强化特征提取能力的航拍图像目标检测算法∗
2020-10-14施皓晨李海林
徐 智 施皓晨 项 超 黎 宁 李海林
(南京航空航天大学电子信息工程学院 南京 211106)
1 引言
近年来,深度学习在视频图像领域的研究应用火热,特别是目标检测方面。深度学习的吸引力之一来自于对大量标注训练数据的有效学习,结合硬件加速计算资源的支持,使得其在目标检测方面取得了一定程度的成功。目前主要存在两大类别的目标检测方法:一阶和二阶目标检测方法。它们之间的主要区别在于是否存在提取候选区域的级联模块。这种级联模块可以使网络有针对性地检测疑似目标区域的物体,使其精度高于一阶目标检测方法。但由于多了这样的级联模块,会使得模型的复杂度高,在检测速度上低于一阶检测方法。
二阶目标检测方法中具有代表性的是R-CNN系列检测方法。Ross Girshick 等相继提出RCNN[1]和Fast R-CNN[2],这两种方法都是通过选择性搜索方式(Selective Search,SS)来产生目标检测的感兴趣区域。后来,Ross Girshick 等[3]又提出了Faster R-CNN方法,其采用了内嵌的区域候选网络(Region Proposal Network,RPN)。RPN 网络相对SS方法更高效,在每张图上生成感兴趣区域仅需要10ms 的 时 间 。 此 外 ,何 凯 明 等[4]提 出 的Mask R-CNN 方法不仅可以应用于图像分割,也可以用于图像目标检测。针对目标检测,这个方法的优势在于对ROI pooling 方式的改进。他提出了新的ROI Align 操作,即加入了双线性插值的方法来精炼感兴趣区域,这种操作能显著提高模型的检测精度。除了R-CNN系列方法,Dai等[5]提出R-FCN网络模型,用专门的卷积层构建位置敏感分数地图来代替Faster R-CNN 的全卷积结构,极大降低了网络的参数量。此外,Lin 等[6]提出FPN 目标检测方法,利用特征金字塔思想做目标检测,在不同尺度特征层进行独立的目标预测。
一阶目标检测方法虽然在检测精度上表现欠佳,但其检测速度非常快。一阶目标检测方法主要包括YOLO 系列[7~9],SSD 方法[10],DSSD 方法[11]和RetinaNet 方法[12]。目前,YOLO 系列方法已经更新到YOLOv3,YOLOv3 改进了对小目标的检测精度,主要是由于使用了ResNet 特征提取架构和多尺度预测方式。但同时模型牺牲了检测中等目标的性能。YOLOv2 采用了很多技巧,如高分辨率分类器,细粒度特征,批归一化等等方法,因此它比YOLOv1更好、更快、更强。对于小目标检测,SSD方法略好于YOLOv1,它参考了YOLOv1 直接预测回归框位置和目标的分类概率的方式,同时又借鉴了Faster R-CNN 大量使用Anchor boxes 来提升检测精度。与SSD 方法相比,DSSD 方法使用了更好的基础网络(ResNet)和反卷积层,它的跨层连接方式给予浅层网络更好的特征信息表达。此外,RetinaNet 是一个基于FPN 的检测网络,它依靠最终的Focal loss 来解决背景负样本过多造成类别不平衡的问题。RetinaNet 结构精炼而强大,是目前比较好的一阶目标检测方法之一。
对于航拍视角下的目标检测,存在背景信息复杂、目标尺度小等问题。针对这些问题,本文提出的方法可以很好地解决这些问题。本算法不仅在数据集上对小目标进行尺度和比例聚类来保证网络模型对小目标的初始先验感知,而且引入密集拓扑结构和最优池化策略,利用注意机制思想提高模型对小目标的特征提取能力。此外,本文提出的模型检测速度快,能进行实时检测。
2 算法介绍
由于像YOLOv2 这种一阶检测模型结构新颖、应用潜力大,并拥有实时检测的能力,在检测精度上具有非常大的提升空间,故本文在YOLOv2 结构基础上提出新的检测模型(Dense of You Only Look Once,DOLO),如图1 所示,其中1/2n(n=0,1,…,5)表示当前特征块的大小是输入图片尺寸的1 2n,故整个网络共有5 次下采样过程。且模型中加入ResNet-v1-50预训练网络,使初始模型拥有更好的特征提取能力。并针对小目标漏检问题,本文提出一系列改进方案,适用于航拍视角下地面小目标检测,并能达到实时检测的效果。
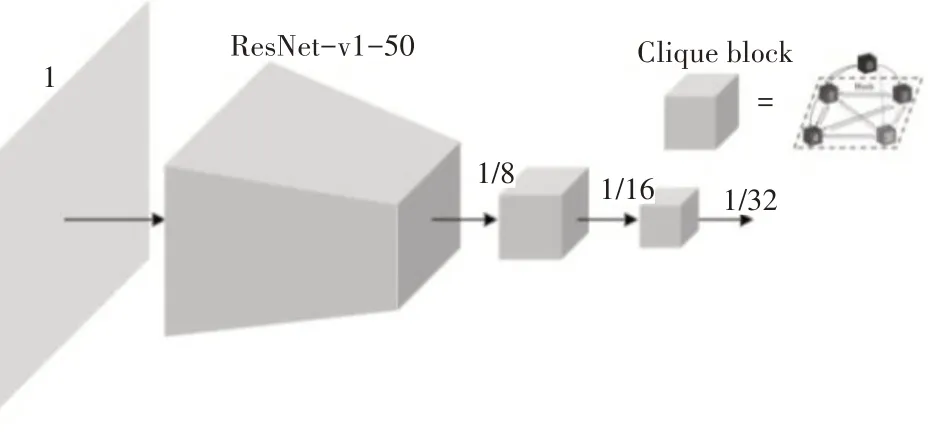
图1 DOLO网络模型
2.1 网格设计和Anchor boxes聚类
由于网络最终输出S×S×F 的特征块,其中S为特征图的宽或高的尺寸,F 为特征层数。由于5次下采样,故由特征块反向映射至原图可得32S×32S 的网格图,如图2(a)所示,其S 值为13。本模型根据1920×1080 大小的航怕图像原始尺寸将网格设置为18×10,如图2(b)所示。不等比例的网格设置不仅可以与原始目标比例相适宜,而且增加了横向网格的数量。精细化的横向网格设置可以更好地保留小目标的信息特征。

图2 不同比例的网格设置
Anchor Boxes 的比例尺寸设置在一定程度上借鉴了Faster R-CNN 中的候选区域提取的思想,它将作为每个网格预测回归框的参考窗口。故本文通过航拍数据集中各种车辆目标的尺寸进行K-Means聚类统计。
如图3 所示,设计了3 个不同比例及1 个不同尺度的Anchor boxes,分别为1∶1、1∶2、2∶1 以及3∶3。而且根据对网格比例数量的设计,每个网格负责4 个回归框的预测,其不存在每个网格中目标数量多于回归框数量的情况,这也确保了模型赋予小目标充足的预测框的能力。
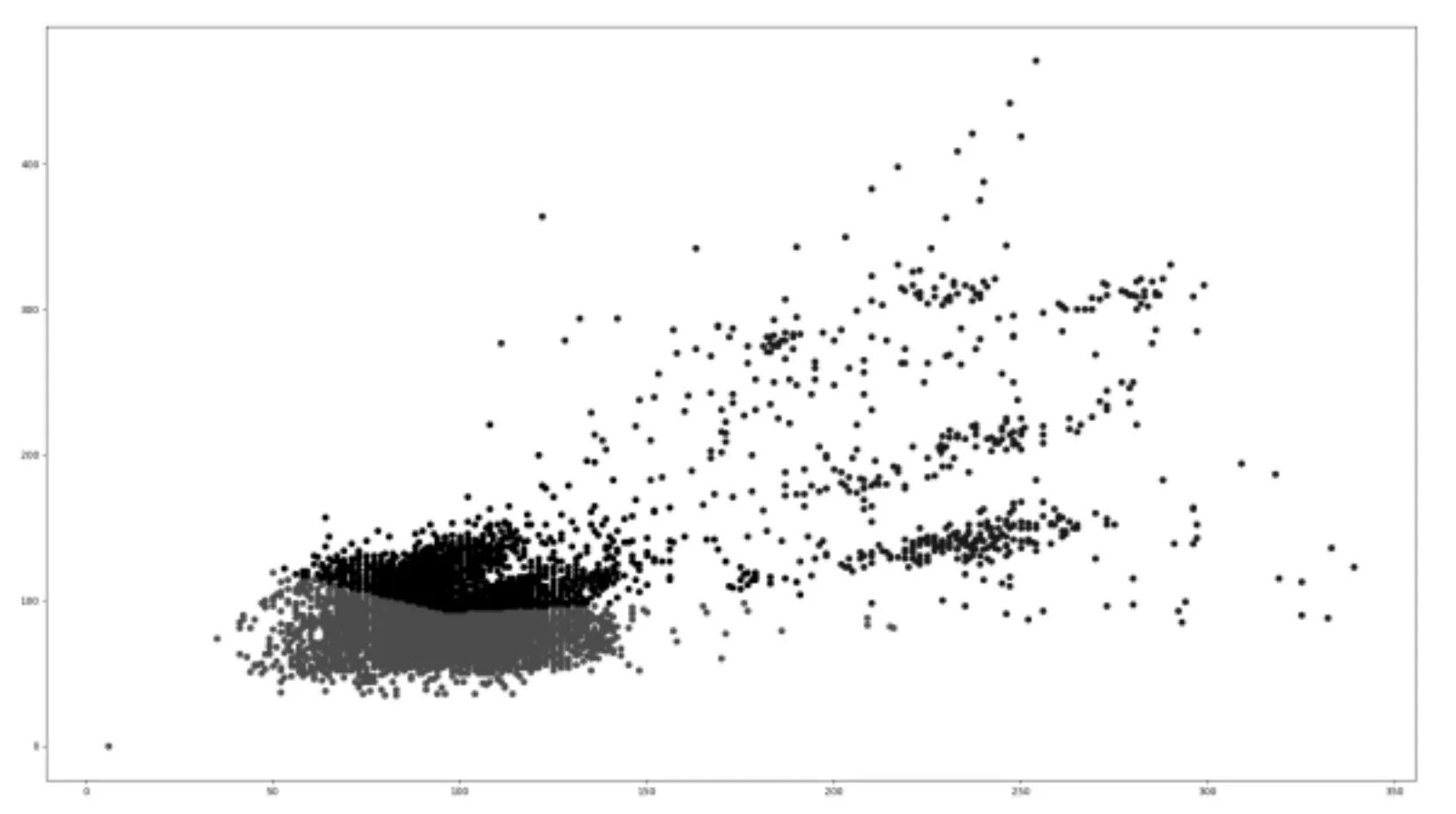
图3 航拍目标尺寸K-means聚类结果图
2.2 网络预测
根据本文对模型的网格设置,最后网络会输出18×10×F 的特征块,如图4 所示。网络中某一网格预测的是相对于对应Anchor boxes 的偏移量以及某一类目标的置信度,分别为目标位置信息的偏移量tx,ty,tw,th和置信度to,然后通过以下公式转换:
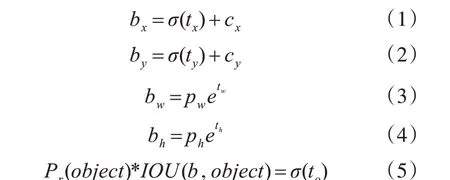
其中cx、cy为该网格左上角的坐标,tw、th为对应Anchor boxes 的宽和高,bx、by、bw、bh则为预测的回归框的位置信息。此外,Pr(object)表示当目标中心落在该网格中时为1,否则为0,IOU(b,object)则表示预测目标的回归框和真实框之间的交并率信息。
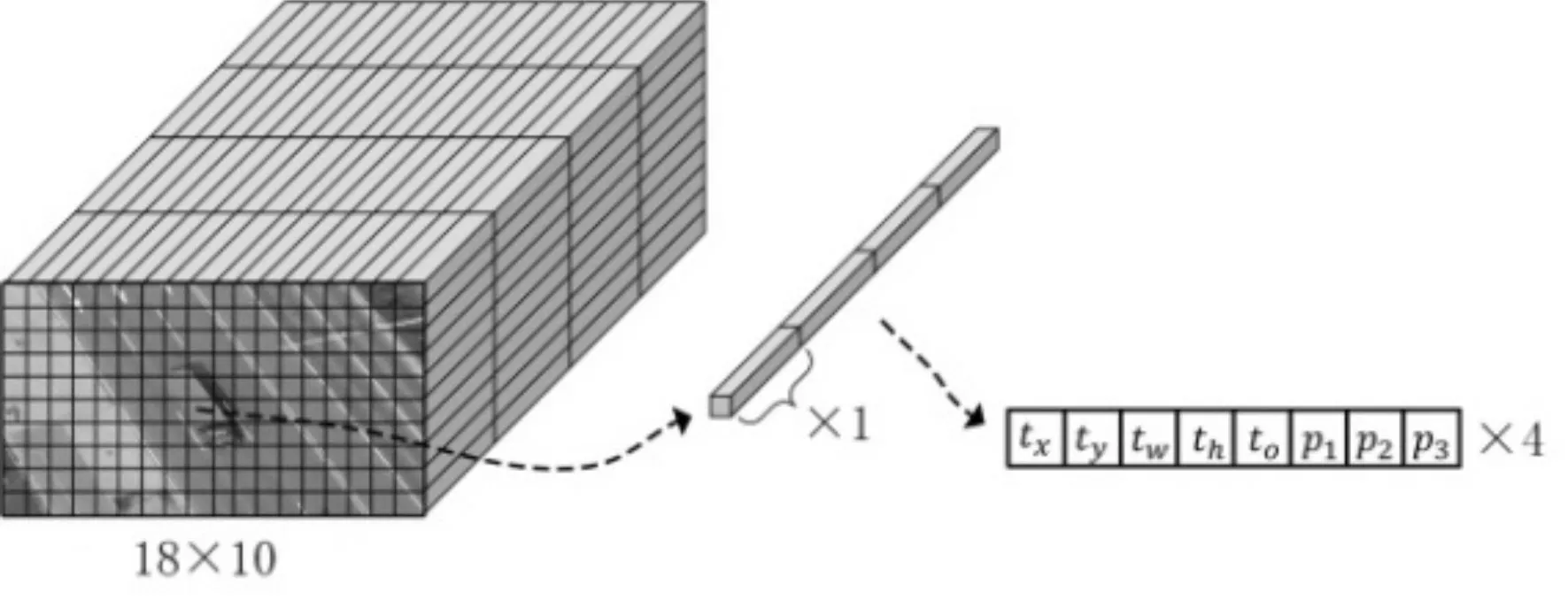
图4 网络输出特征块示意图
2.3 特征提取方式强化
为提高对小目标的检测能力,在连接方式上,YOLOv2 模型提出细粒度特征,即在网络末端添加一个Passthrough Layer 来连接中浅层特征,但一个跨层连接的方式不足以充分利用到浅层特征;YOLOv3 则利用了ResNet 基础网络架构,但随着网络的加深,在同一个位置过多使用Addition 方式来叠加信息,则会弱化信息流,一定程度上相当于特征信息的丢失[13~14]。DSOD[15]则采用DenseNet[16]连接思想,将网络中每一层都直接与前层相连的方式来能实现特征的重复利用。但是DenseNet 的连接方式会使得网络的参数量随着网络深度的加深呈指数增长。故本文提出新的连接方式应用于网络中的特征提取。
首先,我们定义一个非线性变换组合函数F(x),具体为
1)通过使用批归一化(Batch Normalization,BN)对每一层输入进行归一化,提高网络训练效率。
2)应用ReLU激活函数来增强网络的非线性拟合能力,降低网络出现过拟合情况的概率。
3)通过采用尺寸为3×3 的卷积核来提取图像特征信息。
即:
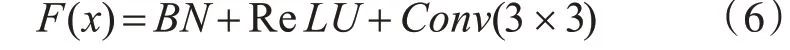
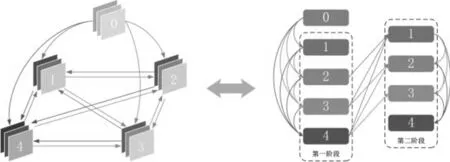
图5 CliqueNet网络结构图
其次,我们定义密集连接结构,为CliqueNet 连接方式,如图5 所示。第一阶段用于初始化块中的所有层,从第二阶段开始重复细化层。在第一阶段,输入层F0通过单向连接初始化该块中的所有层,连接每个新的层以更新下一层。从第二阶段开始,每一层开始交替更新。由于第二阶段得到更好的关注并吸收了更多高级视觉特征,所以仅将第二阶段的特征信息作为下一个块的输入。除了要更新的顶层之外,所有层都相互连接作为底层,并且他们的相应参数也是相互连接的。因此,第k(k ≥2)循环中的第i(i ≥1)层可以表示为
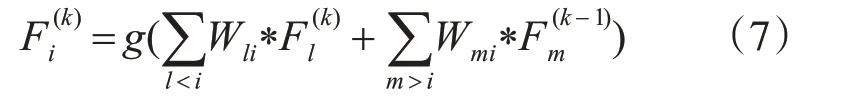
其中*表示带参数W 的卷积运算,g(⋅)为非线性激活函数,Wij在不同阶段不断重复使用。每个层将始终从最近更新的层接受反馈信息。由于每次传播带来自上而下的细化,它实现了空间注意机制。这种循环反馈结构可以确保块中所有层之间的信息传递最大化。
最后,为减少网络模型的参数量,通过采用1×1 的卷积核来缩小Feature Maps 数量,然后对输出进行池化下采用操作,如图6 所示。由于针对于随机初始化的网络模型,Average Pooling 相比较Max Pooling 能使网络模型拥有更好的性能[17],而Max Pooling 又非常适合稀疏化的信息特征(如经过Re-LU 激活函数后的信息特征)[18]。所以,找到最优池化策略是提高小目标检测精度的关键之一。
定义池化操作函数,如下所示:
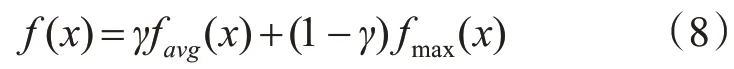
其中 γ ∈[0,1],favg(x)为平局池化函数,fmax(x)为最大值池化函数。但是由于γ 的取值极度依赖于交叉验证实验,导致其自适应能力差,故我们利用网络学习来衡量favg(x)和fmax(x)之间的比例值,故式(8)转化为
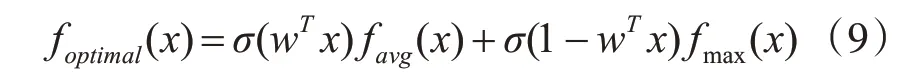
其中 σ(⋅)为Sigmoid 函数,w 为一个可学习的网络权重参数。

图6 最优池化步骤图
3 实验结果与分析
本文所使用的航拍数据集采集于海拔60m~70m 低空中,包括不同光照强度(晴天、阴天和雨天)、不同路段(高速公路、城市道路和交叉口)以及不同道路走向(横向,斜向)。本文主要研究的目标为汽车,公交车和卡车这三类车辆目标。
航拍图像的分辨率为1920×1080,模型的输入图片尺寸为574×320。此外,设置初始学习率为0.001,使用Adam 优化器自适应调整学习率。IOU阈值设置为0.5,经NMS操作输出最终的预测结果。
本文设计了针对航拍小目标检测的卷积神经网络,并在航拍数据集中将本文算法与几种一阶的检测方法进行性能比较,结果如表1 和图7 所示。从表1 可看到,针对航拍数据集,YOLOv2 方法和SSD300 方法对小目标的检测效果低于其在PASCAL VOC2007 公共数据集上的性能表现,mAP 值仅达到49.3%和50.9%。对于YOLOv3 模型,它的多尺度预测机制使得其对小目标检测非常有效,可以达到86.7%的精度,但是其检测速度却降低至17fps。对于本文提出的模型,Dense block 表示模型尾部的密集特征块采用DenseNet 连接方式,而Clique block则表示采用CliqueNet连接方式。
可以看到,本文算法在牺牲较小检测速度情况下获得了极大的精度提升,其中DOLO(Dense block)模 型mAP 值 达 到87.1% ,DOLO(Clique block)模 型mAP 值 达 到89.2%。DOLO(Clique block)模型性能较好的原因主要是因为其循环结构的设计融合了注意机制思想,使得模型更加关注局部小目标信息。此外,Faster RCNN 方法虽然能达到较高的检测精度,但是其检测速度较慢,仅有15fps。
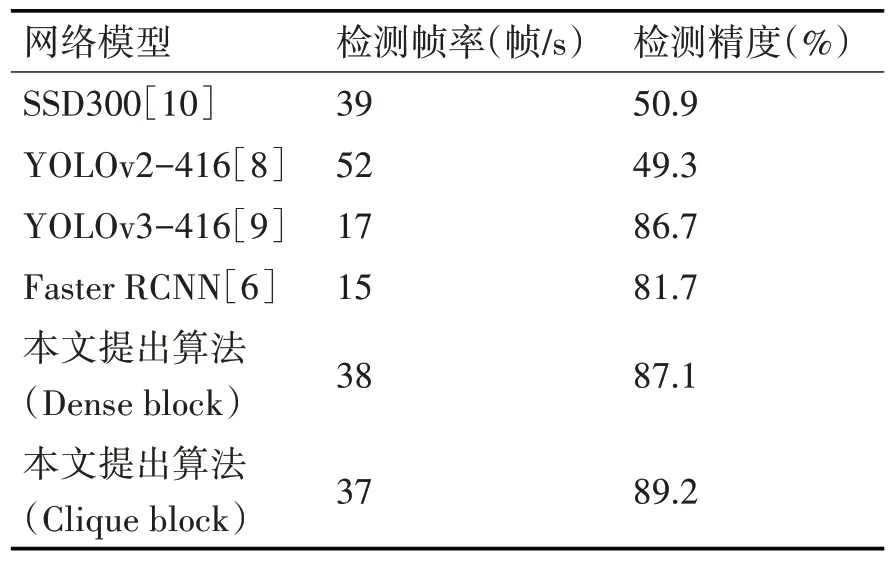
表1 不同检测模型性能对比表
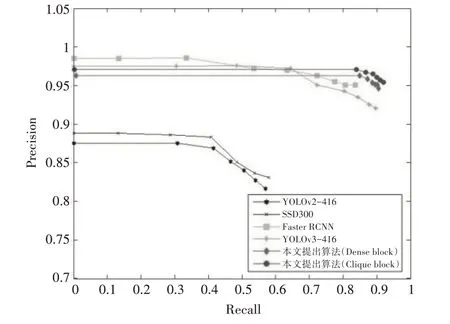
图7 不同检测模型性能对比图
通过设置不同的置信度阈值={0.50,0.55,0.60,0.65,0.70,0.75,0.80,0.85,0.90,0.95,1.00}情况下,得到相应的Precision-Recall 图,如图7 所示。每条曲线下的面积大小即为对应模型的mAP值。本文所提出的算法在保持较高Precision 值情况下,拥有较高的Recall值,故总体性能较好。
此外,从图8 可以看到,DOLO(Clique block)模型比DOLO(Dense block)模型目标定位更加准确(如图中箭头所示),由于CliqueNet 的连接方式比DenseNet更为精炼独到,引入了循环结构和注意机制,故能带来更好的定位精度。
本文做了3 个场景下的车辆目标检测实验,如图9~图11 所示,对比了原始YOLOv2 模型、SSD300模型和本文模型DOLO(Clique block)。可以看到,YOLOv2 模型检测结果较差,漏检现象严重,特别是在车辆目标较多的情况下。SSD 模型的检测结果相比较YOLOv2 表现较好,但同样存在漏检现象。本文改进的模型对小目标检测拥有比较好的鲁棒性,即使在小目标半遮挡的情况下也能将其检测出来,对车辆漏检可能性比较小。

图8 模型检测结果对比

图9 场景一下不同模型检测结果对比图(YOLOv2(a,d)、SSD300(b,e)和DOLO(Clique block)(c,f))

图10 场景二下不同模型检测结果对比图(YOLOv2(a,d)、SSD300(b,e)和DOLO(Clique block)(c,f))

图11 场景三下不同模型检测结果对比图(YOLOv2(a,d)、SSD300(b,e)和DOLO(Clique block)(c,f))
4 结语
本文针对航拍目标的特点,分析设计了针对于小目标检测的神经网络模型。设计了结合密集拓扑结构和最优化池化策略的特征提取模块,极大地提高了模型对小目标特征提取能力,使模型在保持现有检测速度的情况下增强了对小目标检测的鲁棒性。此外,针对样本类别不均衡情况下的目标识别,本模型仍存在很大的探索空间,需要进一步对模型结构做出改良。
