基于PCA-Kmeans聚类法的橡胶树叶片氮含量的近红外高光谱诊断模型研究
2020-10-21钟穗希李子波唐荣年
钟穗希,李子波,唐荣年
(海南大学 机电工程学院,海南 海口 570228)
天然橡胶是一种优质的天然材料,其综合机械性能在军事、医疗等领域起着重要作用[1].由于巨大的经济效益,橡胶树被广泛种植在东南亚的热带和亚热带地区[2-3].研究表明,氮素作为一种重要的营养元素,它与橡胶树的健康状况密切相关[4-5],缺乏或过量使用氮肥都可能会对橡胶树造成不利影响[6].此外,有文献指出,橡胶树叶片的氮含量与橡胶的产量成正相关.因此,实时评估橡胶树叶片中的氮含量对指导橡胶树的精确施肥和估计橡胶产量具有重要意义.尽管经验丰富的工人可以对橡胶树的营养状况进行初步分析,但是这种分析方法准确性较低,并且相当依赖于熟练工人的经验.目前,基于近红外高光谱技术的研究大多数集中在一年生的水果和蔬菜作物上.已有研究表明,近红外光谱技术可被有效应用于黄瓜叶片的氮含量监测[7].此外,高光谱技术还可用于探究小麦的富氮波段和对其指标的估算[8];基于高光谱数据的小麦叶片氮含量监测可为小麦氮含量的诊断打下基础[9].有研究表明,多光谱技术可有效用于果树叶片氮素水平的快速检测[10];也有研究表明,可见-近红外光谱可有效用于估测西红柿叶片的氮含量[11].Tian等人将植被信息应用于检测水稻叶片的氮含量水平[12].有研究表明,水稻冠层光谱可有效检测水稻的氮含量水平[13].亦有研究表明,近红外光谱技术可有效用于评价橘子叶片的氮含量水平[14].此外,高光谱技术对于预测辣椒叶片氮素的空间分布也有较高的精度[15].由于氮素在橡胶树叶片上的分布并不均匀[16-18],而在当前的研究中,常选用随机点光谱选择方法、感兴趣区域光谱选择方法、原始平均光谱法来进行高光谱数据选点,上述传统的光谱选取方法均没有对橡胶树叶片高光谱数据的氮素敏感区域进行选择.因此本研究提出一种新的基于空间-光谱信息的光谱聚类方法,并通过聚类手段来研究橡胶树叶片的氮素敏感区域,旨在提高光谱诊断模型的预测精度.为达此目的,本研究使用GaiaField光谱仪来采集割胶期橡胶叶片的高光谱数据,并通过PCA-Kmeans方法和基于空间-光谱信息对高光谱数据进行聚类,分别以21组聚类区域光谱数据为基础,结合偏最小二乘算法(Partial least square,PLS)建立了橡胶树氮素的光谱检测模型,同时对比传统选点方法的建模结果来探究橡胶树叶片的氮素敏感区域,目的是为高光谱数据的选点过程提供理论依据.
1 材料与方法
1.1 试验材料本研究的样本均选自2017年5月25日从海南省儋州市采集的橡胶树叶片,为了确保样本的随机性,所有样本均从实验地点随机选取.在该实验中,在去除不完整和有明显病虫害的叶片之后,从所采摘的叶子中共挑选了147片成熟叶子.研究所用仪器设备为:GaiaField-F-N17近红外高光谱仪和实验室光谱采集暗箱GaiaSorter.高光谱仪的光谱分辨率为4 nm,在840~1 680 nm波长范围内以3.3 nm的采集间隔均匀地采集光谱数据.
1.2 数据获取以GaiaField-N-17E高光谱仪测量叶片样本的光谱反射率.在实验前,为了避免灰尘等外在因素的影响,叶片表面均用蒸馏水清洗干净.测量叶片前,需要盖上设备镜头盖以获取黑帧图像,并且拍摄99%反射率的标准白板以获取白帧图像.于GaiaSorter暗箱获取完整叶片样本的高光谱图像数据,随后,在计算机中进行高光谱数据的存储、黑白校正和分析,并对原始高光谱数据的非样本区域进行了置0处理.
根据现有文献,凯氏定氮法是一种可靠的氮素含量的检测方法[19-20],因此,在本研究中,以凯氏定氮法所获得的氮素含量来作为橡胶树叶片样本的参考值.详细流程如下:在摘除叶片的叶柄后,将叶片样本加热到105~108 ℃进行杀青,并在60 ℃的环境下将叶片进行干燥和研磨.称取0.08~0.10 g样本和量取3 mL浓H2SO4,混合后于380 ℃恒温1.5 h.为样液澄清并表现出褐色时,加入H2O2并持续加热5 min后冷却,之后便可以把溶液加入凯氏氮含量分析仪(FOSS 2300)来检测样本的氮素含量.在进行称重、溶液混合以及把溶液加入凯氏氮含量分析仪等操作时,由于人工操作以及机器误差等不确定的因素可能会给研究带来检验误差,因此,为了尽可能地提高所测叶片氮含量的准确性,对上述操作均重复两次并取其平均值,并以此作为最终氮含量的参考值.
1.3 PCA-Kmeans聚类方法已知氮素在作物叶片上的分布并不均匀,因此本文提出对高光谱数据的像素点进行聚类,以探讨哪一类区域的光谱数据最适用于橡胶树叶片氮含量诊断模型的建立.为了进一步探究不同采点区域对橡胶树高光谱数据氮素含量模型的影响,需要对高光谱数据的空间信息进行提取.基于颜色识别的机器视觉分割方法已被广泛用于马铃薯、柑橘、苹果和其他样品的损伤识别[22-24],然而,没有研究表明橡胶树叶片的颜色与氮素的分布有关.
高光谱数据由于其数据的多波段性,基于颜色识别的计算机视觉方法并不适用于橡胶树叶片高光谱数据的聚类过程,因此,本研究提出了一种新的基于PCA-Kmeans法的高光谱数据像素点的聚类方法,这使得具有相似光谱特征的光谱数据形成了一个簇,并使簇间的差异尽可能的大,从而实现了基于空间-光谱信息的橡胶树叶片高光谱数据的聚类.
1.3.1 基于PCA特征向量的重加权PCA是最流行的高光谱数据预处理方法之一,是一种降维和特征提取的方法,在统计学中被广泛使用[25-27]. 基于最大化方差的理论,PCA方法旨在找到一系列线性变换矢量来最大化原始数据的方差[28],它可以通过解决以下优化问题来获得线性变换系数μ:
式中X表示经过去均值处理后的高光谱数据:X=(x1,x2,x3,…,xj,…,xn),其中,xj为经过第j波段的二维图像经整形处理后所得到的一维向量数据.优化结果为:μTXXTμ=μTλμ=λ,特征向量的方向为投影的最大方差的方向.
于是在本实验的PCA主成分分析中,以最大方差所对应的主成分特征向量作为高光谱数据的空间特征.
1.3.2 Kmeans均值聚类为了对PCA提取的高光谱数据的空间特征进行聚类,本研究选取了Kmeans聚类算法.K均值聚类算法(Kmeans)是一种迭代求解的算法,具有无监督、迭代速度快的特性[29-30],其在数据空间的聚类方面具有较好的效果.Kmeans的优化目标是使类重心与内部成员位置距离的平方和最小,其优化目标如下式:
其中x(j)为聚类结果中每一个簇的样本坐标,μi为每一个聚类簇的聚类中心的坐标.
在本研究中,Kmeans的具体流程如下:
步骤1:将每个经PCA提取的样本重加权系数矩阵整形为1维列向量;
步骤2:以每个样本的像素权值为变量,单独输入Kmeans函数中,对权值进行聚类;
步骤3:对Kmeans聚类结果进行规则化,并与高光谱数据的索引进行匹配;
步骤4:改变K的取值K=(2,3,4,5,6,7),重复上述操作.
在Kmeans对每个样本的权值系数进行聚类,并匹配到原始高光谱数据的索引后,按照索引获取高光谱数据中相应区域的光谱数据,进行平均,得到PCA-Kmeans聚类簇区域的平均光谱.
1.4 平均光谱的获取办法对每个聚类类别的所有聚类簇数据求平均值,以获得ASC(Average Spectrum of Cluster).为了验证基于PCA-Kmeans的ASC光谱数据的建模效果,出于比较的目的,本研究还参考了三种常用的高光谱数据采集方法,获得了147个高光谱数据样本的ASRS(Average Spectrum of Random Spectrum)和ASROI(Average Spectrum of ROI)以及ASL(Average Spectrum of Leaf).
ASRS、ASROI采样的详细过程如下:在叶片区域中将每片橡胶叶片的高光谱数据从上到下分为六个部分,并从每个部分中随机选择三点光谱,对所选光谱数据进行平均以获得ASRS.对于ASROI,通过平均尺寸为40 * 40像素的矩形框内的1 600个相邻光谱数据,以获得ASROI.至于ASL则是以完整橡胶树叶片的所有像素点作为感兴趣区域,并对该感兴趣区域求平均,以获取ASL光谱数据.
1.5 模型构建本研究中,从样本中随机抽取118个样本用于建模,余下29个样品用于验证模型的精度.本文采用偏最小二乘回归进行模型的建立,偏最小二乘法是通过最小化误差的平方和来找到数据的最佳匹配函数,它兼并多种算法的特点,包括多元线性回归分析、典型相关分析以及主成分分析,因此,偏最小二乘法在建立回归模型上具有表达更全面信息的能力.为此,采用21组聚类簇光谱数据、随机点平均光谱、ROI平均光谱、原始平均光谱数据来分别建立回归模型,并且以均方根误差(RMSE)、决定系数(R2)及相关系数作为评价模型预测精度的指标.
1.6 统计分析软件采用Matlab 2017b对试验数据进行统计分析.
2 结果与分析
2.1 橡胶树叶片的氮含量本研究中,分别应用凯氏定氮法对所采集的147个橡胶树叶片进行了叶片氮素含量参考值的测定.本研究根据所测得的橡胶树叶片的氮素含量对其进行了划分,其结果如下.

表1 本研究所用样本的氮含量等级划分
所采集的橡胶树叶片样本涵盖了各个等级,这有利于建立精准模型.
2.2 橡胶树叶片的光谱数据本研究所基于的SpecView高光谱仪采集的近红外波段高光谱数据是一种三维数据,它不仅具有光谱维信息,而且还具有空间维信息.为了验证本研究所基于的假设,即不同采点区域光谱数据的特征不同,本研究以第十号叶片样本的高光谱数据为例,采集了橡胶树叶片高光谱数据不同采点区域的光谱数据,如图1所示.

图1 橡胶树叶片高光谱数据不同像素位置的光谱曲线
图1是分别从高光谱数据的叶边缘区域、叶肉区域、叶片侧脉区域和主叶脉区域人为地选择单一像素点对应的光谱数据,即1*1*230的光谱数据,各像素点光谱数据均有着相似的趋势.在926 nm~1 300 nm区域均有着较高光谱反射率,在1 376 nm~1 526 nm存在明显的下降趋势,在1 450 nm区域有一个较高的吸收峰.
但是不同像素点光谱数据在反射率上存在较大的差异,在1 076 nm~1 100 nm区域和1 226 nm~1 376 nm区域,光谱反射率的差异尤为明显.橡胶树叶片不同选点区域的高光谱数据确实存在较大的光谱差异,这说明不同选点区域的内部化学成分存在差异,这可能是因为不同氮素含量所导致.
2.3 PCA重加权结果原始平均光谱的采集过程等效于将高光谱数据中每个像素的光谱权重默认地设置为1,然而,对于高光谱数据而言,每个像素的光谱特征是不同的,均匀的权重不利于研究橡胶树叶片高光谱数据的空间特性.从统计意义上讲,方差越大意味着离散数据的波动越大,数据越分散, 因此,基于放大像素点权重差异的目的,本研究选择PCA方法,在最大方差的反向上提取高光谱数据的空间特征,这为后续Kmeans算法提供了聚类依据.
本研究中,采用了PCA重加权方式来探究橡胶树叶片的高光谱数据的空间信息,所有样本第一主成分PC1的贡献率均大于85%,因此本研究中,选用PC1的特征向量作为重加权系数.在本文中,我们比较了基于PCA重加权系数矩阵和原始系数矩阵(每个元素均为1)之间所有样本的高光谱数据的投影方差,如图2所示.
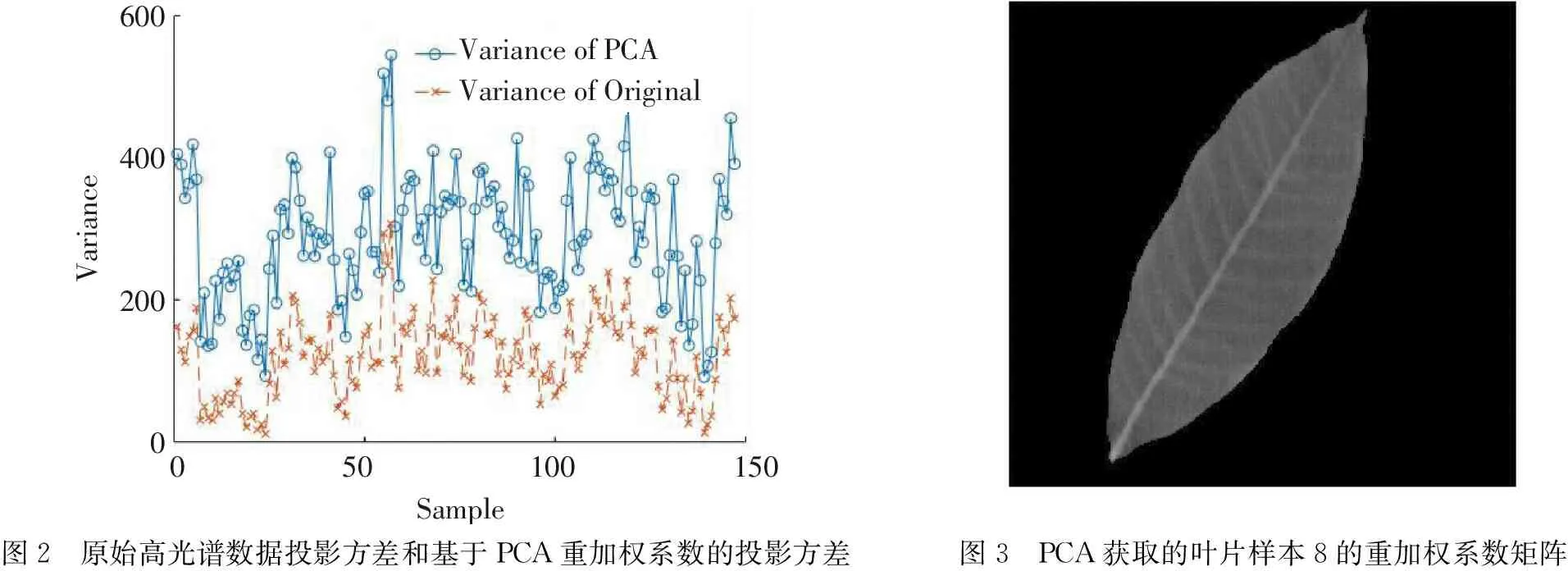
Variance6004002000050100150VarianceofPCAVarianceofOriginalSample图2 原始高光谱数据投影方差和基于PCA重加权系数的投影方差图3 PCA获取的叶片样本8的重加权系数矩阵
为了使得PCA获取的重加权系数矩阵的结果更为直观,对重加权矩阵进行了可视化操作(见图3).
图3中,黑色区域对应权值最小的区域,白色区域对应权值最大的区域,如图所示,重加权矩阵在叶脉、叶边缘、叶肉区域有明显的区分.
结果表明,前者的投影方差明显大于后者的投影方差.由于方差越大,数据的离散度就越大,因此在PCA加权矩阵方向上的投影确实会扩大样本像素之间的差异. 图3显示了一个样本的权重系数矩阵的可视化结果,可视化的权值矩阵可以明显地区分出橡胶叶片的各个区域,即PCA重加权过程确实可以从高光谱立方体的巨大波段数据中找到合适的二维平面.
2.4 高光谱数据聚类的结果对比与分析为使得聚类选点的结果更加直观,本论文对聚类的选点区域进行了可视化操作,其中,8号叶片样本的PCA-Kmeans聚类可视化结果如下图所示:图4至图6是类别2、3和6每个聚类簇的可视化图像,图中白色区域是与每个聚类簇数据集相对应的像素位置,仅在图4(a)中展示了非叶片区域的聚类簇,而在其余图中均不作展示.
聚类结果表明,随着K的增大,叶片区域的区分越精细.如图4所示,当K为3时,可以清楚地区分叶肉区和叶脉区;如图5所示,当K为4时,可进一步地区分出主叶脉和侧叶脉;当K为7时,如图6所示,可将叶片的簇数据集划分得更加细腻,包括叶边缘区域、叶肉区域、侧脉区域和主脉区域.

abc图5 类别3的各个聚类簇的可视化图像

abcdef图6 类别5的各个聚类簇的可视化图像
2.5 最佳氮素敏感区域的选择在橡胶树的生长过程中,营养状况、水分含量以及光照等因素都会影响橡胶树叶片的尺寸和形状,其大小具有随机性,氮素敏感ROI区域的尺寸难以量化,因此本文提出了一种基于PCA-Kmeans的无监督聚类方法,依据像素点的空间特征进行了ROI的划分和选择.
当重加权矩阵分别以K=2~7聚类时,相应的聚类有6种聚类类别,每个聚类类别中的高光谱数据被聚类成相应的K个簇数据集.由于橡胶树叶片的高光谱数据具有非叶片区域和叶片区域,因此在每个类别的簇数据集中均包含了K-1个叶片区域簇ASC(Average Spectral of Cluster)和1个非叶片区域簇数据集ASC0.应当指出,category1的ASC1,即聚类类别1的第二个聚类簇数据集,其对应于高光谱数据的整个叶片区域的平均光谱.
本研究基于PCA-Kmeans法选择了21组聚类簇平均光谱进行建模,其建模结果如表2,由表2可知,聚类类别2的ASC1聚类簇平均光谱所建立的模型的建模精度最佳,其R2达到0.957,RMSE为0.139 9.同时,聚类类别3的ASC2;聚类类别4的ASC2和聚类类别5的ASC3的模型精度也较好,其R2分别为0.941、0.934和0.943.
表2中比较了每个类别中所有ASC的建模结果,从表2可以看出,随着K值的增加,每个类别的整体建模精度都会下降,因此,本论文仅研究了2≤K≤7时的聚类情况.基于类别2的ASC1数据的预测模型,其预测精度最高,R2达到0.957;基于类别6的ASC6的预测模型,其预测精度最差,但其R2也达到了0.863.
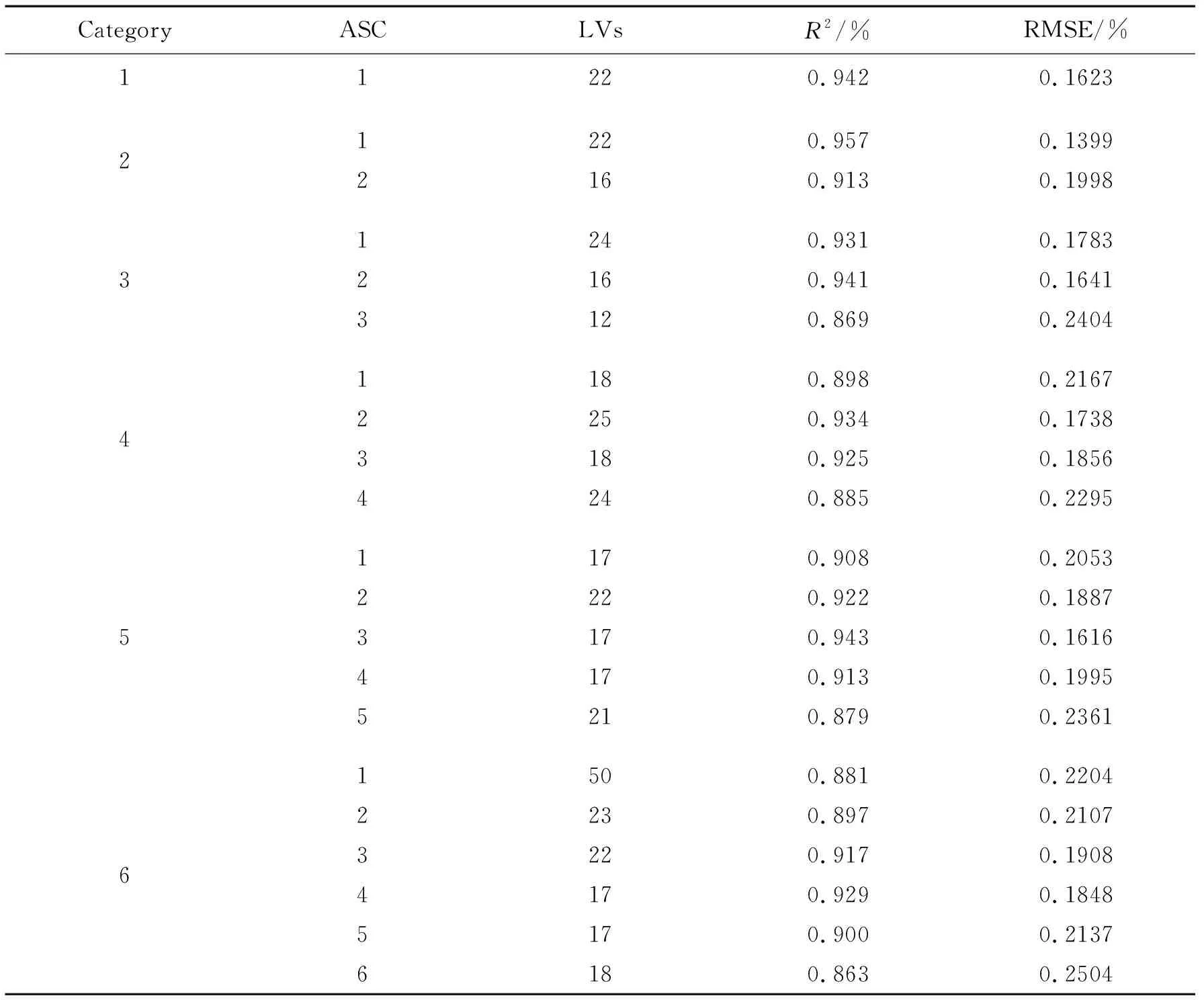
表2 基于所有聚类类别全部ASC所建模型的R2和RMSE对比
结合表2数据和图4~6,始终发现基于叶肉区域聚类数据的模型,其准确性要优于基于其他区域数据模型的准确性,例如,表2类别2的ASC 1的精度明显优于类别2中的ASC 2的精度.聚类ASC 1的光谱数据主要分布在叶肉区域,而ASC 2的光谱数据主要分布在叶肉区域.在类别3的所有建模案例中,最好的模型预测精度出现在ASC 2所建立的模型中,其对应的是叶肉区域的聚类簇光谱数据.同样,在类别4、5、6中,最佳建模精度也出现在基于叶肉聚类簇所建立的模型中.以叶肉簇数据建立的模型似乎总是伴随着最佳的建模精度,而叶边缘和叶脉簇的氮含量检测模型的精度则稍差.
且随着K增大,每个类别中各个簇区域的选点个数减小,其整体建模精度也在下降.该现象在叶边缘区域和叶脉区域尤为明显,其表现为随着所选取的像素点光谱数据越多,其建模精度越高.
2.6 与传统选点方式所建立的氮素检测模型的比较表3展示了ASRS,ASL,ASROI和ASC的建模结果.其中,ASC为基于类别2的ASC 1数据的建模结果.在几种选点方式的建模结果对比中,基于ASC数据的模型其精度最高,基于ASL的模型其精度略低于基于ASC数据的模型精度,但也高于基于其他两个光谱数据的模型的精度.
基于ASRS的建模结果与其他三种选点方式的建模结果差异较大,在此对其光谱的谱形作以下分析.图7和图8分别显示了ASRS和类别2的ASC 1的光谱图像.

reflectance0.700.650.600.550.50107612261376wavelengthbreflectance0.80.60.40.292610761226137615261678wavelengtha图7 ASRS数据的散点图以及其局部区域的散点图
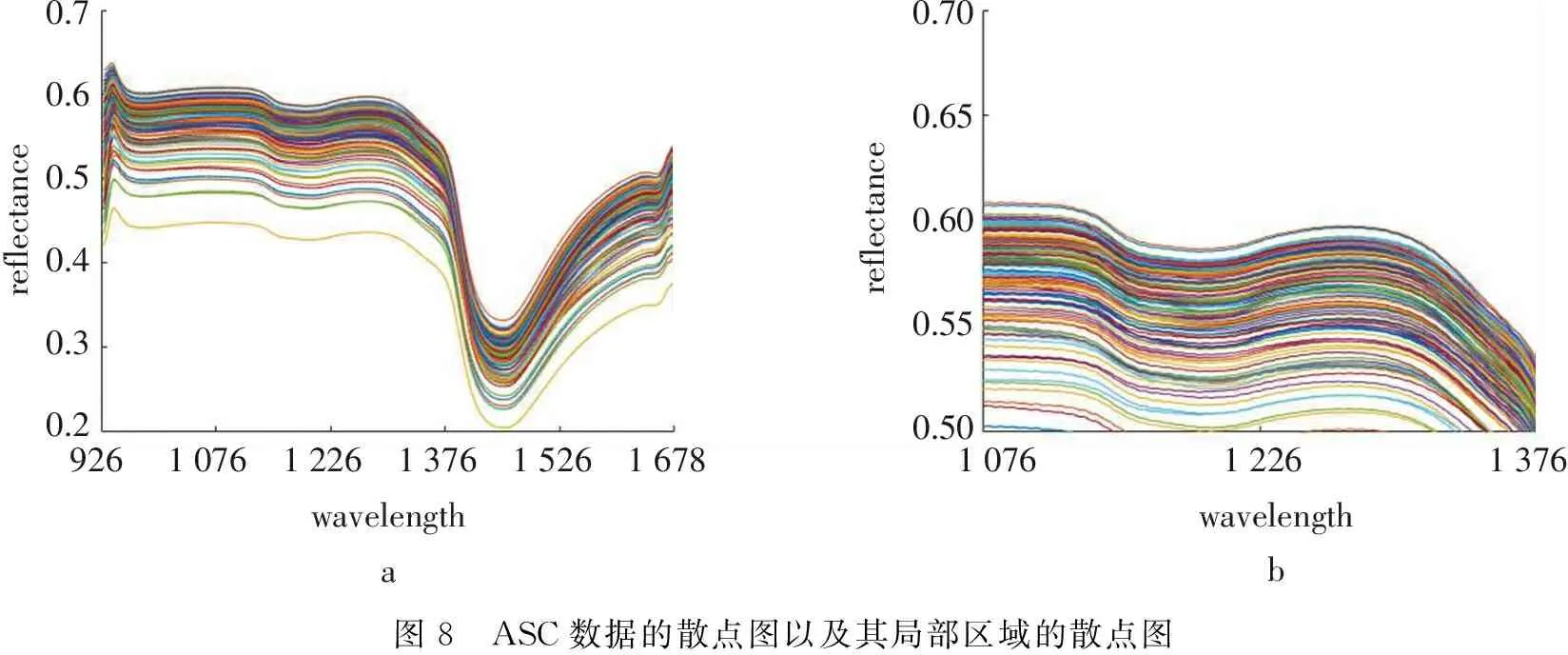
reflectance0.700.650.600.550.50107612261376wavelengthbreflectance0.70.60.50.40.30.292610761226137615261678wavelengtha图8 ASC数据的散点图以及其局部区域的散点图
ASRS和ASC数据在926 nm~1 678 nm波长范围内具有相同的趋势,但是反射率的局部位置有较大差异,ASRS大部分样本数据的反射率高于ASC样本数据的反射率,同时ASRS数据的平滑程度较低,局部位置的波动比较明显,而ASC数据的平滑程度相对理想.
ASRS的建模结果不理想,其决定系数R2较低,仅为0.638,均方根差为0.407 3. 虽然对于ASRS仅仅采集了18像素点光谱,但其建模结果远低于现在所需的建模精度. 与基于ASRS数据所建立的模型相比, 基于ASROI数据所建立的模型其建模精度比ASRS的建模精度好,但与ASC和ASL的建模结果相比仍有一定的差距.ASC所需像素点光谱比ASL所需像素点光谱要少,而其基于类别2的ASC 1所建立的模型,其准确性高于基于ASL数据所建模型的准确性.由表3可以看出,本研究提出的模型比传统方法建立的模型其精度更高,可以用于橡胶树叶片氮素的快速无损检测,并可为橡胶树叶片氮素敏感区域的选取提供参考依据.
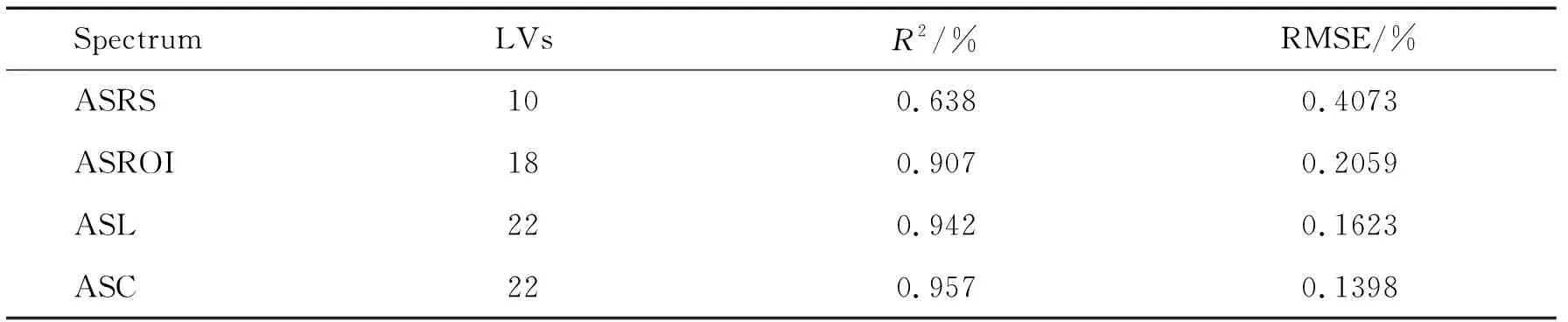
表3 基于类别2聚类簇1、ASRS、ASROI和ASL所建模型的R2和RMSE对比
所以在具体检测中,可以使用基于PCA-Kmeans的无监督聚类方法来进行氮素敏感ROI区域的选择.如果需要进行人工的ROI选取,可选取复数个尺寸较小的ROI区域,使得这些区域可以在避开主叶脉的同时避开侧叶脉区域,仅采集并尽可能多地采集叶肉区域的光谱数据.
3 讨 论
实时监测氮素含量,在橡胶树精确施肥和橡胶产量评估的方面具有重要意义[31].基于氮素在橡胶树叶片上分布不均匀的假设,本论文认为传统的随机选点方法不适用于橡胶树叶片氮素模型的建立,因此有必要研究橡胶树叶片的氮素敏感区域.通过PCA-Kmeans聚类光谱并结合PLSR建立模型,此法可用于检测橡胶树叶片的氮含量,传统选点方法已应用于多项研究之上:黎小清等[31]在叶片非叶脉区域进行随机点光谱选取,并通过基于零阶导数和二次多项式下的SG平滑模式预处理建立了最优的橡胶树氮含量的PLS模型;郑涛等[32]选用10×10单位像素矩阵来提取每个样本的ROI平均光谱;刘燕清等[33]把赣南脐橙叶片的全叶片作为ROI区域,以全叶片平均光谱来研究叶片的氮含量.作为对比,在本次实验中采用了上述传统选点方法来建立模型,这些选点方法分别有随机点平均光谱法、感兴趣区域平均光谱法和原始平均光谱法.建模得到如下结果:ASRS-PLS:R2=0.638,RMSE=0.403 7;ASROI-PLS:R2=0.907,RMSE=0.205 9;ASL-PLS:R2=0.942,RMSE=0.162 3.本研究中采取了基于PCA-Kmeans的聚类选点方法,获取了21组聚类簇平均光谱.基于该方法,本研究的建模结果以聚类类别2的第1组簇数据的模型预测精度最佳,其R2=0.957,RMSE=0.139 9,比传统选点方法的模型精度高.这是由于和之前传统的选点方法相比,本实验在最大方差的方向上提取了高光谱数据的空间特征,并经过Kmeans聚类,把相似权值的高光数据聚成一簇,由此,通过PLSR来探究橡胶树叶片氮素的敏感区域,所以选点过程更具有针对性.
在本研究中,对不同聚类簇区域进行了建模分析,结果显示,叶肉区域簇的建模精度总是比非叶肉区域簇的建模精度高.该结论与温新[34]对于苹果叶片氮素含量的反演结果具有相似的趋势,且本研究的结果表明,远叶柄的叶肉区域的光谱模型精度比近叶柄的叶肉区域的光谱模型精度高.
本研究基于氮素的不均匀分布特性,提取了橡胶树叶片高光谱数据的空间-光谱信息,探究了橡胶树叶片的氮素敏感区域.通过应用PCA-Kmeans聚类光谱并结合PLSR,可准确地预测橡胶树叶片的氮含量.本研究提出的PCA-Kmeans聚类方法,进一步提高了基于高光谱数据的橡胶树叶片氮素模型的精度,这为今后橡胶树氮素含量的预测模型提供了理论依据,同时也为橡胶树叶片光谱诊断模型的在线选点过程提供了指导意见.本研究仅对橡胶树叶片样本的氮素敏感区域进行了研究,所采用的方法在其他营养元素的研究以及在其他作物叶片的氮素敏感区域问题上是否具有范化性还有待进一步的研究.
4 结 论
应用空间-光谱信息的聚类方法可探究橡胶树叶片的氮素敏感区域,所建立的模型可实现橡胶树叶片氮素的快速无损检测.该方法可为橡胶树氮素检测模型的采集过程提供参考依据,同时,也可为实现橡胶树营养元素的快速无损检测提供技术支持.
