换,而是得以改进。 变量的分层聚类分区结果可表示在主成分映射图上或树形图上。 BRT 综合了回归树和Boosting 增强算法。通过回归树拟合一组单模型,并使用增强算法组合回归树的输出以计算总体预测值。BRT 的核心在于,每一棵树是从之前所有树的残差中学习的,利用残差梯度来优化回归树的集成过程。 回归树基于类似样本组中训练数据的递归划分,将特征空间划分为不同的区域,给每个区域以相应的常数,通过将数据划分至不同区域进而得到预测值,其输出是每个组内观察的输出变量的平均值。回归树每次生成树的子节点只有2 个,即递归地二分每个特征,采取平方误差作为评价指标,在每一步选择一个最好的特征来分裂。这样,将输入空间即特征空间划分为有限个单元,并对应以相应的数值。当考虑多个变量时,计算每个变量的最佳节点,并选择导致误差减小最大的节点。因为一个节点中弱相关变量的误差减少一般低于强相关变量,所以算法自动舍弃不相关的变量。Boosting 算法基于训练数据生成的多个简单模型,通过集合中的每个模型的输出的加权和实现整体预测。算法的基本思想是让每个学习者适应前一个集合的残差。 回归树和平方误差损失函数时,原始增强算法的主要步骤可总结如下。 用观测的平均值进行预测: 对于m=1,2,···,M,计算训练集的误差: 绘制训练集的随机子样Sm;考虑Sm,基于前一个集合的残差拟合新的回归树: 更新集合: Fm是最终的模型。通常认为该过程易于过拟合,因为训练误差随迭代而减小。为了克服这一问题,添加正则化参数υ ∈(0,1),从而上一步可以变换为: 已有研究表明,相对较小的正则化参数(υ<0.1)可极大提高泛化能力[9]。通常设较小的正则化参数并考虑多个树,使得误差稳定。随后,使用交叉验证来优化参数。本研究中设定υ=0.001,树的数量上限为10 000。应用十重交叉验证来确定最终集合中树的数量,构建BRT 模型。在此基础上,通过后向消减影响较小的变量,优化建立更为稳健的SBRT 模型。 训练过程主要变量被频繁地选取,次要变量被舍弃,变量xj的IR与它们出现的频率成比例。 式中:Ij为变量xj的相对影响。是在这一节点上xj的改进。变量xj的IR是Boosting 算法所有生成树的平均值。根据IR值来确定变量和效应量的关联性。 使用PDP 通过边际效应识别变量-效应量间的关系。 Xj为变量,在其范围内定义一组等间距值,即对于这些值,模型效应量的平均值计算如下: 基于SBRT 方法的特高拱坝运行初期变形监测和预报模型的实现步骤如下:①监测数据预处理;②基于HCPC 选取典型实测温度变量,确定合适的时效变形表达式;③构建BRT 模型,通过后向消减建立SBRT 模型;④计算各变量的IR,生成部分PDP,判定变量对效应量的影响。 通过平均绝对误差(Mean Absolute Error, eMAE)分析模型的拟合效果,定义如下: 式中:N 为训练或者预测样本集的大小;yi为实测的监测效应量值;F(x)为预测值。 某混凝土双曲拱坝坝顶高程610.0 m,建基面高程324.5 m,共31 个坝段。水库的正常蓄水位、死水位和汛限水位分别为600.0,540.0 和560.0 m,水库具有年调节能力。坝体变形布设坝体垂线监测系统和坝后桥外观大地测量两个监测系统。在坝体典型高程上、下游面各布置1 支温度计观测环境温度,内部则采用应变计组的测温传感器观测内部温度。15#坝段垂线和16#坝段的温度测点布置如图1,其中,T 为温度计,S(k-i)表示k 向应变计第i 个测点。 图1 坝体垂线和16#坝段温度测点布置Fig.1 Layout of embedded pendulums and temperature sensors in Monolith 16 2013 年5 月4 日,导流底孔下闸水库开始蓄水(图2)。2014 年3 月6 日,大坝完成浇筑。2014 年9 月28 日,第一次蓄至正常蓄水位。当前谷幅出现较大变形且仍未稳定(图2)。通过比较15#坝段相同高程两套变形监测系统测值,发现两者在顺河向变位观测值存在3 mm 的差值,但变化规律一致[12]。 图2 蓄水、坝顶径向位移和谷幅变形过程线Fig.2 Time histories of reservoir water level, dam crest displacment and valley contraction deformation 库水位、温度为每日平均测值,垂线测点的监测频次为2~3 d/次。分析的PL15-1 的时间序列为2014 年6 月—2018 年6 月,在此期间坝体经历了4 次完整的加载和卸荷过程。 温度变量采用16#坝段实测温度作为相邻15#坝段的数据。典型测点实测温度过程如图3。可看出,高高程内部测点温度仍有上升的趋势,而坝基内部测点温度变化跟位置有关。应用HCPC 法,以PL15-5 段为例,根据Ward 准则对温度测点聚类,最终确定为4 类(图4),选取的该垂线段的温度计列于表1,同理,其余垂线段的结果也列于表1。高高程垂线测点模型构建还应考虑其下所有典型温度测点。 图3 蓄水过程16#坝段典型高程温度时空变化过程Fig.3 Evolutions of air, water and concrete temperatures of typical points in Monolith 16 图4 PL15-5 库水温和典型段坝体温度测点HCPC 结果Fig.4 HCPC results of reservoir water temperatures and dam concrete temperatures of typical observation points 自蓄水以来,在坝址上下游侧均观测到了显著的、持续收缩的谷幅变形。如图2,坝肩VDL04 测线获得的谷幅变形呈指数函数变化,且存在小的周期性波动。因此,由式(2)和(3)组合表示的时效变量拟合谷幅变形,采用非线性最小二乘法得γ=0.15,R2=0.993,拟合效果如图5。可见,时效变量δθ、δr还可以较好地表达谷幅变形。最终考虑的变量包括库水位、选取的实测温度(表1)、时效变量δθ和δr。 表1 模型构建考虑的实测温度变量Tab.1 Measured temperature variables considered in model construction 一般地,选取样本总数的10%~20%作为预测集[13],考虑到运行初期的非线性,选取15%作为预测集。SBRT 模型构建时的参数按3.2 节方法选取。十重交叉验证得到的最优的树的数量为7 050。为对比分析,还构建了SVM,HTT,HST 等3 种模型,其中,SVM 的因子与BRT 完全一致。SVM 也采用了十重交叉验证优化参数,选择最佳的惩罚因子、不敏感系数取值范围分别为[10, 1 000],[0.000 1, 1],最优值分别为1 000 和0.001。HTT 和HST 采用最小二乘法拟合。HTT 模型的实测温度因子与SBRT 模型相同。各模型的训练和预测的精度列于表2,SBRT 模型最终选取的变量为H,δθ,δr,S6-9,S6-4 和Ta等(其中Ta为空气温度)。各模型的训练和预测效果如图6。 图5 采用时效变量拟合得到的谷幅变形过程线Fig.5 Comparison of observed and fitted values of contraction deformation of VDL04 表2 各模型的训练集和预测集的平均绝对误差Tab.2 Comparisons of mean absolute errors among training and prediction sets of constructed models 单位:mm 图6 各模型的训练和预测效果Fig.6 Comparison of training and prediction effects of models PDP 基于模型学习得到每个变量对效应量的边际效应,为此,可通过PDP 识别变量-效应量间的关系。PDP 可以排除其他变量,仅直观显示一个或一组变量与效应量响应间的关系。因篇幅限制,仅列出了H 和δθ,H 和Ta与PL15-1 的三维PDP 关系,如图7。 图7 变量组合的三维PDP 图Fig.7 3D PDP maps of variable combinations 从图3、表1 可看出,388.7 m 高程以下库水温基本稳定,温度变幅较小,选取了T6,S3-1,S6-4,S6-9 等下游和内部共4 个测点;400~480 m 高程库水温存在年变化,年变幅小于气温,且与气温存在较大的相位差,内部温度主要受环境温度影响,选取了T14 和T15 等2 个环境温度测点;500~540 m 高程库水温存在明显的年变化,但坝体内部水化热温升明显,选取了S5-4,T18,S5-5,T28 等下游和内部共4 个测点;540 m 高程库水温受上游来水温度和气温双重影响,但主要受气温影响,选取了上游测点T29。可见,上游面在温跃层、表温层均选取了典型测点(T15 和T29)。各区坝体温度从封拱后都存在温升现象,内部测点主要受水化热控制,以单调温升为主。底高程温度渐趋稳定,高高程受水化热影响仍持续温升,选取的S5-4 和S5-5测点(图3)尤为典型。BRT 初步选定的变量为19 个,SBRT 削减了影响较小的变量,仅选取H,δθ,δr,S6-9,S6-4 和Ta等6 个变量。 由表2 可看出,SBRT 模型的训练集和测试集精度最高,其次为SVM 模型。HTT 和HST 模型的精度相对较差,HST 模型最差。 从SBRT 模型及其IR分析结果可知,最主要的影响因素是δθ,H 和δr,其值分别为47.15%,27.88%和9.80%。可见,坝体和坝基的徐变及其恢复项对运行初期的变形影响较大,水压荷载次之。对比HTT 和HST 模型,分析HTT 模型能否在一定程度上反映坝体的非稳定温度场,从而改善HST 模型的缺陷。 通过非参数方法和多元线性模型对比可知,受非线性时效和非稳定温度场影响,坝体变形表现出显著的非线性,HST 和HTT 等多元线性模型不适应,其精度不足以准确预测预报。SBRT 和SVM 均具备较高的精度,但SVM 不能较好地联系和分析坝体变形机制,SBRT 根据IR判断变量对效应量的影响大小,并使用PDP 通过边际效应识别变量对效应量的影响规律。 由图7 可知,库水位上升时,坝顶变形与库水位之间近似呈线性关系,且变形与库水位变化之间具有同步性、连续性的特征。库水位的多次式影响不显著。 由于坝体、坝基徐变的影响,运行初期坝体整体表现出向上游的变形趋势,2015 年6 月后变形速率有所减小,但未收敛。加载卸荷引起的弹性位移也有相对较强的影响。考虑到时效能很好地表示谷幅变形,可将坝体总体出现相对向上游变形的特征归结于谷幅变形。此外,坝体内部温度的缓慢回升也使得坝体产生了轻微的向上游变形[14-15]。可见,蓄水初期特高拱坝的变形是一个复杂的非线性过程,其影响因素主要包括时效、库水位、温度回升引起的回弹变形等。 本文提出了特高拱坝运行初期变形监测和预报模型,得到以下主要结论: (1)通过HCPC 方法选取典型温度测点,以其温度测值作为温度变量,减少了实测温度变量的冗余,温度变量选取结果也反映了环境和坝体内部温度非稳定特征。 (2)引入包含徐变及其恢复项的运行初期时效变量,并对谷幅变形进行了拟合,结果表明时效变量能较好地表征谷幅变形。 (3)提出了基于SBRT 方法的运行初期变形监测和预报模型。工程应用表明,SBRT 模型具有高拟合和预测精度,并能解释各变量的影响大小;SVM 模型次之;HTT 和HST 模型精度差,不适用于运行初期变形预测。借助变量相对影响和部分依赖图,SBRT 模型可直观体现主要变量对变形的影响,有利于特高拱坝运行初期的安全监控和管理。可见,基于SBRT 的特高拱坝运行初期变形监测和预警模型具有显著优越性。
2.2 基于SBRT 的模型构建





2.3 变量相对影响大小的确定

2.4 重要变量的部分依赖图

2.5 监测预报模型的实现流程和性能评价

3 工程应用
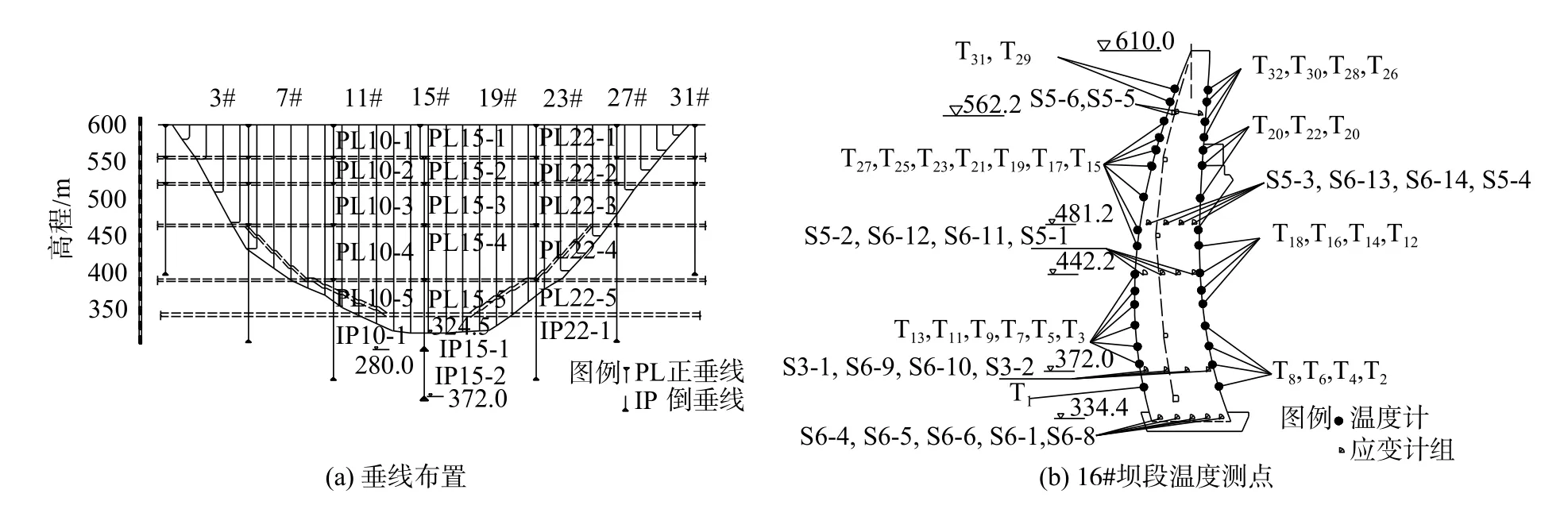
3.1 工程和监测概况
3.2 变量选取

3.3 模型构建

3.4 部分依赖图

4 结果讨论
4.1 变量选取
4.2 模型对比分析
4.3 变形机制分析
5 结 语
