结合模型集成与特征融合的图像拷贝检测
2020-10-19武光华张旭东毛财胜
武光华,张旭东,葛 维,孙 鸽,毛财胜
1.国网河北省电力有限公司 电力科学研究院,石家庄 050021
2.国网河北省电力有限公司,石家庄 050000
3.大连理工大学 软件学院,辽宁 大连 116024
1 引言
随着网络技术的快速发展,数字图像以其易于存储和传播等特点受到广泛应用,同时图像处理技术以及图像编辑软件也日益成熟,且使用门槛越来越低,使得网络上存在着大量拷贝图像[1]。拷贝图像来自于对原始图像进行一种或多种处理变化后的图像,常见的图像处理方式有缩放、裁剪、压缩等。如果这些图像没有经过原图像的版权拥有者的授权而被商业使用,则会对版权人的利益造成侵害。因此检测图像的非法拷贝成为一项亟需研究和发展的领域[2]。
目前,图像版权保护技术可以分为主动式和被动式。(1)主动式即图像水印技术[3],通过将一些标识信息直接嵌入图像的数字载体中同时不影响原图像的使用价值。当图像内容被修改时,水印将会发生变化,从而检测出原始图像是否被拷贝攻击。(2)被动式即基于内容的图像拷贝检测技术[4](Content-Based Copy Detection,CBCD),其本质上属于图像检索技术[5]。CBCD 通过提取图像的内容特征,根据图像特征来检索出拷贝图像。CBCD 相对于数字水印技术的主要优点是不需要对原图像添加额外的标识信息,成本低。基于内容的图像拷贝检测重点在于对图像特征的刻画,要求提取的图像特征针对各种图像攻击具有不变性。现有的图像拷贝检测方法根据其特征提取方式可以简单划分为传统方法以及深度学习方法。
传统的图像拷贝检测方法在早期阶段主要采用全局特征表征图像,其中具有代表性的是基于顺序测度的方法。如Bhat 等人[6]通过顺序测度方法首先将图像分割成若干个子图像,然后计算每个子图像块的平均灰度值,以子图像的平均灰度值大小排序关系作为图像全局特征。此方法描述了图像灰度值的空间结构,因此对于旋转、裁剪、拉伸等变换攻击改变了图像整体结构,基于顺序测度的方法将会失效。Kim等人[1]提出一种基于分块离散余弦变换(Discrete Cosine Transform,DCT)的拷贝图像检测方法,通过DCT 将图像从空间域变换到频域,以变换系数计算顺序测度来提取全局特征。虽然能够有效对抗图像翻转、缩放以及高斯噪声等变换方式,但对于图像旋转、裁剪等变换鲁棒性依然不高。为了解决旋转变换失真的问题,Xu 等人[7]在分块DCT 的基础上,使用DCT中频系数进行顺序测度,同时针对图像旋转变换提出补偿算法。Wu等人[8]使用椭圆环进行图像划分,以每个椭圆环的平均灰度值计算顺序测度。椭圆环在一定程度上具有旋转和拉伸的不变性,因此提取的全局图像特征同样具有该类性质。
SIFT(Scale Invariant Feature Transform)特征[9]提出之后,基于局部特征的拷贝图像检测在应对多种变换攻击的鲁棒性上有了很大的提升。SIFT特征及其扩展,如基于主成分分析SIFT 特征[10](Principal Components Analysis SIFT,PCA-SIFT)、加速鲁棒特征[11](Speed Up Robust Features,SURF)等对旋转、尺度缩放、亮度变化保持不变性,克服了全局特征在图像裁剪、旋转等攻击失效的缺点。针对这些局部特征具有高维性且生成的特征点数目较多的问题,Jegou 等人[12]提出VLAD(Vector of Locally Aggregated Descriptors)方法对局部特征进行聚合得到紧凑的特征表示。然而相比于全局特征,局部特征整体维度依然较高,匹配速度慢,缺少了空间上下文信息,因此会产生很多的错误匹配。
随着卷积神经网络(Convolutional Neural Network,CNN)在图像分类问题上取得突破性成功之后[13],基于深度学习的方法通过CNN 学习图像特征,从而代替了传统的手工特征设计。最近的一些工作致力于基于ImageNet[14]预训练分类模型的图像特征提取。根据提取位置的不同分为高层特征与低层特征。高层特征即CNN 最后一层特征(除去分类层),具有很强的语义信息,属于全局特征[15]。MOP 方法[16]为了避免全局的CNN 特征包含太多的空间信息,将图像分为多个尺度并以图像块的形式提取高层特征,采用VLAD方法对同一尺度上的图像块特征进行聚合。后来的研究表明低层特征,即CNN 中间卷积层特征,具有局部特征的性质[17]。因此可以借助传统方法对局部特征的处理经验对CNN局部特征进行处理[18]。
然而目前并不存在任何一种图像特征描述能够对抗所有不同形式的图像攻击。现有方法虽然在图像特征表示上做了很多改进,但都局限于单个特征表示。借鉴了Li等人在图像检索[19]、视频检索[20]以及图像标注[21]中将多个特征集成表示的思想,本文在CBCD框架的基础上提出一种基于CNN的多特征融合的图像拷贝检测方案,通过特征融合的方式提升提取特征的鲁棒性,从而提升拷贝检测结果的准确性。具体地,(1)本文首先分析了每种类型的CNN特征在图像拷贝检测的优势与不足,然后提出通过多种特征融合的方式实现不同特征之间的优势互补。(2)为了避免单个模型在特征表示上的局限性,并进一步增强特征多样性,本文在预训练模型的基础上使用合成的拷贝数据进行微调,针对图像拷贝检测问题通过度量学习策略对抗拷贝攻击带来的特征差异,集成微调后的度量模型与预训练的分类模型实现多模型特征融合,进一步提升检测精度。
2 基于多种特征融合的图像拷贝检测
一般的基于内容的图像拷贝检测过程如图1所示,其中特征提取过程是整个算法的核心,最理想的情况是提取出的特征能够对各种图像拷贝攻击具有不变性,虽然两张图像在像素空间中具有较大差异,但在特征空间中的距离依然很近。通过在特征空间进行匹配,就可以准确判断图像之间的拷贝关系。图1 中虚线框为索引库的构建过程,整个过程是离线进行的,而拷贝检测过程为下面的分支,检测效率由特征提取以及匹配过程共同决定,特征提取过程过于复杂或者提取的特征维度过高都会负面影响到检索效率。

图1 基于内容的图像拷贝检测流程
前文提到SIFT 特征或者CNN 卷积层特征是一种局部特征,可以应对多种变换攻击,但由于局部特征具有可重复提取的性质,仅依靠局部特征很难表征高层的语义信息,如拍摄角度、图像类别等,容易造成误匹配。本文在ResNeXt-101[22]模型上首先提出融合高层语义特征以及低层局部特征,使图像表征更为全面;其次提出集成预训练模型以及在拷贝数据集上微调后的模型,实现模型之间的特征互补。
2.1 多层特征融合
ResNeXt-101 共有5 个卷积模块,每个模块之间特征图大小相同,而模块之间通过下采样实现特征图大小减半,第五个卷积模块后经过全局平均池化得到2 048维的特征向量,之后通过全连接层实现分类。表1列出了ResNeXt-101的具体结构,其中C=64 表示分组卷积的基数(Cardinality),方括号表示一组残差块,里面描述了各个卷积层的卷积核尺寸以及输出通道数,方括号后表示残差块的堆叠次数。

表1 ResNeXt-101的网络结构
2.1.1 高层语义特征
本文选取ResNeXt-101 第五个卷积模块输出的特征图作为高层语义特征,通过R-MAC(Regional Maximum Activations of Convolutions)特征聚合[23],得到 2 048 维特征向量,依次进行L2 范数正则化,PCA 降维,再进行L2范数正则化,得到1 024维特征。R-MAC通过在特征图上产生多个不同大小不同位置的区域,每个区域内通过最大池化得到区域特征向量,对所有区域特征对应元素求和即得到最终聚合后的图像特征。R-MAC特征相比全局最大池化(Maximum Activations of Convolutions,MAC)而言保留了更多信息,相比全局平均池化(Sum-Pooled Convolutions,SPoC)而言则抑制了响应值较低的背景信息,且最终输出特征维度相同。
2.1.2 低层局部特征
本文选取ResNeXt-101 第四个卷积模块输出的特征图作为图像局部特征表示。假设输入图像大小为224×224×3,则第四个卷积模块输出的特征图大小为14×14×1 024,相比原图缩小了16倍。可以简单认为特征图上每个像素位置对应原图16×16的一个区域,不同通道的特征图在同一个像素位置组成的1 024维特征向量即为原图对应区域的局部特征。因此,类似于SIFT特征,一张图像共由196 个1 024 维局部特征表示。如果对局部特征直接进行串联,显然维度过高且包含大量冗余信息,需要进一步对局部特征进行编码。
一种常用的编码方案是词袋模型[24](Bags of visual Words,BoW),通过将所有图像的局部特征聚成K个类中心,然后用离特征点最近的一个聚类中心去代替该特征点。通过聚类的方式对局部特征进行综合,去除冗余信息。但是,直接使用类中心代替附近的特征点显然会丢失较多信息。VLAD 与BoW 类似,不同的是:VLAD保存了每个特征点到其最近的聚类中心的距离,而BoW 则将聚类中心附近的所有特征点无差异对待,只统计特征点个数。VLAD编码方式用公式表示如下:

其中,ci表示第i个类中心,NN(ci)表示距离ci最近的特征点集合,x表示局部特征向量,v为编码后的向量。虽然VLAD 考虑了每个特征点与聚类中心的差异(距离),对图像局部信息相比BoW有更细致的刻画,但是聚合后的特征维度依然较高,有1 024×K维,因此需要进一步降维处理,得到1 024 维特征。如果直接使用PCA降到1 024维,则需要计算1 024K×1 024K大小的协方差矩阵并进行特征值分解,整个过程对时间和空间的要求很大。因此本文提出分别在特征聚合前后分两次进行降维,如图2 所示,其中灰色条表示一个局部卷积特征,维度为1 024,通过L2范数归一化后降维到128维;经过VLAD编码后的特征维度为128×K,进行归一化后再降维到1 024维,最后再进行一次归一化。

图2 局部特征提取流程
2.2 多个模型集成
多模型特征融合利用了不同模型之间的互补性,但同时也会增加特征维度以及计算复杂度。为了最大化模型之间的互补性,而不是简单的同类模型叠加,本文提出预训练模型与微调模型的集成。具体的,预训练模型指在ImageNet-1k 数据集上训练好的分类模型,具有良好的泛化性;微调模型为本文提出的针对不同类型的图像拷贝攻击在预训练模型进行参数微调后的度量学习模型。下面将详细介绍微调模型的网络结构以及训练过程。
2.2.1 网络结构
为了能够鲁棒提取图像特征,对抗由于拷贝攻击造成两张图像在特征域上的差异,本文利用对比损失函数[25](Contrastive Loss)通过度量学习使得拷贝图像对在特征空间的距离更近,反之使非拷贝图像对在特征空间的距离更远。
本文在ResNeXt-101的基础上,将网络输入从单幅图像的形式改为图像对的形式,同时去掉网络最后的分类层,将全局平均池化后的特征输入到对比损失,如图3所示。对比损失输入为(x1,x2,copy),x1,x2为输入图像对特征,copy=1 表示x1,x2为拷贝图像对(正例),copy=0 表示x1,x2为非拷贝图像对(负例)。对比损失使用欧式距离作为两个特征之间的相似性度量,目标是缩小正例在特征空间的距离,反之增大负例之间的距离,用公式表示如下:
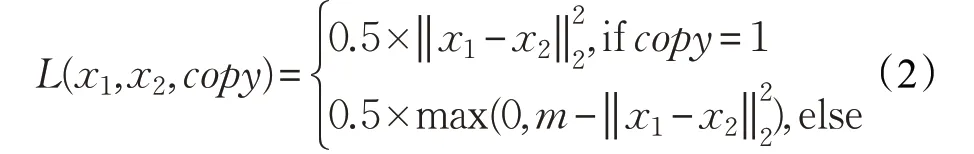
其中超参数m为设定的间隔(margin),对于负例而言,只当特征之间的距离小于设定的间隔时,才给予惩罚。
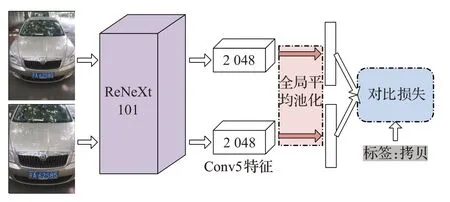
图3 微调模型网络结构
2.2.2 模型训练
本文从ImageNet-1k数据集中选取了前21类数据,每类随机选取100 张图像。根据文献[26],对于每张图像采用15种不同方式的拷贝攻击,如表2所示。其中前18类图像用来制作训练集,后3类图像作为验证集。对于一张原始图像而言,分别与15 种不同的拷贝副本组合生成15 组拷贝图像对,同时为了保证正负样本比例的平衡,从同类别原始图像中选取15 张图像生成15 组非拷贝图像对。选择同类别图像的原因是它们外观相似,容易被误检为拷贝图像,属于困难样例(hard negative example)。因此训练集共有1 800×30=54 000 组图像对,验证集共有9 000组图像对。

表2 15种不同方式的图像拷贝攻击
为了防止过拟合,训练时采用了数据增强策略:(1)首先将训练图像对缩放到256×256 像素,在相同的随机位置上裁剪出224×224 图像块;(2)随机上下或水平翻转;(3)在色调、亮度、饱和度、对比度四个方面随机进行色彩抖动;特别地,数据增强过程对两张图像均执行相同的操作,使训练过程更加稳定。训练时,采用动量梯度下降法优化模型,动量大小为0.9,初始学习率大小为0.001,同时采用余弦退火方案更新学习率大小,共迭代10个周期(epoch)。
3 实验结果
本文将算法在2 个标准的图像拷贝检索数据集上进行测试:Copydays[27]和 Challenging ground-truth[26],同时比较了不同图像特征融合方式对最终检索结果的影响。特征融合方式为串联(concatenate),为了公平比较,所有融合后的特征使用PCA降维到1 024维。除特殊说明,实验中VLAD 编码时使用的聚类中心个数K=256。
3.1 数据集及评价指标
Copydays 数据集一共包含3 212 张图像,其中157张原始图像,3 055 张拷贝图像。平均每张图像包含了19 张拷贝副本,主要由3 种图像攻击方式:裁剪、JPEG压缩、图像增强等。
Challenging ground-truth数据集包含了10 000张图像,分为500组,每组中包含了20张不同时间、位置和角度下拍摄的相似图像。以每组的第一张图像作为查询图像,通过表2 中15 种不同的攻击方式共生成7 500 张拷贝图像。将拷贝图像加入到原始数据集中,共有17 000张库图像,500张查询图像,对于一张查询图像而言,库中包含了15张拷贝图像,19张相似图像。相比Copydays数据集,该数据集在拷贝图像集中混合了很多相似图像,因此更容易将相似图像错误识别为拷贝图像。
实验结果采用多次查询的top-N结果的平均准确率(AP)、平均召回率(AR)以及平均精度均值(mean Average Precision,mAP)三个指标进行评价,计算公式如下:

其中,Q表示查询次数,Ii(j)为指示变量,表示第i次查询的第j项结果是否与查询图像有关,如果有关则取值为1,否则值为0,‖Ii‖0表示了第i次查询正确结果的总数,即Ii中非零元素的个数。Pi(j)表示第i次查询前j项结果的准确率,Mi为所有与第i张查询图像相关的库图像的个数。
3.2 特征融合方式对比
本文首先在Copydays数据集上验证了高层语义特征以及低层局部特征对于拷贝图像检索的性能表现,如表3所示,其中pre-train表示预训练模型,fine-tune表示本文提出的微调模型,RMAC 表示高层语义特征,CONV4 表示低层局部特征,RMAC+CONV4 表示将两类特征进行融合。每次查询选取前20个检索结果进行评估。
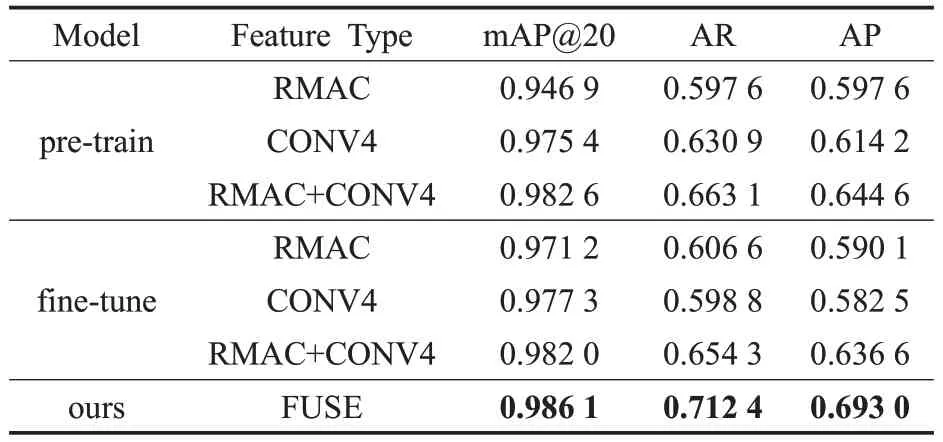
表3 Copydays数据集上不同层特征的性能表现
观察表3中的预训练模型可以发现,高层特征在平均召回率和平均准确率上相比低层特征具有优势,但高层特征的mAP值较低。因为mAP值考虑了返回结果的顺序,即对于同样的返回集合,正确的结果越靠前,mAP值越高。说明了高层特征检索结果大部分具有语义一致性,忽略了图像细节特征,因此在检索结果排序上不具有优势。相反,低层特征涵盖了更多图像细节,对于相似图像的干扰更具有鲁棒性。如图4 所示,(a)为输入的查询图像,(b)和(d)为两种特征的检索结果,为了便于观察,从前20 个检索结果中只展示第6 张到第15张的结果。从(d)中可以发现,高层特征易于将相似图像(c)检测为(a)的拷贝图像。

图4 不同类型特征检索结果对比(从第6张到第15张)
为了进一步提升检索性能,一种直观的想法是融合高层语义特征与低层局部特征,使最终融合的特征包含的信息具有多样性,实现优势互补。表3 中,无论是预训练模型还是微调模型,融合后的特征(RMAC+CONV4)相比单一特征在检索精度和召回率上均有大幅度提升,mAP值也提升了约1%。
对比表3中的预训练模型和微调模型可以发现,通过在制作的拷贝数据集上进行微调可以大幅度提升高层特征检索的mAP 值,说明通过度量学习可以使网络关注到不同的图像攻击方式并与之对抗,拉近拷贝图像与原始图像在特征空间的距离。然而由于神经网络存在的灾难性遗忘(Catastrophic Forgetting)的问题,在新数据集上微调后的模型使用低层特征检索的性能有所降低。
因此本文选择使用预训练模型提取的低层局部特征,以及使用微调模型提取的高层语义特征,融合二者的特征作为最终图像表示(FUSE),从表3中可以看出,相比只是同一模型的不同层特征融合,多模型特征融合之后的检索性能提升更为显著,说明了不同模型提取的特征具有明显的互补性。最终提出的融合方式既利用了不同层特征的多样性,同时也利用了不同模型之间的特征互补性。
3.3 低层局部特征参数分析
低层特征相比高层特征提取过程相对复杂,其中包含了一个十分重要的超参数:K,即聚类中心个数。在2.1.2节提到,需要将128×K维的编码特征降维到1 024维。理论上,K越大,特征编码后的信息损失越少,同时编码后的特征维度越高,第二次降维的信息损失也越大。如图5 所示,本文在Copydays 数据集上,使用预训练模型测试了6 组不同的K值对低层局部特征检索性能的影响,以2的倍数,分别从K=32 到K=1 024。

图5 聚类中心个数对CONV4特征的影响
观察图5 可以发现,随着聚类中心数量不断增加,CONV4 特征检索的平均精度和平均召回率不断上升,从K=256 之后出现稳定,甚至当K=1 024 时,两个指标均出现轻微下降。通过统计,不同类中心数得到的编码特征经过PCA 降维所保留的主要信息比例(即累积贡献率)如表4 所示。当K=1 024 时,PCA 降维后只保留了60%的信息,因此当K超过一个平衡点时,继续增大K将会造成性能下降。

表4 聚类中心个数与PCA降维后的累积贡献率
3.4 Challenging数据集上性能表现及分析
在Challenging ground-truth 数据集上,本文进一步测试了多模型之间的特征融合方式,结果如表5 所示,其中PT表示预训练模型,FT表示微调模型,FUSE即多模型融合,具体融合时使用的模型用上标表示,ALL 表示 RMACFT、RMACPT、CONV4FT、CONV4PT四种特征融合。在Copydays 数据集上,RMACFT+CONV4PT表现最好,但是在Challenging ground-truth 数据集上表现并不好。主要原因是Challenging ground-truth 数据集包含了大量相似图像的干扰,如图6 所示,其中(2)~(5)为(1)的相似图像,(6)~(10)为(1)的拷贝图像。相似图像与拷贝图像在高层语义上十分接近,因此RMAC 特征表现较差,相反,低层局部特征CONV4包含了更多的细节信息,区分能力更强,因此表5 中表现最好的一组特征是CONV4FT+CONV4PT,即两个模型的局部特征融合。

表5 Challenging ground-truth数据集上不同方法对比

图6 Challenging ground-truth数据集可视化
4 结束语
基于内容的图像拷贝检测重点在于图像特征的表示,本文根据特征属性将特征划分为高层语义特征以及低层局部特征,并基于卷积神经网络给出了两种特征的提取方式。本文通过实验分析了高层语义特征与低层局部特征各自的优势与劣势,在此基础上,本文融合了两种类型的特征,实现特征多样性。同时在预训练模型的基础上,针对图像拷贝检测问题制作了训练集,通过度量学习增强网络识别拷贝图像的能力。本文将微调后模型与预训练模型进行特征融合,达到不同模型之间的特征互补。本文通过大量实验证明了多种特征融合的方式可以有效增强特征的鲁棒性,相比单一特征的检索效果提升十分明显。另外本文还测试了多组特征融合方式,可以针对不同的应用场景使用不同的特征融合方式。
