多源环境下中药实体统一视图构建策略
2020-10-14梁杨丁长松蔡雄
梁杨,丁长松,蔡雄
多源环境下中药实体统一视图构建策略
梁杨1,2,3,丁长松1,2,蔡雄4
1.湖南中医药大学信息科学与工程学院,湖南 长沙 410208;2.湖南省中医药大数据分析实验室,湖南 长沙 410208;3.中南大学计算机学院,湖南 长沙 410000;4.湖南中医药大学科技创新中心,湖南 长沙 410208
针对大数据环境下跨数据源查询面临的中药实体呈现多视图,且中药实体在各数据源中表现出属性不完整、多模态、差异性等问题,提出面向多源数据的中药实体统一视图的构建策略。基于实体属性间的相互关系,构建实体多视图融合整体架构,并对实体和属性等关键元素进行抽象化表示;以用户需求为约束提出基于词向量的相关度计算方法,采用Skip-gram模型训练出表征实体属性的词向量;提出基于欧氏距离和Jaccard系数的相关度算法,并以此为依据进行实体融合。共训练完成属性词向量6116个,其中有效词向量230个,以400对不同源中药实体作为测试集,分别采用AFCDS、FF和WVCC方法进行实体融合实验,其融合准确率依次为92.20%、88.47%和94.24%。基于词向量的实体融合策略有效可行,能充分利用属性间的有效信息,自适应性强,实体融合准确率较高,可为解决多源实体融合问题提供新的研究思路。
大数据;多源数据;实体融合;词向量;相关度
大数据时代背景下,中药实体往往分散存储于多个数据源中,从海量而混杂的数据中精确地提取出高利用价值的中药信息日趋迫切[1]。然而,数据结构差异大、来源广、价值密度低、更新实时等问题,给中药实体的规范和查询带来巨大挑战,中药实体统一视图建立的价值就在于从众多分散、异构的数据源中挖掘出隐含的、有价值的信息。中药实体统一视图构建的关键是识别相似实体,相似是指多个实体表象(命名不同的实体)指向现实世界中同一真实实体[2]。笔者基于实体间共有属性的相似度,采用实体相关度来度量实体间的相似程度,识别和聚合属于同一中药实体的实体表象。针对此类问题,众多国内外学者采用多种语义技术进行了相关研究。基于对象属性的分类算法把对象作为多维向量,其每个属性作为向量维度,可以计算两对象间的距离。而分数层融合方法可通过某种规则减少类内距离,增大类间距离,从而实现分数层融合识别,是最常用的融合方式。但分数层融合没有考虑对象之间的关联性,也不能很好区分类内和类间的数据[3]。针对很多分类模型没有考虑问题所在领域知识而造成分类效果不理想的问题,彭京等[4]提出了一种基于概念相似度的数据分类方法,该方法将属性矢量化,数据记录作为属性矢量的和,将数据间相关度计算转换为属性矢量及其相互投影的公式,从而得到任意两条数据的相关度。本体匹配方法能够发现本体语义相关实体之间的对应关系,近年来基于该方法的语义相关度研究取得了显著进展[5]。因此,本研究在多源异构环境下,通过基于词向量的相关度计算(word vector-based correlation calculation,WVCC)方法实现多源实体的有效融合,提出多源环境下实体统一视图的构建策略,为中药实体规范化提供参考。
1 资料与方法
1.1 数据来源及预处理
数据来自《中药学》[6]、《中药大辞典》[7]、《中华本草》[8]、《全国中草药汇编》[9]、药智数据(http://db. yaozh.com)、中药查询网(http://www.zhongyoo.com)。利用以上多源异构数据作为训练和测试对象,在预处理过程中构建常用中药分类样本数据集,见表1。
每种药物作为一个实体,包含性、味、归经、功效、适应症、用量(最小用量和最大用量)、注意事项等属性信息,且一种药物可有多种功效。以三七为例,其实体属性见表2。
表1 常用中药分类样本数据集
名称别名类别 性 味归经功效 一枝黄花大叶七星剑,一枝香解表药凉辛苦肝胆疏风清热,消肿解毒 生地干地黄,苄,生地,熟地,地髓,阳精,细生地,怀生地,鲜生地,原生地,怀庆地黄,还元大品清热解毒药凉甘苦心肝肾滋阴养血,温中下气 关木通马木通,苦木,丁香,丁翁利水渗湿药寒苦小肠,心,膀胱清热利尿,通经下乳 巴豆巴豆霜,七开,八百力攻下药热辛胃,大肠泻寒积,通关窍,逐痰行水,杀虫 白果银杏仁,灵眼止咳化痰药平甘苦涩肺肾敛肺气,定喘咳,止泻 木天蓼葛枣,马枣子,天蓼祛风湿药温辛肝肾心祛风除湿,通经益气 川椒花椒,大椒温里药温辛脾胃肾温中散寒,除湿止痛,杀虫,解鱼腥毒 沉香沉水香理气药温辛苦肾脾胃降气温中,暖肾纳气 谷芽稻芽消导药微温甘脾胃健脾开胃,消食和中 ………………… 名称适应症最小用量/g最大用量/g注意事项 一枝黄花感冒头痛,黄疸,小儿惊风 915不宜久煎,不宜久服 生地胎动不安,月经不调,崩漏,吐血1018泄泻者慎服 关木通口舌生疮,小便赤痛,闭经,膀胱炎,肝硬化腹水,心力衰竭水肿 1.5 5服用过量会引起肾衰竭 巴豆胸腹胀满,水肿,冷积凝滞,痰满闭塞 0.15 0.3无寒实积滞、孕妇及体虚者忌服 白果哮喘,痰咳,遗精,带下,支气管炎,肺结核,梅尼埃病 510有实邪者忌服 木天蓼经闭,风湿病,久痢,白癜风,积聚1530 川椒呕吐,腹痛泄泻,虫病,风寒湿痹,脚气病 3 8阴虚火旺者忌服,孕妇慎服 沉香呕吐,脘腹胀满,腰膝虚冷,男子精冷 1.5 3阴虚火旺,气虚下陷者慎服 谷芽泄泻,不思饮食,腹胀1018 ……………
表2 三七实体属性示例
序号属性属性元素/取值 1名称三七 2别名田七,金不换,山漆,田漆,血参,昭参,田三七,旱三七,猴三七,剪口七,人参三七,猴头三七 3类别化瘀止血药 4性温 5味甘,微苦 6归经肝胃,大肠,心 7功效散瘀消肿,止痛通脉 8适应症吐血,跌仆瘀血,心绞痛 9最小用量/g4.5 10最大用量/g9 11注意事项孕妇忌服
1.2 实验设置
为评估多源环境下中药实体统一视图构建策略的性能表现,实验平台采用真实的大数据集群环境,集群共6个节点,包含1个NameNode节点和5个DataNode节点,其软硬件详细配置信息见表3。
表3 实验平台详细软硬件配置信息
序号名称详细描述 1NamenodeDell OptiPlex 7040,4*CPU Intel Core i5-6500,Memory 8GB DDR4,Disk 1TB 7200rpm 2DatanodeDell Vostro 3470-R1328R,4*CPU Intel Core i3-7100,Memory 4GB DDR4,Disk 1TB 7200rpm 3SoftwareOS CentOS V6.4,Apache Hadoop V2.7.1 4IDEEclipse V4.5.2,PyCharm V2018.2.1
1.3 实体和属性表示
本研究主要针对多源异构的中药实体进行有条件融合,实体通常以多视图存储于多个数据源中,可有多个属性用以描述实体的内在特征。为统一表示多源异构环境下数据源、实体及实体属性,每个中药实体主要信息包含名称和属性两部分,则数据源可以表示为:
={,} (1)
式中,={1,2,…,n}表示某一数据源即多个实体的集合,={1,2,…,n}表示实体名称的集合,={1,2,…,n}表示实体属性的集合,表示该数据源中实体的个数,第个实体i分别对应实体名称i和实体属性i,特别地,中药实体属性i本质上是一个多维的属性向量,构成i的所有属性元素在数据预处理阶段根据设定的格式顺序进行初排序,实体属性向量i为:
i={i1,i2,…,im} (2)
式中,ii表示第个实体的第个属性元素(属性值),为实体属性向量i维数,不同数据源中参与比较的实体其初始属性向量的值可能不同。
1.4 多源实体多视图融合框架
由于中药多源异构的数据库涉及深层次且不统一的语法和语义信息,要高效准确地筛选出表示真实世界同一对象的不同名实体并进行合并和归类,处理难度大、复杂性高、结构化程度低[10-11]。因此,本研究通过对多源环境下实体的各属性进行相关度分析,最终实现实体多视图融合。主要流程为:①爬取来自不同数据源的有效数据,构建原始数据集;②对原始数据集进行数据预处理,主要包括分词、无效信息过滤、数据清洗、属性词排序、文件存储等操作;③根据本文定义的数据词典将属性特征向量化并基于Skip-gram模型训练其特征词向量;④根据本文提出的基于词向量的相关度计算策略分别进行属性相关度和实体相关度的计算,通过设定合适阈值,对相关度满足条件的所有实体对进行实体信息的聚类融合;⑤建立统一视图并输出结果。见图1。
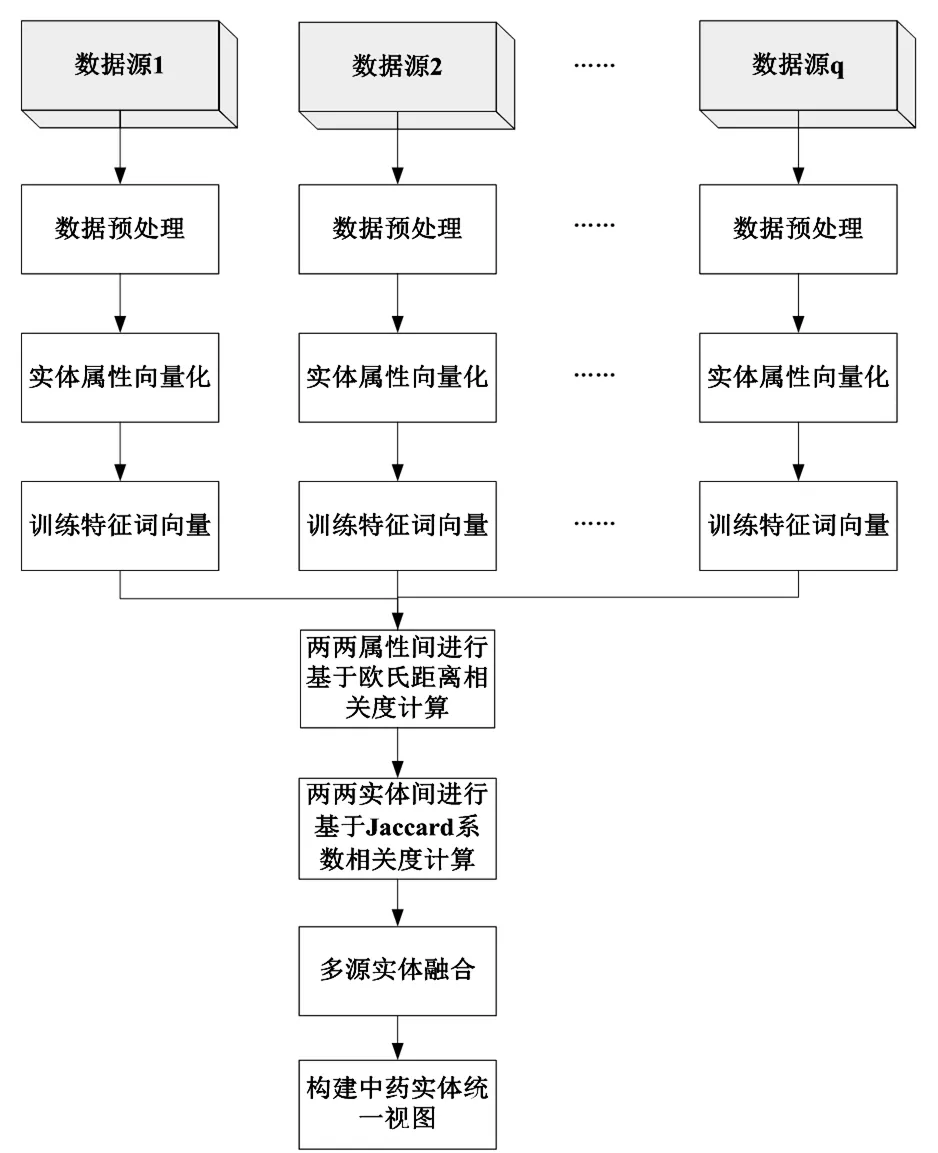
图1 多源环境下实体多视图融合框架图
1.5 基于词向量的相关度计算策略
在提取了实体并经过数据预处理过程获取到对应的属性向量后,需要通过计算属性相关度的方法对实体进行融合[12]。为此,本研究提出基于词向量的属性相关度计算策略。由于初始属性向量的属性元素最初全部以文本形式表示,并且每个属性向量维度可能各不相同,为有效度量文本间的相似性,需要根据向量空间模型(vector space model,VSM)的思想把文本属性转化成计算机可以处理的结构化数据,即中文文本转化为数值特征,则两个或多个实体文本属性向量相关度的问题可以通过计算向量之间的相似性来解决。
词向量是一种基于大量未标注的语料学习而来的低维分布式实数向量,充分挖掘了同义词之间的共现关系[13]。通过对上下文分析挖掘,词向量中每个值都具有一定代表性,都能表示一定的语义和语法特征。基于此,结合中药实体属性的特点和词向量的优势,提出一种基于词向量的相关度计算方法,该方法首先训练把每个文本属性映射为语义层面的特征词向量,接着引入Jaccard系数计算各词向量间的相似度,高于设定阈值者作为共现部分,最终计算整个属性向量的相似度。
1.5.1 基于Skip-gram模型训练特征词向量
针对传统的词向量表示方法中存在的诸如无法表达词与词之间的关系、特征离散稀疏性、维度灾难等问题,采用Mikolov等[14]提出的基于Hierarchical Softmax构造的Skip-gram模型训练特征词向量,该模型根据上下文关系定义了词的向量,关联度高的词有更近的距离,能够表现数据的内在特征。Skip-gram模型本质上是一个改进的三层神经网络结构,包括输入层、投影层和输出层,见图2。
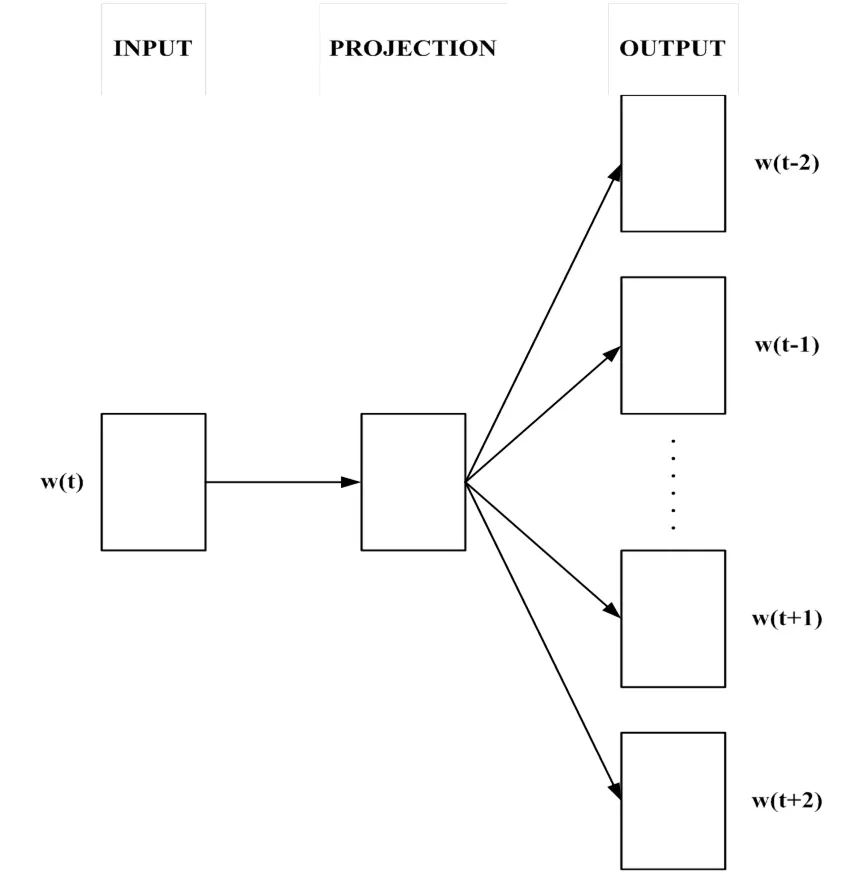
图2 Skip-gram模型
Skip-Gram模型比较适用于大规模数据集,模型输入()是一个特定的词向量,而输出是对应的上下文词向量,输出的词向量个数由算法设定的窗口大小(window size)决定。
在样本训练过程中,设给定的词序列为:1,2,…,n,需要被最大化的目标函数见公式(3)。
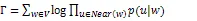
式中,数据词典={|=i,∈[1,n]},()表示当前词的上下文窗口,通常窗口大小为5~10,视具体情况设定,(|)是对应词向量u和w的层次Softmax回归值。
基于以上研究,Skip-gram模型训练参数较少,简单而高效,最终能够通过词向量之间的相似度表示属性在语义层面的相似度。
1.5.2 基于欧氏距离和Jaccard系数的相关度计算
1.5.2.1 属性之间的相关度
实体所包含的各属性根据Skip-gram模型训练得到对应的词向量,本研究通过欧氏距离计算2个特征词向量的相似度,衡量不同数据源实体属性的相关度。
在多维数据空间结构中,2个空间向量欧氏距离的大小可以反映其相似程度,其数值越小,表示2个向量越相近,亦说明2个属性越相关[15-16]。欧氏距离的定义见公式(4)。
Dist(ii,jj)=‖ii-jj‖2(4)
式中,ii、jj分别是属性ii、jj对应的特征词向量。由于训练后的词向量考虑了丰富的属性特征及向量中各元素之间的关联性,因此采用欧氏距离能够简单高效地表征2个向量之间的累积差异,并准确反映出2个词向量之间的相似性,亦即2个属性的相关度。
为方便相似度的计算和表达,限定欧氏距离的取值范围,对式(4)表示的欧氏距离进行归一化处理,得到属性相关度计算公式,见公式(5)。
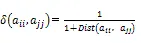
式中,δ(ii,jj)表示属性ii、jj的相关度,取值范围为[0,1]。显然,当δ(ii,jj)值越接近于1,属性ii、jj之间相关度越大;δ(ii,jj)值越趋近于0,属性ii、jj之间差别越大。
1.5.2.2 实体之间的相关度
由于实体属性向量可以唯一表征一个特定的实体,因此实体之间的相关度等价于实体属性向量之间的相关度。根据公式(2),实体属性向量由多个属性构成,若2个实体属性向量中相同或相近的部分越多,即共现属性越多,那么其相关度就越大。基于此,本研究引入Jaccard系数衡量实体属性向量间的相关度。从数学的角度,样本交集个数和样本并集个数的比值称为Jaccard系数。类似地,在实体属性向量的比较过程中,共现属性相对于所有属性所占的比例可以反映出2个属性向量间的相关度。具体形式见公式(6)。
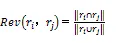
式中,i∩j表示属性向量i和j的共现属性,等同于交集部分,i∪j表示属性向量i和j包含的所有不重复属性,等同于并集部分,则(i,j)可以代表属性向量i和j的相关度。
基于以上分析,设计基于欧氏距离和Jaccard系数的相关度算法1,其伪代码如下。
输入:任意2个实体属性向量i={i1,i2,…,im},j={j1,j2,…,jn}
输出:实体属性向量i,j的相关度
Step 1:分别将实体属性向量i={i1,i2,…,im},j={j1,j2,…,jn}对应转换成由特征词向量构成的属性向量i={i1,i2,…,im},j={j1,j2,…,jn},初始化词向量比较次数(i,j)=0;
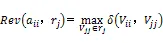
Step 3:把由Step 2中每个词向量ii得出的最大匹配度Rev(ii,j)与属性相关度阈值作比较,≥则将ii归为i和j的交集部分,否则将ii标记为独立不相关属性,并令Rev(ii,j)=0;每次比较后令(i,j)=(i,j)+1;
Step 4:同理,交换i和j,重复Step 2和Step 3的操作;
Step 5:综上,根据公式(6)得出任意2个实体属性向量i、j相关度计算公式:
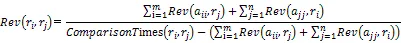
该式的分子是任意2个实体属性向量i、j的共现属性即i、j的交集,分母是i、j的并集,代表所有不重复的共现属性和非共现属性,因此,Rev(i,j)取值范围为[0,1];
Step 6:最后将实体属性向量i,j的相关度Rev(i,j)与属性向量相关度阈值λ进行比较,≥λ则表示两者相关,可以进行实体融合,否则表示不相关,两者指向不同的实体;
Step 7:返回i,j的相关度Rev(i,j)。
2 结果
采用《中药学》[6]电子版教材作为属性词向量的训练集(中文字符数约61万),训练完成词向量6116个,其中有效属性词向量230个,每个词向量维度为200维。部分属性元素对应的词向量训练结果见表4。
表4 部分属性元素对应词向量
属性元素对应词向量(200维) 苦(-0.330 246 0,0.023 602 5,-0.053 613 1,0.071 510 9,…,-0.357 792 0,-0.040 185 4,0.063 908 3) 寒(0.027 702 1,0.028 034 0,-0.285 268 0,-0.022 379 2,…,-0.308 720 0,-0.049 867 3,0.074 089 0) 热(-0.054 055 9,0.107 347 0,-0.142 854 0,-0.024 864 0,…,-0.218 180 0,-0.073 299 0,-0.022 821 1) 胃(0.061 085 1,0.049 659 8,-0.303 895 0,-0.126 678 0,…,-0.227 320 0,0.043 255 8,0.024 517 9) 肺(0.106 635 0,0.031 042 5,-0.215 672 0,-0.098 925 0,…,-0.288 672 0,-0.057 018 8,0.022 042 8) 肝(0.175 962 0,-0.087 078 2,-0.214 995 0,-0.048 901 3,…,-0.181 404 0,0.058 498 8,0.043 795 4) 高血压(0.035 183 0,0.023 626 3,0.016 806 3,0.133 913 0,…,0.119 485 0,-0.059 232 4,0.055 066 8) 牙痛(0.083 277 5,0.009 955 7,-0.061 582 4,0.034 277 6,…,-0.053 500 2,-0.037 828 7,0.008 046 1) 头痛(0.129 037 0,0.005 470 4,-0.127 878 0,0.028 358 7,…,-0.103 271 0,-0.074 404 9,0.069 649 3) 中风(0.069 706 1,0.009 521 96,-0.068 872 2,0.039 171 7,…,-0.021 983 4,-0.035 233 3,0.022 805 9) ……
基于公式(4)、(5)和计算出的属性词向量,首先选择不同数据源中的实体进行属性相关度计算,根据公式(2)所示实体表示方法,以罗布麻={甘,苦,心,肝,肾,清热降火,强心利尿,心脏病,高血压,神经衰弱,肾炎水肿,感冒,高血脂,心悸失眠,浮肿尿少,6克,9克},茶叶花={苦,凉,肝,肾,降火利尿,降血压,高血压,肝炎,肾炎水肿,高血脂,失眠,6克,12克}为例,部分属性相关度计算结果见表5。
根据以上对实体间属性相关度的统计情况,令属性相关度阈值为0.7,≥者认为是2个实体间的相关属性,基于算法1进一步计算多源异构实体间的相关度,用<数据源,实体>二元组形式表示某一数据源中的某一实体,部分实体相关度计算结果见表6。
基于实验结果,选取400对不同源实体,分别采用3种不同的实体融合方法进行相关度计算。其中,基于分类距离分数的自适应融合(adaptive fusion based classification distance score,AFCDS)算法将匹配分数与阈值之间的距离分数作为融合分数指标,不仅携带分类置信度的类别信息,也包含匹配分数与分类阈值之间的距离信息,并通过信息熵定义关联系数和特征权重系数[17]。特征融合(feature fusion,FF)方法从目标实体中提取数据或特征进行融合,将2个源特征向量组合成1个更完整、更具识别度的统一向量,如果2个输入向量的维度不同,则在低维向量的相应位置用零填充[18]。本研究基于词向量计算不同实体及实体属性间的相关度,与以上2种方法进行实验对比,结果见表7。
表5 不同实体间部分属性的相关度
<实体1,属性元素><实体2,属性元素>相关度 <罗布麻,甘><茶叶花,苦>0.502 173 <罗布麻,甘><茶叶花,凉>0.491 540 <罗布麻,苦><茶叶花,苦>1 <罗布麻,苦><茶叶花,凉>0.426 137 <罗布麻,心><茶叶花,肝>0.531 024 <罗布麻,心><茶叶花,肾>0.395 120 <罗布麻,肝><茶叶花,肝>1 <罗布麻,肾><茶叶花,肾>1 <罗布麻,清热降火><茶叶花,降火利尿>0.713 215 <罗布麻,清热降火><茶叶花,降血压>0.692 140 <罗布麻,强心利尿><茶叶花,降火利尿>0.835 214 <罗布麻,心脏病><茶叶花,高血压>0.635 260 <罗布麻,心脏病><茶叶花,肝炎>0.573 010 <罗布麻,高血压><茶叶花,高血压>1 <罗布麻,高血压><茶叶花,肝炎>0.599 269 <罗布麻,神经衰弱><茶叶花,失眠>0.859 848 <罗布麻,浮肿尿少><茶叶花,肾炎水肿>0.812 143 ………
表6 不同数据源间部分实体的相关度
<数据源1,实体> <数据源2,实体>相关度 <中药大辞典,罗布麻><中华本草,茶叶花>0.957 306 <全国中草药汇编,藜芦><中药大辞典,山葱>0.871 354 <中药大辞典,天茄子>
表7 不同实体融合方法实验结果比较
方法计算正确的强相 关实体/对中药数据库有记 载的实体/对实体融合准 确率/% AFCDS27229592.20 FF26129588.47 WVCC27829594.24
3 讨论
实体是指真实世界中客观存在并可相互区分的对象或事物,是代表特定事实信息的重要语义单位。属性则是实体具备的某一特性,一个实体由若干个属性来描述。如“半夏”“青蒿”“三七”等属于中药类别的实体,其对应的性味归经、功效作用、药材性状、药理作用等是中药实体的属性。
然而,不同来源但含义相同的中药实体往往具有多个名称,以“半夏”为例,就有“三叶半夏”“三步跳”“麻芋子”“水芋”“地巴豆”“水玉”“地文”“老和尚头”“泛石子”“地珠半夏”等近20种别名。为判断多源环境下的实体是否指向同一个真实的对象,本研究提出构建多源实体的统一视图,通过将相关度高的实体进行属性合并和名称等价标记等处理,实现多源实体的信息融合和聚集,从而形成更准确、更完整的实体统一视图。
为构建多源环境下中药实体统一视图,本研究提出分别对实体属性相关度和实体间相关度进行量化计算,并对常见的实体属性进行统计和整理。由表1、表2可以看出,某一中药实体由不同的属性取值组合表示,同一中药实体在不同数据源中可能存在不同名或属性不一致等问题。为解决此类问题,本实验中实体属性向量不包含“名称”和“别名”,某一数据源中任一中药实体i可以表示为i={i1,i2,…,im},ii表示第个实体的第个属性元素,每个属性元素可用Skip-gram模型训练出的词向量来等效表示。
对于存储在多个数据源中的实体,通常存在属性表述不同但本质接近的情况,本研究称这类实体为强相关实体,否则称为不相关实体。根据多源实体相关度实验数据的统计结果,令实体相关度阈值λ为0.85,则实体相关度≥λ的2个实体可以认定为强相关实体,能够进行实体属性融合,从而构建该实体的统一视图。
本研究结果显示,WVCC方法实体融合准确率达到94.24%,与基于分类距离分数的自适应融合识别方法、分数层融合方法等常见算法相比,其实体融合准确率较高,为多源环境下实体融合提供了一种可靠、新颖的解决策略。
综上所述,为解决大数据环境中跨数据源查询面临的实体呈现多视图而导致的数据不规范、查询低效、信息缺失等一系列问题,本研究提出了多源环境下实体统一视图的构建策略,首先设计实体融合架构图,接着对实体和属性进行数学抽象,然后提出基于词向量的相关度计算方法,该方法主要分为基于Skip-gram模型特征词向量的训练、基于欧氏距离和Jaccard系数的相关度计算等阶段,最终实现不同源实体的准确融合。实验结果表明,本研究提出的实体统一视图构建策略有效可行,实体融合准确率高,并在查询对象完整性及查询时间开销方面都有较好表现,进一步扩大标准训练集的规模、改进数据融合算法是下一步的研究方向。
[1] 于静,刘燕兵,张宇,等.大规模图数据匹配技术综述[J].计算机研究与发展,2015,52(2):391-409.
[2] 孟小峰,杜治娟.大数据融合研究:问题与挑战[J].计算机研究与发展,2016,53(2):231-246.
[3] 张瑶,李蜀瑜,汤玥.大数据下的多源异构知识融合算法研究[J].计算机技术与发展,2017,27(9):12-16.
[4] 彭京,唐常杰,元昌安,等.一种基于概念相似度的数据分类方法[J].软件学报,2007,18(2):311-322.
[5] SHVAIKO P, EUZENAT J. Ontology matching:state of the art and future challenges[J]. IEEE Transactions on Knowledge and Data Engineering,2013,25(1):158-176.
[6] 高学敏,钟赣生.中药学[M].2版.北京:人民卫生出版社,2013.
[7] 南京中医药大学.中药大辞典[M].2版.上海:上海科学技术出版社, 2006.
[8] 国家中医药管理局《中华本草》编委会.中华本草[M].上海:上海科学技术出版社,1999.
[9] 王国强.全国中草药汇编[M].3版.北京:人民卫生出版社,2014.
[10] LI G L, HE J, DENG D, et al. Efficient similarity join and search on multi-attribute data[C]//ACM SIGMOD International Conference on Management of Data. ACM,2015:1137-1151.
[11] SELLAMI R, DEFUDE B. Complex queries optimization and evaluation over relational and NoSQL data stores in cloud environments[J]. IEEE Transactions on Big Data,2018,4(2):217-230.
[12] RONALD Y, FRED P, PAUL E. Multiple attribute similarity hypermatching[J]. Soft Computing,2018,22(8):2463-2469.
[13] 张群,王红军,王伦文.一种结合上下文语义的短文本聚类算法[J].计算机科学,2016,43(S2):443-446,450.
[14] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[C]//1st International Conference on Learning Representations(ICLR 2013),2013:1-12.
[15] DRAISMA J, HOROBET E, OTTAVIANI G, et al. The Euclidean distance degree of an algebraic variety[J]. Foundations of Computational Mathematics,2016,16(1):99-149.
[16] PAPADAKIS G, KOUTRIKA G, PALPANAS T, et al. Meta-blocking:Taking entity resolution to the next level[J]. IEEE Transactions on Knowledge and Data Engineering,2014,26(8):1946-1960.
[17] 张露,王华彬,陶亮,等.基于分类距离分数的自适应多模态生物特征融合[J].计算机研究与发展,2018,55(1):151-162.
[18] HAGHIGHAT M, ABDEL-MOTTALEB M, ALHALABI W. Discriminant correlation analysis:real-time feature level fusion for multimodal biometric recognition[J]. IEEE Transactions on Information Forensics and Security,2016,11(9):1984-1996.
Construction Strategy for Unified View of TCM Entities in Multi-source Environment
LIANG Yang1,2,3, DING Changsong1,2, CAI Xiong4
To propose a construction strategy of unified view of TCM entities for multi-source data targeting the fact that TCM entities are faced with multi-data query with multiple views in the big data environment, and that TCM entities exhibit incomplete attributes, multi-modality, and differences in each data source.Based on the interrelationship between entity attributes, an entity multi-view fusion overall architecture was constructed, and abstract representations of key elements such as entities and attributes were carried out. A word vector-based correlation calculation method was proposed based on user requirements. The Skip-gram model was used to train word vectors that characterize entity attributes. A correlation algorithm based on Euclidean distance and Jaccard coefficient was proposed, and the entity fusion was based on this.The experiment trained a total of 6116 attribute word vectors, including 230 effective word vectors. 400 pairs of heterologous TCM entities were used as test sets, and the entity fusion experiments were carried out by AFCDS, FF and WVCC respectively. The fusion accuracy was 92.20%, 88.47% and 94.24%.The entity fusion strategy based on word vector is effective and feasible, and can make full use of the effective information between attributes. It has strong adaptability and high accuracy of entity fusion, and can provide new ideas for solving the problem of multi-source entity fusion.
big data; multi-source data; entity fusion; word vector; correlation

R28;R2-05
A
1005-5304(2020)09-108-07
10.3969/j.issn.1005-5304.201906116
国家重点研发计划(2017YFC1703306);湖南省教育厅科学研究项目(19C1391);湖南省重点研发计划(2017SK2111);湖南省教育厅重点项目(18A227);湖南省自然科学基金(2018JJ2301);湖南省中医药科研计划重点课题(2020002);湖南中医药大学电子科学与技术学科开放基金(2018DK04)
丁长松,E-mail:dinghongzhe@yeah.net
(2019-06-09)
(2019-07-05;编辑:陈静)
