内容增强与时间匹配的兴趣点推荐方法
2020-09-29陈炯,张虎
陈 炯,张 虎
(1.山西职业技术学院 计算机工程系,山西 太原030006;2.山西大学 计算机与信息技术学院,山西 太原 030006;3.山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
0 引 言
兴趣点(point-of-interest,POI)推荐通过分析用户历史数据,挖掘用户偏好,为用户推荐可能感兴趣的新的地理位置。POI推荐不仅能够满足用户个性化需求,而且能够帮助商家提供智能化位置服务,实现精准营销,因此,近年来受到学术界和工业界的广泛关注[1]。
现实生活中用户安排某次行程、访问某个位置,往往会参考朋友介绍,并考虑个人喜好、路途远近、时间约束等因素,因此,用户在兴趣点的签到决策是一个复杂的过程,会受到社交关系、地理位置、个人兴趣、时间等多方面因素的影响。目前已有的兴趣点推荐方法大多通过收集并分析用户签到记录关联的社交关系、地理位置、评论内容、签到时间等信息,挖掘用户隐藏偏好,借助协同过滤等方法向用户推荐感兴趣的地理位置[2-7],但是现有方法存在以下不足,一是推荐模型仅仅集成了部分因素,缺乏对用户签到决策影响因素的全面分析;二是很少将评论文本与时间因素同时融入推荐框架,特别是评论文本的情感倾向挖掘以及时间因素的深度分析尚不充分。
针对现有方法存在的不足,本文在分析基于位置的社交网络(LBSN)中多源异构复杂信息的基础上,提出了内容增强与时间匹配的兴趣点推荐模型(GSRT),综合考虑了地理、社交、内容、时间等因素,集成了POI类别与流行度信息,使用自然语言处理技术挖掘评论文本的情感倾向,深度分析用户活动规律与POI流行度的时间匹配,并将情感倾向与时间匹配同时融入推荐模型中,以提高兴趣点推荐的性能。
1 相关研究
用户在兴趣点上的签到模式隐式反映了用户的个性化偏好,一些研究将POI看着传统推荐系统中的项目,借用经典协同推荐算法挖掘用户的签到历史记录进行兴趣点推荐。Ye等[2]使用基于用户的协同过滤框架来计算社交影响,获得用户对候选POI的社交相关分数进行兴趣点推荐。Zhang等[3]采用基于用户的协同过滤方法,聚合用户的社交关系,并对社交签到频率或评分进行分布估计,从而计算社交相关分数参与POI推荐。由于LBSN中POI推荐的特殊性,单纯使用签到数据进行POI推荐很难取得理想效果。
大量的研究致力于融合签到数据与各类多源信息改进POI推荐的性能[8]。Ying等[4]提出了一种称为UPOI-Walk的模型,综合了用户的社交动机、个性化偏好和POI人气吸引力用于推荐,取得了较好效果。Li等[5]提出了一种两阶段兴趣点推荐模型,集成了社交朋友、位置朋友与邻近朋友3种关系,进一步提高了推荐质量。虽然社交影响改善了兴趣点推荐的效果,但其对POI推荐的贡献非常有限[9]。Ye等[2]提出了一种统一的POI推荐框架,基于协同过滤思想,线性融合用户偏好、社交影响和地理影响,由于引入地理因素,模型推荐效果有了较大提高,但是,影响用户签到决策的内容与时间等信息尚未被模型使用,推荐准确率有待进一步提高。王啸岩等[6]提出了一种称为SoGeoCom的兴趣点推荐模型,融合了社交网络数据、地理位置及评论文本3个因素进行兴趣点推荐,并分别使用协同过滤、幂律分布与隐狄利克雷分布等方法和技术,建模用户社交影响、地理影响与用户评论,该方法虽然使用了用户签到POI留下的评论信息,但是仅仅使用隐狄利克雷分布生成评论的主题,没有识别并利用评论文本的情感指向。一些研究尝试引入时间因素进一步改进推荐效果。Zhang等[7]提出了一种称为TICRec的概率框架,综合考虑了社交、位置与时间影响,并利用工作日和周末的时间影响相关性(TIC)来提高模型的推荐质量,取得了较好效果,但是该方法忽略了用户活动的时间规律性和POI随时间变化的流行度,没有将用户和POI之间的时间匹配融入推荐框架中。
鉴于以上不足,本文做尝试使用自然语言处理技术挖掘用户评论情感倾向捕获用户签到偏好,深度分析时间因素挖掘用户活动时间规律与POI时间流行度之间的匹配,并将社交、地理、内容、时间等多种因素同时融入统一的推荐框架中,提出了内容增强与时间匹配的兴趣点推荐模型,实验结果表明所提出的模型推荐质量有了明显提升。
2 兴趣点推荐模型
2.1 问题描述
在LBSN中,包括用户与位置两类实体,以及用户与位置、位置与位置、用户与用户3种关系。用户对位置的签到活动,生成了用户与位置之间的特殊关系,加强了位置之间的相互关联,同时也促进了用户之间原有社交关系的演化。例如,用户签到了一个新的位置,会在用户与位置之间建立签到关系;同一用户访问的两个位置之间的相关关系会发生改变;两个用户之间的社交关系因其签到了相同的位置而得到加强。两类实体之间的这3种关系随着签到活动的持续推进而动态变化,使得LBSN中集聚的信息更加丰富,如图1所示。POI推荐就是通过挖掘这些海量数据背后隐藏的模式和关系,洞悉用户对位置的偏好,为用户推荐未曾访问过的感兴趣的地理位置。
为便于说明问题,对文中所使用的主要符号作如下约定。U和ui分别表示LBSN中用户的集合和集合中的一个用户,Fi代表用户ui的朋友集合,L和li分别代表LBSN中所有位置组成的集合和集合中的一个位置,Li表示用户ui签到位置组成的集合,CH和chi分别表示LBSN上所有签到记录的集合和其中的一次签到,C和ci分别表示LBSN上所有位置的类别组成的集合和类别集合中的一个元素,R与ri分别代表LBSN中所有评论的集合和其中的一个评论,Ω表示工作日与周末组成的集合。

图1 多源异构的LBSN信息网络
2.2 地理因素建模
通常情况下,受物理约束与成本限制,用户更喜欢访问距离较近的POI,用户访问POI呈现地理聚集现象[10]。研究表明LBSN中用户签到位置的距离呈现幂律分布[11]。因此可以使用幂律分布建模用户签到的地理影响。幂率分布函数如式(1)所示
p(d)=c·d-α
(1)
其中,d表示用户当前POI与候选POI之间的距离,p(d)表示用户签到候选POI的概率,c为归一化常数,α为幂指数。
数据拟合与参数估计的方法有多种,最大似然估计常用于幂律分布的参数估计,可使用最大似然估计法计算幂指数α。位置lm与ln之间的距离dis(lm,ln)可以通过Ha-versine 式(2)计算获得

(2)
其中,R是地球的平均半径,latm与latn分别是lm与ln的纬度,lonm与lonn分别是lm与ln的经度。
设用户ui签到过的POI集合为Li,则ui在Li中所有POI处的签到概率可按式(3)计算
(3)
根据贝叶斯规则,用户在候选POIlj上的签到概率p(lj|Li)可按式(4)计算
(4)
经归一化处理后,用户ui签到lj的地理相关分数可按式(5)计算
(5)
2.3 社交关系建模
社交同质理论表明,社交关系在很大程度上影响人类的移动行为[9]。在LBSN中,用户的社交关系不仅对用户的签到决策产生重要影响,而且可以缓解POI推荐面临的数据稀疏与冷启动问题[12]。通过分析签到数据发现,朋友之间的距离不同,社交关系对签到决策的影响也不相同,距离越近影响越大;用户的社交朋友圈一定程度上反映了个人的文化背景和生活习俗,对用户的签到决策也会产生一定的影响,共同朋友越多,社交关系对签到决策的影响越大;用户签到的兴趣点一定程度上反映了用户的个人品味与兴趣偏好,朋友之间共同签到的POI越多,兴趣偏好越相似,其建议被对方采纳的可能性也越大。综合用户距离、共同朋友、共同签到3个方面来度量不同用户之间的社交影响力具有一定的合理性。定义用户ui与uj之间的社交影响力为社交影响因子soi,j,采用式(6)计算
(6)

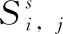
(7)
其中,soi,k为用户ui与uk之间的社交影响因子。
2.4 内容因素建模
LBSN中,与兴趣点关联的内容信息包括评论、照片、视频及评分等。兴趣点推荐算法通常假设,用户总是喜欢其签到过的POI。然而,这种假设忽略了两个事实:一是用户虽然到访了某个POI,却给出了差评;二是用户十分期待尚未签到过的POI。简单地根据用户签到过某POI便得出用户喜欢该POI的结论,显然是不符合实际的。评论文本所蕴含的情感指向才是用户对POI满意度的真实表达。
评论的情感倾向性分析有多种方法,最基本的是基于词典的无监督情感分析方法。该方法使用自然语言处理工具与情感词典,识别评论的情感倾向是积极、消极或中性的。首先需要对原始评论文本进行预处理,包括噪声过滤、标签消除、表情符过滤等,然后使用自然语言处理技术进行分词、词性标注,抽取形容词或副词作为评论的情感词;最后,基于情感词典计算文本中各情感词的极性值总和,作为目标评论的情感倾向性分值。

(8)


(9)
2.5 时间因素建模
2.5.1 用户活动时间规律建模


(10)

(11)

(12)

2.5.2 POI时间流行度建模


(13)
其中,cv(j)表示获取lj类别的操作。

(14)

(15)
2.5.3 用户与POI的时间匹配


(16)

2.6 联合推荐模型

(17)
3 实 验
3.1 实验数据集
采用与文献[19]相同的数据集进行实验。签到数据包含有用户编号、评论文本、位置编号、位置经纬度、签到时间等信息。通过用户编号与位置编号,能够关联用户的社交关系与位置的类别等信息。
为获取评论文本的情感倾向,使用NLTK 3.4与SentiWordNet 3.0[20],首先提取签到数据中的评论文本,滤除非文本符号、非英文字符、URL、重复标点符号等,然后进行拼写校正、词干提取、停用词过滤等,最后对评论进行词性标注,并计算评论的情感倾向性分值。
3.2 评测指标
推荐系统常用的评测指标有准确率(Precision)、召回率(Recall)、均方根误差(RMSE)、平均绝对误差(MAE)等,其中准确率与召回率是通用指标。本文使用Top@N推荐的准确率P@N与召回率R@N进行性能测试。定义如式(18)与式(19)所示
(18)
(19)
其中,R(u)表示推荐给用户u的POI的Top@N列表,T(u)表示测试集中用户实际签到的POI列表。
3.3 参数设置
(1)参数s的设置
参数s的大小反映了模型处理时间因素的粒度,s的取值不同,一方面会影响到用户活动时间规律建模质量,也会影响POI时间流行度模型的精度。为分析s的取值对模型性能的影响并选取最优值,本文在仅考虑时间因素情况下,对比了不同s取值时模型的P@N与R@N,其中,N=5,10,15,20,实验结果如图2与图3所示。当s=24时,模型在不同N值下准确率与召回率平均值分别为0.0314与0.0471,比s=48时模型的准确率平均低0.0004,但召回率平均高出0.005,因此,综合考虑准确率与召回率,当s=24时模型得了最佳性能。

图2 不同s取值下的P@N

图3 不同s取值下的R@N
(2)参数β的设置
为分析β的取值对模型性能的影响并选取合适的β值,本文在仅考虑时间因素情况下,对比了不同β取值时模型的P@N与R@N,其中,N=5,10,15,20,实验结果如图4与图5所示。

图4 不同β取值下的P@N

图5 不同β取值下的R@N
从图中可以看出,当β=5/7时,模型在不同N值下均取得最佳性能,准确率和召回率平均值分别达到最大值0.0319和0.0468。
3.4 性能对比与分析
为了验证本文模型GSRT的有效性,选取US、USG、SoGeoCom、TICRec这4种典型的兴趣点推荐模型作为基准。
(1)US:一种称为UPOI-Walk的兴趣点推荐模型,通过用户的个性化兴趣、社交动机和位置的人气吸引力推断用户位置偏好[4]。
(2)USG:一种兴趣点推荐方法的经典代表,通过组合用户个性化偏好、社交关系和地理位置综合预测用户兴趣位置[2]。
(3)SoGeoCom:一种整合社交网络数据、地理位置及评论文本3个因素的兴趣点推荐方法[6]。
(4)TICRec:考虑了社交影响、地理位置与时间影响相关性因素,利用工作日和周末的时间影响相关性(TIC)来实现时间感知的兴趣点推荐[7]。
(5)GSRT模型:本文提出的集成了社交因素、地理影响、时间匹配、评论情感、分类与流行度信息的推荐模型。
实验中,设置s=24,β=5/7,推荐列表长度N=5,10,15,20,实验结果如图6与图7所示。

图6 各模型精确率P@N对比

图7 各模型召回率R@N对比
从图6和图7中可以看出,所有对比方法的准确率与召回率都比较低,不同N值下,准确率和召回率最高分别为0.176和0.074,这是由于LBSN中用户签到数据集非常稀疏,导致绝对准确率与召回率较低,这与多数主流兴趣点推荐算法的实验结果是一致的[2,7]。
从图6和图7中也可以看出,当推荐列表长度增加时,各种对比基线的准确率和召回率变化趋势与文献[19]实验结果一致。
从图6和图7中还可以看出,US模型的推荐准确率和召回率最低,不同N值下,准确率与召回率最高分别为0.082与0.038,这是因为该模型仅仅考虑了用户的社交关系、分类偏好与POI流行度因素,没有考虑地理位置、评论文本与时间因素。USG比US预测效果要好,是由于模型引入了地理位置信息作为预测因素,但与GSRT模型相比,USG模型没有考虑评论文本与时间因素,也没有利用POI分类与流行度信息,模型的预测性能仍有较大提升空间。与USG相比,SoGeoCom增加了评论文本信息,并通过隐狄利克雷分布挖掘评论的话题用于捕捉用户偏好,导致推荐质量有所提升,但与GSRT相比,未考虑时间因素、分类与流行度信息,也未挖掘用户评论的情感倾向,因此推荐效果比较差。TICRec模型融合了社交影响、地理影响与时间影响相关性3个因素,与SoGeoCom相比,虽未考虑评论文本,但是由于模型集成了时间影响因素,并利用工作日和周末的时间影响相关性改善推荐质量,推荐效果较好,但与GSRT相比,缺乏对评论文本、分类与流行度信息的利用,推荐质量相对较低。GSRT模型在建模地理位置、社交关系对推荐预测影响的基础上,将用户评论内容的情感指向与用户活动的时间规律性匹配同时引入推荐框架中,并集成了位置的分类流行度信息,以增强推荐模型的预测能力,在不同的推荐列表长度下,准确率达到0.176的最高值,与对比方法TICRec相比,准确率与召回率平均提高了17%与21%。验证了同时引入评论内容的情感指向与用户活动时间规律性匹配能够有效改善模型的预测性能。
3.5 模型消解
为解析内容与时间因素对POI推荐的贡献度,通过删除GSRT模型相应组件的方式构建了2个对比模型,分别是GSRT模型删除时间因素与评论文本后获得的子模型GSR与GST模型。实验中,N=5,10,15,20,并设置GST与GSRT模型的s=24,β=5/7,实验结果如图8与图9所示。

图8 各模型精确率P@N对比
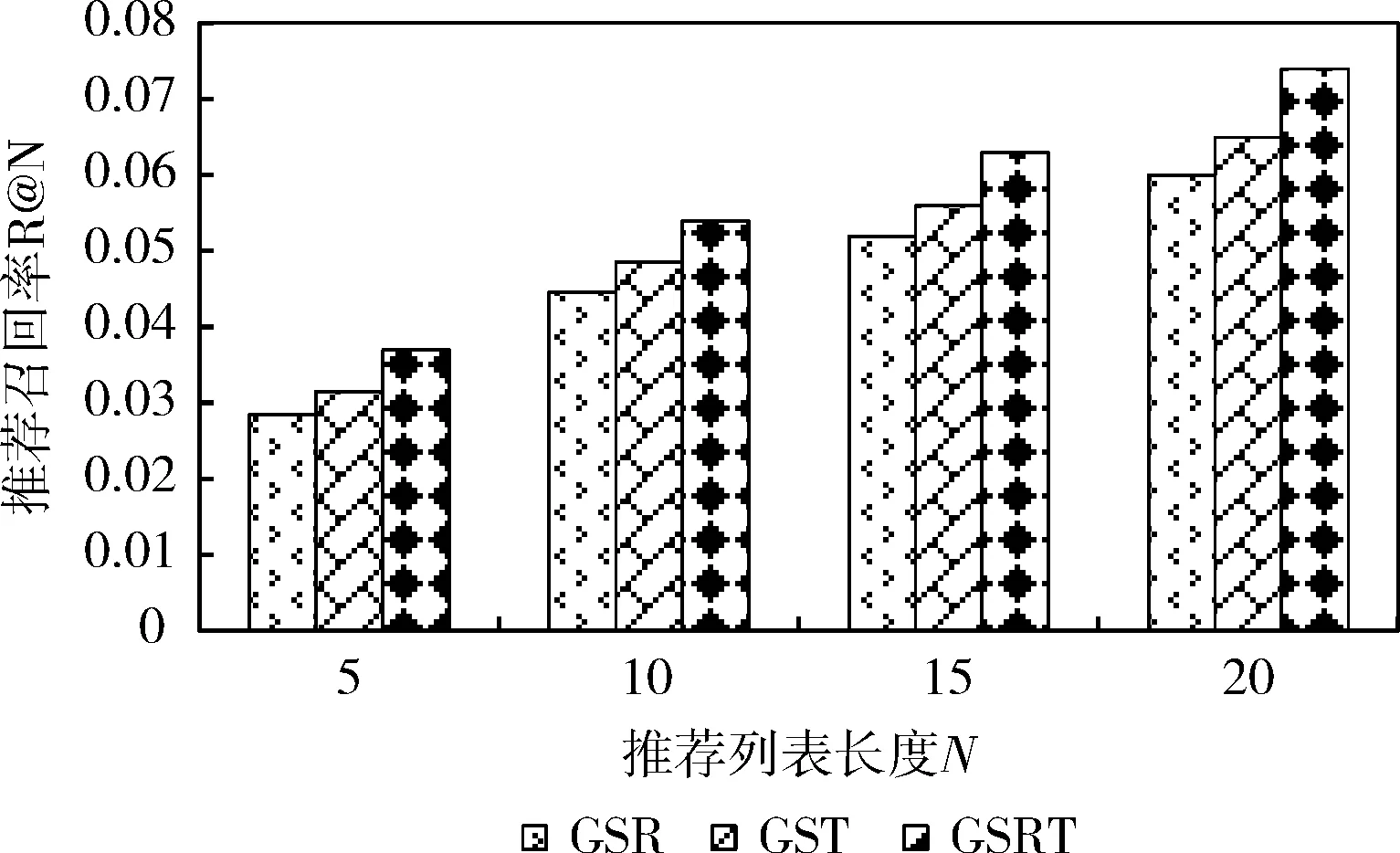
图9 各模型召回率R@N对比
从图中可以看出,融合了地理、社交、内容、时间等因素的GSRT模型明显优于GSR与GST模型,不同N值下,准确率与召回率至少分别提升了0.013与0.0054,这是由于融合了更多因素的推荐模型能够更加准确地建模用户的签到偏好,获得更好的推荐效果。
此外,从图中还可以看出,融合了地理、社交、时间因素的GST模型明显优于融合了地理、社交、内容的GSR模型,不同N值下,准确率与召回率至少分别提升了0.006与0.003,说明时间因素对兴趣点推荐的影响大于内容因素,这是因为人们的日常活动更多的受到时间的制约,尽管人们非常喜欢某个位置,但是时间约束限制了个人偏好的发挥。
4 结束语
本文针对LBSN中现有的兴趣点推荐方法存在的不足,提出了内容增强与时间匹配的POI推荐模型GSRT,该模型在考虑地理位置、社交关系基础上,融入评论情感与时间等因素,通过使用自然语言处理技术挖掘评论文本的情感倾向,来调节用户偏好估计,通过建模用户活动时间规律与POI的时间流行度,匹配用户签到行为,进一步增强推荐性能。大规模Foursquare真实数据上的实验结果表明,GSRT模型明显优于当前主流的兴趣点推荐模型。
近年来,深度学习技术发展迅速[21],并在一些领域取得重大进展,为人工智能和机器学习带来了革命性变革,已被用于各种自然语言处理、数据分析与个性化推荐任务中[22]。因此,未来的研究中,我们将考虑如何将深度学习技术应用到兴趣点推荐中,以进一步提高模型的训练精度和推荐质量。
