藏语阅读中中央凹词频效应及对副中央凹预视效应的影响*
2020-10-20高晓雷李晓伟白学军
高晓雷 李晓伟 孙 敏 白学军 高 蕾,3
(1 西藏大学高原脑科学研究中心,拉萨 850000)(2 天津师范大学心理学部,天津 300387) (3 天津大学管理与经济学部,天津 300072)
1 前言
阅读是一项高级、复杂的认知活动,是现代社会人们获取信息的重要途径之一。在阅读过程中,读者主要通过中央凹区域获取信息,而副中央凹区域在信息获取中的作用也很重要(Yang,Wang,Xu,&Rayner,2009;Yan,Richter,Shu,&Kliegl,2009;Angele,Slattery,Yang,Kliegl,&Rayner,2008;Drieghe,Rayner,&Pollatsek,2008;Liu,Inhoff,Ye,&Wu,2002;Pollatsek,Tan,&Rayner,2000)。读者能通过预视加工从副中央凹区域获取一定的信息,从而促进阅读效率的提高,被称为预视效应(闫国利,陶佳雨,孟珠,姜琨,2019;Rayner,1998,2009)。预视效应是影响文本流畅阅读的重要因素,它能够帮助读者更有效的阅读,进而影响整体阅读效率(Perea,Teiero,&Winskel,2015;Rayner,2009;Pollatsek &Rayner,1982)。对预视效应的研究有利于人们从更为精细的角度了解阅读加工本质(Yan et al.,2009;Angele et al.,2008;Tsai,Lee,Tzeng,Hung,&Yen,2004;Pollatsek et al.,2000),也有利于解决E-Z 读者模型和SWIFT 模型对于阅读过程中注意资源的分配是序列分布还是平行分布的争议(马国杰,李兴珊,2012)。
Rayner 设计了边界范式来研究副中央凹的预视加工(Rayner,1975)。通过这个范式,在保证自然阅读的前提下,研究者可以操纵目标词预视信息的特征,进而精确考察阅读过程中读者从注视点右侧获取信息的范围、类型及副中央凹处信息加工的情况(Niefind &Dimigen,2016;Sommer,Li,Niefind,Dimigen,&Wang,2014;白学军 等,2011;闫国利,巫金根,胡晏雯,白学军,2010;Rayner,2009)。边界范式如图1 所示。

图1 边界范式示意图
采用边界范式,已有研究者对拼音文字和汉语阅读中从副中央凹所能获取的预视信息类型开展了大量的研究。结果发现,无论是在拼音文字阅读中,还是在汉语阅读中,成年读者都可以通过副中央凹预视获取语音和字形信息(Drieghe,Rayner,&Pollatsek,2005;Ashby,Treiman,Kessler,&Rayner,2006;Chace,Rayner,&Well,2005;Miellet &Sparrow,2004;Pollatsek,Lesch,Morris,&Rayner,1992;Yan et al.,2009;Yen,Tsai,Tzeng,&Hung,2008;Liu et al.,2002;Bai,Zang,Yan,&Shen,2006;闫国利,王丽红,巫金根,白学军,2011),而对于语义信息的获取还存在争议(Payne,Stites,&Federmeier,2016;Veldre &Andrews,2016;Hohenstein,Laubrock,&Kliegl,2010;Rayner,2009;Tsai,Kliegl,&Yan,2012;Yan et al.,2009)。但是,在汉语阅读中,多数研究支持了语义预视效应的存在(Li,Wang,Mo,&Kliegl,2017;Yang,Wang,Tong,&Rayner,2012;Yan et al.,2009;王穗苹,佟秀红,杨锦绵,冷英,2009),这一观点也在采用ERP 技术的研究中得到了证实(Zhang,Zhen,Liang,&Mo,2019;Zhang,Li,Wang,&Wang,2015;张文嘉,李楠,关少伟,王穗苹,2014)。
此外,也有研究发现,影响副中央凹预视效应的因素主要来自两个方面(高敏,李琳,向慧雯,隋雪,Radach,2017;白学军 等,2011):第一,被试方面。副中央凹预视效应的大小与阅读技能的高低成正比,阅读技能越高,副中央凹预视效应越大(Radach &Kennedy,2013;Chace et al.,2005;Unsworth&Pexman,2003);第二,实验材料方面。(1)视觉对比和条件变化。有研究者控制了中央凹词n 的可辨别性(清晰、模糊)和呈现形式(大小写字母交替、全部小写),结果发现,当词n 模糊或是由大小写字母交替构成时,副中央凹预视效应会变小(Wang &Inhoff,2010);(2)中央凹加工负荷。已有研究发现,中央凹加工负荷影响副中央凹预视效应的大小(Lavigne,Vitu,&d’Ydewalle,2000)。即相比于低频词和长词,当中央凹词为高频词和短词时,副中央凹预视效应更大(White,Rayner,&Liversedge,2005b;Henderson &Ferreira,1990,1993;Kennedy,Pynte,&Ducrot,2002)。并且,对于中央凹加工负荷在副中央凹预视效应中的作用,已成为众多研究者关注的焦点(王永胜 等,2018;Liu,Huang,Gao,&Reichle,2017;王永胜,2016;Liu,Reichle,&Li,2015;Yan,2015;张慢慢,2015)。词频(高频和低频,相对于高频词,低频词的加工负荷更大)是衡量中央凹加工负荷的标准之一(白学军 等,2011)。在阅读过程中,词频影响着读者的眼动控制(Rayner,2009),读者对高频词注视时间更短,注视次数更少,被称为词频效应(白学军,李馨,闫国利,2015;Vorstius,Radach,&Lonigan,2014;Joseph,Nation,&Liversedge,2013;Rayner,2009;Kliegl,Grabner,Rolfs,&Engbert,2004)。在拼音文字和汉语阅读中,大量的研究证实,在早期指标(首次注视时间、单一注视时间、凝视时间)和晚期指标(总注视时间)上都发现了词频效应的存在。且词频除了会产生词频效应外,还会产生词频的延迟效应(Pollatsek,Juhasz,Reichle,Machacek,&Rayner,2008),即目标词的词频能够对目标词下一个词的识别产生影响。例如,Henderson 和Ferreira (1990)的研究中实验材料为名词-动词词组,同时操纵名词的词频,结果发现,当名词为高频词时,其后动词的注视时间显著小于名词为低频词时的注视时间。也有研究者采用其他方法对词频延迟效应进行了考察,如 Kliegl,Nuthmann 和Engbert (2006)使用回归分析的方法同样发现了词频延迟效应的存在。此外,词频还会影响副中央凹预视效应的大小(Lavigne et al.,2000),当中央凹词为高频词时,相比中央凹词是低频词时,读者的副中央凹预视效应更大(White et al.,2005b;Henderson &Ferreira,1990,1993)。
与英语和汉语相比,在语言类型、书写结构、字/词间标记和透明性等方面,藏语表现出两者兼而有之的特点,即藏语兼具拼音文字和表意文字的特征,而这一特征是其它任何一种语言文字所不具备的,具体见表1。

表1 藏语与英语、汉语的特点比较
眼动记录法是考察阅读过程的重要技术,这一方法可以在比较自然的阅读条件下提供人在进行心理活动过程中的眼球运动数据,研究者可以据此更加精确的推测人们在阅读时的认知加工过程。截至目前,阅读的眼动研究已经有了100 多年的历史。然而,关于眼动控制的本质及其发生的机制问题,目前仍然存在很多的争论和分歧,特别是表现在不同语言文字系统中(臧传丽,孟红霞,白学军,闫国利,2013)。那么,对于藏语这样一种独特的语言,其眼动控制的本质及其发生的机制到底是怎样的?具体而言,在藏语阅读过程中,中央凹加工负荷在副中央凹加工过程中的作用是否会因为藏语是拼音文字,即藏语由字母构成单元,书写结构表现出线性发展的特征,虽然不存在拼音文字中的空格标记,但本身也有其独特的字/词间标记——隔字符,因此而表现出拼音文字的共性;还是会因为藏语所具有的汉语特征,即藏语围绕“基字”前后附加、上下叠写的结构与汉字构字相似,表现出一定的立体性,因此与汉语存在某种共性,目前还缺乏这方面的数据,其内在机制还不清楚,有待实验的证实。此外,对于上述问题的考察,也具有一定的新意和价值:第一、本研究以藏语母语者为被试,有利于了解藏语阅读过程中眼球运动的时空信息,为解释藏语阅读中眼动与认知加工的关系提供基础性证据。与此同时,通过揭示藏语阅读过程的基本规律,为科学提高藏语阅读效率提供实践指导,从而促进藏族文化的传承与传播;第二、本研究以藏语为阅读材料,考察中央凹加工负荷对副中央凹加工的影响,能够在一种独特的文字系统中,寻找到新的证据,有利于推进E-Z 读者模型和SWIFT 模型对于阅读过程中注意资源的分配是序列分布还是平行分布这一争议的解决;第三、本研究以眼动记录仪为研究工具,它作为一种现代测量手段,具有高精度、高生态效度的特点。此外,眼动记录法可以通过记录阅读时的眼动轨迹推测读者的内心状态,是一种通过联机设备对认知过程进行即时测量的最好方法(仝文,刘妮娜,伏干,闫国利,2014;李兴珊,刘萍萍,马国杰,2011;Rayner,2009;闫国利,白学军,陈向阳,2003)。眼动记录法的使用,能够拓展和丰富藏语阅读研究的方法和手段,有利于在更为精细的水平上揭示藏语阅读的内在规律。
已有研究发现,在拼音文字和汉语的阅读过程中,都存在着显著的词频效应(白学军 等,2015;Vorstius et al.,2014;Joseph et al.,2013;Rayner,2009;Kliegl et al.,2004)。此外,已有研究也发现,在拼音文字的阅读过程中,词频除了会产生词频效应外,还会产生词频延迟效应,并影响副中央凹预视效应的大小(Henderson &Ferreira,1990,1993;Lavigne et al.,2000;White et al.,2005b;Kliegl et al.,2006;Pollatsek et al.,2008)。藏语兼具拼音文字和汉语的特点,但它首先是一种拼音文字。因此,在本研究中,对于中央凹词频对副中央凹预视效应的影响,以及这种影响是否会因为藏语是拼音文字而表现出拼音文字的共性,或者因为藏语具有汉语的特点而与汉语存在某种共性等问题的探讨,应该建立在藏语是一种拼音文字的基础之上。因此,依据已有拼音文字中词频效应、词频延迟效应及预视效应的研究结论,本研究设计了两个实验,在实验1 中,考察藏语阅读中是否存在词频效应及词频的延迟效应。当存在词频效应及词频延迟效应时,说明中央凹加工负荷会对副中央凹预视产生影响。以此为前提,在实验2 中,操纵中央凹的词频和副中央凹预视信息类型,采用边界范式,通过对副中央凹预视效应的考察,进一步探讨中央凹加工负荷会对副中央凹预视产生怎样的影响。是对所有类型预视信息的获取都存在影响,还是只会影响其中特定类型预视信息的获取。本研究假设:(1)如果读者对高频词的注视时间更短,注视次数更少,则说明藏语阅读中存在词频效应。如果藏语阅读中不存在词频效应,则说明词频效应不具有跨语言的一致性;(2)如果中央凹词n 为高频词时,读者对词n+1 的加工更容易,注视时间更短,注视次数更少,则说明藏语阅读中存在词频延迟效应,支持E-Z 读者模型关于阅读过程中注意资源的分配是序列分布的观点。如果藏语阅读中不存在词频延迟效应,则支持SWIFT 模型关于阅读过程中注意资源的分配是平行分布的观点;(3)如果读者能从副中央凹提取到语音或字形信息,则说明藏语阅读中存在预视效应。如果藏语阅读中不存在预视效应,则说明预视效应不具有跨语言的一致性;(4)如果藏语阅读中高频中央凹词条件下的副中央凹预视效应更大,则说明中央凹词频影响副中央凹预视效应的大小,支持E-Z读者模型关于阅读过程中注意资源的分配是序列分布的观点。如果藏语阅读中中央凹词频对副中央凹预视效应的大小没有影响,则支持SWIFT 模型关于阅读过程中注意资源的分配是平行分布的观点。
2 实验1:藏语阅读中中央凹词的词频效应及词频延迟效应
2.1 研究目的
考察藏语阅读中不同频率的中央凹词n 是否会影响该词的识别加工(词频效应),若存在影响,那么,这种影响是否能够延迟到读者对下一个词n+1的识别加工(词频的延迟效应)。
2.2 研究方法
2.2.1 被试
西藏大学本科生51 名,其中男生25 人,女生26 人,年龄在19~22 岁之间,平均年龄为M
=20.88(SD
=1.22)岁。所有被试视力或矫正视力正常,母语均为藏语。所有被试开始实验前均需签署知情同意书。2.2.2 实验设计
采用单因素2 水平(词频:高频、低频)实验设计,自变量为中央凹词的词频,因变量为中央凹词n 和词n+1 的各项眼动指标。
2.2.3 实验材料
(1)实验材料的选取
首先,在藏语句子中,藏语短语是组成句子的重要成分,且藏语语序有动词居于句尾、形容词后置于名词等特点(尹蔚彬,2014);其次,对于藏语短语结构类型的研究发现,藏语名词短语是构成藏语句子的核心内容,且名词短语有前置和后置两种形式,有些情况下名词短语必须借助于格助词的连接才能构成一个完整的短语(完么扎西,尼玛扎西,2018);再次,丁海兰(2017)研究也发现,藏语句子成分中的名词短语以名词修饰名词和形容词修饰名词的形式为最多,但只有后置修饰型的短语中没有任何属格结构,即N+A (名词-形容词)型。基于以上三点,并为了排除属格结构对阅读的影响,本研究选择了后置修饰型名词-形容词短语作为词n和词n+1 的目标词。
(2)实验材料的评定(包括词汇评定和句子评定)
①词汇评定。词汇评定包括词频和词长的评定。与词频直接相关的,词长也会对词汇加工产生影响。因此,在严格控制词长的基础上,依据现代藏语频率词典(卢亚军,2007)筛选出高频名词和低频名词共34 对作为词n 的目标词。对所选取的34对高、低频名词的词频和词长进行差异检验,词频检验结果为:t
(33)=2.56,p
=0.013,高频组词频显著高于低频组;词长检验结果为:t
(33)=-1.69,p
=0.096,高频组词长与低频组词长差异不显著。名词n 的词频和词长的平均值和标准差见表2。
表2 名词n 的词频和词长的平均值和标准差(M±SD)
在确定了34 对高、低频名词作为词n 的目标词之后,在每对名词后加上一个使其语义通顺的形容词(作为词n+1 的目标词)组成名词-形容词短语,保证每对名词后所加的形容词相同,且形容词的频率为中等,一共形成了68 个名词-形容词短语。
②句子评定。句子的评定包括合理性和难度的评定。以词汇评定环节确定的68 个名词-形容词短语(34 对)为基础,编制68 个藏文句子(34 个句子框架)。保证每个藏文句子语义通顺、容易理解,且不带有感情色彩,句字长度控制在20~25 个字符之间。此外,保证句子框架中,除名词n 外,其他部分完全一致。请20 名藏族本科生对68 个藏文句子进行合理性和难度评定。句子合理性评定采用5 点计分(1 表示非常不合理,5 表示非常合理),评定结果为:M
=4.23 (SD
=0.32);句子难度评定也采用5点计分(1 表示非常容易,5 表示非常难),评定结果为:M
=1.71 (SD
=0.35)。评定结果表明藏文句子合理且难度不高,符合实验要求。参加词汇评定和句子评定的藏族大学生不参加正式实验。根据实验条件,将最终确定的68 个正式实验句平分成两个block (保证每个句子框架在1 个block 中只出现一次),每个block 包括34 个实验句,其中包含高、低频词n 的句子各有17 句,并加入18 个填充句,实验句和填充句随机呈现。此外,为确保被试认真阅读并正确理解,每个block 中加入18 个问题句,需要进行“是”或“否”的判断,占句子总数的25.7%。每个被试共需阅读70 个句子,即其中一个block 的阅读任务,大约需要30 分钟完成整个实验。
2.2.4 实验程序
本实验采用加拿大SR Research 公司生产的Eyelink1000Plus 眼动仪,采样频率为1000 Hz。被试机屏幕刷新频率为140 Hz,分辨率为1024*768像素。被试眼睛与被试机屏幕之间的距离约为65 cm。参照白学军等(2017)的研究,刺激以 Microsoft Himalaya 32 号字体呈现,每个藏文字符在屏幕上的宽度约为15 像素,形成约0.6 度视角。本实验得到西藏大学伦理委员会批准。实验具体程序为:(1)实验采用单独施测的方式。被试进入实验室之后,首先熟悉实验室的环境,之后向被试简单介绍实验流程;(2)进行校准,以确保眼动记录仪能够准确记录被试的眼动轨迹。采用三点校准,校准的误差值控制在 0.25 以下(闫国利 等,2010;白学军 等,2017);(3)校准完成后,向被试呈现指导语,在被试阅读完指导语后,向被试解释实验内容及要求,并告知被试翻页键和“是”、“否”判断键的位置;(4)开始正式实验。正式实验过程中,被试头部尽量保持不动。被试眼睛在盯着屏幕中央左侧注视点的同时按翻页键开始实验。被试机屏幕会逐屏呈现藏文句子,每屏一个句子,被试按照自己平时的速度认真阅读,并理解句子的意思。在有些句子后面有一个关于此句的判断题,需要被试按“是”或“否”判断键做出判断。如果一个句子阅读完成后没有判断题,被试需要继续盯着屏幕中央左侧注视点的同时按翻页键,开始下一个句子的阅读。正式实验的开始有一个练习阶段,确保被试熟悉实验流程和要求。实验过程中,如果被试需要休息,则暂停实验,休息后需重新校准并再次开始新的藏文句子的阅读。
2.2.5 分析指标
参考以往文献(Rayner,1986;闫国利 等,2019),选取首次注视时间、凝视时间、总注视时间和总注视次数作为分析指标。首次注视时间是指阅读中首次通过某兴趣区的首个注视点的注视时间;凝视时间是指注视点第一次离开某兴趣区之前所有注视时间之和;总注视时间是指兴趣区内所有注视点的时间的总和;总注视次数是指读者在某个区域内所有注视点的个数,它能反映阅读材料的认知加工负荷(闫国利 等,2013)。其中,首次注视时间和凝视时间是反映早期加工水平的指标,总注视时间和总注视次数是反映晚期加工水平的指标(张仙峰,叶文玲,2006)。
2.3 结果与分析
1 名被试的正确率低于70%,其数据被剔除。其余被试的平均正确率为87%。参考已有文献(白学军 等,2017;高晓雷 等,2015;Sheena,Johanna,Simon,&Valerie,2015),根据以下标准对数据进行剔除:(1)被试过早按键或错误按键导致句子呈现中断;(2)追踪丢失的无效数据;(3)注视时间小于80 ms 或大于1200 ms;(4)单句阅读过程中注视点少于5 个。使用SPSS 20.0 对名词n 的眼动数据进行差异检验。根据以上删除数据标准,删除数据占总数据的1.7%,不同条件下名词n 各眼动指标的平均值和标准差见表3。
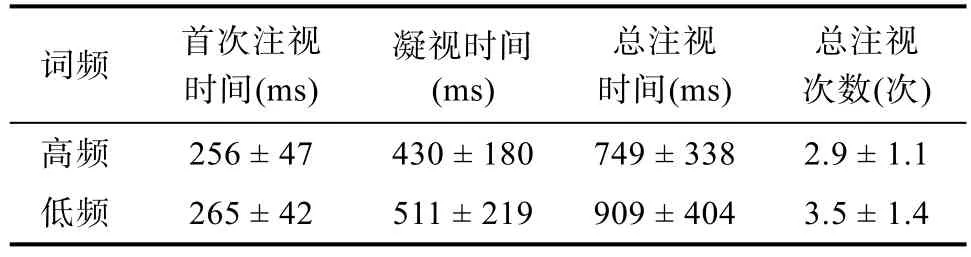
表3 不同条件下名词n 各眼动指标的平均值和标准差(M±SD)
配对样本t
检验结果显示:(1)首次注视时间。不同频率词n 的首次注视时间存在显著差异,t
(49)=-2.02,p
=0.049,Cohend
=0.29,被试对高频词的首次注视时间显著短于低频词,存在显著的词频效应;(2)凝视时间。不同频率词n 的凝视时间存在显著差异,t
(49)=-4.43,p
<0.001,Cohend
=0.63,95% CI=[-117.97,-44.30],被试对高频词的凝视时间显著短于低频词,存在非常显著的词频效应;(3)总注视时间。不同频率词n 的总注视时间存在显著差异,t
(49)=-6.20,p
<0.001,Cohend
=0.88,95% CI=[-212.02,-108.25],被试对高频词的总注视时间显著短于低频词,存在非常显著的词频效应;(4)总注视次数。不同频率词n 的总注视次数存在显著差异,t
(49)=-6.00,p
<0.001,Cohend
=0.86,95%CI=[-0.79,-0.39],被试对高频词的总注视次数显著少于低频词,存在非常显著的词频效应。以上结果表明,与中央凹词n 为低频词相比,当中央凹词n 为高频词时,读者的首次注视时间、凝视时间、总注视时间更短,总注视次数更少,说明藏语阅读中存在显著的词频效应。使用SPSS 20.0 对形容词n+1的眼动数据进行差异检验。删除数据标准与之前保持一致,删除数据占总数据的1.8%。不同条件下形容词n+1 各眼动指标的平均值和标准差见表4。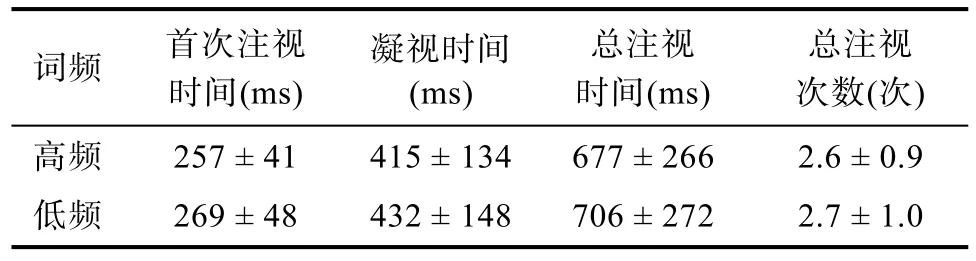
表4 不同条件下形容词n+1 各眼动指标的平均值和标准差(M±SD)
配对样本t
检验结果显示:(1)首次注视时间。中央凹词n 在不同频率条件下,副中央凹词n+1 的首次注视时间存在显著差异,t
(49)=-2.09,p
=0.042,Cohend
=0.30。当中央凹词n 为高频词时,副中央凹词n+1的首次注视时间显著短于中央凹词n 是低频词时,存在显著的词频延迟效应;(2)凝视时间。中央凹词n 在不同频率条件下,副中央凹词n+1 的凝视时间存在显著差异,t
(49)=-2.10,p=
0.041,Cohend
=0.30。当中央凹词n 为高频词时,副中央凹词n+1 的凝视时间显著短于中央凹词n 是低频词时,存在显著的词频延迟效应;(3)总注视时间。中央凹词n 在不同频率条件下,副中央凹词n+1的总注视时间存在显著差异,t
(49)=-2.12,p=
0.050,Cohend
=0.30。当中央凹词n 为高频词时,副中央凹词n+1 的总注视时间显著短于中央凹词n是低频词时,存在显著的词频延迟效应;(4)总注视次数。中央凹词n 在不同频率条件下,副中央凹词n+1 的总注视次数存在显著差异,t
(49)=-2.01,p=
0.039,Cohend
=0.29。当中央凹词n 为高频词时,副中央凹词n+1 的总注视次数显著少于中央凹词n是低频词时,存在显著的词频延迟效应。以上结果表明,与中央凹词n 为低频词相比,当中央凹词n为高频词时,读者对副中央凹词n+1 的首次注视时间、凝视时间、总注视时间更短,总注视次数更少,说明藏语阅读中存在显著的词频延迟效应。实验1 采用单因素两水平实验设计,控制中央凹词的词频,考察藏语阅读中中央凹词的词频效应及词频延迟效应。本实验中有两个重要的兴趣区,即名词n 和形容词n+1。通过对名词n 这一兴趣区的分析发现,在反映早期加工水平的指标首次注视时间、凝视时间和晚期加工水平的指标总注视时间、总注视次数上,都发现了高频词对词n 阅读的促进作用,验证了词频效应的存在;通过对形容词n+1 这一兴趣区的分析发现,在反映早期加工水平和晚期加工水平的指标上,都发现了高频中央凹词n 对词n+1 阅读的促进作用,验证了词频延迟效应的存在。总之,通过对两个兴趣区的分析,得到的结果验证了本实验所提出的假设。
综上所述,实验1 的结果表明,藏语阅读中存在显著的词频效应,且表现在词汇加工的整个过程;藏语阅读中存在显著的词频延迟效应,即中央凹词n 的频率影响着下一个词n+1 的加工,并贯穿于词汇加工的整个过程。
3 实验2:藏语阅读中中央凹词频对副中央凹预视效应的影响
3.1 研究目的
实验1 结果表明,在藏语阅读中存在词频效应及词频延迟效应,即中央凹词n 的词频会对副中央凹词n+1 的加工产生影响。因此,实验2 同时操纵中央凹词n 的词频和副中央凹词n+1 的预视信息类型,采用边界范式,考察副中央凹预视效应及中央凹词频对副中央凹预视效应的影响。
3.2 研究方法
3.2.1 被试
西藏大学本科生 68 名,男女各半,年龄在19~22 岁之间,平均年龄M
=20.68 (SD
=1.21)岁。所有被试视力或矫正视力正常,母语均为藏语。所有被试开始实验前均需签署知情同意书。3.2.2 实验设计
采用2(中央凹词频:高频、低频) × 4(预视词类型:相同预视、音同预视、形似预视、控制预视)两因素被试内实验设计。
3.2.3 实验材料
(1)实验材料的选取实验材料的选取标准和组成短语标准同实验1,选出高、低频名词40 对(共80 个),组成80 个藏语名词-形容词短语。实验2 中的关键词为后置的形容词,根据实验设计,将每个形容词设置为4 种预视条件,即相同预视、音同预视、形似预视和控制(非词)预视,并编制相应条件下的预视词,如图2 所示。

图2 四种预视条件示意图
(2)实验材料的评定(包括词汇评定和句子评定)
①词汇评定(包括词n 的评定和词n+1 的评定)。词n 的评定包括词频和词长的评定。对所选取的40对高、低频名词的词频和词长进行差异检验,词频检验结果为:t
(39)=2.92,p=
0.005,高频组词频显著高于低频组;词长检验结果为:t
(39)=-2.69,p=
0.303,高频组词长与低频组词长差异不显著。名词n 的词频和词长的平均值和标准差见表5。
表5 名词n 的词频和词长的平均值和标准差(M±SD)
词n+1 的评定包括预视词词频、词长的评定和形似词的评定。对相同预视、音同预视和形似预视三个条件下预视词的词频和词长进行差异检验,词频检验结果为:F
(2,117)=1.91,p
=0.153,表明三个条件下预视词的词频差异不显著;词长检验结果为:F
(2,117)=2.47,p
=0.089,表明三个条件下预视词的词长差异不显著。三种预视词的词频和词长的平均值和标准差见表6。
表6 三种预视词的词频和词长的平均值和标准差(M±SD)
此外,请30 名藏族大学生对形似预视词的形似性进行评定,即评定形似预视词与相同预视条件下形容词的字形相似程度。此评定采用5 点计分(1表示完全不相似,5 表示非常相似)。评定结果为:M
=4.01 (SD
=0.35),表明形似预视词与相同预视条件下形容词的字形相似程度较高,符合实验要求。②句子评定。句子的评定包括合理性、难度和可预测性的评定。以词汇评定环节确定的80 个名词-形容词短语(40 对)为基础,编制80 个藏文句子(40 个句子框架)。句子编制规则同实验1。请20 名藏族本科生对80 个藏文句子进行合理性、难度和可预测性的评定。句子合理性评定采用5 点计分(1表示非常不合理,5 表示非常合理),评定结果为:M
=4.12 (SD
=0.31);句子难度评定也采用5 点计分(1表示非常容易,5 表示非常难),评定结果为:M
=1.63 (SD
=0.29);句子的可预测性评定结果为2.5%。评定结果表明藏文句子合理且难度不高,可预测性低,符合实验要求。参与词汇评定和句子评定的藏族大学生不参加正式实验。根据实验条件,对符合实验要求的80 个藏文句子进行拉丁方平衡,分成8 个block,每个block中包括高、低频名词-形容词短语中的一组,和预视词中的一个类型,且含有数量相同的四种预视类型,即每个block 的实验材料包括40 个正式实验句,其中高、低频实验句各有20 个,每种预视词类型10 个。此外,在每个block 中都加入20 个相同的无关填充句,实验句和填充句随机呈现。为确保被试认真阅读并正确理解,每个block 中加入20 个问题句,需要进行“是”或“否”的判断,占句子总数的25%。每个被试共需阅读80 个句子,即其中一个block的阅读任务,大约需要35 分钟完成整个实验。
3.2.4 实验程序、分析指标
同实验1。
3.3 结果与分析
删除标准同实验1,删除数据占总数据的5%。使用SPSS 20.0 对数据进行分析处理,对目标词的眼动数据分别进行基于被试的分析(F
)和基于项目的分析(F
),被试在目标词上各眼动指标的平均值和标准差见表7。
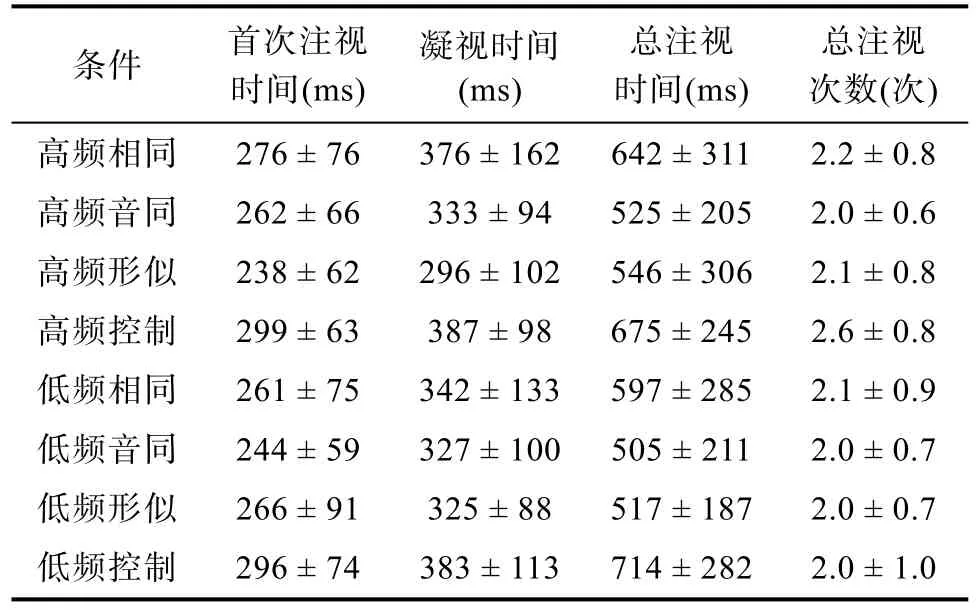
表7 被试在目标词上各眼动指标的平均值和标准差(M±SD)
实验2 采用两因素被试内设计,控制中央凹词的词频和副中央凹预视词的类型,考察藏语阅读中中央凹词频对副中央凹预视效应的影响,进一步确认中央凹词频是对所有类型预视信息的获取都存在影响,还是只会影响其中特定类型预视信息的获取。实验首先对藏语阅读中能从副中央凹获取什么类型的预视信息进行了考察,数据分析结果表明:反映早期加工水平的指标首次注视时间、凝视时间和晚期加工水平的指标总注视时间、总注视次数,都发现了读者可以从副中央凹预视中获得语音和字形信息的证据,验证了预视效应的存在;其次,词频与预视词类型的交互作用分析结果表明:在反映早期加工水平的指标首次注视时间和凝视时间上,都发现了高频中央凹词对字形的预视信息的获取存在更大促进作用的证据。进一步说明了中央凹词频会影响副中央凹预视效应的大小,支持了E-Z读者模型关于阅读过程中注意资源的分配是序列分布的观点。
综上所述,实验2 的结果表明,藏语阅读中存在显著的副中央凹预视效应,读者能够通过预视提取到语音和字形信息,且词频只在词汇加工的早期对形的预视信息的提取产生影响,即在形似预视条件下高频词的预视效应更大。
4 讨论
本研究以藏族大学生为被试,以眼动记录仪为工具,严格控制中央凹词频和副中央凹预视词类型,对于藏语阅读中中央凹词频对副中央凹预视效应的影响进行了考察。实验1 的结果显示,藏语阅读中存在词频效应及词频延迟效应;实验2 的结果显示,藏语阅读中存在显著的副中央凹预视效应,且词频在词汇加工的早期对形的预视信息的提取产生影响。实验1 和实验2 的结果表明,在藏语阅读过程中,中央凹加工负荷影响副中央凹加工过程,并且这种影响只存在于特定类型预视信息的获取上。本研究结果支持了E-Z 读者模型关于阅读过程中注意资源的分配是序列分布的观点。
实验1 的数据分析结果表明,当中央凹词n 为高频词时,与中央凹为低频词相比,读者的首次注视时间、凝视时间、总注视时间更短,总注视次数更少,说明藏语阅读中存在显著的词频效应,与已有研究结果一致(白学军 等,2015;Vorstius et al.,2014;Joseph et al.,2013;Rayner,2009;Kliegl et al.,2004)。对于这一结果,可以从如下两个方面来解释:第一,已有关于汉语和印欧语系语言的研究均发现了词频效应的存在,表明词频效应具有跨语言的一致性(李馨,李海潮,刘璟尧,白学军,2017)。本研究同样发现了藏语阅读中词频效应的存在,进一步证明了词频效应跨语言一致性的存在和正确性;第二,本研究被试的母语是藏语,而藏语是他们彼此之间较多采用的交流用语。因此,频率较高的藏语词汇在藏族的日常生活中较常见,也相对更容易理解,所以激活时间较短;而频率较低的藏语词汇在日常生活中相对不常见,也较难理解,所以激活时间较长,这也是藏语阅读中出现词频效应的原因之一。此外,通过实验1 的数据分析也发现,当中央凹词n 为高频词时,与中央凹为低频词相比,读者对副中央凹词n+1 的首次注视时间、凝视时间、总注视时间更短,总注视次数更少,说明藏语阅读中存在显著的词频延迟效应,与已有研究结果一致(Pollatsek et al.,2008;Kliegl et al.,2006;Henderson&Ferreira,1990),验证了E-Z 读者模型的观点。该模型认为,词频延迟效应的发生可能是因为眼跳发生在注意转换之前,相当于注视点在副中央凹词上,但此时中央凹词注意转换的第二阶段即语义通达阶段尚未完成。本研究控制了藏语材料中除了词频以外的其他属性,当中央凹为高频词时,注意转换的第二阶段即语义通达速度相应较快;而当中央凹为低频词时,其注意转换的第二阶段即语义通达速度就会相应减慢,所以会在副中央凹上表现出词频延迟效应。
实验2 的数据分析结果表明,在藏语阅读中,读者可以从副中央凹预视中获得语音和字形的信息,这个结果得到早期、晚期指标的支持,与已有研究结果一致(Yan et al.,2009;Ashby et al.,2006;Bai et al.,2006;Drieghe et al.,2005;White,Rayner,&Liversedge,2005a;Chace et al.,2005;Tsai et al.,2004;Liu et al.,2002)。但是,只在早期指标上发现词频与预视词类型的交互作用,即形似预视条件下高频词的首次注视时间和凝视时间显著短于低频词,说明词频只在词汇加工的早期对形的预视信息的提取产生影响,这个结果与Henderson 和Ferreira(1990)的研究结果一致,验证了E-Z 读者模型的观点。该模型认为,单词识别包含注意转换和眼跳两个过程,并且这两个过程是独立的、互不干扰的。此外,该模型强调注意的序列转移,它认为,预视效应之所以会产生,其原因在于,注意转换分为两个阶段;第一个阶段为熟悉性检验阶段,第二个阶段为词汇通达阶段。同样,眼跳也包含两个阶段,第一个阶段为不稳定阶段,该阶段眼跳可以取消;第二个阶段为稳定阶段。且注意转换和眼跳这两个过程不是完全同步的,在眼跳的第二阶段尚未完成时,注意转换的第二阶段(词汇通达)已经完成,即相当于注视点在中央凹词上,但是注意已经转移到副中央凹词进行预加工,所以产生了预视效应。而藏语阅读中词频只在早期指标上对预视效应产生影响,其原因在于,注意转换过程中的第一个阶段即熟悉性检验相当于词汇加工的早期,会受到词频的影响。但是眼跳过程的第二阶段不再受词频因素的影响。所以,词频在藏语阅读的早期阶段对预视效应有影响,晚期没有影响。
综上所述,本研究通过两个实验考察了藏语阅读中是否存在词频效应及词频效应对副中央凹预视效应的影响。实验1 的结果表明,藏语阅读中存在词频效应且会延续到副中央凹词n+1 上,再次证明了词频效应跨语言一致性的存在(李馨 等,2017),且为实验2 考察中央凹加工负荷(词频)对副中央凹预视效应的影响提供前提基础。另外,实验2 的结果进一步表明,藏语阅读中中央凹词频在早期指标上对副中央凹预视效应有影响,这与拼音文字的研究结果一致。这一结果说明,虽然藏语与汉语同属于汉藏语系,在书写结构上也表现出与汉语类似的立体性,但汉语是表意文字,而藏语本身是拼音文字,且在语言类型、发音透明性以及字/词间标记上表现出与拼音文字相同的特征(白学军 等,2017)。因此,在藏语阅读中,中央凹加工负荷对副中央凹预视效应的影响表现出拼音文字所具有的共性。另外,本研究中发现的藏语阅读中存在的词频延迟效应及副中央凹预视效应,支持了E-Z 读者模型中有关副中央凹序列加工的观点。
5 结论
(1)藏语阅读中存在显著的词频效应,且表现在词汇加工的整个过程;(2)藏语阅读中存在显著的词频延迟效应,即中央凹词n 的频率影响着下一个词n+1 的加工,并贯穿于词汇加工的整个过程;(3)藏语阅读中存在显著的副中央凹预视效应,读者能够通过副中央凹预视提取到语音和字形信息。藏语阅读中中央凹词频影响副中央凹预视效应的大小,且词频只在词汇加工的早期对形的预视信息的提取产生影响,即在形似预视条件下高频词的预视效应更大;(4)词频延迟效应及副中央凹预视效应的发现,支持了E-Z 读者模型中有关副中央凹序列加工的观点。
