面向AR 环境的典型场景快速重构方法∗
2020-10-09张俞鑫洵李蔚清
张俞鑫洵 李蔚清
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
场景重构主要包含了定位和场景中物体识别等方面,是计算机视觉研究的一个重要领域,其在自动驾驶、军事诊察等领域得到了广泛应用[1]。有时不需要对物体有精确的理解,要求能快速得到位置并识别出物体的种类。随着增强现实技术的发展,越来越多的增强现实设备进入到人们的生活,这些设备的很多应用都需要对场景有所了解。因此本文研究出了一种面向增强现实环境中典型场景的快速定位与物体识别的场景重构方法。该方法包含了定位和物体识别两大功能,并且提高了速度以能够实时完成增强现实设备中单目相机的场景重构。
在场景重构过程中,本文通过微软的混合现实设备Hololens 进行实时扫描,获得整个环境的布局和初步理解,利用环境的部分先验知识,可以得到环境的结构模型和物体的大致方位。在此基础上,通过显著性区域提取和物体识别来识别环境中的物体。
本文利用场景中的人工标志和PnP 算法快速得到相机的相对位姿。物体识别通常有基于特征、基于模型和基于知识等三类识别方法[2,7],本文所采用基于特征的物体识别方法。识别包括三个步骤:提取物体特征;根据训练数据建立物体识别模型;对待识别三维物体进行识别。由于室内物体一般都为人工物体,种类数量有限,且同类的人工物体往往拥有相似的结构、形状等。因此,本文提取物体的SURF 特征,使用词袋模型来描述特征,使用SVM 进行训练。这种方法在Hololens中运行时,拥有较快的识别速度,在物体种类不多的情况下很高的准确率。
本文的主要流程图如图1所示。
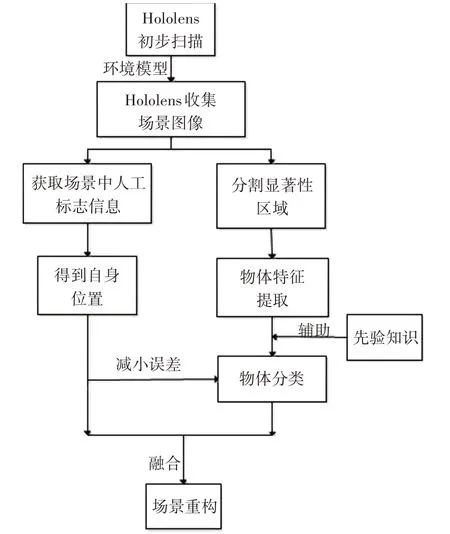
图1 面向AR环境的典型场景快速重构
2 Hololens 中基于人工标识的快速定位
Hololens 可以直接获取到的只有前方的单目摄像头。为了计算深度信息,将人工标志的提前将标志贴在场景中的部分位置,得到这些标志在世界坐标系中的相应位置[3~4,14],当扫描到标志时可以立即计算出位姿。当使用者在场景中行走时,设备捕获到这些标记就能立刻计算出自身在场景中的位置。
2.1 Hololens环境扫描
Hololens 在打开时会用多传感器结合对场景进行一次扫描,此时可以获得该场景的大致模型,后续再通过环境中张贴的人工标志进行粗定位。该方法可以很快得到环境模型和相机在模型中的位置,即便在Hololens 的资源受限情况下也能实时完成定位。
2.2 基于标志的位姿获取
Hololens 的视角较小,并且运算速度有限,如果执行定位时消耗过多资源会影响其他应用以及场景重构的效率。因此采用的标志要具有显著性、易识别、计算快等特点。本文采用ArUco 库进行编码的设计,ArUco 是一个开源的微型的现实增强库,还经常用于实现一些机器视觉方面的应用。
对Hololens 采集到的图像进行处理后,随后进行轮廓提取,对得到的轮廓进行多边形逼近,去除不是四边形的轮廓。通过判断外圈是否为均匀的黑色边界,得出该区域是否为提前设置的人工标记。最后,对人工标志进行解码获取该标志的ID,得到该人工标志四个端点的三维世界坐标。
得到了标志四个端点在像素坐标系中的位置后,可以计算得到相机相对于标志的位置。本文采用N 点透视算法(PnP)来计算相机的实时位姿。PnP 问题是指在己知相机内参的情况下,通过n 个图像像素点与实际空间点的对应关系来求解相机旋转矩阵R 与平移向量t,从而求得相机位姿。PnP问题一直被视为计算机视觉领域的经典问题,在自动驾驶、视觉定位等方面均有重要应用[10]。
通过标志的四点与它们的世界坐标和PnP 计算出相机相对于标志的位姿后,再通过计算可以直接得到相机在世界坐标系中的坐标。
2.3 快速定位实验结果及分析
定位系统的测试方法是操作人员佩戴Hololens 在场景中行走,计算位姿后转换到世界坐标系中并发送至后台电脑。为了方便观察与检测,本文在后台另外设置一台电脑进行误差检测与时延计算。
实验场景分为狭隘的走廊空间和宽阔的大厅空间。走廊长为10m,宽为1.5m,张贴三张标志。大厅长为10m,宽为8m,贴4 张标志。通过开关灯来控制室内亮度。合格判据如下:
1)在光照良好、场景宽阔情况下,若能在3m距离内,垂直于标记60°以内,计算能在1.5s 内完成,则认为合格。
2)在光照不足、场景宽阔情况下,若能在2m距离内,垂直于标记60°以内,计算能在1.5s 内完成,则认为合格。
3)在光照良好、场景狭窄的情况下,若能在3米距离内,垂直于标记45°以内,计算能在1.5s内完成,则认为合格。
4)在光照较差、场景狭窄情况下,若能在2m距离内,垂直于标记45°以内,计算能在1.5s 内完成,则认为合格。
不同场景下,控制实验条件,每组实验次数为50,实验数据如表1和表2所示。
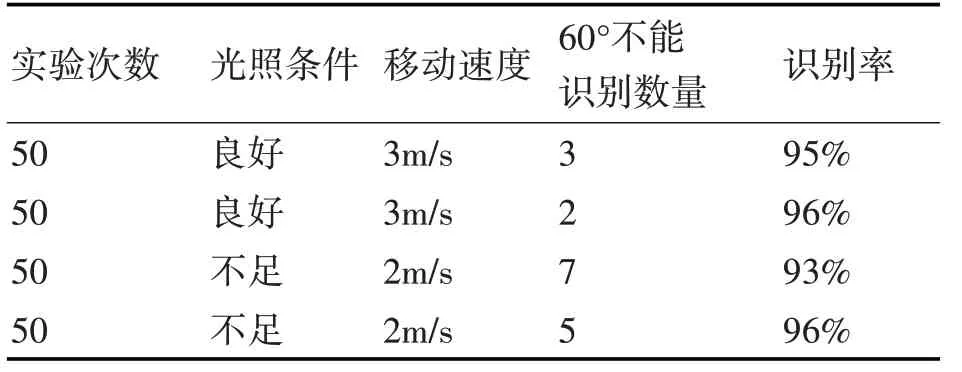
表1 控制光照条件的定位测试
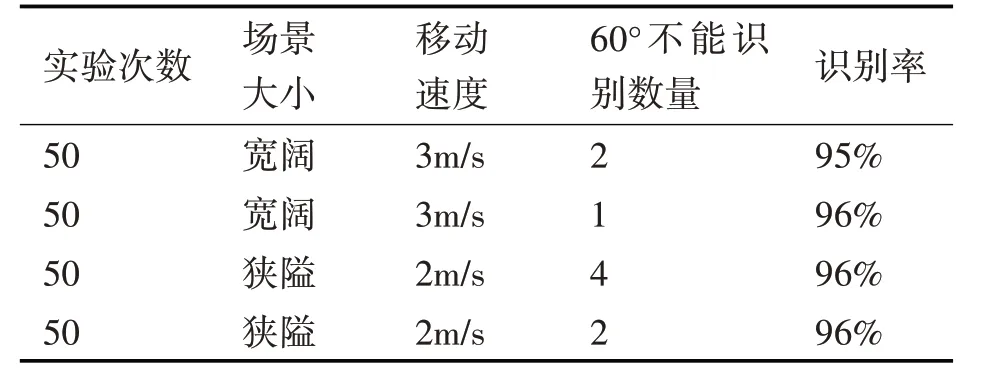
表2 不同场景下的定位测试
通过实验可以发现,该方法拥有很强的光照容忍性并且在各场景中也表现良好。可以达到实时准确地计算位在后续增强现实系统中各个功能提供了良好基础。
3 显著物体的快速建模
本文采用FT 算法进行显著性区域检测,提取该区域中的特征建立BOW 模型,用SVM 分类器给出识别结果。
3.1 显著性区域提取
FT 算法是利用颜色和亮度特征来估计中央周边差对比度,叠加多个带通滤波器得到全分辨率显著 图[8,16]。图 像 中 某 个 像 素(x,y) 的 显 著 性 为S(x,y)。其表达式为
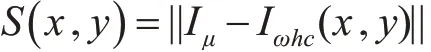
上式中,Iμ为图像特征平均值向量,Iωhc(x,y)为像素点(x,y)在高斯平滑后的对应的像素向量。其中‖ ‖代表为欧几里得距离。最后计算图像的SaliencyMap。在得到图像的SaliencyMap 后,提取其中较亮的区域作为显著性区域。
3.2 建立BOW模型
BOW 忽略文本的语法和语序等要素,仅仅看作是若干个词汇的集合。基于BOW 的物体识别方法的是将每幅图像描述为局部关键点特征的无序集合,对关键点特征进行聚类,形成视觉词典,建立图像的BOW 表达。将所有特征词投影到视觉词典中,根据每个特征词出现的数目把图像描述成特征向量[9,11~12]。物体识别过程如图3所示。
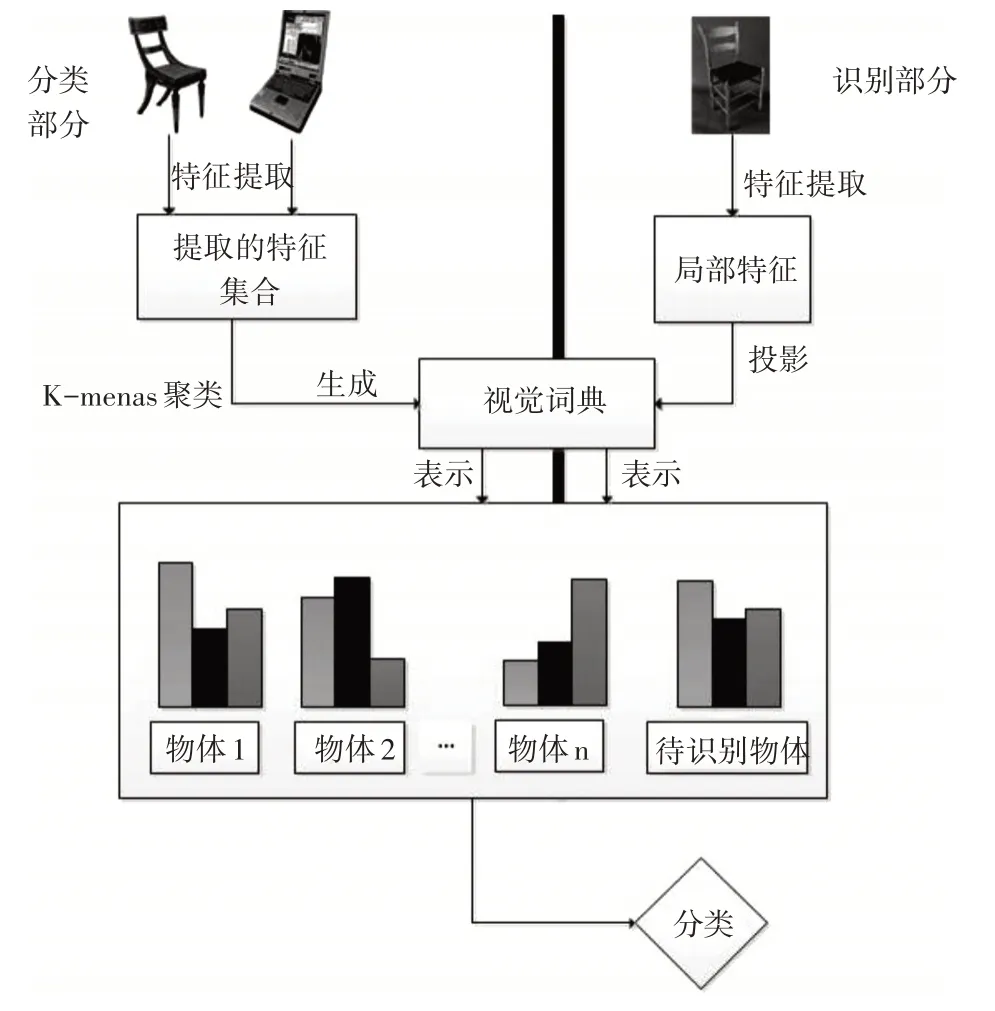
图2 基于BOW的物体识别流程
3.2.1 构建词典
设置N张训练图片,提取图像SURF特征,最终将得到T 个特征点,用这些特征点构建词典。构建词典过程需要使用聚类算法,本文选用K均值聚类方法,通过迭代算法算出最终的n 个聚类中心,用这些聚类中心构建词典,即直方图的基[13]。之后每产生一个新的特征点,都映射到n 个聚类中心中的一个,使之数量加1。不同类别拥有不同的特征直方图,用得到的直方图来表示这幅图像。对所有图像计算完成之后,就可以进行分类聚类训练预测[17]。图3为不同物体的特征直方图。
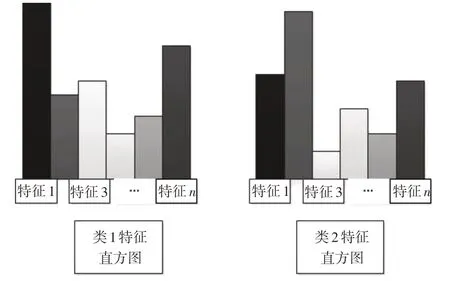
图3 生成的物体特征直方图
3.2.2 训练分类模型
本文使用的分类器为SVM,使用的核为直方图正交核[2]。两个直方图的交集函数如下:
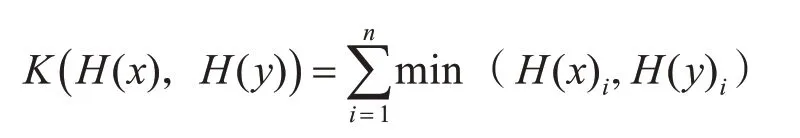
其中x,y为两个直方图,H(x)i为为x直方图中的第i 个bin,n 为直方图bin 的个数。两个直方图每个bin 的重叠数为两个bin 的最小值,所有bin 的重叠数之和,为该层次的交集函数值。随后可以计算两个层级的交集函数之差N(i),通过N(i)计算两个直方图的相似性函数。
该核是一种基于隐式对应关系的内核函数,解决了无序、可变长度的矢量集合的判别分类的问题。其基本思想是将特征集映射到多分辨率超平面中,然后对这些超面进行比较[15]。在本文的应用中,该核函数常用的RB等核函数相比,有用更高的性能。
3.3 物体识别实验
本文将快速室内定位和物体识别进行结合,实现Hololens 上的快速场景重构。程序在Unity3D 开发。本文中训练集采用caltech101中的部分室内常见物体。拥有室内的部分先验知识后,可以了解物体的大致分布。物体分别的先验知识如图4 所示。这种方法可以加快物体识别的速度,也为提高正确率提供了一定的保障。得到物体种类后,在该物体区域的最大外接矩形中心处显示物体的种类与名字。
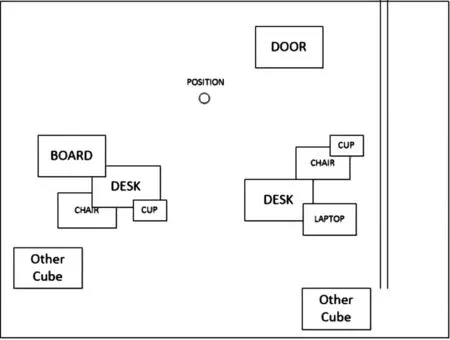
图4 先验知识的物体分别
图5 为Hololens 中对显著性区域内物体的识别。

图5 Hololens中物体识别
实验场景为分别复杂室内场景和简洁室内场景。复杂场景中包含了大量的不同种类的室内物体,并且有叠加、遮挡重叠等多种情况。在简洁场景中只包含了少量的室内物体并且具有较少的重叠。通过开关灯来控制室内的光照。在不同的场景中,测试是否能正确识别该物体。本文的测试图像为处理过的视频流,共计图像1983 帧,其中每帧都有提前设计好的包含一个物体的显著性区域。
表3 和表4 为在不同的实验场景中,部分物体的平均识别率和平均计算时间。
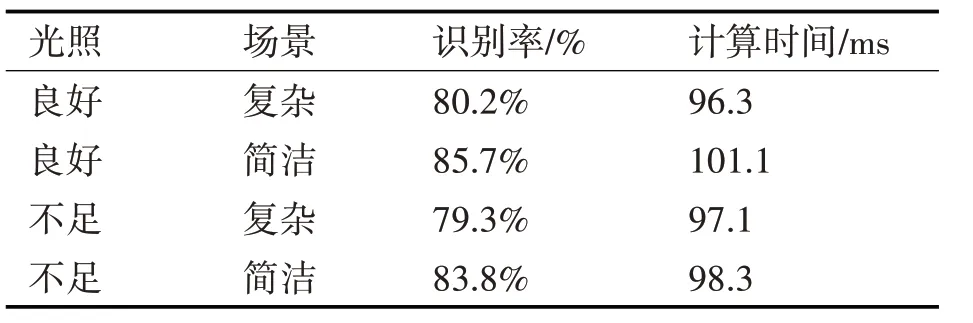
表3 室内显著性物体识别(CHAIR)
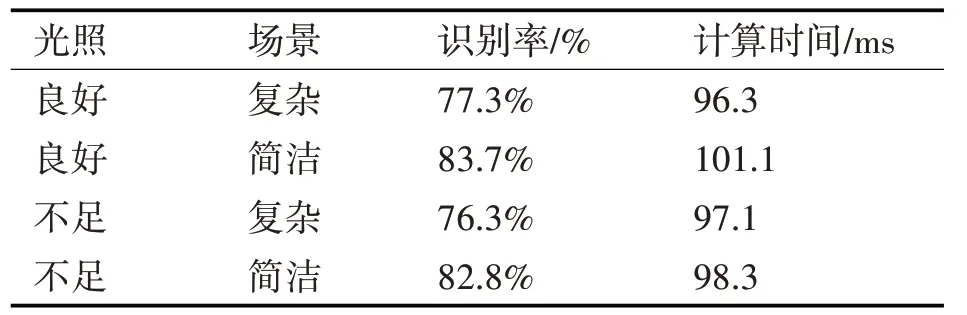
表4 室内显著性物体识别(LAPTOP)
本文的方法的计算速度较好,一秒钟可以处理的帧数在十帧以上,物体识别率对光照的变化有一定的容忍性。表5 为目前常见的词袋模型进行的多种物体平均识别准确率。
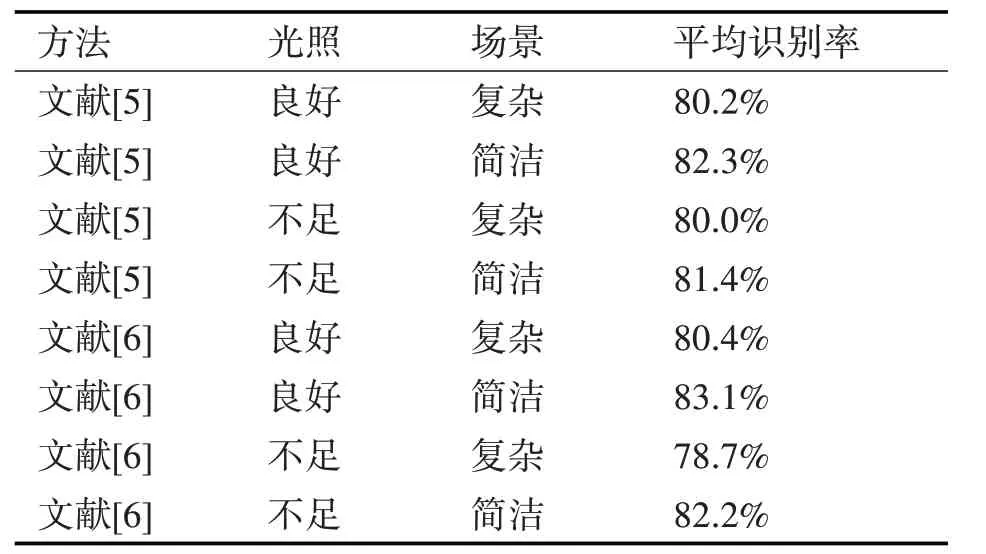
表5 常见的词袋模型物体平均识别率
本文的整体系统运行稳定,与其他方法具有相似的识别率,且具有较快的识别速度,保证每秒能处理十帧以上的图像。为增强现实设备的快速环境重构打下基础。
4 结语
将两者结合后整个系统的发挥稳定,能够保证在不高于3m/s 的移动速度运动时,可以实时得到位置,完成显著性物体进行识别工作。本文的整体系统在Hololens 运行稳定,可以进行快速粗定位和物体识别工作,成为在增强现实设备中进行视觉处理的前提。
本文的系统还有很多值得改进的地方,比如将人工标志改成在环境中的自然路标,提取物体的多种特征进行融合从而提高物体的识别率等。这些将会在接下来的实验中进行完善和改进。
