基于深度信念网络的驾驶行为研究∗
2020-10-14黄丽蓉潘雨青
黄丽蓉 潘雨青
(江苏大学计算机科学与通信工程学院 镇江 212013)
1 引言
世界卫生组织2015 年指出交通事故死亡人数近140 万人,伤残人数约2000 万至5000 万人次[1]。据公安部统计显示,2016 年我国道路交通事故864.3万起,造成死亡6.3万。导致事故发生的主要原因之一是驾驶人员的不良驾驶行为,驾驶行为与驾驶安全性有着密切的关系,因此驾驶员的驾驶安全性研究具有重要价值[2]。车载GPS 模块等车载设备的不断普及,让车辆的行驶信息和驾驶员的操作行为记录和保存成为可能,其中保存的大量数据为学者研究驾驶员的驾驶行为习惯提供了巨大的价值[3]。
当前,已有不少人从不同的方面的对驾驶行为进行分析研究。任慧君等利用GPS 数据来计算行驶速度、加速度和转弯信息来分析公交车司机的驾驶安全性[3]。庄明科、Tseng 等研究了危险驾驶与驾驶员行为之间的关系,包括风险驾驶和驾驶经验与技术、驾驶员的态度与驾驶员性格之间的关系[4~5]。在这些研究中,主要利用数据分析方法计算驾驶行为的一些主要影响因子,以此研究驾驶安全性。由于驾驶影响因子众多,这些论文对部分因子进行讨论,未对驾驶行为行为加以分类研究。
徐国功等[6]利用K-means 对驾驶员进行聚类,用GMM对聚类结果分析评估。Johnson等[7]通过对传感器采集到的数据进行降噪处理,采用基于分类的机器学习方法对候选行为特征提取进行分类学习。刘凯利等[8]根据驾驶行为与路况环境和行驶信息之间的关系,运用决策树C4.5 算法对驾驶行为进行分类。王忠民等[9]利用移动终端采集到的车辆三轴加速度数据,通过SF-CNN 识别分析驾驶员行为。在这些研究中,驾驶影响因子选取不够细化,有的分类方法未能对影响因子抽取更深层次的特征以研究驾驶行为。
基于此,本文根据GPS 数据,提取驾驶行为的相关特征因子,并根据这些特征因子,提出一种基于深度信念网络的驾驶行为研究方法,对驾驶员的行为进行分析。
2 驾驶员行为数据分析
驾驶行为研究过程主要是通过分析研究各种行车数据,从中挖掘影响驾驶员驾驶行为的特征参数,并对驾驶行为聚类分簇,利用分类器根据评价体系对驾驶行为实现在线评估,从而对驾驶行为进行约束,提高安全性。
2.1 驾驶行为影响因子选取
影响驾驶员驾驶行为的因素众多,不同的影响因素数据的采集需要不同资金成本与时间成本的投入,GPS数据采集明显比其他的车载设备的实用性更好,在这里使用的行车数据均采自GPS。根据这些行车数据的分析和前人的一些研究成果,驾驶行为分析主要是驾驶安全性的研究。
驾驶安全性行为一般分为严重危险驾驶、危险驾驶、平稳驾驶和谨慎驾驶。事故发生的主要影响因子有速度、速度标准差、负加速度、负加速度标准差、正加速度、正加速度标准差。这些都可作为驾驶行为特征的重要参数,是驾驶行为分析的重要依据[10]。另外,在安全驾驶中急加速、急减速和超速具有很大的安全隐患,特别地,在交通拥堵的时候,这些行为会引发车辆追尾和车辆部件磨损。
2.2 影响因子参数研究
1)速度均值、速度标准差
刘志强等[11]表明与交通事故发生的关系,即速度标准差越大,车速分布就越离散,发生交通事故的概率也就越高。此外,国内有专家对速度标准差和亿公里事故率进行了回归分析[11],如图1 所示。澳大利亚RAT 研究指出车速与交通事故风险增长之间的关系[12~13],如表1所示。
这两个表征驾驶行为特征的重要参数的计算公式为

其中,vavg为车辆在道路上的速度均值,vi是驾驶员第i 次的驾车速度,vstd是在这过程中的速度标准差。

图1 车速标准差与亿车公里事故率的关系图
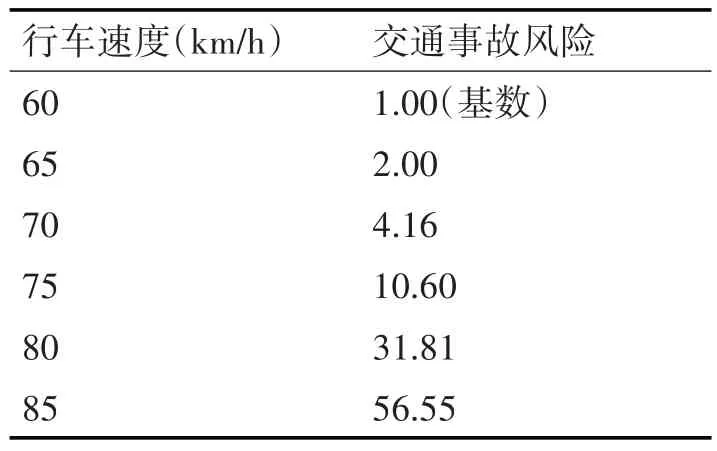
表1 行车速度与交通事故风险的关系
2)负加速度均值、负加速度标准差、急减速
减速行为是由于驾驶员对加速踏板的释放或制动踏板的压制引发的结果,可以用负加速度来描述这一减速过程。当负加速度越大说明车辆减速越不平稳,越会影响行车安全。负加速度和负加速度标准差的计算公式为
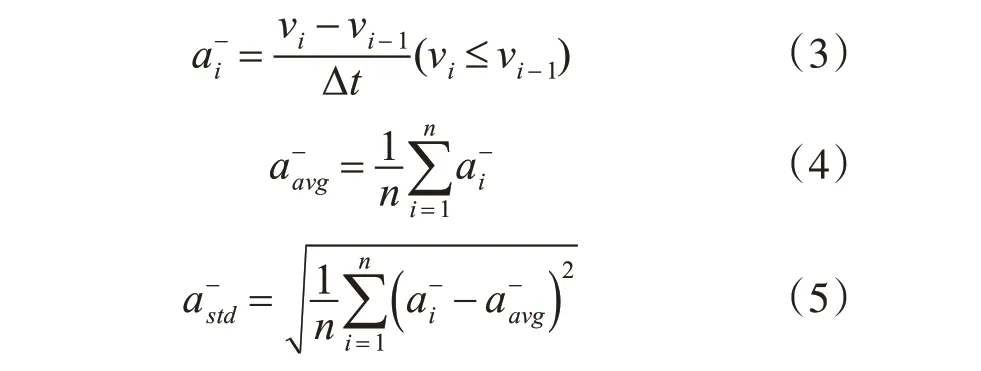

3)正加速度均值、正加速度标准差、急加速
相应地,加速行为是由于驾驶人员对加速踏板的一个踩压控制或制动踏板的释放控制。如果压制或释放过度,即加速度过大,会对当前的驾驶环境造成严重的危害。因此,正加速度和正加速度标准差可以作为衡量驾驶行为的重要参数,它们的计算公式为
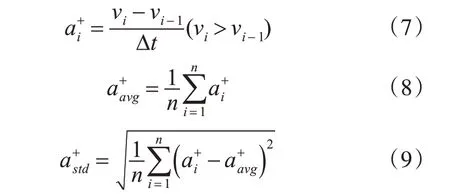

3 基于DBN模型的驾驶行为分析
本文的数据主要来源于EXLIVE 超越位置服务平台所存储的2017 年3 月份的GPS 历史数据。由于车辆并不是一直在运行当中的,在本文中只考虑车辆不是在连续停车的情况下来进行研究分析。原始数据包括2000 位驾驶员的驾驶信息,数据处理结果如表2所示。

表2 影响因子参数提取结果
3.1 深度信念网络
Hinton 等[15]于2006 年提出DBN 模型。DBN 由堆叠的RBM 构建的具有多个隐含层的概率模型(结构如图2 所示),并以分层的方式进行训练,前一个RBM 的隐含层将作为下一个RBM 的输入层,在训练过程中每个隐含层都可以获得比上一层更高级的数据特征,也就是说,底层特征向量映射到高层特征空间,原始数据可以被尽可能多地保留。

图2 DBN结构图
受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)是一种经过变体的玻尔兹曼机,基于能量的定义输入分布的建模方法,是二值分布的神经网络。受限玻尔兹曼机与标准玻尔兹曼机的主要区别在于玻尔兹曼机中同一层节点之间相互独立,它们之间没有任何的连接,其结构如图3所示。

图3 受限玻尔兹曼机结构图
可以直观地看出无论可视层还是隐藏层,只有层与层之间的连接,而同层之间是相互独立的。RBM的能量公式可定义为
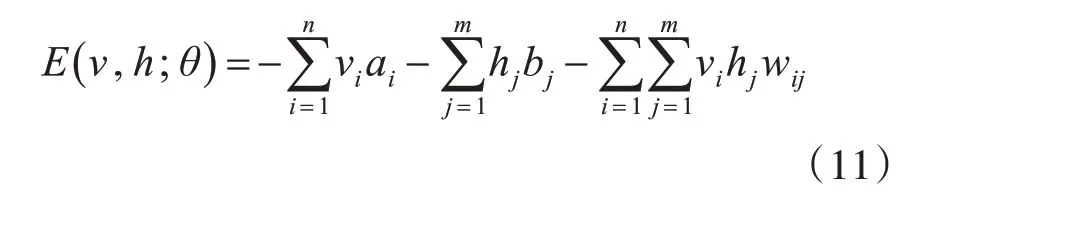
其中,θ={w,a,b}表示RBM的模型参数,v 代表输入向量,h 代表隐藏单元,wij则表示输入节点i 到隐含层节点j 之间的权值,a 和b 分别表示网络输入层和隐含层的偏置。在受限玻尔兹曼机中,输入层节点与隐含层节点之间的联合概率分布的计算公式为
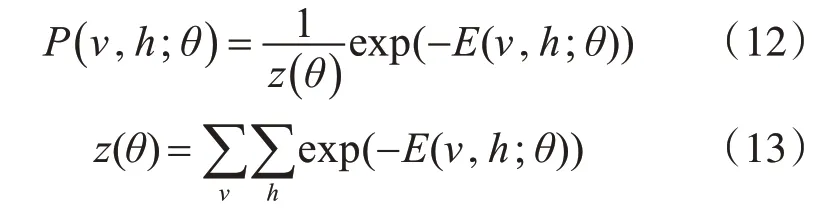
其中,z(θ)是归一化函数(也称配分函数),使得联合概率P 在(0,1)范围内分布。但是在实际计算中,我们更关心的是联合概率分布P(v,h;θ)的边缘分布P(v;θ),即观测变量的分布。
受限玻尔兹曼机的特点是层内神经元无连接,若输入层节点或隐藏节点的其中一层的状态给定时,另外一层的节点之间相互独立,则有以下表达式:

其中式(14)表示第j 个隐含层神经元的激活概率,式(15)表示i 个输入神经元的激活概率,sigmoid(x)= 1/(1+exp(-x))表示激活函数。
在RBM 训练过程中,目的是为了学习出θ={w,a,b}的值。在本文中,采用Hinton[16]在2002年提出的对比散度(CD)算法来更新各个参数。
3.2 改进的DBN
由于导数消亡问题会导致深度网络没有全部体现在深度网络上特征提取学习的优势[17~18]。在反向传播网络误差的过程中误差信息会逐步减弱,导致在底层的网络不能根据返回的误差来进行充分学习,从而使得深度网络容易陷入局部最小值。根据基础DBN 的模型结构,在本文中将提出一种多层有监督训练与学习微调的DBN 模型,结构如图4所示。
多层有监督训练与学习微调的DBN 算法思想:在每一层RBM 网络进行训练提取特征参数后,同时把分类结果输出,最后在微调阶段利用BP 算法,结合每一个RBM 的输出分类的误差,逐层逆向传播误差回到输入层,优化DBN 参数。修改后DBN的RBM训练算法流程如下所示。
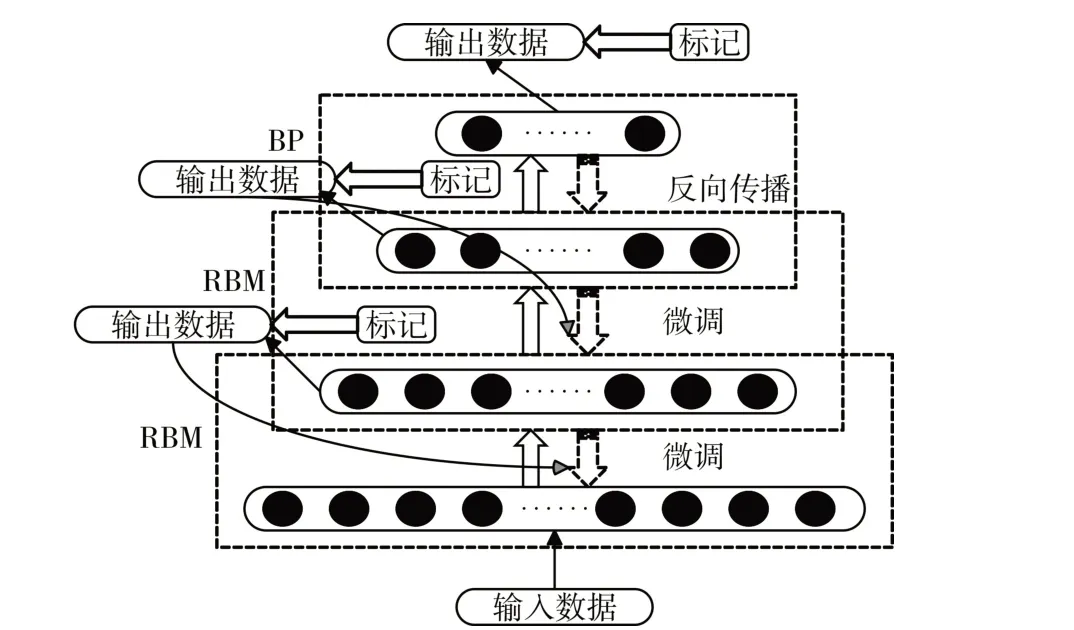
图4 改进DBN结构图
RBM训练步骤
输入:训练样本X;隐含层单元个数m,学习率ε;最大训练周期。
输出:连接权重矩阵W,输入层的偏置a,隐含层的偏置b,当前RBM的分类输出Y。
训练阶段:

3.3 分类模型评估
根据驾驶安全性行为的常有分类,即严重危险驾驶、危险驾驶、平稳驾驶和谨慎驾驶,在本文的实验数据设置中,总共选取四类数据,每一类随机选取4000 个训练样本,并随机选取8000 个样本作为测试数据。
3.3.1 评价指标
在本文中,将会引入准确率(Accuracy,记为P)来对模型的分类结果进行评价。准确率是对分类质量的评价,等于每一类正确分类的样本数量除以总样本数量,即:
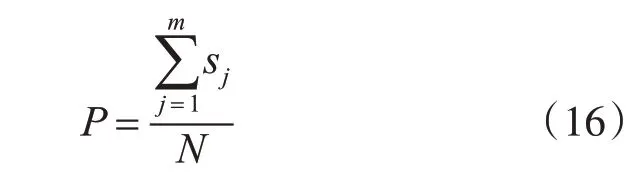
其中,m 表示总类别数量,sj表示每一类正确分类的样本数,N 表示测试样本总数。
3.3.2 驾驶行为分析模型构建
对于本文中的分类模型,首选速度均值、速度标准差、超速次数、负加速度均值、负加速度标准差、急减速次数、正加速度均值、正加速度标准差、急加速次数和疲劳驾驶次数等10 个驾驶行为影响因子作为模型输入,将严重危险驾驶、危险驾驶、平稳驾驶和谨慎驾驶作为模型的输出。为了使模型的分类性能更好,在模型建立之前首先对其模型深度、隐含层神经元个数和训练周期进行简要讨论。
1)深度对模型的影响
Le Roux、吕启等[19~20]表明RBM 的层数会影响DBN 的建模能力,使DBN 具有更高的分类和预测性能。同时,吕启等表明当DBN 的层数过多时反而会因为过拟合而降低模型的性能[20]。因此,我们应该根据具体的数据集来选取合适的层数。
根据上述说明,本文中首先需要确定模型的层数。实验过程中,首先固定训练样本数量为16000,DBN 的层数从1变化到6(不含BP 层),实验结果如图5所示。由图5可知,在本实验中,当DBN层数为4时,模型准确率最高。

图5 DBN层数对分类准确率的影响
2)隐含层神经元个数对模型的影响
Larochelle 等提到神经元过多会出现过拟合问题,而过少可能会不足以提取与分类有关的信息[21]。在本实验中,根据前面已经得出结论,确定DBN 层数为4 时,模型性能较好。驾驶行为的影响因子作为模型的输入层,即第一层,因此我们需要确定隐含层的神经元个数。在实验过程中逐渐增加隐含层数量和其对应层的神经元数量,以确定模型的隐含层的神经元数量。实验结果如表3所示。

表3 第一隐含层神经元个数对分类准确率的影响
从表中可以看到当第一隐含层的神经元个数不同时,训练准确率也不一样,当神经元个数到达7 个时,再增加神经元没有太多的准确率变化。因此,将第一隐含层的神经元个数设为7,设置实验确定第二隐含层的神经元个数,结果如表4所示。
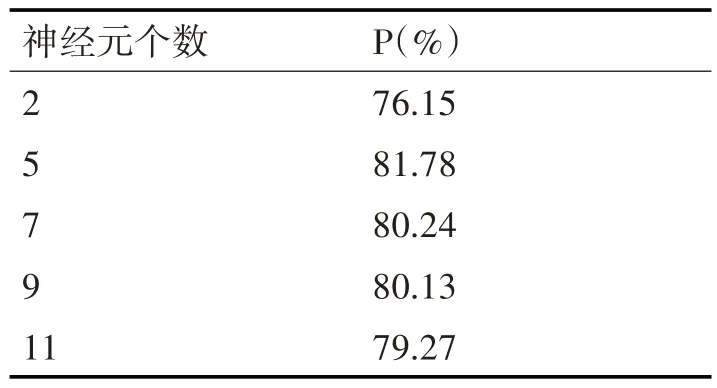
表4 第二隐含层神经元个数对分类准确率的影响
表中可以明显看到神经元个数为5 时,模型的分类准确率最高,神经元增加到11 时,分类准确率有下降。所以在第二隐含层中,我们选取神经元个数为5。基于此,再增加第三层隐含层来确定其神经元个数,实验结果如表5所示。
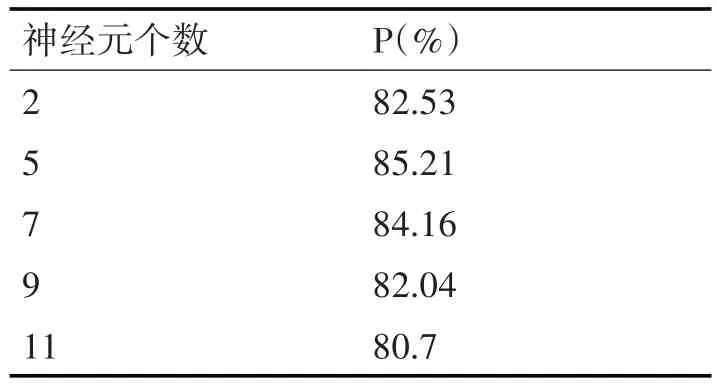
表5 第三隐含层神经元个数对分类准确率的影响
综上分析,我们选取DBN 模型的结构为10-7-5-5-4,输入层的神经元个数10,第一隐含层的神经元个数为7,第二隐含层的神经元个数为5,第三隐含层的神经元个数为5,输出层的神经元个数为4,则本实验构建的DBN网络结构如图6所示。
3.3.3 结果分析与比较
我们将基于改进的DBN 模型的分类结果与原DBN模型及BP网络等进行了实验对比。首先随机选取16000 个样本作为各个模型的训练样本,再从剩余样本中随机选取8000 个样本作为测试数据,检验不同模型的分类准确率。这三种模型的对比实验结果如表6所示。

图6 驾驶行为分类DBN模型

表6 不同分类方法结果比较
从表中可以看出经过深度网络训练后,再用BP 神经网络算法对其分类比直接使用BP 神经网络算法进行分类的准确率提高了。本文提出的多层有监督训练与学习微调的DBN 比基础DBN 的分类准确率提高,其准确率为86.22%,说明此方法能够消除导数消亡问题。
4 结语
本文通过对采集到的GPS 数据进行预处理和分析后,建立了基于改进DBN 的驾驶行为分类模型。实验过程中与基础DBN 和BP 模型进行实验对比。实验结果表明BP 和DBN 模型都能够根据数据学习并抽取特征,其很强的学习能力都可用于分类预测模型,相对于BP网络,DBN具有更强的特征学习能力;多层有监督训练与学习微调的DBN模型能够有效解决由于DBN 受导数消亡影响分类性能的问题。
