一种新的模型平均法:基于贝叶斯模型概率分析
2020-10-10袁杰徐鹏张少龙
袁杰 徐鹏 张少龙

摘 要:本文提出了一种新的模型平均法,其权重的计算方式是将传统方法的权重与贝叶斯方法的模型概率相结合。先用模拟数据验证了该方法的有效性,再用Fama-French三因子的数据进行实证,结果显示该模型平均法可进一步提升模型的预测精度。
关键词:模型平均法 貝叶斯 预测精度
中图分类号:F270.7 文献标识码:A 文章编号:2096-0298(2020)09(b)--04
模型平均法因其具有良好的预测性质一直受到广泛关注,被应用于计量经济学、社会科学和金融等诸多领域。虽然单一的模型在很多情况下可以解决问题,但这要求模型建立足够准确,否则就会丢失大量有用信息,导致预测误差较大。当模型的自变量很多且并不存在线性相关时,单一的全模型会包括很多自变量子集构成的模型,模型平均法恰好可以将这些模型包含的信息充分利用,有效地提升预测精度。
模型平均法的核心是如何计算加权的权重,权重的分配合理与否,直接影响预测的精度。所以如何提高权重的准确度一直都是讨论的热点。本文的创新点正是在传统的权重计算方法上结合了贝叶斯方法的模型概率,进一步提升了权重的合理性,最终分别通过模拟数据和真实数据证实了预测精度的提高。
本文结构安排如下: 第1部分是文献综述;第2部分是新模型平均法原理说明;第3部分是模拟分析,第4部分是实证分析,最后是结语。
1 文献综述
Hansen(2007)提出了Mallows 模型平均法 (MMA),该方法与之前的方法类似,仍需要对模型的标准误进行初步估计,再计算加权权重,虽然一定程度上提升了预测精度,但不适用异方差和小样本情形。Hansen and Racine (2012) 提出了jackknife模型平均法(JMA),该方法无需估计模型标准误,同时又适用于异方差情形。但在同方差或小样本情形下,该方法表现劣于MMA。Zhang et al.(2015)基于Kullback–Leibler距离,提出了一种修正的MMA方法(KLMA)。该方法在小样本和异方差情形下表现优于MMA。Xie, T.(2015)提出了一种不依赖于模型的标准误的模型平均法(PMA),该方法的表现优于前面三种方法。
Francisco Barillas and Jay Shanken(2018)提出了一种基于标准F-统计量计算的封闭式的贝叶斯资产定价检验。该检验利用贝叶斯概率的思想,通过计算给定自变量子集的所有可能模型集合的模型概率,比较模型的定价能力。
本文受到Francisco Barillas and Jay Shanken(2018)计算模型贝叶斯概率的启发,将模型的贝叶斯概率与以往的模型平均法结合,提出了一种新的计算加权权重的方法。
2 新模型平均法原理说明
是一个随机样本,且。假设数据产生的过程是,其中,且。y、、u可为的矩阵。对于一个线性近似模型序列,有个回归方程,例如在模型中,其中是一个的系数。令,则模型的的最小二成估计为。
令为各模型的权重,且。用模型平均法估计的为
以往的权重计算方式通常为定义一个以为参数的目标函数,令目标函数取最小值时的即为模型平均法的加权权重。PMA,MMA,JMA,KLMA四种方法分别对应的目标函数如下:
(1)
其中表示有效参数。
(2)
其中为包含全部自变量模型的标准误。
(3)
其中,,是最小二乘法的残差,是的对角矩阵且其对角元素为,是矩阵的第个对角元素。
(4)
其中为全部自变量模型的标准误,是其参数个数。
模型的预测值即为,其中为与做回归分析得到的系数。
Francisco Barillas and Jay Shanken(2019)通过计算给定自变量子集的所有可能模型集合的模型概率,比较模型的定价能力,计算公式如下:
(5)
其中是基于数据的模型贝叶斯概率,用于衡量超额收益,即模型截距项是否等于0。根据有效市场理论,该概率越大表示模型资产定价能力越强。是基于贝叶斯原理计算的各模型的边际概率,作为后验概率,为各模型的先验概率。
基于以上所述,从本质上来说也可以作为一种模型平均法的加权权重,即定价能力越强的模型赋予越大的权重。后验概率可以根据数据计算,但先验概率该如何设置才合理?前人的做法通常为等权重设置,或根据理论知识主观判定,这显然存在扩大误差的风险。
George (1997)等也提出了用扩散单位信息先验分布作为一种基准先验概率分布。本文针对这一问题,提出了新的观点,用PMA,MMA,JMA,KLMA四种模型平均法的加权权重作为先验概率带入式(5),将得到的新模型贝叶斯概率作为模型平均法(以下简称为CBMA)的新加权权重。
3 模拟分析
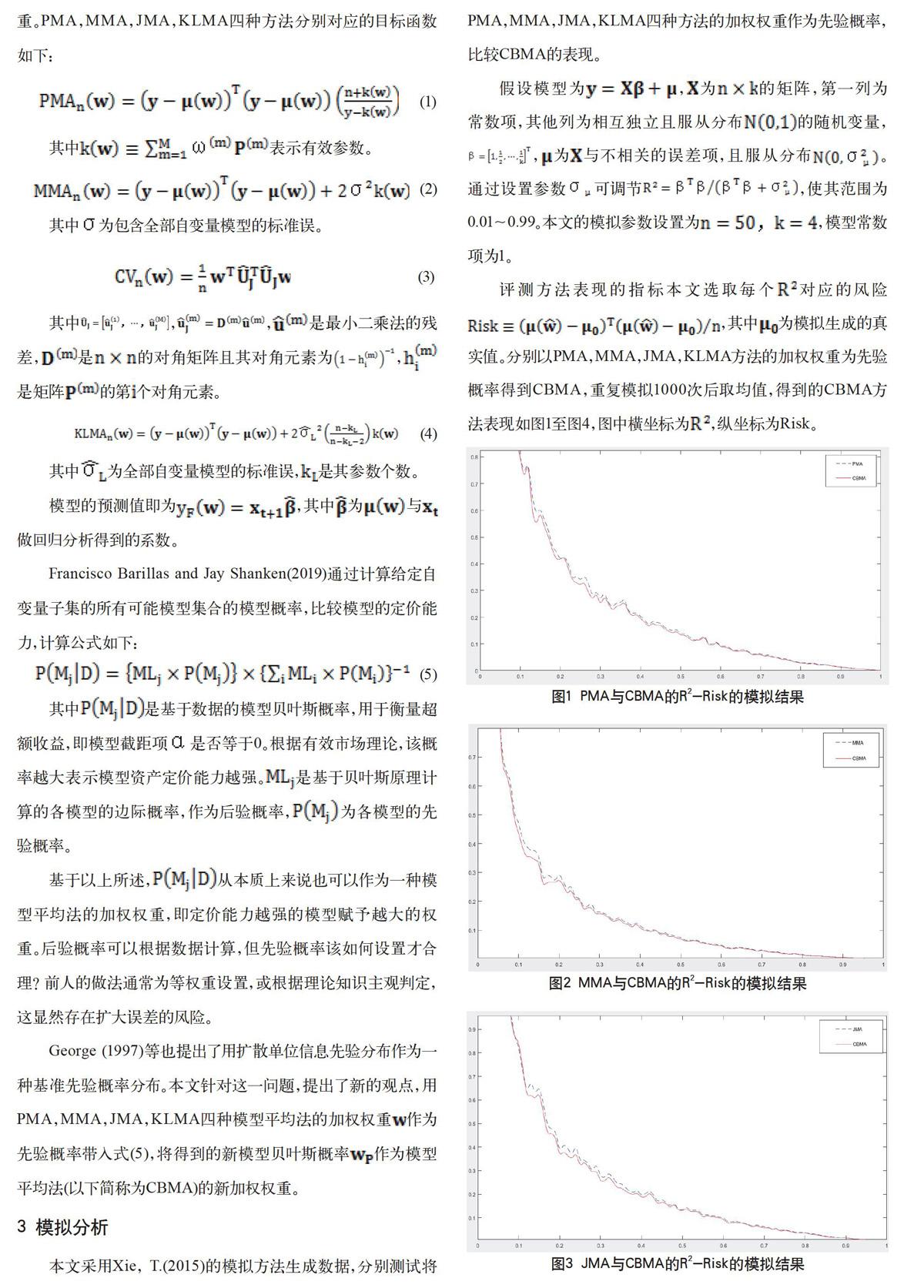
本文采用Xie, T.(2015)的模拟方法生成数据,分别测试将PMA,MMA,JMA,KLMA四种方法的加权权重作为先验概率,比较CBMA的表现。
假设模型为,为的矩阵,第一列为常数项,其他列为相互独立且服从分布的随机变量,,为与不相关的误差项,且服从分布。通过设置参数可调节,使其范围为0.01~0.99。本文的模拟参数设置为,模型常数项为1。
评测方法表现的指标本文选取每个对应的风险,其中为模拟生成的真实值。分别以PMA,MMA,JMA,KLMA方法的加权权重为先验概率得到CBMA,重复模拟1000次后取均值,得到的CBMA方法表现如图1至图4,图中横坐标为,纵坐标为Risk。
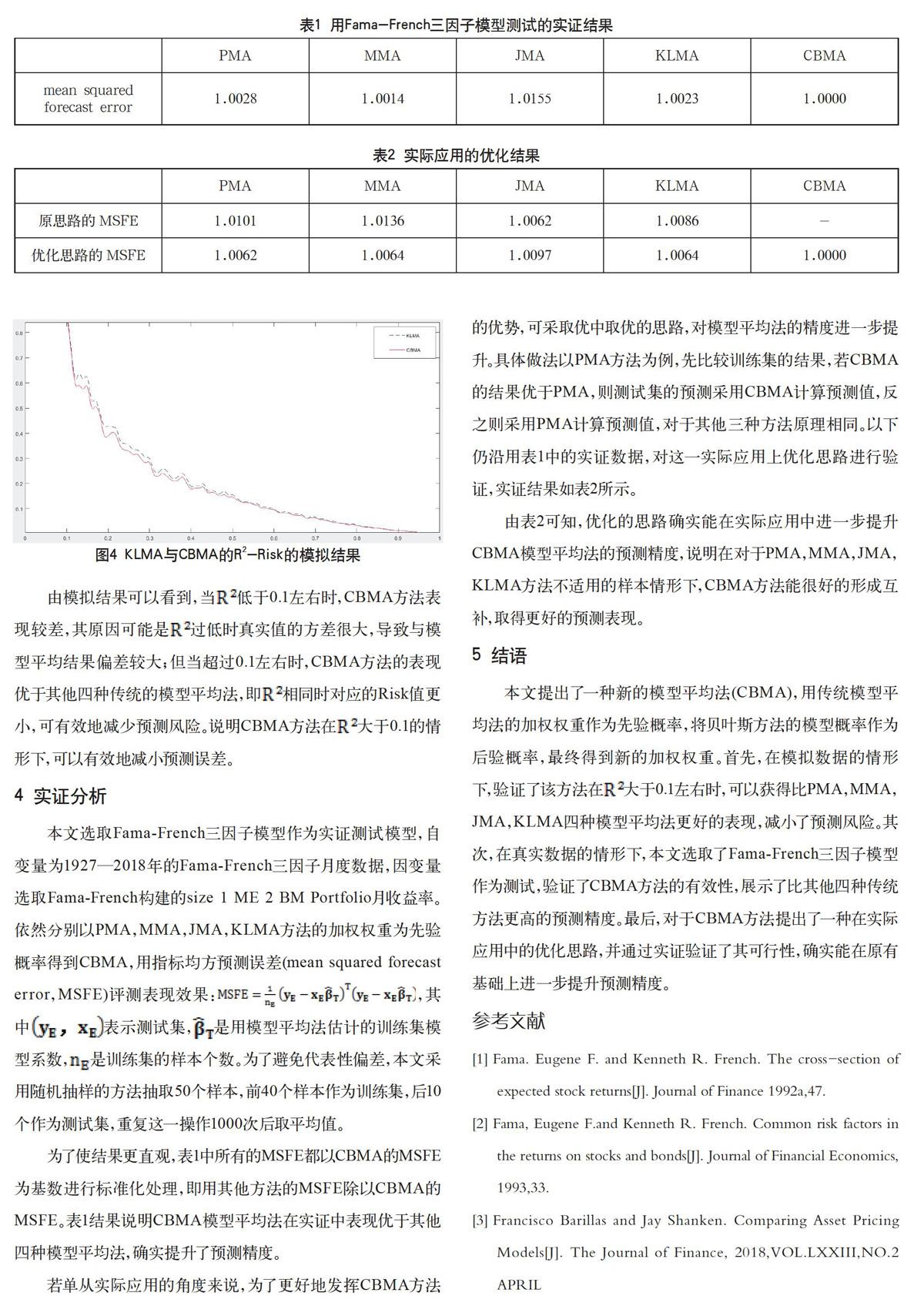
由模拟结果可以看到,当低于0.1左右时,CBMA方法表现较差,其原因可能是过低时真实值的方差很大,导致与模型平均结果偏差较大;但当超过0.1左右时,CBMA方法的表现优于其他四种传统的模型平均法,即相同时对应的Risk值更小,可有效地减少预测风险。说明CBMA方法在大于0.1的情形下,可以有效地减小预测误差。
4 实证分析
本文选取Fama-French三因子模型作为实证测试模型,自变量为1927—2018年的Fama-French三因子月度数据,因变量选取Fama-French构建的size 1 ME 2 BM Portfolio月收益率。依然分別以PMA,MMA,JMA,KLMA方法的加权权重为先验概率得到CBMA,用指标均方预测误差(mean squared forecast error,MSFE)评测表现效果:,其中表示测试集,是用模型平均法估计的训练集模型系数,是训练集的样本个数。为了避免代表性偏差,本文采用随机抽样的方法抽取50个样本,前40个样本作为训练集,后10个作为测试集,重复这一操作1000次后取平均值。
为了使结果更直观,表1中所有的MSFE都以CBMA的MSFE为基数进行标准化处理,即用其他方法的MSFE除以CBMA的MSFE。表1结果说明CBMA模型平均法在实证中表现优于其他四种模型平均法,确实提升了预测精度。
若单从实际应用的角度来说,为了更好地发挥CBMA方法的优势,可采取优中取优的思路,对模型平均法的精度进一步提升。具体做法以PMA方法为例,先比较训练集的结果,若CBMA的结果优于PMA,则测试集的预测采用CBMA计算预测值,反之则采用PMA计算预测值,对于其他三种方法原理相同。以下仍沿用表1中的实证数据,对这一实际应用上优化思路进行验证,实证结果如表2所示。
由表2可知,优化的思路确实能在实际应用中进一步提升CBMA模型平均法的预测精度,说明在对于PMA,MMA,JMA,KLMA方法不适用的样本情形下,CBMA方法能很好的形成互补,取得更好的预测表现。
5 结语
本文提出了一种新的模型平均法(CBMA),用传统模型平均法的加权权重作为先验概率,将贝叶斯方法的模型概率作为后验概率,最终得到新的加权权重。首先,在模拟数据的情形下,验证了该方法在大于0.1左右时,可以获得比PMA,MMA,JMA,KLMA四种模型平均法更好的表现,减小了预测风险。其次,在真实数据的情形下,本文选取了Fama-French三因子模型作为测试,验证了CBMA方法的有效性,展示了比其他四种传统方法更高的预测精度。最后,对于CBMA方法提出了一种在实际应用中的优化思路,并通过实证验证了其可行性,确实能在原有基础上进一步提升预测精度。
参考文献
Fama. Eugene F. and Kenneth R. French. The cross-section of expected stock returns[J]. Journal of Finance 1992a,47.
Fama, Eugene F.and Kenneth R. French. Common risk factors in the returns on stocks and bonds[J]. Journal of Financial Economics, 1993,33.
Francisco Barillas and Jay Shanken. Comparing Asset Pricing Models[J]. The Journal of Finance, 2018,VOL.LXXIII,NO.2 APRIL
George E I,McCulloch R E.Approaches for Bayesian variable selection[J].Statistica Sinica, 1997(2).
Hansen, B.E. Least squares model averaging[J]. Econometrica, 2017,75(4).
Hansen, B.E., Racine, J.S. Jackknife model averaging[J]. Econometrics, 2012,167(1).
Xie, T. Prediction model averaging estimator[J]. Economics Letters, 2015,131.
Zhang, X., Zou, G., Carroll, R.J. Model averaging based on Kullback–Leibler distance[J]. Statistica Sinica, 2015,25.
