基于朴素贝叶斯和支持向量机的评论情感分析∗
2020-10-09葛霓琳凡甲甲
葛霓琳 凡甲甲
(江苏科技大学计算机学院 镇江 212003)
1 引言
随着社交网络和电子商务等的蓬勃发展,网络平台每日产生海量的个人言论和商品服务的评论,其中包含人们的各种情感倾向,如赞扬或是批评。这些大量的评论中含有用户的主观情感,其中蕴藏着丰富的现实意义和巨大的商业价值[1],而文本情感分析技术可以用来挖掘这些价值。文本情感分析是自然语言领域的一个重要研究方向,涉及语言学、统计学、心理学、人工智能等领域的理论和方法[2]。本文主要介绍现阶段情感分析的研究工作及其一般的处理流程,对文本分词算法和相关的机器学习方法进行概要的说明,进行情感分析的实验并对结果进行分析。
2 相关工作
情感分析,又称为意见挖掘,是指对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程[3]。从文本粒度的角度考虑,情感分析主要分为词语级、短语级、句子级、篇章级以及多篇章级等[4]。从文本类别的角度考虑,主要包括基于新闻评论的情感分析和基于产品评论的情感分析[5]。
目前,较成熟的情感分析的研究方法主要是基于情感词典和基于机器学习方法。基于情感词典的方法需要依赖事先建立好的情感词典,中文的情感词典主要有中国知网的Hownet 情感词典、台湾大学的NTUSD 情感词典等。利用机器学习方法进行情感分析,实则是分类问题。一般地,机器学习方法主要分为无监督学习和有监督学习。监督学习中常用的方法主要是朴素贝叶斯(Naive Bayes,NB)[6]、支 持 向 量 机(Support Vector Machine,SVM)[7]、条 件 随 机 场(Condition Random Field,CRF)、最大熵(Maximum Entropy,ME)[8]等。
基于机器学习的文本情感分析起初是由Pang[9]等提出,采用支持向量机、朴素贝叶斯、最大熵三种方法对电影的评论进行分类,实验结果表明,支持向量机比另两种方法分类效果较好。Ni[10]等认为情感分析问题可以看作是两类情感的问题,利用朴素贝叶斯、支持向量机和Rocchio 算法以及信息增益进行特征选择。Ye[11]等将旅游博客中的评论文本作为数据集,分析朴素贝叶斯、支持向量机以及基于特征的N-gram 模型的分类效果。Li[12]等将文本分为个人情感以及非个人情感两种类别,利用半监督学习方法进行分类。
基于机器学习方法的情感分析的过程主要是:首先获取文本数据,由于评论数据的语料来源丰富,并且评论文本一般可视为主观性文本,所以评论语料库或是利用爬虫技术从网络上获取的评论数据是较常见的语料库资源。其次,对收集的文本数据进行预处理,如分词、去停用词等。接着,采用词向量的方法将文本转换为数字表示的向量,从而利用向量来表示一个文本数据。最后利用分类器对其进行情感分类,大致流程图如图1。

图1 基于机器学习的情感分析过程
3 相关技术
3.1 中文分词
分词是处理中文文本的基础[13]。分词方法主要包含三种方法:基于词典的分词方法、基于统计的分词方法以及基于语义的分词方法。
基于词典的分词方法是指将字符串和词典进行匹配,其中按照扫描方向的不同可分为正向匹配法和逆向匹配法;按照长度的不同可分为最大匹配法和最小匹配法。基于统计的分词方法是指在上下文中,相邻的字同时出现的次数越多则越有可能构成一个词,因此字与字相邻出现的概率能反映词的可信度。主要的统计模型有N 元统计模型(N-gram)、隐马尔可夫模型(Hidden Markov Model,HMM)。基于语义的分词方法是指通过模拟人对句子的理解,利用句法分析和语义分析来进行分词。
常见的分词工具主要是哈工大语言云(LTP-cloud)[14]、汉语词法分析系统(ICTCLAS),Jieba 分词等。其中,Jieba 分词是以模块的形式引用,简单方便,支持三种分词模式如精确模式、全模式以及搜索引擎模式。Jieba 的基本原理是基于前缀词典实现高效的词图扫描,生成句子中文字组成词的所有可能的情况,从而构成有向无环图(DAG),然后利用动态规划找出最大概率路径以及基于词频的最大切分组合。对于未登录的词(即其词典中未记录的词)则利用基于HMM模型及Viterbi算法。
3.2 文本表示
为保证对文本进行分类的准确性,需要将文本进行形式化表示。常用的文本表示方法主要有向量空间模型、主题模型、词向量模型等。词向量(Word embedding)是指利用向量将文字转换成计算机能够识别的一种方式。词向量的主要思想是通过词所在位置的上下文情况来表示词语。词向量生成模型(Word2vec)主要包含跳字模型(skip-gram)以及连续词袋模型(continuous bag of words,CBOW)。
利用词向量模型将文本数据表示成一个N 维向量,但一般向量的维度会比较高,从而导致模型过于复杂,此时需要采取特征降维的方法,如主成分分析(PCA)和线性判别分析(LDA)。
其中,主成分分析(PCA)是指通过一种线性的投影,将高维的向量映射至低维空间,并且保留尽可能多的向量差异信息,在新的向量空间里任意两个维度所包含的信息不重复。
3.3 文本分类
分类问题一般分为训练和分类两个过程,训练过程是指依据已知的训练数据集,利用合理的方法训练出一个分类模型;分类过程是指利用训练出的分类模型对新的测试数据集进行分类。分类问题分析过程如图2。

图2 分类问题分析过程
3.3.1 朴素贝叶斯
朴素贝叶斯分类器是机器学习中常见的分类器之一,是以贝叶斯定理以及特征条件相互独立为前提进行分类。朴素贝叶斯的基本原理是:训练期间,当特征条件相互独立时,通过计算得到先验概率、条件概率和联合概率分布[15]。预测期间,根据贝叶斯定理计算后验概率,接着以后验概率的大小为基准,输出测试数据的分类结果。朴素贝叶斯分类器的训练和分类过程大致如下:
1)对任意一个数据样本,n 维特征向量X(x1,x2,…,xn)表示n 个特征属性的特征向量。输出类别分别是C1,C2,…,Cm共计m个类别。
2)计算类先验概率:对于类别Ci(1≤i≤m),先验概率的公式如式(1)。

其中,Ni是指训练样本中属于类别Ci的样本数量,N 是指训练样本的总数。
3)计算条件概率:朴素贝叶斯算法是基于条件独立的基础,即
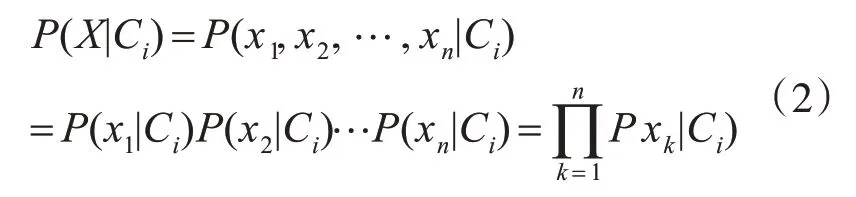
其中P(xi|Ci)(1≤i≤k,1≤i≤m)是由训练过的数据计算出的。条件概率计算公式为
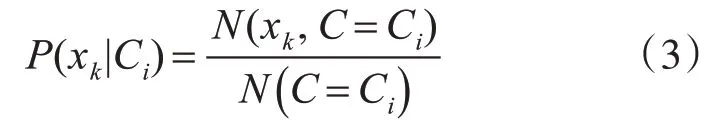
其中N(xk,C=Ci)表示样本中属于类别Ci并且具有特征xk的样本数目,N()C=Ci表示样本中属于类别Ci的样本数量。
4)计算后验概率:基于贝叶斯定理,可推出后验概率P(Ci|X)的计算公式为
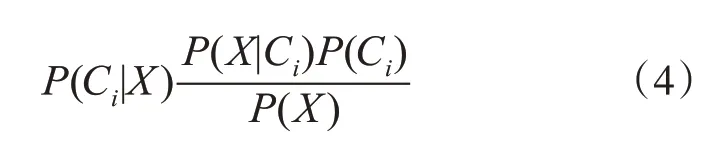
其中P(X|Ci) 是条件概率,P(Ci) 是类先验概率,P(X)是常数。
5)输出类别:比较得出的全部后验概率的大小,朴素贝叶斯分类器对未分类的样本进行分类,最终输出结果是类别Ci,当且仅当Ci满足条件:P(Ci|X)<P(Cj|X) 1≤i≤m,j≠i。
3.3.2 支持向量机
支持向量机是一种有监督的二分类模型,以结构风险化最小原则为基础。一般分为两种情况,一是基于线性可分的情况,寻找到能够将两种不同类别完全分开并且保证类别之间的间隔达到最大的超平面。另一种情况是基于非线性情况则需要引入核函数。
支持向量机的基本原理如下:
假 设 存 在 训 练 数 据 集A={(a1,b1),(a2,b2),…,(an,bn)},其中ai是指第i 个特征向量(1≤i≤n),ai∈Rn,bi是指向量属于的类别,bi∈{+1,-1},若bi为1则表示正向,若bi为-1则表示负向。
在两类不同样本的空间中存在多个超平面,划分超平面的线性方程[16]如式(5)所示:

其中,ω=(ω1,ω2,…,ωd)是法向量,表示超平面的方向;b 是位移项,表示超平面到原点之间的距离。从而得知法向量ω 和位移b 能确定一个超平面,可记为(ω,b)。样本空间中任意一点x 到超平面(ω,b)的距离可以表示为

若超平面(ω,b)能够正确地将训练集分类,则bi=-1,则有ωTxi+b<0。对于(ai,bi)∈A,若bi=+1,则有ωTxi+b>0;若
4 实验及结果分析
4.1 文本获取及预处理
本文选择整理收集的酒店评论语料作为训练集和测试集,该语料中包含四种语料子集,本文选取正面负面评论各2000 条,每一条评论存储为一个文本文档。为方便后面处理,将所有的正向评论整合到一个文本文档,所有的负向评论整合到一个文本文档。
接着,用Jieba 分词对正向及负向文本进行分词处理,并利用停用词词典去除一些无意义的词。所谓“停用词”是指在较多的文本数据中对分析情感倾向无影响的词语,如“啊”、“的”、“地”等。根据汇总的停用词,可以去除文本数据中的无用词,提高分类的准确率。所以此次选取中科院计算机所中文自然语言处理开发平台发布的中文停用词表,包含1208 个停用词。正向评论和负向评论处理部分结果分别如图3~4所示。

图3 负向评论处理结果

图4 正向评论处理结果
4.2 获取特征词向量
将相关评论经过文本预处理后,需要将文字转换成计算机能识别的格式,即将分词后的结果转换成对应的词向量。选用维基百科的中文语料作为训练的语料库进行词向量Word2vec 模型构建。然后基于已训练好的词向量模型进行特征词向量的抽取。
获取特征词向量的主要步骤如下:
1)读取模型词向量矩阵。
2)遍历语句中的每个词,从模型词向量矩阵中抽取当前词的数值向量,一条语句转换为一个二维矩阵,行数则是词的个数,列数是模型设定的维度。
3)根据得到的矩阵计算矩阵均值,作为当前语句的特征词向量。
4)全部语句计算完成后,拼接语句类别代表的值,写入csv文件中。
将前面处理好的文本转换成向量表示,第一列是类别对应的数值(1 代表pos 正向,0 代表neg 反向),第二列开始则是数值向量,每一行代表一条评论,部分结果如图5所示。
4.3 降维
由于在训练word2vec 模型时设定的向量维度是400,所以得到的词向量是400维,利用PCA算法对结果进行降维。由图6 可知,前100 维能够较好地包含原始数据大部分内容,从而选择前100 维作为模型的输入。

图5 词向量处理结果

图6 向量维度
4.4 分类模型及结果
本文分别利用朴素贝叶斯及支持向量机作为分类模型,通过计算测试数据集的预测精度和ROC曲线来验证分类器的有效性。在本次实验中选取80%的数据作为训练集,20%的数据作为测试集,然后利用两种分类器分别对测试集进行分类,其预测准确率如表1所示。

表1 两种分类器的准确率
一般地,ROC曲线的面积(AUC,反映分类器综合性能的指标)越大,则模型分类效果越好。如图7所示。

图7 朴素贝叶斯ROC曲线
从上面的图表中可以得出结论:针对同一测试数据集,支持向量机分类的效果较朴素贝叶斯分类的效果好。基于朴素贝叶斯的情感分析是通过计算概率对文本的情感进行分类,算法较为简单,在小规模数据方面有较好的分类效果。但对输入的数据的形式较敏感,并且需要计算先验概率,从而会在分类方面存在一定的错误率。

图8 支持向量机ROC曲线
5 结语
本文利用朴素贝叶斯和支持向量机两种不同的机器学习方法对同一语料集进行情感分析的效果对比,得出在酒店评论数据方面,支持向量机的分类效果优于朴素贝叶斯的分类效果的结论。但若针对不同领域的评论语料,分类器的效果会有所不同,具有一定的局限性。
基于情感词典和基于机器学习的方法都需要较高的人工成本,而深度学习是一种新兴的方法应用在情感分析方面,节省了一定的成本,同时也具有较好的效果。接下来的工作是利用深度学习的方法对用户评论文本进行情感分析。
