胶囊网络用于短文本多意图识别的研究*
2020-10-15李艳玲
刘 娇,李艳玲,林 民
内蒙古师范大学计算机科学技术学院,呼和浩特 010022
1 引言
人机对话系统主要由语音识别(automatic speech recognition,ASR)、口语理解(spoken language understanding,SLU)、对话管理(dialog management,DM)、对话生成(dialogue generation,DG)和语音合成(text to speech,TTS)五部分组成[1],其中口语理解是对话系统中最重要的一部分,目的是理解用户的需求。为了让机器给用户反馈正确的信息,口语理解中的意图识别起着至关重要的作用,意图识别的准确性直接关系到整个对话系统的性能。Moldovan等人[2]通过研究对话系统中各个模块对系统性能的影响,得到结论——意图识别对系统的影响非常大。因此为了构建性能更好的人机对话系统,意图识别的研究非常重要。
由于人与机器的频繁交互以及用户表达的随意性,意图文本可以分为无意图文本和有意图文本,其中无意图文本一般具有主题不明确,检索困难等特点,如聊天类意图文本。有意图文本指主题明确,属于任务型对话的意图文本。随着人们对智能助理的依赖以及人机对话系统研究的深入,用户表达的意图往往不只含有一种,而是两种及以上,例如:“我想看完新闻再听音乐”,这句话中包含“看新闻”和“听音乐”两种意图。如果让机器同时理解用户意图文本中的两种或两种以上的意图还是比较困难的,因此针对这一问题,本文对含有多个意图的文本进行研究。
为了理解用户的多意图表达,多意图(multi-intent,MI)识别是研究的主要内容。多意图识别类似于多标签(multi-label,ML)分类,但又不同于多标签分类,多标签分类通常处理的是长文本,而多意图识别主要针对短文本进行处理[3]。如何对较短的文本识别出用户的多种意图是意图识别的一个难点。目前大部分学者对单个意图识别的研究较多,而对多种意图识别的研究较少,还处于探索阶段。
2 相关工作
多意图识别问题又可以看作是一种多标签分类问题,徐晓璐[4]针对传统的多标签分类方法无法对数据的不平衡问题进行处理,而循环神经网络(recurrent neural network,RNN)会产生梯度消失或梯度爆炸的问题,提出使用长短时记忆(long short-term memory,LSTM)网络对文本进行特征提取,并利用门控循环单元(gated recurrent unit,GRU)模型进一步提取特征,同时利用构建的标签树对短文本进行多标签分类。刘心惠等人[5]利用多头注意力机制处理单词权重分配,然后采用胶囊网络(capsule network,CapsNet)和Bi-LSTM(bidirectional long short-term memory)分别进行特征提取,通过平均融合特征进行多标签文本分类,将不同层次的文本特征合理利用提升分类性能。李德玉等人[6]针对文本情绪多标签分类任务,利用标签特征增强标签和文本情绪的关系,采用卷积神经网络(convolutional neural networks,CNN)进行多标签分类,提升分类性能。牟甲鹏等人[7]针对标签之间的相关性问题,在类属属性(每个特征都有自己的特性)的空间中附加相关标签来引入标签相关性从而提升多分类算法性能。
针对多意图识别任务,Xu等人[8]采用对数线性模型并利用不同意图组合之间的共享意图信息进行多意图识别,但是针对大量的意图组合则会出现数据稀疏问题。Kim等人[9]提出一种基于单意图标记训练数据的多意图识别系统。他将句子看作三种类型,单意图语句、带连词的多意图语句和不带连词的多意图语句,然后采用两阶段法,利用最大熵模型[10]和线性链条件随机场(conditional random fields,CRF)分类器[11]实现多意图识别,但限定只能识别两种意图。杨春妮等人[12]将用户意图文本进行依存句法分析确定是否包含多种意图,利用词频-逆文档频率(term frequency-inverse document frequency,TF-IDF)和训练好的词向量计算矩阵距离确定意图的数量,将句法特征和CNN结合进行意图分类,最终判别用户的多种意图。该方法在10种类别的多意图识别任务中取得不错的效果,但是依赖于句法结构特征,因此基于深度学习的多意图识别研究仍然比较少。
CNN是一种深度学习网络,它主要由输入层、卷积层、池化层、全连接层和Softmax层五部分构成[13]。胶囊网络是一种新的深度神经网络,它主要是对卷积神经网络的一种改进,主要包括输入层、卷积层、初级胶囊层和全连接胶囊层[14]。“胶囊”的概念最初由Hinton等人[15]提出,用以解决CNN和RNN的表征局限性,一个胶囊包含一组神经元的向量表示,向量的方向表示实体属性,向量的长度表示实体存在的概率。Sabour等人[14]提出胶囊网络,将CNN的标量输出特征检测器用矢量输出胶囊代替,并且通过协议路由(protocol routing)代替最大池化(max-pooling)。相比于原来的CNN,胶囊网络会通过动态路由过程保留特征之间的准确位置关系。因此,Zhao等人[16]首次将胶囊网络用于文本分类任务,分类性能优于CNN,同时将胶囊网络用于多标签文本分类任务,提出三种动态路由策略提高动态路由过程的性能,以减轻噪声(停用词和与类别无关的词)胶囊的干扰,在路透社数据集上获得60.3%的性能效果。Xia等人[17]提出一种基于胶囊网络的意图胶囊模型,该模型对意图文本提取加入自注意力机制的语义特征,然后采用动态路由机制进行意图分类。该模型在意图识别任务上取得了不错的效果,但是该方法仅仅针对单意图进行识别,并未对多意图识别任务进行研究。Renkens等人[18]针对少量训练集,研究胶囊网络是否能够有效利用有限可用的数据集进行训练,考虑到原有的深度神经网络需要大量的训练数据,提出一种采用双向循环神经网络(bidirectional recurrent neural network,Bi-RNN)编码的胶囊网络完成口语理解任务,实验表明该方法在GRABO数据集[19]上优于其他基线方法,胶囊网络能够利用小数据集获得更好的效果。由于胶囊网络利用动态路由可以建立特征之间的位置关系,使得在小型数据集上优于结构相似的卷积神经网络[20]。
胶囊网络存在以下优势:第一,相比于CNN,胶囊网络中的动态路由可以保留句子中出现概率较小的语义特征,保证特征信息的完整性,具有很好的鲁棒性以及拟合特征的能力;第二,由于动态路由无法共享权重,在大型数据集上耗费时间较长,其他深度神经网络需要大量训练数据才可以学习到更好的效果,而胶囊网络在小型数据集上就可以很好地利用训练数据。因此本文针对比较稀缺的多意图语料,采用胶囊网络构造基于单意图标记的多意图分类器对用户的多意图文本进行研究,通过增加卷积胶囊层提取句子中的深层次语义信息,合理利用句子中的完整特征信息,动态学习属性特征和意图类别之间的关系,从而完成多意图识别任务。
3 多意图识别研究
3.1 多意图识别问题定义
假设带有标记的数据集记为{(S,L)},其中S表示样本集合,Si是数据集中的一个样本,L表示样本所对应的意图标签的集合,记为L={l1,l2,…,ln}。如果Si对应L集合中的两个或两个以上的标签,则说明一个句子中同时含有两种或两种以上的意图,这样的语句可以称为多意图文本。在多意图文本中,如果可以同时识别出两种或两种以上的意图称为多意图识别问题。
3.2 模型构建
本文的模型结构如图1所示,主要分为四层:第一层为卷积层,用于提取句子中的n-gram特征;第二层为初级胶囊层,用于封装句子中低级特征的各种属性;第三层为卷积胶囊层,用于提取句子中的高层次语义信息,增强特征质量;第四层为全连接胶囊层,将卷积胶囊层得到的高层次语义特征进行整合,使其包含输入句子的所有组合特征信息,如语法、语义和位置等信息,进而完成意图分类,同时在意图胶囊类别中增加孤立胶囊(见图1意图胶囊中的深色胶囊)用于处理与意图类别无关的特征信息,避免影响其他意图种类的识别。
3.2.1 数据预处理
本文针对用户的中文意图文本,首先进行分词处理,然后采用word2vec得到词语的词矢量,进而将意图语句进行向量化表示,使其作为深度学习模型的输入向量。而英文数据本身词和词之间存在分隔,因此不需要进行分词处理,只需要将其词矢量化然后表示成句子向量。
3.2.2 卷积层
卷积层主要对意图文本进行特征提取,通过卷积操作提取句子的n-gram特征。这里假设句子的长度为L,词向量的维数为V,n1为n-gram的长度,为了获取有序的词组搭配信息,采用的滤波器以步长为1在句子的不同位置提取特征,因此会得到L-n1+1维的特征序列,每一维特征可以表示为:

如果采用X个n-gram长度为n1的滤波器进行特征的提取,得到组合,即A=[a1,a2,…,aX]。
3.2.3 初级胶囊层
所谓胶囊是指一组向量神经元的集合,每个神经元表示意图文本中出现的某个特征的不同属性,例如:n-gram特征、单词或短语的位置信息、句子的语法特征等。由于胶囊中包含的信息比较丰富,因此用矢量输出胶囊代替CNN的标量输出特征检测器可以使句子特征信息更加丰富。
初级胶囊层主要用于封装句子低级特征的各种属性,因此在卷积层上得到的低级特征中选取ngram长度为1的词向量矩阵Ai(i=1,2,…,L-n1+1),为了封装每个词组的不同属性,采用d种W2∈R1×X的滤波器以步长为1将低级特征变换成一组初级特征胶囊,胶囊的维度为d,每个胶囊特征中包含句子特征的多种属性,如:词和短语的语法以及位置信息等。此时,就会得到L-n1+1个d维的胶囊,即,每一个胶囊的每一层可以表示为:

其中,ij表示第i(1 ≤i≤L-n1+1) 个胶囊的第j(1 ≤j≤d)层,b2表示偏置项,f是非线性激活函数,如果采用Y个过滤器,则会得到(L-n1+1)×Y个d维的胶囊,即。
3.2.4 卷积胶囊层
为了得到更深层次的语义信息,保证特征信息的质量,本文采用卷积的方法对初级胶囊特征进行卷积处理,选取n-gram长度为n2的低层胶囊(n2=3,便于将零散的语义特征进行整合),采用d种W3∈n2×Y×d的滤波器以步长为1对初级胶囊特征再次进行卷积操作,将n2×Y个低层胶囊(见图1初级胶囊层的深色部分)记为ui,Z为高层胶囊的数量(相当于有Z个滤波器)。为了学习低层特征胶囊和高层特征胶囊之间的关系,首先需要得到低层特征胶囊对高层特征胶囊的预测向量uj|i,同时利用动态路由算法生成高层特征胶囊sj,最后得到(L-n1-n2+2)×Z个d维的高层胶囊。胶囊层之间的计算过程如图2所示。

Fig.2 Calculation process diagram between capsule networks图2 胶囊网络之间的计算过程图

其中,cij为低层胶囊连接高层胶囊的概率值,由动态路由计算得出,也称为动态路由的耦合系数,这些耦合系数的和为1,通过更新cij从而更新胶囊输出值sj。在胶囊网络中,低层胶囊到高层胶囊的变换都是以向量的形式进行传递,因此需要对胶囊的方向进行处理,即采用非线性激活函数squash[21],表达式如下:

vj是所有胶囊共同作用的结果,是将sj经过squash非线性函数压缩之后得到的整体预测向量,大小在0~1之间。该公式的前半部分为压缩函数,主要对vj向量的模长进行约束,将其归一化到0~1之间。后半部分则是将sj向量单位化,使其方向与vj一致。
3.2.5 全连接胶囊层
将卷积胶囊层中得到的高层胶囊向量展开存入胶囊列表中,同时输出到全连接胶囊层中,高层特征胶囊和意图胶囊之间通过矩阵变换,同时利用动态路由算法计算每个高层特征胶囊对意图胶囊作用的结果,得到意图文本的最终胶囊表示以及它所属类别的概率。其中,意图胶囊层中的胶囊个数为意图文本的类别数和孤立类别数之和,利用胶囊向量的模长表示意图的概率大小,胶囊向量的方向表示意图类别的属性。孤立类别用于表示与意图类别无关的信息以及未被训练成功的噪声胶囊。
3.2.6 动态路由
胶囊网络的处理主要分为两个阶段,即仿射变换(矩阵变换)和动态路由。仿射变换主要针对胶囊向量,借助神经网络中的线性组合对预测向量进行计算,而动态路由主要是解决低层胶囊连接高层胶囊所需权重大小的问题。
在动态路由过程中,需要利用softmax函数不断更新耦合系数cij,使其低层胶囊被动态分配到合适的高层胶囊上,计算公式如下:

bij表示低层胶囊连接高层胶囊的先验概率,初始值为0,bij直接影响动态路由过程中的cij。在胶囊网络中,利用低层胶囊的输入,即单个胶囊的预测向量uj|i和高层胶囊的输出向量vj的内积来判断向量之间的相似性,同时用于更新bij。胶囊耦合系数越高表示两个胶囊的相似度越高,低层胶囊连接高层胶囊的可能性就越大。
最后用输出胶囊的范数(向量长度)计算输出意图标签的概率,利用间隔损失函数作为目标函数使损失和最小化,每个胶囊vj的损失函数Lj定义如下:
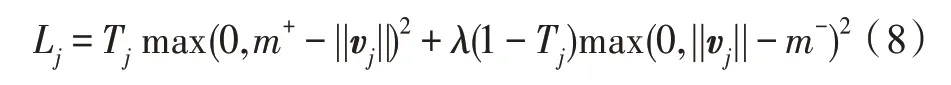
其中,j表示意图类别,Tj为分类的指示函数,如果j类在意图文本中存在,则Tj=1;反之,则Tj=0。||vj||表示意图胶囊的输出概率,m+为上界,设置为0.9,惩罚假阳性,若j类在意图文本中存在,预测不存在则会导致损失函数的值很大。m-为下界,设置为0.1,惩罚假阴性,若j类在意图文本中不存在,预测存在则会导致损失函数值很大。λ为比例系数,用于调整公式前后部分的比例。
3.2.7 阈值设定
由于胶囊网络中的动态路由算法可以输出属于各类意图的概率值,而且概率之和不为1,因此适用于多意图分类问题。本文通过设置阈值为0.5来判定预测的意图类别是否在意图文本中,如果预测的意图胶囊的概率大于阈值,则说明该意图文本中含有该意图类别,如果预测的意图胶囊的概率小于阈值,则说明该意图文本不包含该意图类别。
4 实验
4.1 实验数据
本实验采用第七届全国社会媒体处理大会SMP2017中文人机对话技术评测提供的实验语料[22]的补充以及英文数据集SNIP-nlu[17],其中中文数据集共包含27种单一意图,共4 039句,英文数据集共包含7种意图,共13 802句。本文主要利用以上数据收集基于单意图标签的多意图文本测试集,其中中文多意图测试集共收集445句,英文多意图测试集共收集610句,部分多意图语料示例如表1所示。
本文主要针对较短的用户意图文本,多为对话文本进行研究,每个句子中仅包含2种或3种意图,多意图测试集的统计数据如表2所示。
4.2 实验设置
本实验采用64维的中文词向量,300维的英文词向量对用户意图文本进行向量化表示,采用Adam-Optimize优化算法模型,学习率设置为0.001,胶囊的维度设置为16。

Table 1 Examples of multi-intent corpus表1 多意图语料示例
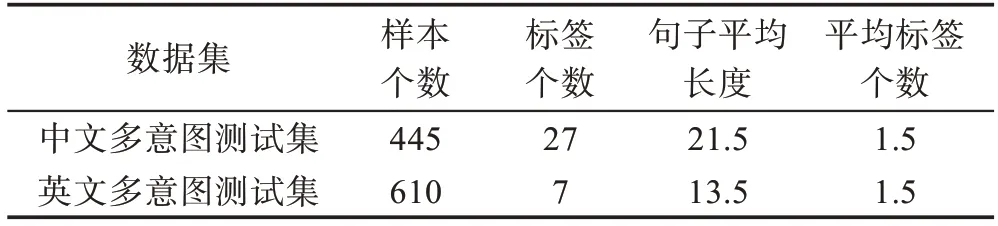
Table 2 Multi-intent test set description表2 多意图测试集描述
4.3 评价指标
多意图识别任务不同于单意图识别任务,它需要考虑意图文本中存在的多个意图标签,因此在多意图识别任务中,需要思考不同标签对意图文本分类的影响。本文采用宏平均精确度(Macro_P)、宏平均召回率(Macro_R)、宏平均F1值(Macro_F)作为多意图识别性能结果的评价指标,n表示类别数,i表示每一种类别,计算公式如式(9)~式(11)所示。

4.4 实验结果分析
本文采用CNN、胶囊网络(CapsNet)和增加卷积胶囊层的胶囊网络(CapsNet+Conv)分别在中文和英文数据集上对用户的多意图文本进行实验。另外针对增加卷积胶囊层的胶囊网络又分析了取不同ngram值得到的实验性能结果,各模型在中英文数据集上的多意图识别性能结果如表3所示。
实验结果表明,在多意图识别任务中,胶囊网络优于CNN,因为CNN中的池化层只能提取句子中最显著的语义特征或平均语义特征,忽略了有助于句子分析但出现概率较小的语义信息,而且CNN在训练过程中需要大量的语料数据。而胶囊网络将CNN的标量输出用矢量胶囊代替,使得句子中的属性特征信息更加丰富,同时胶囊网络中的动态路由可以将句子中的属性特征动态分配到意图类别中,保留了句子中的全部语义特征,有助于提升性能效果,同时胶囊网络适用于小型数据集,具有更好的拟合特征的能力。为了提升意图文本特征的质量,获取更具有意图类别特性的语义信息,本文通过增加卷积胶囊层提取句子中的深层次语义信息,使得最终提取到的特征包含句子中的所有高层次特征信息,如词组、语序、语法和语义等信息,有助于多种意图的识别,同时胶囊网络中的动态路由可以将提取到的完整语义特征动态分配到意图类别中,有助于完成多意图识别任务。不同的n-gram值可以提取到意图语句的不同词组搭配,其中n-gram值取3时,可以得到更好的词组搭配,得到的多意图识别性能最好。虽然相对于CNN和胶囊网络,增加卷积胶囊层的胶囊网络的实验参数有所增加,实验过程需要的时间较长,但n-gram值取3时,实验结果性能均好于CNN和胶囊网络。相比于胶囊网络,n-gram值取3时,增加卷积胶囊层的胶囊网络在中英文数据集上的宏平均F1值分别提升0.092和0.071。
胶囊之间的关系运算往往由动态路由决定,本文在第一次动态路由过程中通过迭代3次动态学习初级特征胶囊与高层特征胶囊之间的关系,充分进行语义搭配。第二次动态路由可以将各种属性特征融合后作用于意图胶囊类别,从而完成多意图分类。而且不同的路由迭代次数会影响多意图识别的性能结果,本文在第二次动态路由过程中通过使用2、3、4的迭代次数分别在中文数据集上和英文数据集上进行实验,实验结果如表4所示。
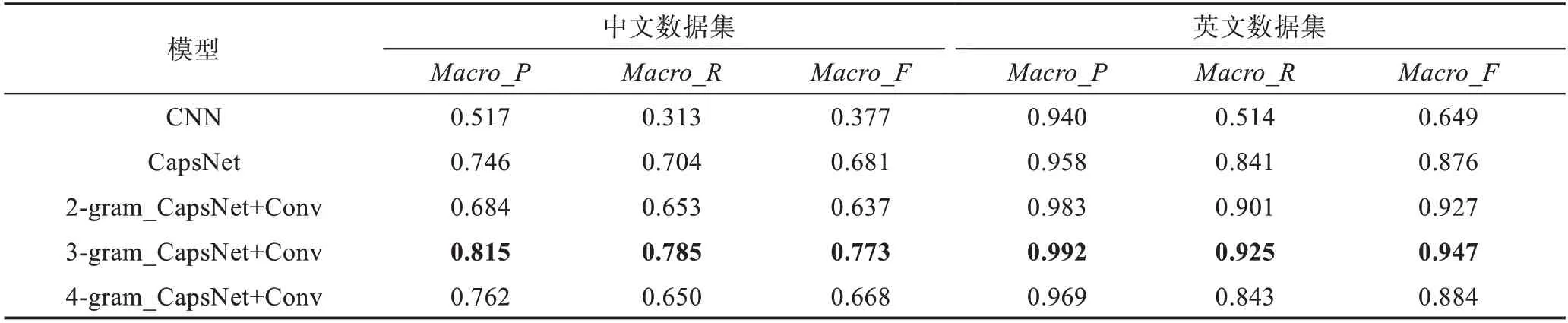
Table 3 Comparison of multi-intent detection performance results of different models表3 不同模型的多意图识别性能结果对比
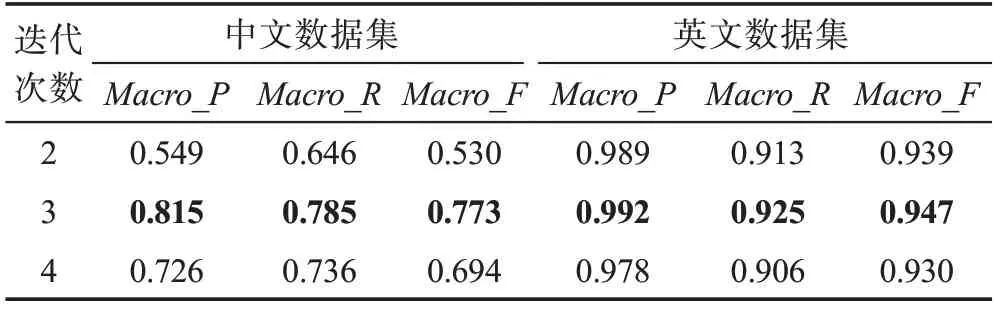
Table 4 Performance results of multi-intent detection with 2,3 and 4 routing iterations表4 路由迭代次数分别为2、3、4的多意图识别性能结果
实验结果表明,在第二次动态路由过程中,动态路由迭代3次的效果最好,因为迭代2次不能充分将高层特征胶囊与意图胶囊动态连接,没有找到高层胶囊和意图胶囊之间的最佳路由关系,使得性能较差,而迭代4次不仅需要花费更长的时间,而且容易造成过拟合,导致识别性能降低。
在胶囊网络模型中,多种意图存在的概率往往取决于阈值的设定,本文主要分析阈值分别取0.4、0.5、0.6、0.7得到的多意图识别性能结果,实验结果如图3所示,图3(a)为中文数据集中不同阈值得到的多意图识别性能结果,图3(b)为英文数据集中不同阈值得到的多意图识别性能结果。结果表明在中英文数据集中,阈值取0.5时,多意图识别的宏平均准确率、宏平均召回率和宏平均F1值均取得最高值,因为阈值太大或太小都会使与意图类别相关的意图文本不能正确分类到相应意图标签中。因此本文通过设置阈值为0.5进行多意图分类,使得多意图识别性能效果更好。
5 结论与展望
本文主要针对人机对话过程中用户语句含有多种意图的情况,而多意图语料数据比较稀缺,胶囊网络在小型数据集上可以很好地利用数据,因此采用胶囊网络构造基于单意图标记的多意图分类器对多意图文本进行识别,实验结果表明胶囊网络在多意图识别任务上的性能效果优于CNN,而且增加卷积胶囊层的胶囊网络可以更优化地利用语义特征进而提升多意图识别性能。不同的n-gram值会影响意图文本中的词组搭配关系,而n-gram值取3时,增加卷积胶囊层的胶囊网络得到的性能效果较好。在第二次的路由过程中,不同的路由迭代次数会影响识别性能结果,迭代3次得到的多意图识别性能更好。
虽然本文在一定程度上取得了进展,但是在多意图识别任务以及胶囊网络模型上还有许多值得研究的地方:(1)针对多意图语料的稀缺问题,本文主要基于已有的单意图标签收集多意图测试集进行研究,后续会采用零样本学习[17]实现多意图识别任务,为对话系统的研究进行铺垫。(2)针对胶囊网络模型,本文主要改进了特征质量,下一步准备对胶囊网络中的动态路由算法进行改进,利用数学方法减少模型参数,提升模型效率。
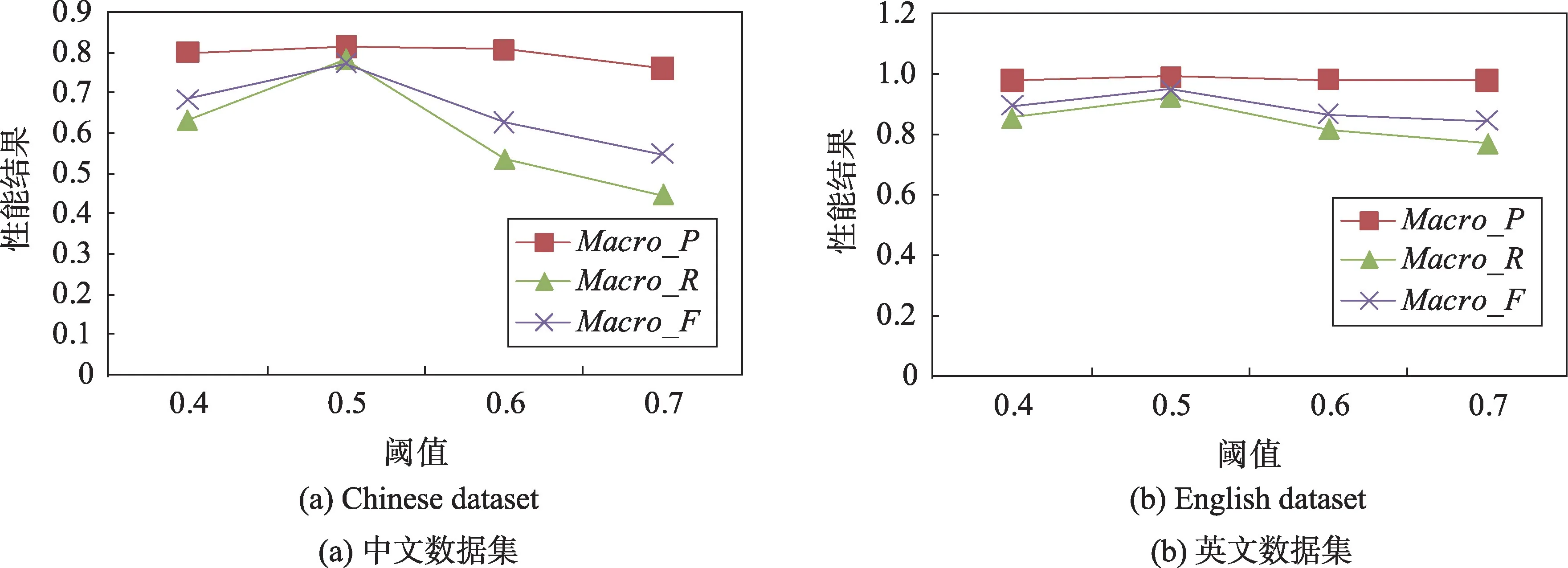
Fig.3 Comparison of performance results of different threshold values in Chinese and English datasets图3 中英文数据集中不同阈值得到的性能结果对比
