联合场景和行为特征的短视频行为识别*
2020-10-15周丽娜宋艳艳
董 旭,谭 励,周丽娜,宋艳艳
北京工商大学计算机与信息工程学院,北京 100048
1 引言
随着抖音、快手和美拍等短视频平台的火爆出现,越来越多的人成为短视频内容的制造者[1-2],带动了短视频行业的蓬勃发展;此外,短视频因为更加符合人们快节奏的生活、碎片化的阅读,深受人们的追捧和喜爱。但是和长视频相比,短视频时长受限,拍摄质量受制于设备,更重要的是短视频的质量和内容良莠不齐[3],大量的短视频如果不加以过滤筛选,直接推送给用户,会造成审美疲劳;另外,短视频受制于拍摄设备质量的限制,和专业设备拍出的视频不同,极有可能出现视频模糊不清、分辨率不高或者相机抖动的问题;此外,短视频因为时间较短,包含的信息不够完整,会产生歧义,如果被不法分子利用,短视频可能会变成谣言传播的载体,造成极其恶劣的影响。因此,对短视频内容的理解,是极其必要且迫在眉睫的。在研究过程中,短视频中的人物行为的识别是短视频理解的关键。
行为识别[4-6]是计算机视觉中一个重要的研究课题,主要目的是解决“人干了什么”这一任务,涉及的领域包括视频监控、人机交互、视频索引等。目前主流的行为识别方法是基于深度学习方法,如双流CNN(convolutional neural network)方法[7],通过卷积神经网络分别提取视频中的RGB信息和光流信息,进行分数融合,从而得到最终的行为识别结果,而Karpathy等人[8],更进一步地研究传统CNN在videolevel的应用上存在的问题,提出在不同网络层中进行融合,取得了一定的效果;而3D卷积方法[9-10]是先对图像信息进行提取,再利用CNN网络对图像的时序信息进行学习,最终得到视频的行为类别。但是,目前的方法更关注于行为动作本身,忽略了视频中行为和场景之间联系。短视频中包含的信息量较少,且包含的信息不够完整,需要尽可能地利用视频中的多种特征信息,并利用它们作为先验知识,帮助提高人物行为识别的准确率。这其中,场景特征的重要性不言而喻。例如,在生活中,做饭这个动作,通常情况下发生的场景是厨房;看电视这个动作通常会发生在客厅或者卧室;打开衣柜这一动作发生场景通常为卧室,如图1所示。因此,将场景特征信息作为上下文线索,并用于行为识别中,是值得深入研究的。本文的贡献主要是构建了一种基于字典学习的场景和行为的联合学习模型,通过场景特征作为上下文信息,提高行为识别效果。

Fig.1 Scene and behavior example图1 场景和行为示例
2 相关工作
Peng等人[11]提出了一种基于运动场景的无监督聚类算法,该方法将静态场景特征和动态特征进行结合,并在此基础上建立了一个通过上下文约束的模型。首先,通过单视图和多视图约束来探索每个上下文中的多视图子空间表示的互补性。然后,通过计算上下文约束的关联矩阵,并引入MSIC(motion-scene interaction constraint)以相互规范场景和运动中子空间表示的不一致。最后,通过共同约束多视图的互补性和多上下文的一致性,构造了一个总体目标函数来保证视频动作聚类结果。Zhang等人[12]利用相关的场景上下文来研究提高动作识别性能的可能性。首先,将场景建模为中级“中间层”,以便桥接动作描述符和动作类别。然后,作者使用朴素贝叶斯算法学习场景和动作之间的联合概率分布,该算法用于通过组合现成的动作识别算法在线联合推断动作类别,并通过实验比对,证明了方法的可行性。Yang等人[13]提出了一种利用语义信息对建筑工地员工行为识别的方法。采用非参数化的数据驱动场景分析方法对构造对象进行识别。从训练数据中学习了基于上下文的动作识别模型。然后,通过使用已识别的构造对象来改进动作识别。Hou等人[14]提出了一种分解动作场景网络FASNet。FASNet由两部分组成,一部分是基于Attention的CANET网络,这一部分能够对局部时空特征进行编码,从而学习到具有良好鲁棒性的特征;另一部分由融合网络构成,主要将时空特征和上下文场景特征进行融合,学习更具描述性的特征信息。Simonyan等人[7]提出了经典的包含空间和时间的双流网络架构,空间流从静止视频帧执行动作识别,同时训练时间流以识别来自密集光学流动形式的运动动作,最后通过后期融合进行行为识别。而Dai等人[15]针对物体形状复杂问题,提出了一种可形变的卷积结构(deformable convolution networks),它对感受野上的每一个点加一个偏移量,使得偏移后感受野和物体的实际形状相匹配,更好地获取物体的特征信息。
3 算法概述
生活中,人物的行为会受到特定场景的影响,在特定的场景下,人们的行为能够呈现出一定的规律性。如在前文中举例的厨房、客厅和卧室等特定场景中,人物的行为分别为做饭、看电视、打开衣柜。因此,在本章中,将介绍一种基于字典学习的场景特征和行为特征联合学习方法。
3.1 模型定义
设短视频序列V={v1,v2,…,vn},其中L={l1,l2,…,ln}是每段短视频最终输出的行为类别。对于短视频序列,S={s1,s2,…,sn}为利用基VGGNet的场景分类结果,而A={a1,a2,…,an}为利用可变卷积[15]的双流方法得到的行为识别结果。于是,对于第i个短视频,可以将模型定义为:

其中,vi是第i个短视频,ai是第i个短视频的行为类别,si是第i个短视频的场景类别,ωi为学习参数。对于设定的模型,需要有行为特征参数和场景特征参数,因此第i个短视频的学习ωi可以定义为:

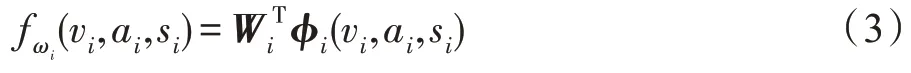
其中,φi(vi,ai,si)用于表示第i个短视频中,行为和场景的联合特征向量。根据以上,可以定义为:
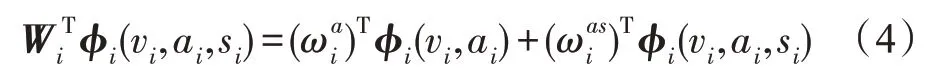
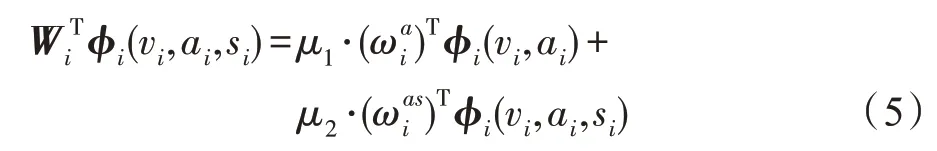
将μ1和μ2设置为0.5,最终问题可以转化为求解学习参数ω的过程,ωa是指行为特征参数信息,ωas是联合特征的参数信息。ωa可通过训练得到,ωas则需要通过构建字典联合求解所得。
3.2 字典学习和稀疏表示
稀疏字典学习也称为字典学习,目标是通过学习一个完备字典,通过字典中少量的原子,对给定数据进行稀疏表示,如图2所示。
对于一般的稀疏表示问题,可以将问题转变成为一个优化问题,公式如下:

其中,Bαi需要尽可能模拟xi,使所得误差最小,只有这样,才能更好地通过模型反映数据。实验过程中,对αi的约束规范选择的是L1范数,因为L1范数可以将不重要的小权重衰减为0,L1范数定义如下:

其中,L1范数是向量元素的绝对值之和。选择L1范数的原因L1是L0范数的最优凸近似,而且L0本身是一个NP难问题,L1更加容易求解。
3.3 基于场景和行为联合特征的行为识别
在前两节中,定义了问题模型,并对字典学习的原理进行了阐述。在本节中,将阐述本文所用的方法。主要工作分为特征提取和构建联合特征,图3为行为识别的工作流程图。
3.3.1 特征提取
特征提取分为场景特征提取和行为特征提取。首先,对短视频提取场景特征。设短视频序列V={v1,v2,…,vn},其中n为短视频的个数。场景特征利用基于VGGNet的深度融合网络进行提取。利用VGGNet16网络,对场景中的全局特征进行学习提取,利用VGGNet19对场景中的局部细节特征进行学习提取,分别将所学习到的特征进行融合。使用VGGNet的原因是网络选择3×3的卷积核,使得参数量更小,小卷积层的叠加能够进行多次的非线性计算,对特征的学习能力较强。假设场景类别个数为Nscene,对于第i个短视频,场景识别的目的是找到场景预测概率的最大值,因此有:
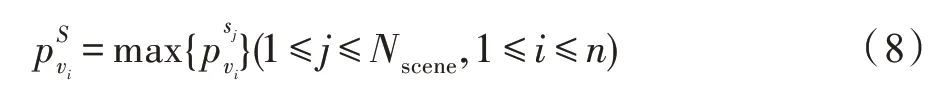

Fig.3 Joint feature learning workflow图3 联合特征学习工作流程图
其中,vi为第i个短视频,为第i个短视频对应第j个场景的概率值。但是在这里,需要保留vi在所有场景中的概率值,尽可能多地保留视频中的有用信息,因此:
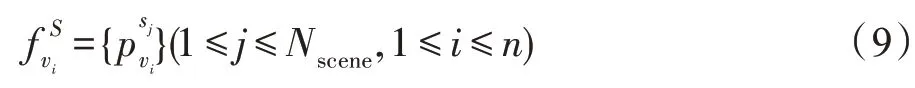
接下来,需要对短视频提取行为特征,利用可变卷积网络的双流CNN算法进行RGB特征和Flow特征提取。可变卷积网络的优点在于,它能通过添加的偏移量,更改卷积核的形状,从而提高卷积网络对图像适应能力。可变卷积网络的结构如图4所示。
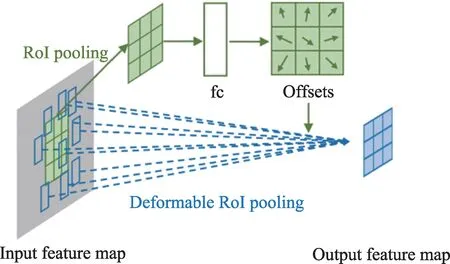
Fig.4 Schematic diagram of variable convolution network图4 可变卷积网络示意图
假设行为类别个数为Naction,对于第i个短视频,对于行为识别的结果可以定义为:
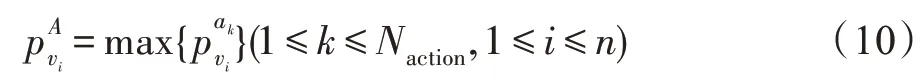
其中,vi为第i个短视频,为第i个短视频对应第k个行为的概率值,进一步看,可以定义为:

同样,行为特征提取部分,需要保留每段短视频对所有行为的概率值,定义如下:
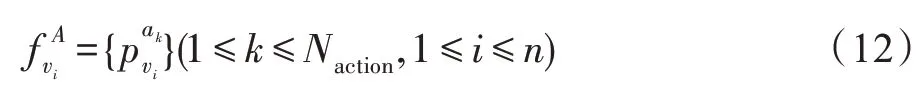
3.3.2 构建联合特征

在这里,选择的方法是字典学习,原因是,如果直接对行为特征和场景特征进行操作,就会产生大量的联合特征。在这些联合特征中,部分影响较小的特征,会对预测过程产生干扰,影响模型的鲁棒性。因此,需要进行降维。本文中采取的方法是利用字典学习的方法,求取每个样本的稀疏编码,从而提高模型的效果,其稀疏过程如图5所示。此外,模型的稀疏表示可以更好地解释具有决策性的特征,因为模型训练到最后,非零元素的个数较之于起始会大幅减少,从而更加容易解释模型。
Fig.5 Sparse representation process图5 稀疏表示过程
因此,问题可以转化为:


可求得所有短视频联合特征结果。在构造字典的过程中,选择的方法是MiniBatch Dictionary Learning。在字典学习的过程中,划分为MiniBatch,能够提升模型的训练速度,并增加随机性。并通过设置字典中的元素n_components进行学习。迭代次数分别设置为100次、200次、500次、1 000次、2 000次和5 000次。通过字典学习和稀疏表示,可以得到每个短视频在所有场景-行为联合特征的概率值。
4 仿真实验过程及结果
4.1 实验所用环境
本实验平台为戴尔服务器PowerEdge R430,操作系统Ubuntu 14.04,CPU Intel®Core i3 3220,内存64 GB,GPU NVIDIA Tesla K40m×2,显存12 GB×2。
4.2 实验参数设置
4.2.1 数据集选择
实验所选择的数据集是Charades数据集[16]。Charades数据集共有9 848个视频段,每段视频长度在30.1 s,行为类别共有157个,场景类别共有16个。在实验前,针对厨房场景进行了视频的筛选,选择其中的90段短视频用于训练,获取特征,并另外选择30段短视频作为测试集。与厨房相关的短视频示例如图6所示,数据预处理阶段,利用ffmepg工具,按照30 frame/s对短视频进行分帧处理。对于光流图像部分,利用opencv光流计算方法,输出为flow_x和flow_y两个图像。

Fig.6 Schematic of Charades kitchen scene图6 Charades厨房场景示意图
4.2.2 实验参数设置
场景特征提取过程使用PyTorch框架,所用的模型是基于VGGNet的深度融合网络,在ImageNet进行预训练后,在Charades数据集进行fine-tuning,训练时批量(batch-size)设置为8,动量(momentum)设置为0.9,优化方法选择Adam方法。行为特征提取过程中,RGB图像和光流图像分别放入到网络中进行训练;其中,光流网络需要截取成等长的连续帧放入到网络中进行训练;Deform-GoogLeNet训练过程使用反向传播方式,采用Adam优化。字典学习过程中,方法选择的是MiniBatch Dictionary Learning,n_component设置为16。
4.3 实验结果
场景特征提取和行为特征提取过程的训练结果如图7、图8所示,通过预训练模型对厨房场景进行训练。从图7中可以看出,在4 000次左右时,模型已基本收敛。
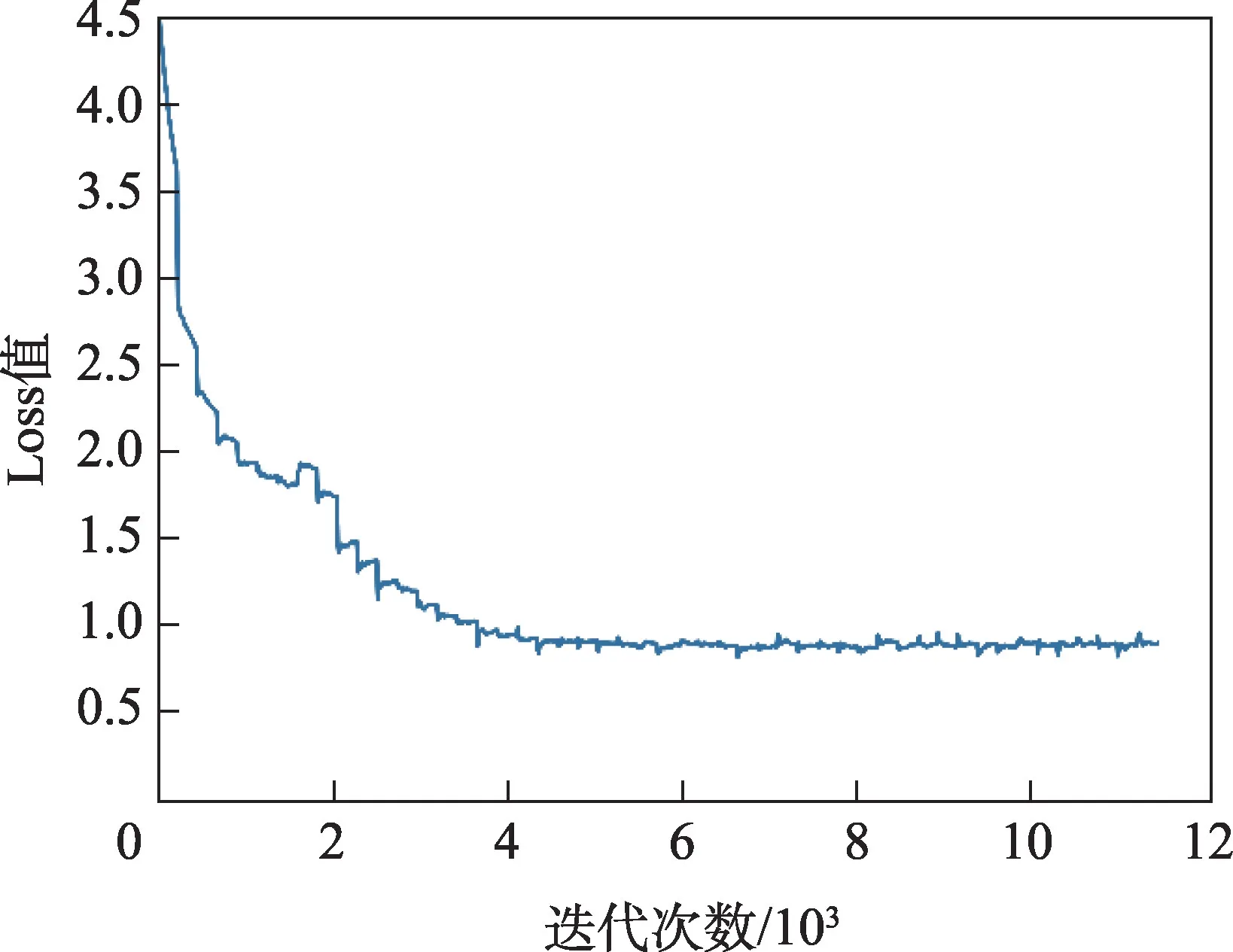
Fig.7 Changes in loss value of scene feature extraction图7 场景特征提取过程Loss值变化

Fig.8 Changes in loss value of action feature extraction图8 行为特征提取过程Loss值变化
在对行为特征进行训练时,需要利用双流CNN网络分别对RGB特征和Flow特征进行提取。图8为行为特征提取过程Loss值变化,从图8(a)中可以看出,RGB特征提取过程,在前9 000次迭代过程中,Loss值下降速度比较快,说明模型收敛比较快,而在9 000次迭代之后,Loss值的下降速度放缓,模型缓慢收敛;由图8(b)中可以看出,Flow特征提取过程,在前7 500次迭代过程中,Loss值下降速度比较快,7 500次迭代之后,模型收敛速度放缓,但是基本趋于稳定。
将数据集标注的行为动词和场景类别进行了可视化分析,结果如图9中的词云所示。

Fig.9 Behavior verbs and scene nouns in Charades kitchen图9 Charades厨房场景中行为动词和场景名词
通过图9(a)中词云展示,可以比较明显地看出在厨房的一些特定的行为,如“烹饪(cook)”“洗(wash)”“倒(pour)”和“喝(drink)”等动作;而图9(b)中展示了数据集和厨房有关的场景中的物体信息,如“炉(stove)”“桌子(table)”“餐具柜(pantry)”和“三明治(sandwich)”等。通过词云的呈现,可以比较容易地找出动作和场景之间的关系。比如,“吃(eat)”和“食物(food)”,“开(open)”和“冰箱(refrigerator)”,“洗(wash)”和“盘子(dish)”等,能够反映出场景和人物的行为存在着一定的联系。
在字典学习过程中,分别在100次、200次、500次、1 000次、2 000次和5 000次的迭代次数下进行了多次实验,并求取平均值。之后对不同迭代次数下的top-5准确率结果进行比对,结果如图10所示。通过图10可以发现,当迭代次数为1 000次的时候,top-5准确率为33%,但是迭代次数的设置并不是越多越好,当迭代次数从1 000次增加到5 000次时,准确率呈下降趋势。

Fig.10 Test set top-5 results图10 测试集top-5结果
为了证明本文方法的有效性,分别使用Two-Stream方法和基于可变卷积的Two-Stream方法和本文方法进行比较,实验结果如表1所示,本文方法有了比较明显的提高。证明了场景作为上下文信息能够提高行为识别的准确率。
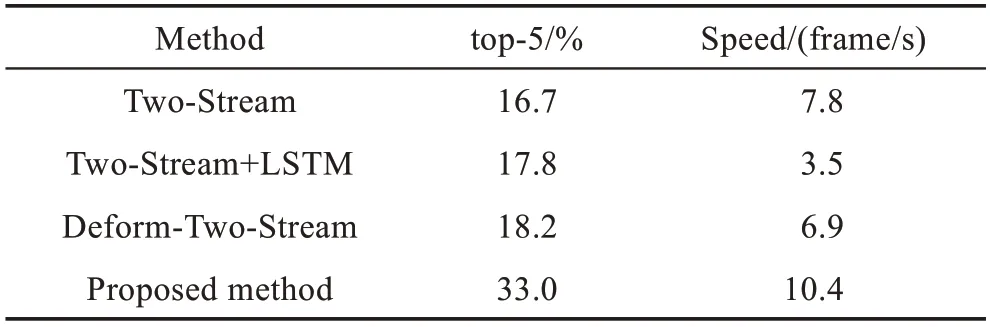
Table 1 Comparison of different methods on Charades test set表1 不同方法在Charades测试集上的比对结果
5 结束语
本文针对短视频的行为识别现状存在的问题,提出了一种基于场景和行为的联合特征学习的短视频行为识别方法,对短视频中的行为识别问题进行了研究。首先,利用VGGNet16和VGGNet19分别提取场景的全局特征和局部细节特征;之后,融合两个网络提取的特征结果,得到深度融合网络提取场景特征信息;最后,利用基于可变卷积网络的双流CNN网络提取短视频中的行为特征。提取行为特征过程的优势,一是利用可变卷积网络通过添加的偏移量更改卷积核形状,获取更多特征信息以提高网络对图像的适应能力;二是分别对RGB特征和Flow特征提取,充分利用了视频的空间和时间维度信息。利用本文提出的联合特征学习方法,将场景信息作为背景知识,结合提取的行为特征,进行最终行为识别的判断,并运用字典学习的方法,减少联合特征的维度,得到了准确和高效的识别效果。在Charades测试集top-5准确率为33%,和之前的方法比较,有了明显的提升,证明了本文方法的有效性。在未来的工作中,计划将短视频中的物体特征和场景特征同时作为行为识别的先验知识,进一步提高行为识别的效果。
