面向“挑战性课程”的多目标跟踪实验设计
2020-10-09刘歆浏刘议聪
陈 娟,杨 倩,文 泉,刘歆浏,刘议聪
(1. 电子科技大学 计算机科学与工程学院,四川 成都 611731;2. 西南自动化研究所,四川 绵阳 621000)
“挑战性课程”的核心思想是:教师以全球的前沿科研问题作为切入点,并集成相关基础学科的核心知识体系,设计兼具“调整性”和“趣味性”课程内容;在教学环节的设计上,着重激发学生的学习主动性和创造性,让学生在教学活动中通过挑战自我、互动协作、探索钻研,来获取知识、提示学习能力、增强学习的获得感。综合性的课程实验,是“挑战性课程”非常重要的教学资源。本文面向人工智能系列“挑战性课程”,开发和设计了“视频多目标跟踪”综合实验,引导学生使用性能领先的“神经网络”技术[1-3],来解决“视频多目标跟踪”的科研问题。
“视频多目标跟踪”[4-10]的核心任务:在视频序列中,预测多个运动目标在下一个时刻的坐标位置,维持每个跟踪目标的序号(即目标的标识符),记录每个运动目标的轨迹。在本实验中选择“行人跟踪”[11]作为研究问题,主要原因包括:第一,在现实生活中,行人是会发生剧烈形变的“非刚体”目标;第二,行人的多目标跟踪,在实时监控和安防等领域有着非常广泛的应用;第三,全世界知名高校和优秀科研机构,提供了丰富的“行人跟踪”的视频数据集。
本文在国际权威期刊提供的公开数据集[12]上,对比和实现了“视频多目标跟踪系统”的综合实验设计。
1 多目标跟踪的实验原理
通过实现性能领先的神经网络技术,来设计“多目标跟踪系统”的综合实验[12],包括使用递归神经网络[13],计算视频目标在下一帧中的坐标位置和运行长短期记忆模型[14],来完成不同视频目标之间的数据关联。
1.1 实验参数的定义
M是整个视频中所有目标的个数,N是视频的某一帧中所有目标的个数。D是目标的坐标维度,在本实验中D=4 。具体地,本文使用目标中心点的横坐标x和纵坐标y,以及目标包围框的长h和宽w,来表示目标的信息。t表示视频帧的序号。
其中,表示编号对应概率关系的矩阵A 的每个元素的取值在0 和1 之间;表示目标出现概率的向量ε的每个元素的取值在0 和1 之间。
1.2 基于递归神经网络的多目标跟踪
1.2.1 递归神经网络的输入和输出
递归神经网络的“输出”参数包括:①当前帧中目标的预测位置;②当前帧中目标的更新位置(用于递归神经网络的下一次迭代计算);③当前帧对应的网络隐藏层节点ht+1;④当前帧中目标出现的概率;⑤前一帧和当前帧中,同一个目标出现概率的绝对值差分。
1.2.2 递归神经网络的优化
递归神经网络的损失函数,定义为:
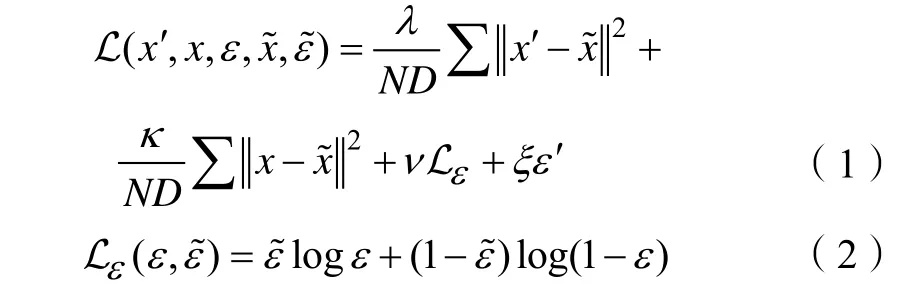
1.3 基于长短期记忆模型的数据关联
1.3.1 长短期记忆模型的输入和输出
长短期记忆模型的“输入”参数包括:①前一次迭代的记忆单元ci;②前一次迭代的隐藏层节点hi;③第t+1 帧中不同目标之间的位置距离Ct+1。
长短期记忆模型的“输出”参数包括:①后一次迭代的记忆单元②后一次迭代的隐藏层节点③第t+ 1帧中出现的目标的序号
其中,不同目标之间的位置距离定义为:
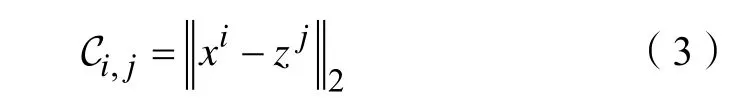
1.3.2 长短期记忆模型的优化
长短期记忆模型的损失函数,定义为:
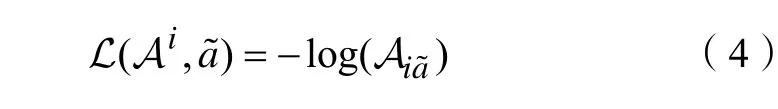
2 多目标跟踪的实验设计
2.1 视频目标跟踪平台的搭建
本文选择轻量级的Lua 脚本语言和科学计算平台Torch 作为“视频多目标跟踪”系统的编程环境。本文实验的硬件条件包括:GPU 的型号为GTX965M,显存为2 G,内存为8 G。
在本实验中,递归神经网络只包含1 层神经元,共300 个节点。长短期记忆模型包含2 层神经元,每层共500 个节点。
2.2 视频多目标跟踪的指标
本文选择了9 种公认的衡量视频多目标跟踪结果的指标[12],来评价实验平台在视频多目标跟踪方面的性能。这9 种指标的定义如下:
FP(↓):跟踪过程中,丢失的目标总数。
FN(↓):跟踪过程中,误报的目标总数。
MT(↑):目标的大部分被跟踪到的轨迹占比(>80%)。
ML(↓):目标的大部分跟丢的轨迹占比(<20%)。
FM(↓):真实轨迹被打断的次数。
IDS(↓):一条跟踪轨迹改变目标序号的次数。
MOTA(↑):结合目标丢失、目标误报、目标序号改变这3 个方面的综合准确性。
MOTP(↑):所有跟踪目标与标准包围框的平均边框重叠率。
FPS(↑):每秒能处理的视频帧的数目。
其中,(↑)表示指标的值越大目标跟踪的效果越好,而(↓)表示指标的值越小目标跟踪的效果越好。
2.3 多目标跟踪的视频数据集
本文使用了国际权威期刊提供的“行人跟踪”公开数据集,所有的视频序列都是在室外的街道上拍摄的,包含固定摄像机和移动摄像机2 种类型的视频序列。其中,移动摄像机佩戴在第三方的行人身上。而固定摄像机的视野位置分为2 种:与行人高度相当的位置和远高于行人高度的监控位置。
2.3.1 行人跟踪视频的数据规模
训练数据集由11 个视频组成,包含6 个固定摄像头的视频序列和5 个移动摄像头的视频序列。训练数据集共计5500 帧,包含550 条跟踪轨迹。
测试数据集由11 个视频组成,包含6 个固定摄像头的视频序列和5 个移动摄像头的视频序列。测试数据集共计5783 帧,包含721 条跟踪轨迹。
2.3.2 行人目标的密度
行人目标的密度定义为:整个视频的所有目标包围框的个数除以整个视频的总帧数。其中:(1)在训练数据集中,共计39 905 个目标包围框,行人目标出现的平均密度为7.3 个/帧;(2)在测试数据集中,共计61 440 个目标包围框,行人目标出现的平均密度为10.6 个/帧。
2.3.3 视频的光照条件和视野尺寸
视频数据集的光照条件:(1)在训练数据集中,晴天的视频序列占36%,阴天的视频序列占55%,夜间的视频序列占 9%;(2)在测试数据集中,晴天的视频序列占55%,阴天的视频序列占45%。
视频数据集的视野尺寸:(1)在训练数据集中,视野尺寸较大的视频序列占 9%,视野尺寸中等的视频序列占 82%,视野尺寸较小的视频序列占 9%;(2)在测试数据集中,视野尺寸较大的视频序列占18%,视野尺寸中等的视频序列占82%。
3 多目标跟踪的实验结果
本文使用性能领先的神经网络技术,实现了“多目标跟踪系统”的实验,在测试数据集上得到的视频多目标跟踪的平均结果总结在表1 中。根据实验结果的指标显示:在 FP 指标上,在“摄像机固定”的视频中丢失的目标总数更少;在 FN 指标上,在“摄像机固定”的视频中误报的目标总数更少;在MT 指标上,在“摄像机移动”的视频中大部分跟踪到的轨迹数目更多;在ML 指标上,在“摄像机固定”的视频中大部分跟丢的轨迹数目更少;在FM 指标上,在“摄像机移动”的视频中真实轨迹被打断的次数更少;在IDS 指标上,在“摄像机移动”的视频中跟踪轨迹改变目标序号的次数更少;在MOTA 指标上,在“摄像机固定”的视频中目标丢失、目标误报、目标序号改变这3 方面的综合准确性更高;在MOTP 指标上,在“摄像机移动”的视频中所有跟踪目标与标准包围框的平均边框重叠率更高;在FPS 指标上,在“摄像机固定”的视频中每秒能处理的视频帧的数目更多。

表1 行人视频数据集上的多目标跟踪结果
本实验对摄像机固定的视频序列和摄像机移动的视频序列完成行人多目标跟踪结果的样例,如图1 所示。在图1 中,使用不同颜色的方框来标定不同行人在视频中的位置。实验结果表明,在视频背景复杂、行人目标密集的情况下,本文设计的多目标跟踪系统,能够比较准确地定位视频中的多个行人目标。

图1 行人多目标跟踪结果举例
4 结语
本文在“行人跟踪”数据集上,使用性能领先的神经网络技术,实现了“视频多目标跟踪系统”的综合实验。通过实验结果的分析发现,基于递归神经网络和长短期记忆模型的“视频多目标跟踪”系统,能够有效地完成“行人”的多目标跟踪。
