心理测试中掩饰行为的识别研究
2020-10-19王秀超郑秀娟
赵 童,黄 钲,王秀超,李 淼,张 昀,郑秀娟,刘 凯
1.四川大学 电气工程学院,成都 610065
2.中国科学院 沈阳自动化研究所 机器人学国家重点实验室,沈阳 110016
3.中国科学院大学 计算机与控制学院,北京 100049
4.中国人民解放军空军军医大学 军事医学心理学系,西安 710032
5.西安交通大学 电子与信息工程学院,西安 710049
1 引言
心理测试作为一种科学的测试方法已得到广泛应用,近年来,越来越多的人事单位运用心理测试进行人事选拔[1]。目前量表是衡量心理测验结果的最为有效的工具。但心理检测量表也存在一些缺陷,比如无法有效检测受试者在检测过程中是否存在掩饰行为,导致测试结果不准确,从而影响人事选拔决策的准确性,影响人事选拔的决策。因此,为提高心理量表的有效性需对心理检测过程中受测人员是否存在掩饰行为进行有效识别。
已有的方法主要通过测量受试者的血压、皮肤电、脉搏和呼吸等生理信号来检测。这些传统方法都是通过人体的外围生理信号间接反映大脑思维活动的方法,具有片面性。而脑电信号是大脑组织电活动和大脑功能状态的直接反映,能够准确反映出受试者的心理状态,具有不可掩饰性[2]。然而受数据采集成本高的限制,国内外并没有将脑电信号应用到人才选拔的心理测试研究行为的研究。近些年来,许多学者提出了基于事件相关电位(Event Related Potentials,ERP)P300 和N400测谎方法。2014年高军峰等提出了一种基于P300和极限学习机的脑电测谎方法[3],并且在2017年通过P300成份的样本熵特征进行测谎研究[4]。2016年,顾凌云等通过主成分分析网络(PCANet)对P300 成分进行特征提取,并用SVM 进行分类[5]。2017 年,艾玲梅等将人工免疫算法和超极限学习机相结合,提出了基于AIA-ELM的N400诱发电位的测谎方法[6]。陈冉等在2018年利用相锁值算法和SVM 相结合对P300 进行相同步测谎研究[7]等等。然而基于ERP 的测谎研究需要给予受试者固定的简单刺激从而诱发特定的ERP信号,测试过程要求高。然而心理测试过程,受试者进行心理答题,受到的刺激不固定,此时受试者脑电信号主要体现了其复杂思考的行为,而非特殊事件诱发的ERP 信号。因此,本文将通过分析被测人员在心理测试答题全程中整体的脑电信号(EEG),对其是否存在掩饰的行为进行识别。
由此可见,由EEG 信号中提取有效的特征是掩饰行为识别的关键。EEG 信号传统的特征提取方法主要有时域分析法(如均值方差特征)、频域分析法(如功率谱估计、AR模型)、时频域分析法(如小波变换)。文献[8]证明了脑是一个随机混沌的动力学系统,而EEG 信号具有明显的非线性动力学特征。传统的分析方法无法提取EEG信号的非线性特征,因此,非线性动力学分析方法能够有效实现EEG 信号非线性特征的提取和分析[9]。目前,非线性动力学方法主要有Lempel-Ziv 复杂度(Lempel-Ziv Complexity,LZC)[10]、样本熵(Sample Entropy,SE)[11]、排列熵(Permutation Entropy,PE)[12]、模糊熵(Fuzzy Entropy,FE)[13]等。非线性分析法已经在情感识别、癫痫的预测[14]、心脏疾病方面取得了显著的进展。
本文提出了一种基于EEG信号非线性特征融合的方法并用于心理掩饰行为识别中。首先提取LZC、SE、PE、FE四种非线性特征,对不同的特征组合采用多维尺度分析(Multidimensional Scaling,MDS)[15-16]进行融合及降维。最后,通过正则化核函数极限学习机(Regularization Kernel Extreme Learning Machine,RKELM)构建分类模型并验证了分类器的性能。该方法有效识别受试者的掩饰行为,从而提高了心理检测量表的效度。
2 数据获取
本文所采用的实验数据由空军军医大学提供。共招募27名身心健康的受试者参加心理测试题目问答并记录测试过程中的EEG 信号,其中每位受试者均需进行两次试验,分别记为试验一和试验二。在试验一中,受试者需要“正向”回答问题,即选择与参考答案一致的选项。在试验二中,受试者需要“反向”回答问题,即选择与参考答案相反的选项,模拟在心理测验中的掩饰行为。在试验一和试验二测试中均含有50道双选题。试验一用作模拟未掩饰行为,而试验二则用作掩饰行为。答题过程中受试者的EEG 信号使用Neuroscan 脑电记录系统采集,电极的分布根据国际通用的标准10-20 系统[17],如图1 所示,其中拥有 30 导通道记录 EEG 信号,2导通道记录眼电信号(水平眼电HEOG 和垂直眼电VEOG),另外2 导通道(A1 和A2 通道)为平均参考电极。本文利用该实验过程中采集的EEG信号进行掩饰行为的分析。
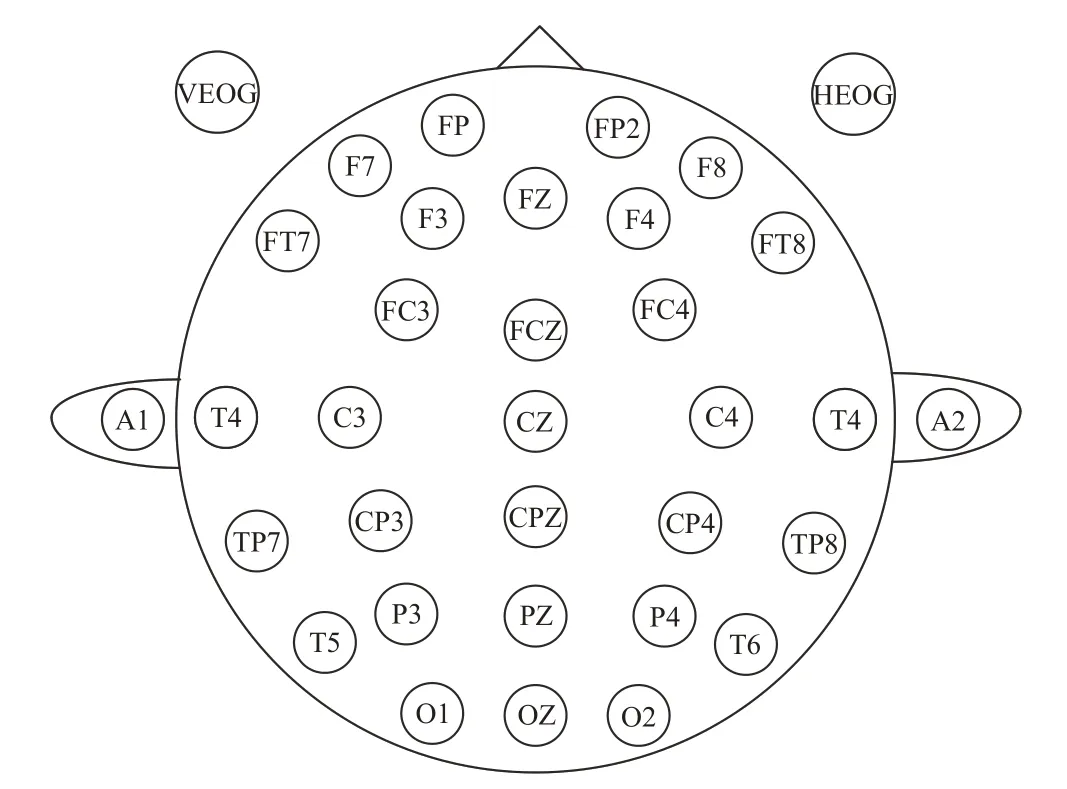
图1 实验电极放置图
3 方法
本文提出了一种基于EEG信号非线性特征融合方法并用于心理测试掩饰行为的检测。该方法包含4 个主要步骤:(1)对原始EEG信号进行预处理;(2)提取预处理后EEG信号的LZC、SE、FE以及PE四种特征,并对以上特征进行六种特征组合;(3)对每种特征组合进行MDS 特征降维;(4)采用正则化核函数极限学习机RKELM 构建分类模型。该方法的流程图如图2 所示,具体方法将在后续文章中进行详细描述。
3.1 EEG信号预处理
本文中对EEG信号的预处理包含以下三个步骤:
(1)对原始EEG信号采样频率从1 000 Hz降采样至500 Hz,同时对EEG信号去除基线漂移和1~50 Hz带通滤波。
(2)用独立成分分析法ICA 对信号进行分解,去除眼电信号等干扰成份[18]。
(3)去除2个眼电信号通道和2个参考电极,保留剩下的30 个通道的EEG 信号,并根据受试者答题的时间进行数据分段。
3.2 EEG信号预处理
本文选取了非线性动力学里的Lempel-Ziv 复杂度(LZC)、样本熵(SE)、排列熵(PE)和模糊熵(FE)四种特征对EEG进行特征提取。
3.2.1 Lempel-Ziv复杂度LZC
Lempel-Ziv 复杂度表征了一个时间序列出现新模式的速率。LZC越高说明出现新模式的概率越高,同时也说明动力学行为越复杂。LZC的计算方法如下:
(1)对原始序列x={x1,x2,…,xN}进行粗粒化,本文选择序列平均值xi作为阈值。大于xi的为“1”,小于xi的为“0”,得到了一个由“0-1”组成的任意字符串X={X1,X2,…,Xn} 。
(2)在字符串X后增加一个新的字符串Q组成新字符串XQ,将XQ中最后一个字符删掉得到字符串XQv。
(3)如果X包含Q,则称Q为X的复制,复杂度不变。若X不包含Q,则为插入,复杂度的值加1。对所有字符串中的全体都进行以上的变化得到复杂度C(N)。
(4)进行归一化处理,得到复杂度的最终表达式,如公式(1)所示:

3.2.2 样本熵SE
样本熵SE表示的是非线性动力系统产生新模式的速率。样本熵值越大,序列越复杂。SE的算法如下:
(1)对原始序列x={x1,x2,…,xN}进行相空间重构以得到m维矢量,如公式(2)所示:
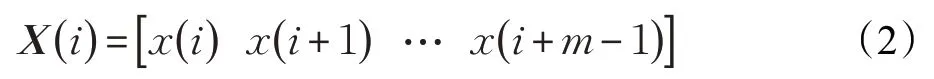
(2)计算向量X(i)和X(j)之间的距离,向量X(i)和X(j)的距离为两者对应元素中差的绝对值最大的1个,即:

式中,k=1,2,…,m-1,i,j=1,2,…,m-1。
(3)对每个i值,用n表示d[X(i),X(j)]小于r的数目。计算此数目与距离总数N-m+1 的比值,记作即:

对其所有i值的平均值:
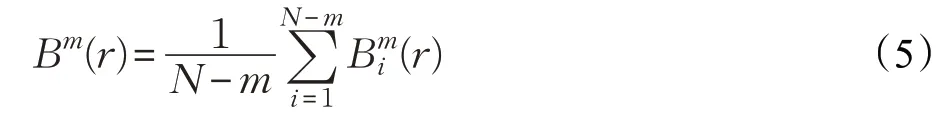
(4)将维数加1,维数变为m+1,重复步骤(1)到(3),得到。
(5)当序列长度N为有限值时,可得到样本熵的估计值,表示为:

3.2.3 排列熵PE
当级配碎石拌和完毕后应及时采用大吨位自卸式卡车将其运输至施工现场,运输过程中车辆的行驶速度不宜过快,避免混合料出现较为严重的离析现象,另外,运输车的车厢上方宜覆盖一层帆布,以减小级配碎石混合料的水分散失。
排列熵PE能够衡量一维时间序列随机性。该算法具有简单明了、计算速度快、抗噪声能力强的优点,基本流程如下:
(1)对序列x={x1,x2,…,xN}进行相空间重构,得到:

其中,m为嵌入维数,τ为延迟时间。

图2 方法流程图
(2)将xs(t)中的重构分量按数值大小升序排列为:

j1,j2,…,jm表示重构序列中各个元素所在位置的序号,则位置序号π={j1,j2,…,jm} 有m!种不同的情况。
(3)用f(π)表示每种排序模式出现的次数,则其对应的排序模式出现的概率为:

其中1 ≤i≤m!,根据香农熵定义,排列熵为:

(4)对熵值进行归一化,可以得到:

模糊熵FE是对样本熵SE的改进,把样本熵里的相似性度量公式采用指数函数作为模糊函数,通过指数函数的连续性使得模糊熵值变得平滑。该算法的具体步骤如下:
(1)对原始序列x={x1,x2,…,xN}进行相空间重构以得到m维矢量,如公式(12)所示:

(2)计算向量X(i)和X(j)之间的距离,向量X(i)和X(j)的距离为两者对应元素中差的绝对值最大的1个,即:

式中,k=1,2,…,m-1,i,j=1,2,…,m-1。

式中,n和r分别为模糊函数的边界梯度和宽度。
(4)定义函数:
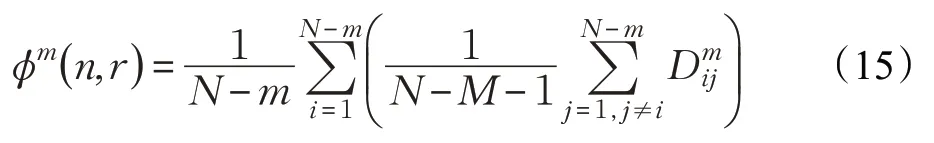
(5)将维数加1,维数变为m+1,重复步骤(2)到(4),得到φm+1。
(6)定义模糊熵:

3.3 MDS降维
经过预处理后有效的EEG信号有30个通道。选取n种特征融合,则初始特征因子就有n×30 维度。本文采用多维尺度分析(MDS)对数据组合降维。MDS是一种非线性降维方法,该方法的基本思想是降维后的低维空间中的矩阵Bm×q能够保持高维矩阵Am×n数据点之间的联系。对于特征矩阵Am×n(n是特征维度,m是特征个数),经典的MDS具体过程如下:
(1)计算距离矩阵P(其中元素pij表示xi和xj之间的距离)。P是一个对角线为0的实对称矩阵。
(2)计算矩阵P中每个元素的平方,即:

通过变换,由上式可得:


(3)定义由bij构成的内积矩阵Β,由上式得式(20),其中为元素全为1的列向量。

(4)计算内积矩阵Β的q个最大特征值{λ1,λ2,…,λq}和对应的q个标准正交化的特征向量y=(y1,y2,…,yq)。则降维后的q维空间坐标为:

3.4 正则化RKELM
构建分类模型是决定脑电掩饰行为检测的关键步骤,本文采用正则化核函数极限学习机[19](RKELM)来构建分类模型。正则化核函数极限学习机是基于极限学习机(ELM)[20-21]的改进算法。相较于传统的误差反向传播网络(BPNN)通过梯度下降法迭代获取网络参数,极限学习机通过直接获取网络参数的解析解,因此极限学习机具有更快的学习效率以及更优越的泛化能力。
如图3 所示,极限学习机的网络结构与BPNN 相同,但是极限学习机的权重设置却与BPNN 差距较大。假设训练样本集为Xi∈Rk,i=1,2,…,n,训练样本集的标签为Ti∈Rv,i=1,2,…,n,若假设极限学习机网络的中间层节点数为M,输入层到隐含层第j个神经元的权重和偏置分别为Wj和bj激活函数为g(⋅),隐含层中第j个神经元到输出的权重为W2j,则有极限学习机的输出为:
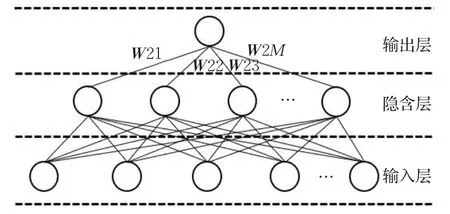
图3 极限学习机结构图
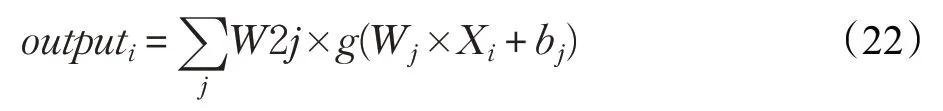
将极限学习机的输出转换为矩阵相乘形式,即:
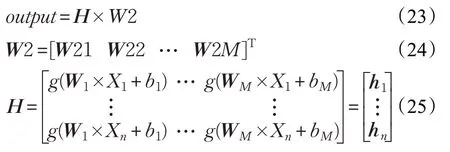
同BPNN 相同,极限学习机希望能以0 误差逼近训练样本集的标签,即满足:

若满足J=0,则有此时W2=H+T,其中H+为H的广义逆矩阵,由此可见给定H,即可获取隐含层到输出层权值的解析解,相对于梯度下降法迭代更新权值,极限学习机具有更高的学习效率。
为了提高极限学习机的泛化能力,可以将隐含层到输出层的权值进行正则化,则极限学习机的损失函数可以转化为式(27),其中λ为经验误差所占的权重。

构造拉格朗日函数,可以将极限学习机的损失函数转化为:

其中αi为拉格朗日算子,由KKT 条件可以得到极限学习机的最终输出:

核函数极限学习机是通过构造核函数来代替hiHT,核函数极限学习机的输出可以表示为:
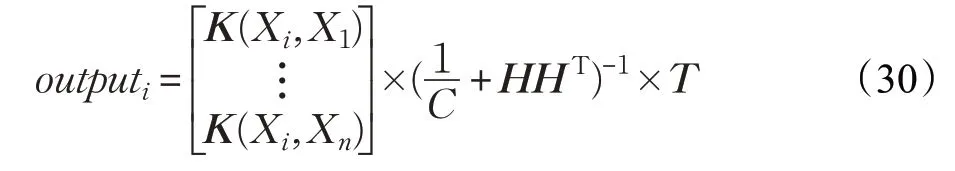
4 实验结果及分析
采集27 名受试者的2 608 段EEG 信号,包含1 314段“反向”回答(模拟掩饰行为)时采集的脑电信号以及1 294 段“正向”回答时采集的脑电信号。并从中提取214段“反向”回答时采集的脑电信号及294段“正向”回答时采集的脑电信号组成测试集以验证分类模型性能,其他样本作为训练集用于正则化核函数极限学习机训练。
为更全面衡量分类器性能,本文引入准确率(ACC)、召回率(REC)以及特异性(SPE),其定义如下所示,其中TP、TN为正确分类的正样本及负样本,FP、FN为误分类的正样本和负样本。本文中正样本为“反向”回答时的脑电信号,负样本为“正向”回答时的脑电信号。

一般而言,特征的选取直接决定分类器的性能,基于不同特征组合的分类器具有不同的性能,本文选取六种特征组合(FE+PE,LZC+SE+FE+PE,LZC+SE+FE,LZC+SE+PE,SE+FE+PE,FE),经MDS 降维后,通过正则化核函数极限学习机训练分类网络,所得到的分类器性能如图4所示,特征组合SE+FE+PE具有最高的准确率和特异性,FE 具有最高的召回率,FE 的召回率仅比SE+FE+PE 高0.001,而FE 的特异性和准确率却比SE+FE+PE 分别低0.01 和0.006,因此综合而言,特征组合SE+FE+PE 的分类效果最佳。此外,图5 为基于不同特征组合训练得到的分类模型的ROC曲线和AUC 值,特征组合SE+FE+PE具有最高的AUC值,为0.882 6,而引入 LZC 的特征组合 LZC+SE+FE+PE 的 AUC 值仅为0.847 6,可见LZC的引入导致分类模型性能的下降。
此外,特征降维算法的选择也是影响分类性能的重要因素。为了验证MDS在心理测试中掩饰行为识别任务中的性能,基于不同分类算法包括支持向量机、稀疏堆栈自编码器(SSAE)、随机森林(RF)和RKELM,本文对比了MDS 和四种常用特征降维算法,包含主成分分析(PCA)、核函数主成分分析(KPCA)、线性判别分析(LDA)及等度量映射(ISOMAP)在不同特征组合下的最佳分类性能。实验结果如图6 所示,MDS、PCA、LDA、KPCA以及ISOMAP在不同特征组合下所取得的最高分类准确率分别为82.9%,82.3%,80.3%,80.5%以及75%,其中MDS所取得的最佳分类准确率最高,其次为PCA,而ISOMAP效果最差,因此本文选用MDS作为特征降维算法。

图4 不同特征组合在进行MDS降维和RKELM分类后的分类性能

图5 不同特征组合的ROC曲线和AUC值
同时,分类器的选择也是影响分类性能的重要因素。为验证分类器的选择对最终分类模型性能的影响,基于六种特征组合,通过多种分类算法包含SVM、稀疏堆栈自编码器(SSAE)、随机森林(RF)训练分类模型,并通过测试集测试分类模型性能。实验结果如表1 所示,加粗字体代表各分类器所能取得的最佳分类性能。对于不同的分类器,最优特征组合也不同,如对应于SVM的最优特征组为LZC+SE+FE+PE,而对应于SSAE的最优特征组合为FE。此外,SVM、SSAE、RF及RKELM所能取得的最佳分类准确率分别为77.6%,76.6%,59.7%及82.9%,由此可见RKELM在所有分类器中性能最优。
5 结束语
检测心理测试中的掩饰行为是十分重要的。本文采用空军军医大学提供的受试者参加心理测试中的EEG信号,提出了一个基于脑电非线性特征融合的心理掩饰行为的检测方法。首先,经过预处理后提取了30个通道的非线性特征里的LZC、SE、PE 和FE 四种特征。接着,对提取四种特征利用非线性的多维尺度分析MDS 进行六种特征组合(FE+PE,LZC+SE+FE+PE,LZC+SE+FE,LZC+SE+PE,SE+FE+PE,FE)及降维。最后利用正则化核函数的极限学习机RKELM 构建分类模型。实验表明:(1)SE+FE+PE 特征组合分类效果最佳,准确率达到了82.9%,其分类器AUC的值为0.882 6,并且引入LZC特征组合LZC+SE+FE+PE会导致分类模型的下降。(2)相较于其他常用的特征降维算法,包括PCA、KPCA、ISOMAP以及LDA、MDS在基于脑电信号的心理掩饰行为识别任务中效果更优。(3)对于本文所采用的六种特征组合,RKELM分类效果明显优于SVM、SSAE和RF分类,说明RKELM在处理小样本非线性样本上具有很好的效果。本文提出的心理掩饰行为的检测方法是十分有效的,能给心理医生提供较为准确的参考。下一步工作将关注减少EEG通道数量来降低数据采集的门槛,用来更好地辅助心理测试的实验设计。

图6 五种降维算法在不同特征组合上的最高分类性能
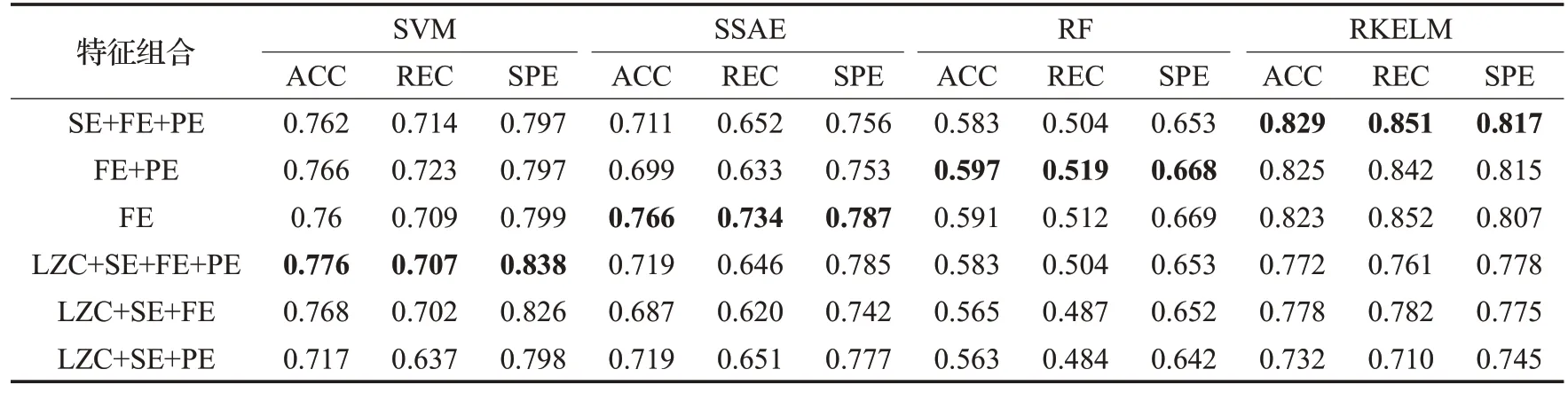
表1 不同分类器构造分类模型的性能对比
