高准确度网络安全意识个体评估及群体指数构建方法
2020-10-21李蕊潘丽敏郝靖伟张寒青罗森林吴倩
李蕊, 潘丽敏, 郝靖伟, 张寒青, 罗森林, 吴倩
(北京理工大学 信息与电子学院,北京 100081)
随着网络安全事件的日益频发以及社会工程学等技术在网络攻击中的广泛使用,网络安全意识淡薄成为信息领域制约社会信息化发展的主要因素之一[1].
目前,评估网络安全意识的方法主要有基于问卷调查的评估方法、基于机器学习的评估方法和基于模拟攻击的评估方法等. 基于问卷调查的评估方法调查范围广、易于统计分析. 如Kruger等[2]提出的网络安全意识评估框架,可用于评估组织成员的网络安全意识. 基于机器学习的评估方法普遍使用无监督学习,不依赖标签数据. 如孙夫雄[3]提出的基于信度分析和聚类算法的网络安全意识评估模型,对个体网络安全意识评估为低、中和高三个层次等. 但是,基于机器学习的评估方法通常难以解释评估结果的物理含义,而基于问卷调查的评估方法使用的数据也缺乏客观性. 与前两者相比,模拟攻击方法从行为角度出发,可不依赖主观调查信息. 如绿盟公司提出的安全意识评估服务,通过绿盟云平台给公司的被测试员工发送钓鱼测试邮件,评估公司员工安全意识. 然而模拟攻击多数使用欺骗攻击方法,仅是web应用安全的一部分,评估准确度不足.
针对以上问题,本文提出了一种高准确度网络安全意识个体量化评估及群体指数构建方法. 该方法利用多源数据融合主观评判和客观评估,从而提高了个体网络安全意识评估方法的准确度和客观性;该方法利用监督信息对个体无标签行为数据进行客观评估,从而易于解释评估结果的物理含义;同时,通过引入Grubbs来弱化群体中的异常点信息,该方法实现了对群体网络安全意识指数的科学计算,为群体网络安全意识评估提供有效方法.
1 方法原理
1.1 原理框架概述
图1所示为本文所述评估方法的原理图. 该方法将评估网络安全意识分为3个层次,即个体网络安全意识量化、个体网络安全意识分级和群体网络安全意识量化. 该方法首先要完成对问卷安全数据、PC终端安全数据和移动终端(本文中提到的移动终端皆基于Android操作系统)安全数据等多源数据的采集和预处理. 过程Ⅰ中,针对预处理后的问卷安全数据,该方法使用层次分析法设定问卷指标权重,使用加权计算得到个体在问卷上的安全得分. 针对预处理后的PC终端和移动终端安全数据,该方法基于混合回归模型得到个体在PC和移动终端上的安全得分. 过程Ⅱ中,针对问卷、PC和移动终端3个安全得分,该方法利用改进的标签传播算法对量化后的数据分级. 过程Ⅲ中,该方法利用Grubbs准则构建指数公式计算群体网络安全意识指数.
1.2 数据采集及预处理
本文从安全配置、安全操作、安全知识等方面采集了问卷调查数据、PC终端安全数据和移动终端安全数据等. 其中,基于国民网络安全素养评估指标体系[4]设计了网络安全意识调查问卷. 问卷题目的设计以获取用户网络安全意识的真实情况为目标,因此,问卷题目中不使用含褒义或贬义的具有诱导性和倾向性的词语. 由于采集到的原始数据中含有噪声、空缺值,存在维度过高等问题,需要对原始数据进行预处理. 本文采取的预处理方法包括使用等深分箱法剔除异常值、数据标准化、使用均值法补全空缺值和使用包装法进行特征提取等.
1.3 个体网络安全意识量化
个体网络安全意识量化包括两个部分,量化问卷安全得分和量化终端安全得分. 通过层次分析法[5]对网络安全意识调查问卷题目设定权重,然后利用加权计算得到问卷安全得分. 通过德尔菲法[6]分别为预处理后的PC终端安全数据和移动终端安全检测数据设定分数标签[0-100],然后利用混合线性回归模型量化得到问卷安全得分. 其中专家模型为支持向量回归机,门限函数为BP神经网络算法,概率加权函数为EM算法. 首先利用K-means聚类算法对具有分数标签的终端安全数据设定不具有物理含义的类别标签,然后使用多层感知机对聚类后带有标签的终端安全数据分类,最后利用支持向量回归机得到个体的终端安全得分. 交替训练专家模型支持向量回归和门限函数多层感知机,直到均方误差σMSE<1为止.
1.4 个体网络安全意识分级
基于个体网络安全意识量化方法可得到特定个体的网络安全意识的问卷安全得分、移动终端安全得分和PC终端安全得分等. 在此基础上,本文进一步提出了基于改进标签传播算法的个体网络安全意识分级方法.
标签传播算法[7]是一种基于图的半监督学习方法,其基本思路是用标签节点的标签信息去预测无标签节点的标签信息. 标签传播算法存在对标签数据的依赖,而网络安全意识评估相关的数据源往往没有标签. 为解决这个问题,本文提出了一种改进的标签传播算法(rank label propagation,RLP),适用于网络安全意识评估.
改进的标签传播算法具体实现步骤如下.
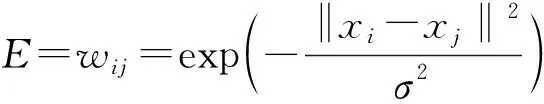
步骤2设定监督信息即2个极端标签,监督信息1为安全得分全为100分的样本为最优等级,监督信息2为安全得分全为0的样本为最差等级. 随机设定监督节点外的其他节点的标签;
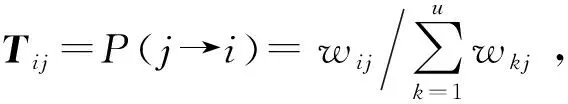
步骤4在将网络安全意识分为最优和最差两类后,选取聚类结果为网络安全意识最差的数据进行步骤2和步骤3,将网络安全意识分为低和中两类. 然后选取分类结果为网络安全意识最优的数据进行步骤2和步骤3,将网络安全意识分为高和较高两类. 最终得到网络安全意识评估的4类输出. 算法实现的伪代码如下.
Algorithm:改进的标签传播算法—RLP(G,n,α,σ)
Input:G=(V,E)-全连接图,|V|=n-节点个数,
σ-高斯函数带宽参数,α-平衡参数
Output:个体网络安全意识等级Label[1…n]
基于E构造传播矩阵T
初始化除监督节点的标签得到矩阵Y
t=0
repeat
A(t+1)=αTA(t)+(1-α)Y;
t=t+1
until迭代收敛至A*=(1-α)(I-αT)-1Y
fori=2 tondo
Label[i]←argmax1≤j≤|y|(A*)ij
ifLabel[i]=1
该节点构建图G1=(V1,E1)
else
该节点构建图G2=(V2,E2)
end for
for(v,e)∈G1,G2do
基于e构造传播矩阵T
初始化除监督节点的标签得到矩阵Y
t=0
repeat
A(t+1)=αTA(t)+(1-α)Y
t=t+1
until迭代收敛至A*=(1-α)(I-αT)-1Y
fori=2…ndo
Label[i]←argmax1≤j≤|y|(A*)ij
endfor
endfor
1.5 群体网络安全意识量化
基于个体网络安全意识分级方法可得到特定个体的网络安全意识等级. 在此基础上,针对多个个体构成的群体数据,本文进一步提出了群体网络安全意识的评估方法. 群体网络安全意识量化方法应达到两个目标,弱化群体中的异常点对群体的影响和量化结果具有单调性. 其中,单调性是指群体中等级高的个体越多,群体网络安全意识量化结果越高,群体中等级低的个体越多,群体网络安全意识量化结果越低[8-11].
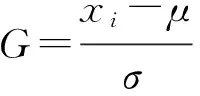
(1)
式中:N为群体网络安全意识指数;Normalize为min-max归一化,指数范围为[0,1];NRj为每个等级的数量;Rj为网络安全意识等级;Wi为权重,如表1所示,其中β为偏移值.

表1 不同数据情况下的权重值
2 实验分析
2.1 个体网络安全意识量化评分实验
2.1.1实验数据
采集问卷安全数据、PC终端安全数据和移动终端安全数据等样本数据共1 261组. 通过数据预处理,最终得到可用样本数据984组. PC终端中的特征为UAC状态、账户启用数量、共享文件夹开启数量、公共网络防火墙是否开启、专用网络防火墙是否开启、浏览器smart screen数量、防火墙规则数量、防火墙开启类别数量、用户密码永不过期数量,移动终端中的特征为手机是否被root、应用程序危险权限数量、是否有开机密码、敏感信息数量、麦克风权限赋予数量、相机权限赋予数量等.
2.1.2评价指标
测试选择均方误差MSE作为个体网络安全意识量化方法的评价指标. 均方误差代表真实数据与拟合数据之间的差异程度,均方误差越小,预测效果越好. 均方误差定义如式(2)所示为
(2)
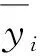
2.1.3实验结果与分析
将预处理后的15维984组终端安全特征数据和问卷安全数据按照80%和20%的比例分成训练集和测试集. 训练集中的数据用于进行混合回归模型的构建,测试集中的数据用于对预测效果评价. 混合回归模型中,K-means算法的初始参数k=2,多层感知机算法的权重优化器为lb fgs. 设置两个隐藏层:第一层隐藏层有5个神经元,第二个隐藏层有3个神经元. 随机数生成器的状态为1,正则化项参数为1×10-5,支持向量回归机算法选用线性核函数,皆为最优参数.
实验结果显示,经过10折交叉验证后得到PC终端安全数据的MSE误为4.03,移动终端安全数据的MSE误为7.94,实验预测效果较好. 针对某个个体的网络安全意识量化实验结果如图2所示.
2.2 个体网络安全意识分级算法对比实验
2.2.1实验数据
实验数据为984组经过个体网络安全意识量化评分后得到的数据. 其中包含6维特征变量,分别为问卷安全得分中的网络安全知识安全得分、网络安全认知得分、网络法律伦理得分、网络安全能力得分、PC终端安全得分以及移动终端安全得分.
2.2.2评价指标
理论上理想情况下将分级算法的结果映射到直线上,各级之间不存在重叠部分且分布均衡. 因此本文选择聚类结果经过降维后重叠的数量ON值(overlapping number)和各类分布的标准差CSD值(class standard deviation)作为评价指标.
ON值代表聚类结果降维后重叠的数量. ON值越小说明各类重叠的数量越低,聚类算法区分不同类别的能力越好. 计算ON值,首先建立一个大小为1×984的空矩阵s;接下来分别获取聚类结果经过降维后得到的类别为低、中、较高、高的数据点,然后在这些数据点在空矩阵中对应的位置上加1,最后统计空矩阵中大于1的数量.
CSD值代表聚类结果降维后各类分布的离散程度. CSD值越大说明各类分布的离散程度越高,聚类算法区分不同类别的能力越好. 其定义如公式(3)(4)所示.
(3)
(4)
式中:N为降维后聚类得到的类别的数量4;xi为类别i=1,2,3,4映射到直线上的长度;μ为平均值,maxi为降维后类别i中包含的数据点坐标的最大值;mini为降维后类别i中包含的数据点坐标的最小值.
2.2.3实验结果与分析
分别使用K-means和RLP对经过个体网络安全意识量化后数据进行实验. K-means算法中簇的数量设置为4,改进的标签传播算法中折中参数为1,构图参数为0.7,皆为最优参数. 由于算法的结果均有一定的随机性,因此经过多次实验,直至实验输出ON值、CSD值的平均值稳定为止. 其中使用TSNE降维算法将所有特征映射到直线上.
图3显示,本文提出的RLP算法的ON值为113.16,CSD值为11.497,K-means算法的ON为186.96,CSD为28.336. 实验结果表明,RLP算法在实验中ON值和CSD值均比K-means算法小.
2.3 群体网络安全意识指数计算实验
2.3.1实验数据
构建了11个不同数据粒度、控制变量和变量的数据集,如表2. 等级1、2、3、4分别代表个体网络安全意识低、中、较高和高.
2.3.2实验结果与分析
使用本文提出的基于Grubbs准则的群体网络安全意识指数构建方法对11个数据集进行实验,实验结果如图4. 实验结果表明,该方法能够弱化群体中的异常点对群体的影响且量化结果具有单调性.
3 讨 论
个体网络安全意识量化评分实验中,混合回归模型对终端安全得分预测均方误差均不大于10,表明基于混合回归模型的量化方法预测效果较好. 个体网络安全意识分级算法对比实验中,改进的标签传播算法的ON值平均比K-means少60%,CSD值平均比K-means小59.4%,证明了改进的标签传播算法对于个体网络安全意识分级具有更好的效果. 群体网络安全意识指数计算实验中,基于Grubbs准则的群体指数构建方法能够反映群体网络安全意识水平和量化群体内部共同意识,证明了该算法能够对群体网络安全意识进行科学有效的评估. 表3为网络安全意识评估方法功能对比. 对比4种网络安全意识评估方法的功能,相对于其他3种方法,本文所述方法皆具有3个及以上功能上的优势,证明了本文所述方法更加全面、准确.
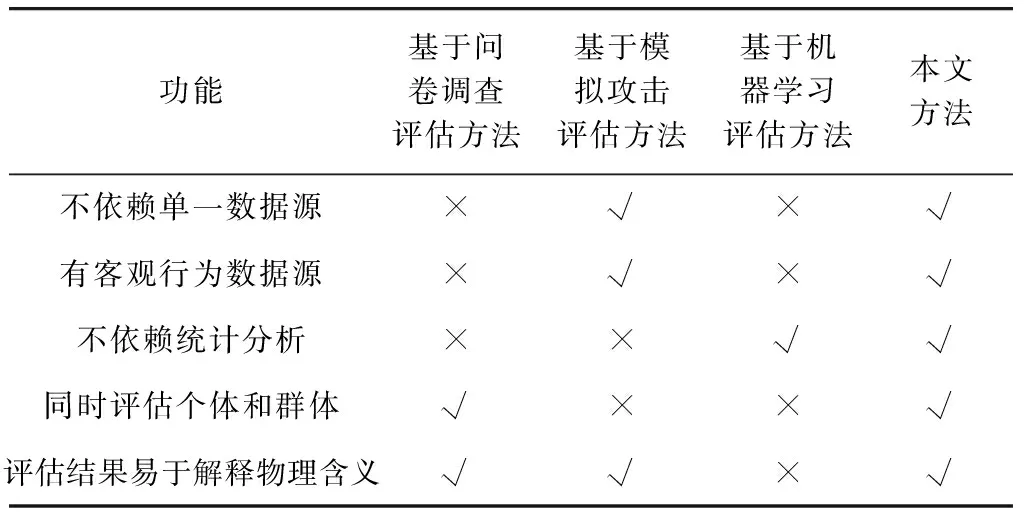
表3 网络安全意识评估方法功能对比
4 结 论
本文提出了一种高准确度的网络安全意识个体量化评估及群体指数构建方法,该方法利用多源数据,融合了主观评判和客观评估系统实现了3个层次的网络安全意识的评估. 实验结果表明相对现有方法,该方法更加准确、客观,实现了网络安全意识的客观行为和主观意识的量化表达,为网络安全意识的全面提升和闭环促进提供了技术方法. 本文的方法同样存在一些局限,采集到的移动终端和PC终端的数据为静态行为数据,未来考虑加入动态行为数据,使网络安全意识评估方法更加准确.
