基于深度卷积网络的葡萄簇检测与分割
2020-10-19娄甜田杨华胡志伟
娄甜田,杨华,胡志伟
(1.山西农业大学农业经济管理学院,山西 太谷030801;2.山西农业大学 信息科学与工程学院,山西 太谷030801)
葡萄(Vitis vinifera)作为常见果树树种之一,在我国栽培范围较为广泛[1]。传统的葡萄种植、采摘等一系列环节,均需耗费大量人力、物力等资源。而在葡萄精准种植过程中,要对其尽早进行产量估计及劳动力需求预测,其关键步骤与有效前提是能对棚架环境下葡萄部位进行精确监测。计算机视觉可为葡萄自动检测提供一种有效手段,但真实果园种植场景下浆果粘连、杂物遮挡等问题给高精度检测带来较大挑战。
传统基于机器视觉的葡萄簇分割常采用颜色、形状、纹理等形态学特征。Badeka 等[2]基于LBP 纹理与颜色特征的组合进行特征提取,并采用KNN 算法对红白葡萄品种进行分割;Behroozi等[3]基于颜色特征采用人工神经网络与遗传算法分割葡萄簇;Reis 等[4]使用颜色映射与形态学扩张技术对单束白红葡萄品种进行分割,并未考虑多束场景分割问题。上述方法均过度依赖采集图像自身质量,在真实种植场景下,光照条件、藤蔓遮挡、葡萄簇粘连等复杂因素均给高质量图像获取带来极大难题。因此迫切需要高鲁棒性算法以对不同环境葡萄簇进行高精度分割,而基于深度学习的卷积神经网络CNN(Convolutional neural net⁃work)对图像特征具有强大的表征能力[5,6],并已在苹果[7]、芒果[8]、柑橘[9]等水果检测方面得到成功应用,探讨将其用于葡萄个体研究成为可能。目前基于CNN 的葡萄领域研究集中于种类识别[10]、产量估计[11]、叶片分割[12]等方面,其中针对葡萄簇的检测与分割对产量估计、自动化采摘尤为重要。Santos 等[13]采 用YOLOV2/YOLOV3 与Mask-RCNN 对葡萄簇分别进行目标检测与实例分割。Marani 等[14]利 用 预 训 练 的CNN 模 型 对 葡 萄 簇 进行逐像素分割,准确度可实现87.5%。但上述针对葡萄个体的研究所采用的CNN 结构较为单一,未探讨不同模型结构下相应数据集的分割效果,且在衡量分割准确率高低上所采用的指标较为单一,在真实种植场景下,不同葡萄簇距离拍摄镜头远近不一,针对不同大小的簇,势必需要分别给予不同指标以全方位衡量分割效果。
本文提出一种基于深度卷积网络的非接触、低成本的葡萄簇检测与分割新方法,该方法结合不同骨干网络特征提取结果与Mask R-CNN、Cascade Mask R-CNN 任务分割网络进行端到端训练,并研究不同学习率对模型效果影响,多条件计算各自模型AP 指标值,在真实种植场景下,能实现对深度分离、浆果粘连、杂物遮挡等不同条件葡萄簇高精度检测与分割,以期为产量估计与自动化采摘等提供模型支撑。
1 试验数据
1.1 试验数据说明
本文试验数据来源于Santos 等[13],该数据集包括137 张共2 020 个实例标注葡萄簇,共包含5个葡萄品种,分别为霞多丽(24 张)、品丽珠(33张)、赤霞珠(28 张)、长相思(29 张)以及西拉(23张)。前4 个品种图像于2017 年4 月采用Canon EOS Rebel T3i 佳能1800 万像素单反相机拍摄,其分辨率大小为2 048×1 365,西拉品种葡萄于2018 年4 月采用摩托罗拉Z2 Play 智能手机拍摄,其分辨率大小为2 048×1 536,拍摄过程中相机位于葡萄藤线间,距离藤线1~2 m。采用基于Noma等[15]提出的基于图匹配的交互式图像分割方法,使用多边形形状对葡萄对象进行实例级精确标注。不同品种部分图像标注结果如图1.a 所示,该数据集能反映真实场景,并未对果园葡萄植株进行修剪、脱叶及其他任何干预型处理。

图1 数据集展示及预处理Fig.1 Dataset display and preprocessing
1.2 试验数据预处理
为获得模型有效输入,对Santos 等原始数据集经过如图1.b 所示2 步预处理操作以得到适用于本文模型的真实果园种植环境下的葡萄检测与分割数据集:
(1)为降低模型显存占用率,减少运算量,加速模型训练速度,对原始数据集及其标注结果进行恒等放缩变换,变换后霞多丽、品丽珠、赤霞珠、长相思品种图像分辨率大小变为1 024×682,西拉品种图像变为1 024×768,其过程如图1. b 中①所示。
(2)为丰富数据集,提升模型泛化能力,考虑到初始数据集训练样本较少不足,对(1)处理图片进行数据增强操作,每张图片仅以50%概率随机执行加入高斯噪声、翻转180°以及改变亮度值中的1~3 种变换生成4 张增强图片,其中亮度值的阈值修改范围为0.5~1.5,大于1 表示调暗,小于1表示调亮,其过程如图1.b 中②所示。
经上述2 步处理后,共获得标注图片685 张,按照通用数据集划分策略[16],将其以14∶3∶3 的比例划分为训练集、验证集与测试集,其中训练集大小为481 张,验证集与测试集均包括102 张图片。
2 葡萄检测与分割模型
2.1 Mask R−CNN 模型
Mask R-CNN 是 在Faster R-CNN[17]基 础 上发展而来,其由4 部分组成,分别为特征提取(如ResNet[6]系列网络)与组合网络(Feature Pyramid Network,FPN)、区域提交网络(Region Proposal Network,RPN)、ROIAlign 以及功能性网络,其模型结构如图2 所示,图中编号①~④分别对应上述4 个组成模块。
ResNet 网络常被用于骨干网络以对输入图像进行特征提取,为解决深度网络训练过程中的退化问题,其将残差思想引入网络结构中,在深层网络与浅层网络间引入跳跃连接以在增加网络层数的同时避免出现准确率饱和甚至下降现象,此外,ResNet 系列网络在训练中将不同特征图大小通过stage 阶段方式组织,其可作为后续FPN 特征组合网络的有效输入;FPN 用于对骨干网络不同阶段不同大小特征提取结果进行有效融合,与常规网络结构仅采用最后一层输出作为最终特征提取结果不同,FPN 充分融合骨干网络提取的底层到高层间的特征图,不同层级特征图对不同大小物体敏感度不同,使得Mask R-CNN 对于小目标个体的检测与分割同样有效;区域提交网络RPN[17]主要用于提取候选区域,RPN 作为一个轻量的神经网络,其通过滑动窗口扫描特征图的方式进行卷积操作,并结合不同尺寸与长宽比以生成称为an⁃chor 的互相重叠区域,并为每个anchor 预置位置信息,对于每个anchor 输出两类信息,第1 类为对an⁃chor 前景或背景类别的预测,前景类别代表在该anchor 中以一定概率存在某类或者多类目标,背景类别指待检测目标以外的其余物体,在后续目标与特征图指派过程中,该部分信息将会滤除;第2类信息是对预置边框位置的精调,在目标中心与前景anchor 的中心间存在偏移时,输出位置变化百分比以精确调整anchor,以对目标位置的拟合更为准确,在前景中出现多个anchor 互相重叠时,通过非极大值抑制方法(non maximum suppression,NMS)[18]滤除低分的anchor,保留高分anchor 以最终生成感兴趣区域;Mask R-CNN 通过引入ROIAlign 以解决特征图与原始图像不对准问题,其 是 在ROIPooling[17]基 础 上 改 进 得 到,在ROIPooling 在将候选框处理为相同大小特征图过程中,通过两次量化取整操作使得候选区域中目标位置出现较为明显的偏差,ROIAlign 取消量化操作,使用双线性插值的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转换为一个连续操作,使带有候选区信息的特征图内目标位置更为准确;功能性网络主要包括两部分,如图2 中④所示,对于输入特征图E1~E3,分别经过两路分支以实现不同的任务,上行分支主要经过全连接层以进行目标类别划分以及目标框位置定位操作,下行分支经过全连接网络以对目标进行分割。综合上下行分支,可以对目标个体类别、个体位置以及个体像素区域进行多种任务实现。
Mask R-CNN 对输入图像经过ResNet 等骨干网络进行特征提取并引入FPN 对ResNet 不同阶段特征进行融合以生成卷积特征图C1~C4,并将其作为RPN 区域提交网络输入以生成建议窗口,将建议窗口映射到C1~C4 特征图上以生成可能包含目标个体的卷积特征子图D1~D3,后将其作为ROIAlign 层输入转换为固定尺寸大小特征图E1~E3,并利用全连接层进行目标分类与目标框定位,利用全卷积层进行目标分割以得到最终输出。
2.2 Cascade Mask R−CNN 模型
Cascade Mask R-CNN 网 络 是 由Cai 等[19]提出,其核心模型结构如图3(b)所示。与3(a)中Mask R-CNN 不同的是,Cascade Mask R-CNN 通过串行级联几个检测网络以达到不断优化预测的目的,与普通级联不同,Cascade Mask R-CNN 的几个检测网络是基于不同IOU[20]阈值确定的正负样本上训练得到,前一个检测模型的输出作为后一个检测模型的输入,位置越靠后的检测模型,其界定正负样本的IOU 阈值越大,如图3(b)中①~③分别对应的IOU 阈值为0.5、0.6、0.7。
与Mask R-CNN 类似,Cascade Mask R-CNN对输入图像经过骨干网络特征提取、FPN 进行特征融合,由RPN 通过映射关系生成一系列可能存在目标的候选窗口,首先将其输入阈值为0.5 的检测网络H1 中(包括分类器、目标框回归器及其目标分割器),对识别过程中存在目标的特征图,将其目标回归器与目标分割器修正后的新区域送入阈值为0.6 的检测网络H2,将H2 子网络输出的新区域位置及分割结果送入阈值为0.7 的检测子网络H3,最终将H3 子网络输出的分类、目标框位置及其分割结果作为Cascade Mask R-CNN 的输出。由于采用多阈值检测子网络的级联结构,级联顺序按照阈值由小到大排列,不断修正目标位置及其像素点区域,解决了传统单个网络设置阈值时对高阈值正样本数量不足及低阈值对高IOU 区域修正效果降低间的矛盾。
3 训练参数设置及模型评价指标
3.1 训练参数设置
试验运行平台配置为16GB Tesla V100 GPU,系统为Ubuntu16.04,采用PyTorch 框架进行模型代码编写。一个批次训练8 张图片,遍历全部训练集数据称为1 轮迭代,试验中设置迭代轮数为32。图像尺寸大小为1 024×682 与1 024×768,数据集增强前的大小为137,数据增强后总数据集大小为685,将其划分为训练集、验证集与测试集,其中训练集大小为481,测试集与验证集大小均为102。采用SGD 作为优化器,优化器学习率设置为0.02(4.2 节会针对不同学习率大小进行对比实验),为加速模型收敛避免陷入局部最优解或者跳过最优解,设置权值衰减weight_decay 参数为0.0001,设置动量momentum 为0.9。将图像输入骨干网络前,对三通道值进行均值为(123.675,116.28,103.53)方差为(58.395,57.12,57.375)的归一化处理,计算AP 指标时,采用与COCO[21]一致的指标定义方式。对于Mask R-CNN 任务网络,模型训练过程中采用0.5 大小阈值进行目标框位置筛选,对于Cascade Mask R-CNN 任务网络,模型训练过程中其3 个级联网络分别采用0.5、0.6与0.7 大小的IOU 阈值进行目标框位置筛选。
3.2 模型评价指标
模型指标采用检测与实例分割领域公认的检测精度AP 作为评价标准以衡量模型对果园种植场景下葡萄簇的检测与分割能力。AP 表示精确率-召回率(Precision-Recall)曲线下方面积,其公式化表示如式(1),(2),(3)所示。考虑到选用不同的IOU 直接影响TP 与FP 值进而造成AP 指标值波动,选用0.5、0.75、0.5∶0.05∶0.95(其中0.05表示增长步长)3 种IOU 阈值分别记为AP0.5、AP0.75、AP0.5:0.95以衡量不同条件下模型检测与分割预测情况。同时考虑到葡萄簇摄像头间距离以及葡萄簇大小差异带来的簇个体占图像比重问题,将葡萄簇大小分为中等目标(322<簇大小所占区域面积<962)与大目标(簇大小所占区域面积>962),并在IOU 值为0.5~0.95 间单独计算不同大小目标下的AP 指标值,分别记为AP0.5:0.95-medium与AP0.5:0.95-large。


其中TP 表示模型预测为葡萄个体框(像素)且实际为葡萄部位(像素)的样本数量,FP 表示模型预测为葡萄个体框(像素)但实际不为葡萄个体(像素)的样本数,FN 表示预测为背景但实际为葡萄个体框(像素)的样本数量。
4 结果与分析
4.1 不同骨干网络对预测性能影响
骨干网络作为各种CNN 模型的共享结构,常被用于特征预提取操作。为探究不同骨干网络对模型检测与分割的影响状况,选取2 种常见ResNet 衍生版本(ResNet50 与ResNet101)对输入图像分别进行特征提取,并将提取结果分别作为Mask-RCNN 与Cascade-Mask-RCNN 任 务 网 络的输入,最终计算其在测试集上的检测与分割AP指标值。
4.1.1 对葡萄检测性能影响
表1 为ResNet50(R50)与ResNet101(R101)两种骨干网络特征提取结果在测试集上Mask RCNN 与Cascade Mask R-CNN 两种任务网络对葡萄簇检测框预测的AP 指标值状况。

表1 不同任务网络在不同骨干网络下不同IOU 阈值检测AP 指标值状况Table 1 AP index value status of different IOU thresholds for different task networks under different backbone networks
试验结果表明:
(1)不同骨干网络对Mask R-CNN 与Cascade Mask R-CNN 任务网络葡萄检测框预测效果不一。对于Mask R-CNN 任务网络,以R50 作为骨干网络的效果优于R101,在AP0.75指标上提升22.3%,而对于Cascade Mask R-CNN 模型,R50骨 干 网 络 逊 于R101,在AP0.5:0.95-large指 标 上,R101超过R50 骨干网络1.6%,说明对于不同任务网络,骨干网络的选取对预测效果有一定影响,与R50 相比,虽然R101 网络更深,理论上可提取更为复杂的局部信息,但对于特定任务相关网络,并非骨干网络越深,对任务更有利。
(2)同一骨干网络,采用不同任务网络,葡萄位置检测精度不一。采用Cascade Mask R-CNN作为检测任务网络,其检测精度明显优于Mask RCNN 网络,在AP0.75指标上,以R50 作为骨干网络条件下,前者先较于后者提升8.8%。说明即使以相同的特征提取结果作为输入,选用不同的任务相关网络仍会带来不同的性能,且以级联方式充分融合多种IOU 阈值检测结果的模型Cascade Mask R-CNN 显然具有更优的检测效果。
4.1.2 对葡萄分割性能影响
表2 为ResNet50(R50)与ResNet101(R101)两种骨干网络特征提取结果在测试集上采用Mask R-CNN 与Cascade Mask R-CNN 任 务 网 络对葡萄簇分割预测的AP 指标值状况。

表2 不同任务网络在不同骨干网络下不同IOU 阈值分割AP 指标值状况Table 2 AP index values of different IOU thresholds for different task networks under different backbone networks
试验结果表明:
(1)不同骨干网络的选取对模型分割结果有一定影响。在采用不同任务网络条件下,选用R50骨干网络的各个分割AP 指标值优于选用R101 的网络,以Cascade Mask R-CNN 作为任务网络为例,在AP 指标上,选用R50 骨干网络比R101 提升2%~13.5%,说明,即使对于较为复杂的骨干网络理论上可以抽取更为丰富的特征,但对于下游任务网络而言可能并非骨干网络越深,其任务效果越佳,实际中需根据数据及任务特点选用合适深度的骨干网络。
(2)对于同一骨干网络,选用不同的任务网络分割结果存在较大差异,且采用Cascade Mask RCNN 作为任务网络在各个AP 指标上性能均优于Mask R-CNN。以R50 作为骨干网络,选用Cas⁃cade Mask R-CNN 作为任务网络比Mask R-CNN在AP0.75指标上提升4.4%,即使在提升幅度不明显的AP0.5指标上仍能带来0.7%的性能提升,说明即使选用相同的骨干网络,任务网络的选取对分割性能的进一步提升仍具有重要意义,且其带来的提升幅度弱于骨干网络。
4.2 不同大小学习率对预测性能影响
学习率(Learning Rate,LR)是指导模型通过损失函数的梯度调整网络权重的超参数,学习率越低,损失函数变化速度越慢,模型收敛需要的时间越长,且降低的学习率大小容易使模型陷入局部最优解。而学习率较高,损失函数变化震荡幅度较大,不利于模型的稳定性,为探讨不同学习率对Mask R-CNN-R50 与Cascade Mask R-CNNR50 任务网络的影响程度以选用合适的学习率大小,本文以R50 为骨干网络,以0.005 大小步长在0.005~0.03 间选用6 个不同学习率在2 大任务网络上进行试验。
4.2.1 对葡萄检测性能影响
表3 为Mask R-CNN 与Cascade Mask RCNN 在以R50 作为骨干网络在不同学习率条件下的检测AP 指标值状况。试验结果表明,随着学习率大小的增加,不同IOU 阈值的检测AP 指标值出现先增加后减小的现象。Mask R-CNN-R50 与Cascade Mask R-CNN-R50 分别在LR 等于0.02与0.025 下各个IOU 阈值AP 指标值效果最佳。以Mask R-CNN-R50 为 例,在LR 选 取 为0.02 与LR 为0.005 相比在AP0.75指标上提升15.8%,即使在提升幅度不为明显的AP0.5指标上仍然能获得4%的性能提升。说明选用不用的学习率对于模型检测位置准确率具有一定影响,且学习率大小与检测精度间不存在正比关系,这是因为学习率主要用于训练过程中最优参数的迭代更新,选用较大的学习率可能会因为更新过大跳过模型的最优解,而选用较小的学习率可能使模型参数始终处于较小更新中,导致模型只获得局部最优解。
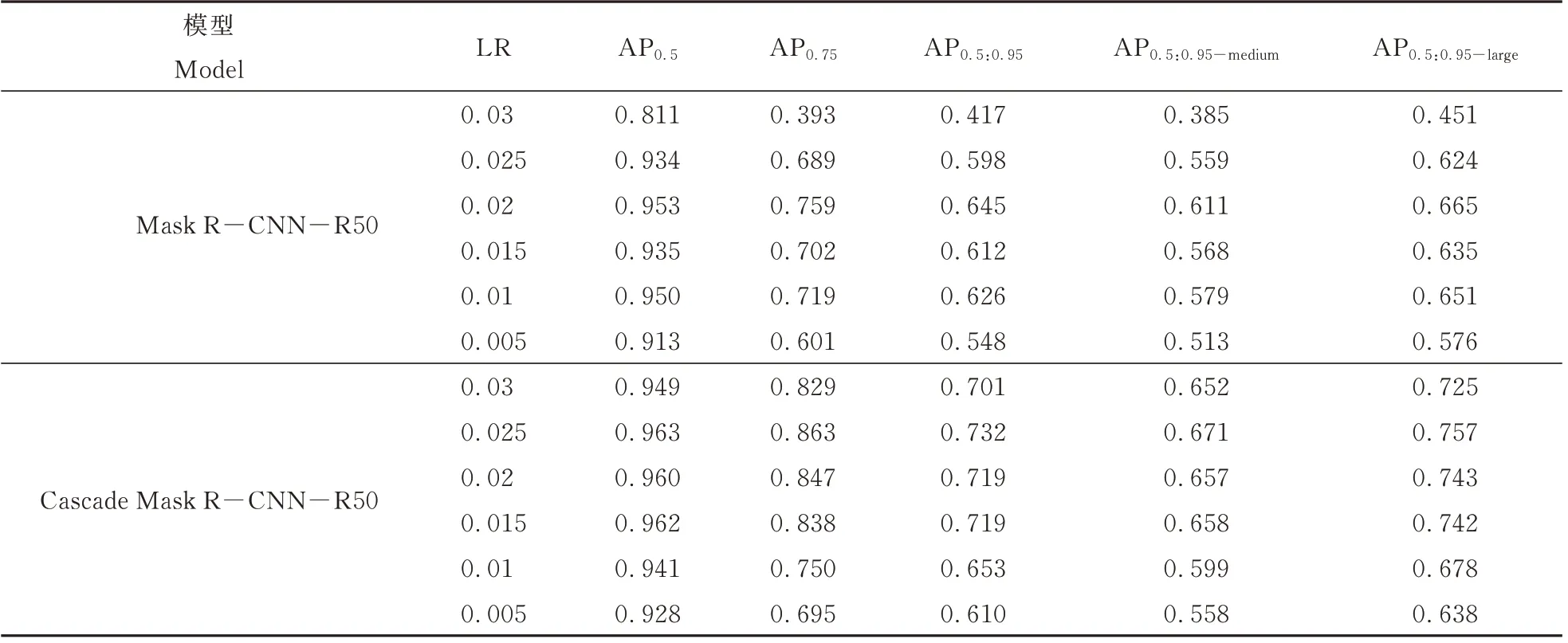
表3 模型在不同学习率条件下的不同IOU 阈值检测AP 指标值状况Table 3 The status of AP indicators under different IOU thresholds under different learning rate conditions
4.2.2 对葡萄分割性能影响
表4 为Mask R-CNN 与Cascade Mask RCNN 在以R50 作为骨干网络在不同学习率条件下的分割AP 指标值状况。试验结果表明,Mask RCNN-R50 与Cascade Mask R-CNN-R50 均 在LR等于0.02 条件下各个IOU 阈值分割AP 指标值最佳,且在选用相同学习率时,Cascade Mask RCNN-R50 模型优于Mask R-CNN-R50。两大模型在学习率递增过程中同样出现先增加后减小现象。以Cascade Mask R-CNN-R50 为 例,LR 选 用为0.02 比LR 等 于0.005 与0.03 在AP0.75指 标 上分别提升28.4%、14.5%,在AP0.5:0.95指标上提升18.7%与11.6%,即使在提升幅度不是很明显的AP0.5指标上,LR 为0.02 条件下比其他学习率大小提升0.5%~4.6%。说明学习率大小的选用会影响分割结果的好坏,且并非在检测效果较好的学习率上分割效果也相应最佳(如Cascade Mask R-CNN-R50 在LR 为0.025 时检测效果最佳但在LR 为0.02 时分割效果最佳),这是因为检测与分割分属于2 种不同任务,Mask R-CNN-R50 与Cascade Mask R-CNN-R50 两大任务网络将2 种任务整合于同一框架,但2 种任务采用的损失函数以及优化策略存在一定差异,因而并非选用相同学习率能够对两者同时起到性能提升作用,实际中可综合考量对检测与分割任务的倾向度以选择合适的学习率大小。

表4 任务网络在不同学习率条件下不同IOU 阈值分割AP 指标值状况Table 4 AP index values of different IOU thresholds under different learning rate conditions
4.3 不同大小学习率下预测精确率与损失函数值变化曲线分析
为更加直观观察不同学习率条件下训练过程中训练精度与损失函数变化情况,对以R50 为骨干网络的Mask R-CNN-R50 与Cascade Mask RCNN-R50 两大任务网络训练过程精度与损失函数值绘制折线图如图4 所示,其中准确率为分类精度、检测精度以及分割精度3 者的平均值,其值越大,效果越佳,损失函数值为分类损失、检测损失以及分割损失3者的平均值,其值越小,效果越好。

图4 不同大小学习率下模型预测精度与损失函数变化曲线Fig.4 Model prediction accuracy and change curve of loss function under different learning rates
试验结果表明,以Mask R-CNN-R50 为模型条件下,LR 选取0.03 时效果最差,而将LR 选取为0.02 时,从第8 轮迭代开始均能取得较高的精度值与较低的损失值。而对于Cascade Mask R-CNNR50 模型,在选用不同LR 大小的初期,各个子模型能取得相近的精度,但随着迭代的深入,从第6轮迭代开始,LR 等于0.025 的模型优势更为明显,说明选用不同的LR 在模型训练初期,其均能很好的更新模型权重以使得模型趋向于最优值,但随着迭代次数的增加,选用不合适大小的LR 可能会导致跳过全局最优值或限于局部最优值,在实际的训练过程中需尝试多个不同的LR 以在不改变模型结构的基础上进一步提升模型精度。
4.4 不同场景下模型预测结果可视化
为进一步研究模型在不同场景下的鲁棒性,将测试集分为深度分离、浆果粘连、杂物遮挡3 种情形对其进行分割与检测可视化,其部分可视化结果如图5 所示。

图5 不同场景检测与分割可视化Fig.5 Different scene detection and segmentation visualization
从中得知,Cascade Mask R-CNN-R50 模型在3 种场景下的分割与检测效果最佳,Mask RCNN-R101 效果最差。对于杂物遮挡(如葡萄茎秆与葡萄叶片等)情形,即使有叶片遮挡葡萄簇个体(图5 中杂物遮挡列图像内编号为①与④的葡萄簇),Cascade Mask R-CNN-R50 仍然能够将其有效分割出来,且分割边缘更为圆润,但对于Mask R-CNN-R50,其将叶片也作为葡萄簇个体进行了分割,这不利于实际中产量估计。对于浆果粘连情况,Mask R-CNN-R50 分割结果较为粗糙,分割粘连度较高,其将本不属于葡萄簇个体的部分错误的归为葡萄个体,而Cascade Mask R-CNN-R50分割更为精细,即使在葡萄簇中出现茎秆等信息(图5 中浆果粘连列图像内编号为①的葡萄簇),其仍能剔除茎秆影响,考虑到上述不同场景中Cas⁃cade Mask R-CNN-R50 能够取得最好的分割性能,实际中可将其作为产量估计的参考模型。
5 讨论与结论
本文基于深度卷积网络理论,构建不同骨干网络与Mask R-CNN、Cascade Mask R-CNN 分割任务网络结合模型进行端到端训练,研究不同学习率对模型效果影响,且分析不同学习率条件下Mask R-CNN-R50、Cascade Mask R-CNN-R50模型在训练过程中的精度与损失函数变化情况,并对不同果园场景下的检测结果进行可视化展示,主要结论如下:
(1)不同骨干网络对Mask R-CNN 与Cascade Mask R-CNN 等任务网络葡萄簇检测与分割效果具有一定影响。选用R50 作为骨干网络的效果一般情况优于R101,在分割结果上,以Cascade Mask R-CNN 为任务网络,选用R50 骨干网络比R101 提升2%~13.5%,表明并非骨干网络越深,效果越佳。
(2)相同骨干网络条件下,不同任务网络预测AP 指标值存在差异。以Cascade Mask R-CNN 为任务网络获得的葡萄簇分割与检测各个AP 值更优,且能在骨干网络带来性能提升的基础上进一步加大提升幅度,说明结构较好的任务网络对于任务精度具有积极作用。
(3)以R50 作为骨干网络不同大小学习率对分割与检测AP 指标值带来较大程度变化。两大任务网络在学习率递增过程中各AP 值先增加后减小,综合考虑各AP 指标值状况,在学习率为0.02 条件下,2 大任务网络效果较好。
(4)对比分析深度分离、浆果粘连、杂物遮挡等果园场景下预测可视化结果,Cascade Mask RCNN-R50 模型的葡萄簇分割与检测效果最佳,Mask R-CNN-R101 效果最差。
本文为真实种植场景下非接触、低成本的葡萄簇检测与分割提供新方法,能实现对深度分离、浆果粘连、杂物遮挡等不同条件葡萄簇高精度检测与分割,其可为为产量估计与自动化采摘等实际生产提供模型支撑。
